• Is used to invoke a program with a particular CPU priority • Show niceness value in `top` command • Range from -20 (highest priority) to 19 (lowest priority) • Priority (share of the CPU time): 20 − • Max priority ratio: !" # #!" !" #$% = 40
Range from -100 (highest priority) to 40 (lowest priority) • Calculation • Normal process: PR = 20 + NI (ranges from -20 to 19) • Real time process: PR = -1 - real_time_priority (ranges from 1 to 99) • RT means PR = -100
A CPU subsystem of cgroups • A relative amount of CPU time for task to run CPU Quota • A CPU subsystem of cgroups • To enforce a hard limit to the CPU time allocated to processes CPUSET • A CPU subsystem of cgroups • Limit the specific CPUs or cores can use
CFS • A default scheduler since Linux 2.6.23 • Implemented by red-black tree • Based on process’s cumulative run-time • Timeslice is not fixed • CFS batch • Similar to CFS • Longer time quantum (fewer context switch) • Round robin • Cycle through each process • Default 100ms in this paper’s evaluation
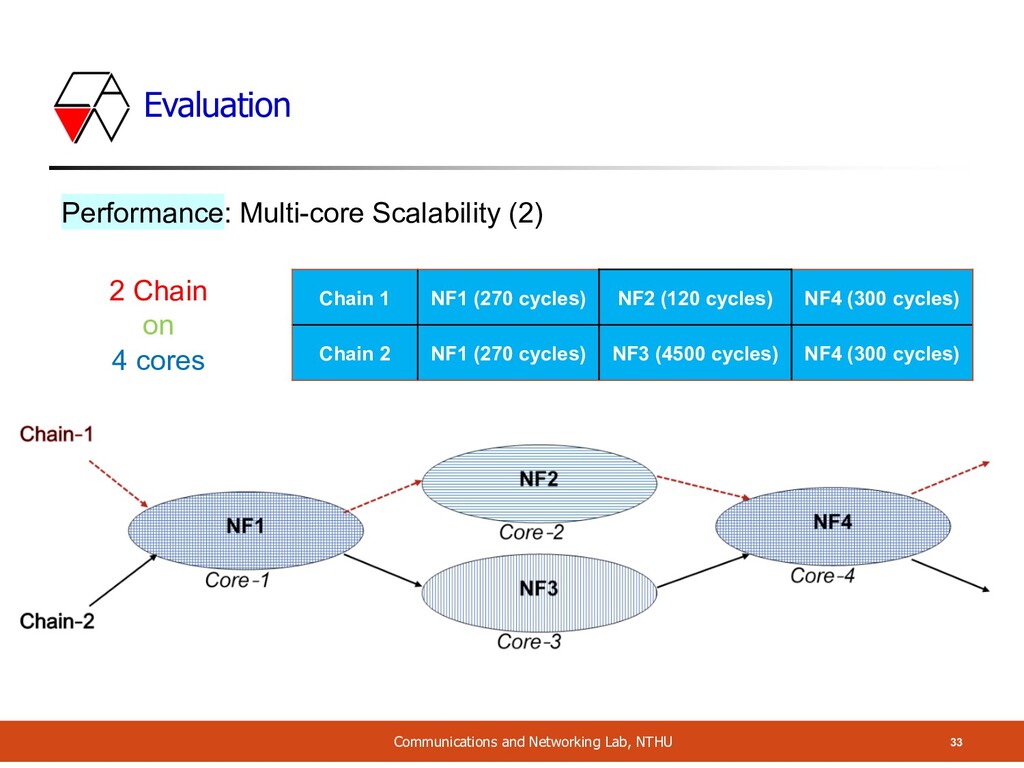
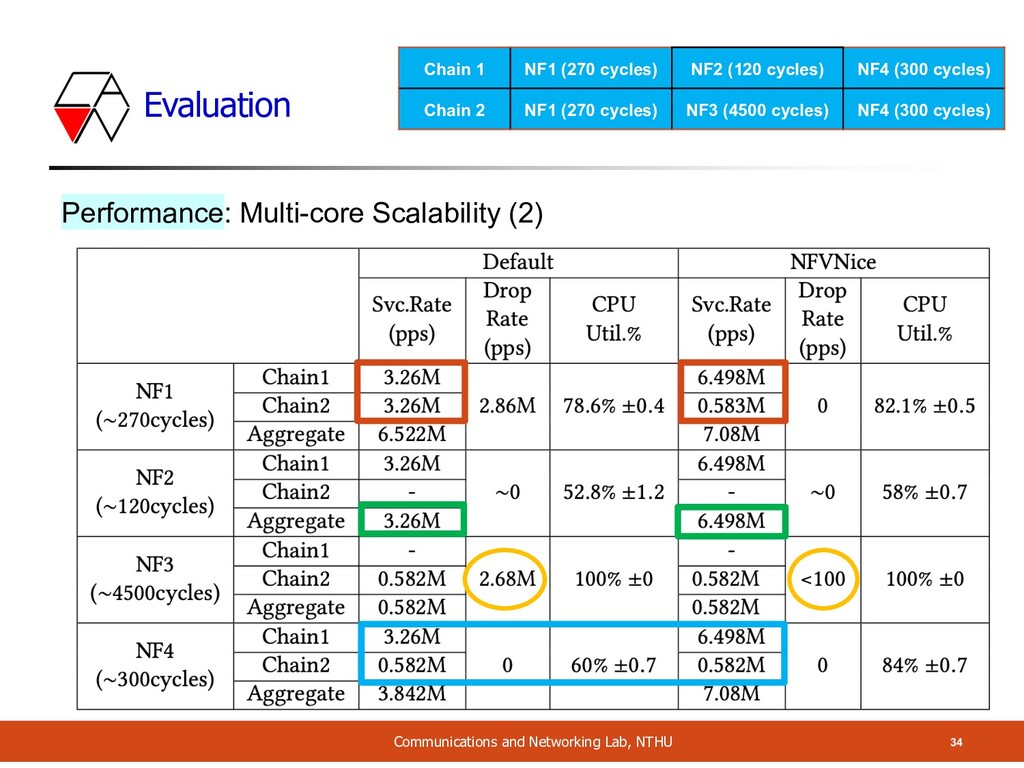
should be equal for 2 VNF chain if arrival rate are equal • Even if chain A has 2x processing cost to chain B • Current Linux CFS cannot achieve it • It doesn’t know the state of each NFs • Unfair scheduling causes processing waste (drop too late) 30 Mbps 20 Mbps 40 Mbps Drop: 10 Mbps 30 Mbps 30 Mbps 20 Mbps
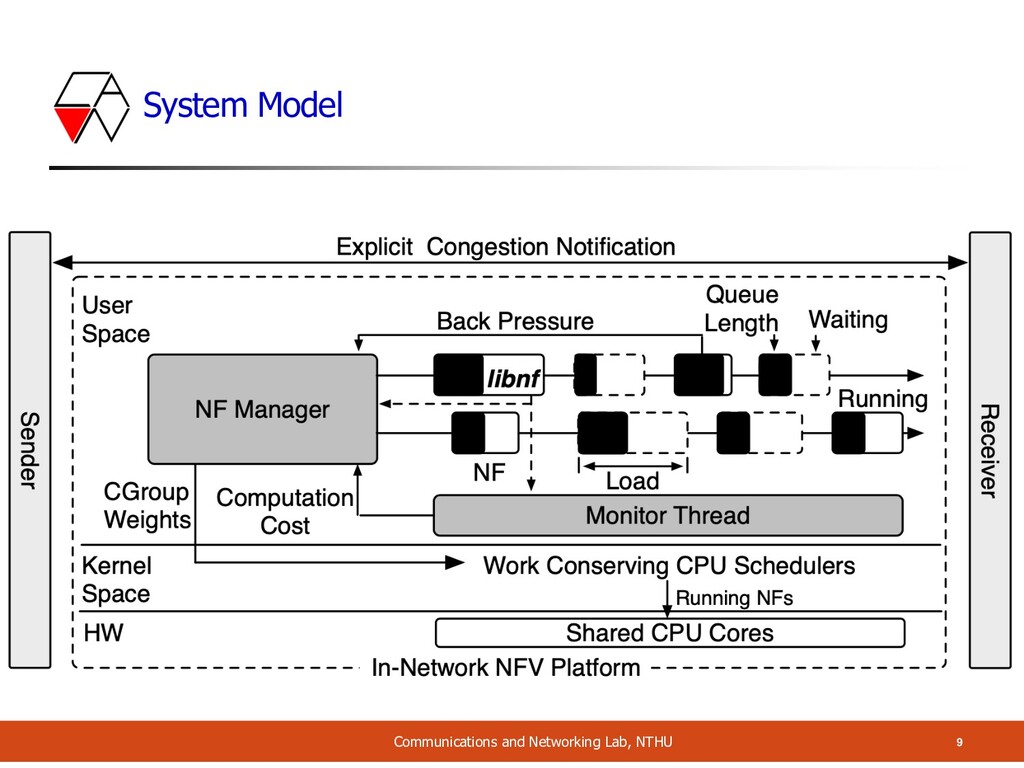
• User space’s NF scheduler • Service chain management framework • Scheduler-agnostic • Features • Base on arrival rate, processing cost: auto tuning CPU parameters • Service chain level backpressure (congestion control)
can • Monitor average computation time of NFs per packet • Monitor queue size of NF • Monitor I/O activities • NF state in chain (overloaded, block on I/O) • Libnf • A library support this framework • Can • Efficient reading/writing packets • Overlapping processing with non-blocking async I/O • Schedule/deschedule NFs
Activating NFs • Why • NF is always busy wait (poll mode) • Waste CPU • Previous work • ClickOS, netmap • But both of them are too simple, only on and off • In NFVnice • NFs sleep by blocking on a semaphore (share with NF Manager) • According to NF queue, downstream’s queue • So, no need to provide information to OS scheduler
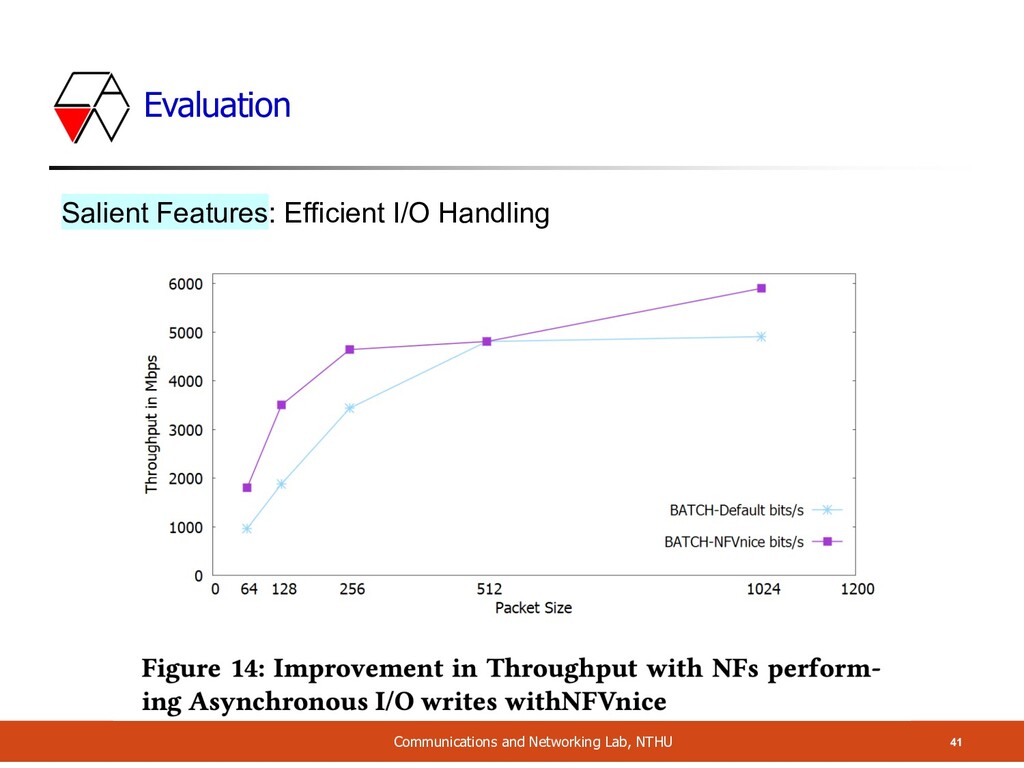
Relinquishing the CPU • Whether to process next batch of packet • NF calls libnf for decision • Libnf checks the flag set in shared memory by NF manager • If true: block on the semaphore until notified by the manager • This provides a flexible way to ask NF to give up CPU
CPU Scheduler • Multiple NF processes are likely to be runnable • Scheduler has to: • Determine which process to run, for how long • But the cost of sync information to kernel is high • NFVnice carefully: • Control NFs (including yield) • CFS batch is good: • Long running time • Less frequent preemption
Assigning CPU Weight • NFVnice estimates the requirement of CPU in real time • To avoid outliers from skewing these measurement: • A histogram of timings is maintained • For each NF on shared core : • = ∑& '($ () • = ' ∗ ' • : arrival rate • : service time • ℎ' = ' ∗ )*+,(') /*0+)1*+,(2)
Pressure • When NF Manager’s TX thread detect: 1. Receive queue length for an NF > HIGH_WATER_MARK 2. Queuing time > threshold • Then • Determine which flows are with whole packet of that queue • Drop at the upstream NFs • When • Queue length < LOW_WATER_MARK • Enable flows at the upstream
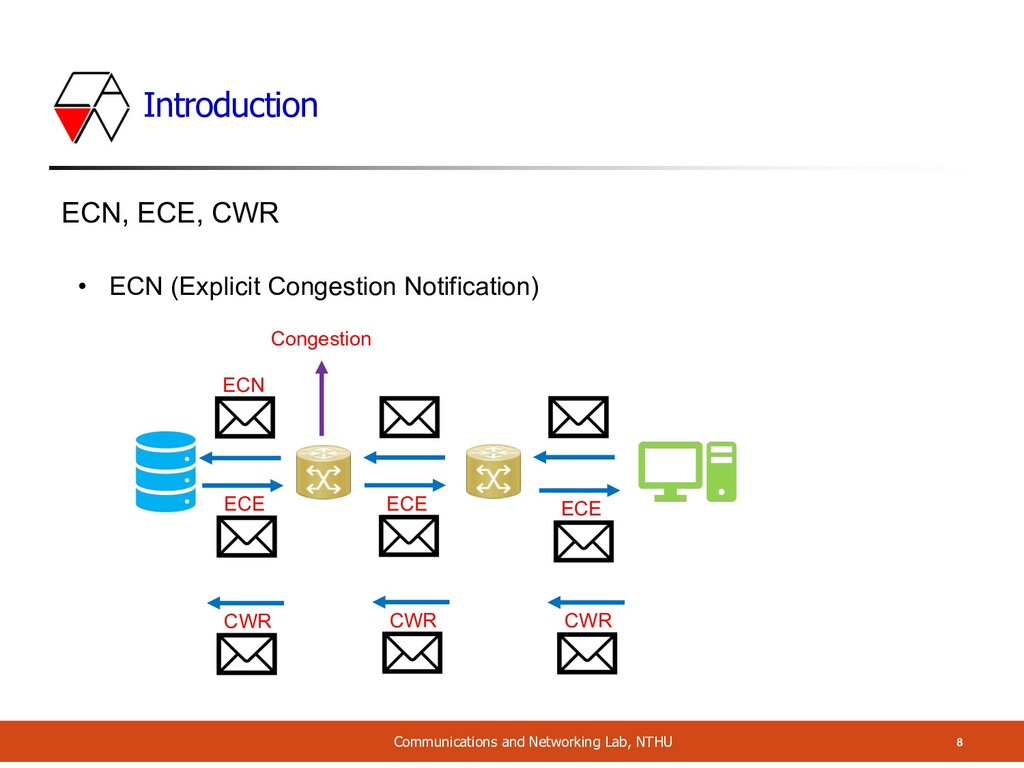
Optimization and ECN • NFVnice provides simple local backpressure • When output TX queue becomes full à block • Use case: • Downstream NFs are slow • NF Manager TX thread is overloaded • NF-driven, not via Manager • Mark ECN bit in TCP flow • Facilitate end-to-end management
Overload Detection and Control • Due to NFV platform process millions of packets per second • Separate out overload detection from the control mechanism • NF Manager’s TX thread enqueues a packet to NF’s RX queue • Only when the queue is < HIGH_WATER_MARK • Get return value about state of the queue (write to NF’s meta data) • NF Manager’s Wakeup thread • Scan all NFs and classify them into 2 categories: 1. Backpressure should apply 2. Need to be woken up • Provide some hysteresis control
Load Estimation and CPU Allocation • It’s critical that modifying `sysfs` (cgroup) should be done outside of the packet processing data path • Data plane (libnf) samples the packet processing time per 1ms (lightweight) • Observe the CPU cycle counter before & after the NF’s packet handler function • Store in a histogram in shared memory • NF Manager allots CPU shares • Use the median over 100ms moving window • Update the weight every 10ms
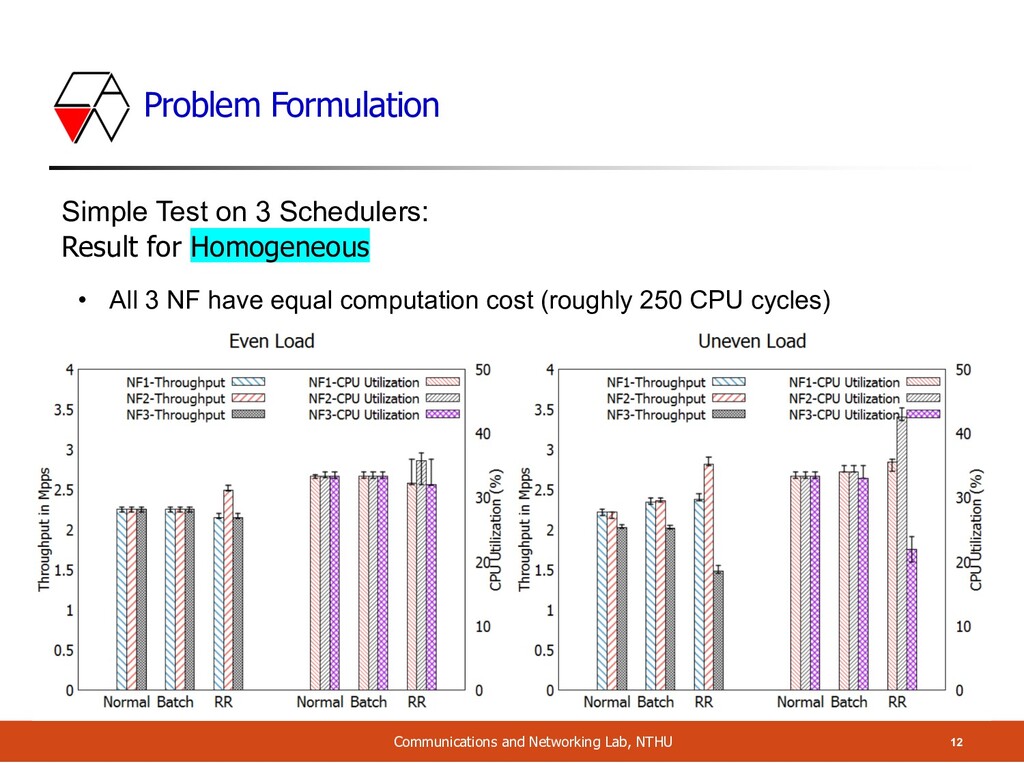
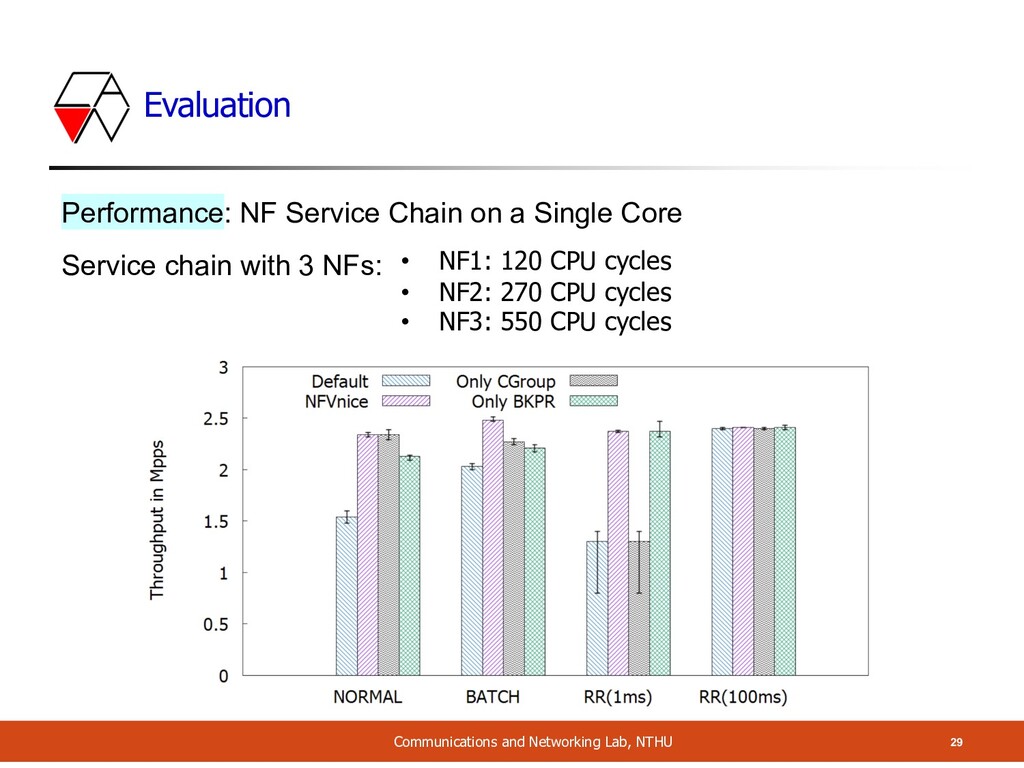
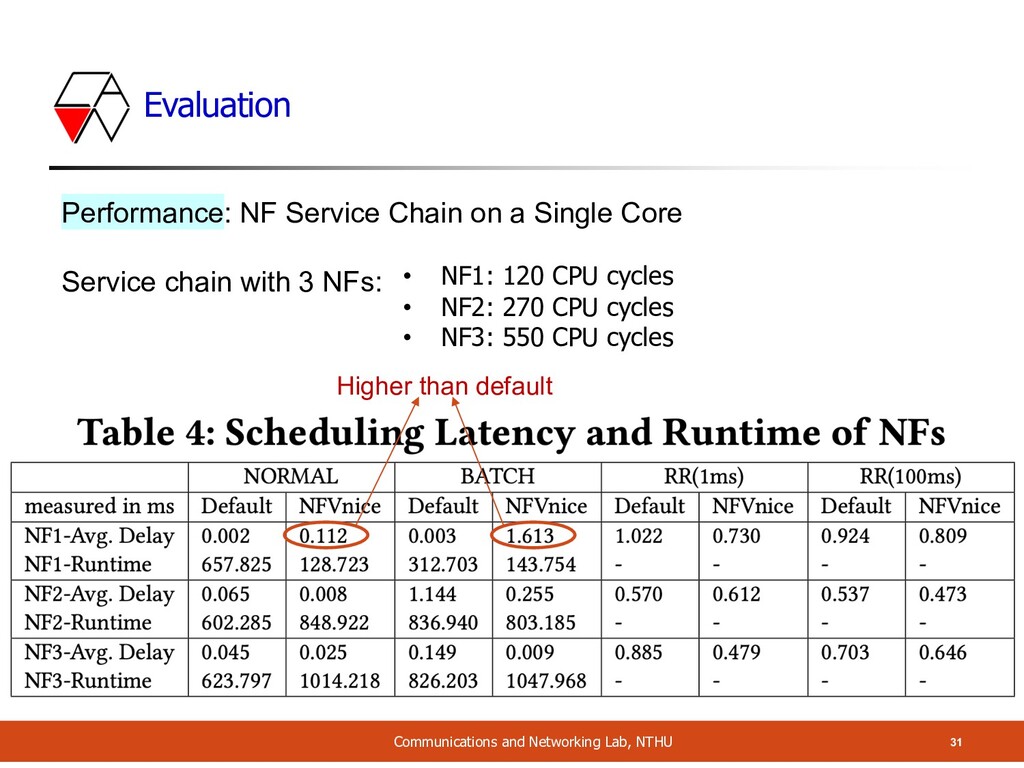
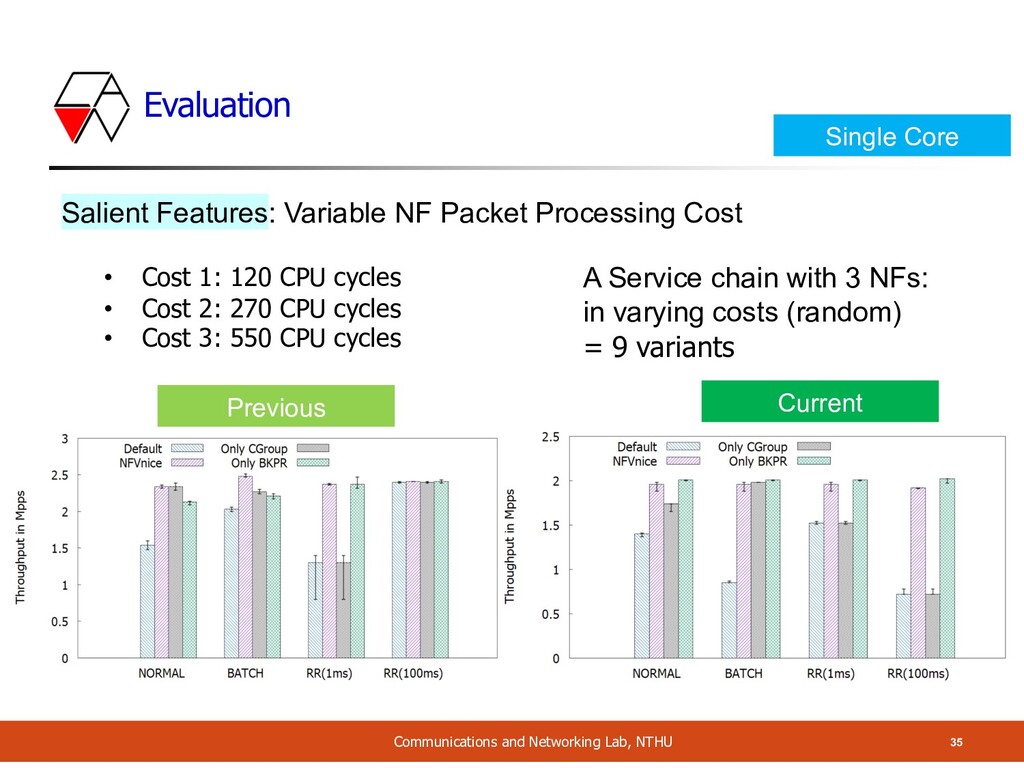
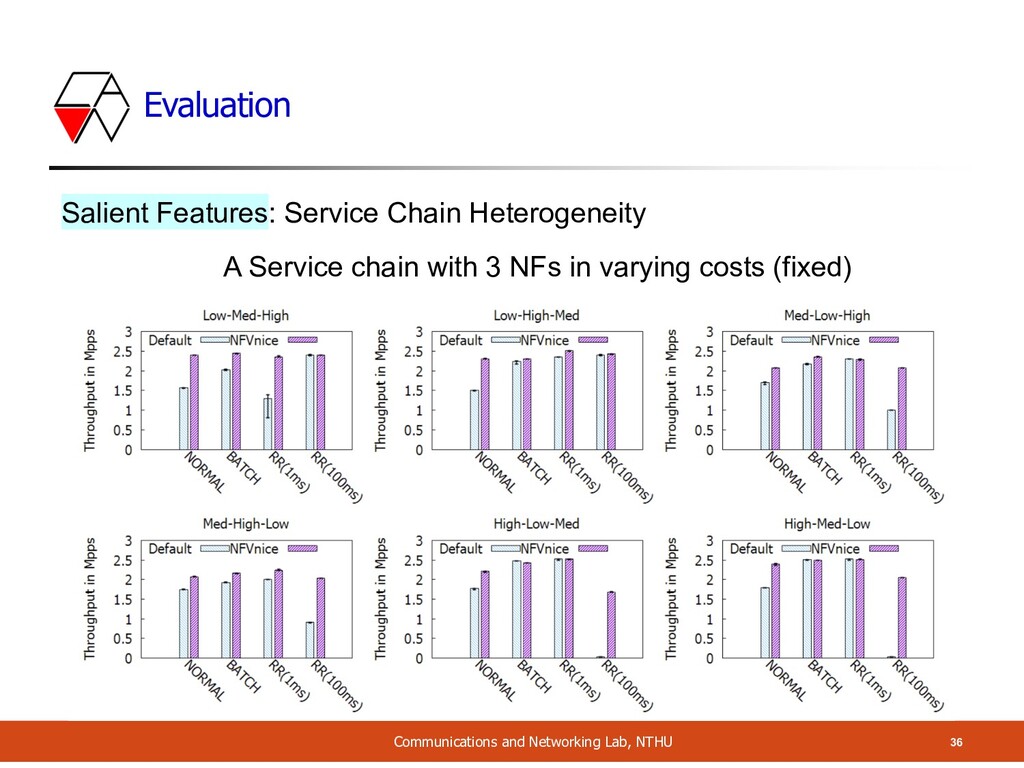
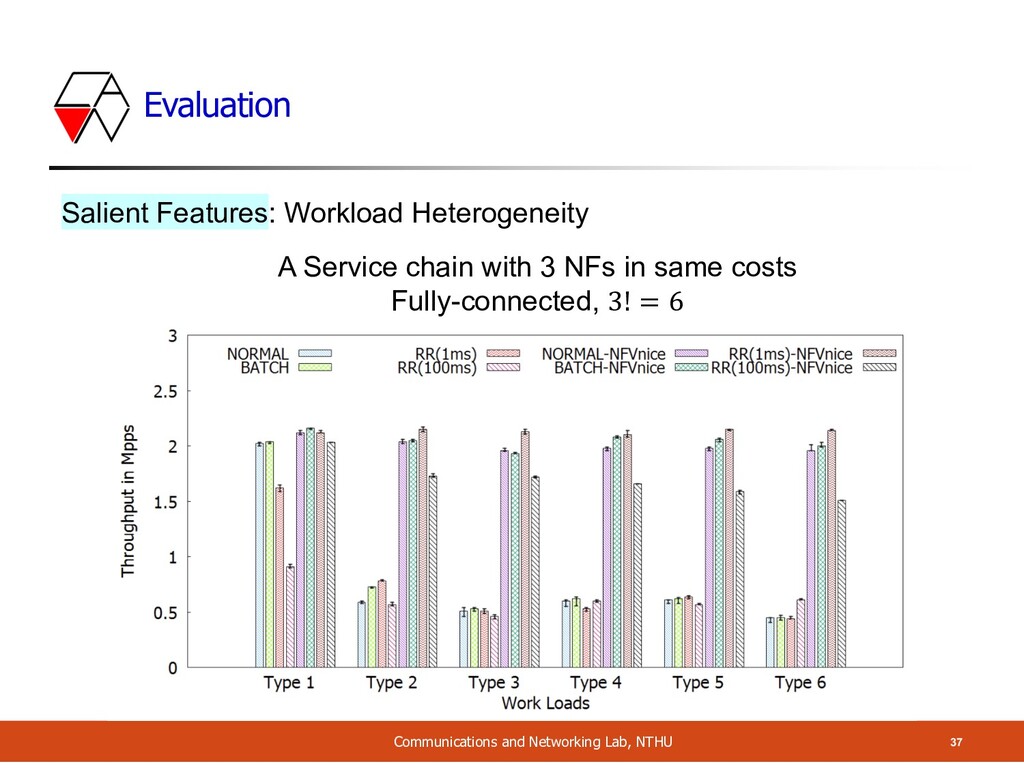
NF Packet Processing Cost A Service chain with 3 NFs: in varying costs (random) = 9 variants • Cost 1: 120 CPU cycles • Cost 2: 270 CPU cycles • Cost 3: 550 CPU cycles Single Core Current Previous
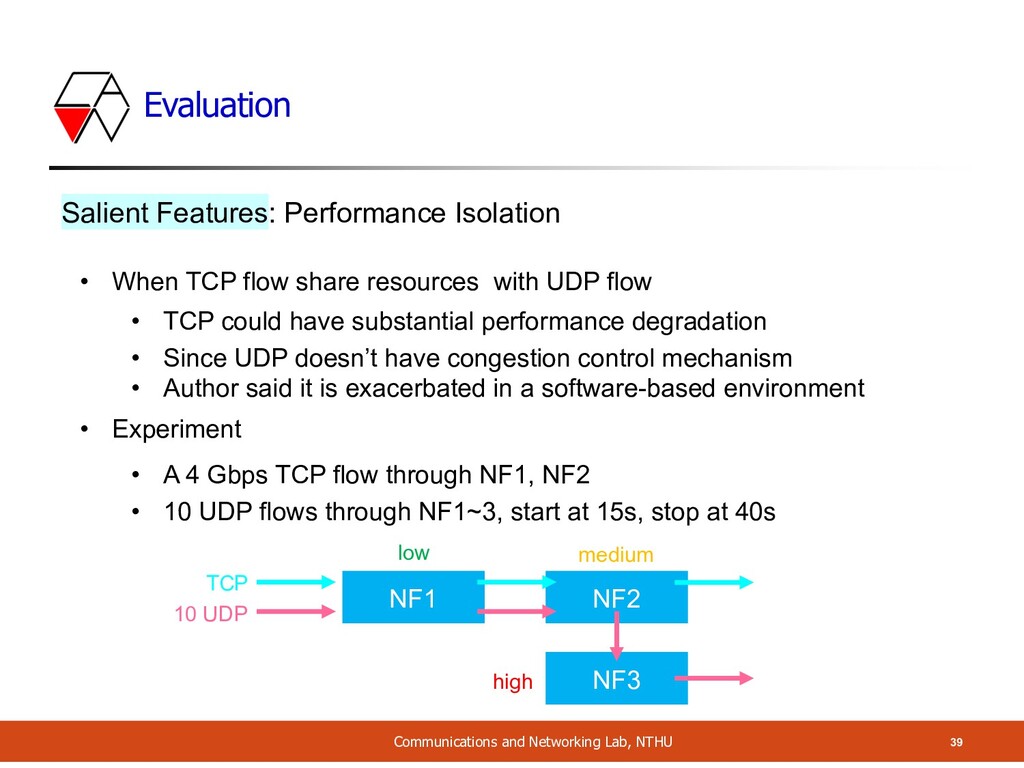
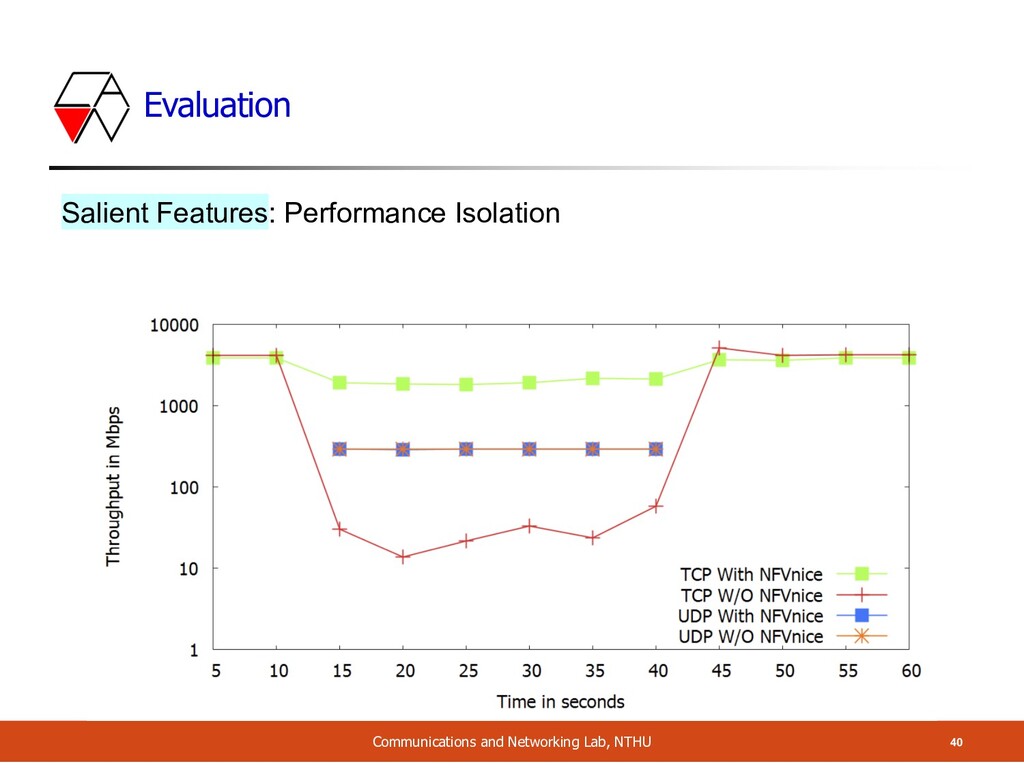
Isolation • When TCP flow share resources with UDP flow • TCP could have substantial performance degradation • Since UDP doesn’t have congestion control mechanism • Author said it is exacerbated in a software-based environment • Experiment • A 4 Gbps TCP flow through NF1, NF2 • 10 UDP flows through NF1~3, start at 15s, stop at 40s
Isolation • When TCP flow share resources with UDP flow • TCP could have substantial performance degradation • Since UDP doesn’t have congestion control mechanism • Author said it is exacerbated in a software-based environment • Experiment • A 4 Gbps TCP flow through NF1, NF2 • 10 UDP flows through NF1~3, start at 15s, stop at 40s NF1 NF2 NF3 low medium high TCP 10 UDP
n Improve CPU utilization n Method n Schedule NFs according to their state n Backpressure n Results n NFVnice conquers most of scenarios Communications and Networking Lab, NTHU 43
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}