di sviluppo software, è una disciplina nuova ◦ “best practices” stanno ancora formulando ◦ tool di sviluppo sono molto “freschi” • Oltre la codice che definisce il modello, bisogna gestire tanti dati ◦ artefatti dei modelli (100 Mbyte ... 700 Gbyte) ◦ dataset (fino all’ordine di grandezza di 50 Tbyte) ◦ non ci stanno in git… • Tanti esperimenti affidandosi all’intuizione
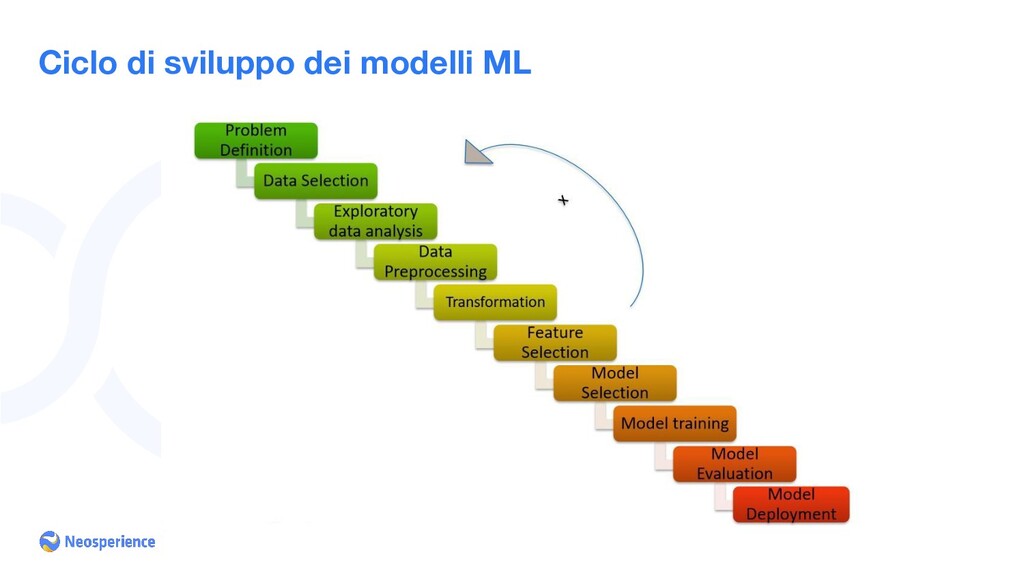
passo di avere tutto il dataset a disposizione • Subsampling del dataset ◦ Prendiamo una quantità di dati che è gestibile con un singolo workstation ◦ Subset preferibilmente rappresentativo ◦ Strumenti: Athena, SQL, prefissi S3, etc. • Exploratory Data Analysis (EDA) ◦ Acquisiamo una “conoscenza” dei dati ◦ Distribuzione, statistica, correlazioni, istogrammi ◦ Dati mancanti o errati e come gestirli ◦ Intuizione di quali coloni di input possono essere di maggior aiuto
dati e feature extraction ◦ Gestione dei dati mancanti e errati ◦ Conversione dei dati categorici ◦ Conversione dei dati testuali ◦ Normalizzazione • Selezione del modello ◦ A base della tipologia dell’input (tabulare, immagini, testo naturale, altro tipo “esotico” o la combinazione di questi) ◦ Addestramento del primo modello “baseline” sul subset dell’input • Addestramento sul dataset intero ◦ Aggiustamento dei parametri del modello ◦ Valutazione delle metriche ◦ Repeat
modello ◦ Tipicamente nella forma di un web service ◦ Serverless? Il modello ha bisogno del GPU? ◦ In produzione bisogna eseguire i stessi trasformazione dell’input che sono stati definite prima dell’addestramento! • Monitoring ◦ Model drifting: la distribuzione dei dati di input possono cambiare con il tempo ◦ Possibilmente arrivano nuovi dati di addestramento
dell’input ◦ preprocessing dei dati ◦ addestramento del modello ◦ salvataggio e versionamento degli artefatti del modello ◦ deploy in produzione in un singolo script python, che può essere eseguito manualmente o automaticamente quando il codice o i dati di input cambiano. • L’idea è simile a Step Functions, soprattutto al Data Science SDK di SF
entrambi per fare EDA e preprocessing • Glue Data Brew ◦ Solo trasformazioni predefiniti ◦ Utile anche per finalità non machine-learning (ETL) ◦ UI sul console AWS ◦ Deploy: Glue job • SageMaker Data Wrangler ◦ Trasformazioni custom (pyspark / pandas) ◦ Per preprocessing dei dataset ◦ Addestramento piccolo modello di baseline in situ ◦ UI in JupyterLab ◦ Deploy: SageMaker pipelines, nel Feature Store o codice
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}