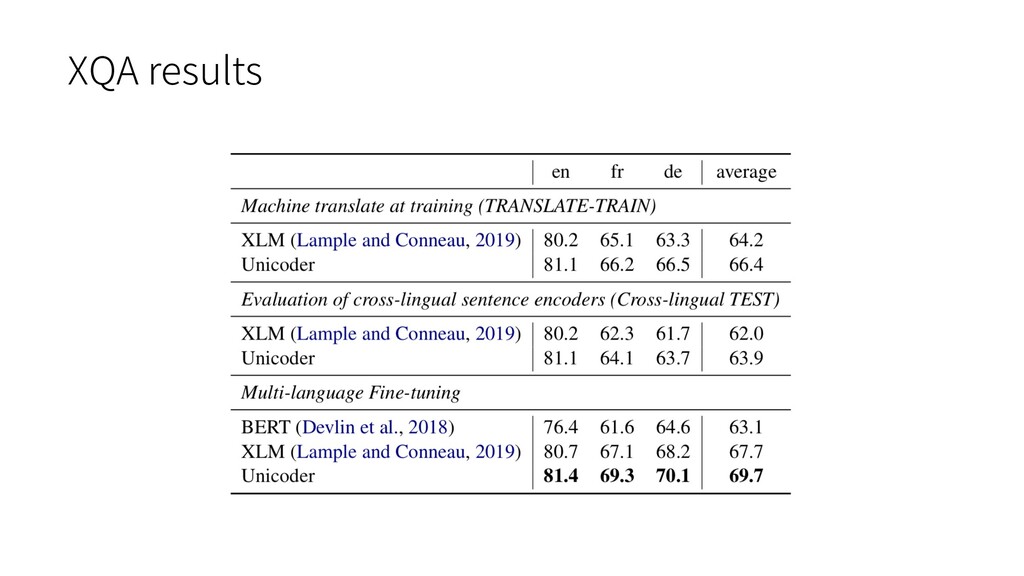
are collected from MultiUN, II TBombay corpus, OpenSubtitles2018, EUbook-shop corpus and Gloval voices Model • 12-layer Transformer with 1024 hidden units and 16 heads Task • Cross-lingual Natural Language Inference (XNLI) • Cross-lingual Question Answering (XQA) Ø They proposed a new dataset XQA. Ø XQA contains three languages including English, French and German. Ø Only English have training data. Experiment settings
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}