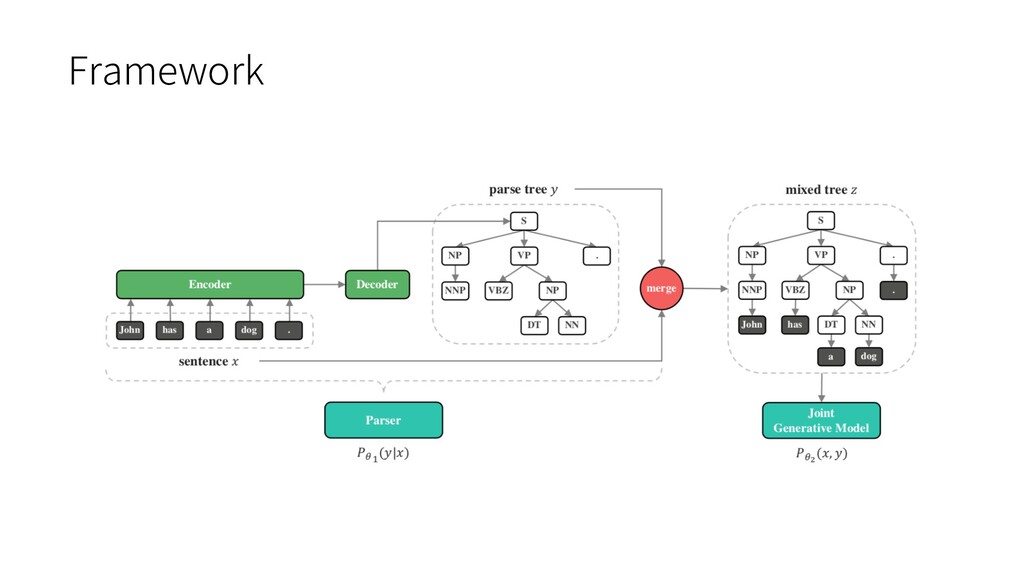
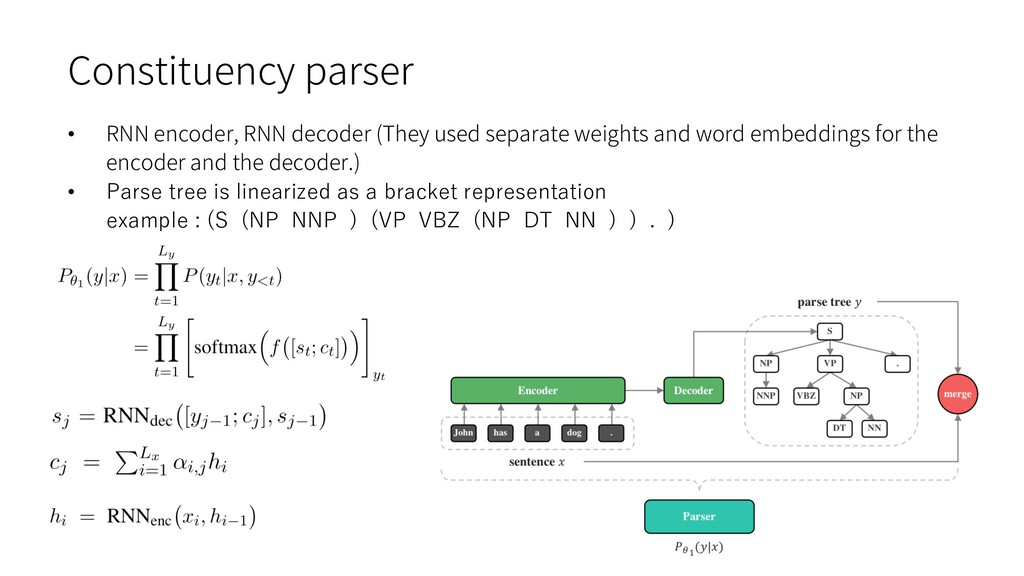
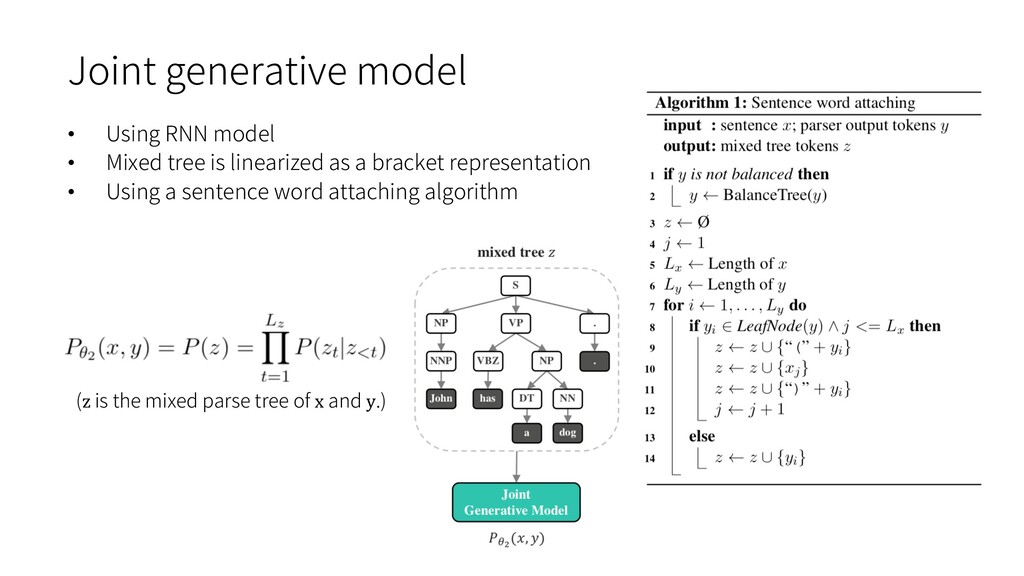
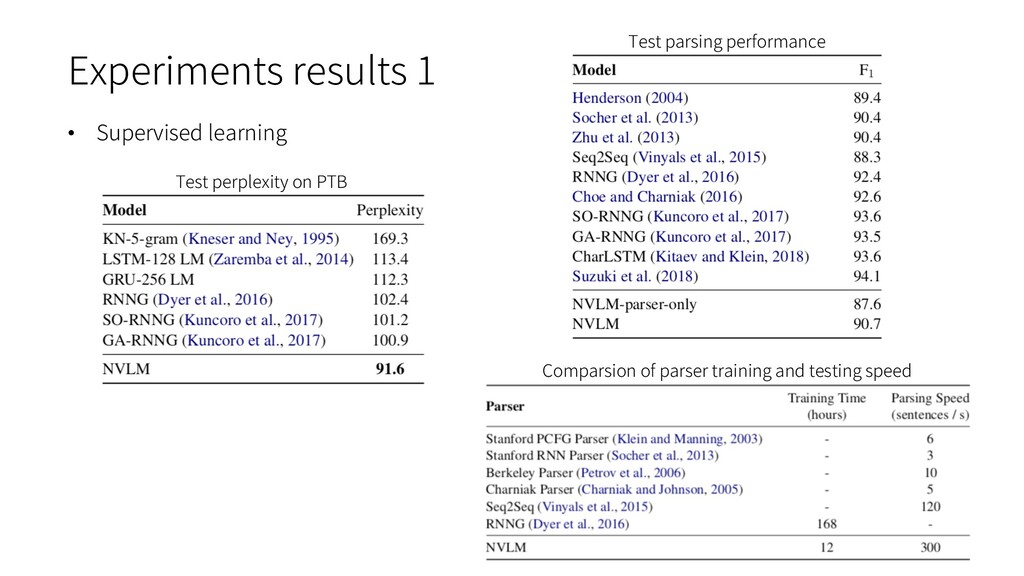
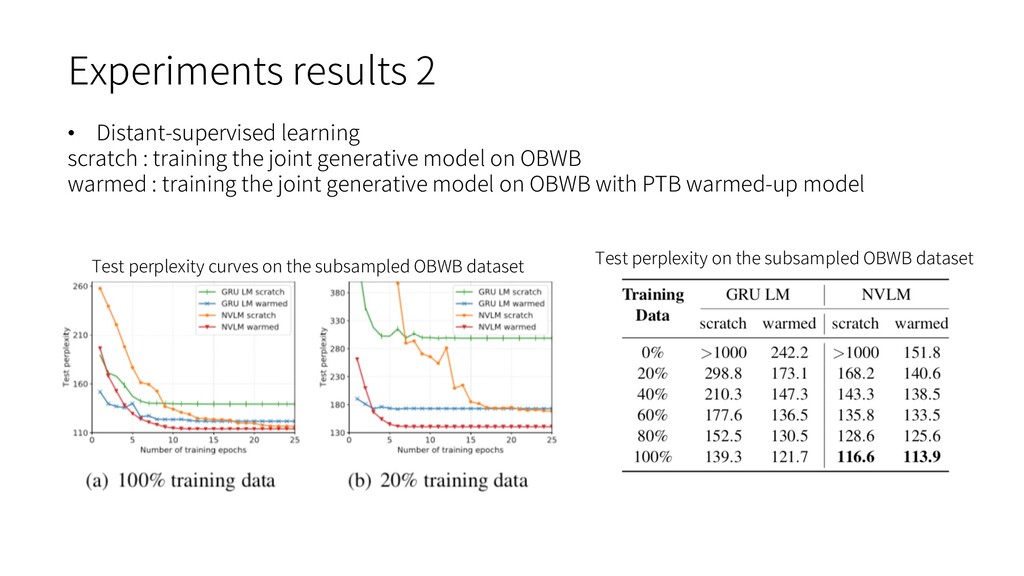
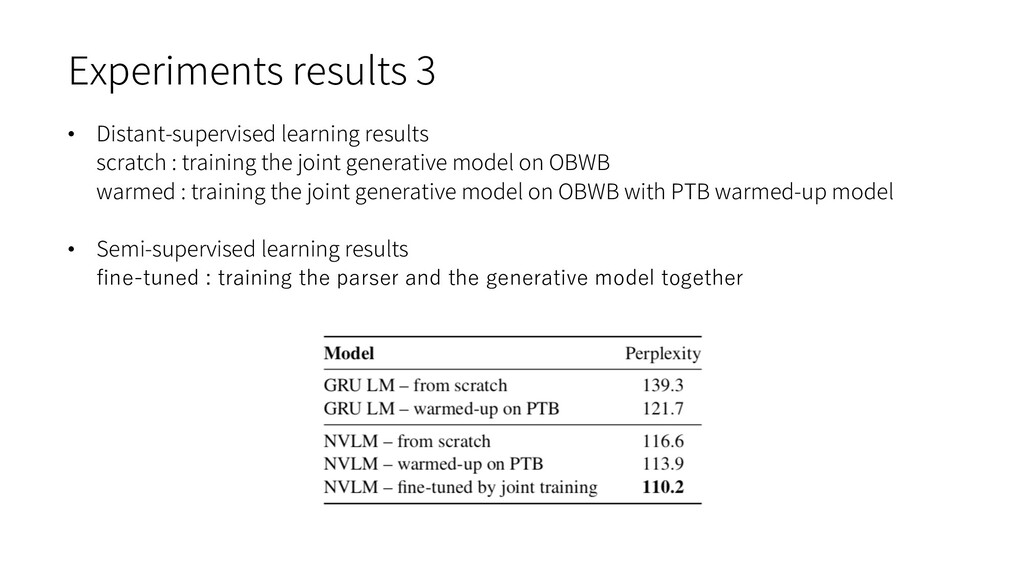
natural language latent structure, such as RNNGs and PRPNs, require syntactic annotations. Ø accurate syntactic annotation is very costly Ø tree bank data is typically small-scale and not open to the public • The RNN language model performs terribly when training and testing on different datasets. • Training from scratch on every new corpus is obviously not good enough. Ø computationally expensive and not data-efficient Ø The size of target corpus may be too small To bridge the gap of language modeling on different corpora, grammar is the key since all corpora are in the same language and should share the same grammar.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}