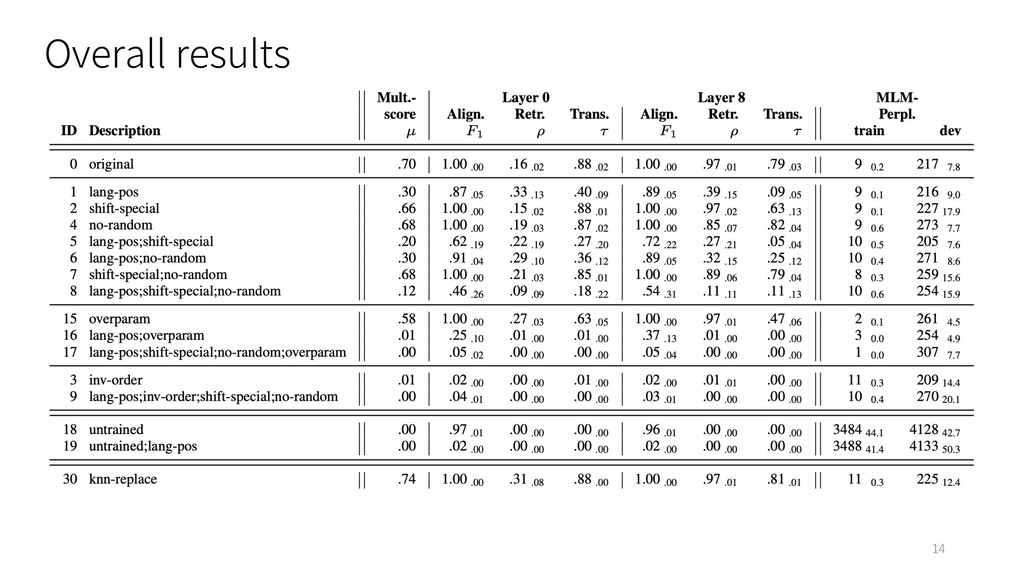
Word Translation 4 d-dimensional wordpiece embedding : similarity matrix : Two wordpieces and are aligned if Word Alignment の評価は precision, recall, ! で評価
ℎ- Ø Shared Position Embedding: - Ø Random Word Replacement: - 9 仮説: special token ([UNK], [CLS], [SEP], [MASK], [PAD]) は頻繁に出てく る且つ語彙が共有されていない設定でも共有されている →multilinguality に影響を与えているのではないか 検証のため special token についても id をシフトして実験
ℎ- Ø Shared Position Embedding: - Ø Random Word Replacement: - 10 仮説: position embedding は通常⾔語間で共有されており multilinguality に⼤きな影響を与えているのではないか 検証のため⾔語独⾃の language position を⽤いて実験
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}