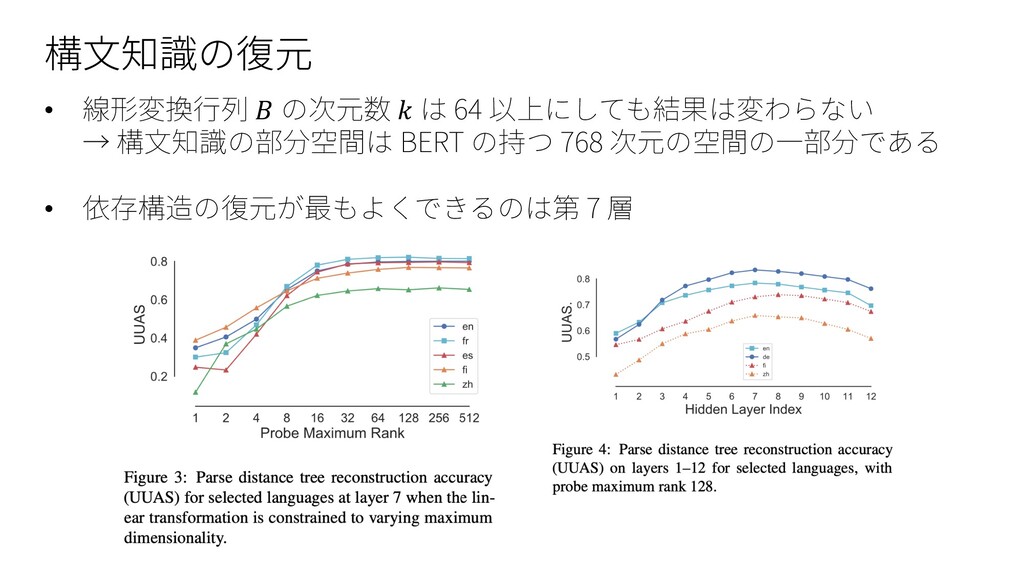
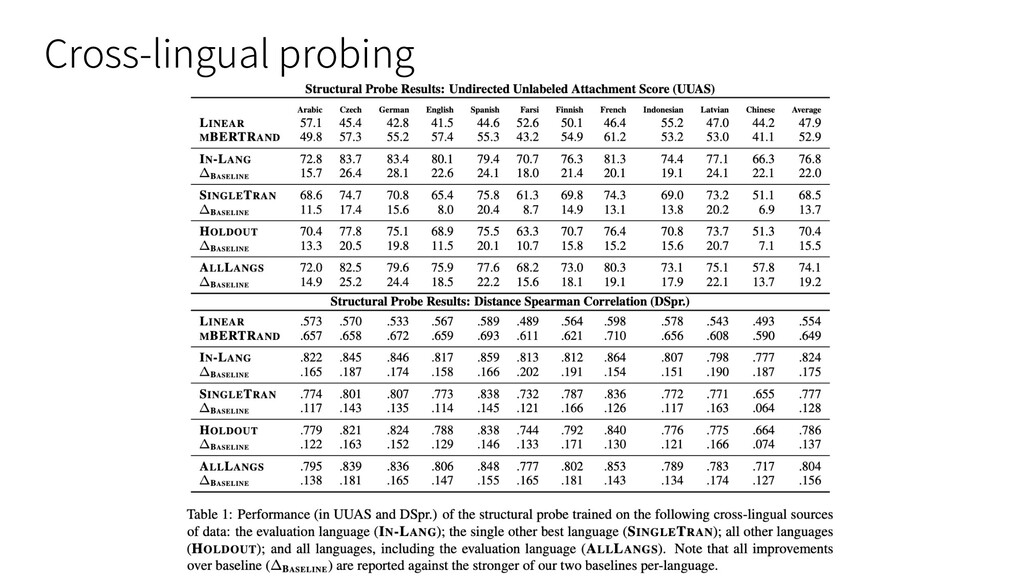
• Model : Multilingual BERT (Google-research, pre-trained) 104 languages, 12-layer, 768-hidden, 12-heads, 110M parameters • Baselines : MBERTAND : ランダム初期化された Multilingual BERT LINEAR : 全ての単語の依存構造が左から右に連なっていると仮定 したモデル • 評価⼿法 : UUAS (Unlabeled Undirected Attachment Score) : 各⽂の各単語間に正しい辺が貼られているものの割合 DSpr. : スピアマンの相関係数
{kind=link}
{kind=link}
![先⾏研究 [Hewitt et.al., 2019] • structural probe を提案 Ø BERT](https://files.speakerdeck.com/presentations/844dedae165544e1b847eb89d80b7898/slide_2.jpg){kind=link}
![実験設定 • Data : Universal Dependencies v2 [Nivre et.al., 2020]](https://files.speakerdeck.com/presentations/844dedae165544e1b847eb89d80b7898/slide_3.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}