This is a talk in Flink Forward Seattle 2023.
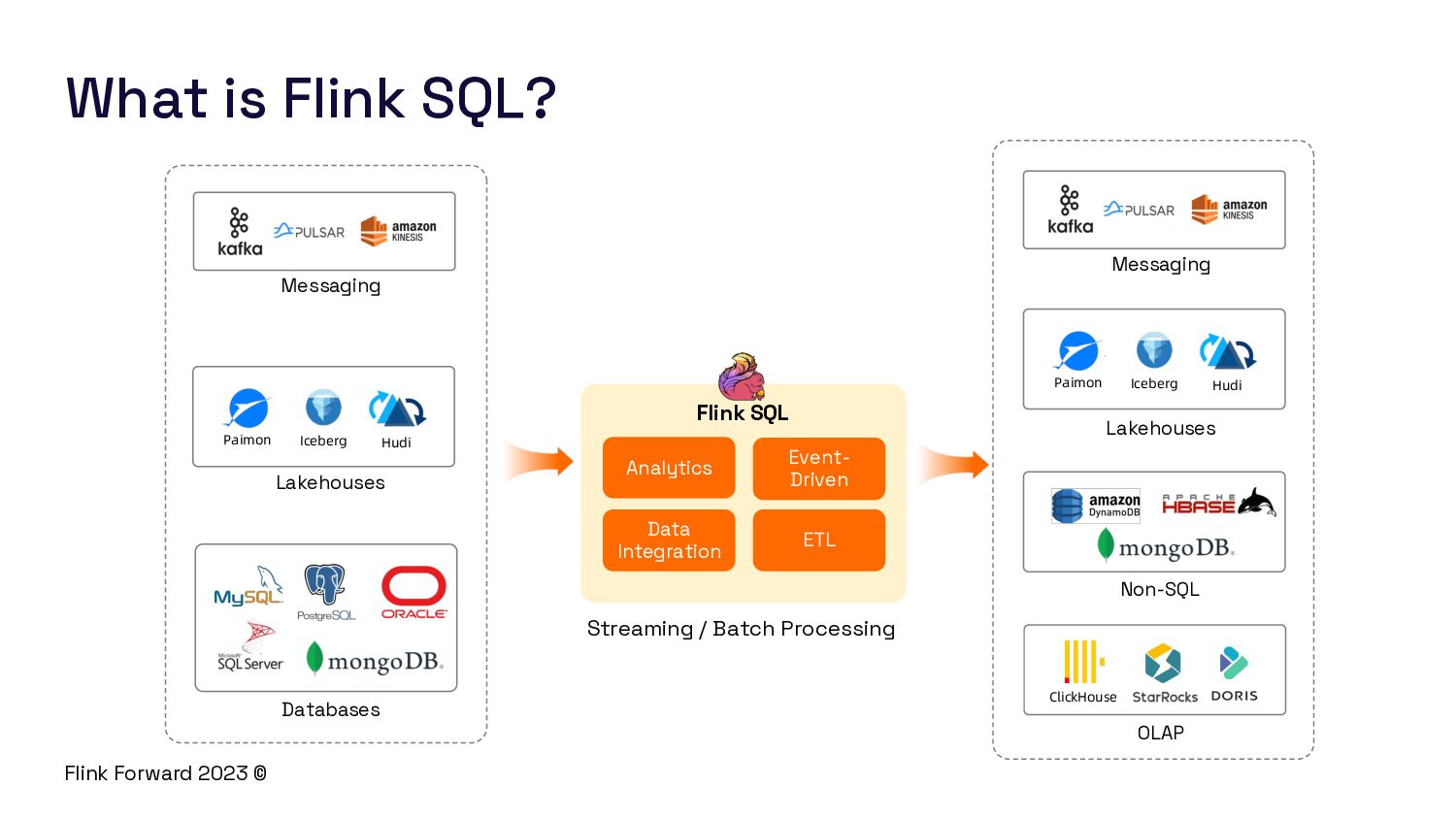
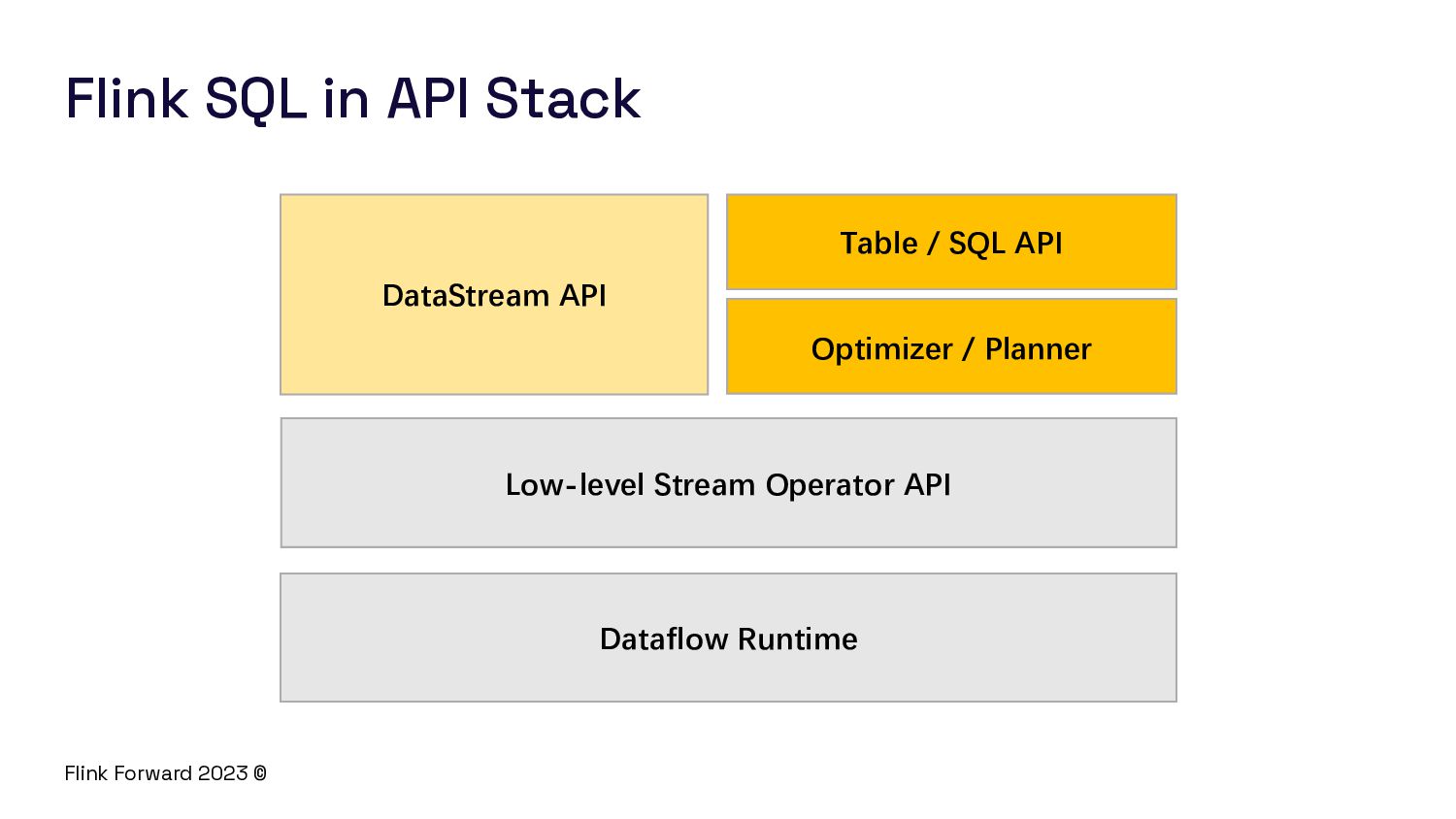
Flink SQL is a powerful tool for stream processing that allows users to write SQL queries over streaming data. However, building a streaming SQL engine is not an easy task. In this session, we will explore the challenges that arise when building a modern streaming SQL engine like Flink SQL.
We will discuss the following challenges and how Flink SQL resolves them:
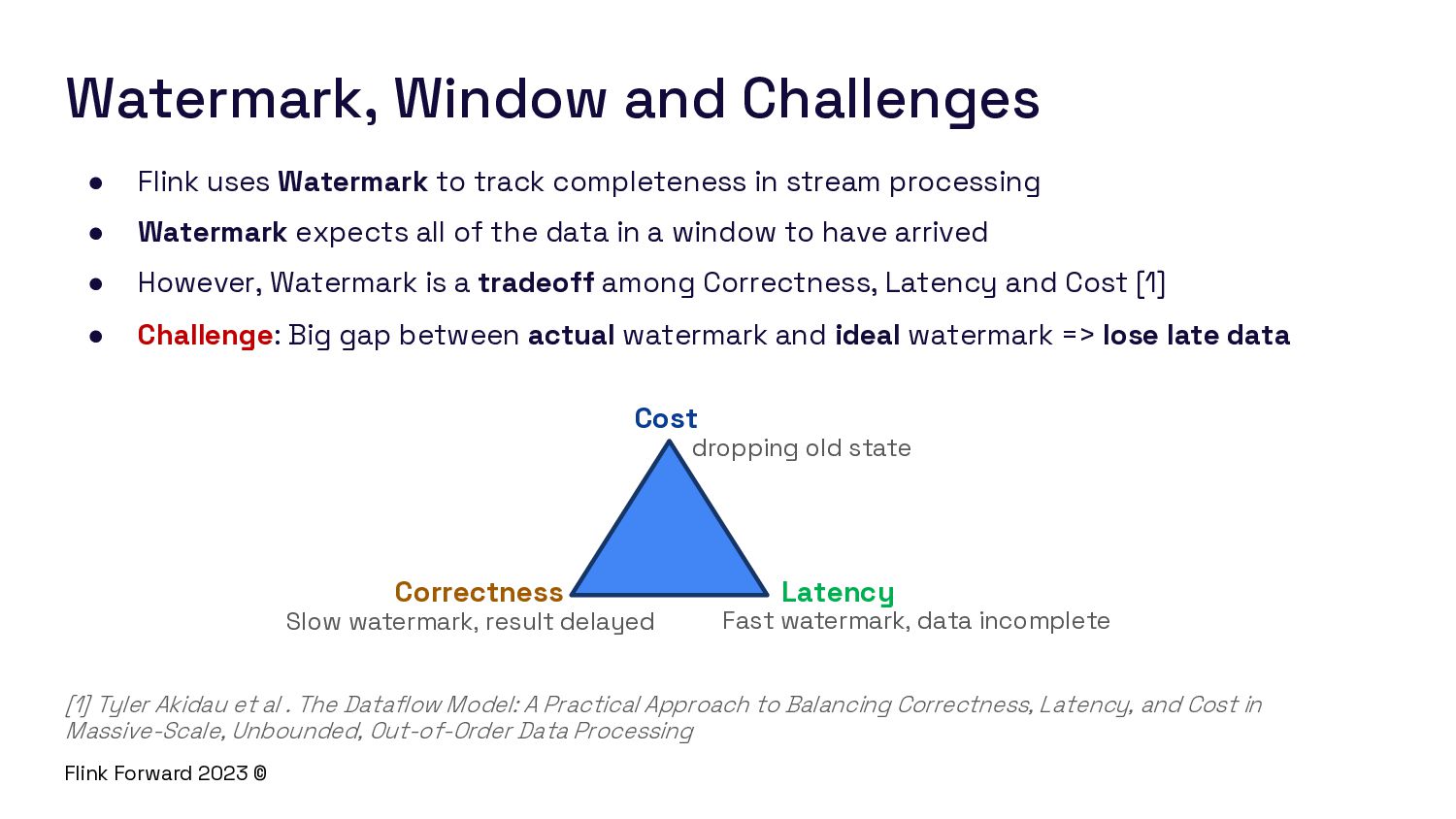
- Late Data: Handling late arrival data and guaranteeing result correctness.
- Change Data Ingestion and Processing: How to ingest change data from databases in real-time and apply complex operations on the change events.
- Event Ordering: Shuffle may disrupt the order of data updates and get the wrong result.
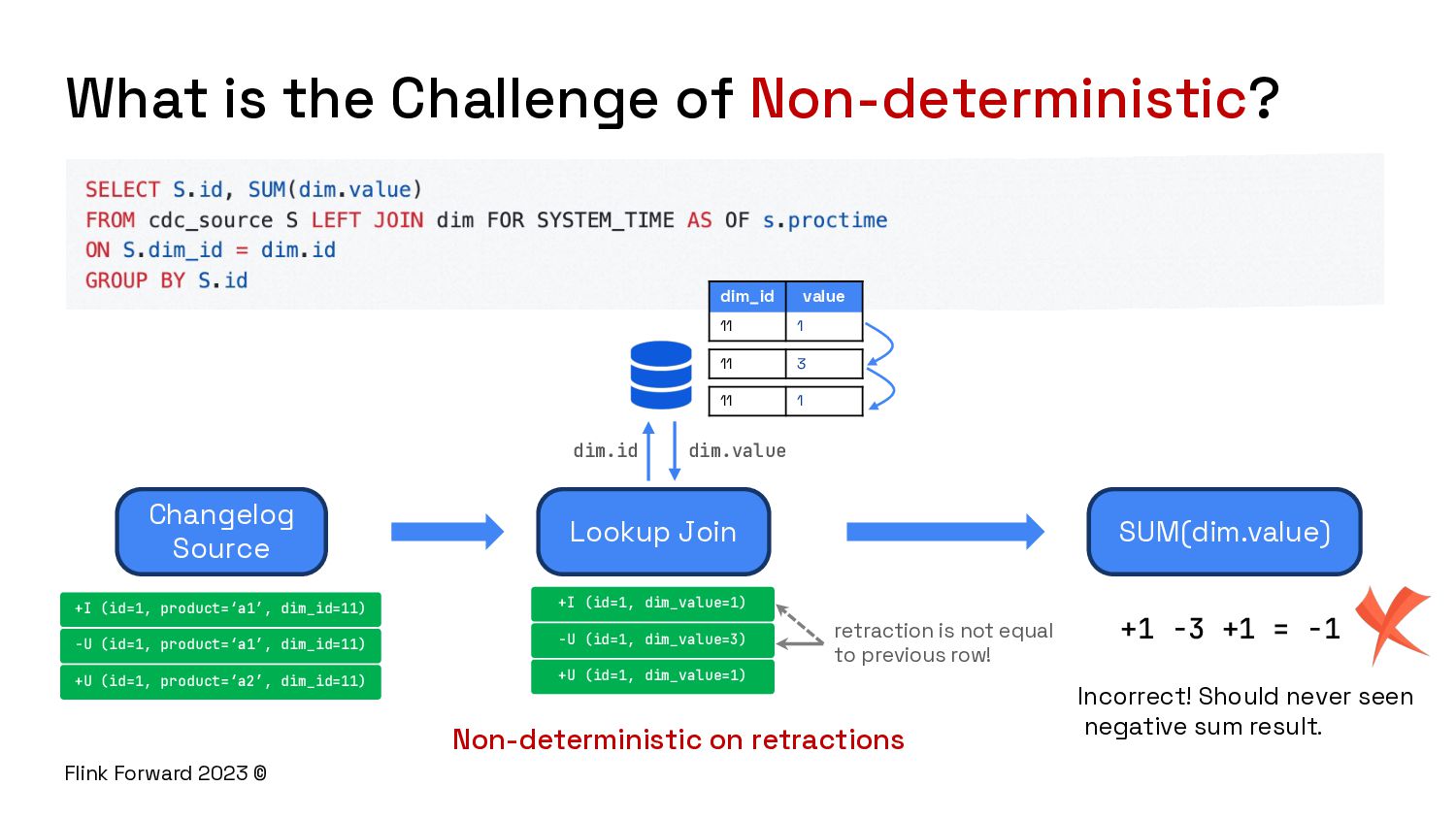
- Nondeterminism: Nondeterministic functions and external system lookups may produce different results on change data and get the wrong result.
By the end of this session, you will better understand the challenges involved in building a streaming SQL engine and how to overcome them.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}