Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
ICML2018読み会 Policy and Value Transfer in Lifelo...
Search
Yuu David Jinnai
July 28, 2018
Research
610
3
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
ICML2018読み会 Policy and Value Transfer in Lifelong Reinforcement Learning
Yuu David Jinnai
July 28, 2018
Other Decks in Research
See All in Research
某助成金プロジェクト採択に向けて企業研究所のアウトリーチ専任者がやったこと
afroscript
0
120
Apache Gravitinoで実現する Icebergカタログ統合とアクセスの一元化
matsumooon
0
350
COMETAを用いたデータ民主化運動の歴史
sazimai
0
130
kintone リサーチ副部/UXリサーチャー 業務紹介
cybozuinsideout
PRO
0
120
AIエージェント時代のLLM-jpモデルのあるべき姿
k141303
0
520
Fukui Shibiten 39 - AI Art
butchi
0
150
東京大学工学部計数工学科、計数工学特別講義の説明資料
kikuzo
0
570
羽田新ルート運用6年の検証
1manken
0
180
多様なデータを許容し学習し続ける模倣学習 / Advanced Imitation Learning for VLA
prinlab
0
250
長時間動画QAにおけるマルチエージェント推論 ・SVAgent: Storyline-Guided Long Video Understanding via Cross-Modal Multi-Agent Collaboration
murakawatakuya
1
160
YOLO26_ Key Architectural Enhancements and Performance Benchmarking for Real-Time Object Detection
satai
3
890
Sequences of Logits Reveal the Low Rank Structure of Language Models
sansantech
PRO
1
290
Featured
See All Featured
Site-Speed That Sticks
csswizardry
13
1.3k
Refactoring Trust on Your Teams (GOTO; Chicago 2020)
rmw
35
3.7k
SERP Conf. Vienna - Web Accessibility: Optimizing for Inclusivity and SEO
sarafernandez
2
1.5k
Between Models and Reality
mayunak
4
380
Navigating Weather and Climate Data
rabernat
0
400
The Power of CSS Pseudo Elements
geoffreycrofte
82
6.5k
Groundhog Day: Seeking Process in Gaming for Health
codingconduct
0
250
XXLCSS - How to scale CSS and keep your sanity
sugarenia
249
1.3M
Conquering PDFs: document understanding beyond plain text
inesmontani
PRO
4
2.9k
How to optimise 3,500 product descriptions for ecommerce in one day using ChatGPT
katarinadahlin
PRO
1
3.7k
Practical Orchestrator
shlominoach
191
11k
[Rails World 2023 - Day 1 Closing Keynote] - The Magic of Rails
eileencodes
38
2.9k
Transcript
Policy and Value Transfer in Lifelong Reinforcement Learning David Abel*,
Yuu Jinnai*, George Konidaris, Michael Littman, Yue Guo Brown University
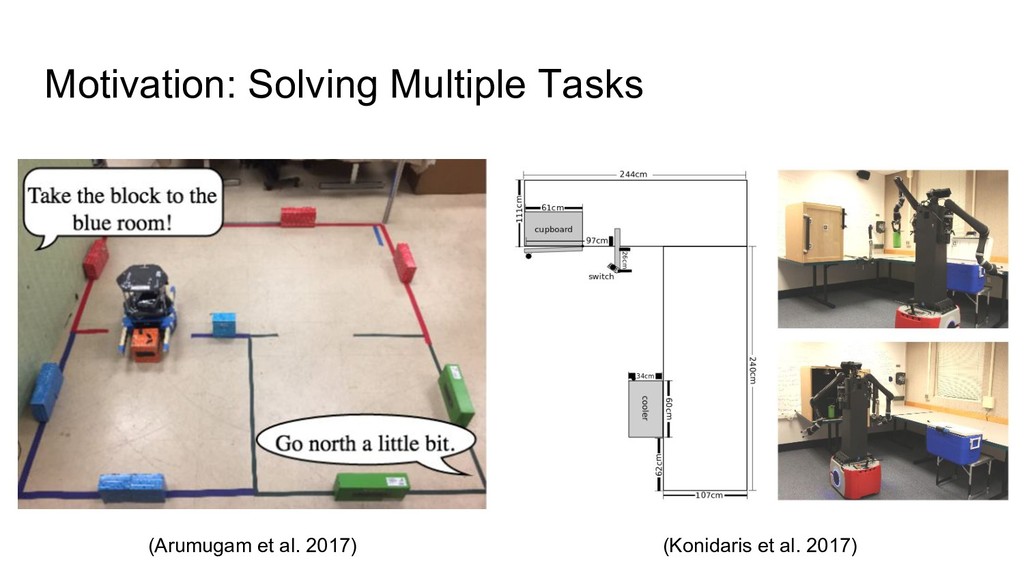
Motivation: Solving Multiple Tasks (Arumugam et al. 2017) (Konidaris et
al. 2017)
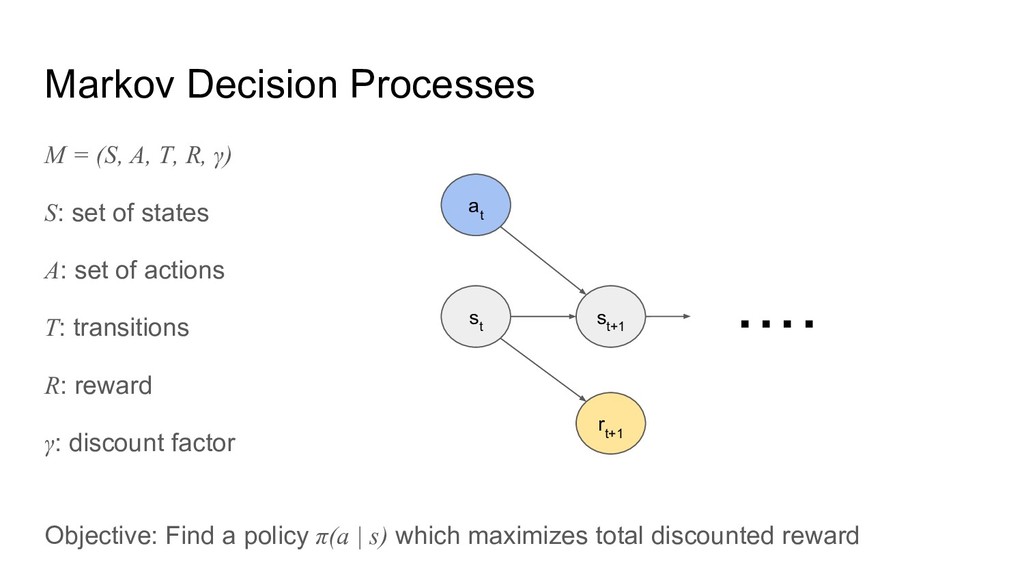
Markov Decision Processes M = (S, A, T, R, γ)
S: set of states A: set of actions T: transitions R: reward γ: discount factor Objective: Find a policy π(a | s) which maximizes total discounted reward s t s t+1 r t+1 a t ・・・・
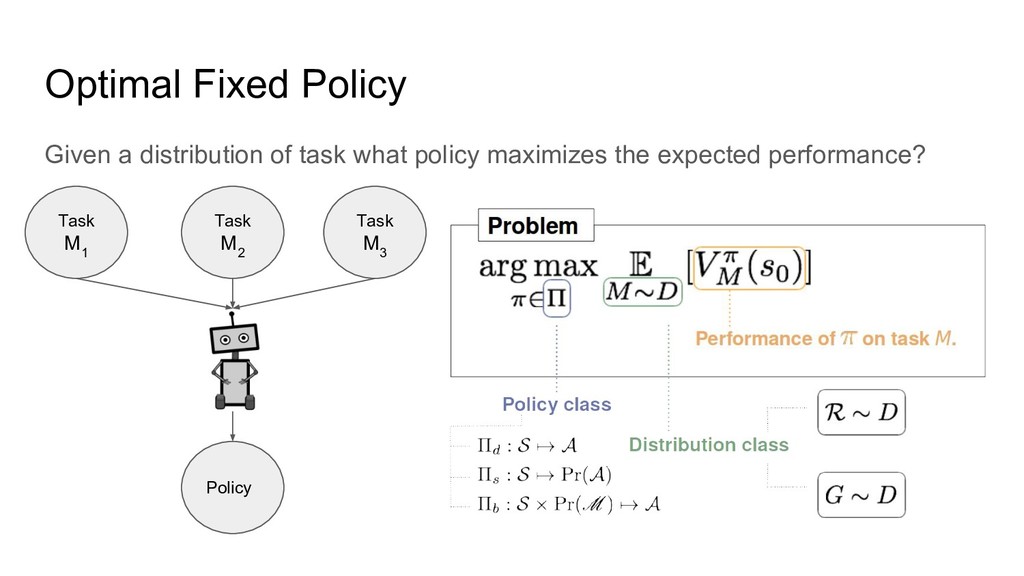
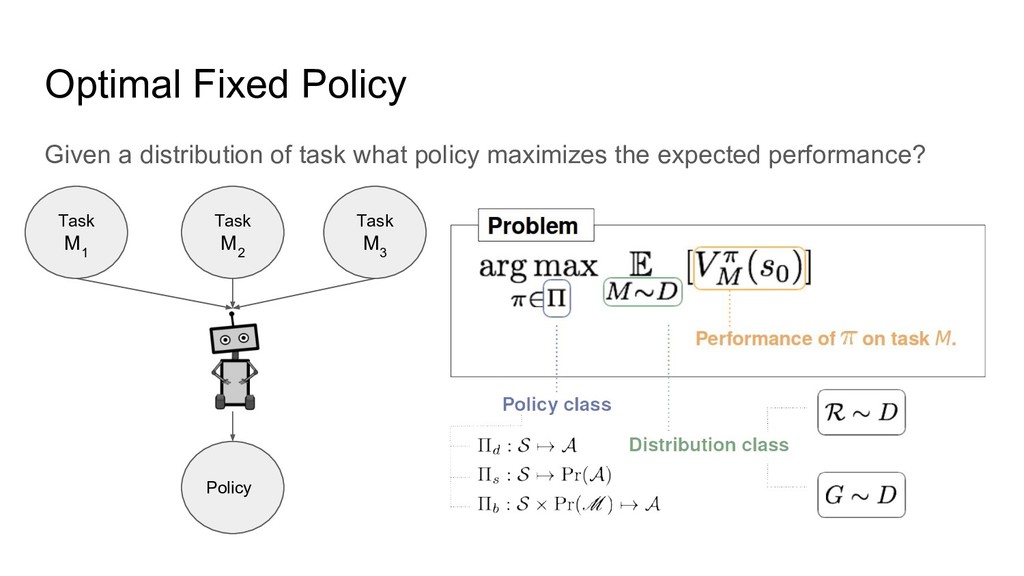
Optimal Fixed Policy Given a distribution of task what policy
maximizes the expected performance? Task M 1 Policy Task M 2 Task M 3
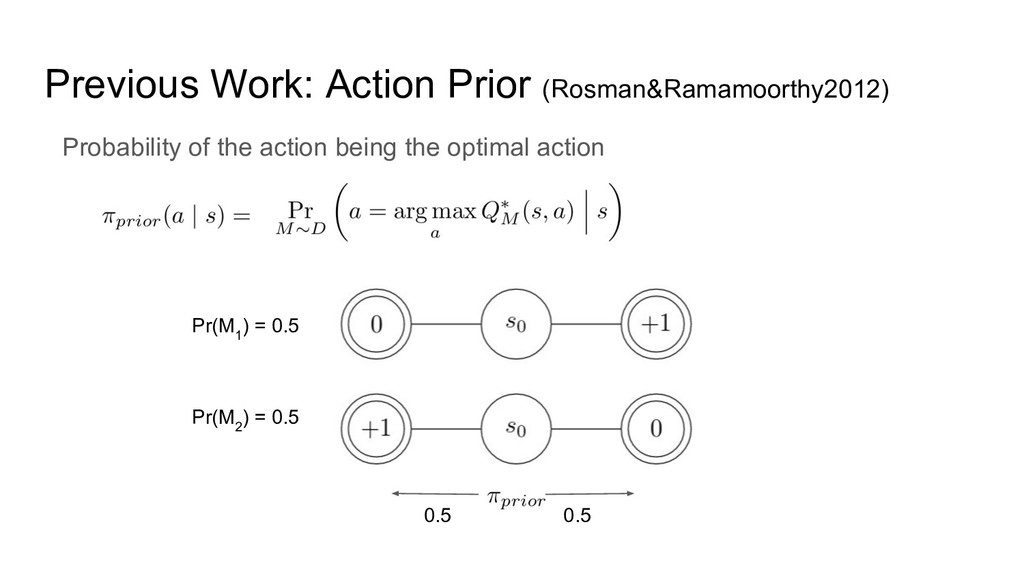
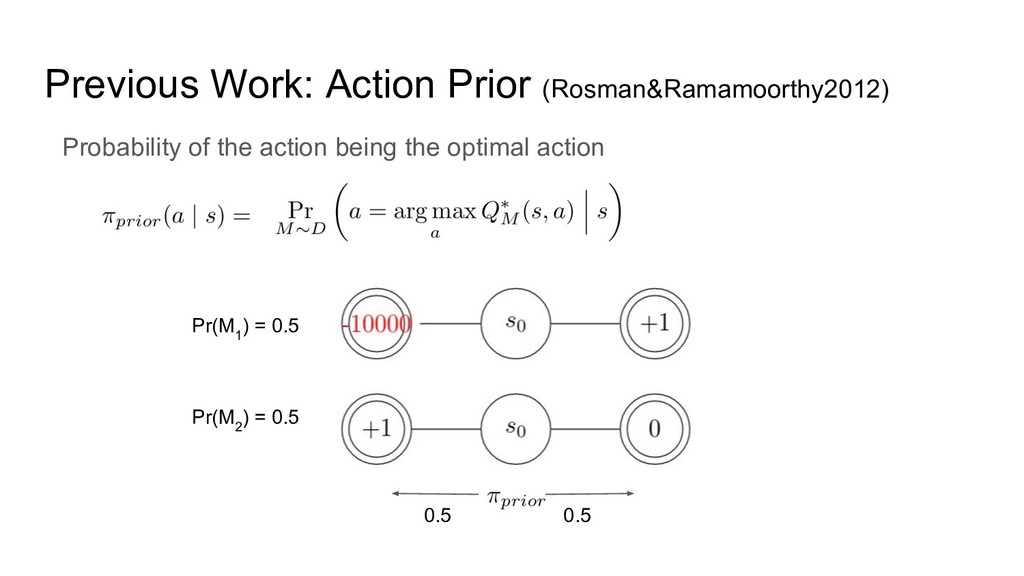
Previous Work: Action Prior (Rosman&Ramamoorthy2012) Pr(M 1 ) = 0.5
Pr(M 2 ) = 0.5 0.5 0.5 Probability of the action being the optimal action
Pr(M 1 ) = 0.5 Pr(M 2 ) = 0.5
Probability of the action being the optimal action Previous Work: Action Prior (Rosman&Ramamoorthy2012) 0.5 0.5
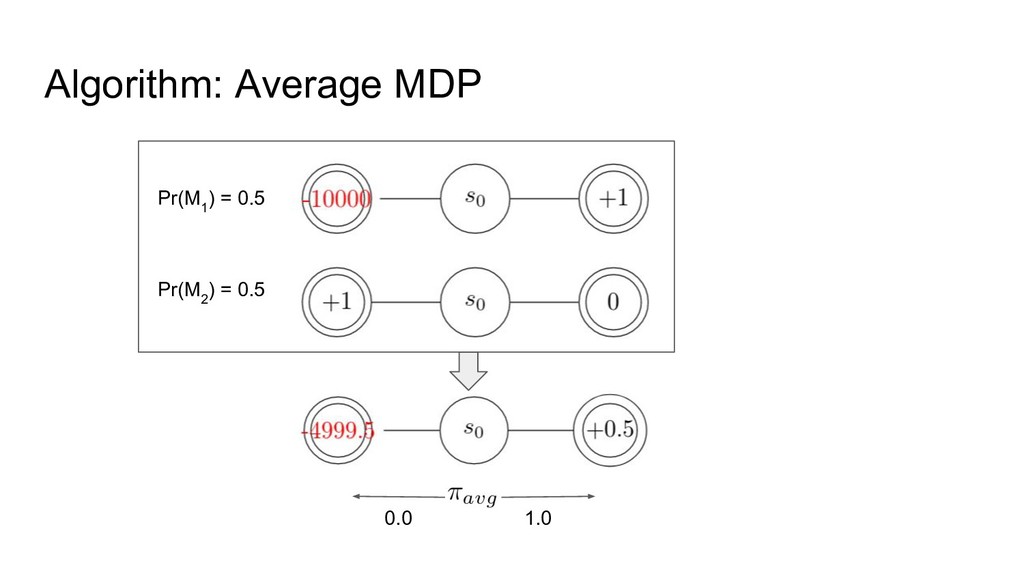
Algorithm: Average MDP Pr(M 1 ) = 0.5 Pr(M 2
) = 0.5 0.0 1.0
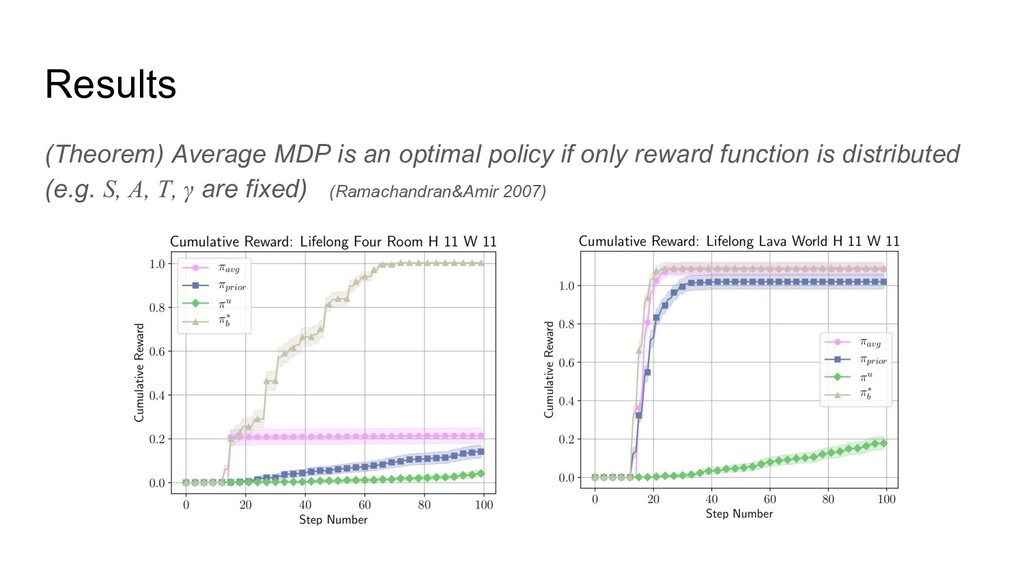
(Theorem) Average MDP is an optimal policy if only reward
function is distributed (e.g. S, A, T, γ are fixed) (Ramachandran&Amir 2007) Results
Optimal Fixed Policy Given a distribution of task what policy
maximizes the expected performance? Task M 1 Policy Task M 2 Task M 3
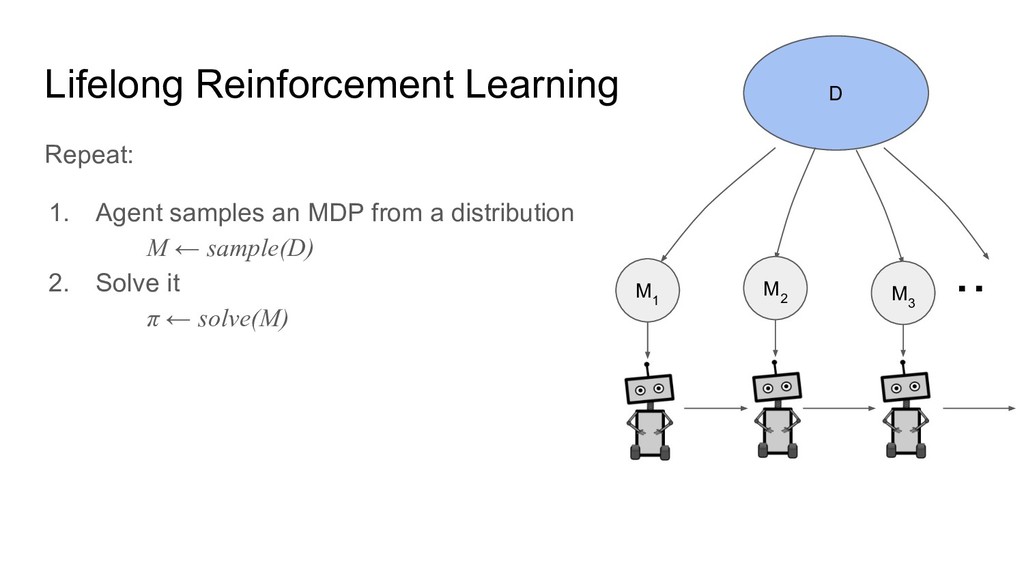
Lifelong Reinforcement Learning D ・・ Repeat: 1. Agent samples an
MDP from a distribution M ← sample(D) 2. Solve it π ← solve(M) M 1 M 2 M 3
Optimistic Initialization (Keans&Singh 2002) Initialize Q-value: Initialize Q-value optimistically to
encourage exploration
PAC-MDP (Strehl et al. ‘09; Rao, Whiteson ‘12; Mann, Choe
‘13) (Theorem) Sample complexity of PAC-MDP algorithms are: IF:
PAC-MDP (Strehl et al. ‘09; Rao, Whiteson ‘12; Mann, Choe
‘13) (Theorem) Sample complexity of PAC-MDP algorithms are: Minimize: the overestimate Subject to:
PAC-MDP (Strehl et al. ‘09; Rao, Whiteson ‘12; Mann, Choe
‘13) (Theorem) Sample complexity of PAC-MDP algorithms are: Minimize: the overestimate Subject to: Solution:
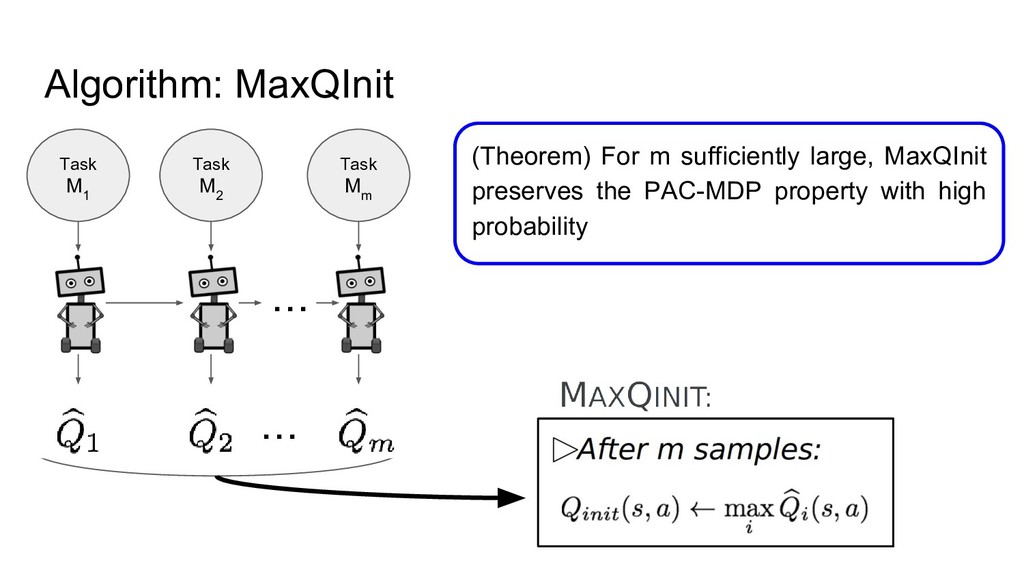
Algorithm: MaxQInit Task M 1 Task M 2 ・・・ Task
M m ・・・ (Theorem) For m sufficiently large, MaxQInit preserves the PAC-MDP property with high probability
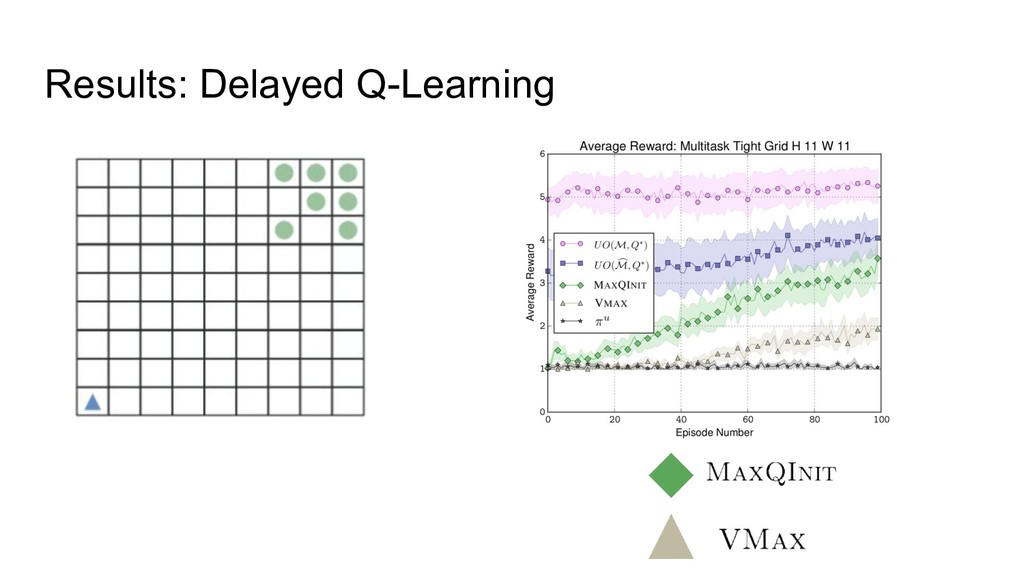
Results: Delayed Q-Learning
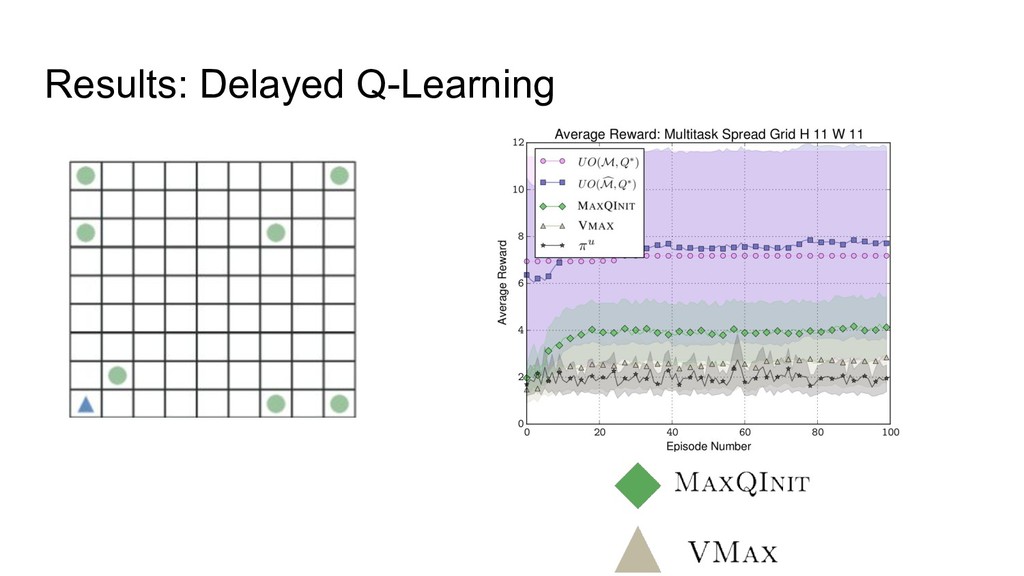
Results: Delayed Q-Learning
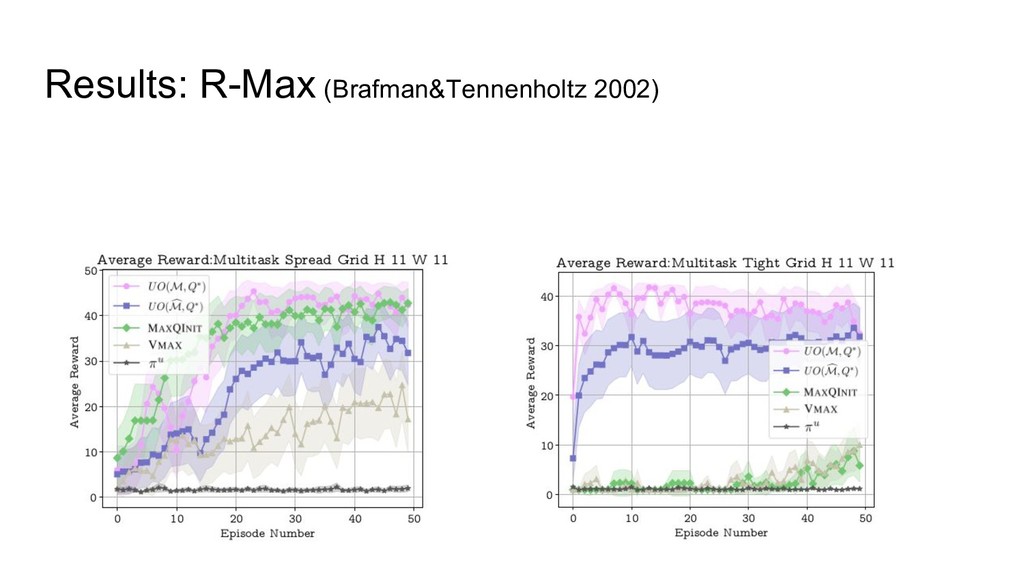
Results: R-Max (Brafman&Tennenholtz 2002)
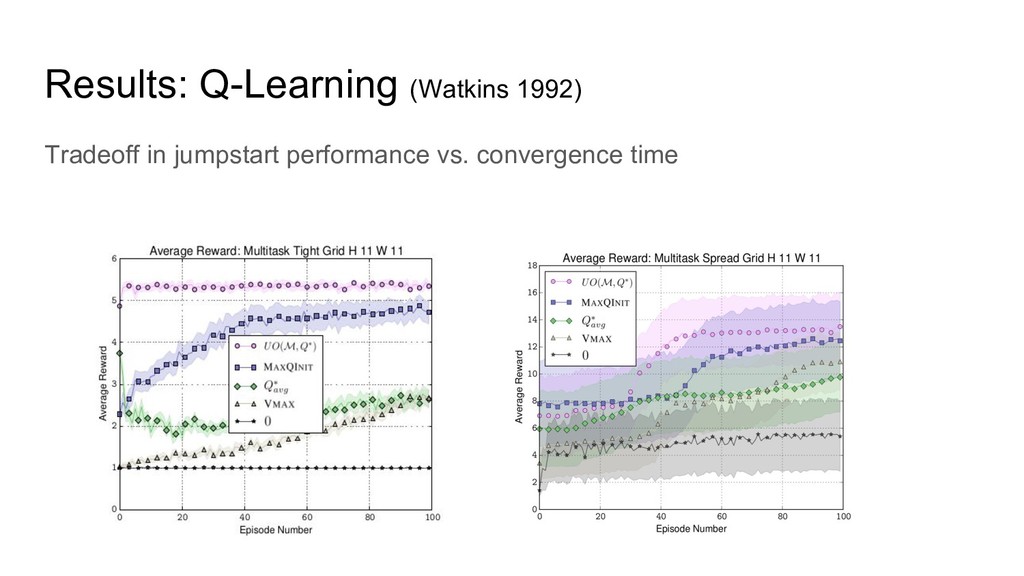
Results: Q-Learning (Watkins 1992) Tradeoff in jumpstart performance vs. convergence
time
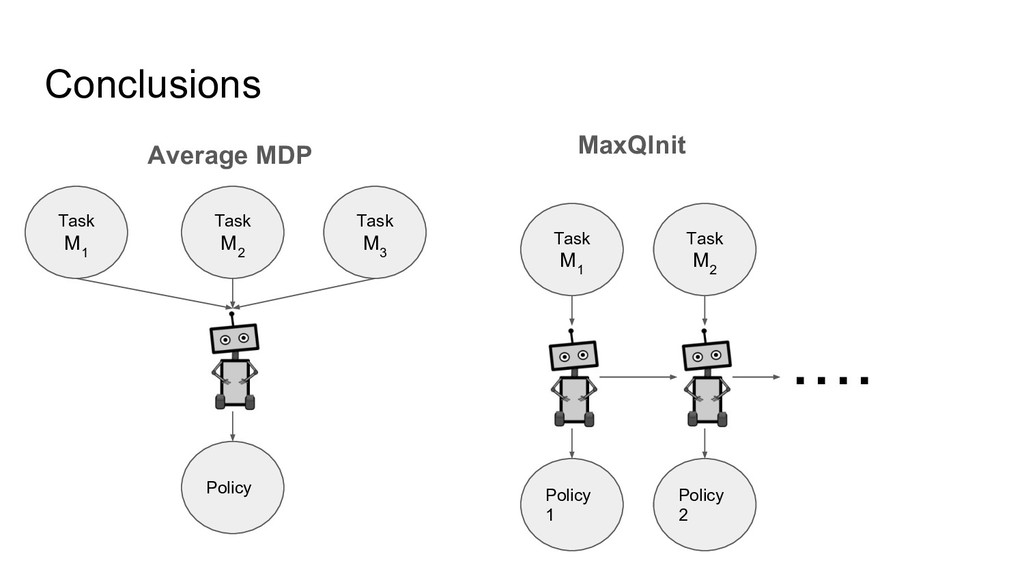
Conclusions Average MDP Task M 1 Policy 1 Task M
2 Policy 2 ・・・・ MaxQInit Task M 1 Policy Task M 2 Task M 3
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
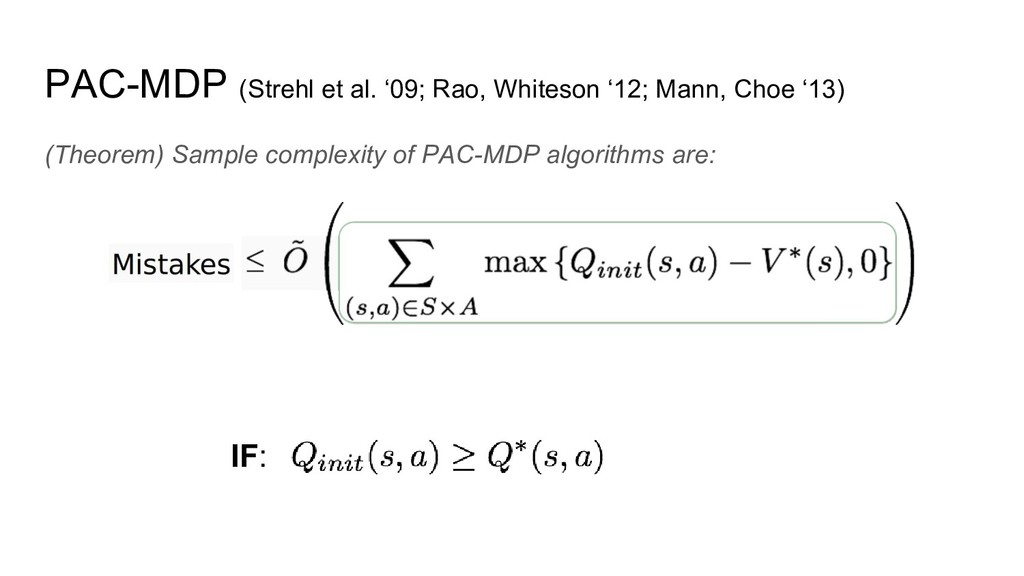{kind=link}
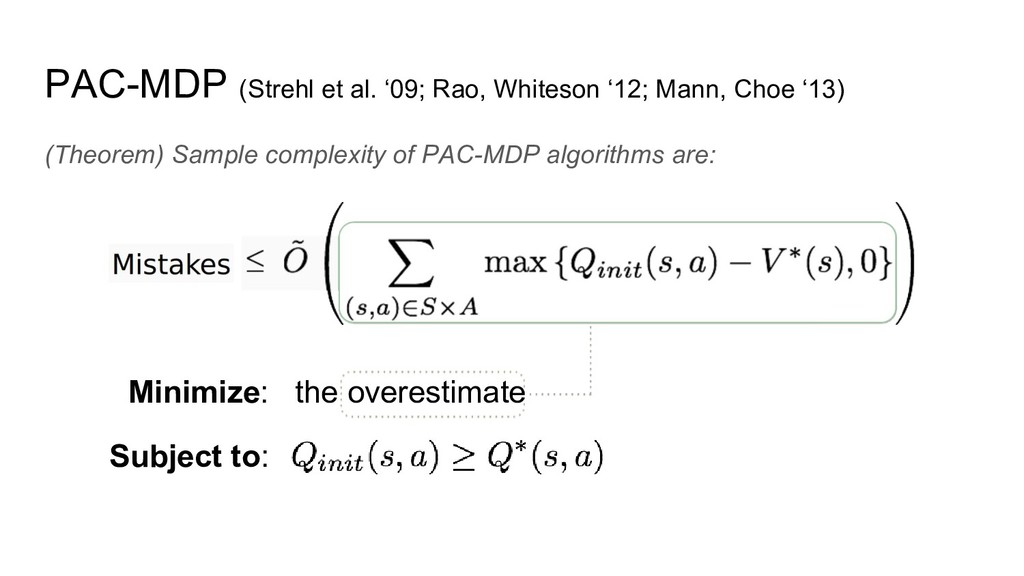{kind=link}
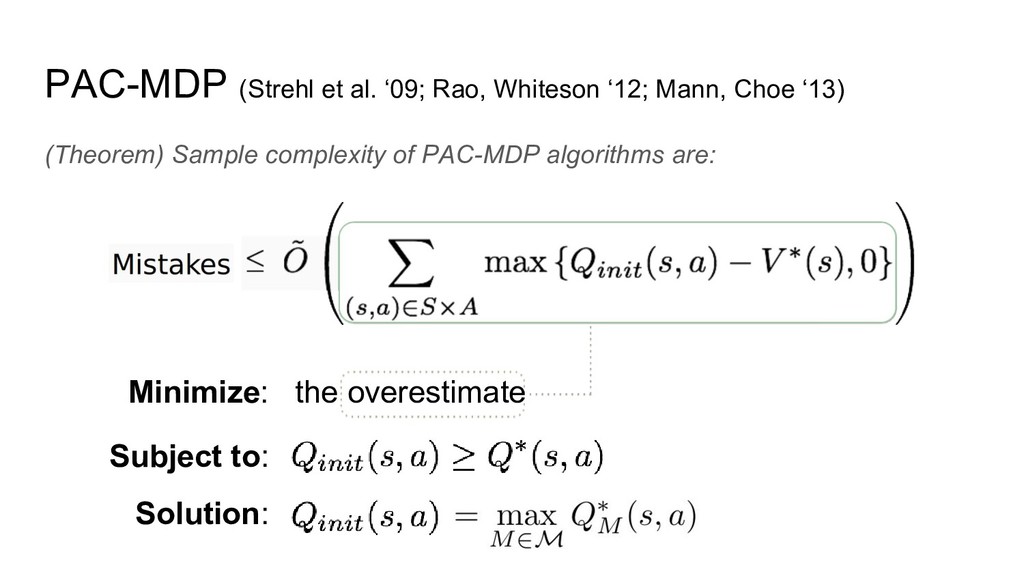{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}