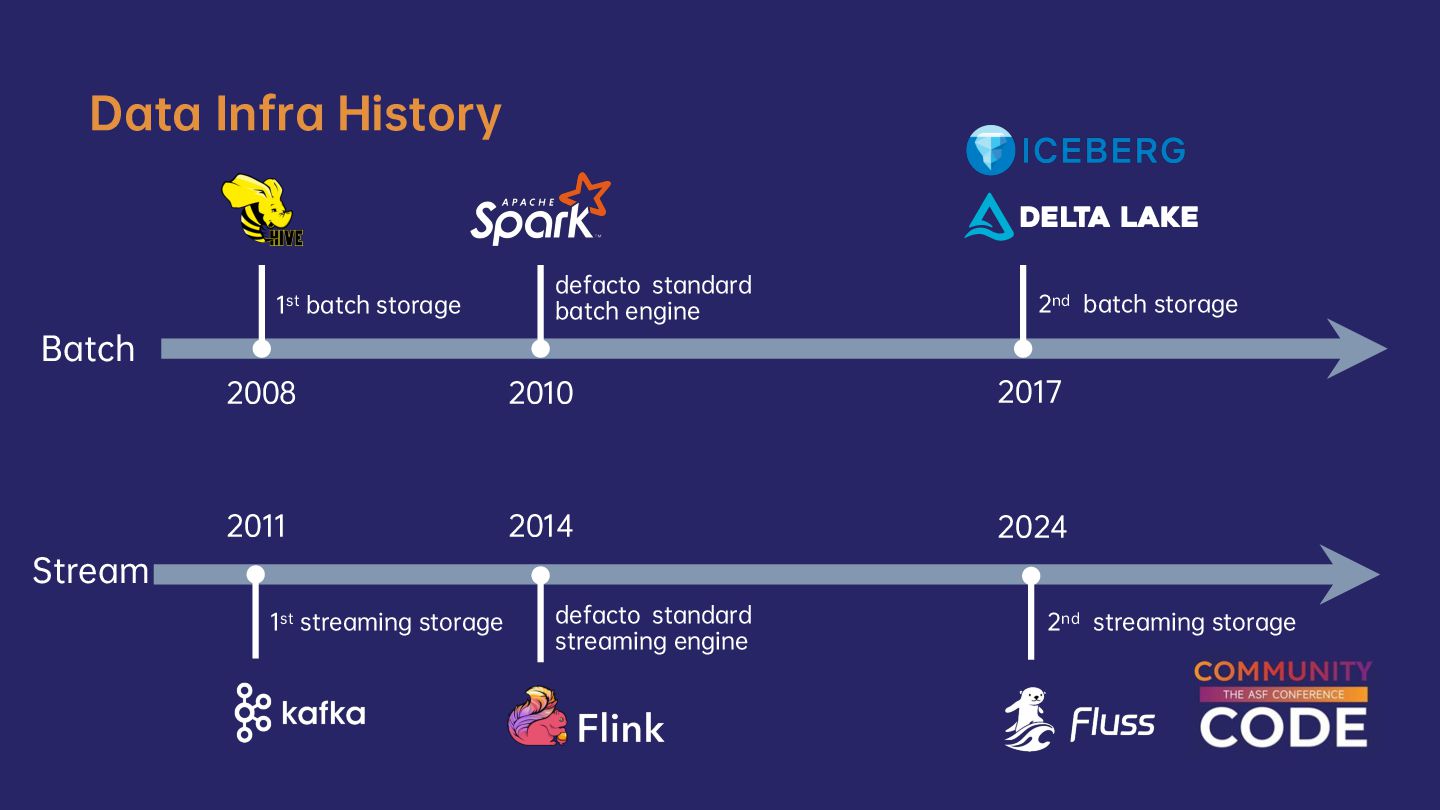
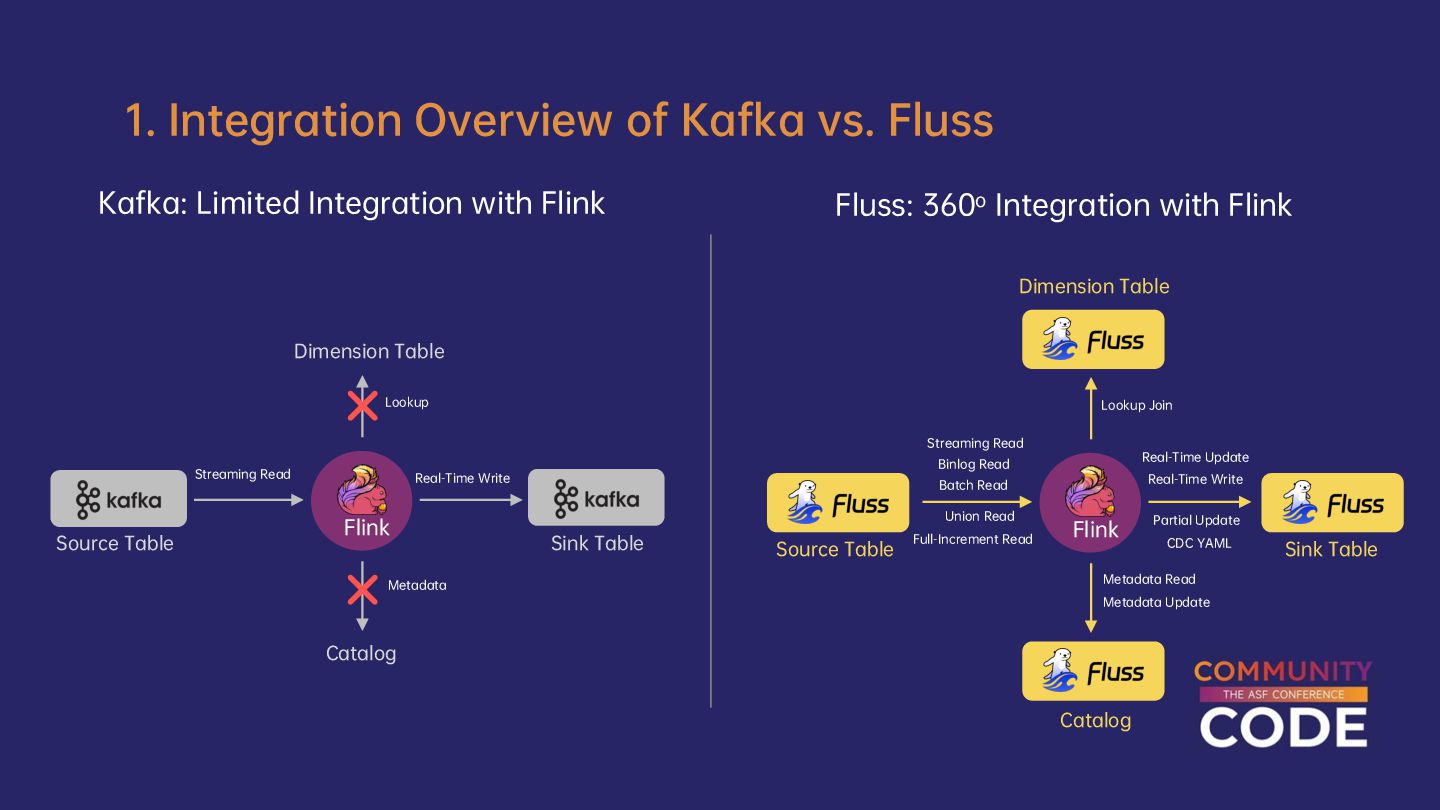
Kafka and Flink have been widely used together in streaming processing scenarios, becoming a defacto standard paradigm for building streaming warehouses and real-time analytics. However, it still faces many challenging issues that are hard to resolve. This session will explore the challenges and problems this paradigm faces in streaming analytics.
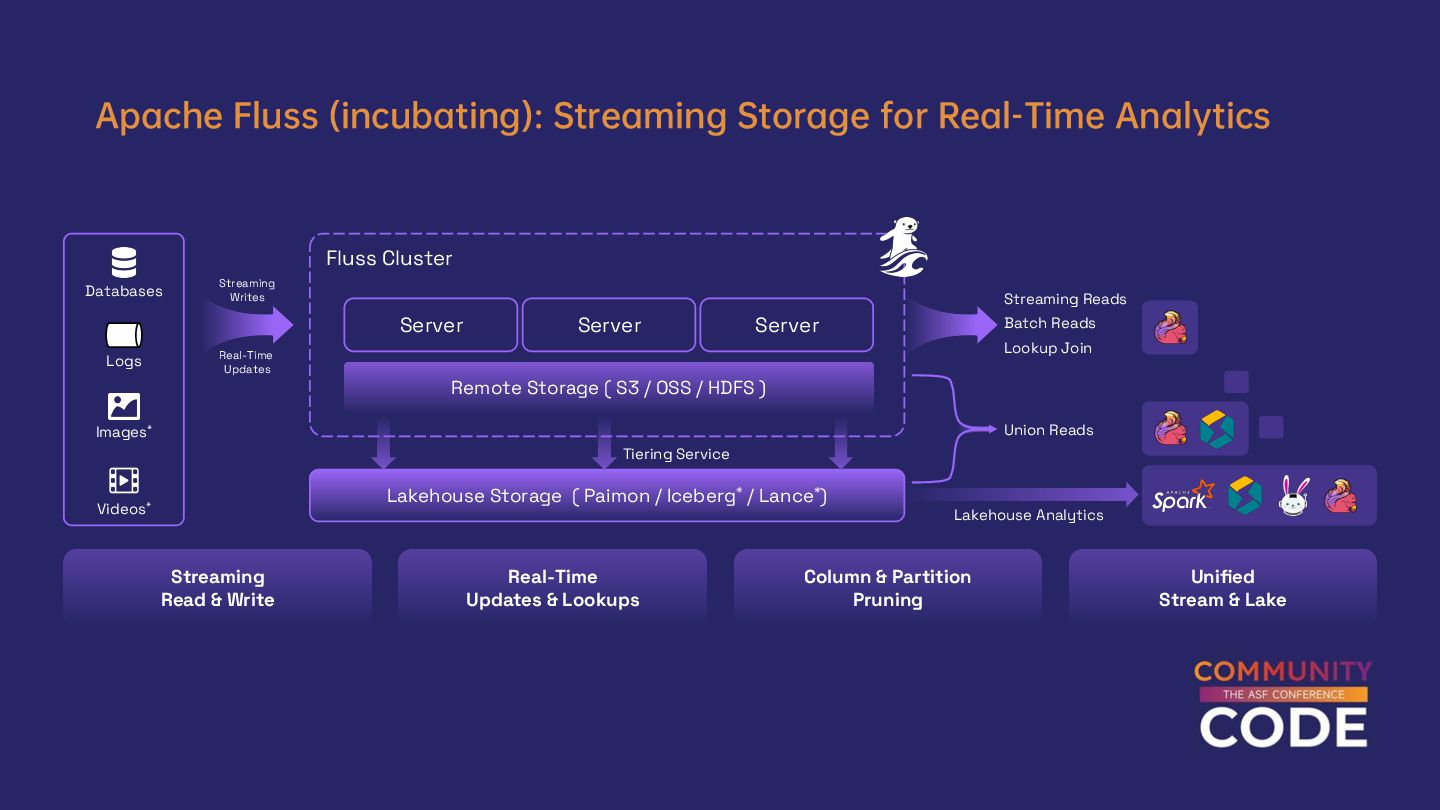
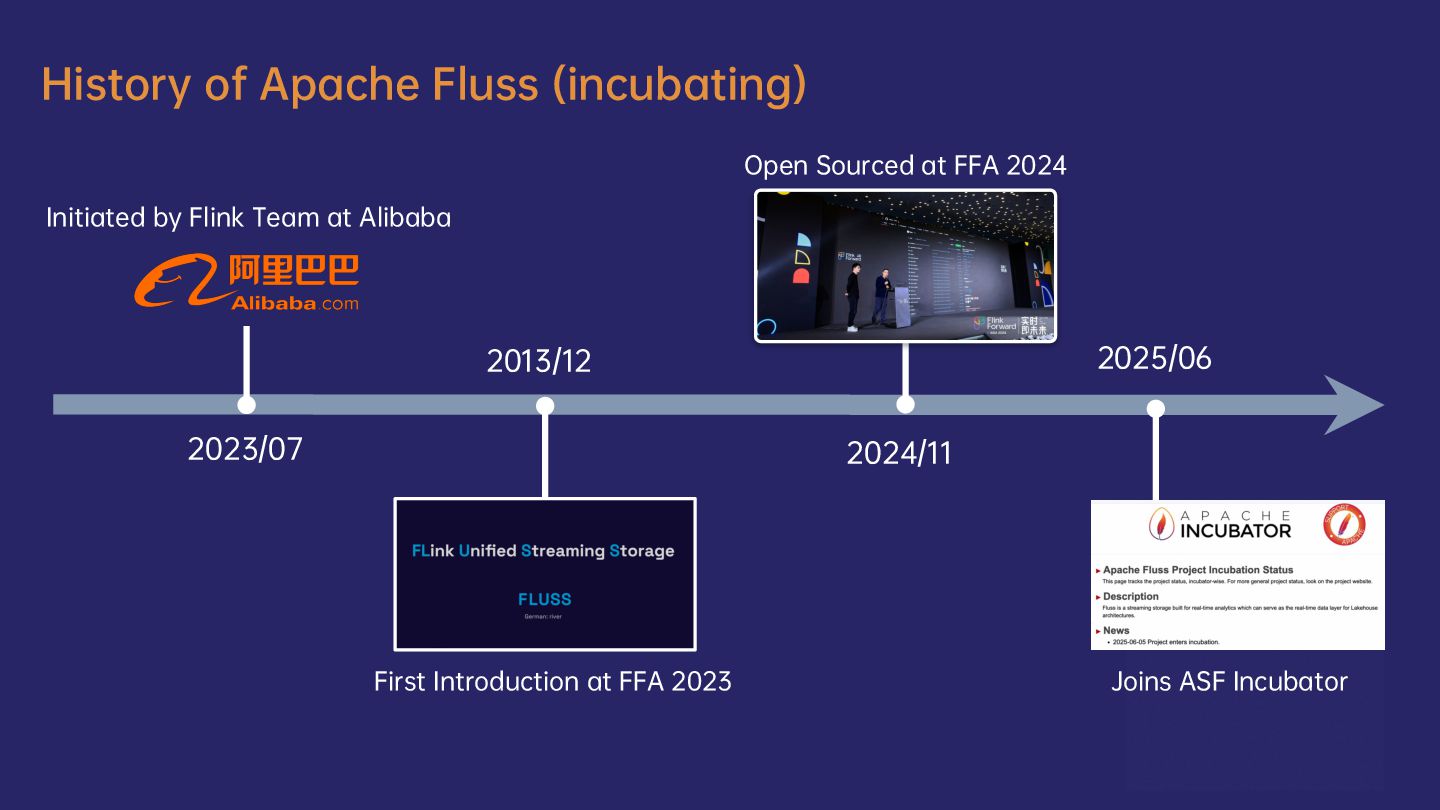
We will first discuss the limitations and pain points of Kafka when used with Flink. Then we will introduce Fluss, a next-generation streaming storage designed for streaming analytics. We’ll walk through its architecture and core innovations, highlighting how it seamlessly integrates with Flink to power the next generation of streaming warehouses. You’ll discover the game-changing capabilities unlocked by combining Flink and Fluss, such as streaming column pruning, delta joins, union reads, and merge engines.
Finally, we’ll explore real-world use cases of Flink + Fluss, showcasing how this powerful combination delivers true benefits like reduced infrastructure costs, improved performance, and enhanced stability for large-scale streaming and batch workloads.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
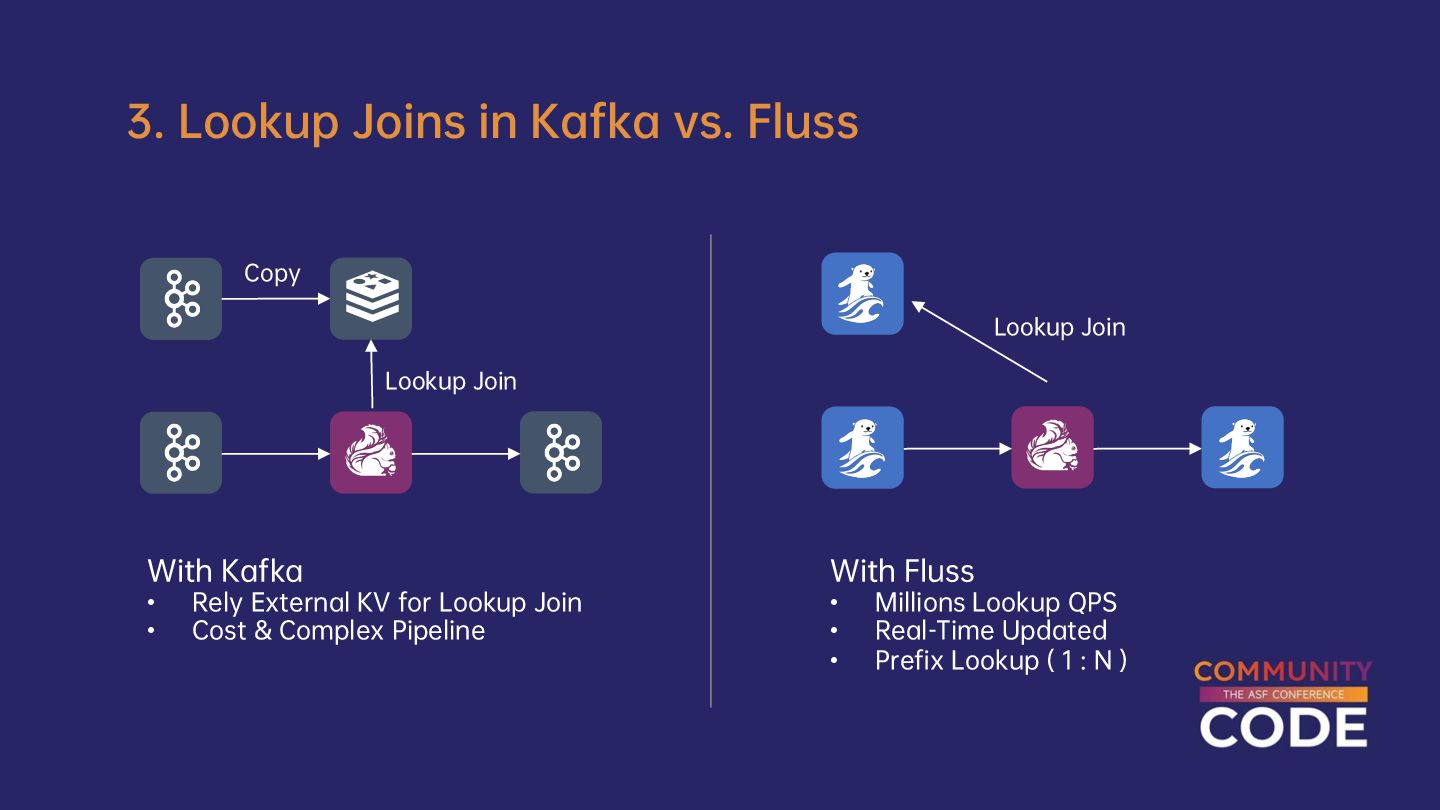{kind=link}
{kind=link}
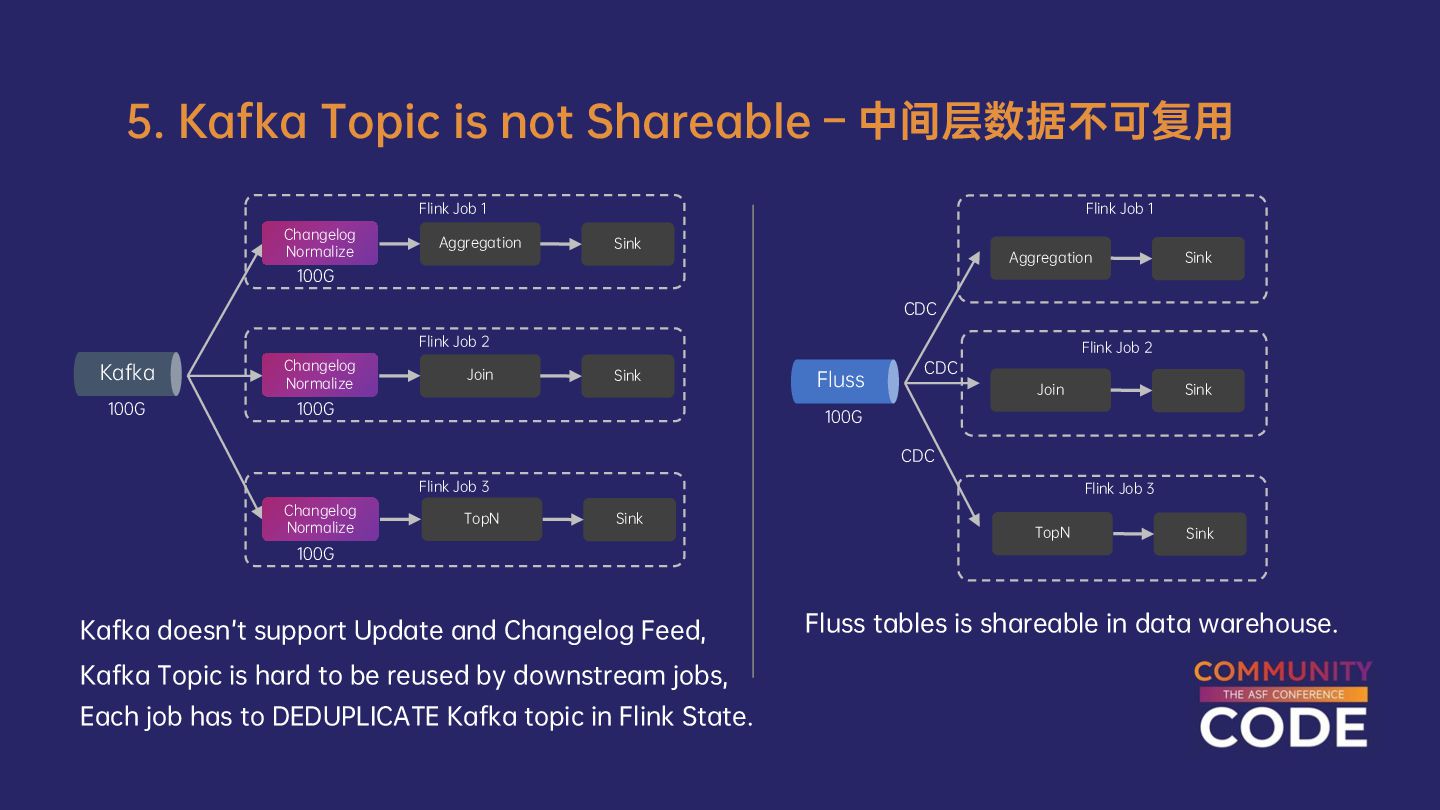{kind=link}
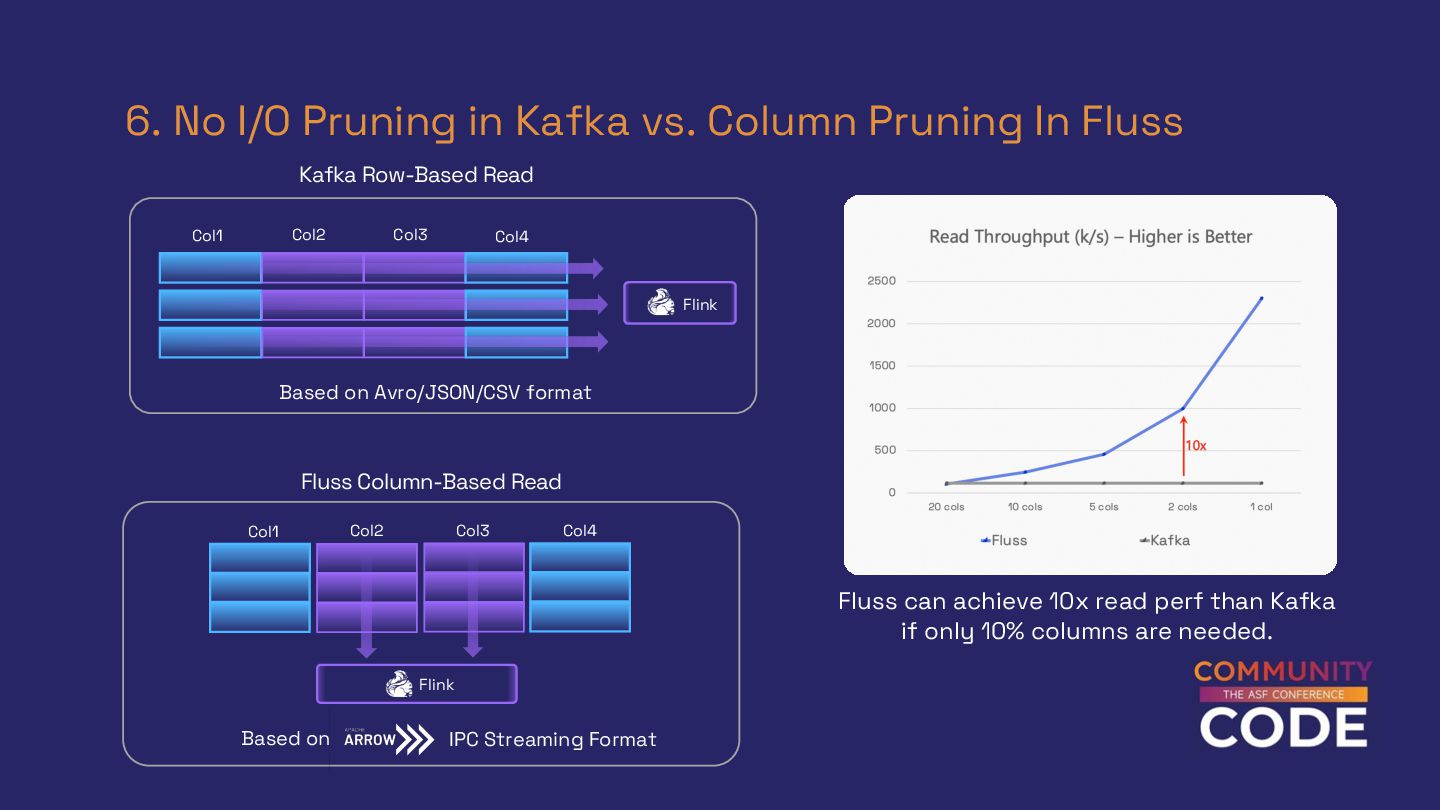{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
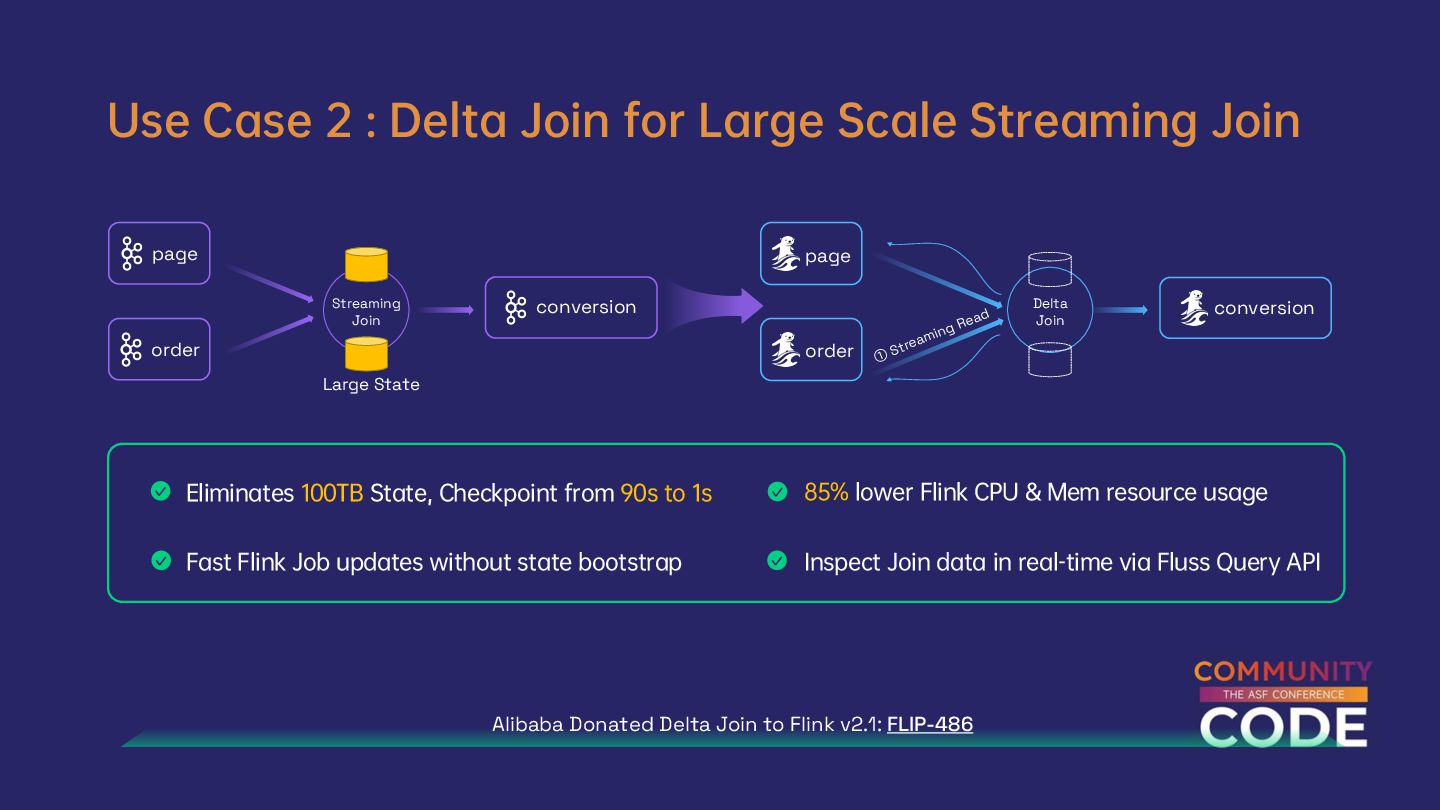{kind=link}
{kind=link}
{kind=link}
{kind=link}