Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
2020COLING読み会_Linguistic-Profiling-of-a-Neural-...
Search
Ikumi Yamashita
January 19, 2021
Technology
110
0
Share
2020COLING読み会_Linguistic-Profiling-of-a-Neural-Language-Model
Ikumi Yamashita
January 19, 2021
More Decks by Ikumi Yamashita
See All by Ikumi Yamashita
2021論文紹介_When-Do-You-Need-Billions-of-Words-of-Pretraining-Data?
ikumi193
0
190
2021EACL/NAACL論文紹介_Multilingual-LAMA-Investigating-Knowledge-in-Multilingual-Pretrained-Language-Models
ikumi193
0
71
2021論文紹介_CANINE:-Pre-training-an-Efficient-Tokenization-Free-Encoder-for-Language-Representation
ikumi193
0
330
2020EMNLP読み会_Identifying-Elements-Essential-for-BERT's-Multilinguality
ikumi193
0
140
2020ACL読み会_FastBERT:-a-Self-distilling-BERT-with-Adaptive-Inference-Time
ikumi193
0
160
2020論文紹介_Finding-Universal-Grammatical-Relations-in-Multilingual-BERT
ikumi193
0
290
2019EMNLP読み会_Unicoder_A_Universal_Language_Encoder_by_Pre-training_with_Multiple_Cross-lingual_Tasks
ikumi193
0
72
2019論文読み会_Language-Modeling-with-Shared-Grammar
ikumi193
0
230
2019ACL読み会_Choosing-Transfer-Languages-for-Cross-Lingual-Learning
ikumi193
0
61
Other Decks in Technology
See All in Technology
Chart.js が簡単に使えるようになっていたので OGP 画像生成に使った話
kamekyame
0
150
AI Engineering Summit Tokyo 2026 AIの前に、やることがある 〜医療データ企業の4フェーズ〜
dtaniwaki
0
1.7k
Databricks 月刊サービスアップデート 2026年05月号
tyosi1212
0
200
GoとSIMDとWasmの今。
askua
3
490
コードレビューを制するチームがソフトウェアデリバリーのフローを制す / Beyond Code Review: Distributing Its Responsibilities Across the SDLC
mtx2s
3
1k
AIプラットフォームを運用し続けるための可観測性
tanimuyk
4
1.1k
Oracle AI Database@Azure:サービス概要のご紹介
oracle4engineer
PRO
6
1.9k
AI-DLCを活用した高品質・安全なAI駆動開発実践 / AI Driven Development
yoshidashingo
1
340
[モダンアプリ勉強会]今更聞けないGit/GitHub入門
tsukuboshi
0
240
タクシーアプリ『GO』の実践的データ活用
mot_techtalk
2
130
Oracle Cloud Infrastructure IaaS 新機能アップデート 2026/3 - 2026/5
oracle4engineer
PRO
1
180
新アーキテクチャ「TiDB X」解説とDedicated比較 TiDB Cloud Premiumのゲーム運用活用を検証
staffrecruiter
0
110
Featured
See All Featured
svc-hook: hooking system calls on ARM64 by binary rewriting
retrage
2
280
Joys of Absence: A Defence of Solitary Play
codingconduct
1
390
How To Stay Up To Date on Web Technology
chriscoyier
790
250k
Lightning talk: Run Django tests with GitHub Actions
sabderemane
0
190
Put a Button on it: Removing Barriers to Going Fast.
kastner
60
4.3k
Thoughts on Productivity
jonyablonski
76
5.2k
Exploring the relationship between traditional SERPs and Gen AI search
raygrieselhuber
PRO
2
4k
Tell your own story through comics
letsgokoyo
1
940
B2B Lead Gen: Tactics, Traps & Triumph
marketingsoph
0
130
Stewardship and Sustainability of Urban and Community Forests
pwiseman
0
220
Imperfection Machines: The Place of Print at Facebook
scottboms
270
14k
Building Applications with DynamoDB
mza
96
7.1k
Transcript
紹介者:⼭下郁海 (TMU M1 ⼩町研究室) 2020/01/19 @ COLING2020 読み会 1
• BERT の内部表現に対して詳細な分析を⾏った論⽂ Ø 様々な⾔語特性を反映した 68 のサブタスクを⽤いた分析 • Fine-tuning 前後での変化を確認
Ø 各⾔語での NLI での Fine-tuning により広範囲な⾔語特性をカバーする能 ⼒が失われることを確認 Ø 代わりによりタスク固有の知識を獲得している • BERT の持つ⾔語知識が下流タスクにどのような影響を与えるのかの調査 Ø より広範な⾔語特性をカバーしていれば、下流タスクの性能も向上するこ とを確認 Overview 2
Settings 3
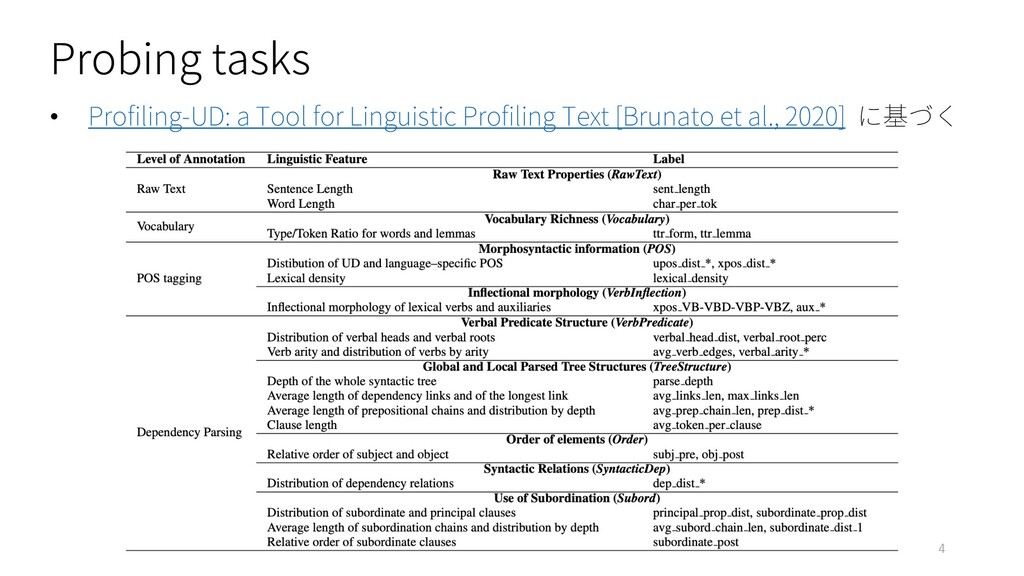
Probing tasks • Profiling-UD: a Tool for Linguistic Profiling Text
[Brunato et al., 2020] に基づく 4
Models • NLM Ø pre-trained English BERT (12 layers, 768
hiddens) Ø ⽂レベルの表現を得るために CLS トークンを使⽤ • Probing Model Ø LinearSVR Ø BERT の CLS トークンを⼊⼒に、各 probing task の値を計算 例:⽂⻑、type token ration、POS タグの分布、など 5
Profiling BERT 6
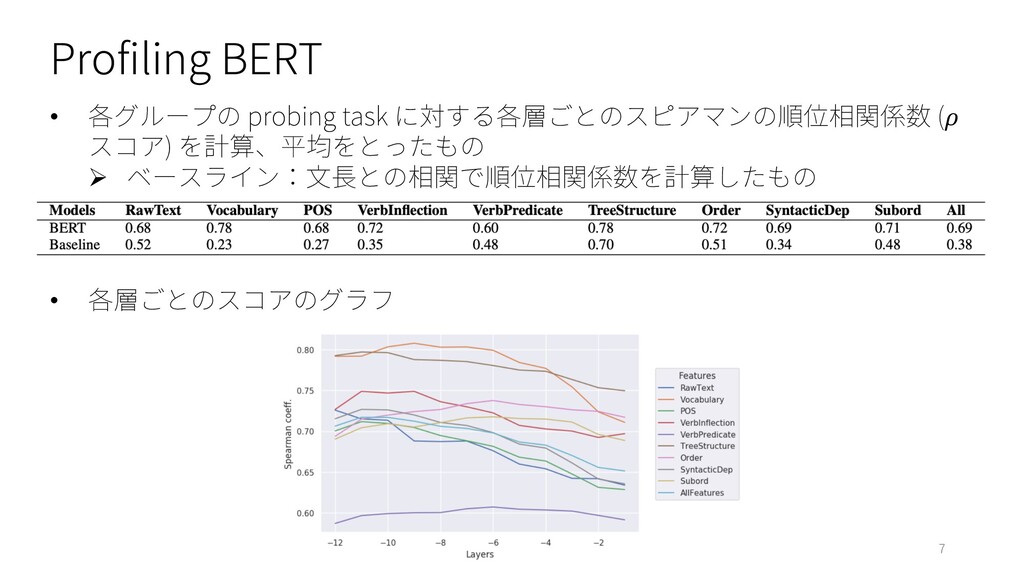
Profiling BERT • 各グループの probing task に対する各層ごとのスピアマンの順位相関係数 ( スコア) を計算、平均をとったもの
Ø ベースライン:⽂⻑との相関で順位相関係数を計算したもの • 各層ごとのスコアのグラフ 7
Layerwise scores • 各 probing task に対する各層ごとのスピアマンの順位相関係数 ( スコア) Ø
ベースライン (B):⽂⻑との相関で順位相関係数を計算したもの 8
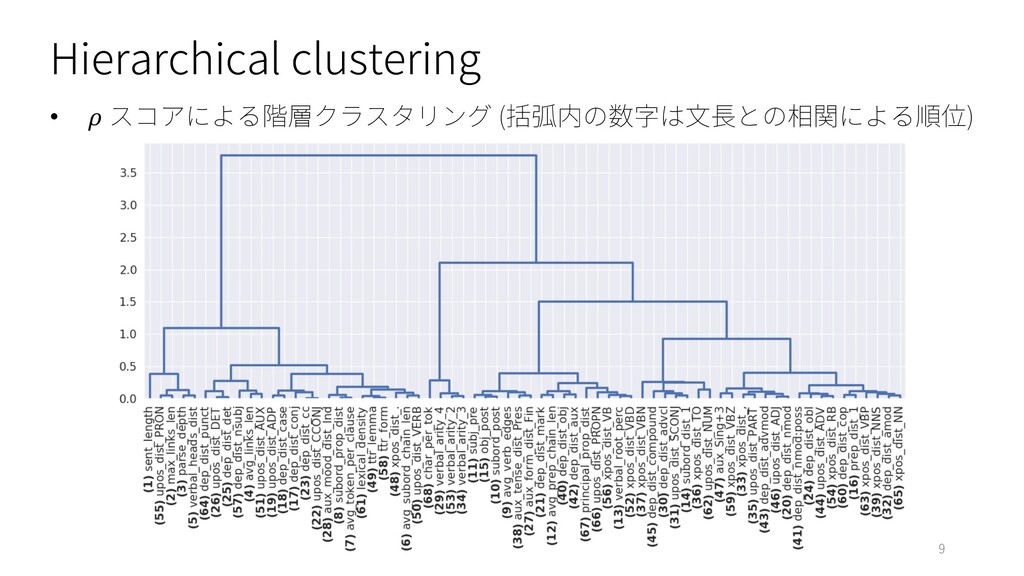
Hierarchical clustering • スコアによる階層クラスタリング (括弧内の数字は⽂⻑との相関による順位) 9
Impact of fine-tuning 10
NLI fine-tuning • NLI (Native Language Identification) Ø (Natural Language
Inference ではない) Ø 第⼆⾔語で書かれたエッセイから⺟国語を当てるタスク Ø 今回はイタリア語と各別⾔語の⼆値分類 Ø ベースラインは zero rule algorithm • 結果から BERT はどの⾔語でも性能が⾼いことがわかる Ø イタリア語から遠い⾔語ほど性能が⾼く、近い⾔語ほど性能が低い 11
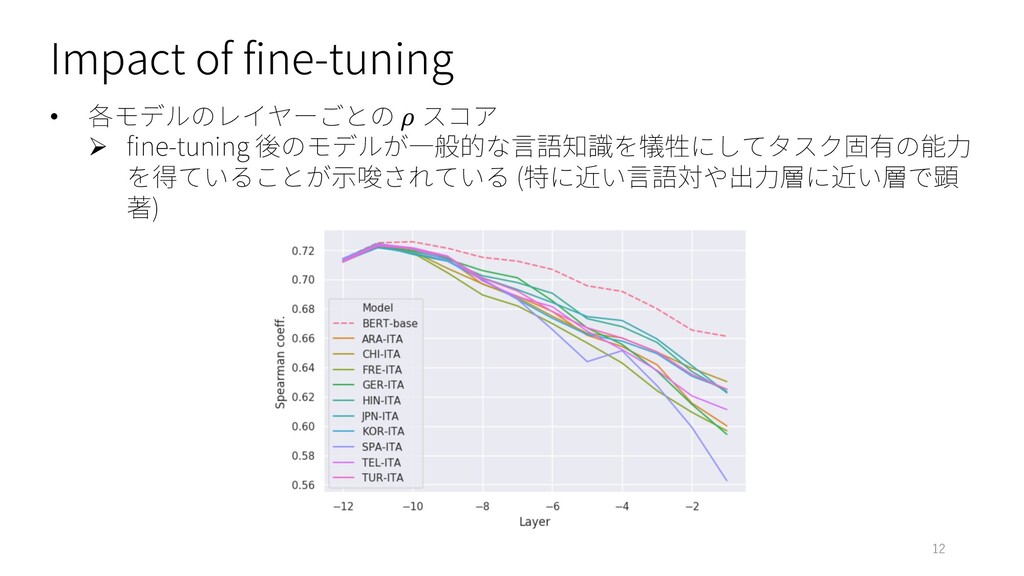
Impact of fine-tuning • 各モデルのレイヤーごとの スコア Ø fine-tuning 後のモデルが⼀般的な⾔語知識を犠牲にしてタスク固有の能⼒ を得ていることが⽰唆されている
(特に近い⾔語対や出⼒層に近い層で顕 著) 12
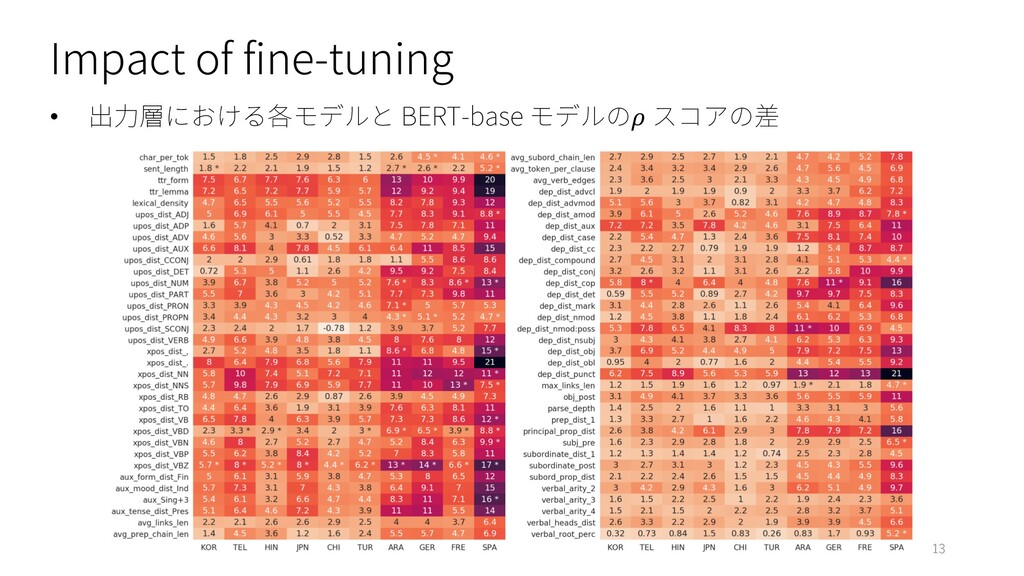
Impact of fine-tuning • 出⼒層における各モデルと BERT-base モデルの スコアの差 13
Are BERT’s linguistic knowledge useful for downstream task? 14
Are linguistic features useful? • NLI のデータを正しく分類できたセットと正しく分類できなかったセットに 分割、各⽂に対して probing task
を実⾏ Ø 各セットにおいて probing task の予測値と実際の値の誤差を Wilcoxon Rank-sum test を⽤いて同⼀の分布であるか判定 → ⼤きく異なる分布であ ることを確認 Ø これは正しく分類できた⽂とできなかった⽂に対する BERT の能⼒が異な ることを⽰唆している 15
Are linguistic features useful? • NLI で正しく分類できた⽂の probing task の
MSE が分類できなかった⽂ probing task の MSE より低い feature の割合のグラフ Ø 正しく分類できた⽂に対しての⽅が、よく把握できている⾔語現象の割合 を⾒ている Ø この割合が⾼い = 正しく⾔語現象が把握できている⽂は下流タスクでも正 しく分類できており、⾔語現象がうまく把握できない⽂は下流タスクでも 正しく分類できない → BERT の⾔語知識は下流タスクにも重要な役割 16
Are linguistic features useful? • NLI で正しく分類できた⽂は他の⽂に⽐べて⽂⻑が⻑い • ⽂⻑のみを⼊⼒として probing
task を⾏う LinearSVR を新たに学習、NLI で正 しく分類できた⽂とできなかった⽂のそれぞれのセットで probing task スコ アを計算 Ø ⽂⻑のみで分類しているのではないか?という点の確認 • NLI で正しく分類できた⽂よりもできなかった⽂の probing task スコアの⽅が ⾼い Ø 正しく分類するには BERT の持つ複雑な⾔語能⼒が必要 17
Conclusion • BERT に対して probing task を⽤いて詳細な分析を実⾏ Ø BERT が広範な⾔語知識を獲得していることを確認
• fine-tuning 前後で⽐較することによって、元々持っていた⾔語知識の多くを 失い、代わりにタスク固有の知識を持つことを確認 • BERT の持つ⾔語知識が下流タスクを解く上で重要な役割を果たしていること を確認 Ø 特定の⽂に対して BERT の持つ⾔語知識が優れていれば、下流タスクの性 能も良い可能性 18
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}