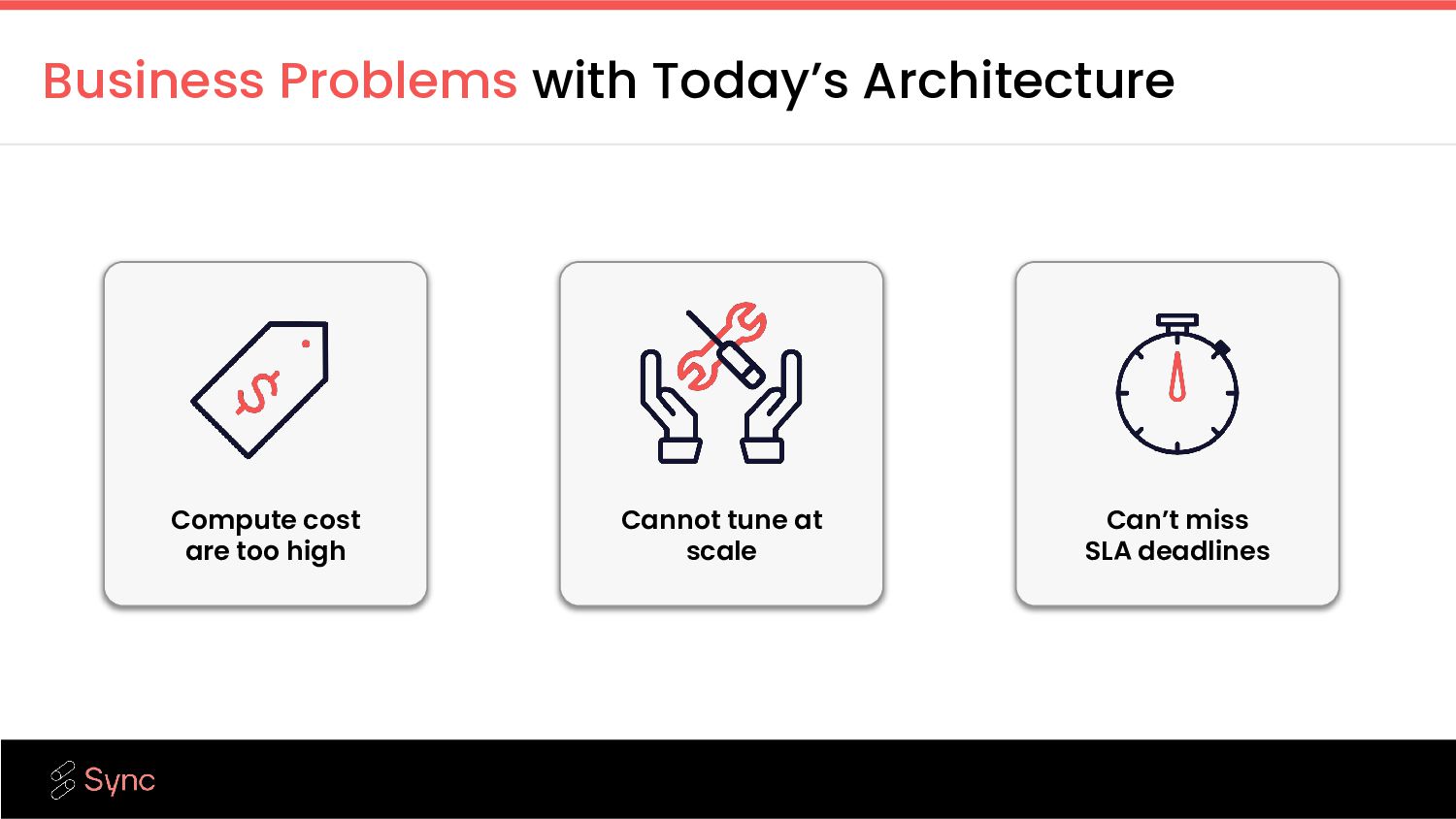
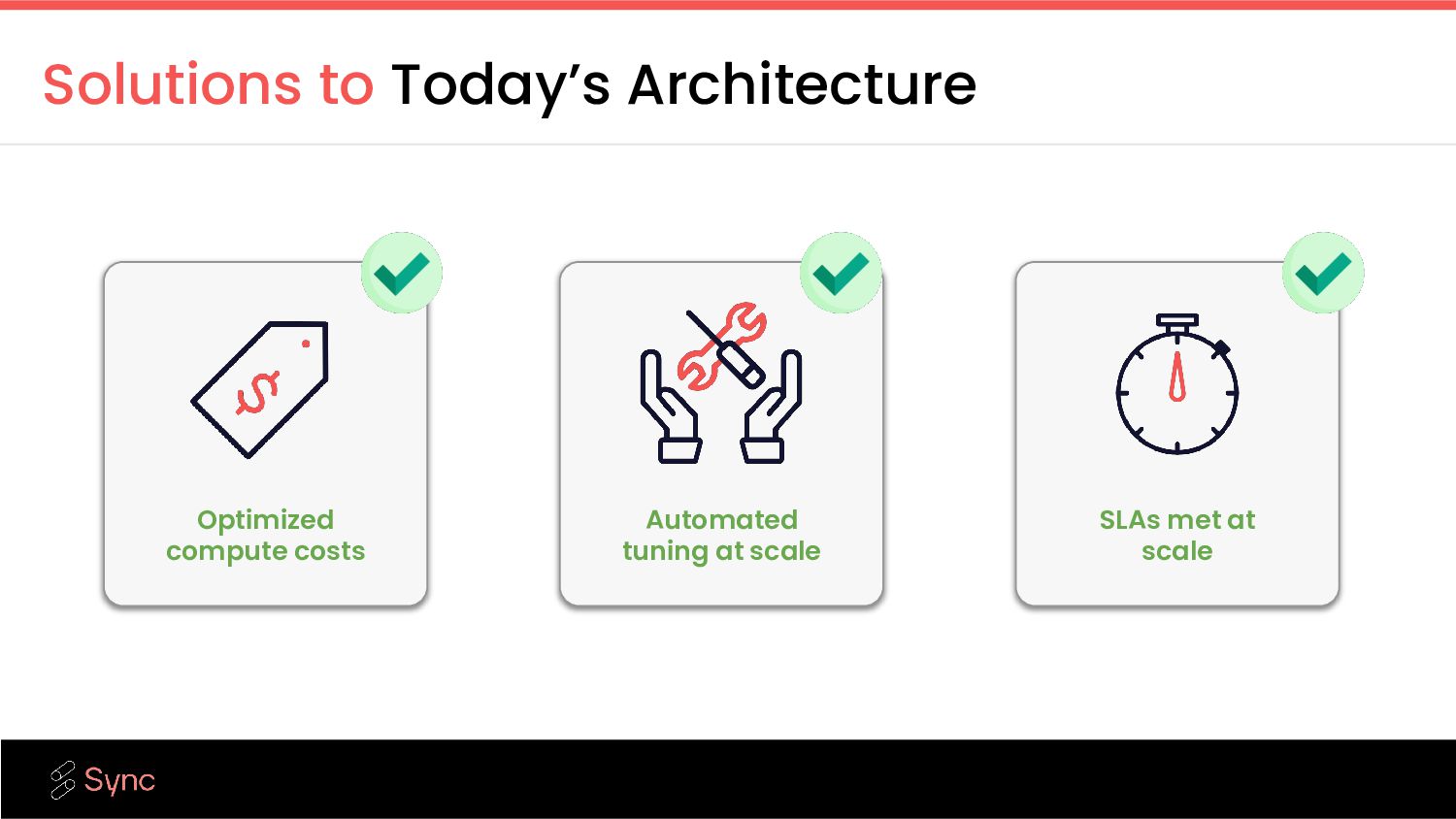
are relying on mission critical pipelines finishing on time- hitting SLA goals is critical Cannot tune at scale Platform teams struggle to meet business demands due to lack the Spark expertise to make changes confidently Customer’s Problems Gradient’s Solutions Visibility to make teams faster Gradient’s insights and visibility helps data engineers quickly diagnose problems and get to solutions faster Free data engineering time With automatic cluster tuning, data teams are free to focus on more business relevant tasks, freeing up precious time Databricks cost are too high Databricks is a high percentage of cloud spend with ample opportunity to save costs Maximize cloud computing performance Gradient’s ML model custom trains and tunes each cluster to reduce costs and improve efficiency
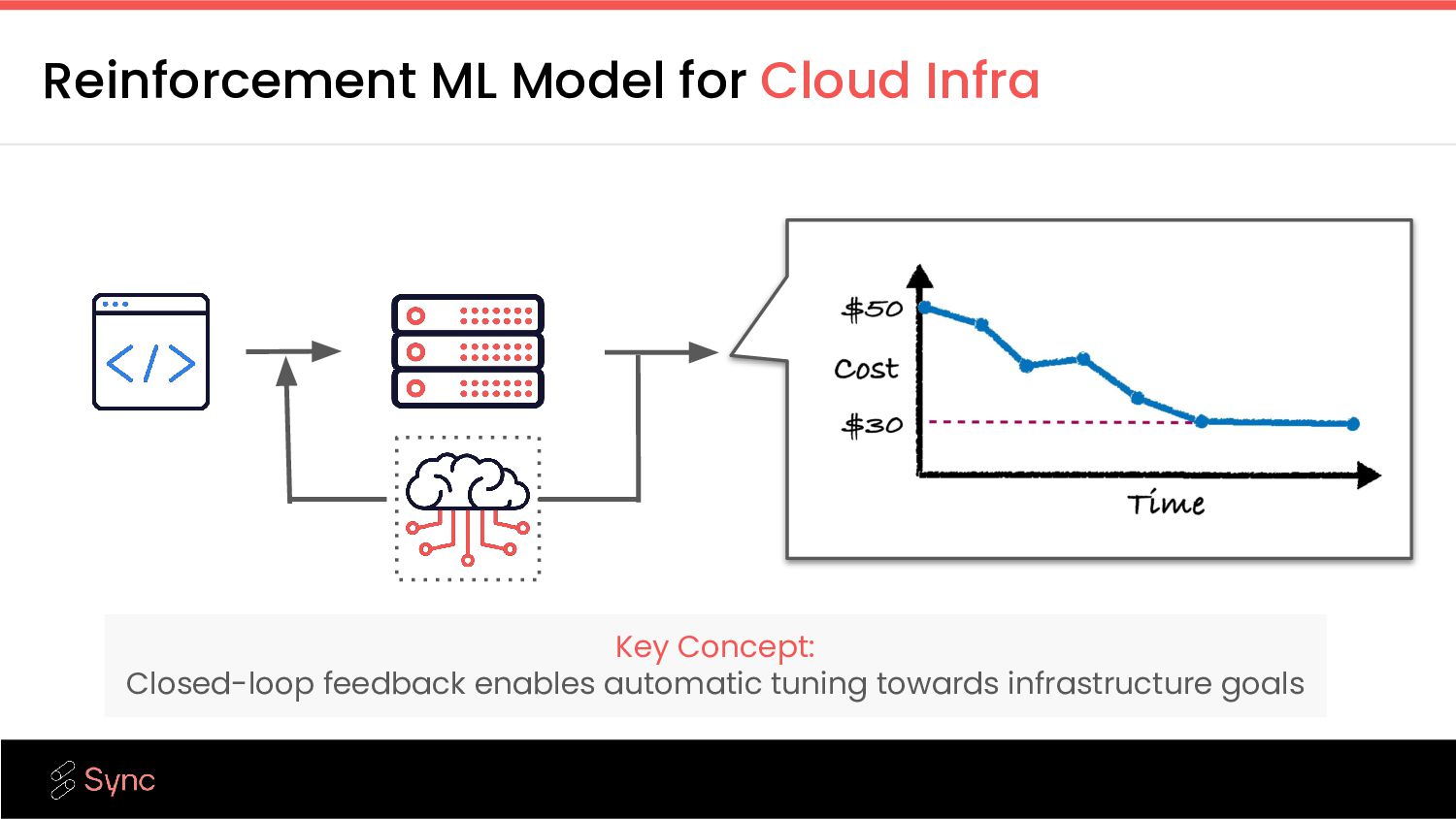
data infrastructure, platform teams struggle to tune clusters to meet business demands due to expertise, or the sheer volume of workloads running (e.g. you cannot manually tune 10K jobs) Alternatives Gradient Opinionated optimization Leverage years of research and millions of DBUs managed that have shaped opinions about the right metrics to monitor and power Gradient’s intelligent insights & custom optimizations. Advanced ML models Gradient’s self-improving ML algorithms were developed at MIT. They use closed-loop feedback to continue to improve Passive recommendations Lists of optimizations that might have an impact, can only take you so far. Active management of data infrastructure Gradient automates compute optimization with ML-powered optimizations, customized per workload
{kind=link}
![[Confidential] 01. 02. 03. 04. Agenda Introduction to Sync What](https://files.speakerdeck.com/presentations/9850f18f4f7843a6a6946773a0aa7f02/slide_1.jpg){kind=link}
![[Confidential] Introduction to Sync Staff & Advisors From Founder’s story:](https://files.speakerdeck.com/presentations/9850f18f4f7843a6a6946773a0aa7f02/slide_2.jpg){kind=link}
{kind=link}
![[Confidential] 01. 02. 03. 04. Agenda Introduction to Sync What](https://files.speakerdeck.com/presentations/9850f18f4f7843a6a6946773a0aa7f02/slide_4.jpg){kind=link}
![[Confidential] The Resource Allocation Problem: Today Cost: $100 Runtime: 1](https://files.speakerdeck.com/presentations/9850f18f4f7843a6a6946773a0aa7f02/slide_5.jpg){kind=link}
{kind=link}
![[Confidential] Declarative Compute Resources Cost: $50 Runtime: 1 hour Latency:](https://files.speakerdeck.com/presentations/9850f18f4f7843a6a6946773a0aa7f02/slide_7.jpg){kind=link}
{kind=link}
![[Confidential] 01. 02. 03. 04. 05. Agenda Introduction to Sync](https://files.speakerdeck.com/presentations/9850f18f4f7843a6a6946773a0aa7f02/slide_9.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![[Confidential] 01. 02. 03. 04. Agenda Introduction to Sync What](https://files.speakerdeck.com/presentations/9850f18f4f7843a6a6946773a0aa7f02/slide_16.jpg){kind=link}
![[Confidential] Databricks is Just The Start](https://files.speakerdeck.com/presentations/9850f18f4f7843a6a6946773a0aa7f02/slide_17.jpg){kind=link}
{kind=link}
{kind=link}