Chun-Fu Kuo Advisor: Jung-Chun Kao Date : 2021/07/28 1 Department of Computer Science, National Tsing Hua University, Hsinchu, Taiwan Communications and Networking Lab, NTHU
for performance prediction o Operators: how many servers should I have? o Vendors: how is the performance regarding my NF in different servers? o Consideration o The throughput of NFs varies from different CPU, NIC, RAM, etc. o The growth of throughput against the CPU usage is not linear o Contention happens in cache, memory, NIC o CPU manufactories have their own proprietary techniques which are not presented in white paper o Objective: o Given packet arrival rate, predict the CPU usage
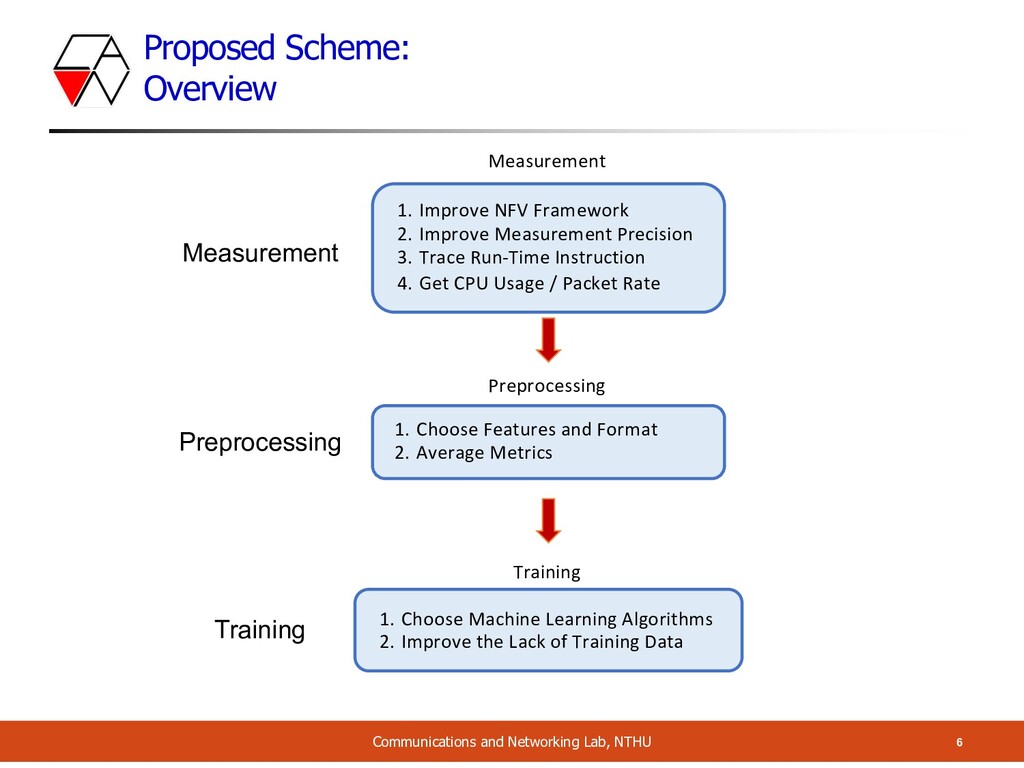
Preprocessing Training 1. Improve NFV Framework 2. Improve Measurement Precision 3. Trace Run-Time Instruction 4. Get CPU Usage / Packet Rate Measurement Preprocessing 1. Choose Features and Format 2. Average Metrics 1. Choose Machine Learning Algorithms 2. Improve the Lack of Training Data Training
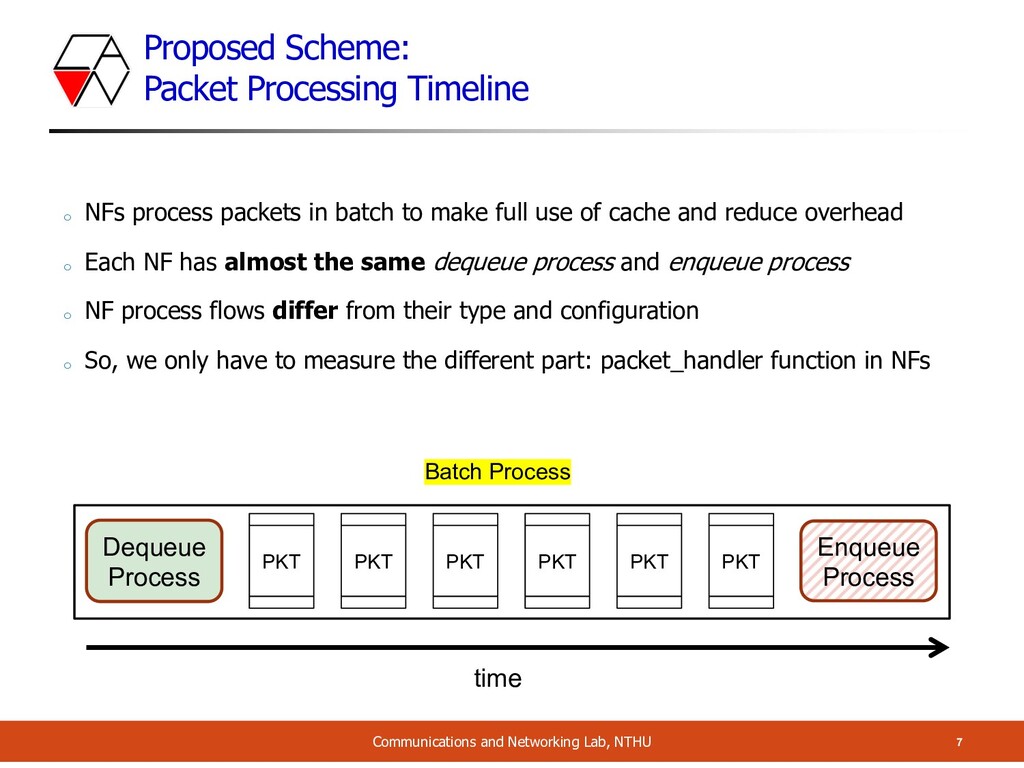
NTHU Batch Process Dequeue Process Enqueue Process PKT PKT PKT PKT PKT PKT time o NFs process packets in batch to make full use of cache and reduce overhead o Each NF has almost the same dequeue process and enqueue process o NF process flows differ from their type and configuration o So, we only have to measure the different part: packet_handler function in NFs
o The performance (CPU usage) of NF depends on o Packet arrival rate o Executed instructions o Accessed memory size o Use DynamoRIO to measure instructions and memory in run time o A instrumentation tool developed by HP Labs & MIT o Free and open source o Cross architecture: IA-32, AMD64, ARM, AArch64 o Cross platform: Linux, Windows, macOS
Average the CPU usage and packet rate o Since we sample 5 seconds CPU usage NF status o Combine instructions and memory record to pairs o The instructions with different memory access size are considered as different features o Such as: 𝑚𝑜𝑣_2, 𝑚𝑜𝑣_6, 𝑎𝑑𝑑_4 o We give them with notation “𝑜𝑝𝑒𝑟𝑎𝑡𝑖𝑜𝑛” or “𝑜𝑝”
Take 4 machine learning methods for comparison o Linear Regression o Decision Tree o AdaBoost o Gradient Boosting o Training data format o x = [𝑝𝑘𝑡_𝑟𝑎𝑡𝑒, # of 𝑜𝑝_1, # of 𝑜𝑝_2, ..., # of 𝑜𝑝_𝑛] o y = [𝑐𝑝𝑢_𝑢𝑠𝑎𝑔𝑒] x = [4230000, 5, 3, 2] y = [65] 𝑎𝑑𝑑_4 𝑚𝑜𝑣_2 𝑚𝑜𝑣_6 𝑝𝑘𝑡_𝑟𝑎𝑡𝑒
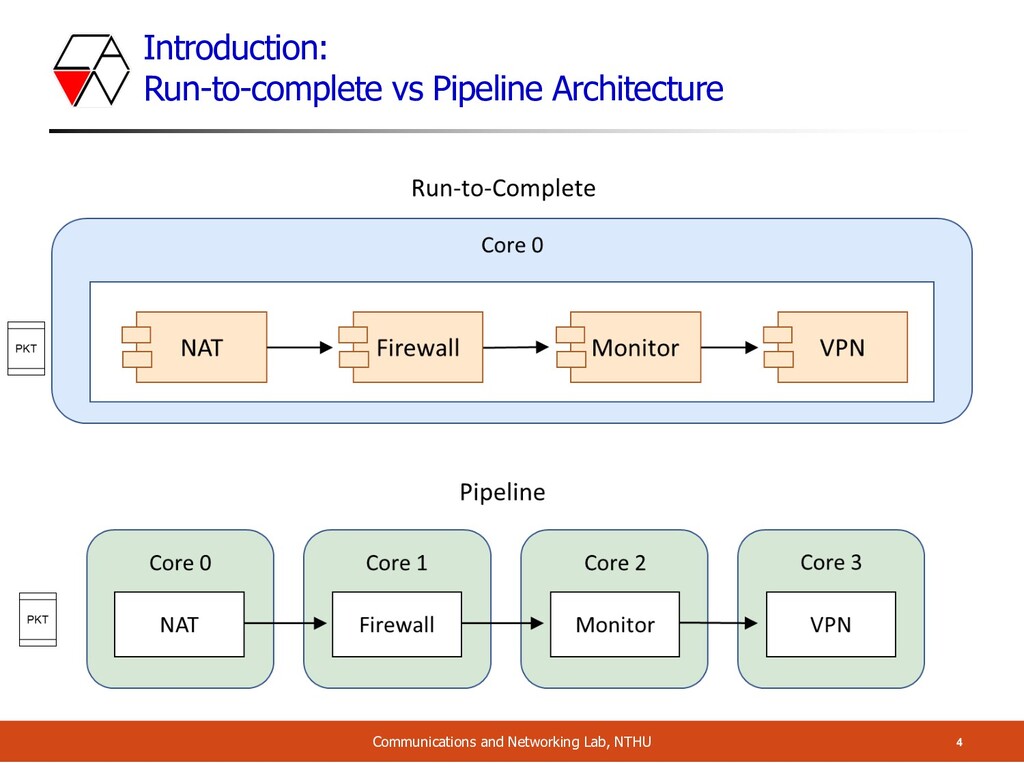
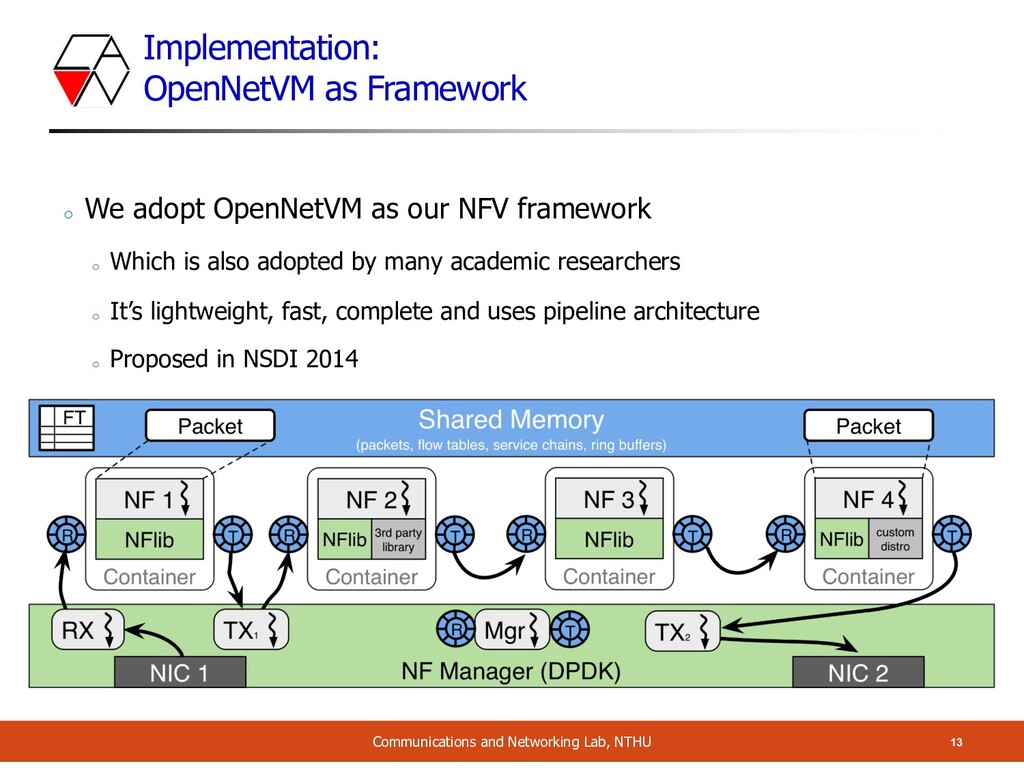
o We adopt OpenNetVM as our NFV framework o Which is also adopted by many academic researchers o It’s lightweight, fast, complete and uses pipeline architecture o Proposed in NSDI 2014
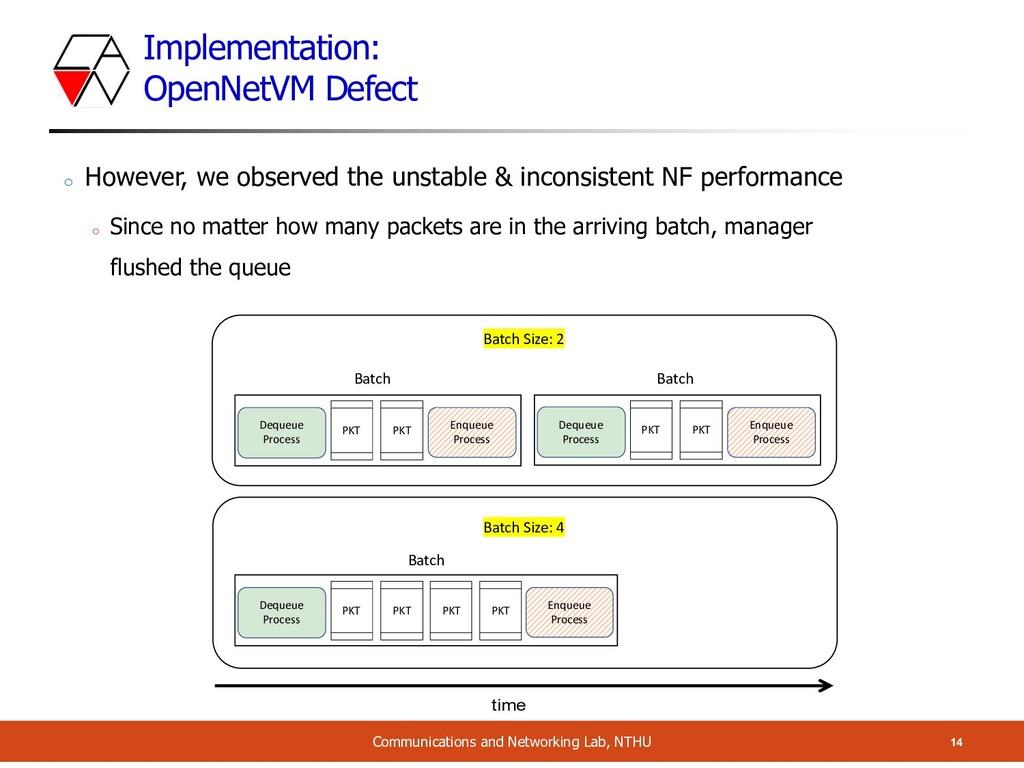
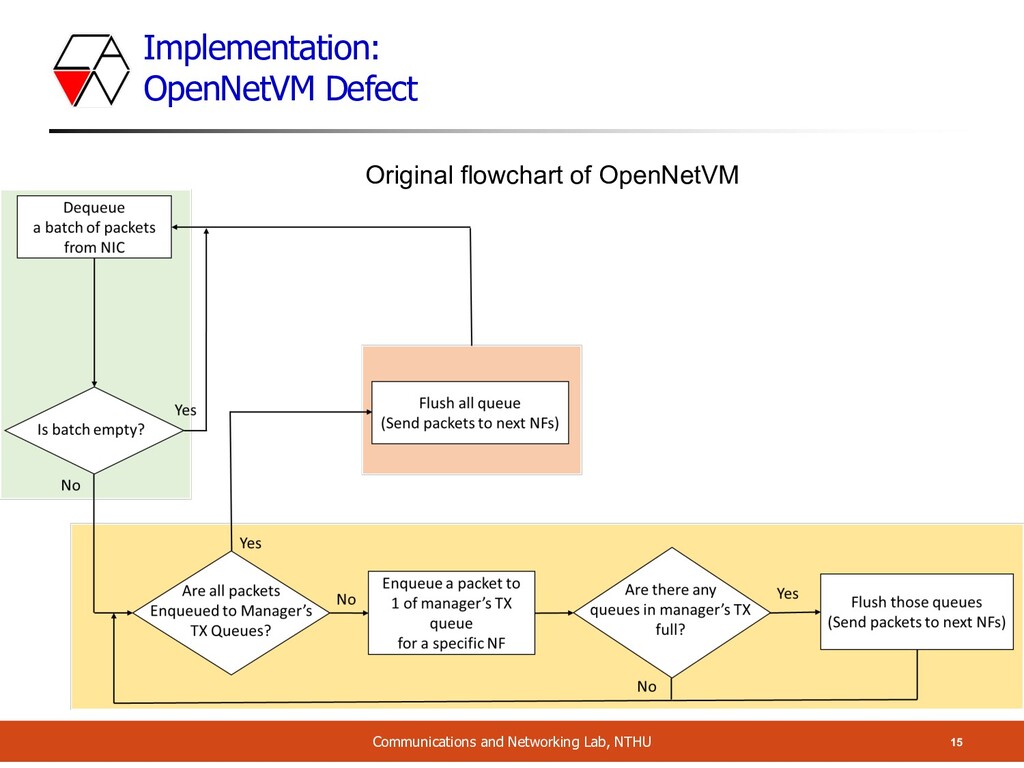
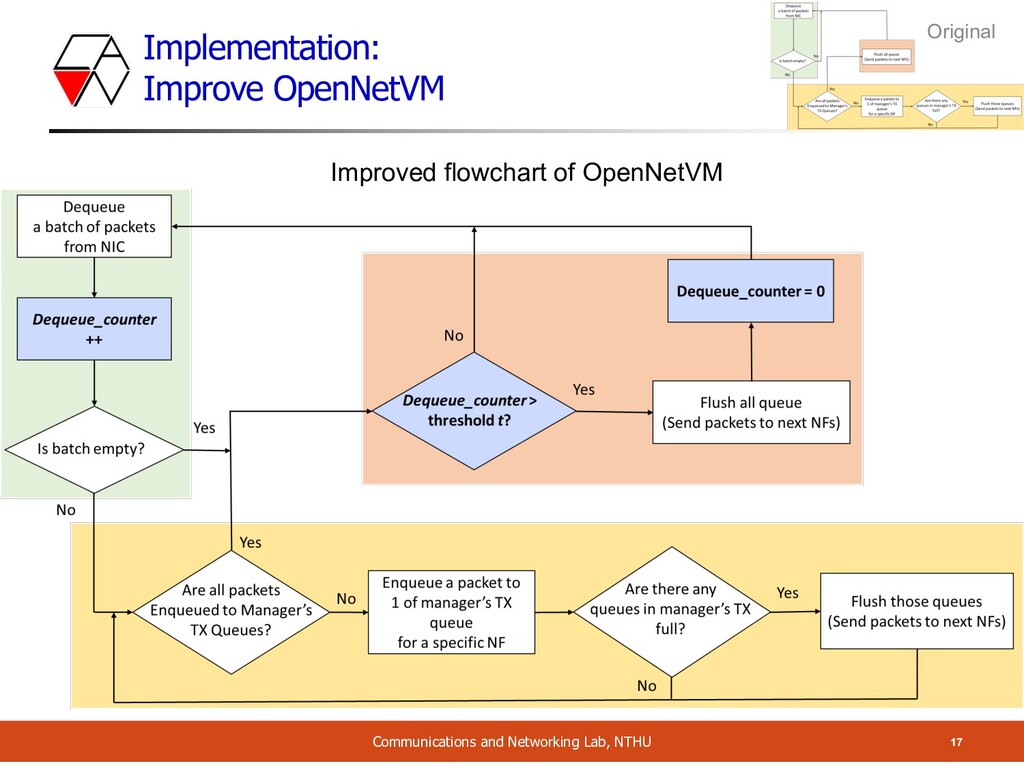
However, we observed the unstable & inconsistent NF performance o Since no matter how many packets are in the arriving batch, manager flushed the queue Batch Size: 2 Batch Dequeue Process Enqueue Process PKT PKT Dequeue Process Enqueue Process PKT PKT Batch Batch Size: 4 Batch Dequeue Process Enqueue Process PKT PKT PKT PKT time
We propose a workaround which leverages the input packet rate: o Slow packet input rate ⇨ fast counter increment rate o Fast packet input rate ⇨ slow counter increment rate o It makes sure the batch is as full as possible o The increased latency impact for every packet is < 0.01 ms when threshold is 1000 o Performance improvement ~ 20%
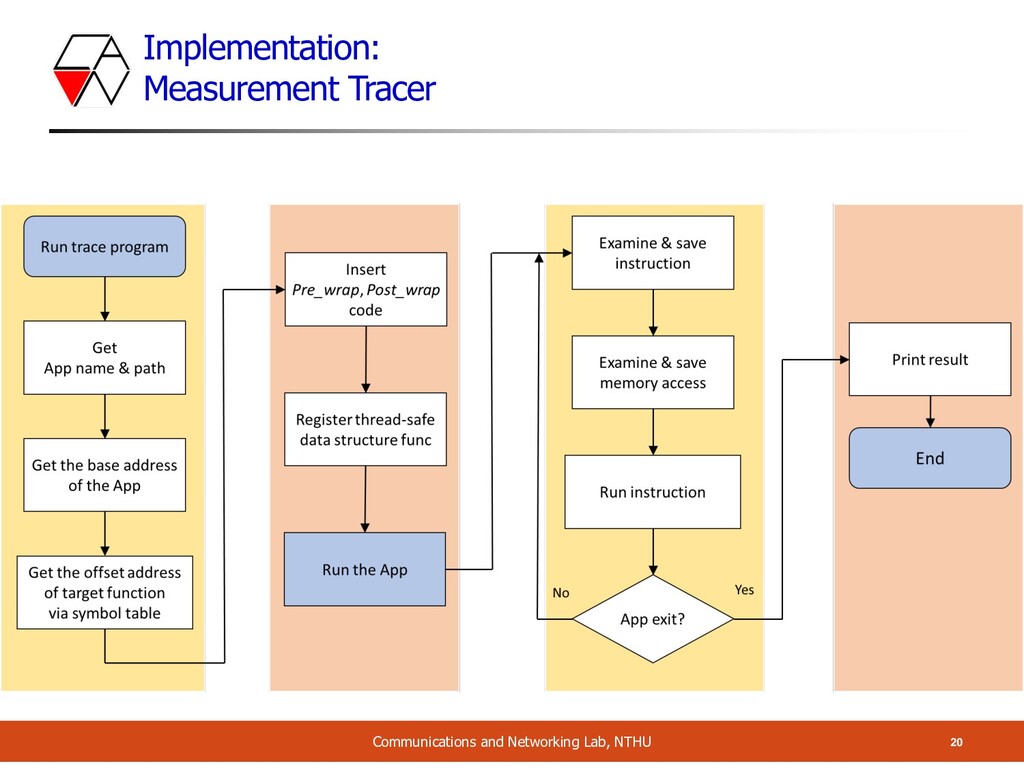
We trace the packet_handler function during NF run time o Exports the executed instruction & memory access for each thread separately o Use DynamoRIO library o Works in AMD64, AArch64 Linux o Can trace almost every executable o About 650 lines of code (LoC) in C
NTHU o To address the lack of training data o Add redundant code to NFs with several 𝑏𝑢𝑠𝑦_𝑡𝑖𝑚𝑒 o It increases the variety of NF o We apply it to Firewall & Forwarder
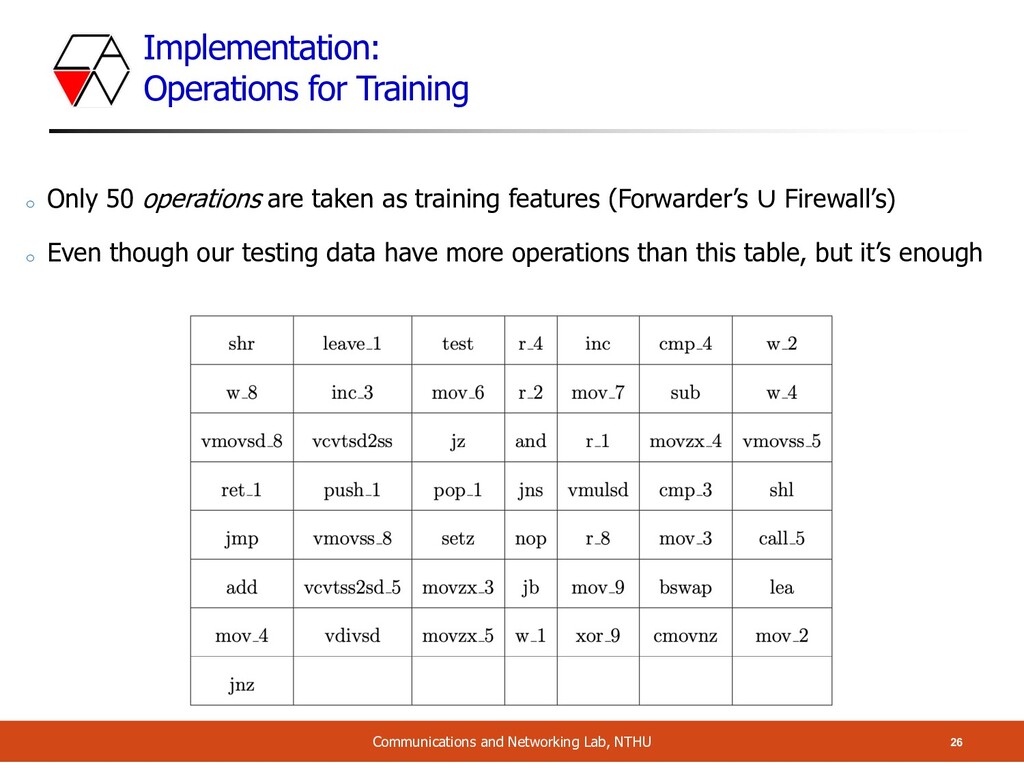
o Only 50 operations are taken as training features (Forwarder’s ∪ Firewall’s) o Even though our testing data have more operations than this table, but it’s enough
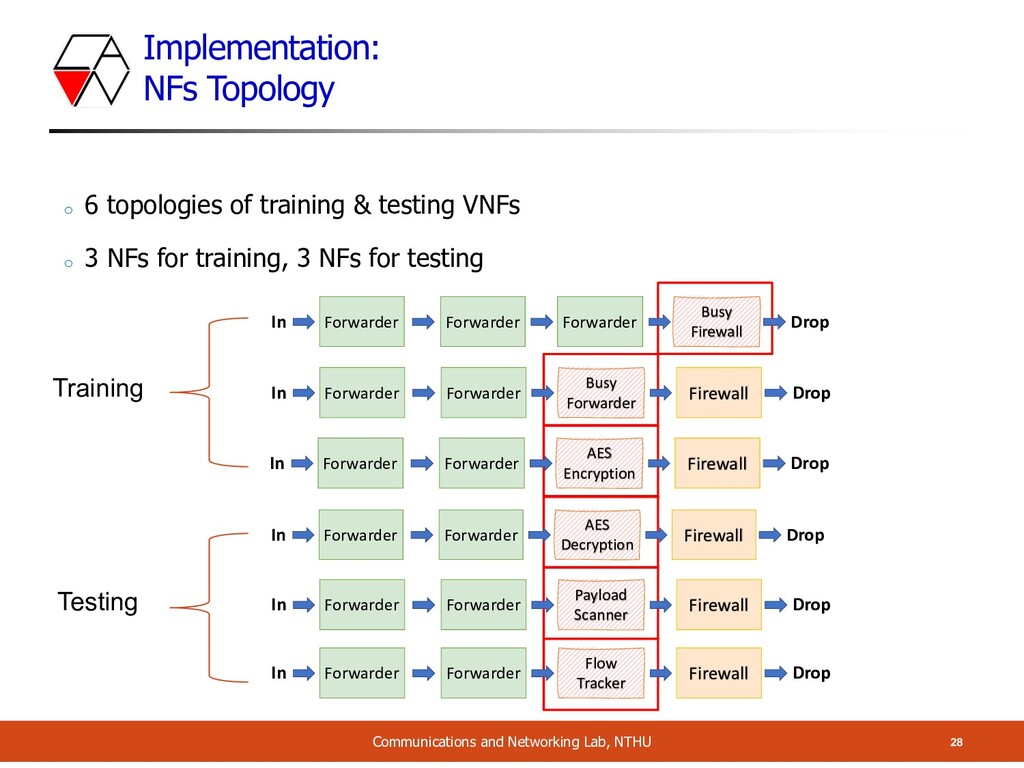
6 topologies of training & testing VNFs o 3 NFs for training, 3 NFs for testing Training Testing In Forwarder Firewall Forwarder Busy Forwarder Drop In Forwarder Firewall Forwarder AES Encryption Drop In Forwarder Firewall Forwarder AES Decryption Drop In Forwarder Firewall Forwarder Payload Scanner Drop In Forwarder Forwarder Busy Firewall Drop Forwarder In Forwarder Firewall Forwarder Flow Tracker Drop
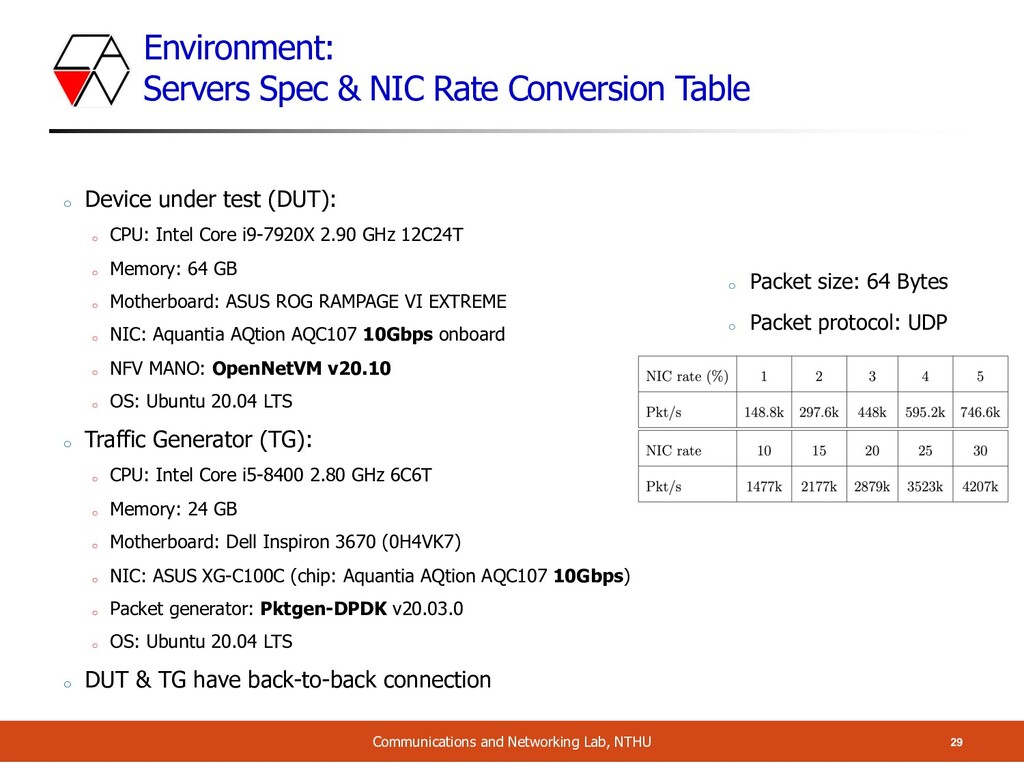
and Networking Lab, NTHU o Device under test (DUT): o CPU: Intel Core i9-7920X 2.90 GHz 12C24T o Memory: 64 GB o Motherboard: ASUS ROG RAMPAGE VI EXTREME o NIC: Aquantia AQtion AQC107 10Gbps onboard o NFV MANO: OpenNetVM v20.10 o OS: Ubuntu 20.04 LTS o Traffic Generator (TG): o CPU: Intel Core i5-8400 2.80 GHz 6C6T o Memory: 24 GB o Motherboard: Dell Inspiron 3670 (0H4VK7) o NIC: ASUS XG-C100C (chip: Aquantia AQtion AQC107 10Gbps) o Packet generator: Pktgen-DPDK v20.03.0 o OS: Ubuntu 20.04 LTS o DUT & TG have back-to-back connection o Packet size: 64 Bytes o Packet protocol: UDP
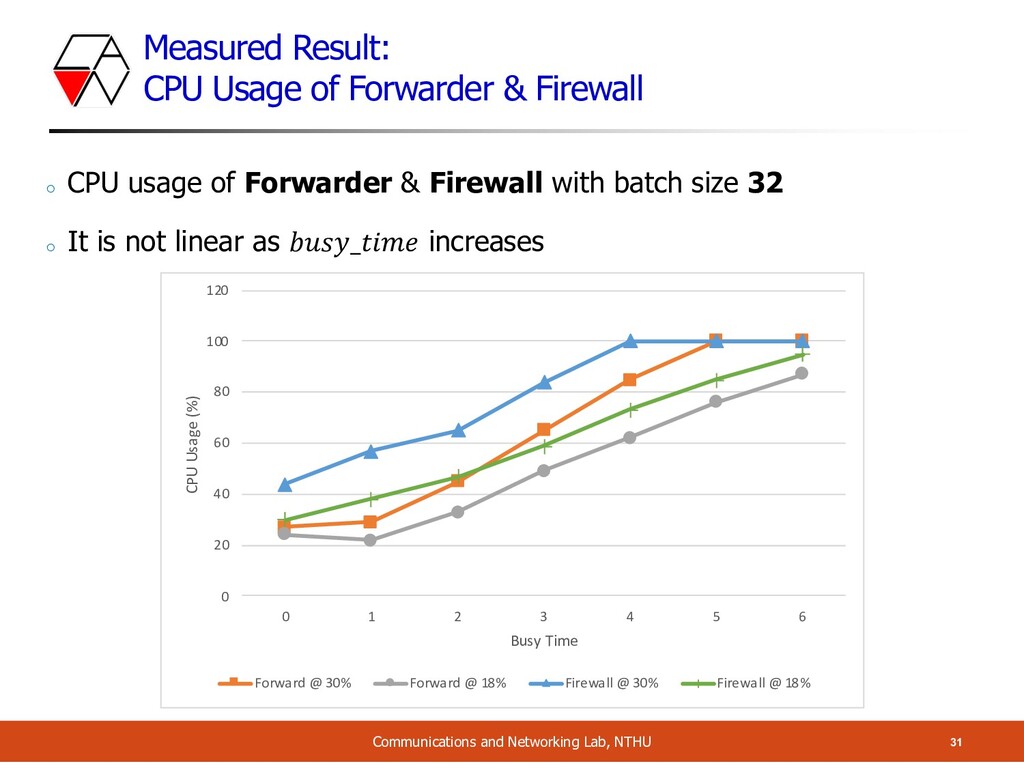
and Networking Lab, NTHU o CPU usage of Forwarder & Firewall with batch size 32 o It is not linear as 𝑏𝑢𝑠𝑦_𝑡𝑖𝑚𝑒 increases 0 20 40 60 80 100 120 0 1 2 3 4 5 6 CPU Usage (%) Busy Time Forward @ 30% Forward @ 18% Firewall @ 30% Firewall @ 18%
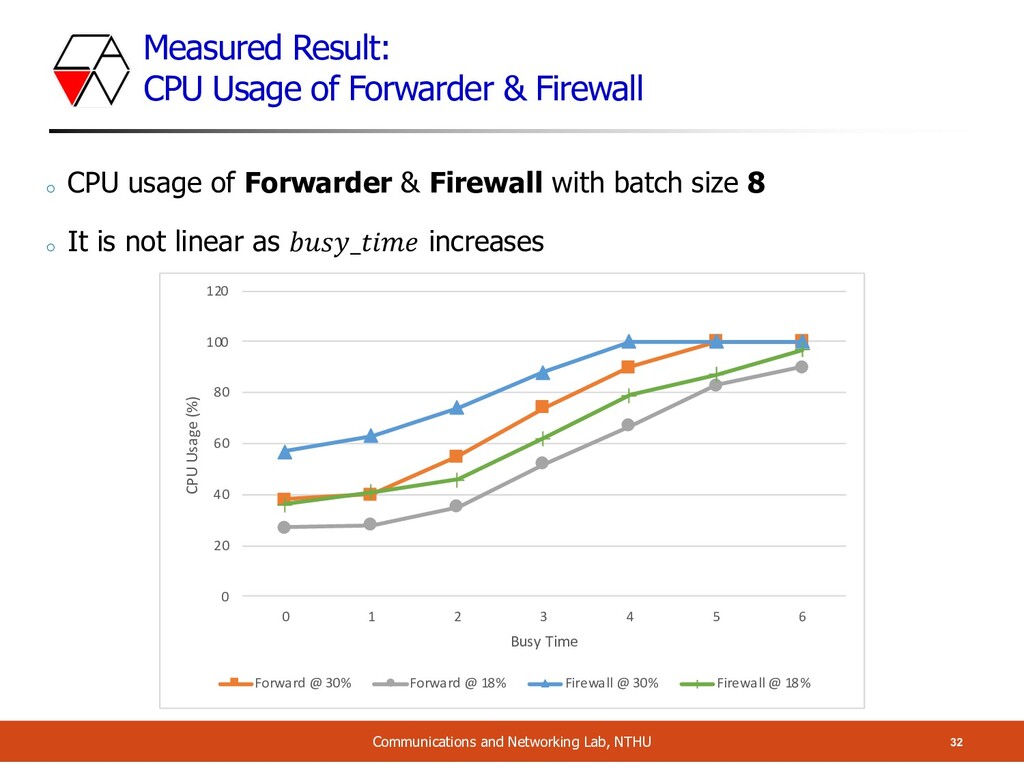
and Networking Lab, NTHU o CPU usage of Forwarder & Firewall with batch size 8 o It is not linear as 𝑏𝑢𝑠𝑦_𝑡𝑖𝑚𝑒 increases 0 20 40 60 80 100 120 0 1 2 3 4 5 6 CPU Usage (%) Busy Time Forward @ 30% Forward @ 18% Firewall @ 30% Firewall @ 18%
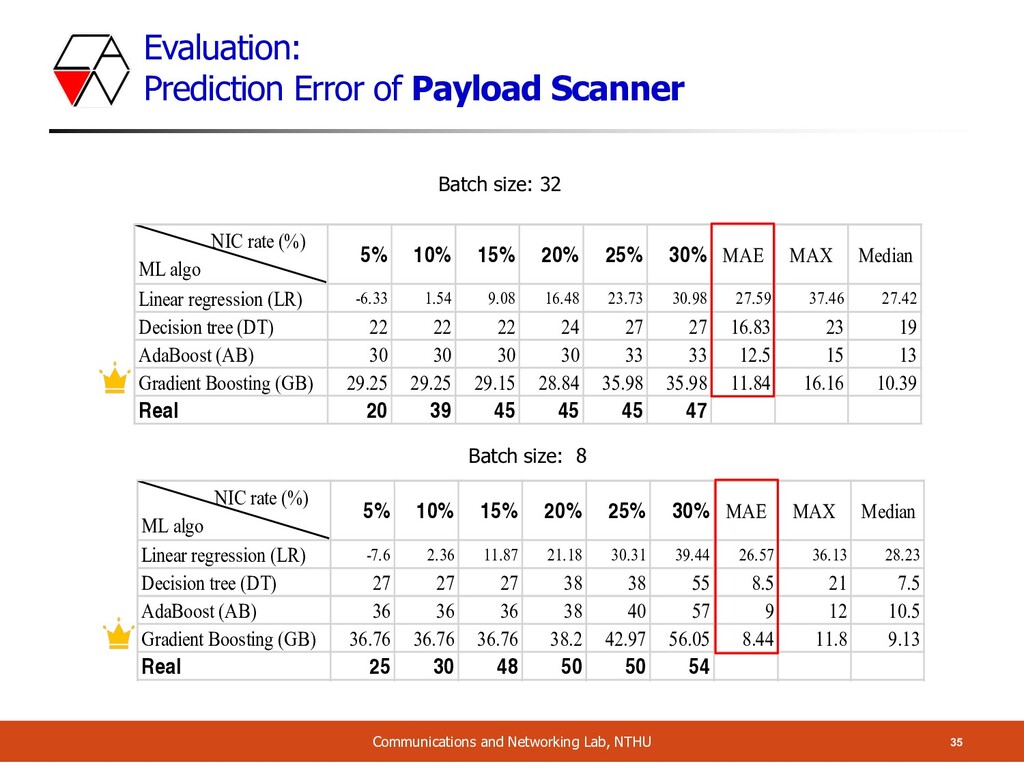
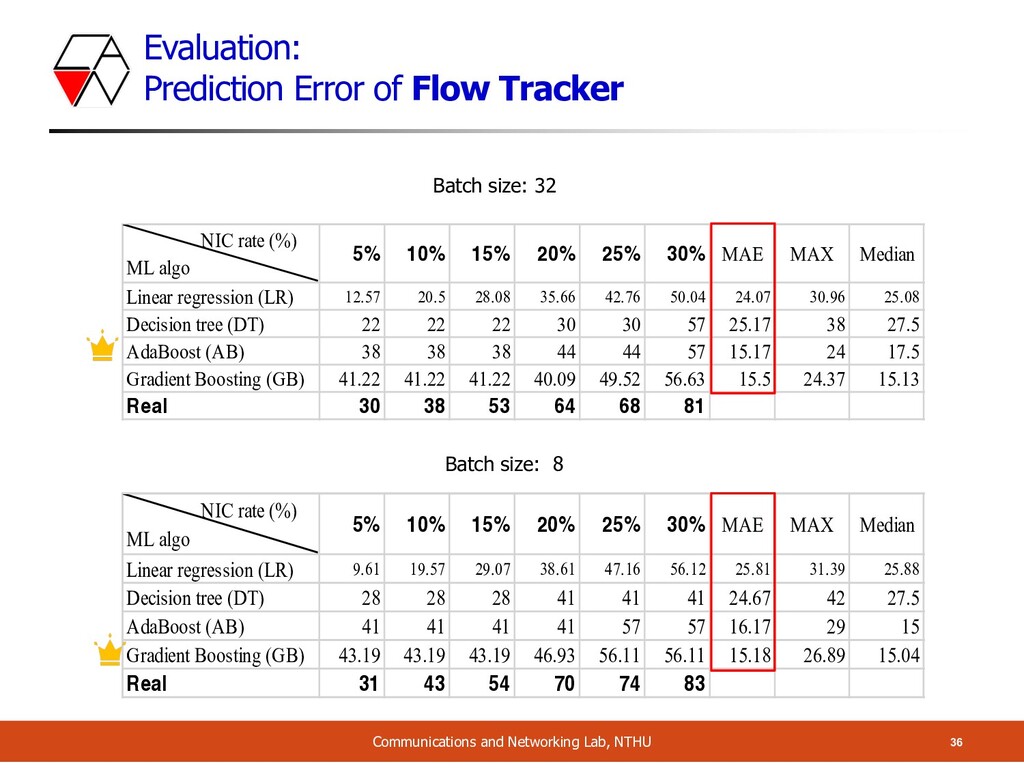
Given throughput (packet per second), predict the CPU usage o Proposed scheme: o Measure the instruction of critical function of NF o Then use machine learning methods to predict CPU usage o Prediction result: o If there exists similar NF in training data, prediction is pretty accurate o Even though the NFs have never been trained, MAEs are all < 16
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}