with integration into prominent job schedulers such as SLURM, used by Meta, exascale large institutions and universities, for scalable management of HPC environments along with tools for granular understanding of operational health of HPC environments and tasks running, with enterprise governance capabilities and control. HPC Environment Management Confidentiality Notice: This presentation, including any attachments, is for the exclusive and confidential use of the intended recipient(s). If you are not the intended recipient, please note that any form of dissemination, distribution, or copying of this communication is strictly prohibited and may be unlawful. If you have received this presentation in error, please immediately notify the sender and delete all copies.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
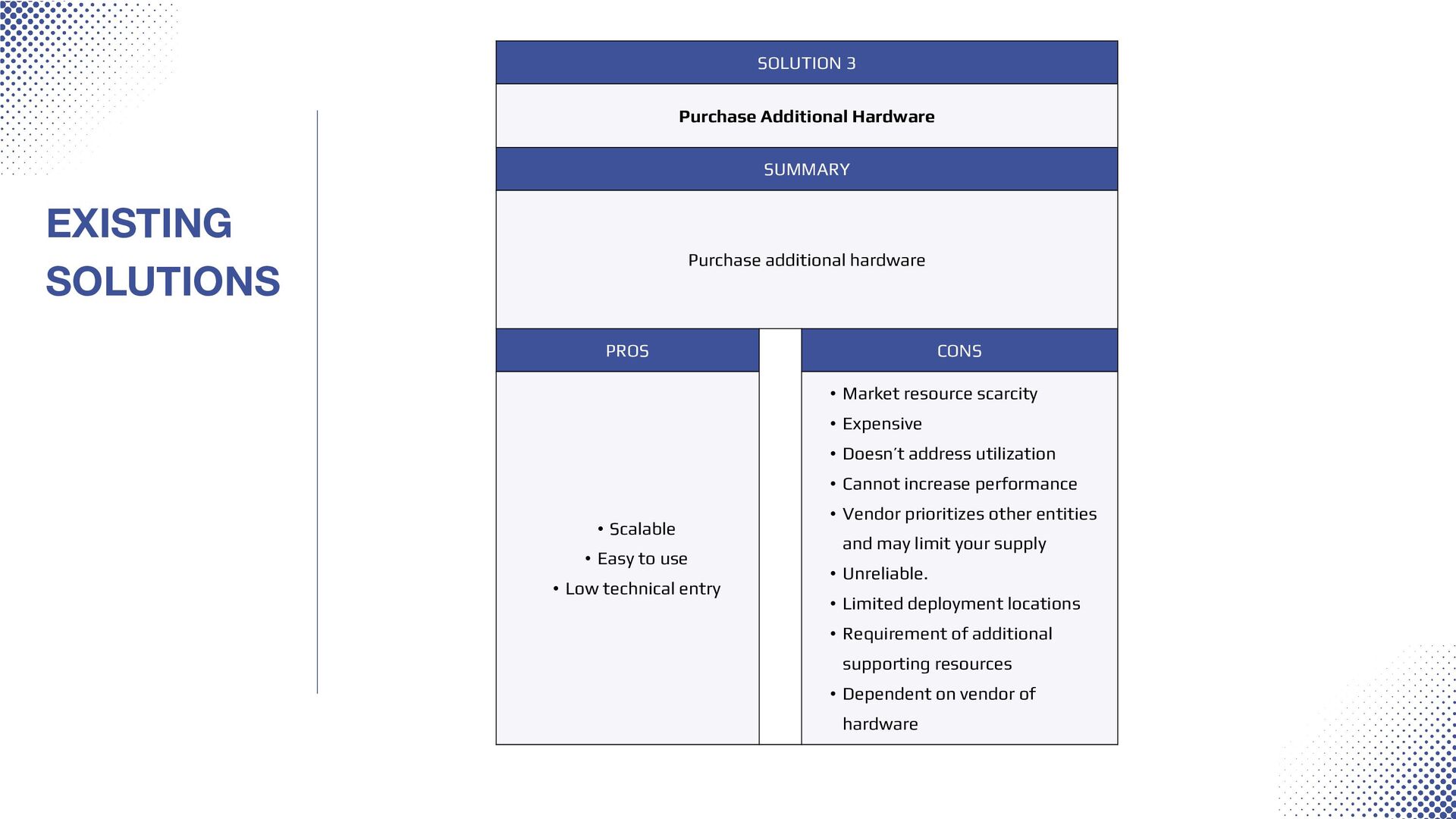{kind=link}
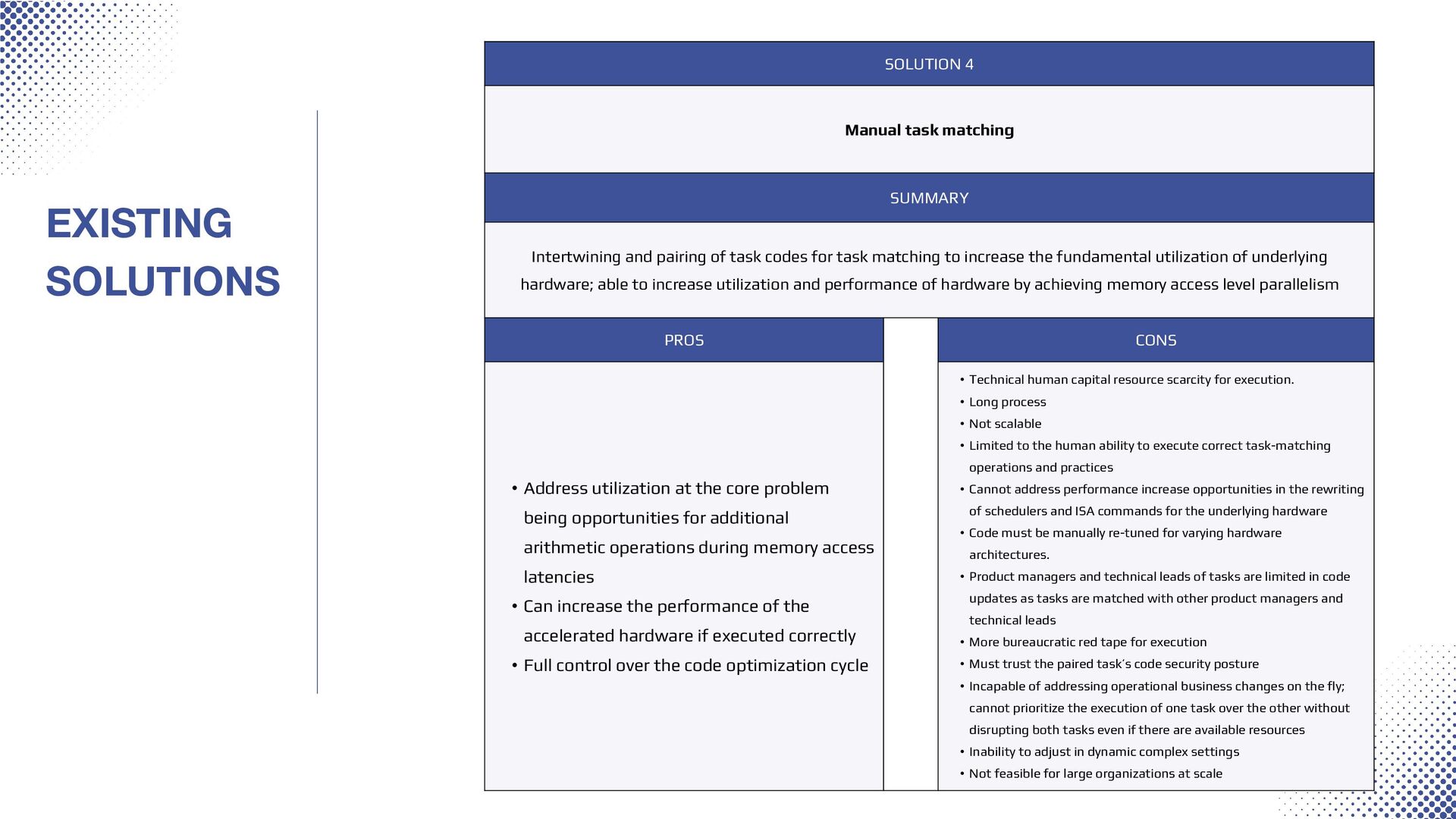{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
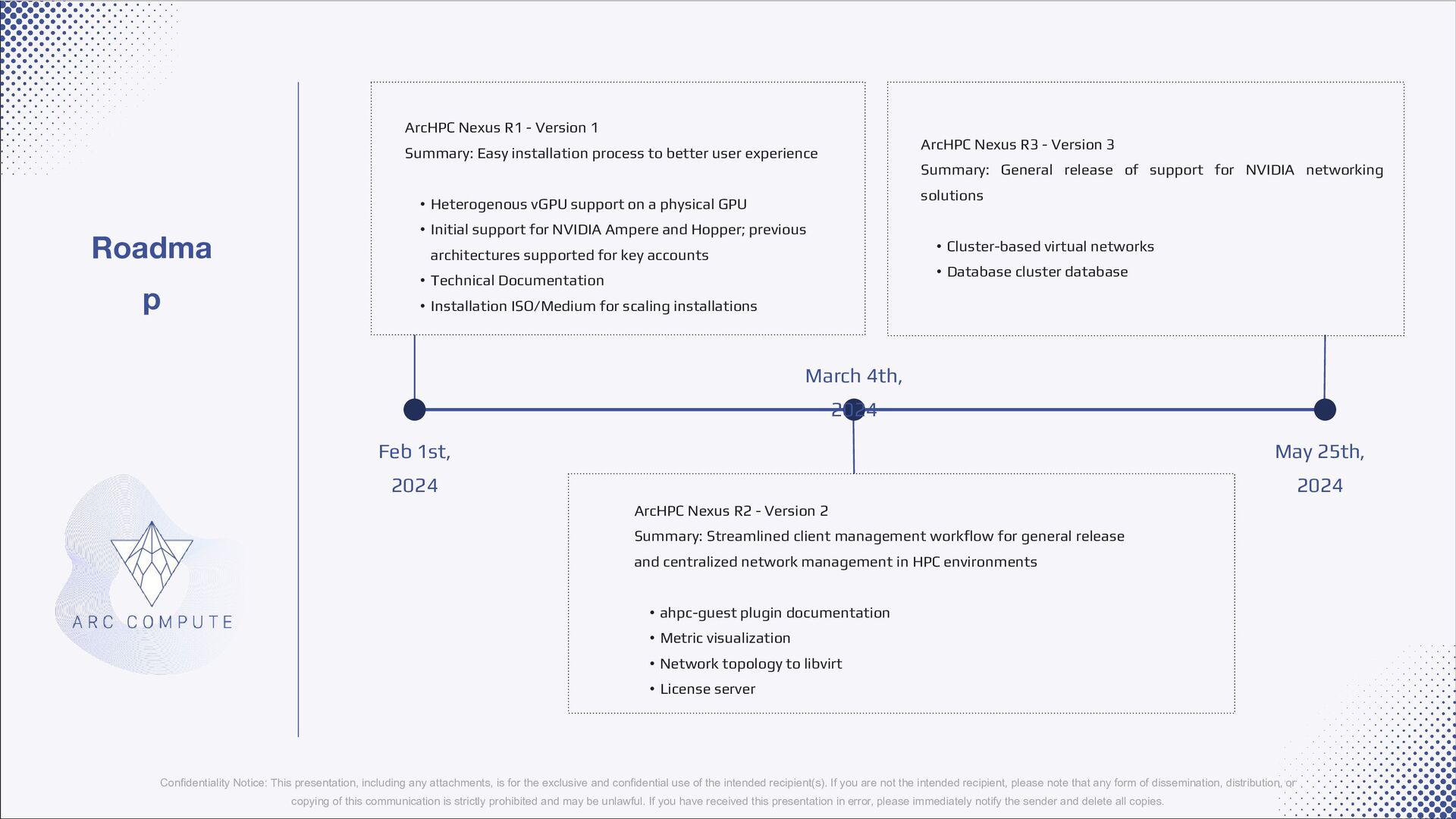{kind=link}
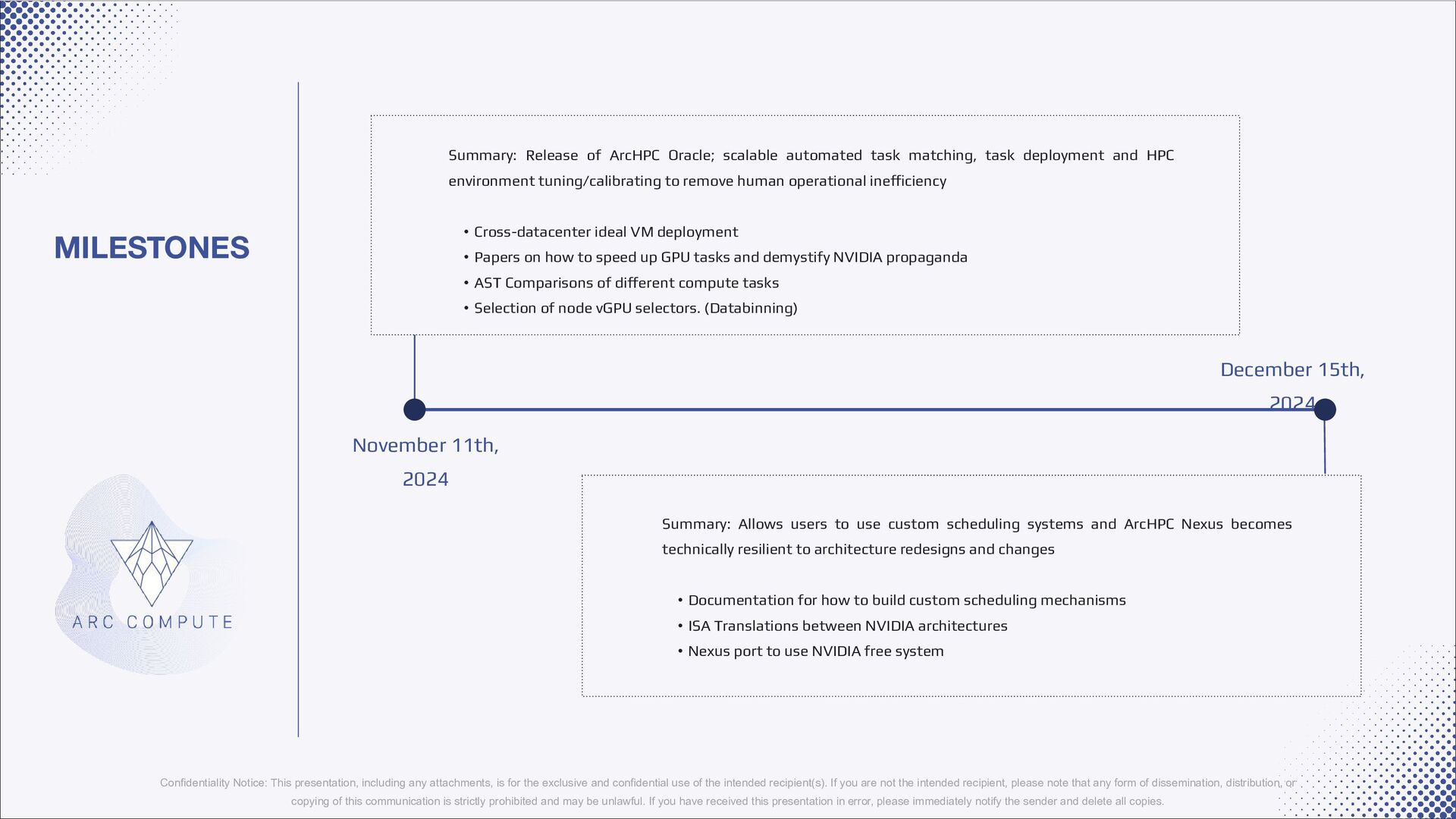{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}