NLP では語彙の圧縮・未知語問題解決のために使われている ü 単語分割では未知語が出る,⽂字分割では計算量の問題がある ü そこで,⽂字以上単語以下のサブワードで分割をしたい ü ただし闇雲にやるのではなく意味のある分割が望ましい Ø (ざっくりいうと) 全単語を⽂字に分割 → 頻度の⾼い 2-gram を結合,を 繰り返して語彙を得る 例: {[q, u, i, c, k, l, y], [a, c, c, u, r, a, t, e, l, y]} → {[q, u, i, c, k, ly], [a, c, c, r, a, t, e, ly]}
Ø NSP (Next Sentence Prediction) • 2種類の Loss (⼀度に⽤いるのは1つ) Ø Autoregressive Character Loss ü 空⽩区切りのスパンで mask or replace → predict ü 予測の際の順序はシャッフル (left-to-right である必要はない) Ø Optional Subword Loss ü サブワード単位で mask → predict ü サブワードの語彙は存在しないため replace はなし
{kind=link}
{kind=link}
{kind=link}
{kind=link}
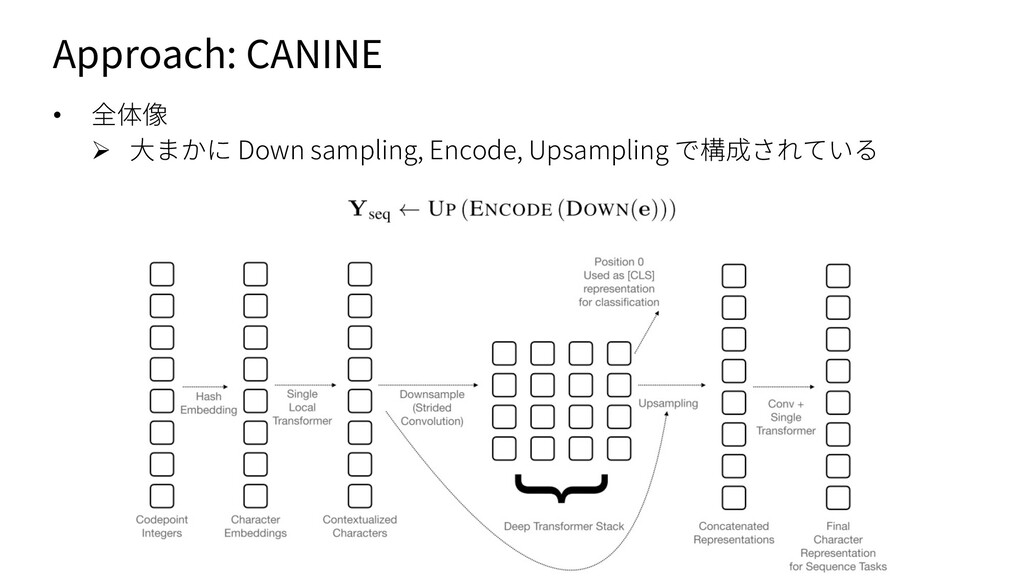{kind=link}
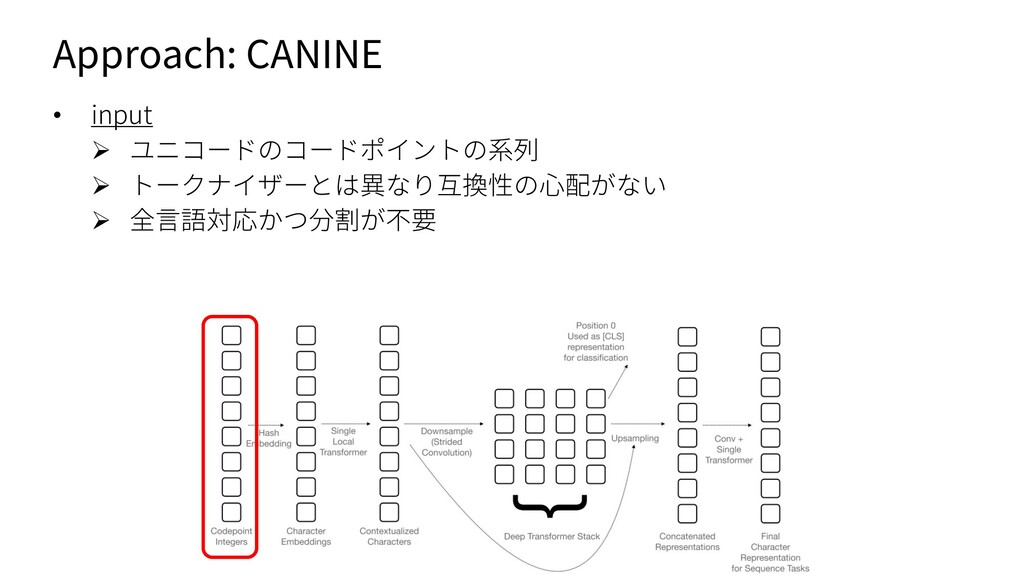{kind=link}
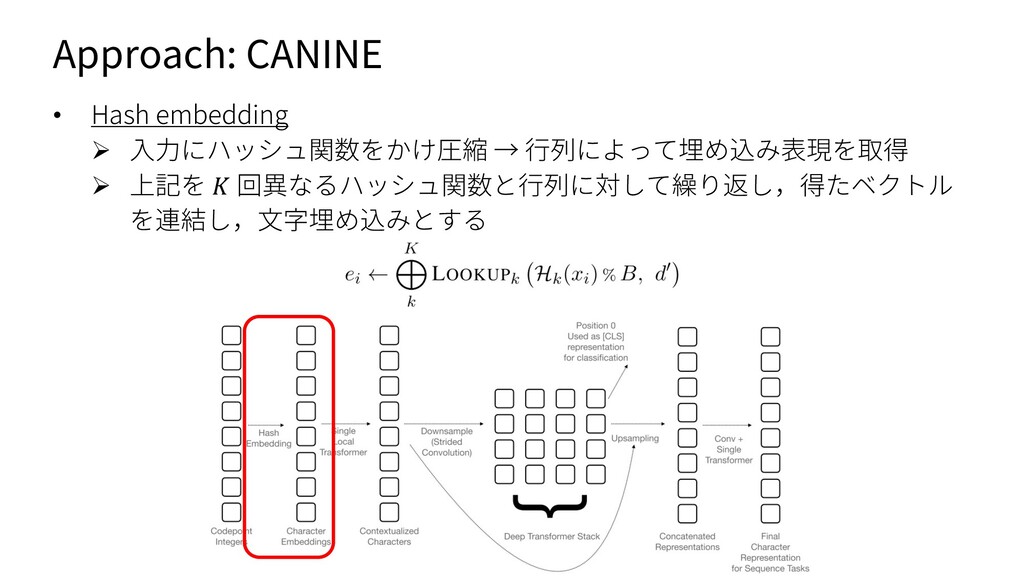{kind=link}
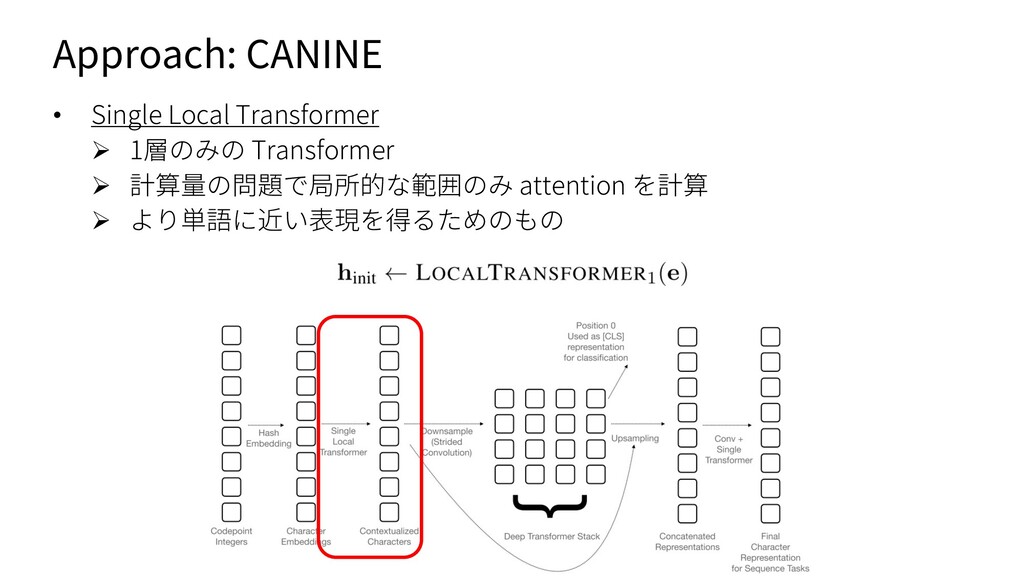{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
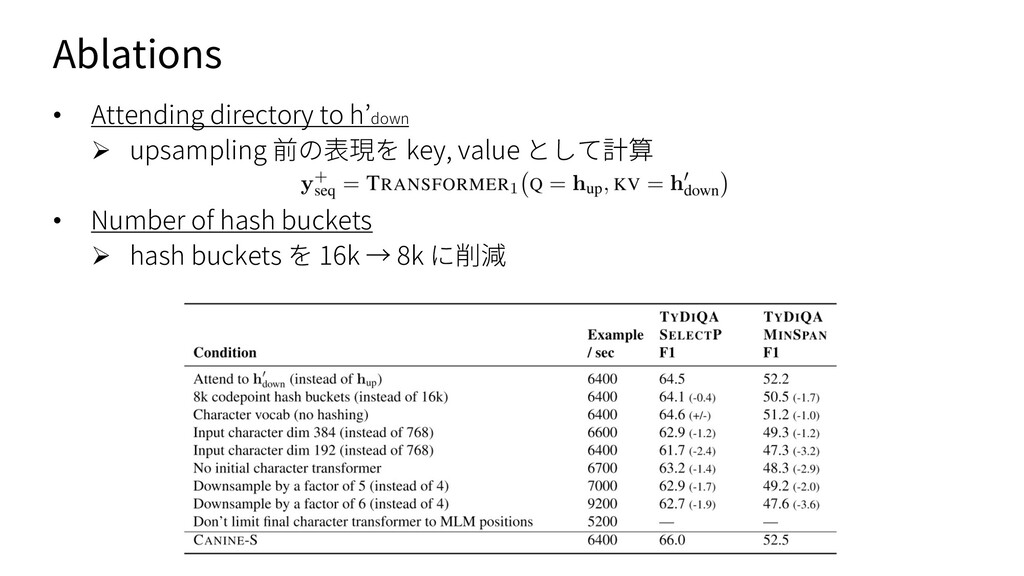{kind=link}
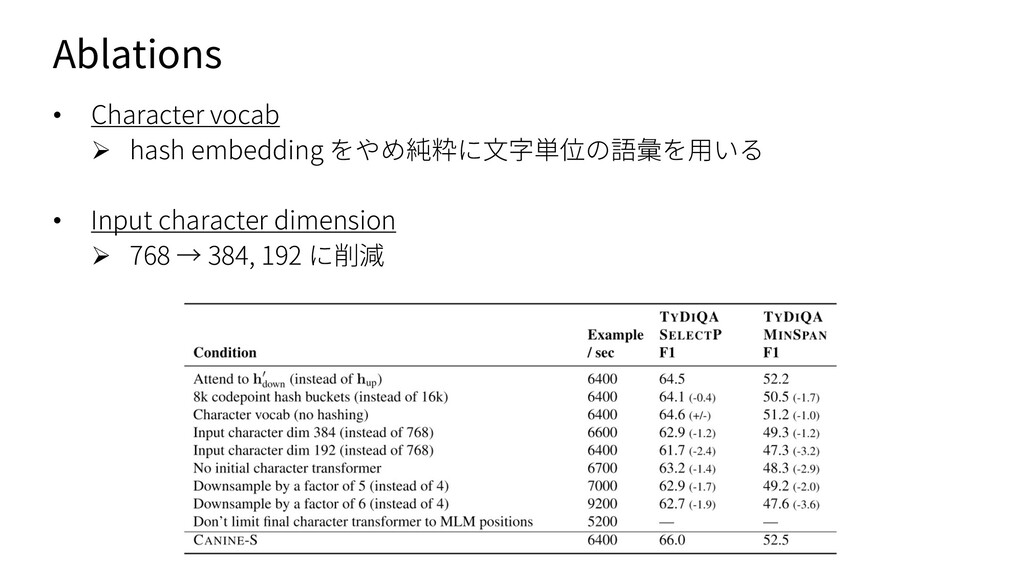{kind=link}
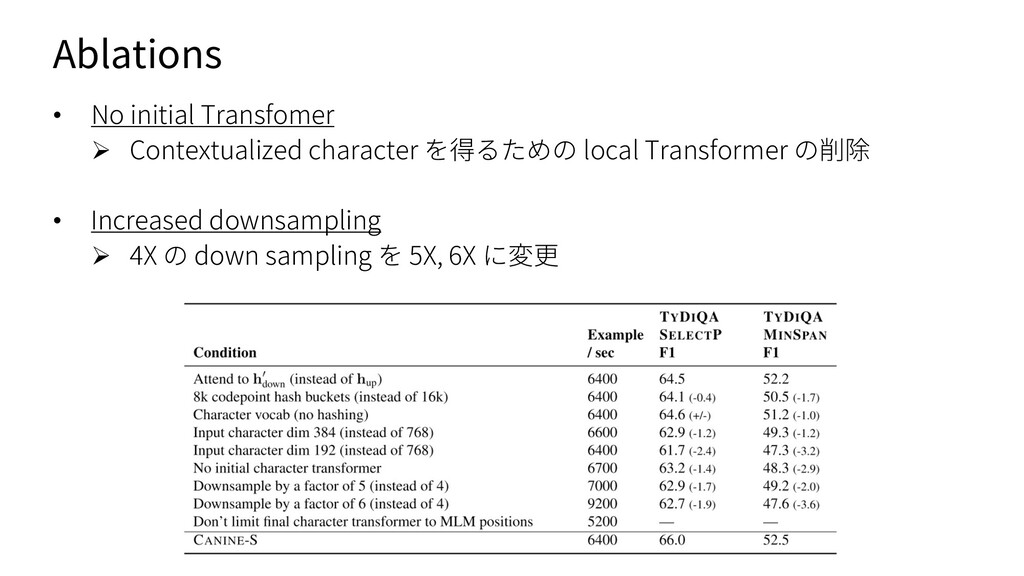{kind=link}
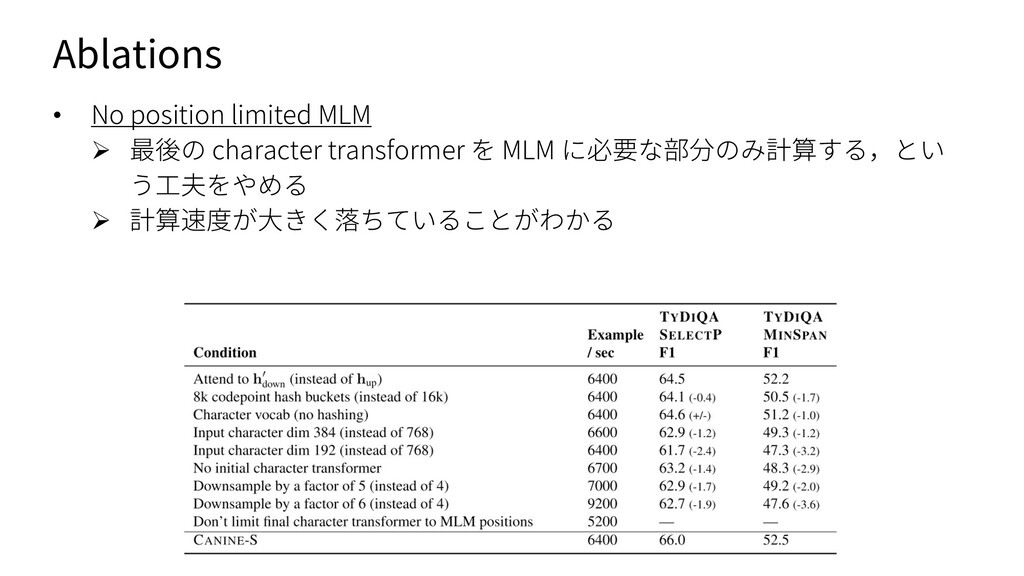{kind=link}
{kind=link}
{kind=link}