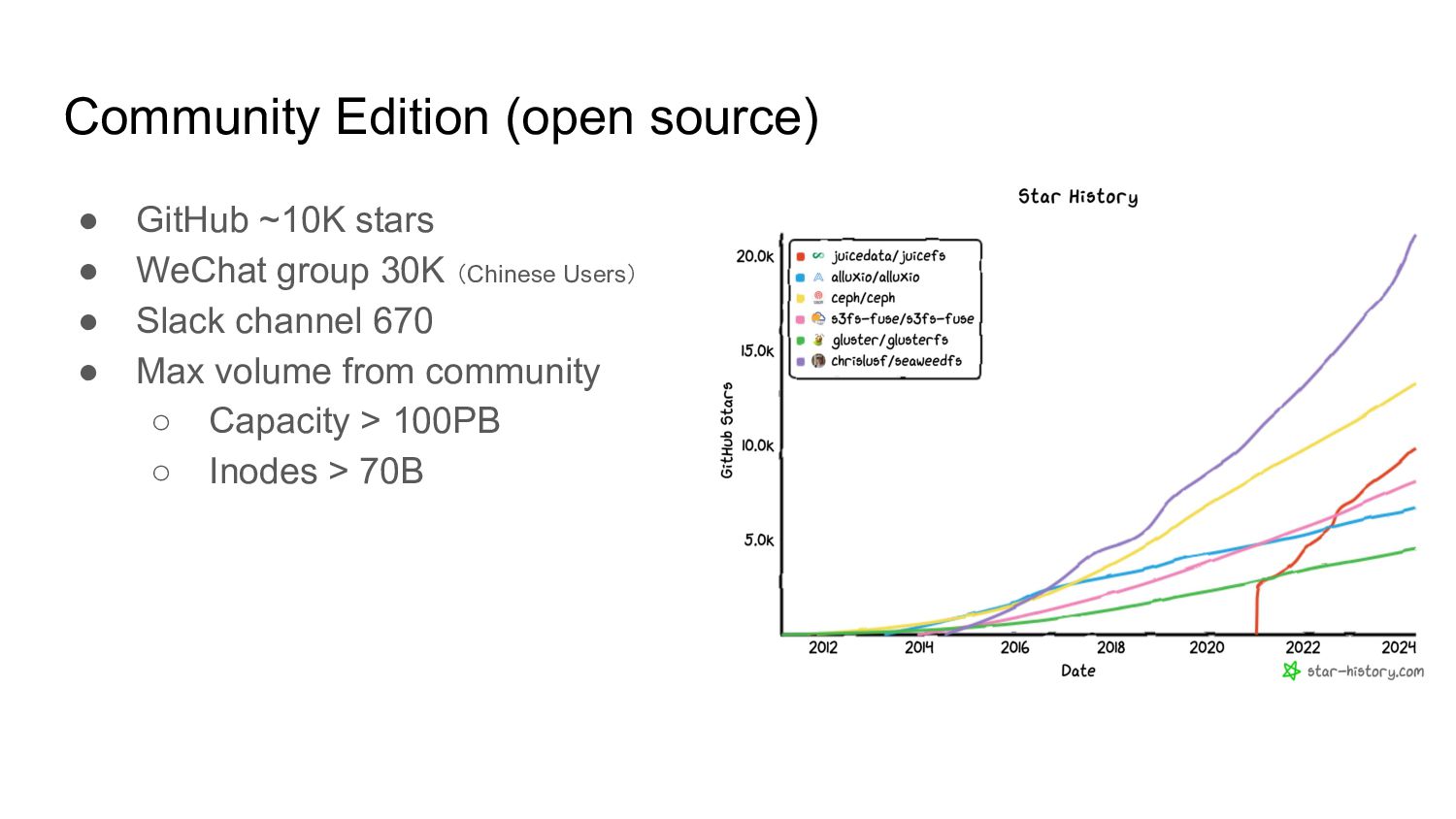
released under Apache 2.0 license, widely adopted globally. • Cloud Service on AWS, Azure, and GCP • Today ◦ 10K stars on GitHub (the fastest-growing open-source project in distributed file systems) ◦ Max volume exceeds 100PB ◦ More than 70B files in one volume Davies Liu, Founder and CEO ▪ MooseFS contributor ▪ Author of BeansDBa and DParkb ▪ Formerly at Meta and Databricks Rui Su, Co-founder ▪ Former CEO & Founder of a startup ▪ Former Tech Lead & PM at Douban Moviec ▪ 3 years of experience in NGO ▪ 1st engineer at Maxthon Browser a BeansDB: a simple object storage created in 2000, used in production environments with petabytes of data. b DPark: a Spark Python clone written in 2010. c Douban Movie: dubbed as the Chinese version of IMDb/Rotten Tomatoes.
Early releases with several clients • 2021 Community Edition (Open Source) released under AGPLv3 License • 2022 Community Edition v1.0 LTS GA under Apache2.0 License • 2023 Enterprise Edition v5.0 GA, CE v1.1 LTS GA • 2024 Community Edition v1.2 LTS, RC currently (20+ people)
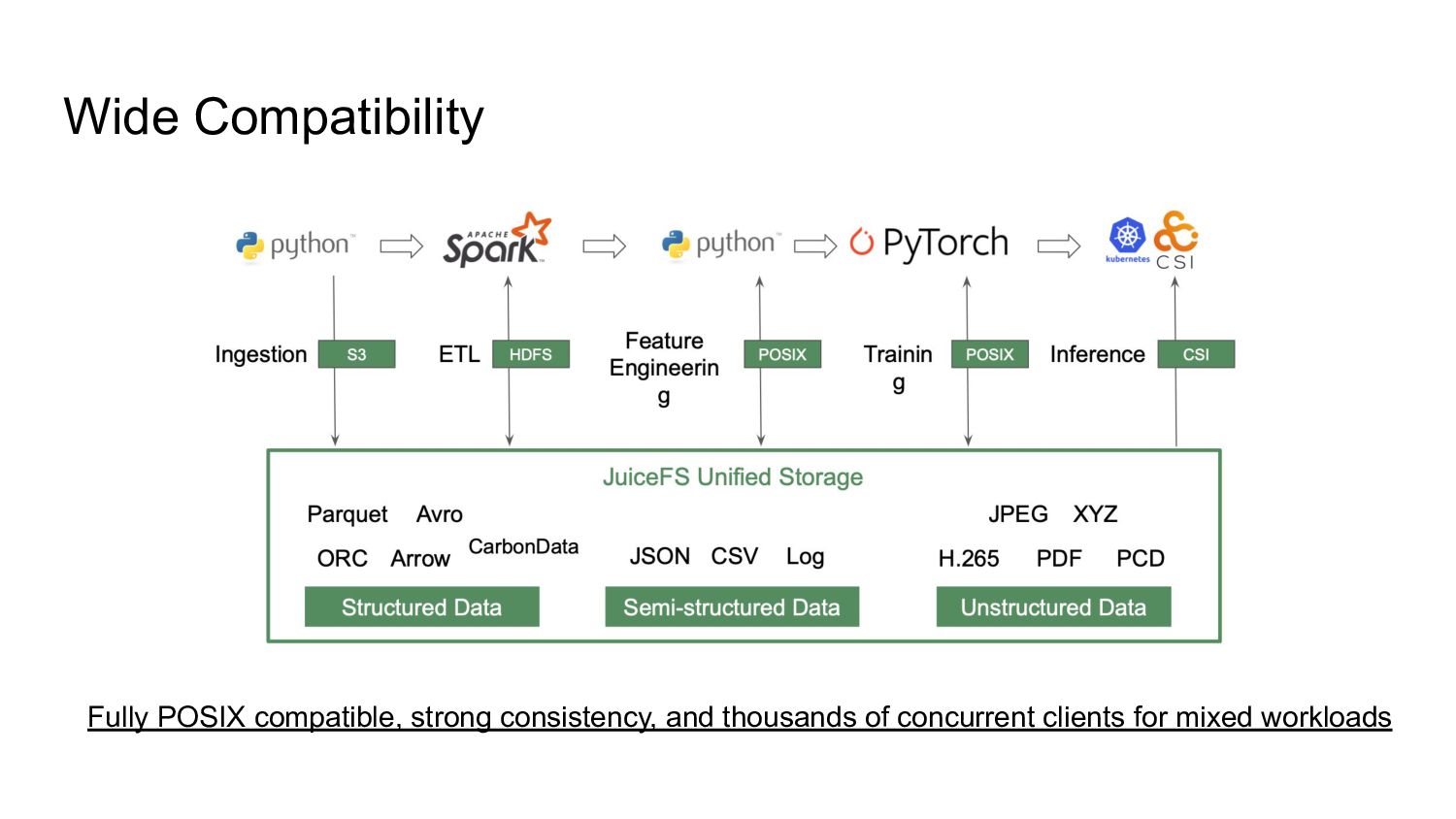
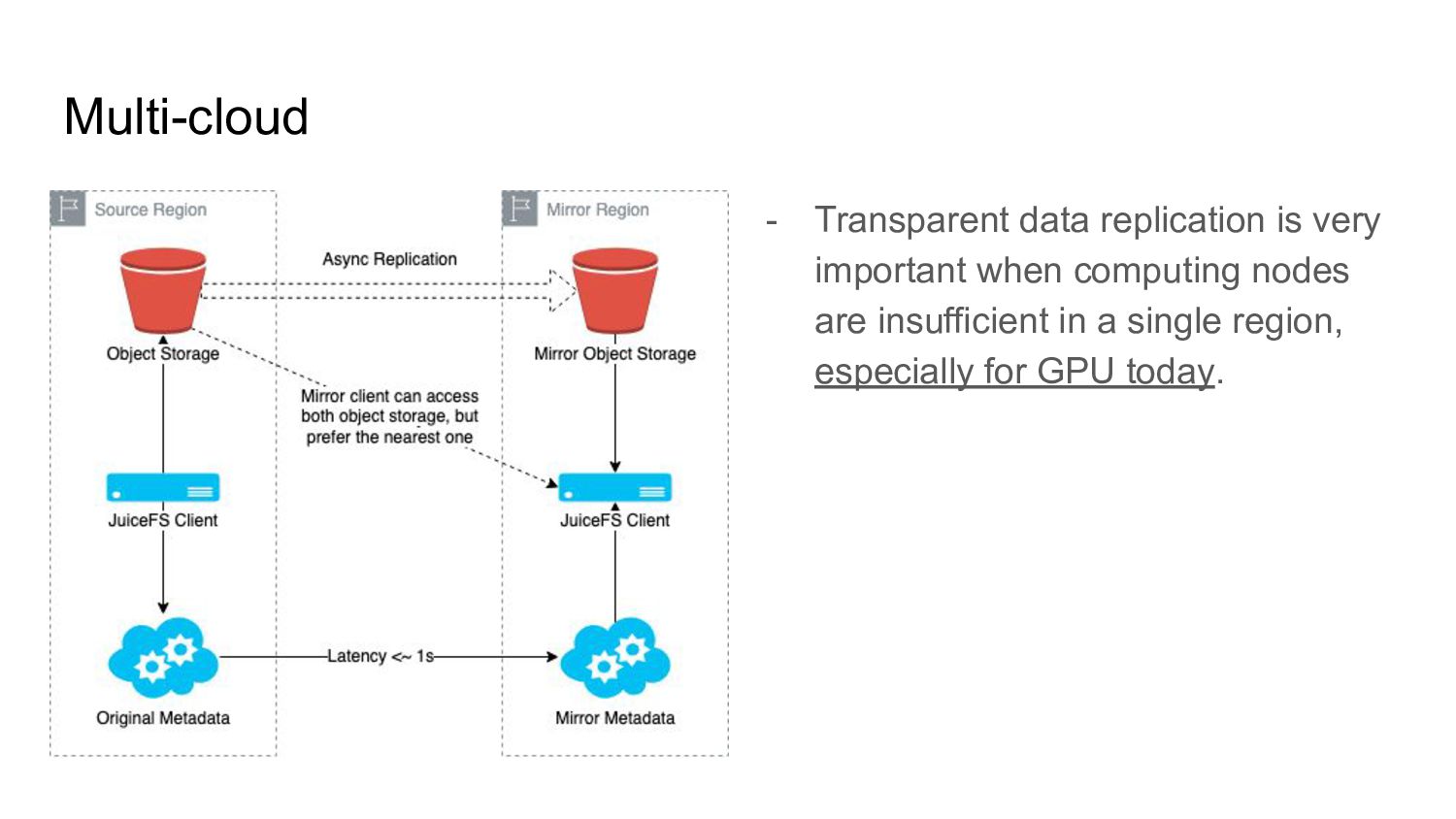
web services, but has limited compatibility with data-intensive workloads. - No file system was designed for the cloud; most were built from bare metal, not elastic and much more expensive than S3. - Throughput is usually tied to data capacity and can't scale up independently. - Managing LOSF (lots of small files) is a persistent challenge of file storage, especially in the AI domain. - Data access in multi-cloud and hybrid-cloud environments is an emerging requirement.
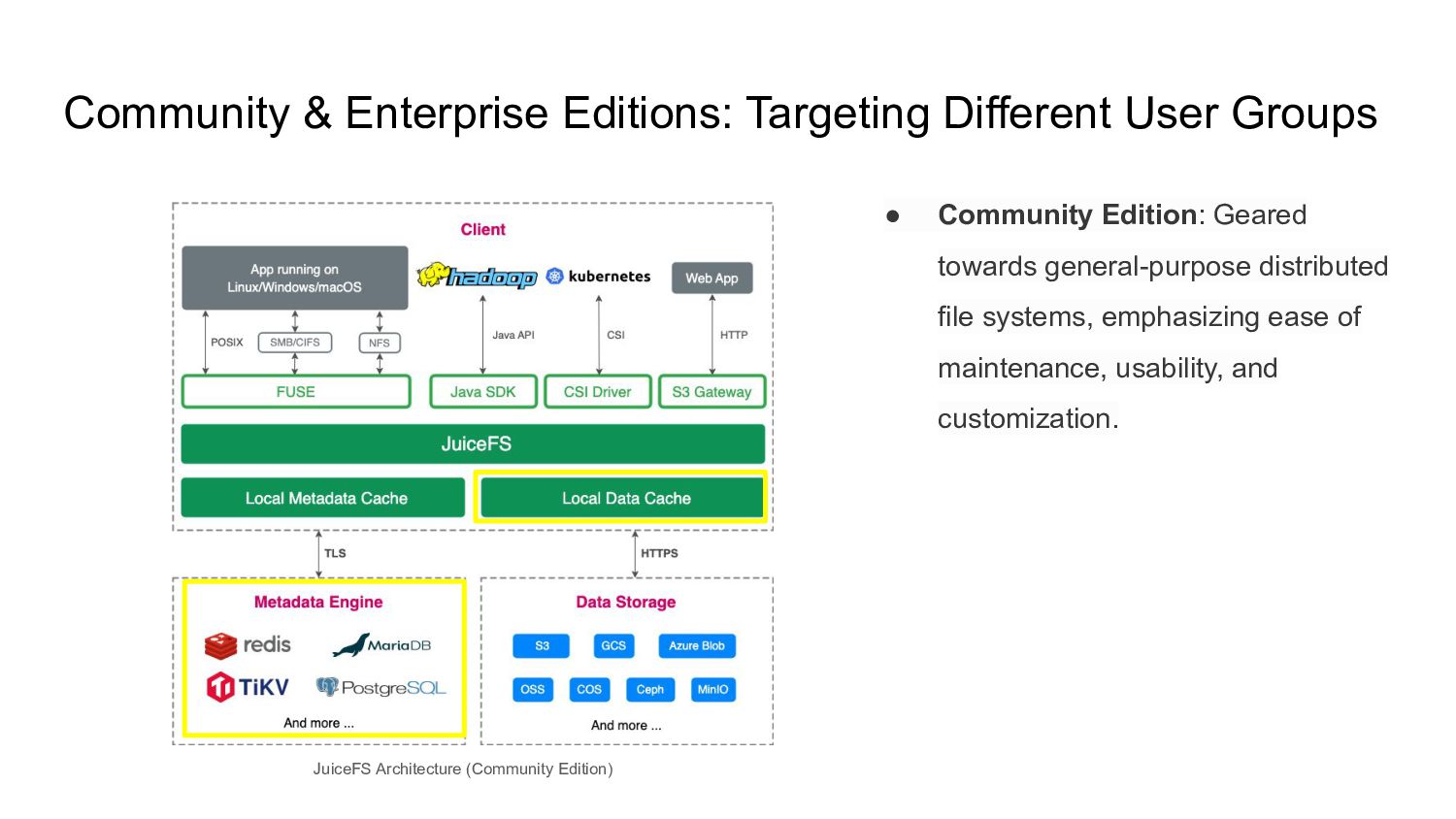
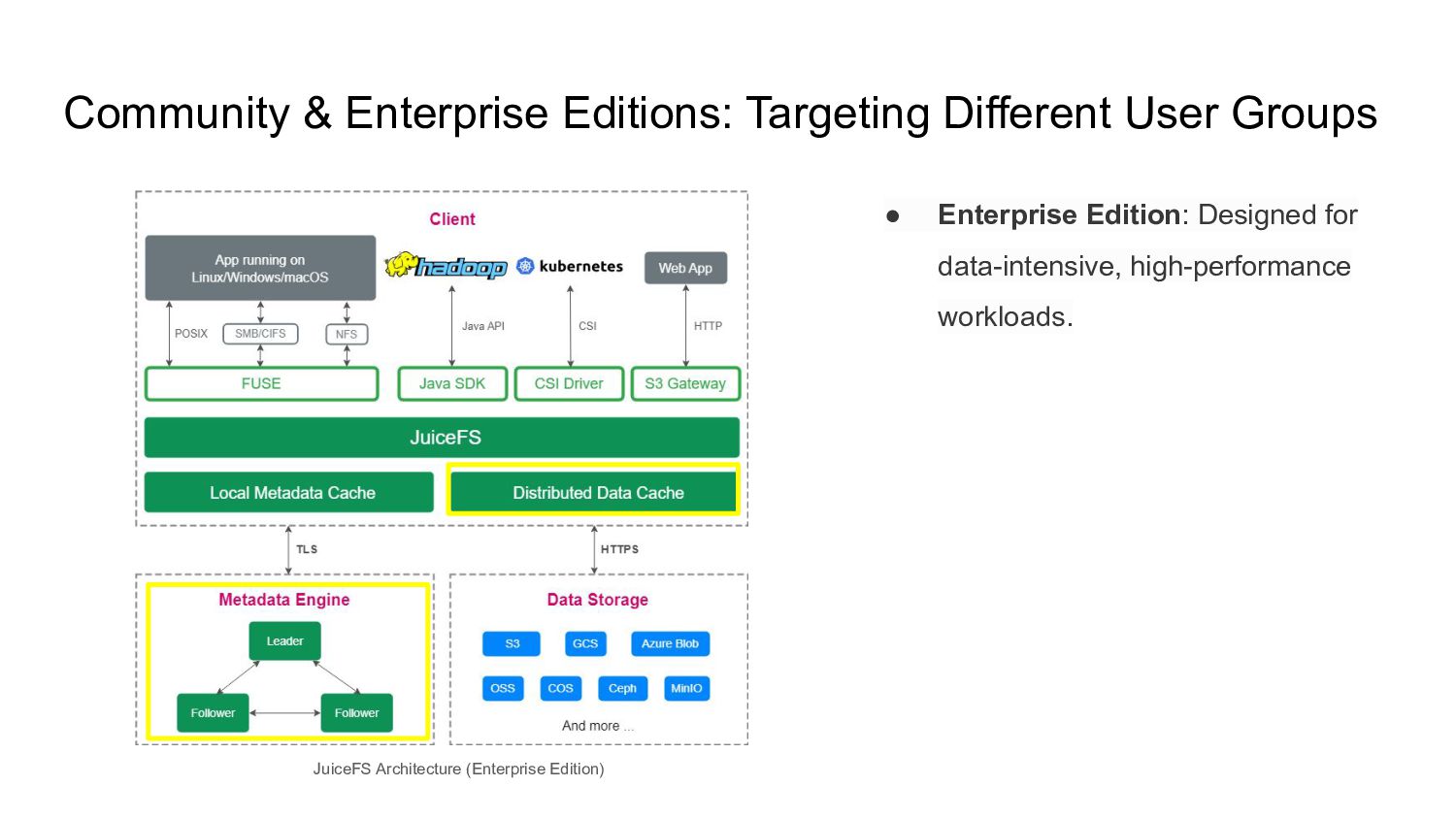
complex maintenance work. Juicedata is committed to empowering every enterprise to easily tackle the challenges of massive data and high-performance workloads. POSIX, Elastic, High throughput, 10B in one volume, Multi-cloud, Not expensive
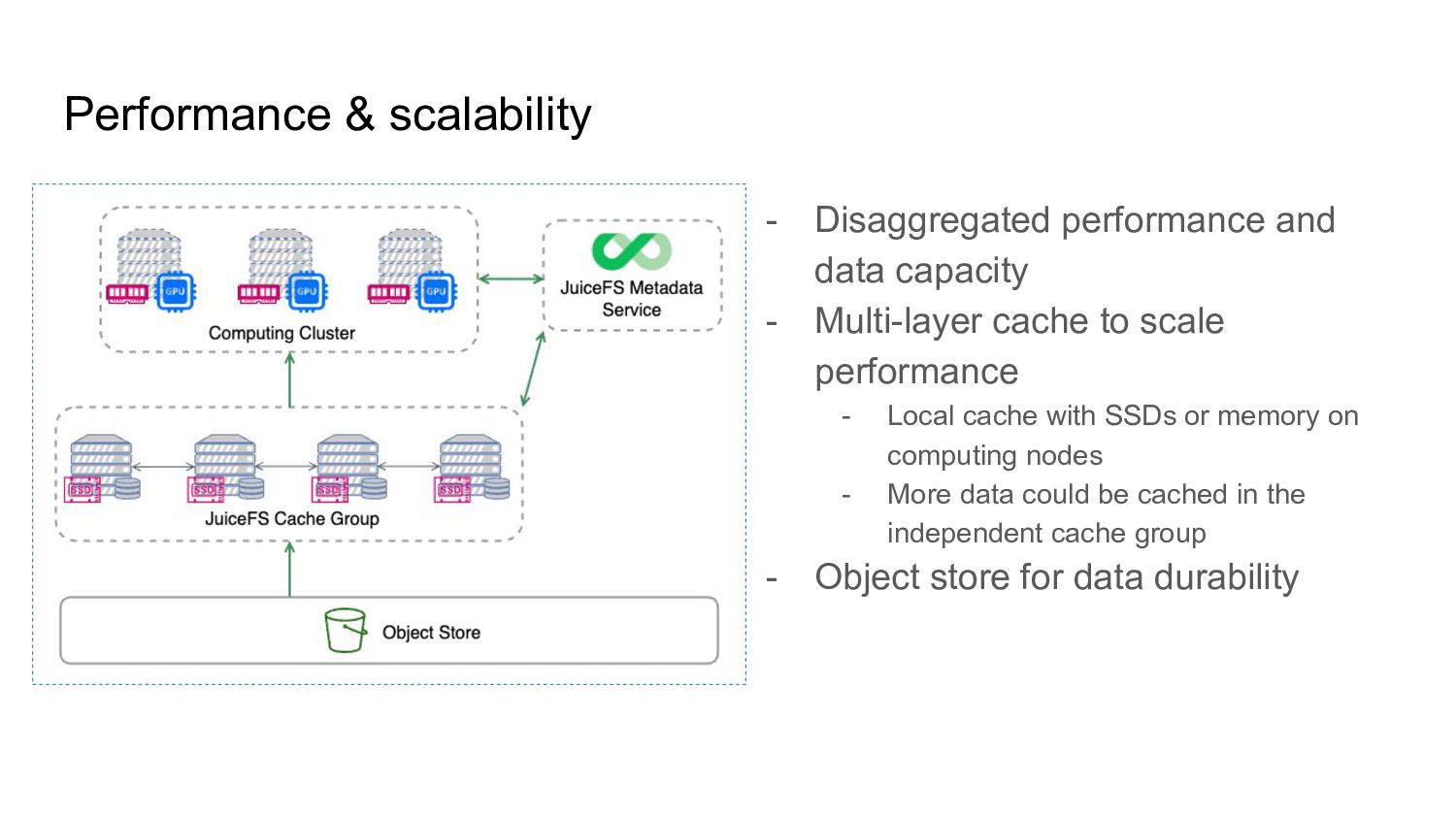
Multi-layer cache to scale performance - Local cache with SSDs or memory on computing nodes - More data could be cached in the independent cache group - Object store for data durability
AI - Autonomous Driving - Quantitative Trading - BioTech Data Lake - HDFS alternative, S3 improvement - Integrated with all components of big data ecosystem Kubernetes Persistent Volume
$2.5B - Unified storage for LLM pre-training pipeline - Local NVMe cache on each GPU node + independent NVMe cache group + object storage(cloud service and Ceph RADOS) - > 300GBps throughput in ONE JuiceFS volume - Cloud + DC, auto data replication See also: - JuiceFS Benchmark on MLPerf - NAVER uses JuiceFS in its machine learning platform - BentoML uses JuiceFS to reduce model deployment time
GM, Mercedes-Benz, Toyota - Some metrics in the production environment - 20B files in ONE volume, average 100KiB per file - 450K metadata QPS - File read QPS 300K - Avg response latency 0.4ms - Throughput peak 70GiB/s - Cache hit > 80% - Synchronization latency between 2 sites about 20ms
cloud, founded in Silicon Valley, AUM exceeding $15B. - Early on, they used AWS FSx for Lustre and Aliyun CPFS (IBM GPFS), but throughput scale was limited by data capacity and too expensive. - JuiceFS Cloud Service enables them to decouple performance and capacity at a low cost. More details: - Metabit: Setting Up a Cloud-Based Machine Learning Platform with JuiceFS
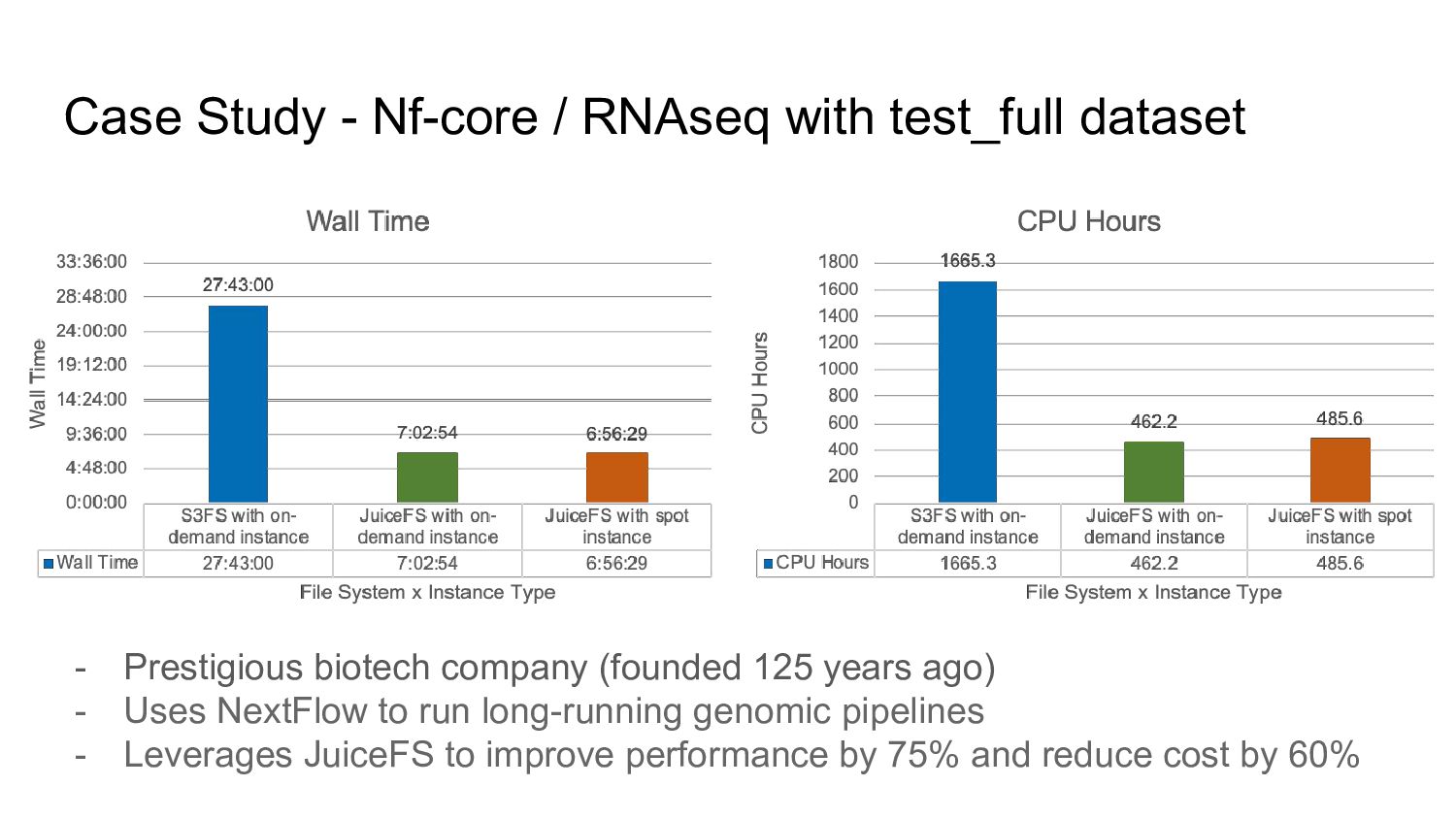
Prestigious biotech company (founded 125 years ago) - Uses NextFlow to run long-running genomic pipelines - Leverages JuiceFS to improve performance by 75% and reduce cost by 60%
JuiceFS Deployment AWS Managed Service Juicedata Managed Service, On-Prem, and AWS Marketplace Data Access Protocol POSIX POSIX, HDFS and S3 Performance Peak of aggregate throughput 1000MB/s/TiB Unlimited aggregate throughput, scale by adding more cache Multi-cloud and Hybrid-cloud No Yes Pricing $0.6 per GB-month + Provisioned metadata IOPS fee + Backup storage fee + Data transfer fee $0.04 per GB-month • $0.02 per GB-month (Juicedata charge) • $0.02 per GB-month (approximate, S3 charge) https://juicefs.com/en/pricing
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}