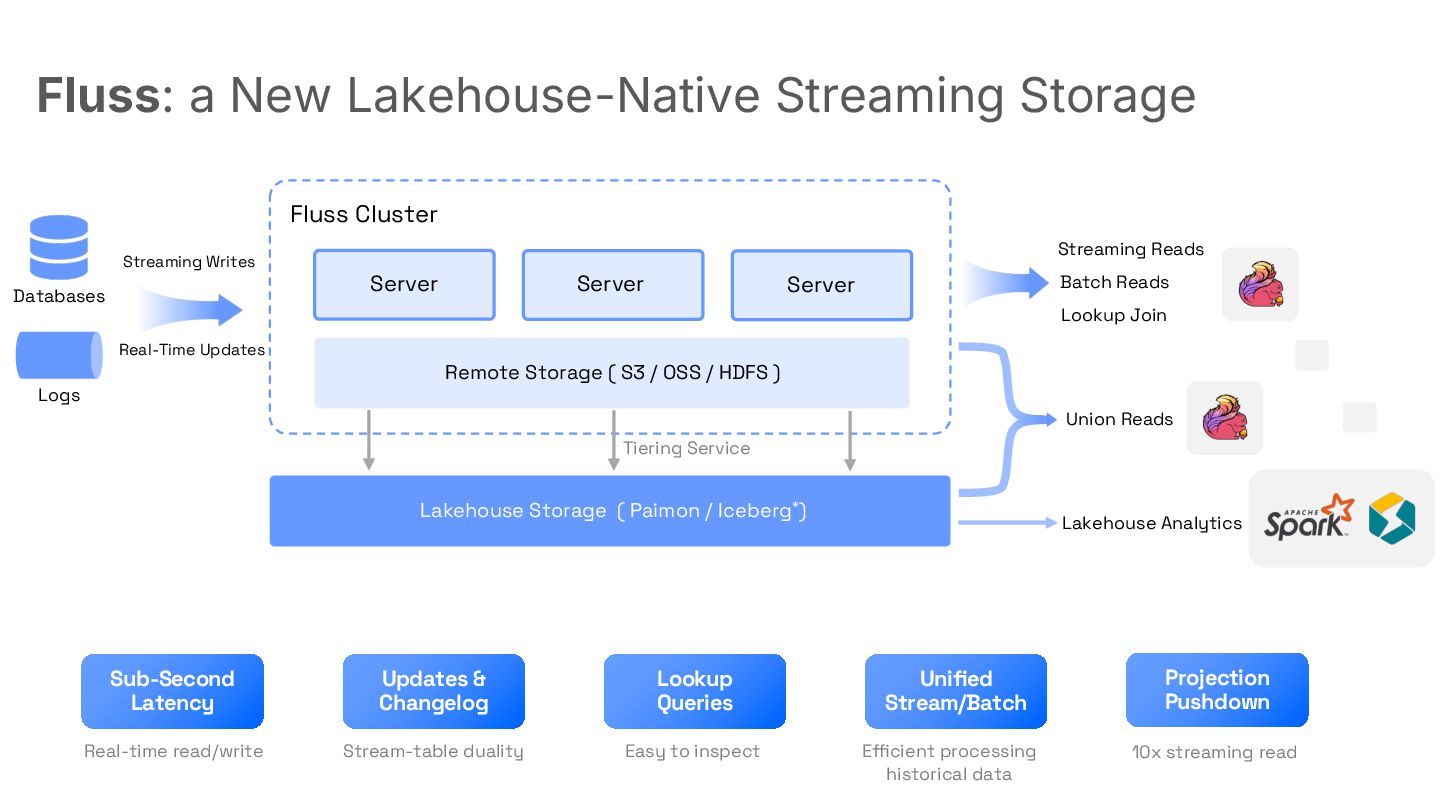
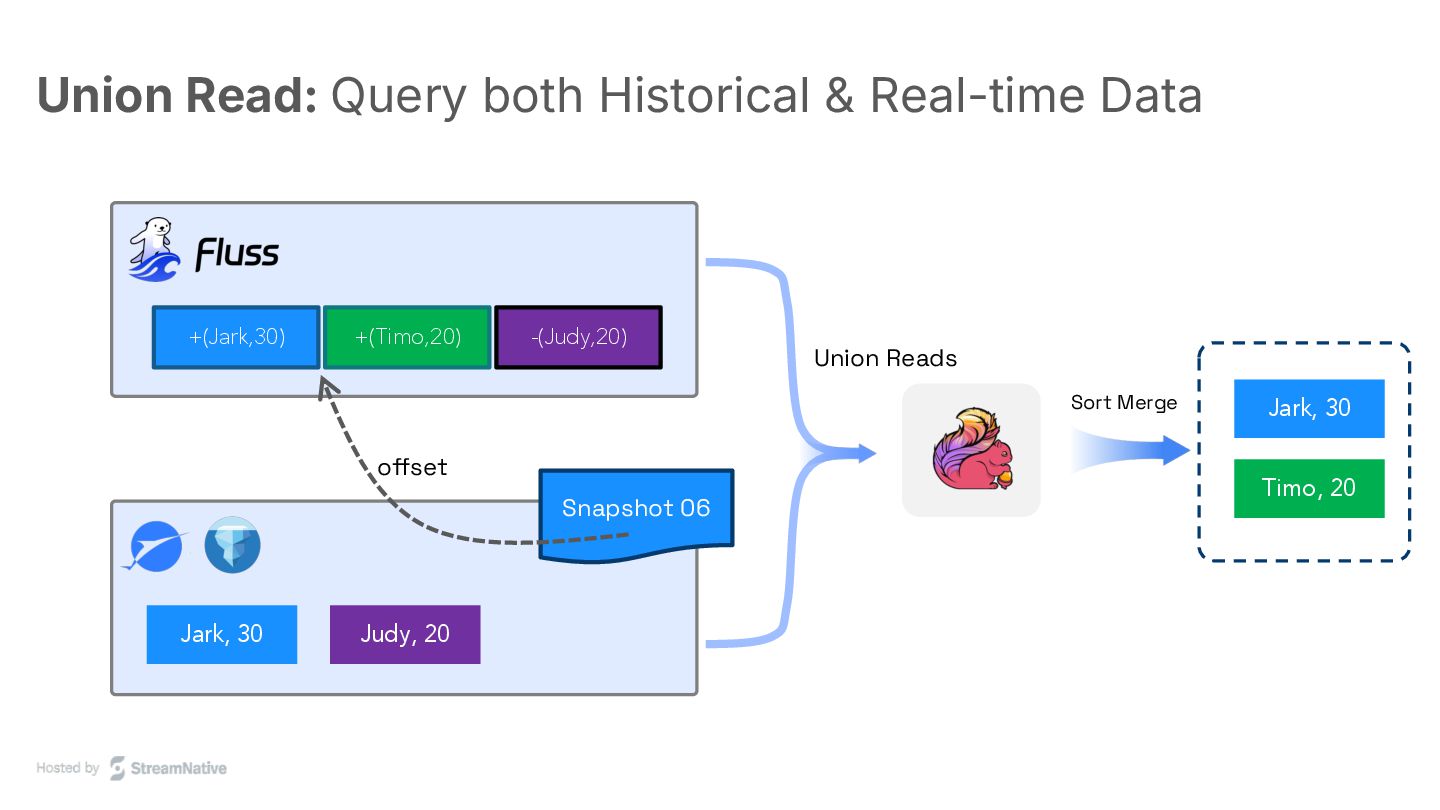
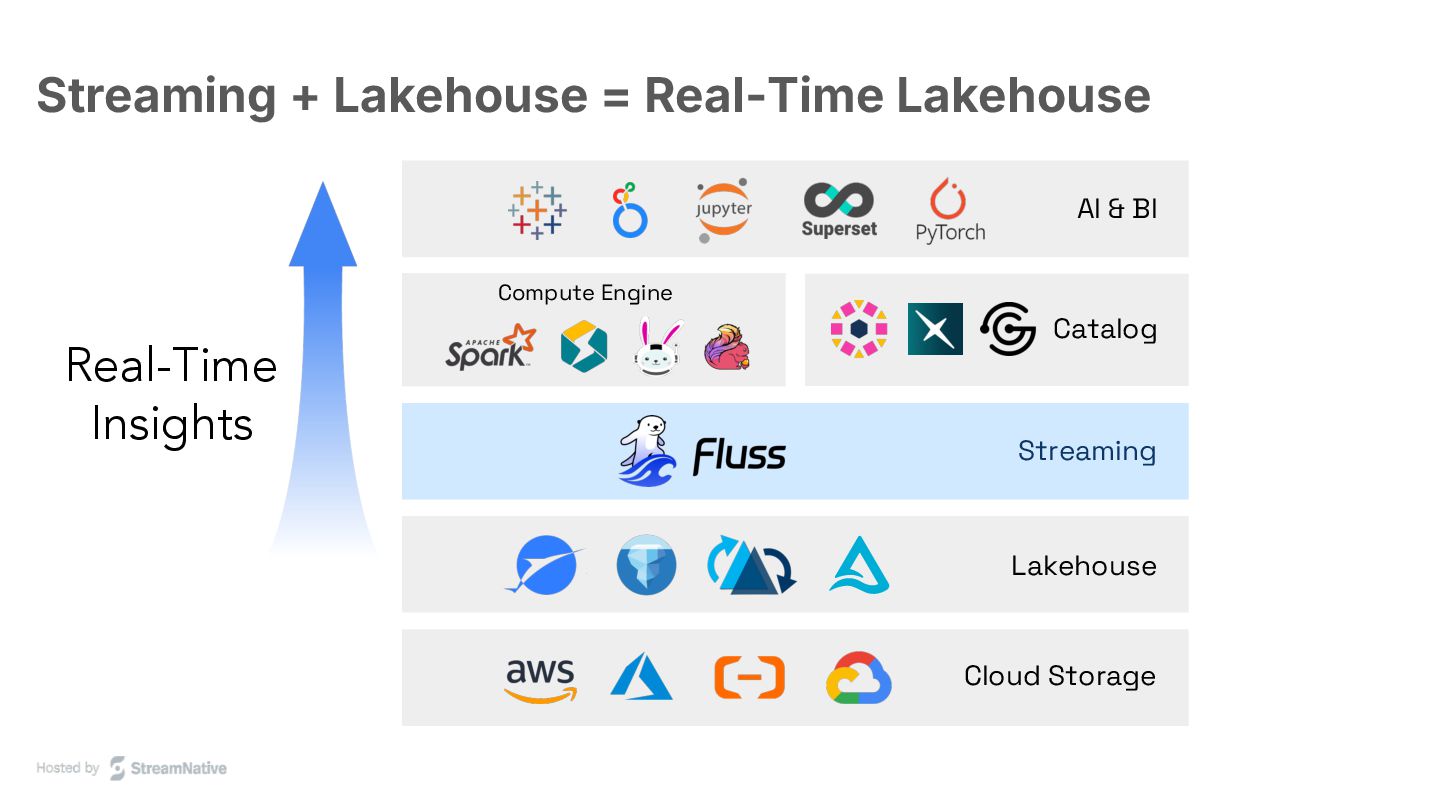
The session addresses the limitations of Kafka in creating real-time lakehouses necessary for modern AI applications. Fluss is introduced as a novel system built from scratch to integrate seamlessly with Lakehouse architectures.
Video: https://www.youtube.com/watch?si=8JrS6jhVSJoykY1t&v=OzE0mVD0GPs&feature=youtu.be
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}