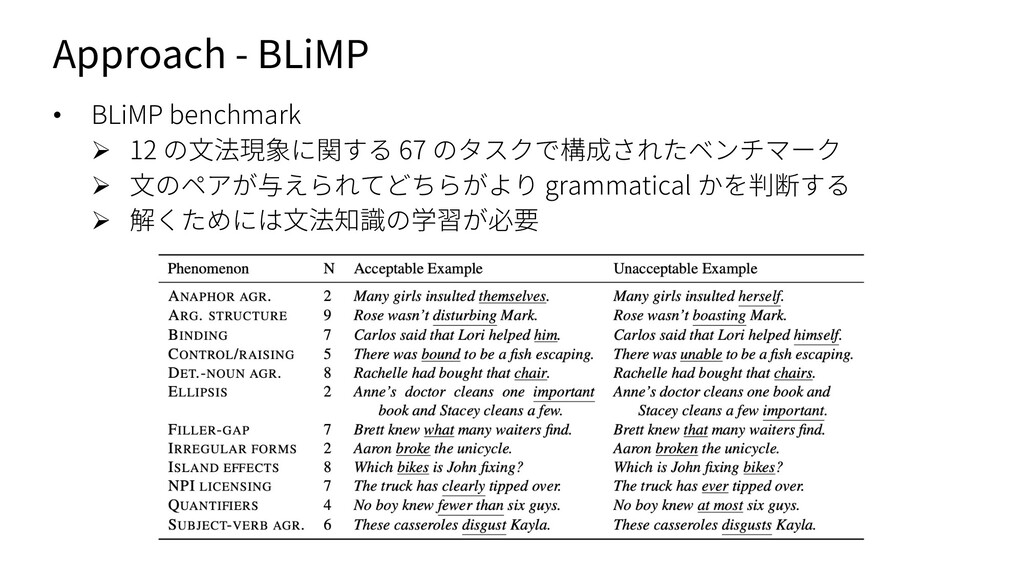
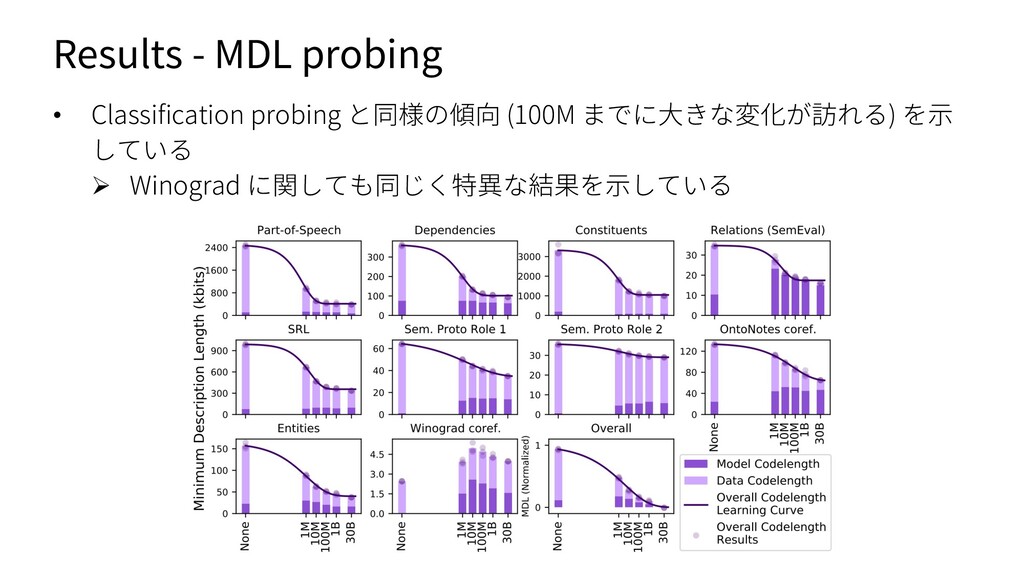
通常の probing では性能しか⾒ていない,という問題点を解消すること を⽬指した probing ⼿法 (classifier を学習するのは通常と同じ) Ø 簡単に⾔うと,性能を達成するために必要なデータ量も勘案してスコア をつけている (データ量を横軸,loss を縦軸にとった際の学習曲線の AUC を⾒ている) Ø ラベル y を⼊⼒ x を圧縮した姿だと捉えて伝送コストを考える ü Data codelength: 最終的なモデルの質を⽰す,loss を⽤いる ü Model codelength: 表現からラベルを抽出するための労⼒を⽰す
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}