With the rise of containerized applications, more and more people are starting to consider running high-availability applications in production with Docker. This is not to be taken lightly and the path is fraught with peril. In this talk, we'll discuss what a highly-available Docker-powered PHP environment looks like and how to build one. We'll also look at strategies for using Docker and container concepts to avoid getting burned by "disposable" cloud hardware. We'll look at load balancing, service discovery, failover, and talk about tools that make these manageable. We'll also talk about the speed at which the Docker ecosystem is moving and how to cope with that when dealing with production applications.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
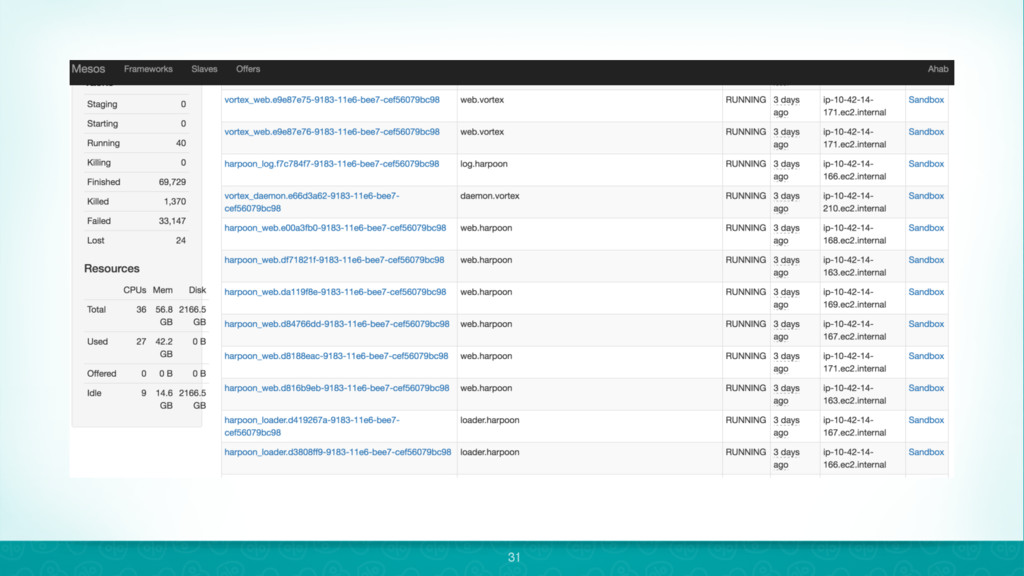{kind=link}
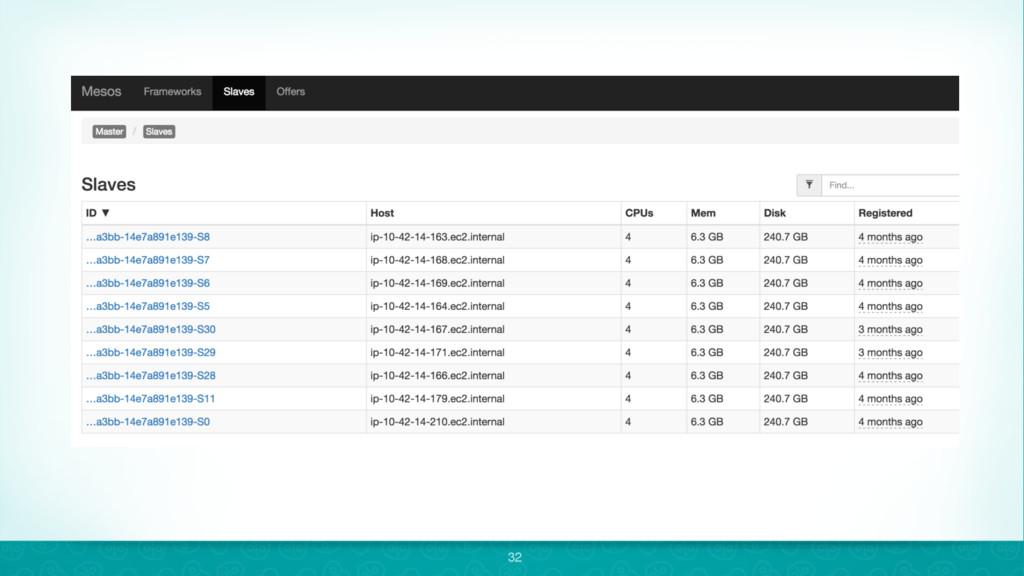{kind=link}
{kind=link}
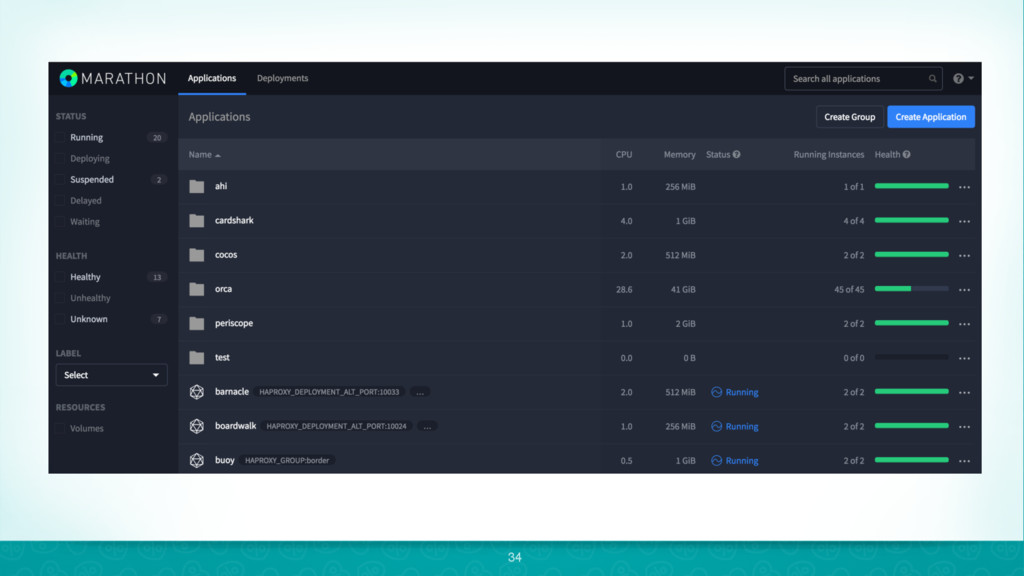{kind=link}
{kind=link}
{kind=link}
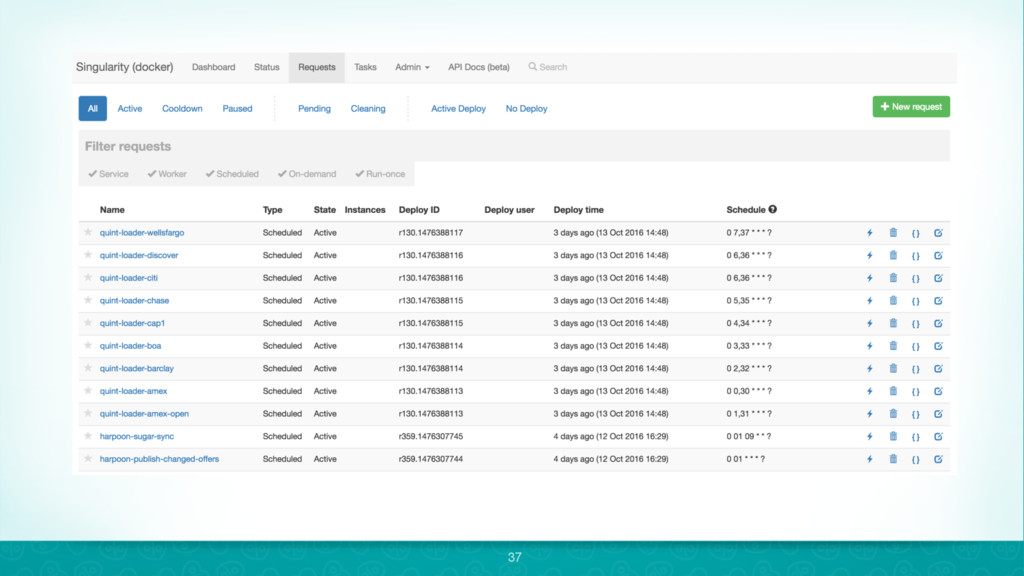{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
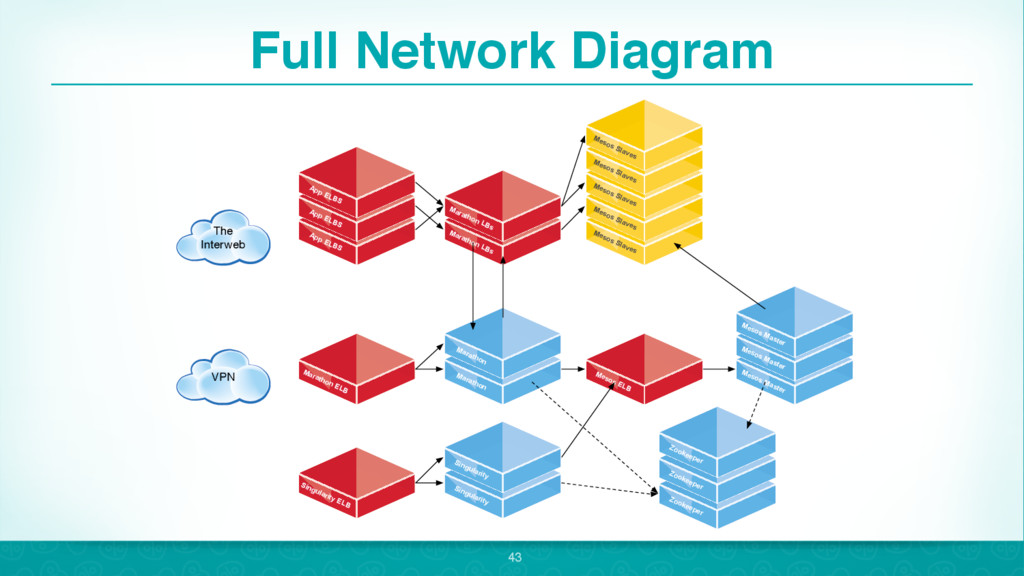{kind=link}
{kind=link}
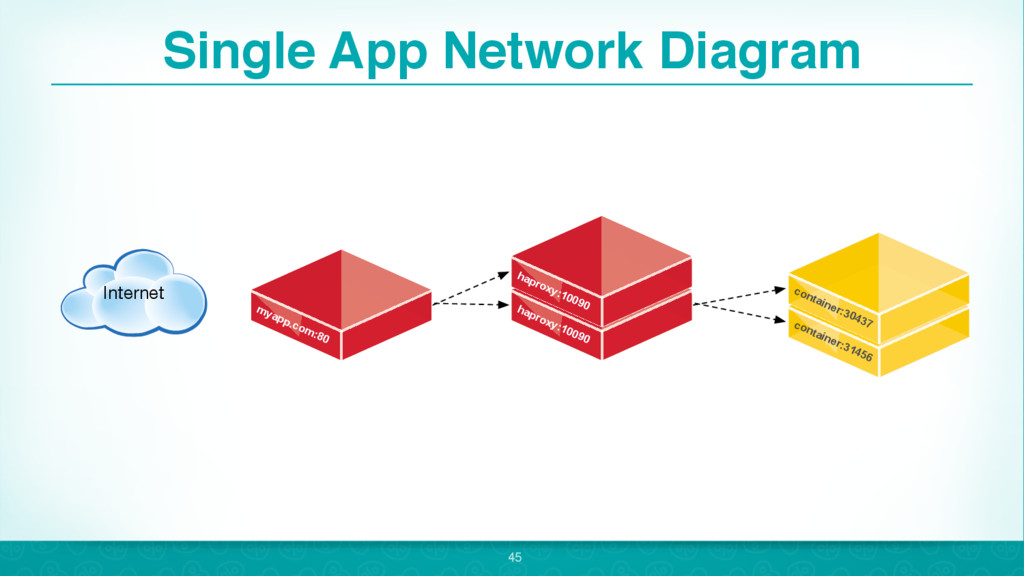{kind=link}
{kind=link}
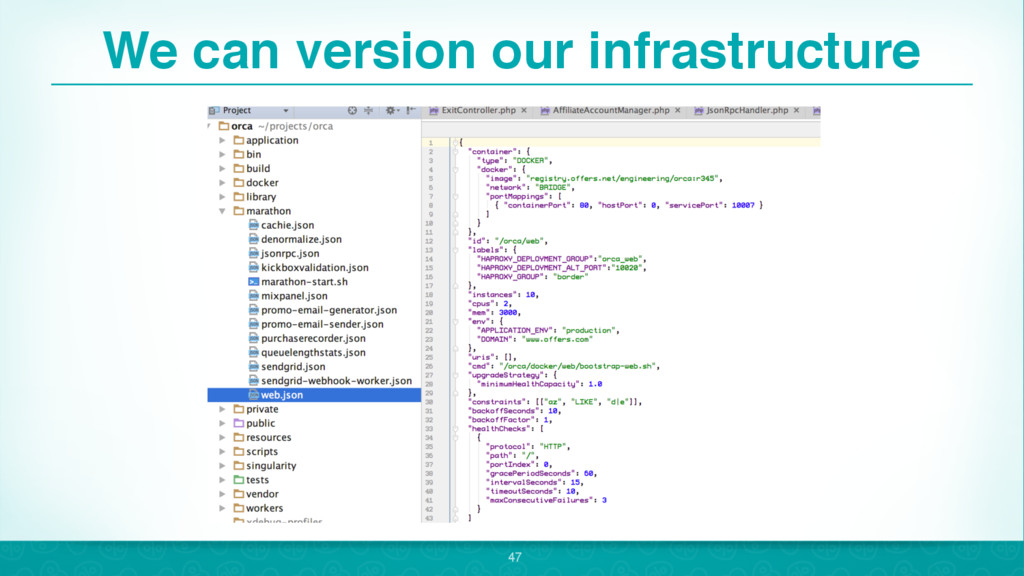{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}