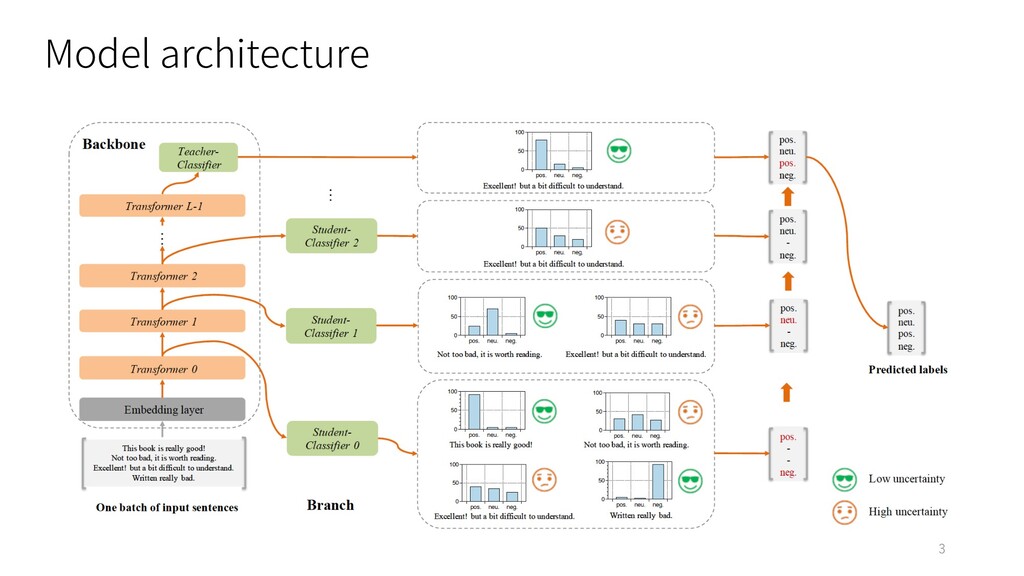
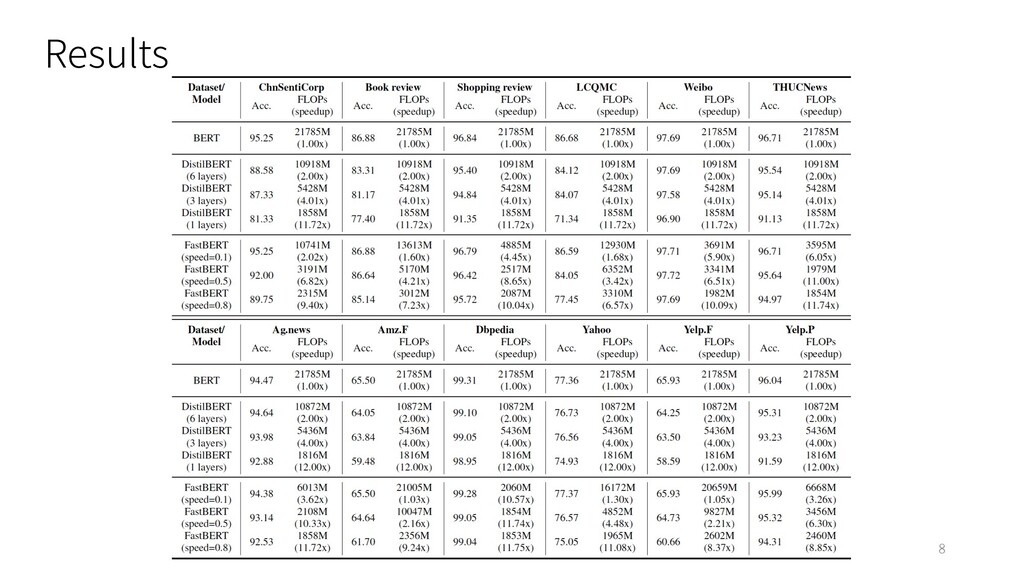
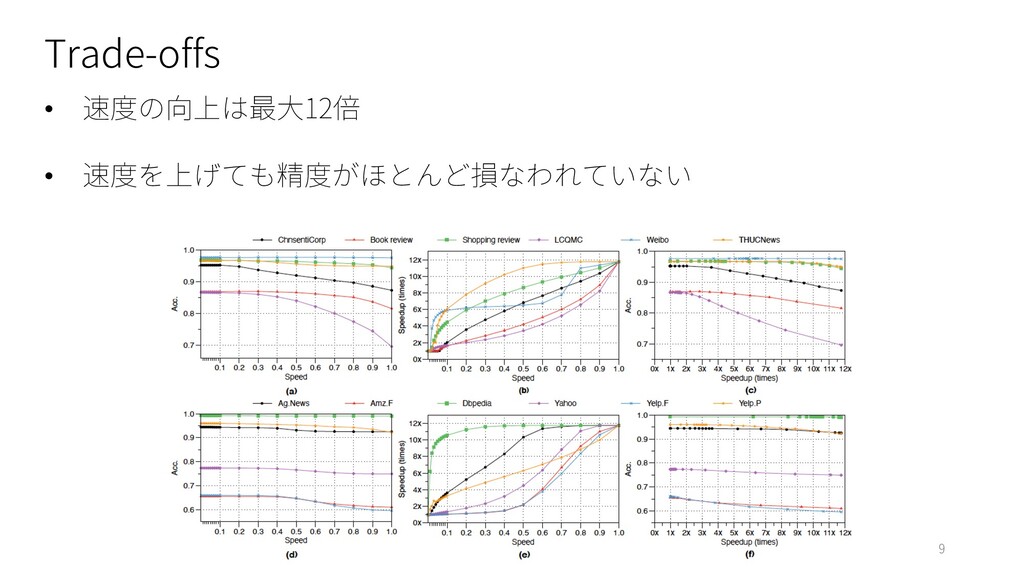
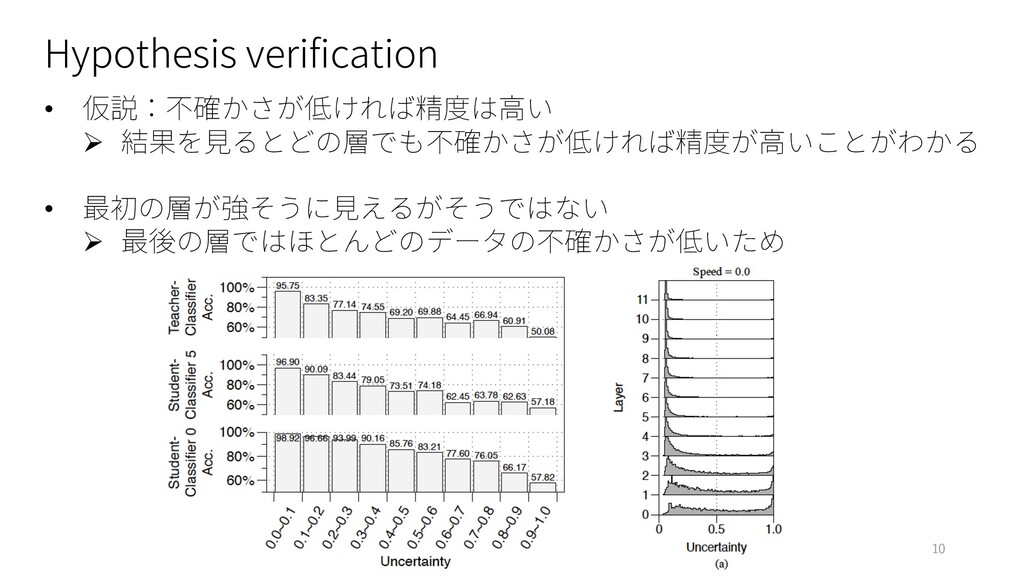
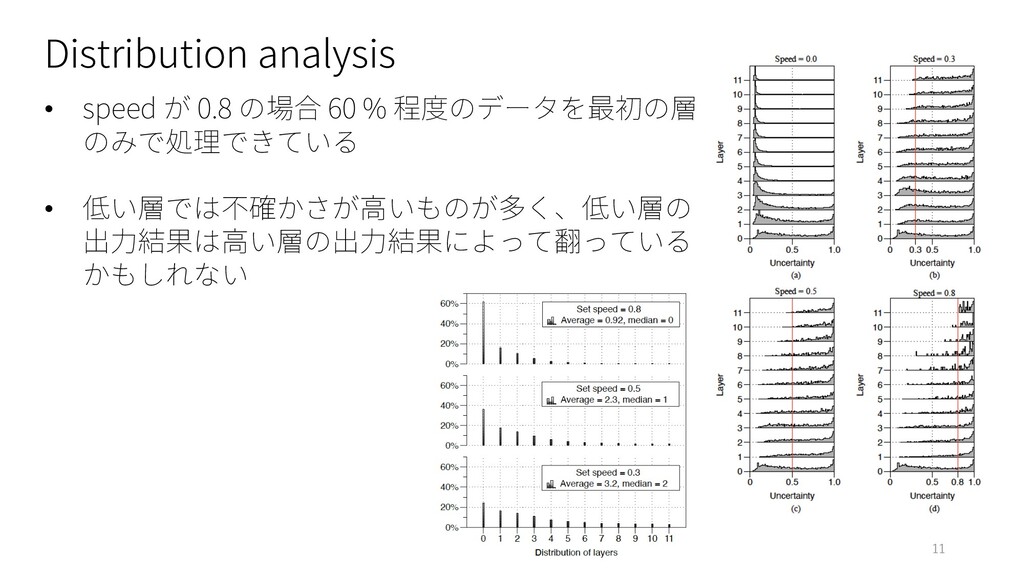
: ChnSentiCorp, Book review, Shopping review, Weibo and THUCNews Ø English : Ag.News, Amz.F, DBpedia, Yahoo, Yelp.F and Yelp.P • Model : BERT-base model (Google-research) • Baselines : BERT, DistillBERT • Evaluation Metrics : Ø Accuracy Ø FLOPs (Floating-point operations) 7
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}