Talk for Bitkom e.V. AK Legal Tech (Berlin, 10.12.2025)
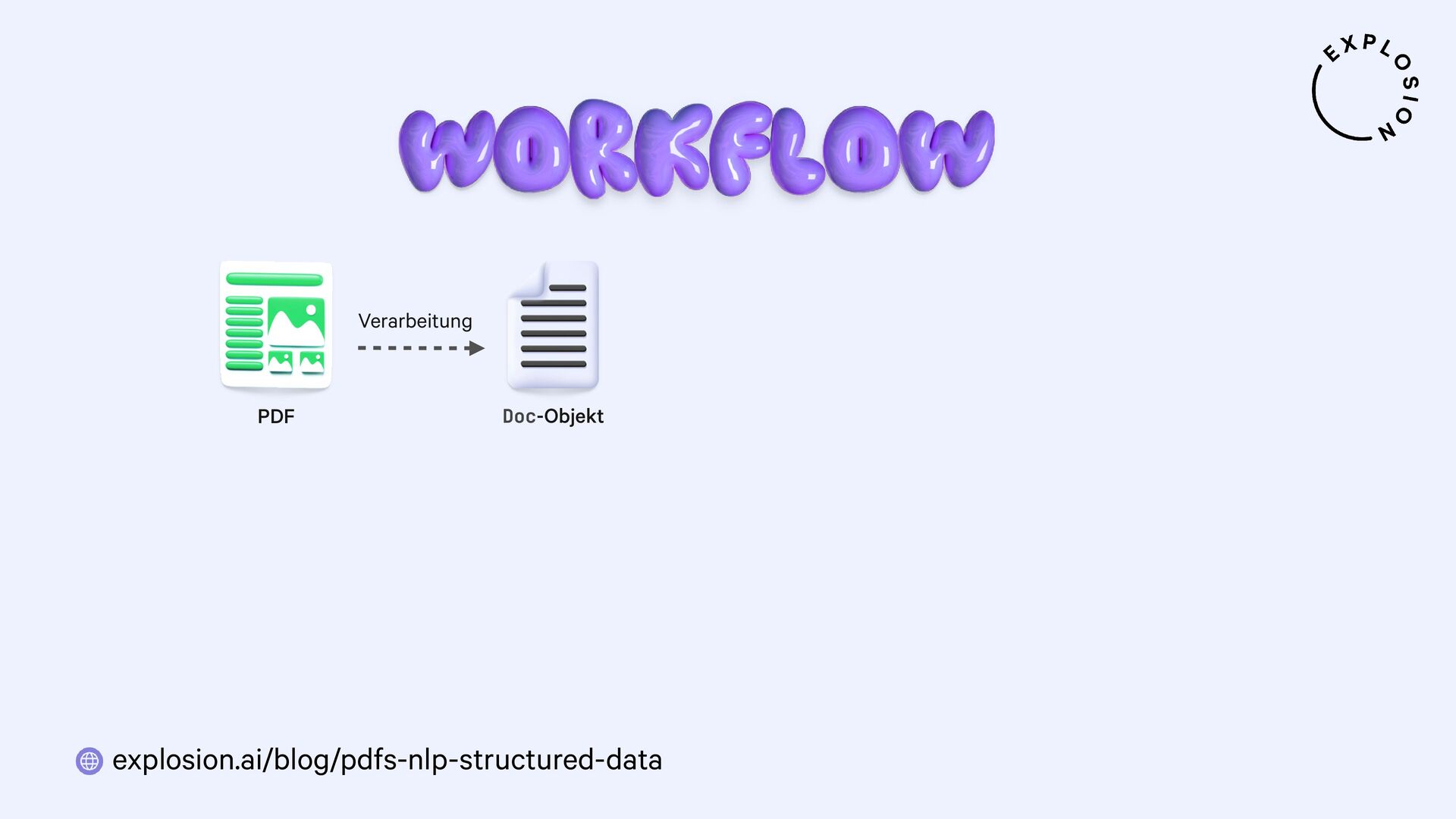
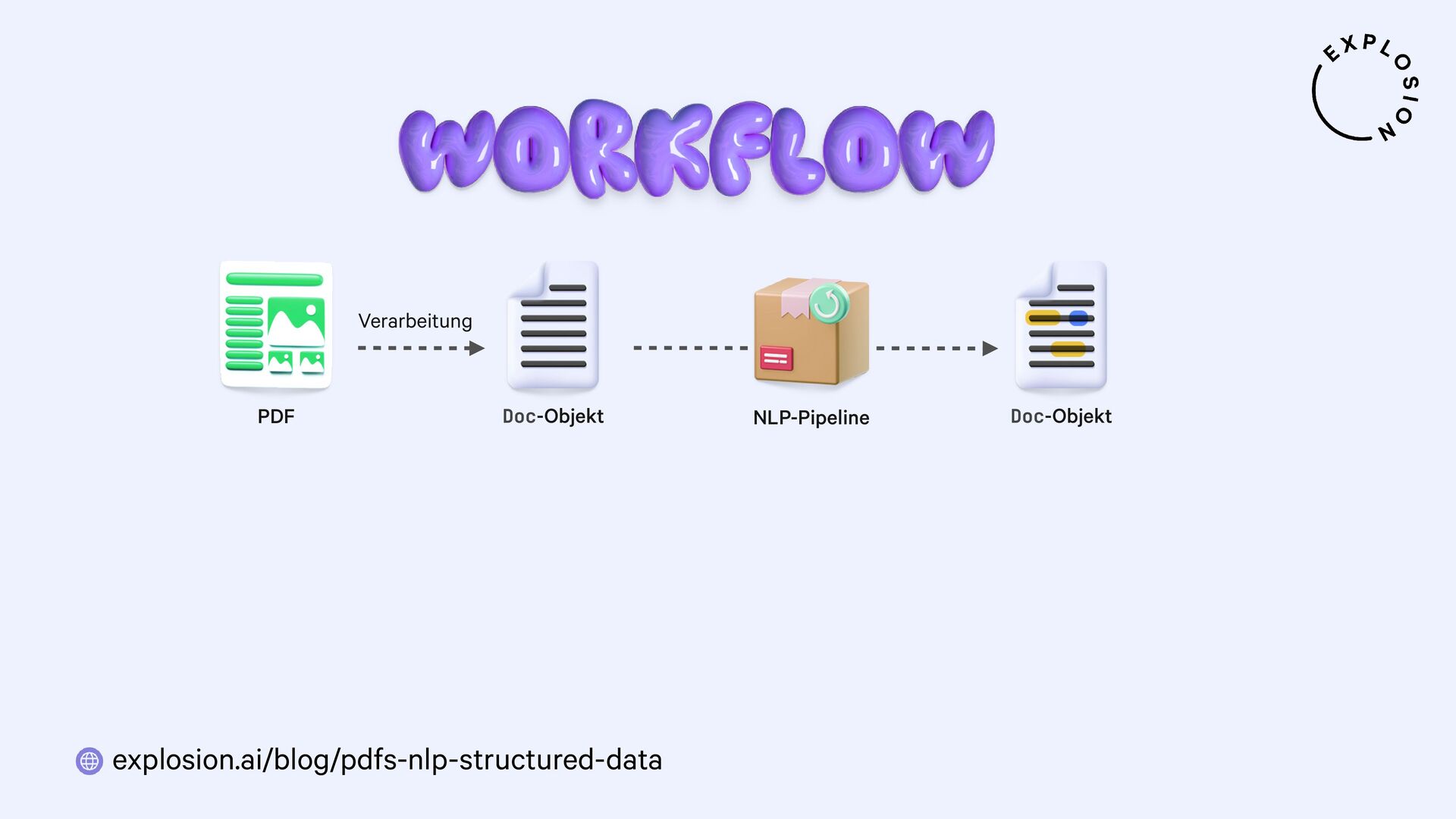
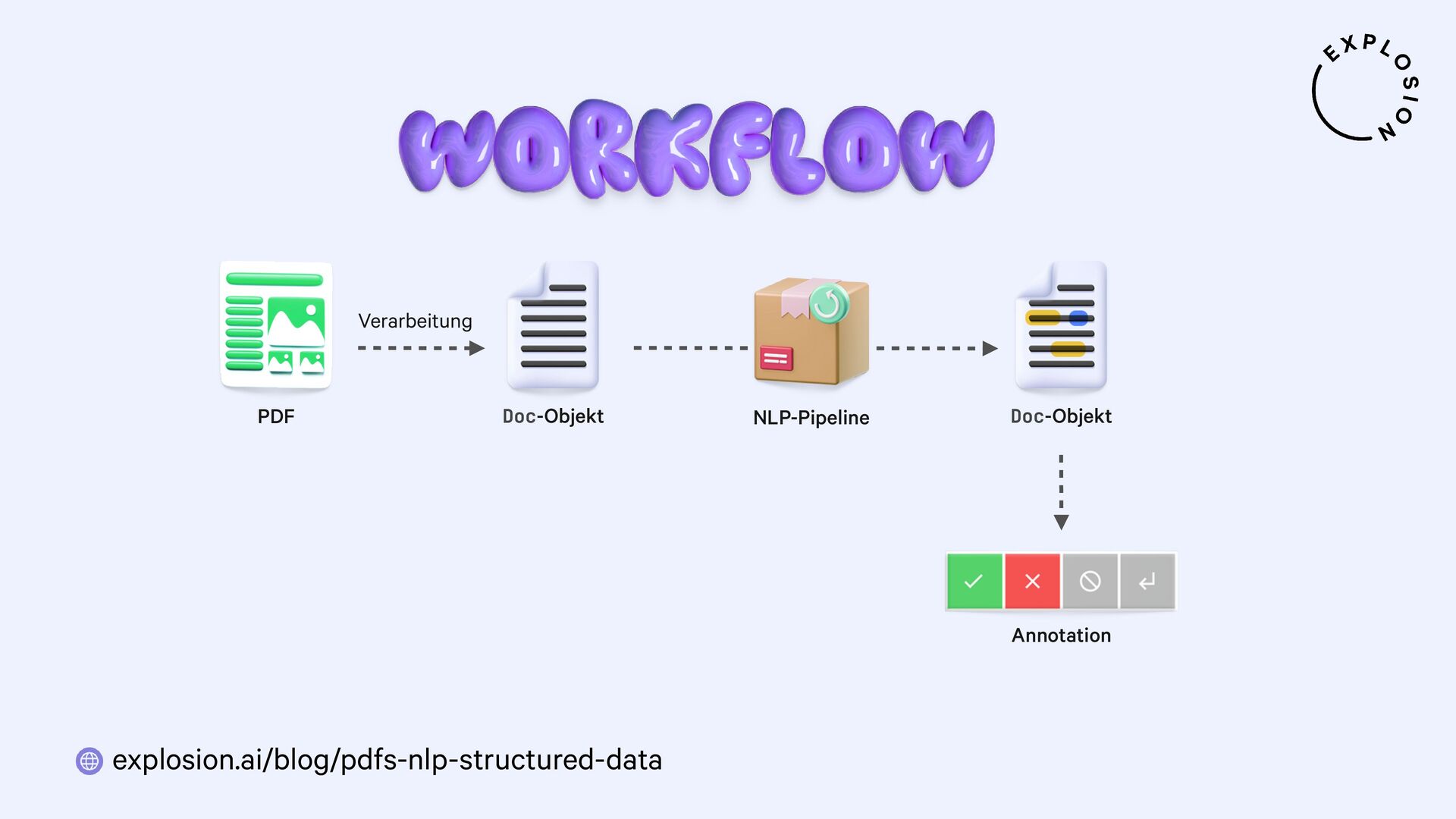
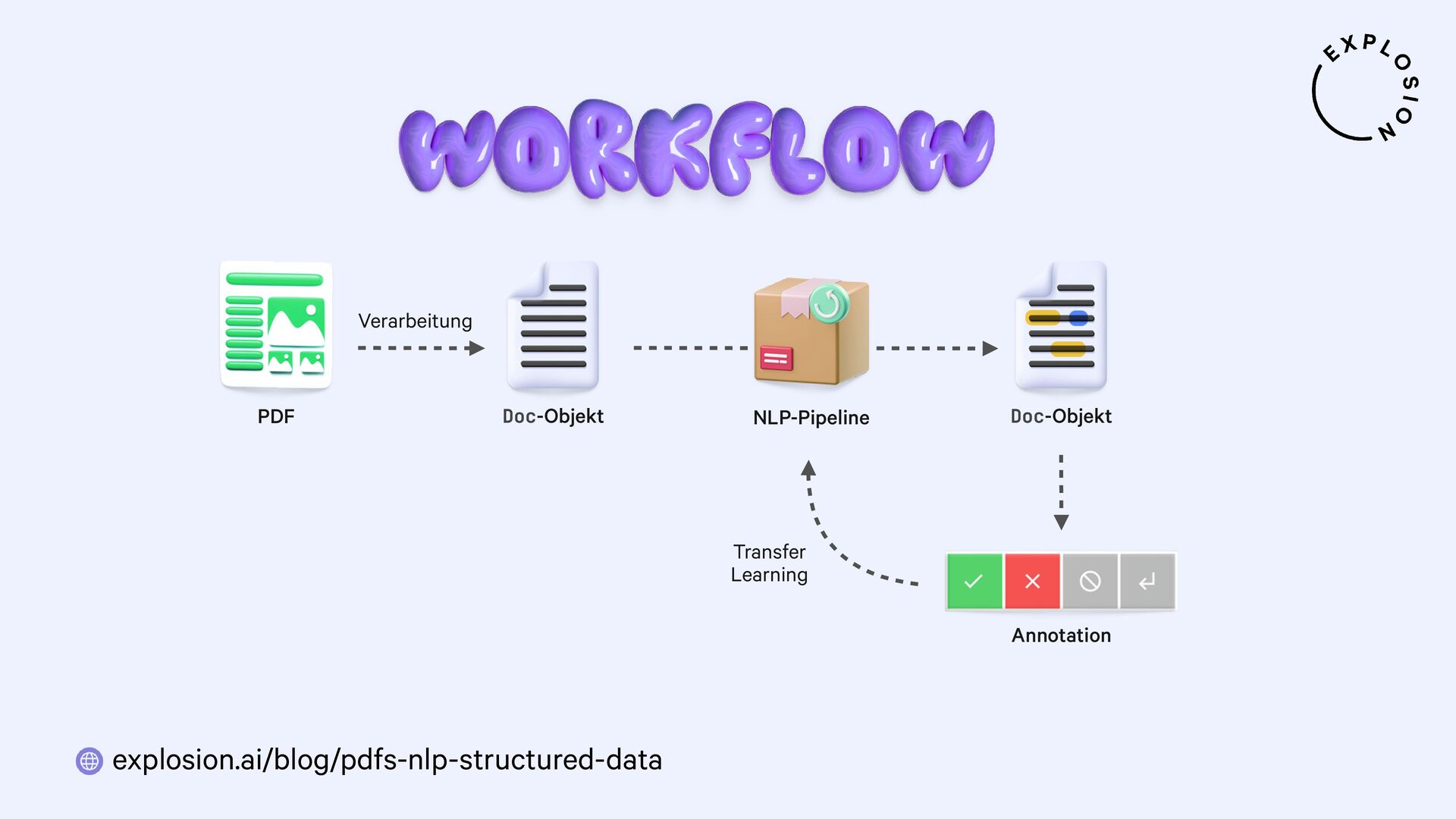
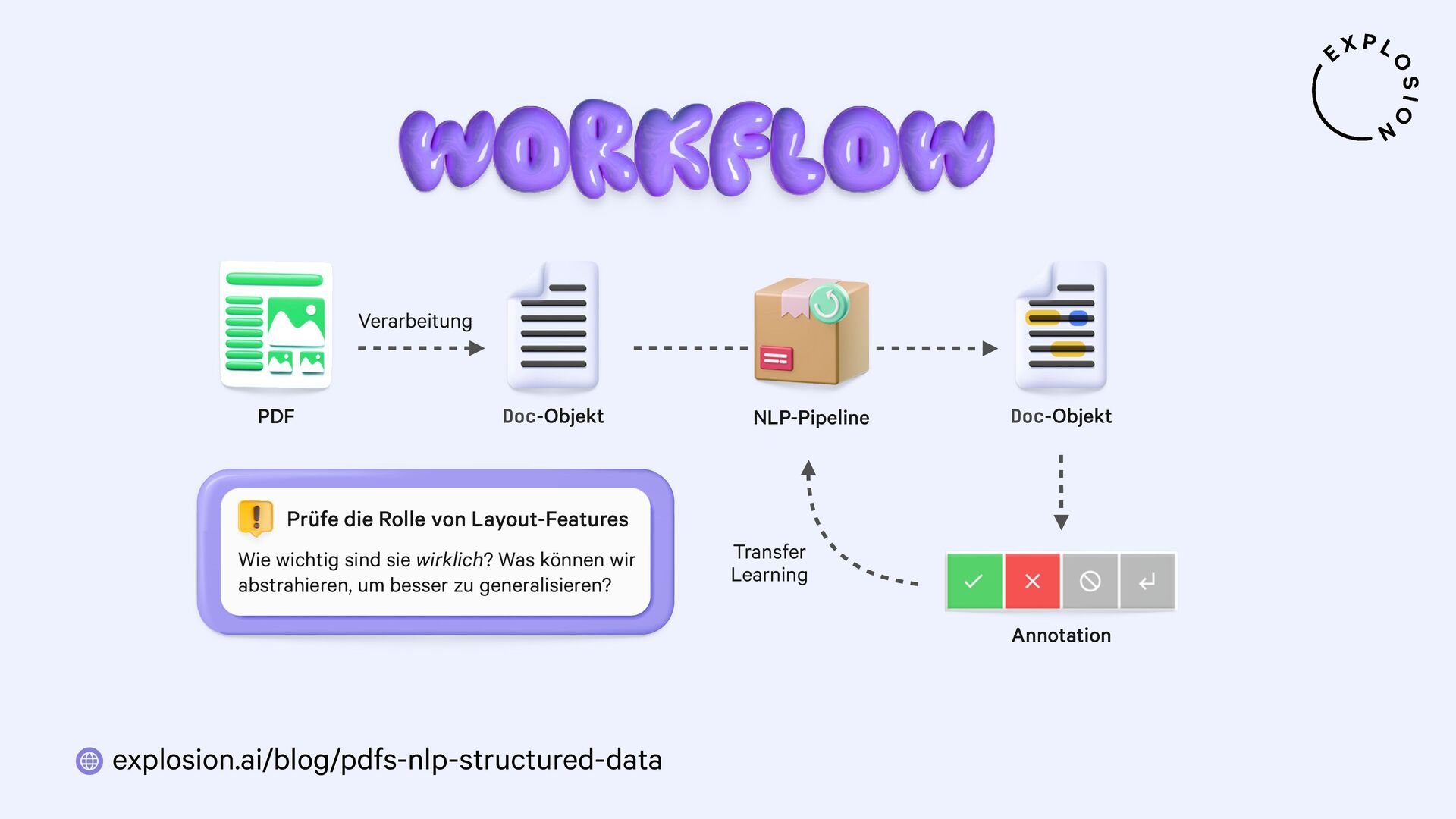
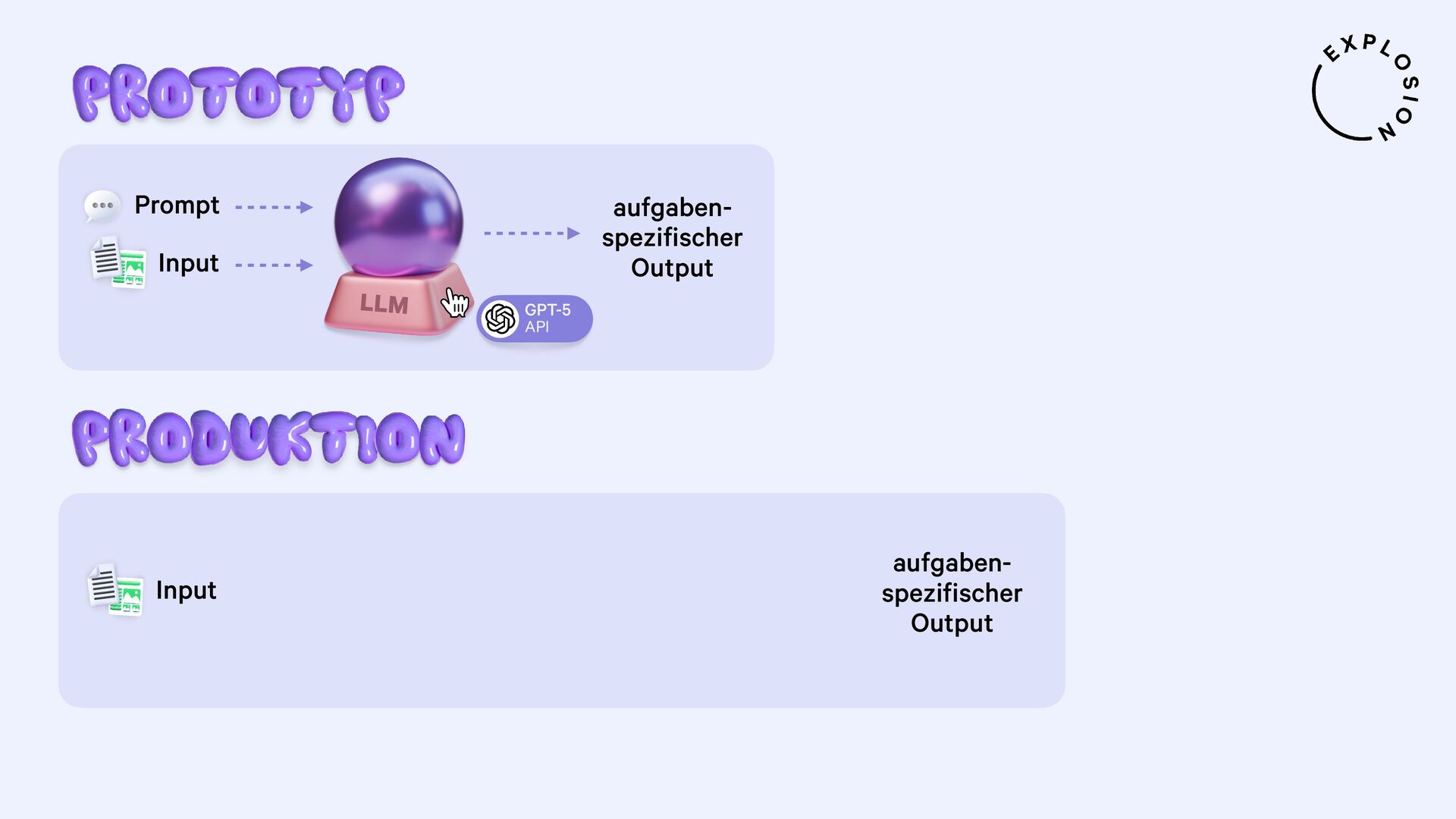
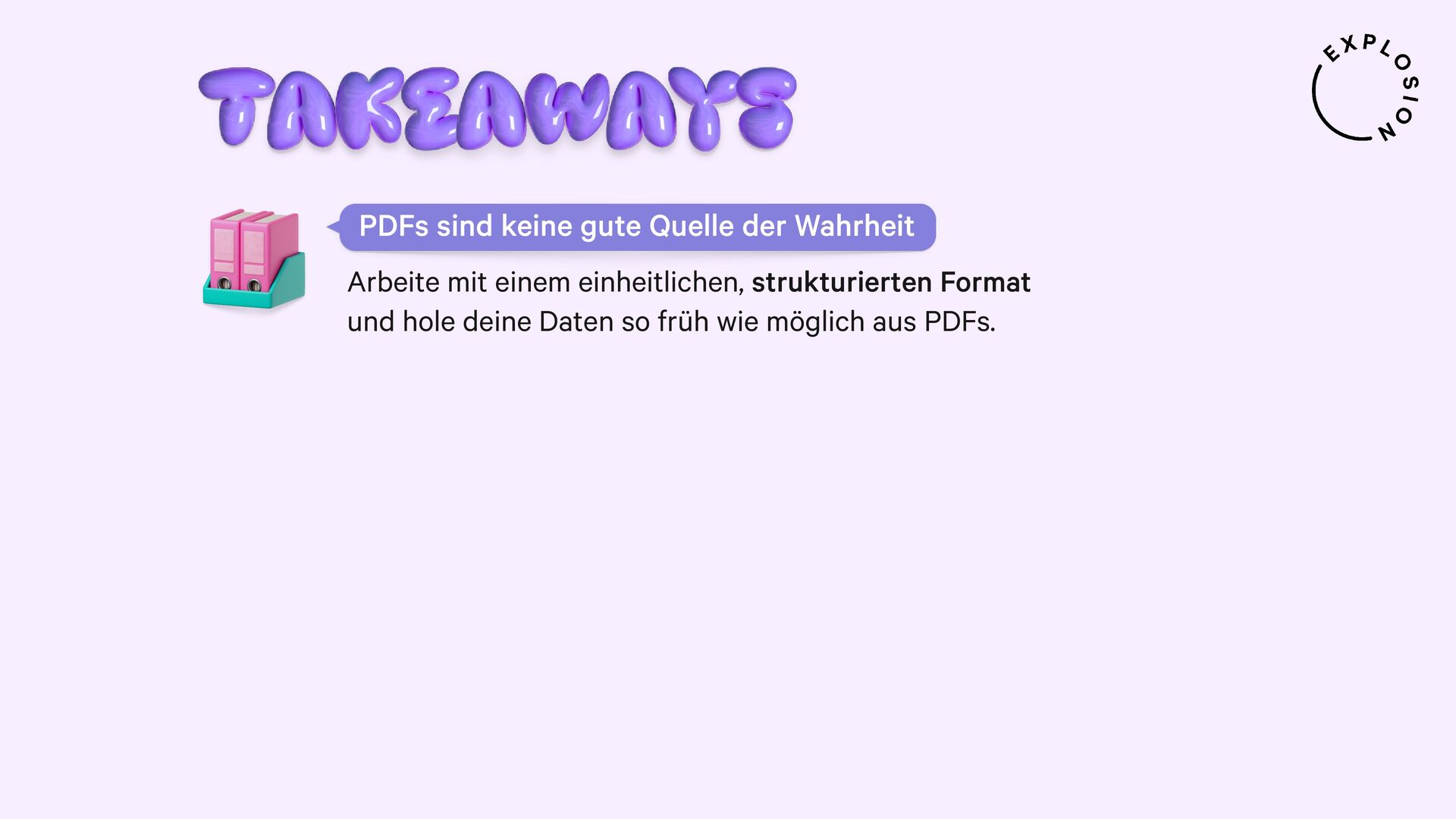
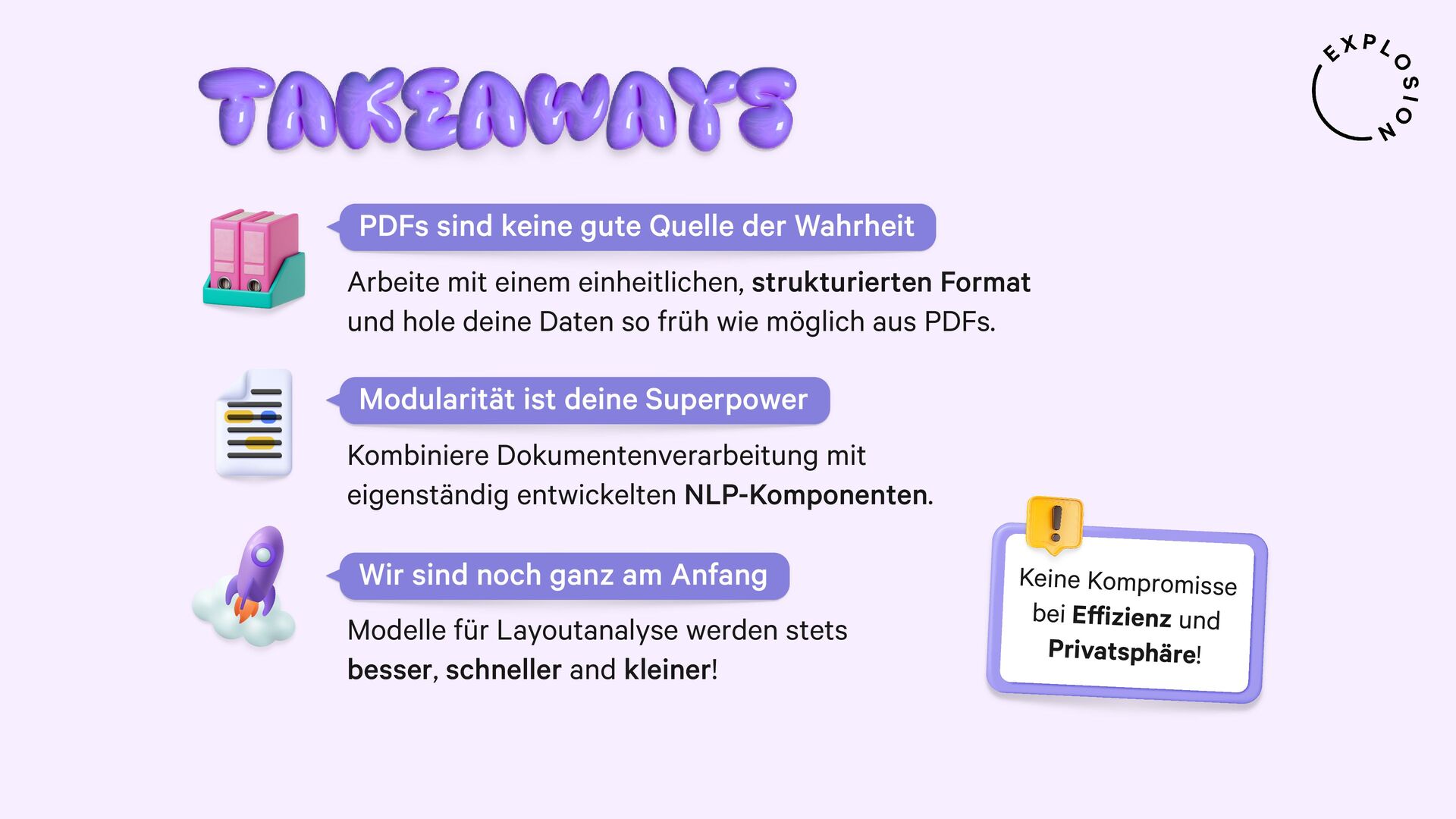
NLP und Data Science könnten so einfach sein, wenn all unsere Daten als sauberer, reiner Text vorlägen. Doch in der Praxis sind sie meist versteckt in PDFs, Word-Dokumenten, Scans und anderen Formaten, deren Verarbeitung sich als Albtraum erwiesen hat. In diesem Talk präsentiere ich einen neuen, modularen Ansatz für die Entwicklung von robusten Systemen für Dokumentenanalyse mit Hilfe von modernsten Modellen und dem großartigen Python-Ökosystem. Ich zeige, wie wir von PDFs zu strukturierten Daten gelangen und sogar vollständig benutzerdefinierte Informationsextraktions-Pipelines für spezifische Anwendungsfälle aus der Praxis erstellen können.
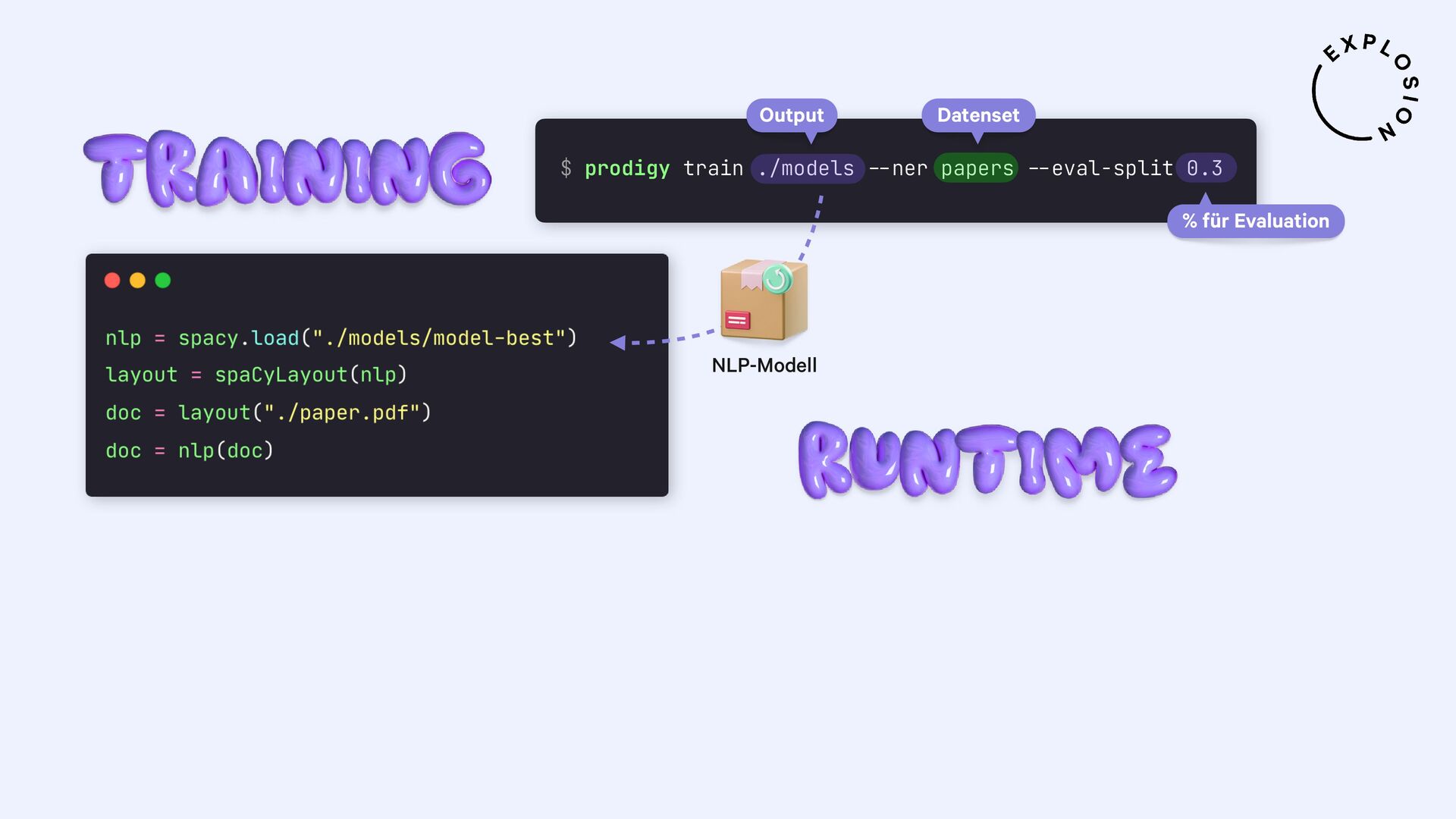
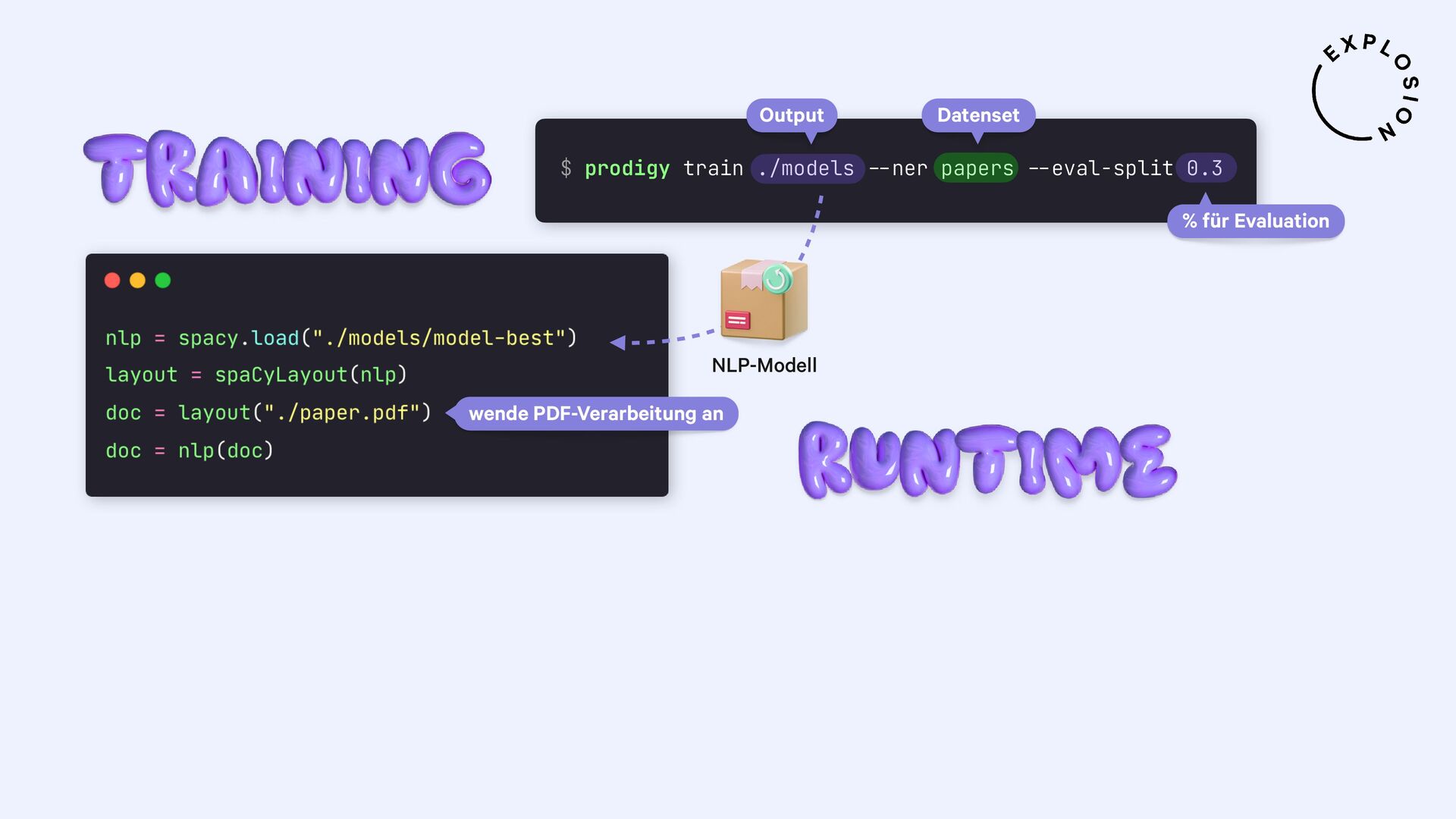
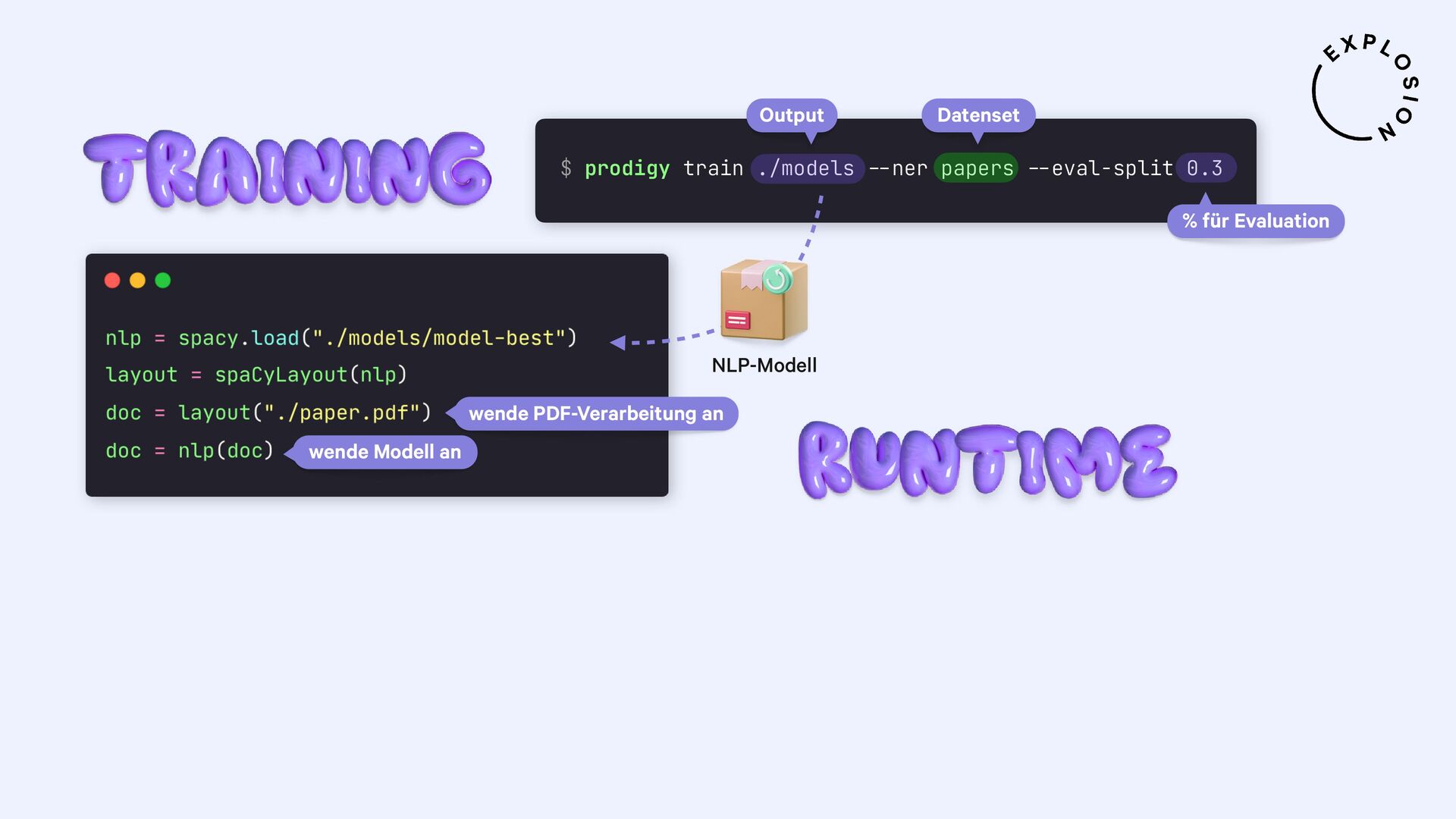
Für die praktischen Beispiele verwende ich spaCy, sowie die Bibliothek und Layoutanalysemodelle von Docling. Ich thematisiere außerdem optische Zeichenerkennung (OCR) für bildbasierten Text, die Verwendung von bewährten NLP-Techniken, und Strategien zur Erstellung von Trainings- und Evaluationsdaten für Informationsextraktionsaufgaben wie Textklassifizierung und Entitätserkennung anhand von PDFs und anderen Dokumenten.
Blogpost: https://explosion.ai/blog/pdfs-nlp-structured-data
https://explosion.ai/blog/pdfs-nlp-structured-data
Blogpost und Basis dieses Talks mit mehr Informationen und Beispielen
https://speakerdeck.com/inesmontani/conquering-pdfs-document-understanding-beyond-plain-text
Englische Version und Video dieses Talks
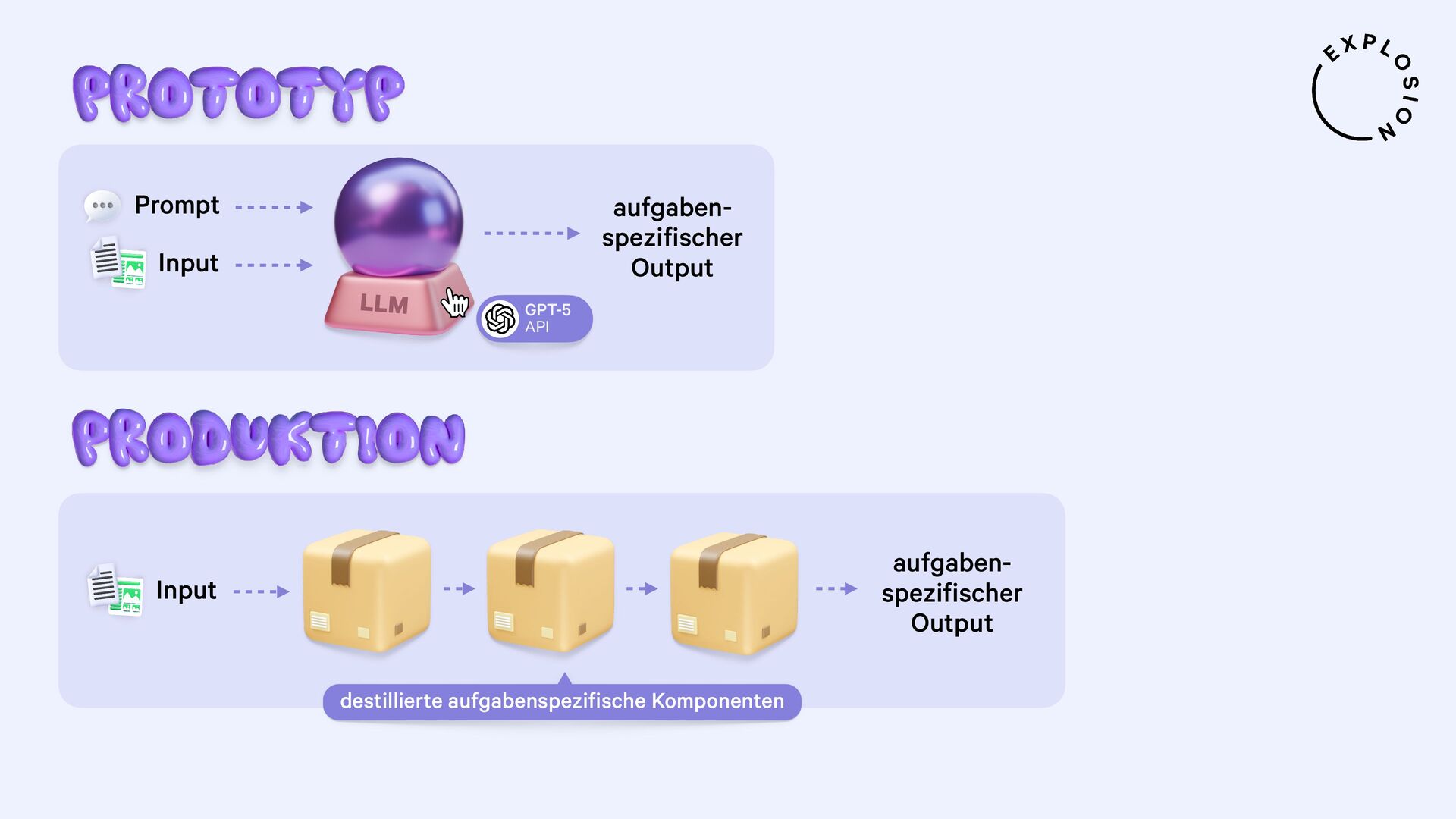
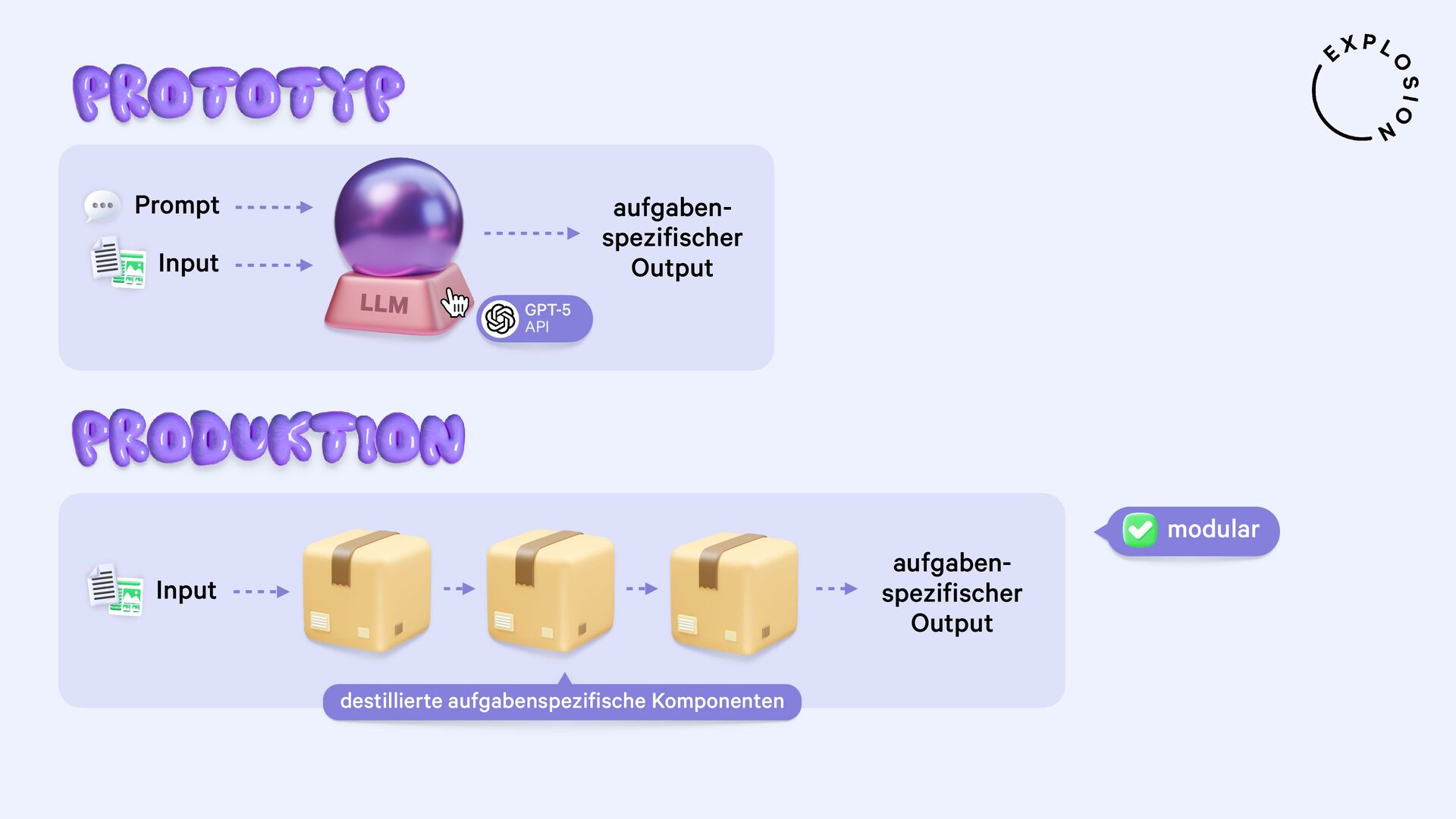
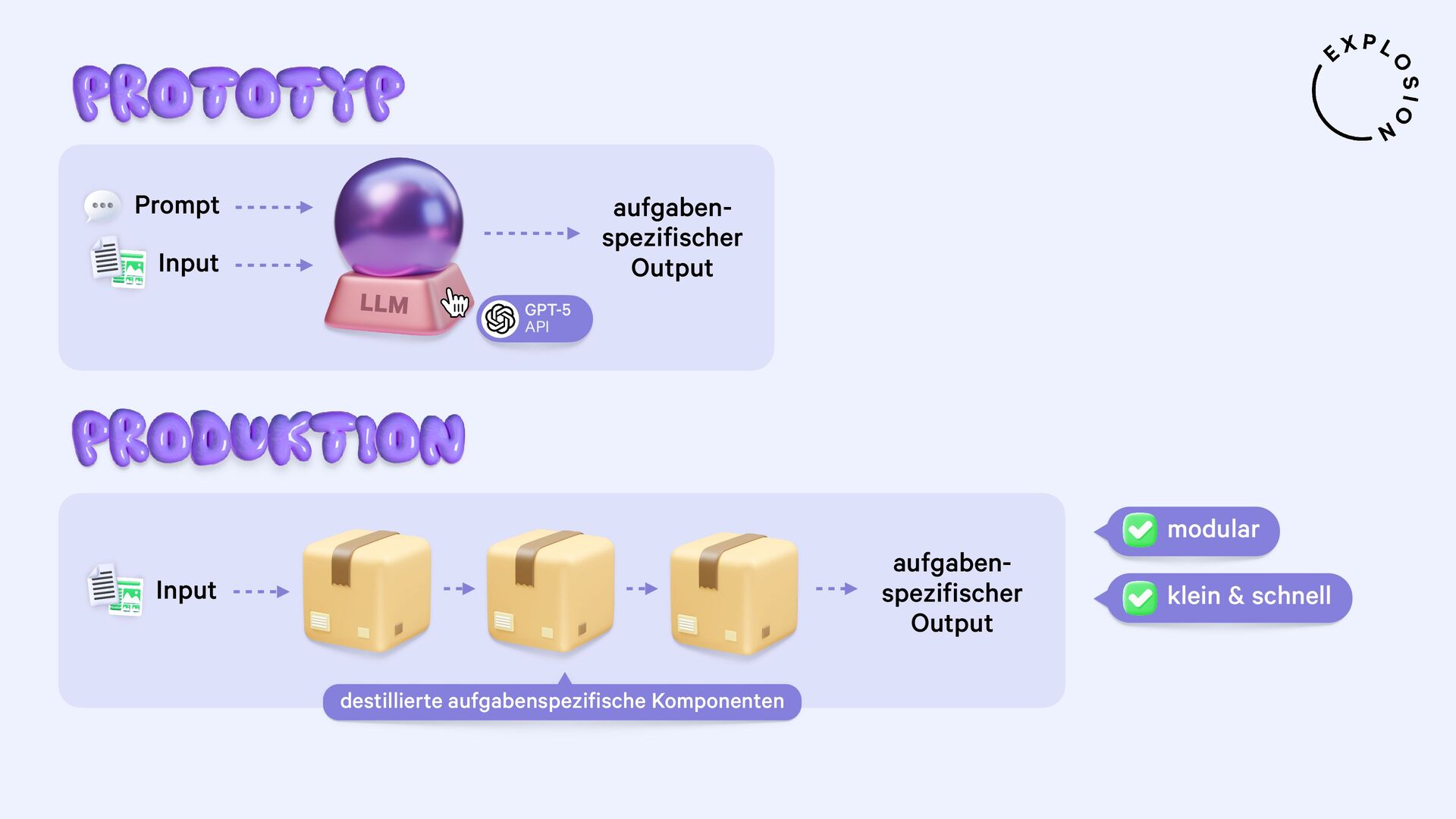
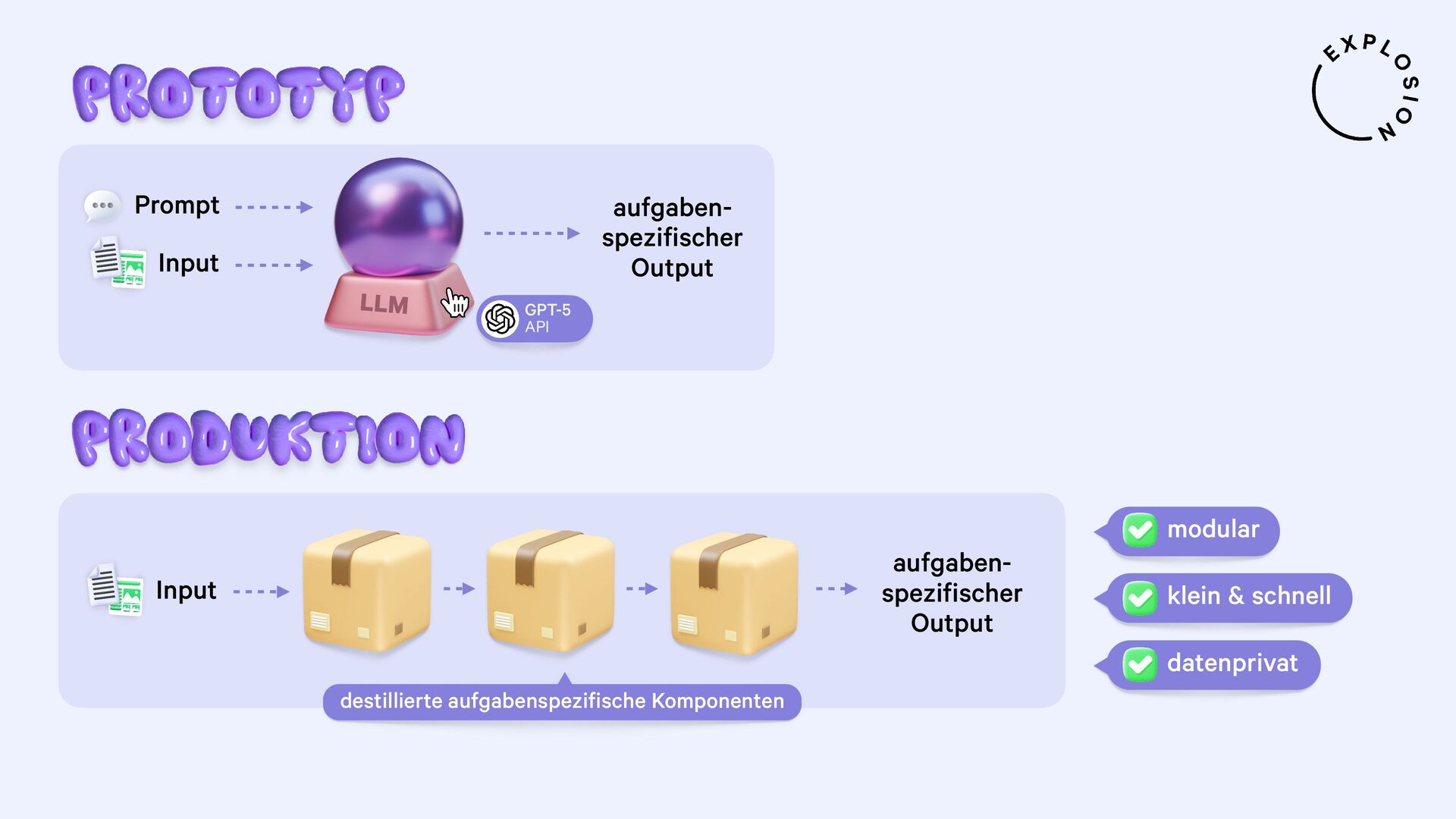
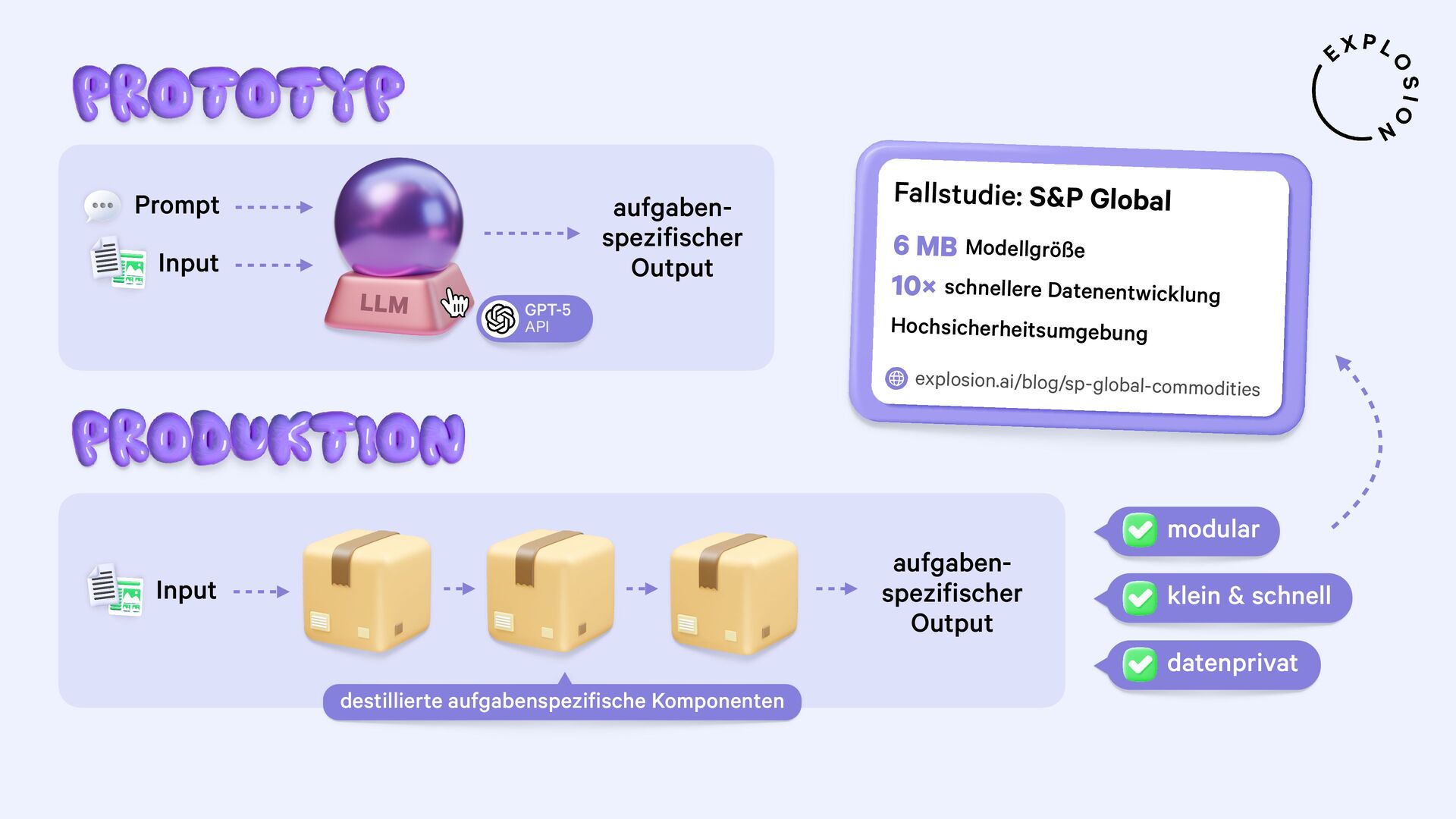
https://explosion.ai/blog/human-in-the-loop-distillation
Praktische Lösungen für die Destillation der neusten Large Language Models in kleinere, schnellere und datenprivate Komponenten
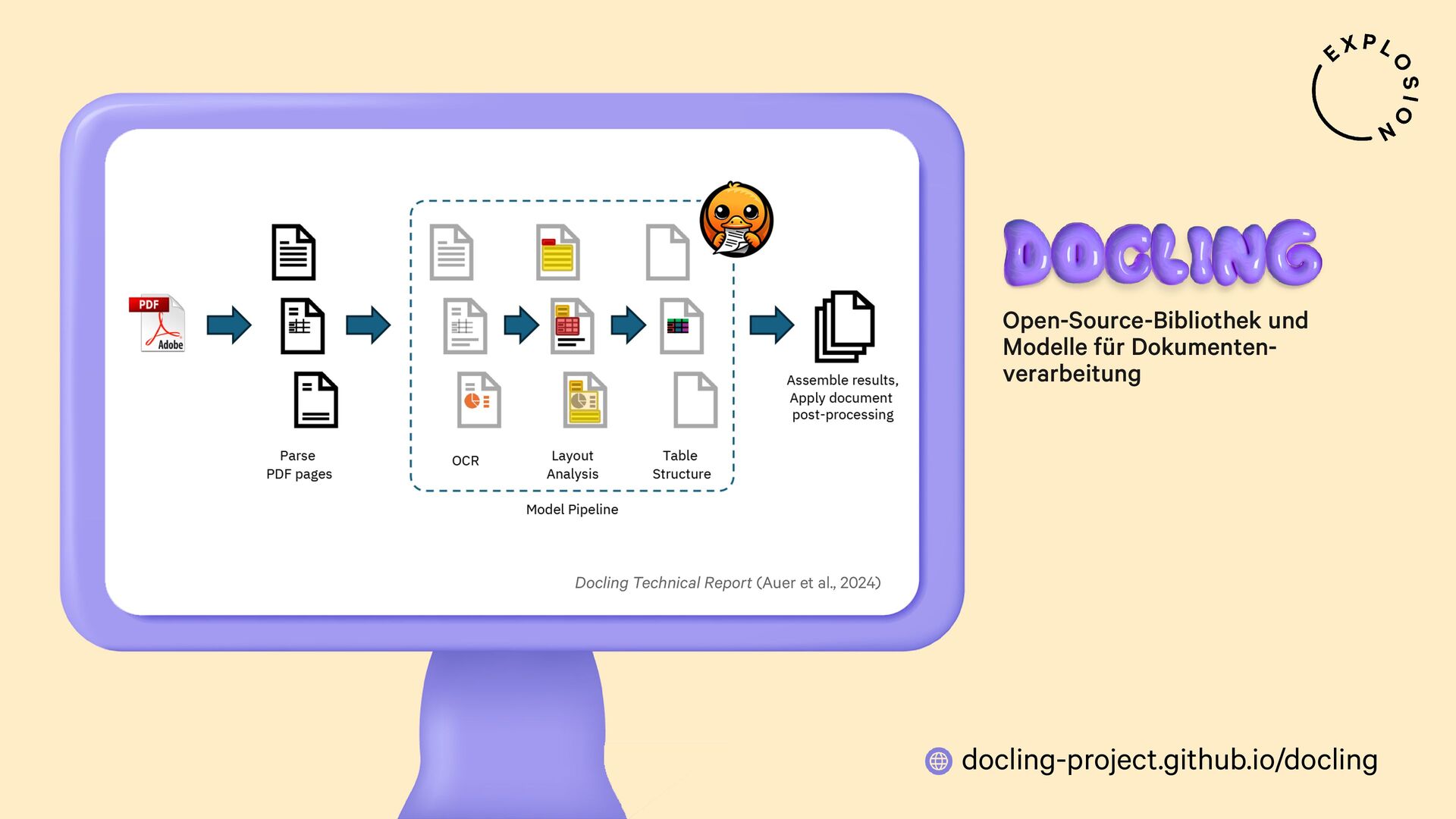
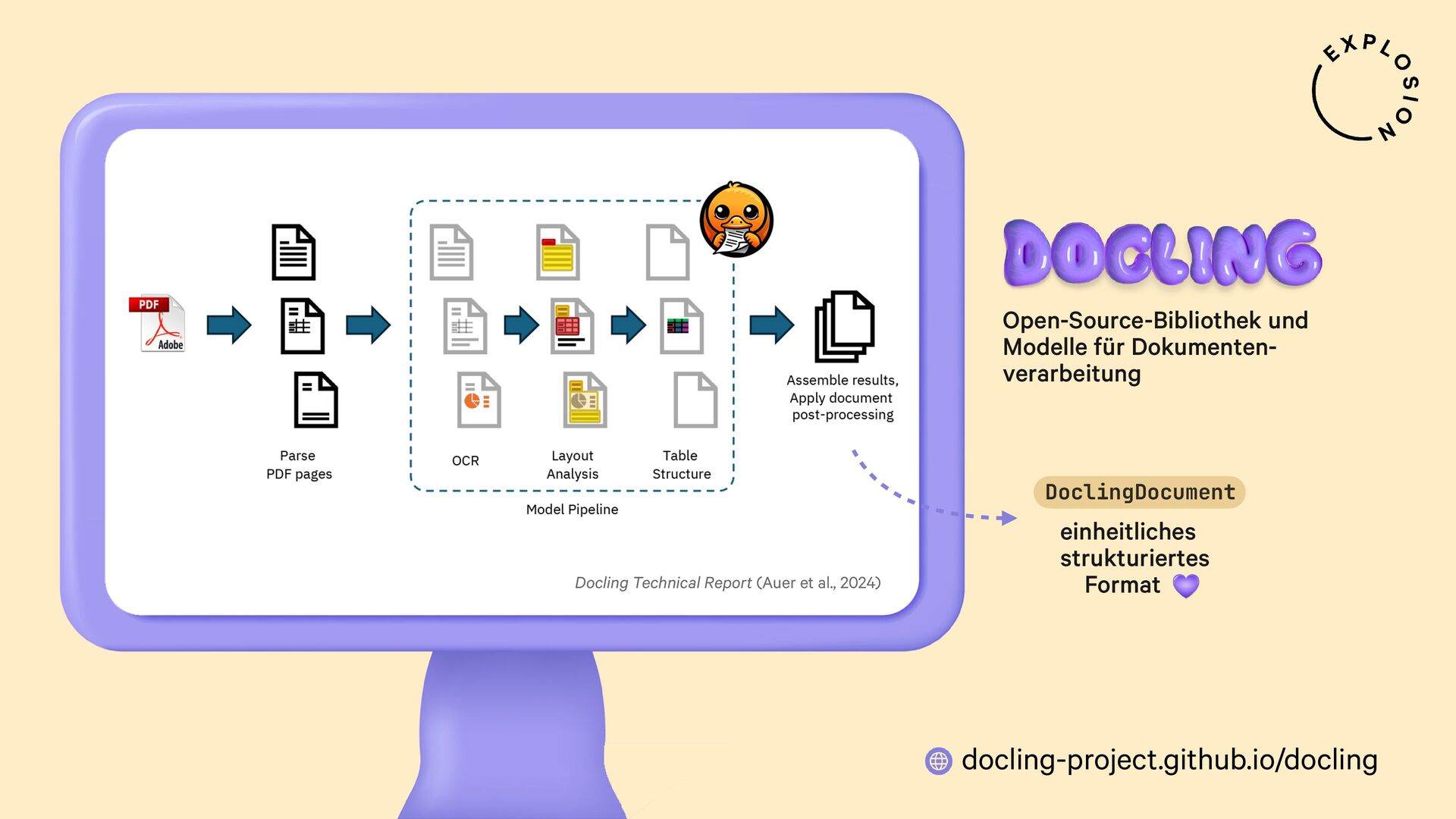
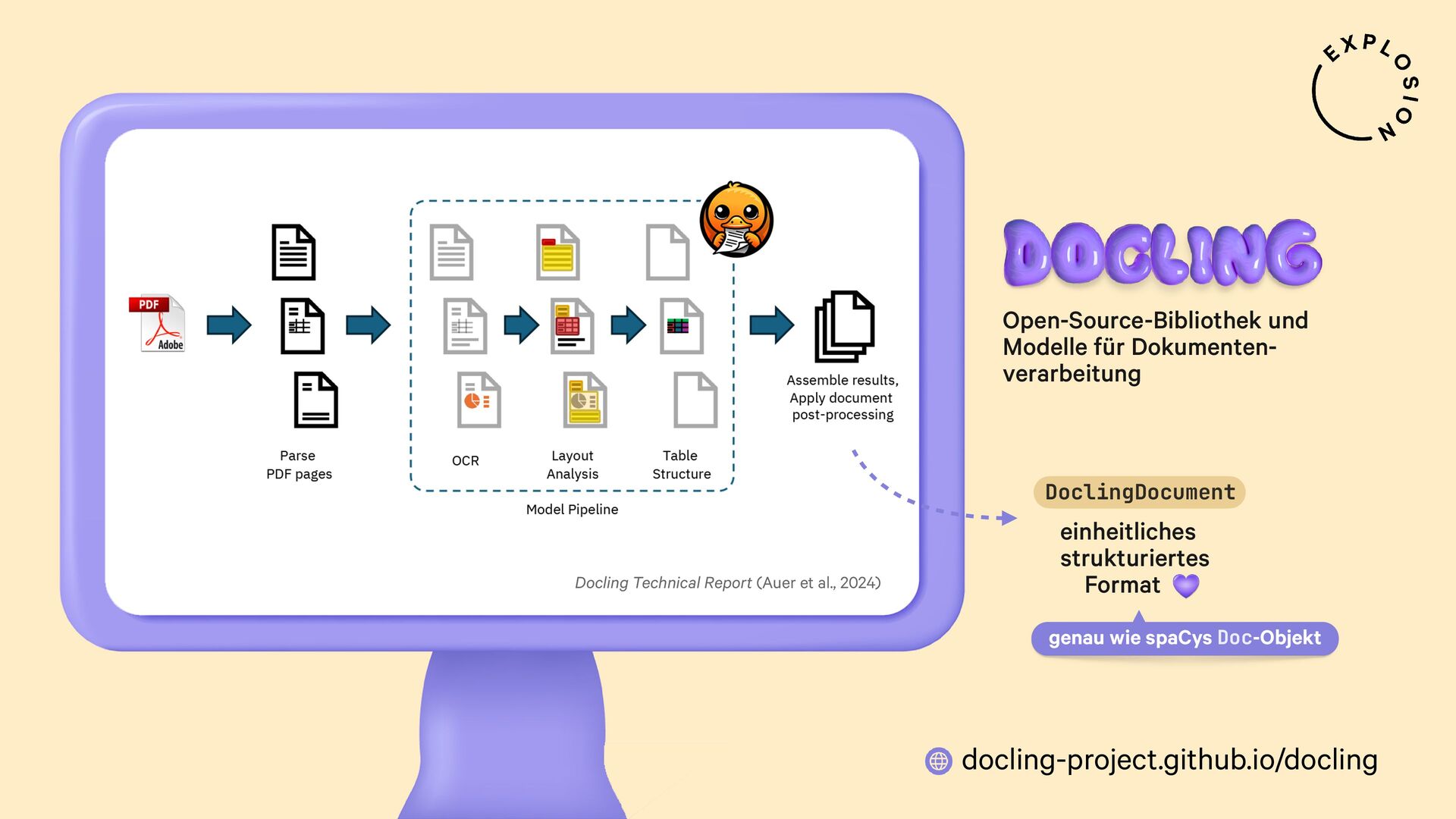
https://docling-project.github.io/docling/
Open-Source-Bibliothek und Modelle für die Verarbeitung von PDFs, Word-Dokumenten etc.
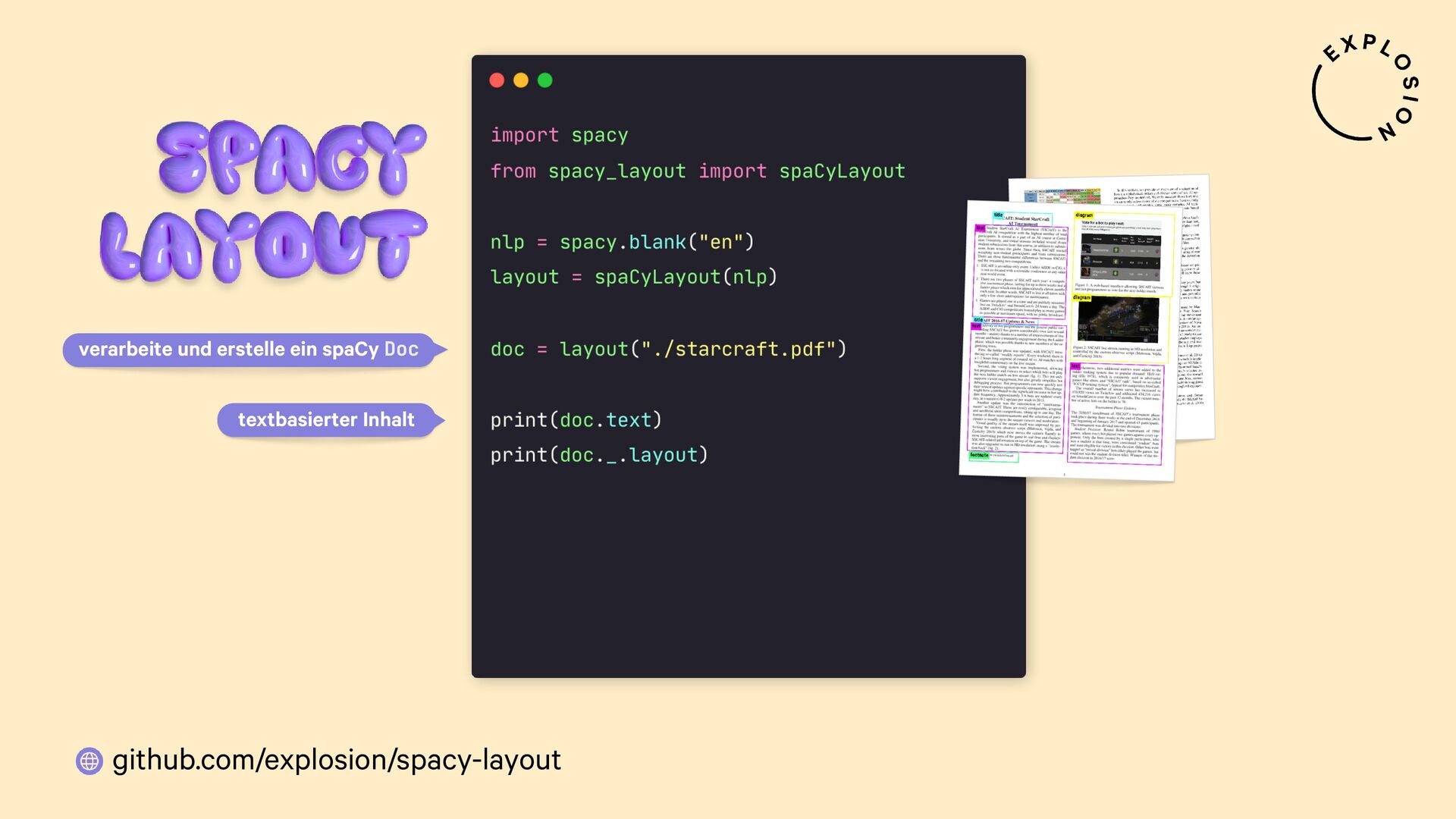
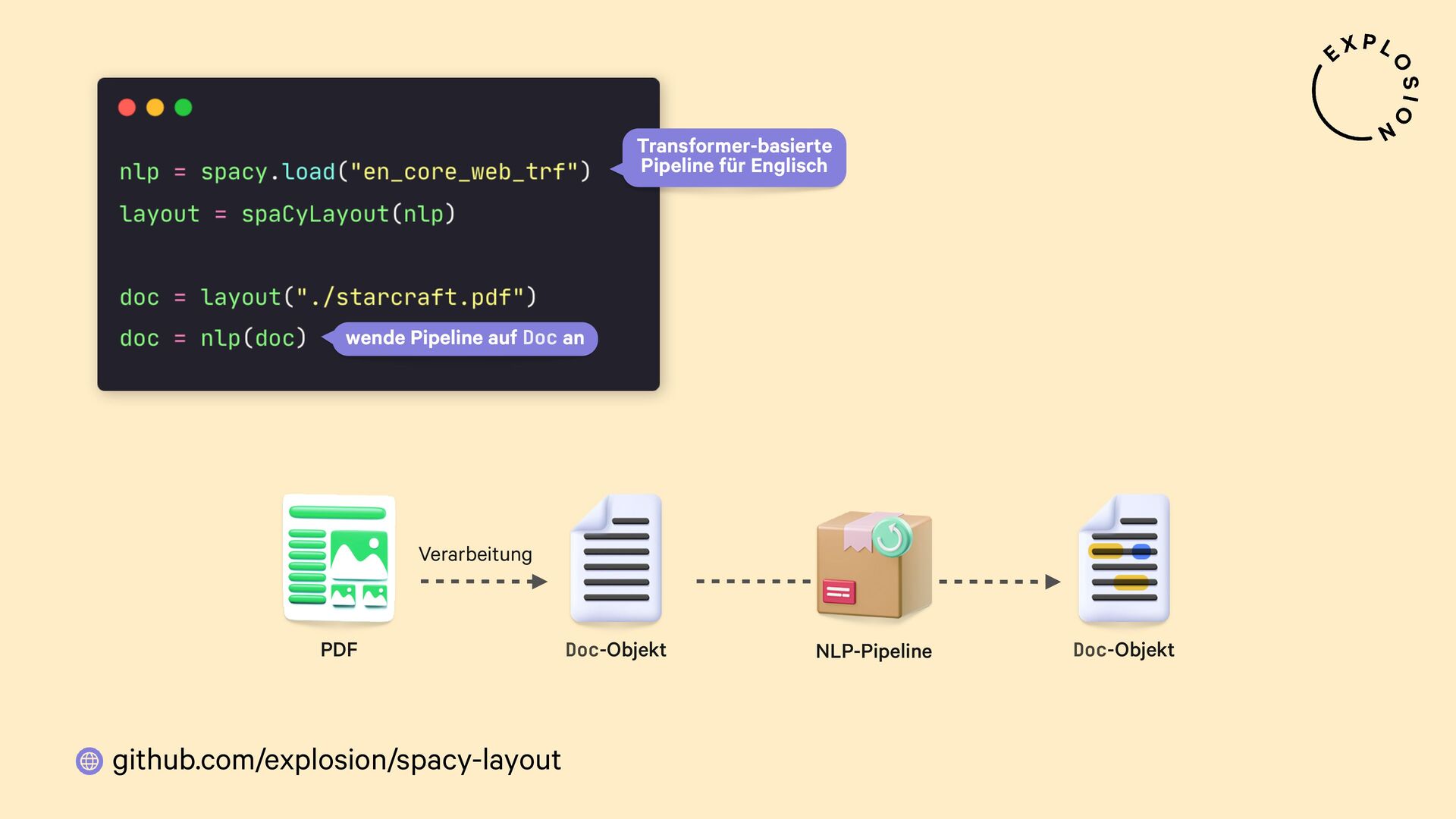
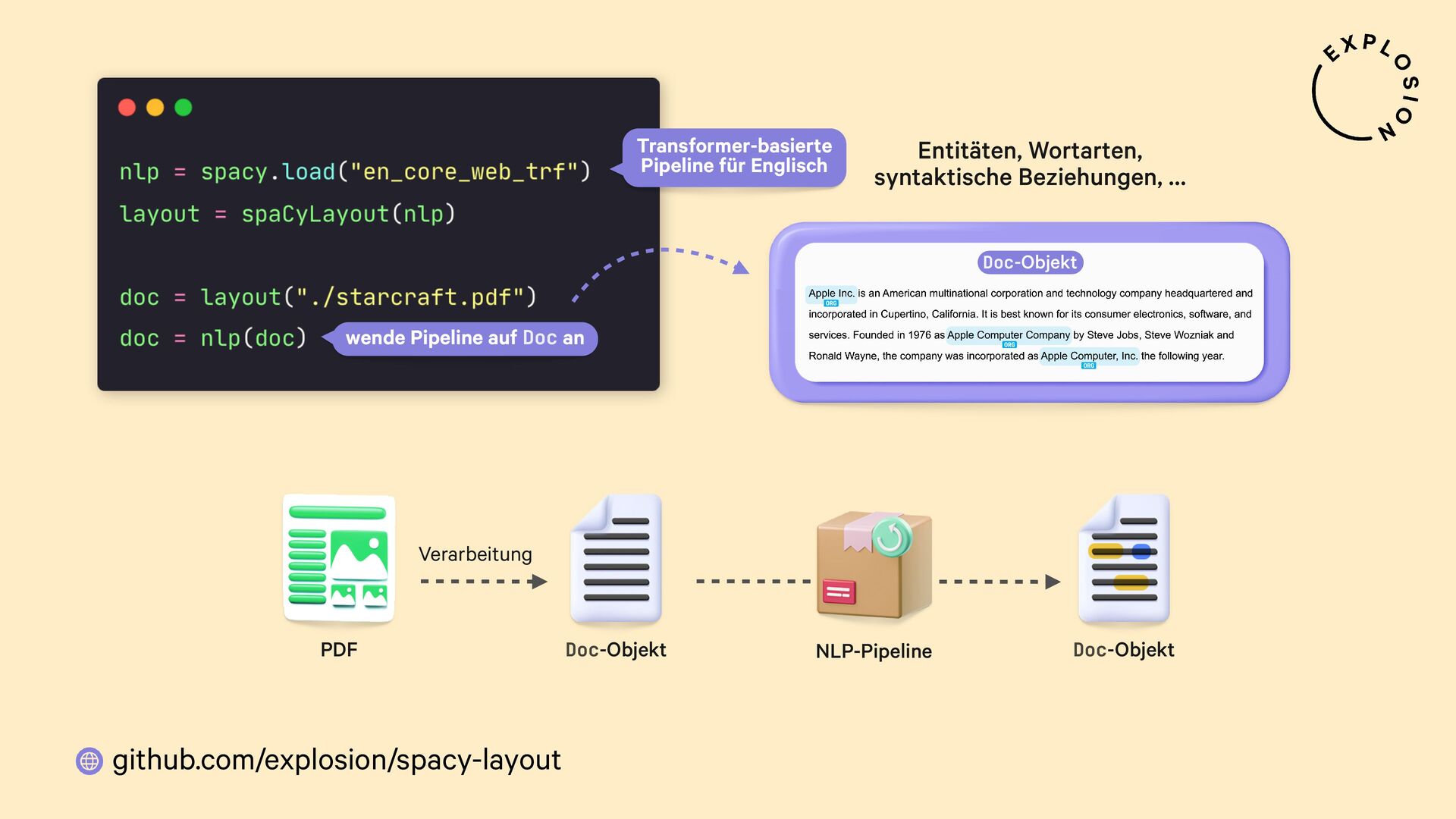
https://github.com/explosion/spacy-layout
Open-Source-Bibliothek für die Verarbeitung von PDFs mit spaCy
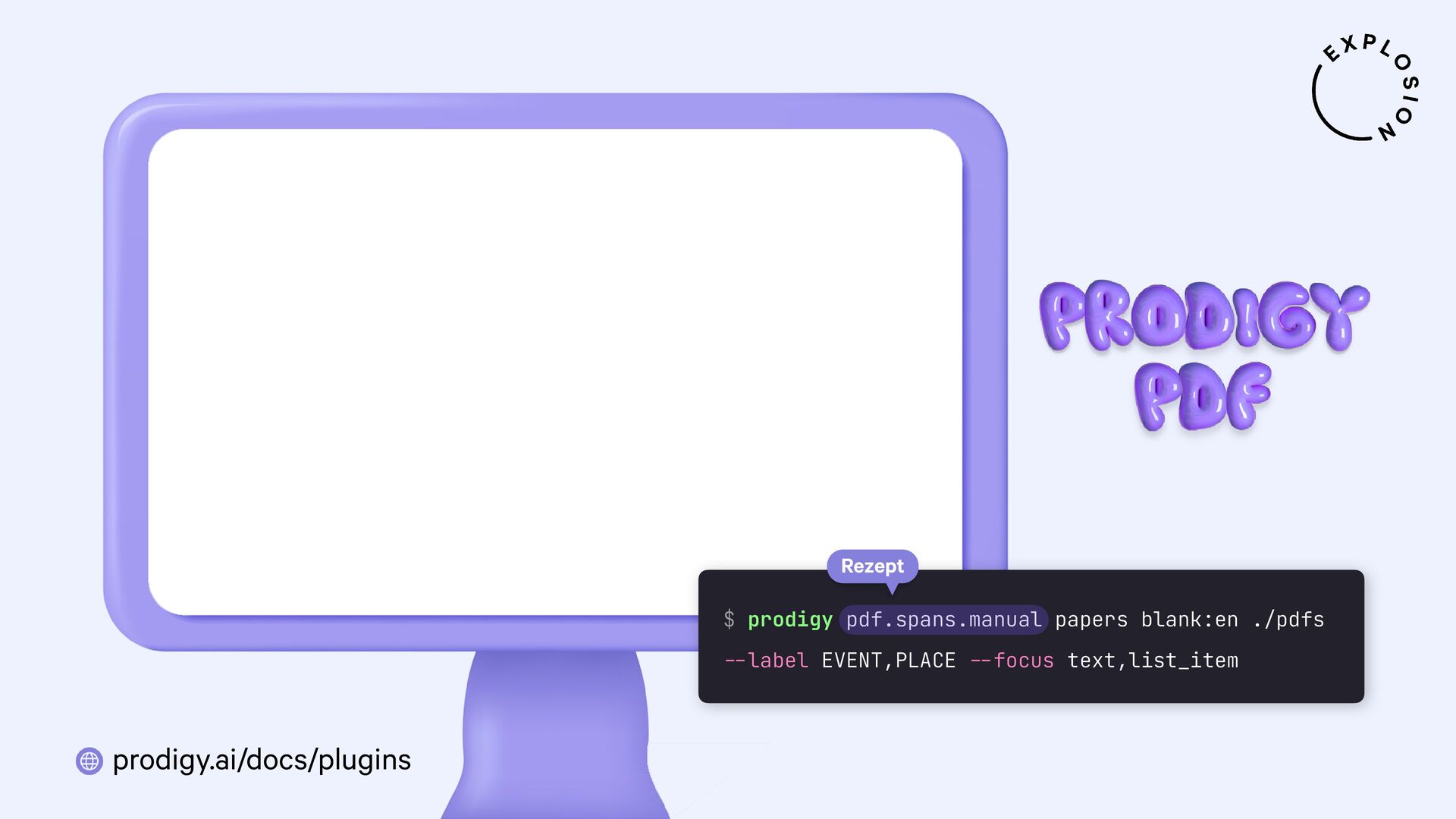
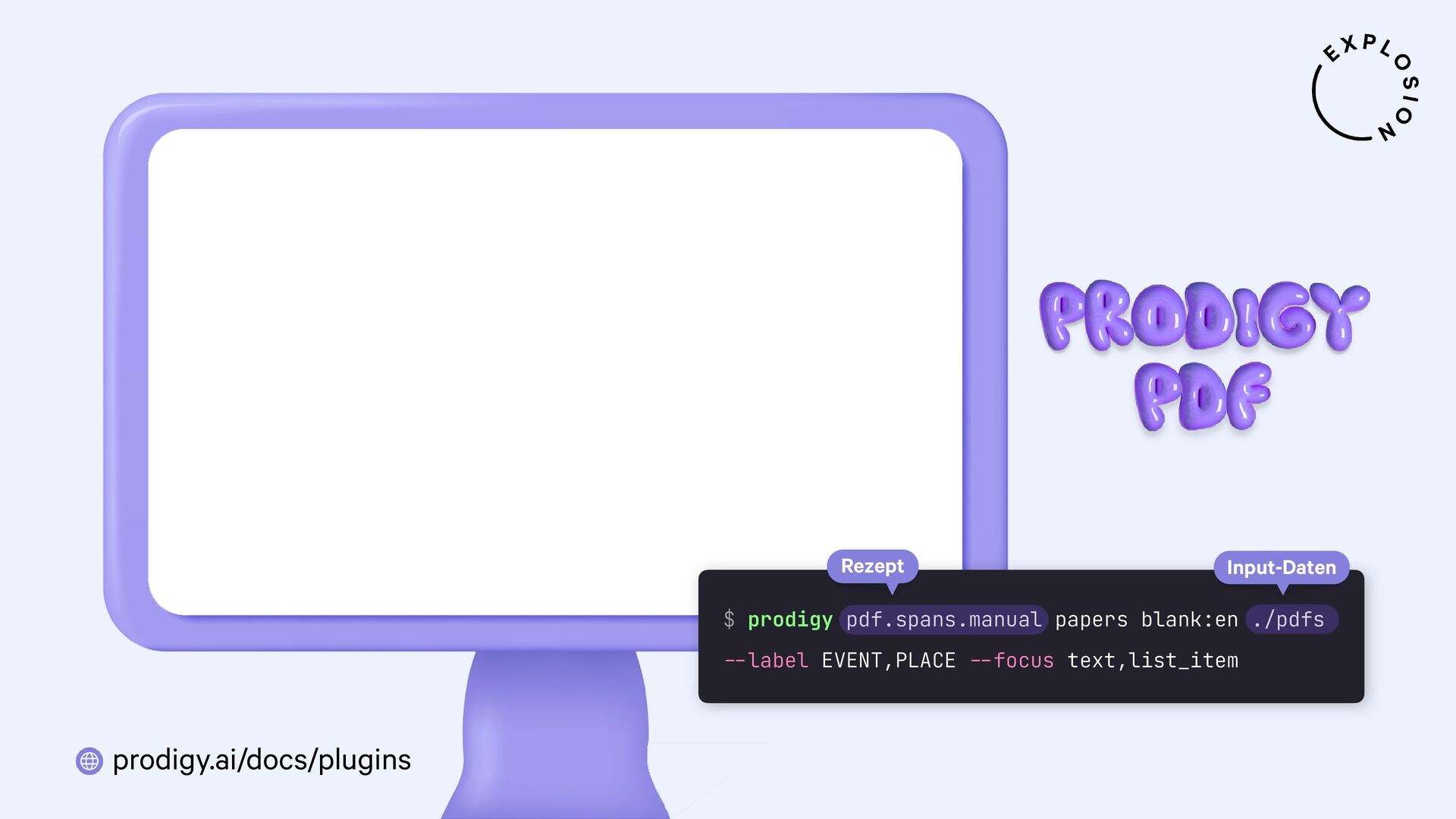
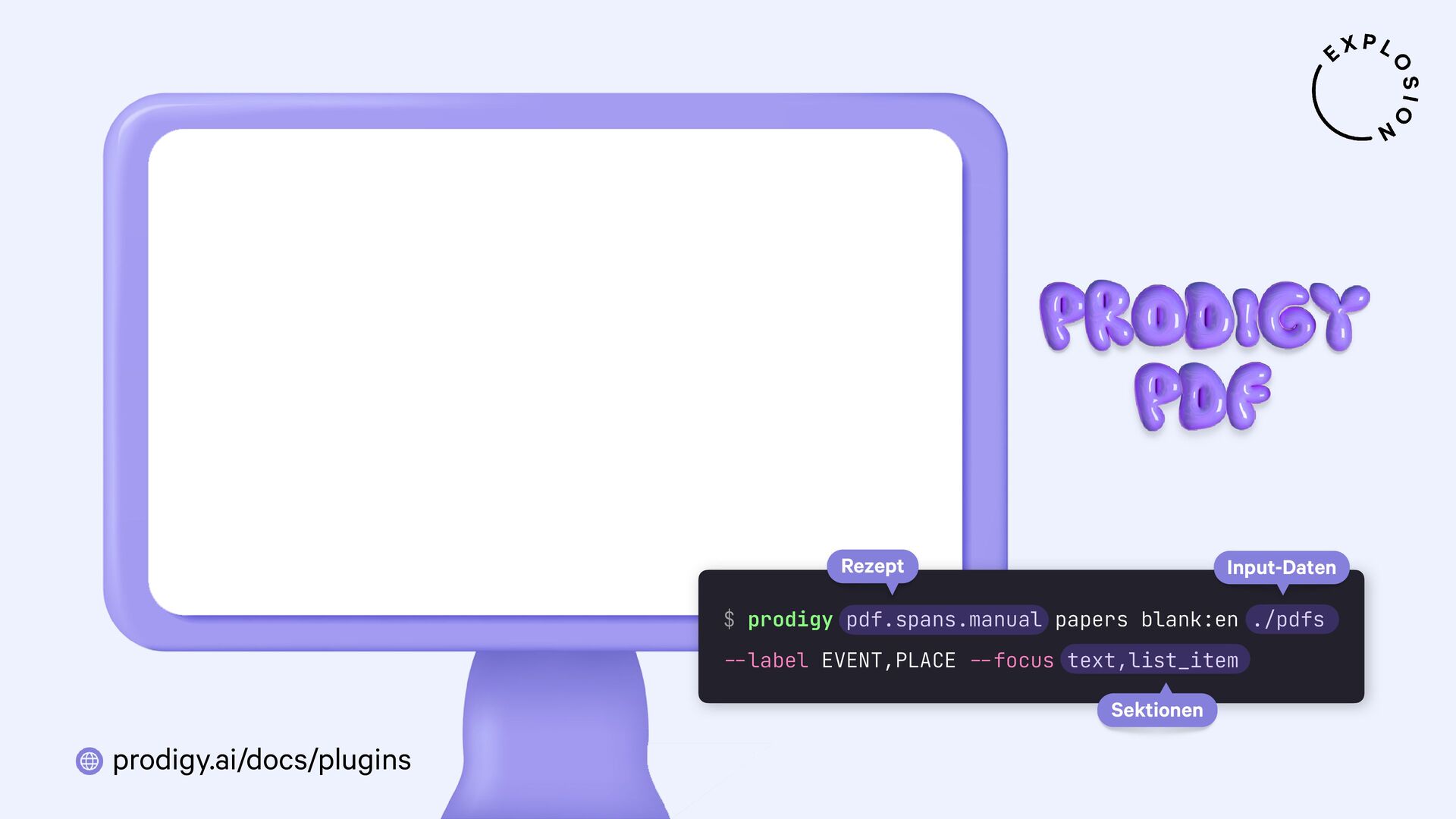
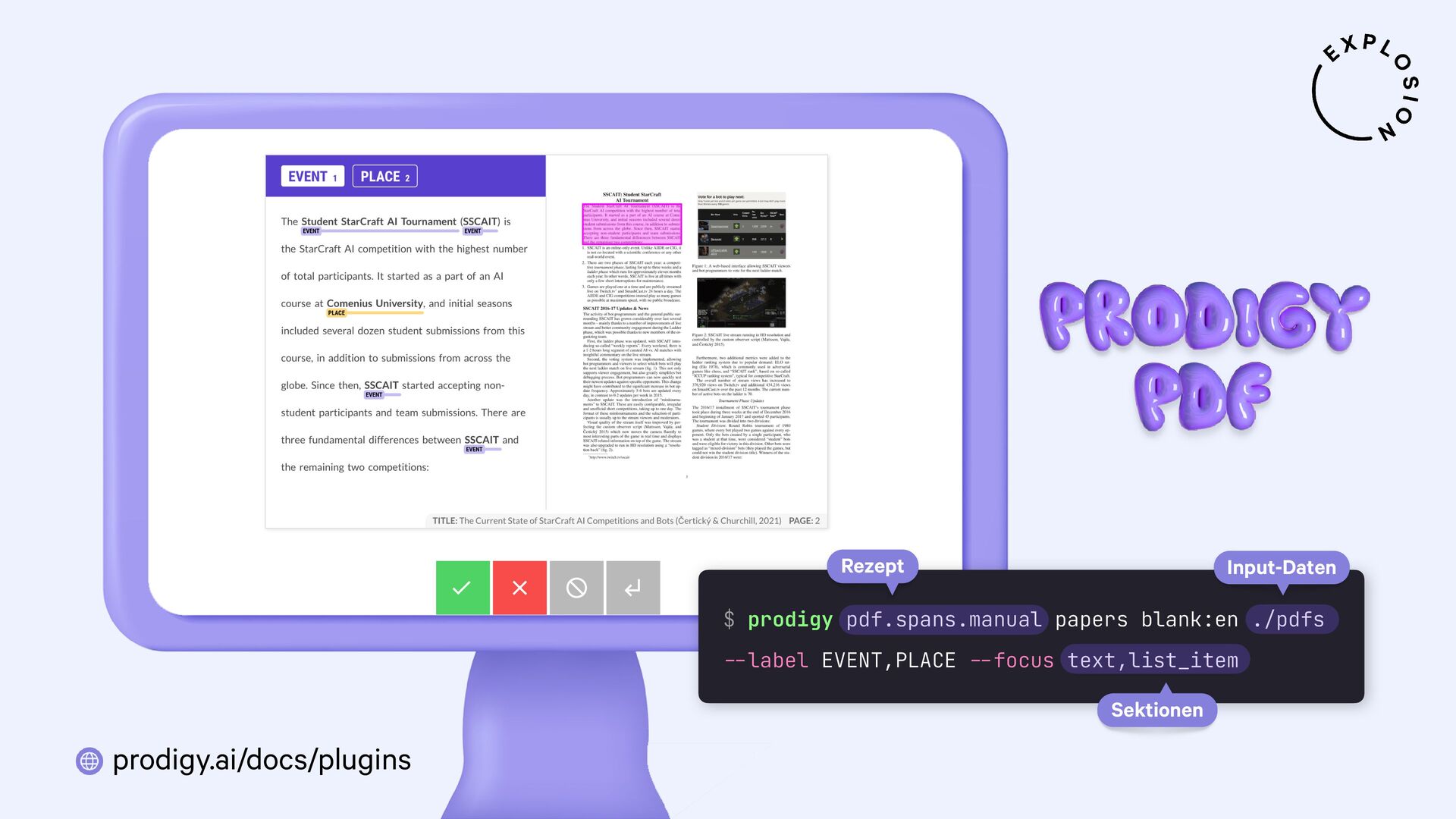
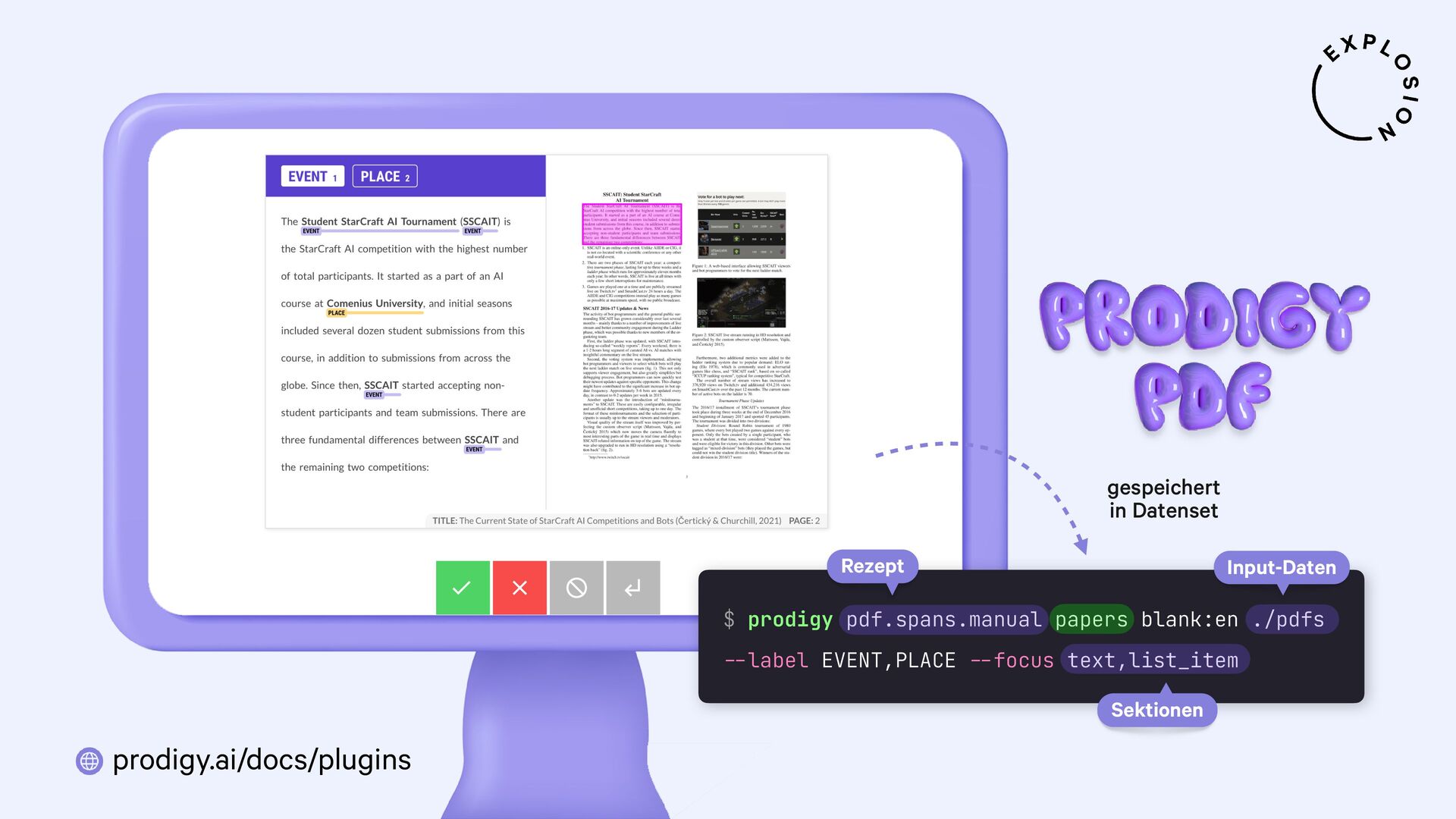
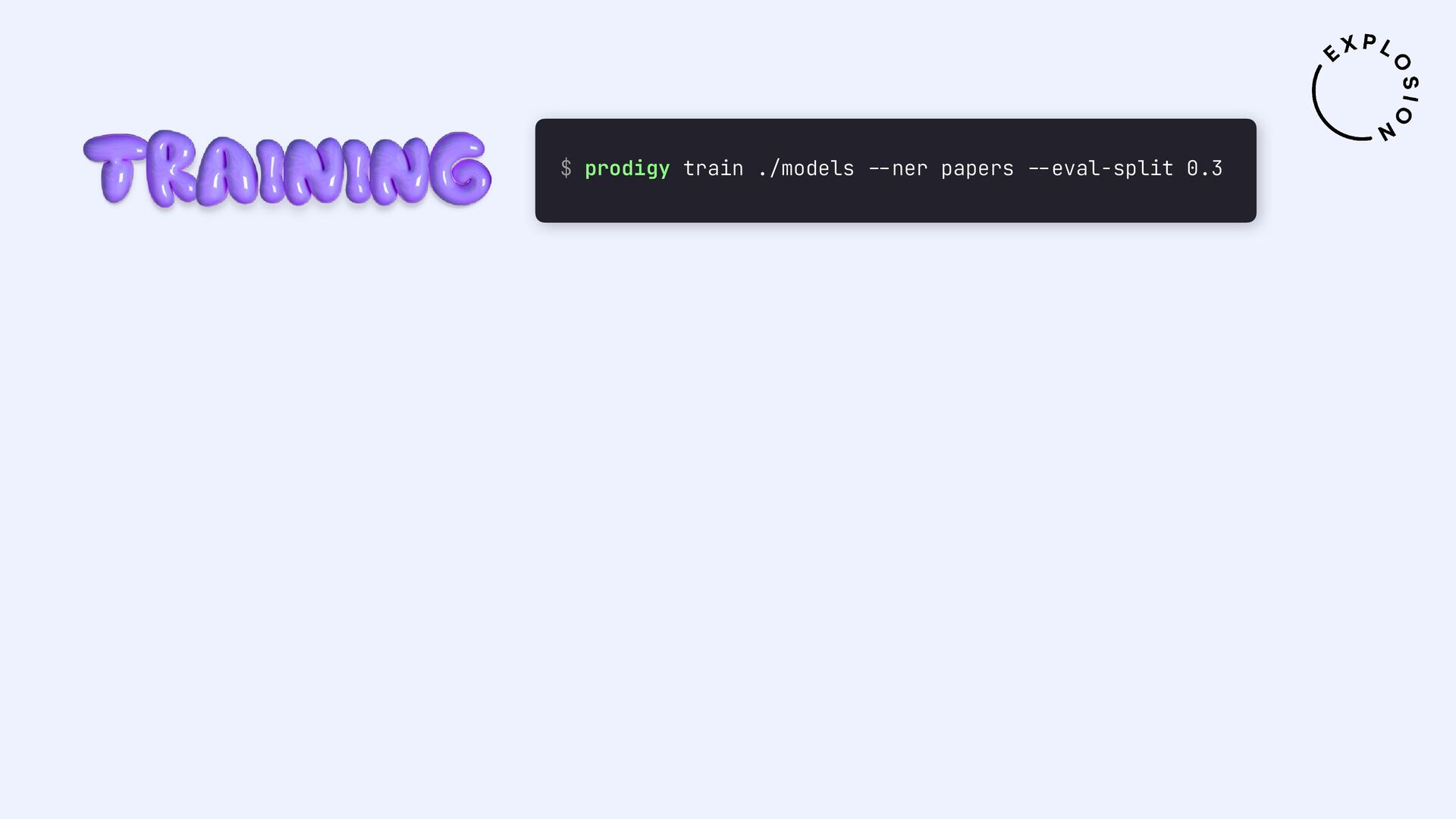
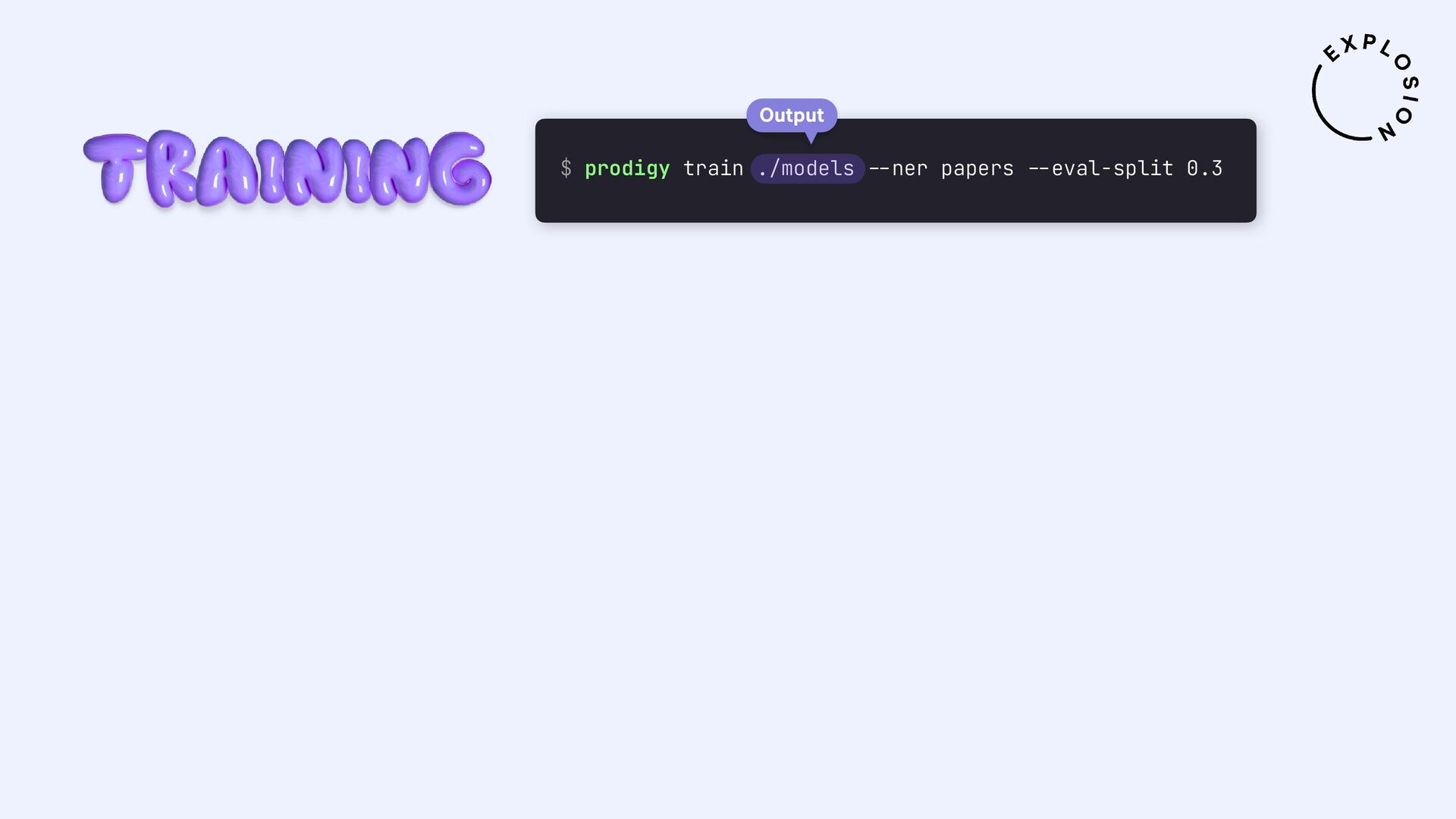
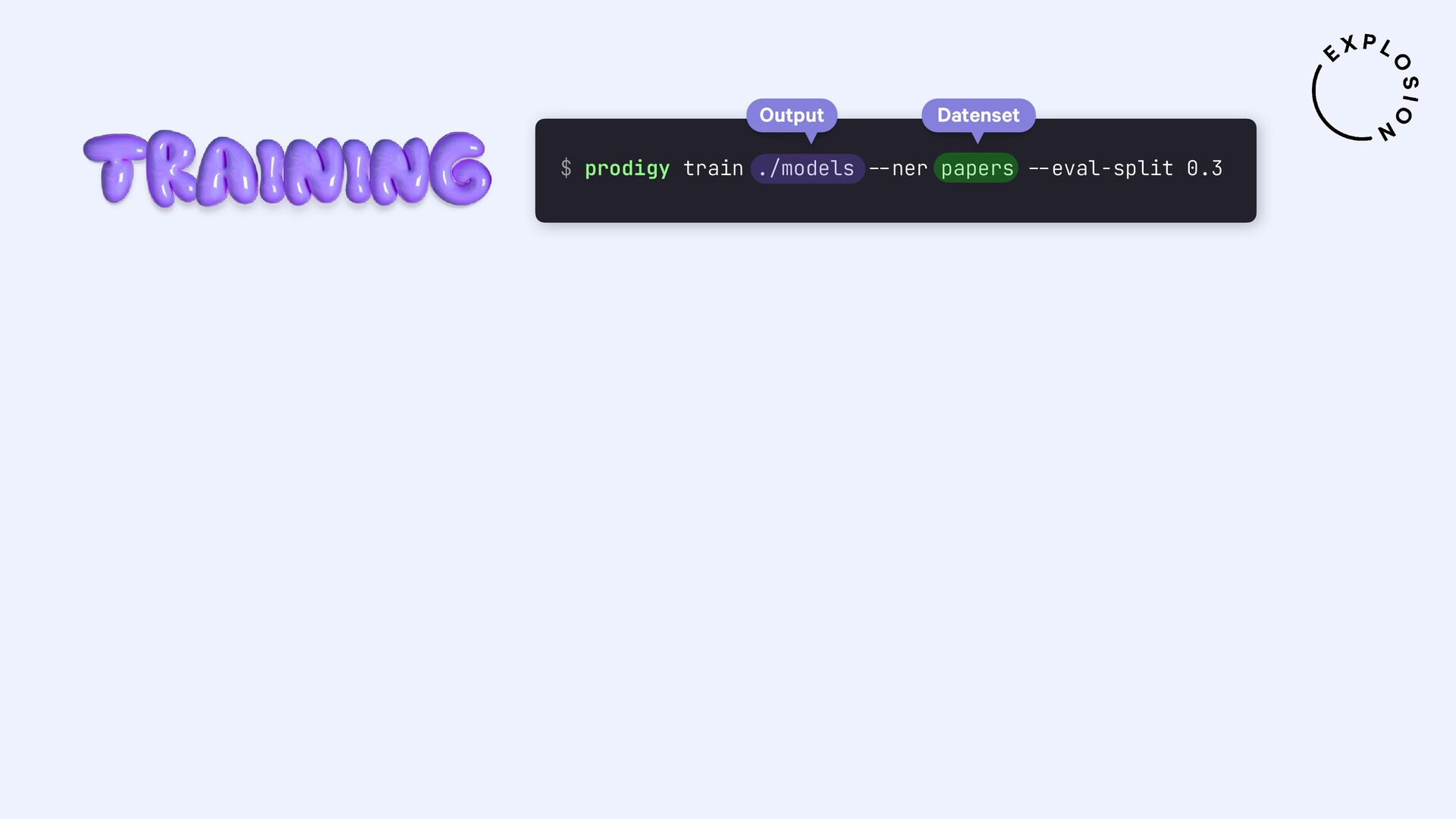
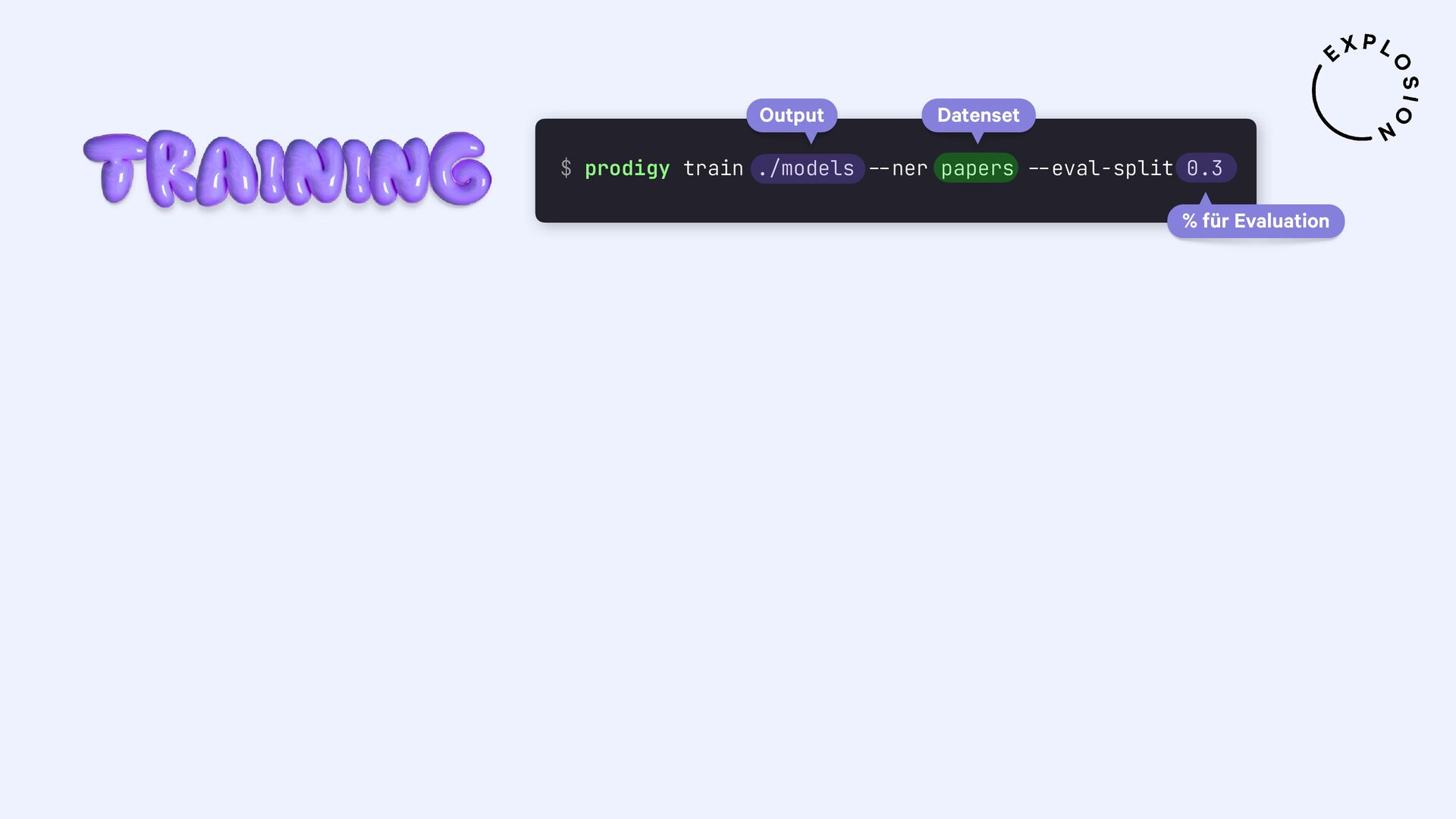
https://prodi.gy/docs/plugins#pdf
Plugin für das Annotationstool Prodigy mit Workflows für bild- und textbasierte Annotation von PDFs
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Explosion spaCy Prodigy Mastodon Bluesky explosion.ai spacy.io prodigy.ai @[email protected] @inesmontani.bsky.social](https://files.speakerdeck.com/presentations/53a67f60b3184de0bc286aa66b3649e5/slide_64.jpg){kind=link}