Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
2019ACL読み会_Choosing-Transfer-Languages-for-Cros...
Search
Sponsored
·
SiteGround - Reliable hosting with speed, security, and support you can count on.
→
Ikumi Yamashita
November 18, 2019
Technology
61
0
Share
2019ACL読み会_Choosing-Transfer-Languages-for-Cross-Lingual-Learning
Ikumi Yamashita
November 18, 2019
More Decks by Ikumi Yamashita
See All by Ikumi Yamashita
2021論文紹介_When-Do-You-Need-Billions-of-Words-of-Pretraining-Data?
ikumi193
0
190
2021EACL/NAACL論文紹介_Multilingual-LAMA-Investigating-Knowledge-in-Multilingual-Pretrained-Language-Models
ikumi193
0
71
2021論文紹介_CANINE:-Pre-training-an-Efficient-Tokenization-Free-Encoder-for-Language-Representation
ikumi193
0
330
2020COLING読み会_Linguistic-Profiling-of-a-Neural-Language-Model
ikumi193
0
110
2020EMNLP読み会_Identifying-Elements-Essential-for-BERT's-Multilinguality
ikumi193
0
140
2020ACL読み会_FastBERT:-a-Self-distilling-BERT-with-Adaptive-Inference-Time
ikumi193
0
160
2020論文紹介_Finding-Universal-Grammatical-Relations-in-Multilingual-BERT
ikumi193
0
290
2019EMNLP読み会_Unicoder_A_Universal_Language_Encoder_by_Pre-training_with_Multiple_Cross-lingual_Tasks
ikumi193
0
72
2019論文読み会_Language-Modeling-with-Shared-Grammar
ikumi193
0
230
Other Decks in Technology
See All in Technology
正解のないAIプロダクトをどう導くか?dodaが挑む、ユーザーの『本音』を構造化する評価設計と検証のリアル
techtekt
PRO
0
180
電子辞書Brainをネットに繋げてみた(自力編)
raspython3
0
430
ポケモンの型をTypeScriptの型システムで表現してみた
subroh0508
0
290
React、まだ楽しくて草
uhyo
7
4k
「気づいたら仕事が終わっている」バクラクAIエージェント本番運用の裏側 / layerx-bakuraku-aie2026
yuya4
18
9.7k
生成 AI × MCP で切り拓く次世代 SRE!自律型運用への挑戦と開発者体験の進化
_awache
0
140
【5分でわかる】セーフィー エンジニア向け会社紹介
safie_recruit
0
50k
マーケットプレイス版Oracle WebCenter Content For OCI
oracle4engineer
PRO
5
1.8k
速さだけじゃない! VoidZero ツールが移行先に選ばれる理由
mizdra
PRO
6
740
サイバーセキュリティ概論 / Introduction to Cybersecurity
ks91
PRO
0
140
ルールやカスタム機能、どう使う?理想の出力を引き出すために今知りたいIBM Bob 5つの機能
muehara
1
330
noUncheckedIndexedAccess、3時間、1万円。 / noUncheckedIndexedAccess, 3 Hours, 10,000 JPY.
kaonavi
1
270
Featured
See All Featured
Navigating the moral maze — ethical principles for Al-driven product design
skipperchong
2
380
Are puppies a ranking factor?
jonoalderson
1
3.5k
Building AI with AI
inesmontani
PRO
1
1.1k
Typedesign – Prime Four
hannesfritz
42
3.1k
Building a Scalable Design System with Sketch
lauravandoore
463
34k
個人開発の失敗を避けるイケてる考え方 / tips for indie hackers
panda_program
122
22k
Color Theory Basics | Prateek | Gurzu
gurzu
0
340
How to build an LLM SEO readiness audit: a practical framework
nmsamuel
1
770
How to Talk to Developers About Accessibility
jct
2
220
sira's awesome portfolio website redesign presentation
elsirapls
0
270
How to make the Groovebox
asonas
2
2.2k
RailsConf & Balkan Ruby 2019: The Past, Present, and Future of Rails at GitHub
eileencodes
141
35k
Transcript
Choosing Transfer Languages for Cross-Lingual Learning Yu-Hsiang Lin, Chian-Yu Chen,
Jean Lee, Zirui Li, Yuyan Zhang, Mengzhou Xia, Shruti Rijhwani, Junxian He, Zhisong Zhang, Xuezhe Ma, Antonios Anastasopoulos, Patrick Littell, Graham Neubig ACL2019 2019/11/18 ACL2019読み会 紹介者:⼭下郁海
Overview • Cross-Lingual Transfer において最適な転移元の⾔語を選ぶためのフレーム ワーク -"/( 3"/, を提案 •
Machine Translation, Entity Linking, POS tagging, Dependency Parsing の4つ のタスクにおいて従来の転移元⾔語の選択⽅法よりも良い転移元⾔語を選択 できることを⽰した • 複数の素性でモデルを学習し、転移元⾔語の選択にどういった素性が強く影 響しているのかの分析を⾏った
Previous works 従来の転移元⾔語の選択⽅法 • 同じ語族の⾔語から選ぶ → 単⼀の語族の⾔語全てが同じ特性を持つとは限らない • タスクに重要な⾔語特性が類似したものから選ぶ (例
: Parsing task における語順が類似したもの) → どの⾔語特性が転移の際に重要であるかは⾃明ではない
-"/( 3"/, 特定の NLP タスクにおけるタスク⾔語と転移元⾔語の集合が与えられたとき、 スコアを⾼くするような転移元⾔語を選ぶランキングタスクとして定義 タスク⾔語と転移元⾔語のペアから複数の素性を抽出 → モデルを学習
Ranking features (Data-dependent) • Dataset size • Type-Token ratio (TTR)
• Word overlap and subword overlap "# : 転移元⾔語の training example 数 "$ : タスク (転移先) ⾔語の training example 数 % &'( &') : dataset size の⽐ MT, POS, DEP はコーパス中の⽂数 EL は bilingual entity gazetter 中の entity 数
Ranking features (Data-dependent) • Dataset size • Type-Token ratio (TTR)
• Word overlap and subword overlap "# : 転移元⾔語の type 数と token 数の⽐ "$ : タスク (転移先) ⾔語の type 数と token 数の⽐ "", = (1 − "'( "') )2 : TTR 間の距離 EL には TTR に関連する feature は⼊れていない
Ranking features (Data-dependent) • Dataset size • Type-Token ratio (TTR)
• Word overlap and subword overlap "# , "$ : 転移元⾔語とタスク (転移先) ⾔語の type 集合 "#, "$ : 転移元⾔語とタスク (転移先) ⾔語の subword 集合
Ranking features (Data-independent) • Geographic distance • Genetic distance •
Inventory distance • Syntactic distance • Phonological distance • Featural distance ※ 全て URIEL Typological Database から取得 678 : Glottolog 3.3 に基づいた地球表⾯状の⾔語距離 679 : Glottolog 3.3 の⾔語系統⽊に基づいた⾔語の系図状の距離
Ranking features (Data-independent) • Geographic distance • Genetic distance •
Inventory distance • Syntactic distance • Phonological distance • Featural distance :9; : PHOIBLE database に基づいた⾳韻素性ベクトル間のコサイン距離 &<9 : WALS database に基づいた⾔語構造素性ベクトル間のコサイン距離
Ranking features (Data-independent) • Geographic distance • Genetic distance •
Inventory distance • Syntactic distance • Phonological distance • Featural distance =>8 : WALS database と Ethnologue database に基づいた⾳韻素性ベク トル間のコサイン距離 #7? : 上記の 5 つの特徴を結合させたベクトル間のコサイン距離
Ranking model Model : GBDT + LambdaRank 1 つのモデルあたりの決定⽊の数は 100
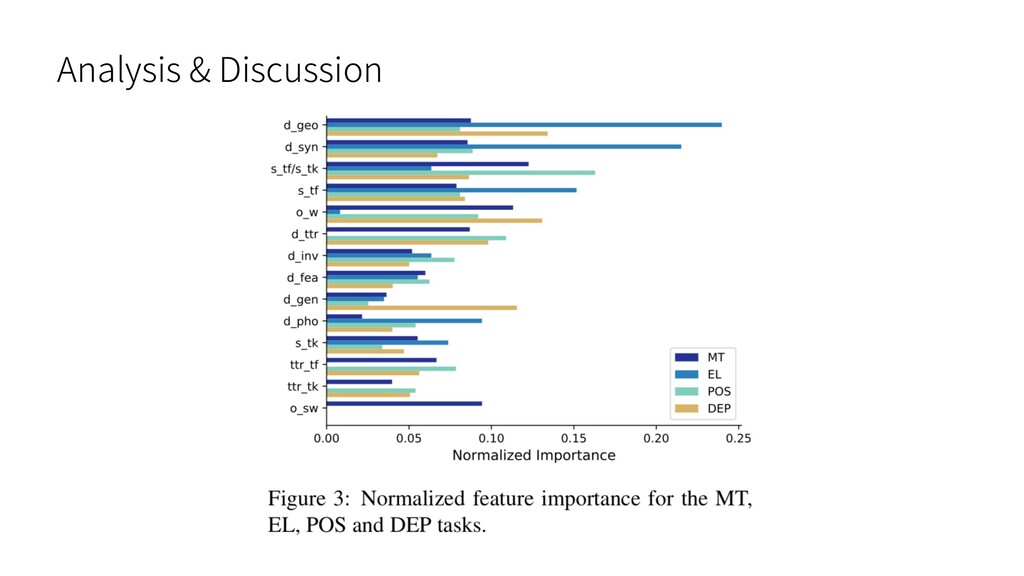
1 つの決定⽊あたりの葉の数は 16 利点 : 1 ) 現在の SOTA の⼿法の⼀つ (特に特徴量が少なくデータに限りがあるときに 強い) 2 ) 決定⽊ベースのアルゴリズムは⽐較的解釈しやすい (どういった素性が重要なのかの分析がしやすい)
Experimental settings • MT Model : attention-based seq2seq model (Bahdanau
et al., 2015). Data : multilingual TED talk corpus (転移元もタスクも 56 ⾔語, 翻訳先は全て 英語) → 2862 task/transfer pairs 転移は転移元⾔語とタスク⾔語のデータを concat して学習することで⾏う • EL Model : two character-level LSTM encoders Data : ⾔語に link した Wikipedia article titles のデータ (タスク⾔語が9, 転移 元⾔語が 53) → 477 task/transfer pairs zero-shot setting で学習
Experimental settings • POS Model : bi-directional LSTM-CNN-CRF model Data
: Universal Dependencies v2.2 dataset (データの少ないタスク⾔語 26, 転移元⾔語 60 を選択) → 1545 task/transfer pairs タスク⾔語の train データがあれば concat して, なければ転移元⾔語のみで 学習 • DEP Model : deep biaffine attentional graph-based model Data : Universal Dependencies v2.2 dataset (タスク⾔語, 転移元⾔語共に 30 を選択) → 870 task/transfer pairs zero-shot setting で学習
Evaluation protocol 1 それぞれのタスクのモデルの評価は leave-one-out cross validation で⾏う テストセットに使う⾔語のうち⼀つを test
データとし、残りは train 学習中は train のデータのうちの⼀つを dev として残りを train に 以上を⾔語の数だけ繰り返す
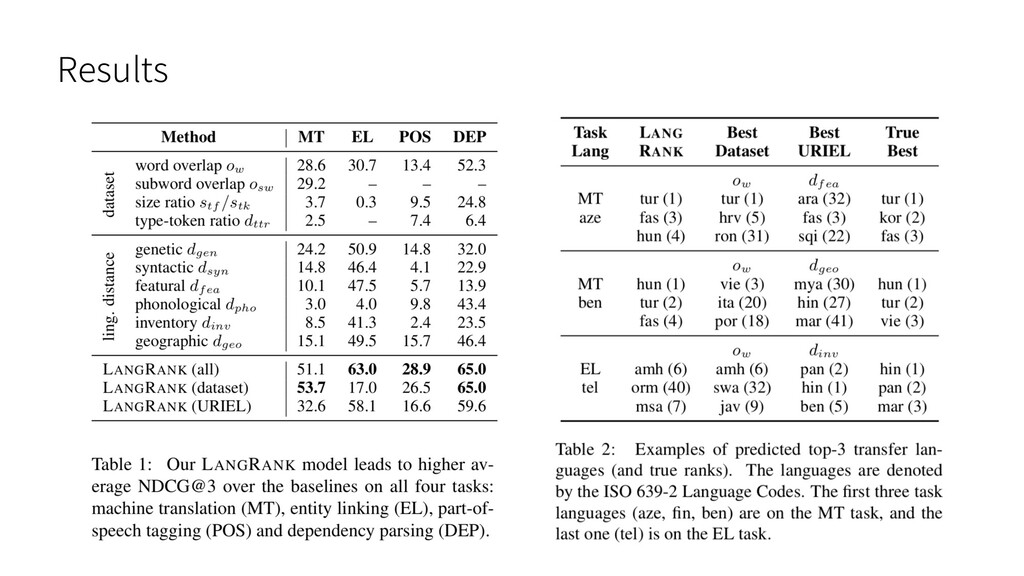
Evaluation protocol 2 ranking model の評価は NDCG@3 で⾏う (A?B =
10) : は 番⽬だと予測された⾔語の点数 (gold の top が A?B 、そこから⼀つ順位 が下がるごとに点数が 1 下がる ) IDCG は DCG と同じ計算を gold に対して⾏う NDCG は ranking が全て正しければ 1 になる
Results
Analysis & Discussion
Conclusion • タスクを転移元⾔語を選ぶランキングタスクと定義することによって予測モ デルを構築することが可能になった • 単⼀の⾔語的要素やデータに関する要素のみで転移元⾔語を選ぶよりも複数 の素性を考慮して選んだ⽅が良いことを⽰した • それぞれのタスクにおいてどのような要素が強く影響を及ぼしているのかの 分析・洞察を得られた
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}