Kubeflow is a popular MLOps platform built on Kubernetes for designing and running Machine Learning pipelines for training models and providing inference services. Kubeflow has a notebook service that lets you launch interactive Jupyter servers (and more) on your Kubernetes cluster. Kubeflow also has a pipelines service with a DSL library written in Python for designing and building repeatable workflows that can be executed on your cluster, either ad-hoc or on a schedule. It also has tools for hyperparameter tuning and running model inference servers, everything you need to build a robust ML service.
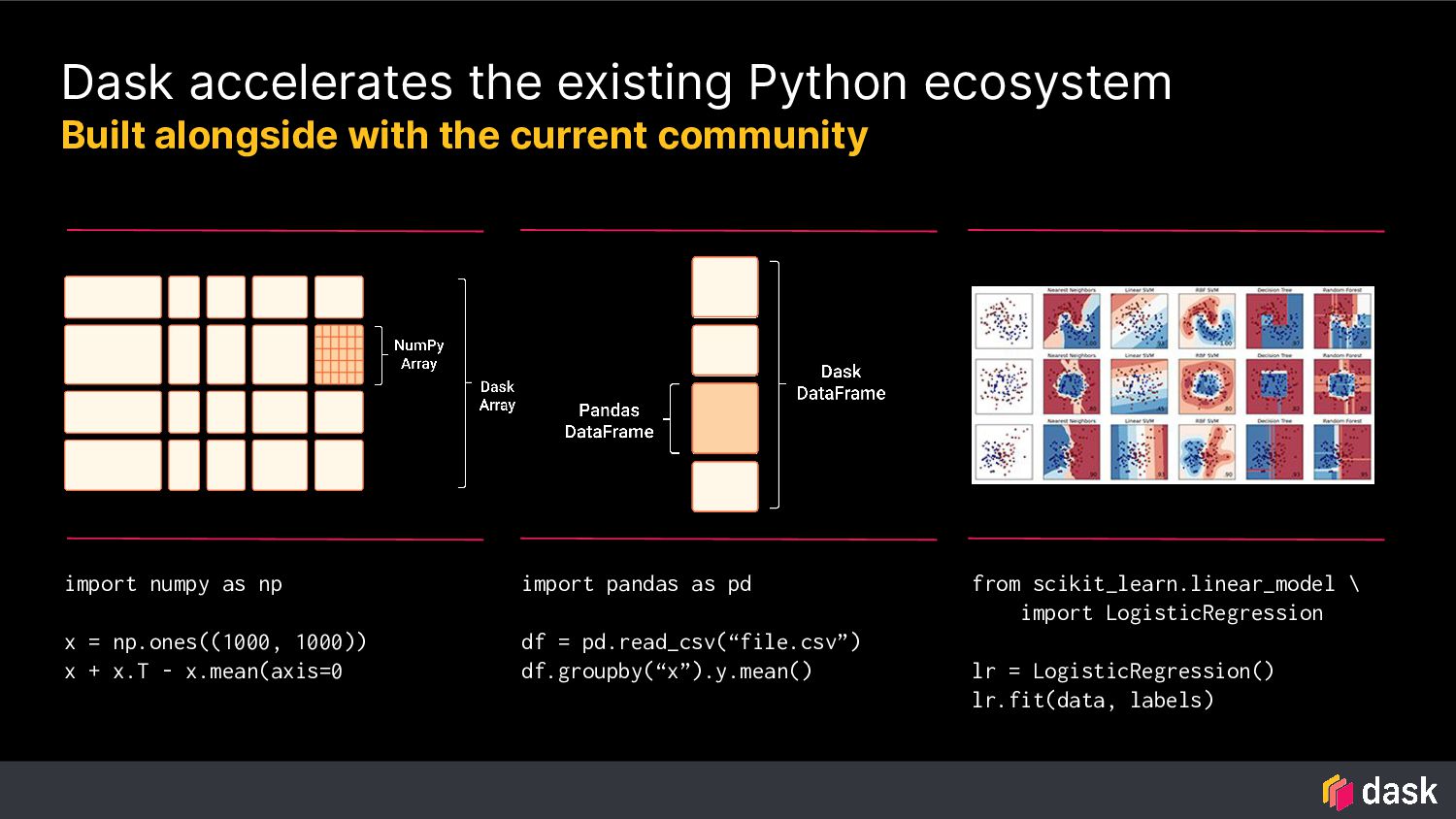
Dask provides advanced parallelism for Python by breaking functions into a task graph that can be evaluated by a task scheduler that has many workers. This allows you to utilize many processors on a single machine, or many machines in a cluster. Dask’s many high-level collections APIs including dask.dataframe and dask.array provide familiar APIs that match Pandas, NumPy and more to enable folks to parallelize their existing workloads and work with larger than memory datasets.
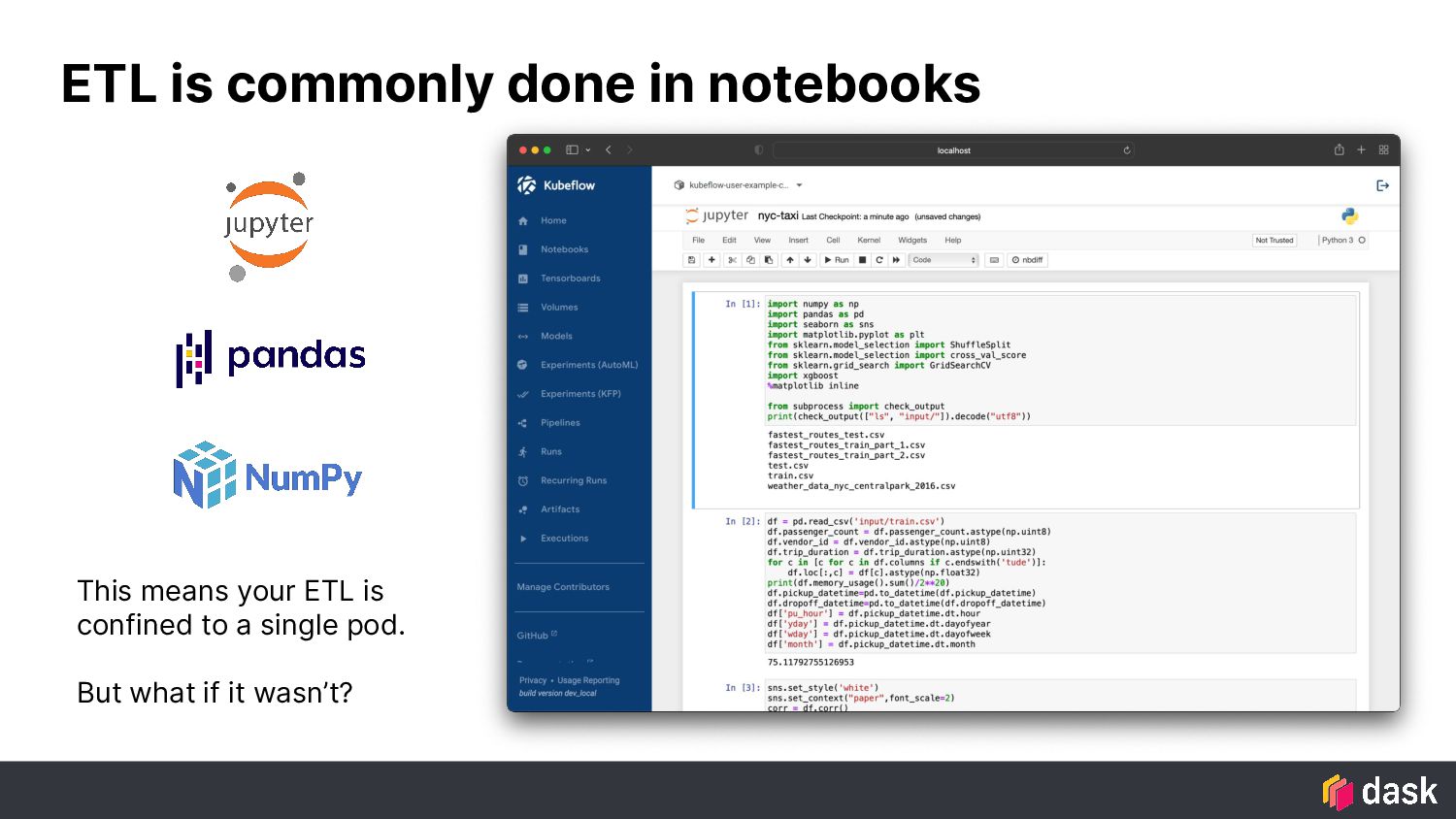
The Kubeflow Pipelines DSL provides the ability to parallelize your workload and run many steps concurrently. But what about parallelism in your interactive sessions? Or leveraging existing parallelism capabilities from Dask at the Python level? Can Dask help users leverage all of the hardware resources in their Kubeflow cluster?
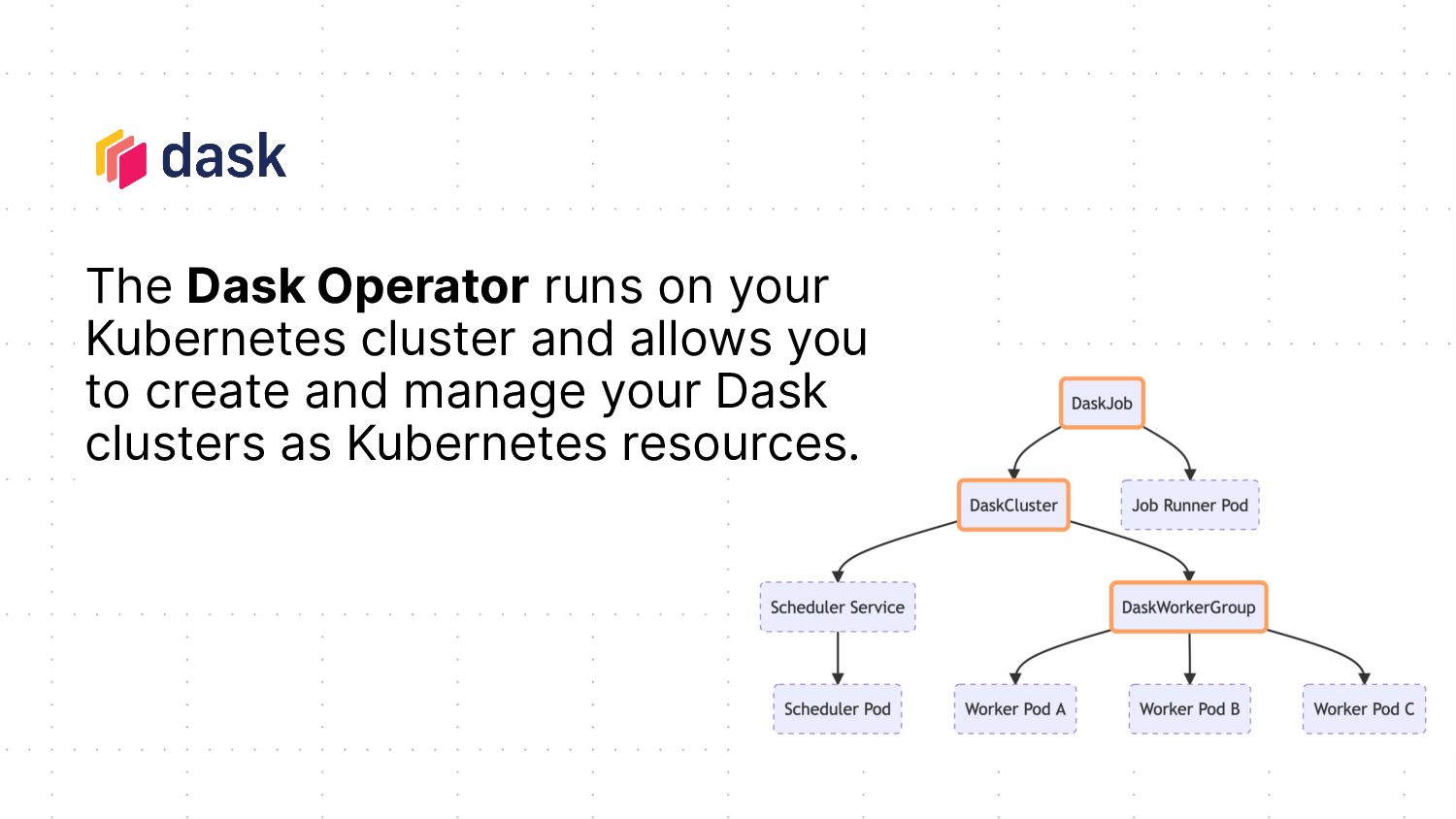
These questions lead the maintainers of Dask’s Kubernetes tooling to build a new cluster manager to empower folks to get the best out of Dask on their Kubeflow clusters, both interactively and within pipelines.
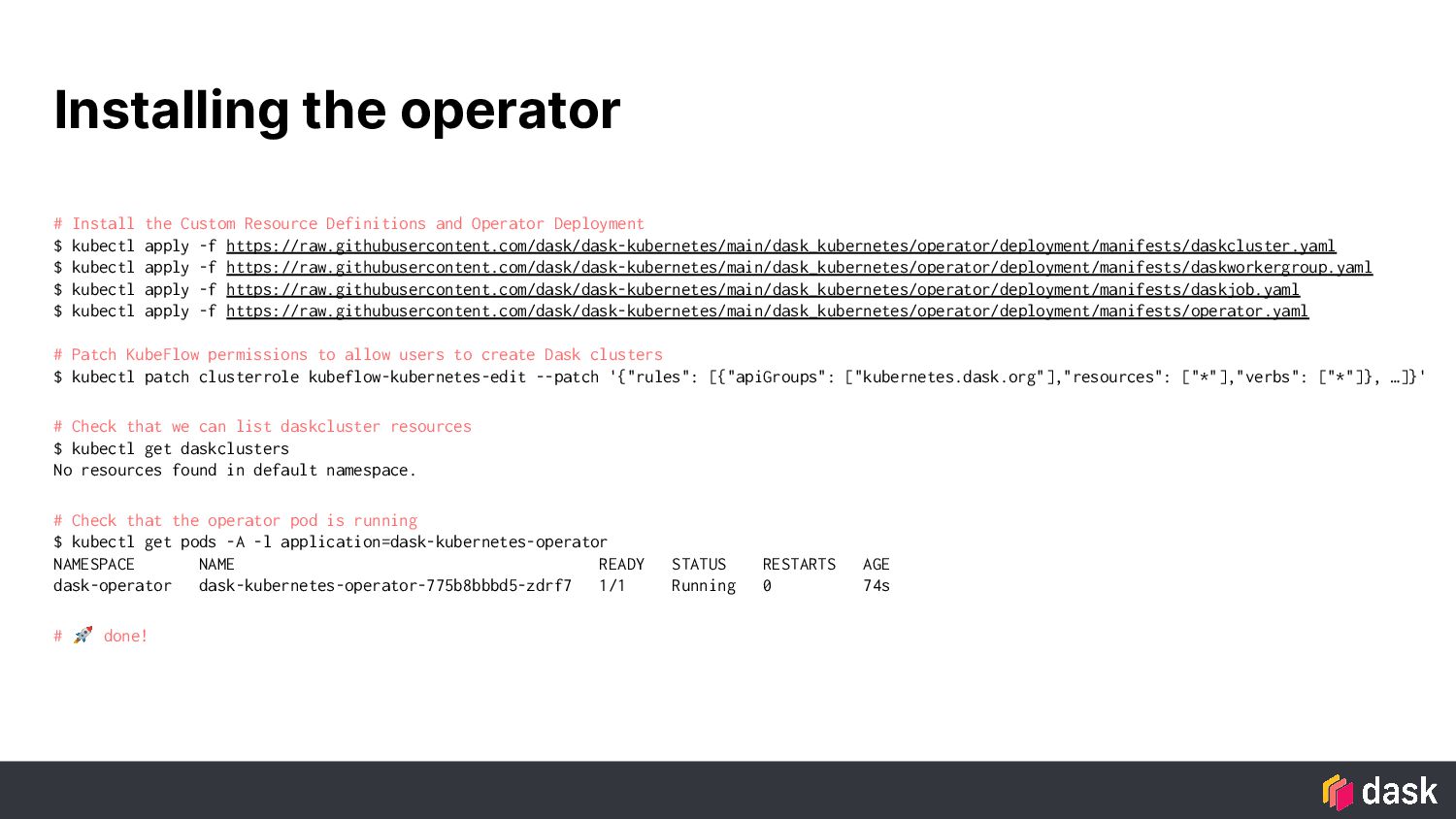
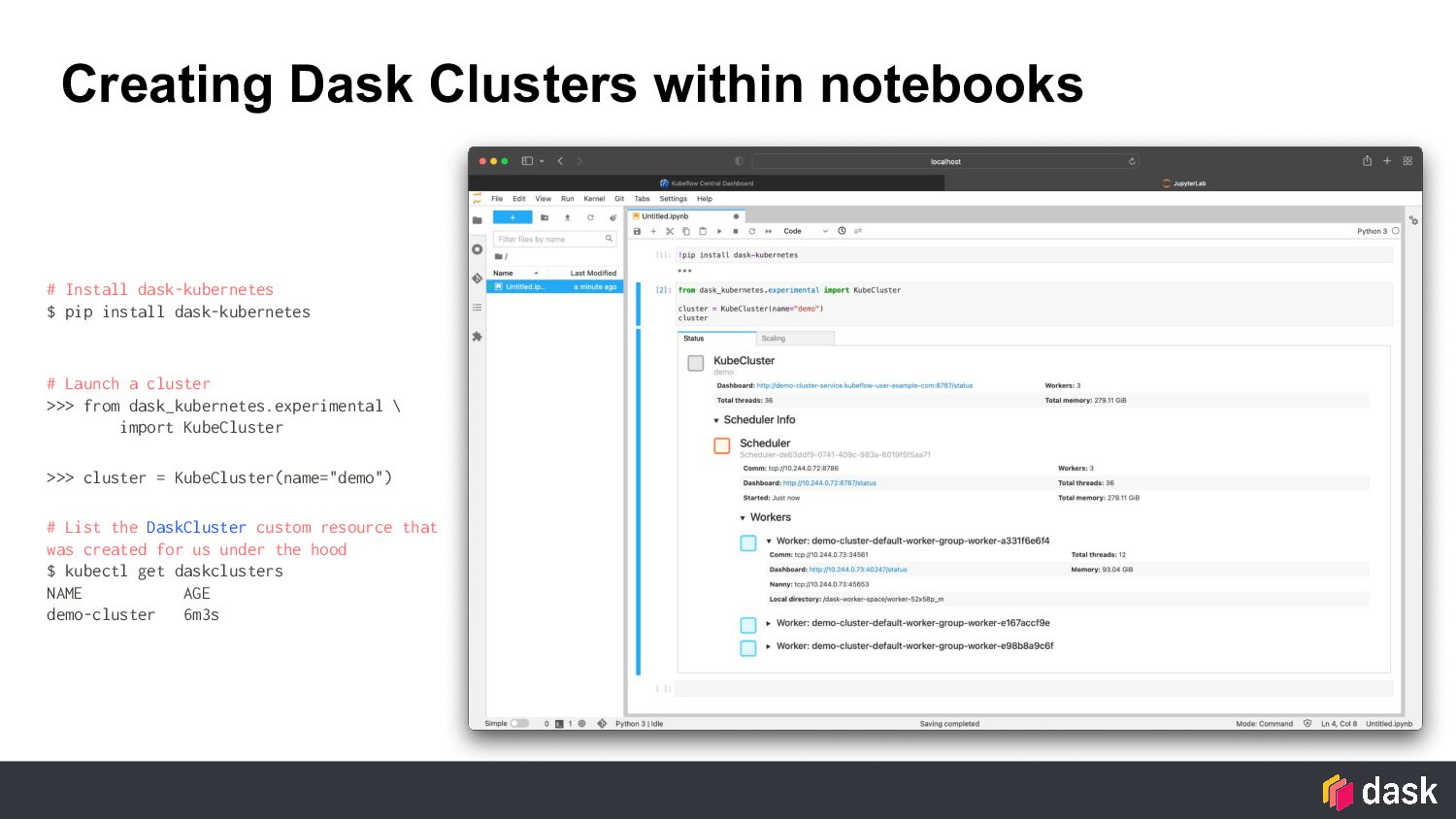
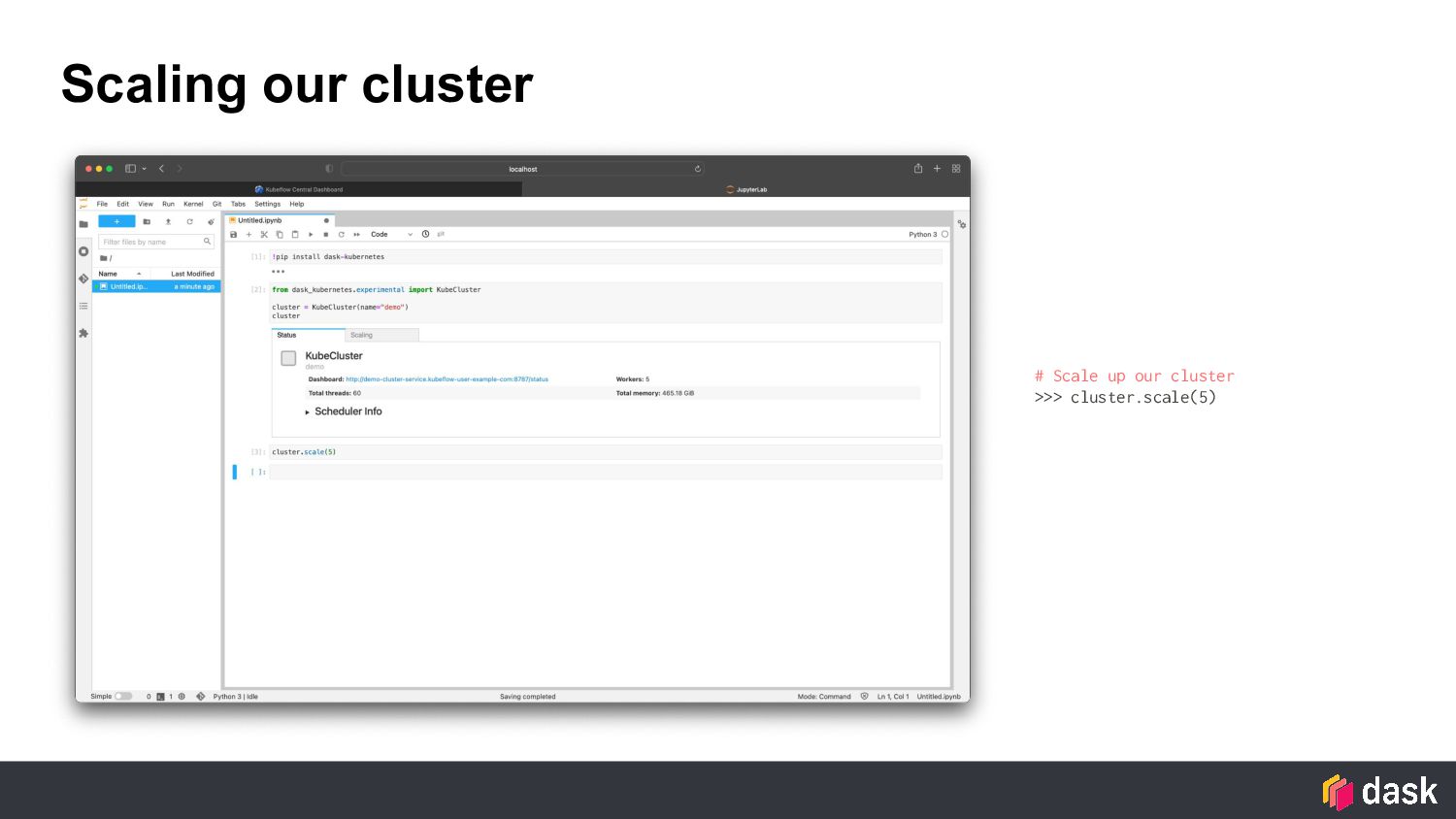
With the new Dask Operator installed on your Kubeflow cluster, users can conveniently launch Dask clusters from within their interactive Jupyter sessions and burst beyond the resources of the Jupyter container. Dask clusters can also be launched as part of a pipeline workflow where each step of the pipeline can utilize the resources provided by Dask, even persisting data in memory between steps for powerful performance gains.
In this talk, we will cover Dask’s new Kubernetes Operator, installing it on your Kubeflow cluster, and show examples of leveraging it in interactive sessions and scheduled workflows.
What You Will Learn:
Data Scientists commonly use Python tools like Pandas on their laptops with CPU compute. Production systems are usually distributed multi-node GPU setups. Dask is an open source Python library that takes the pain out of scaling up from laptop to production.
Technical Level: 5
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}