Kazuki Takigawa, Masaki Murata, Masaaki Tsuchida, Stijn De Saeger, Kazuhide Yamamoto and Kentaro Torisawa. Generation of Summaries that Appropriately and Adequately Express the Contents of Original Documents Using Word-Association Knowledge. Proceedings of The 24th Pacific Asia Conference on Language, Information and Computation (PACLIC 24), pp.693-700 (2010.11)
{kind=link}
{kind=link}
{kind=link}
![Related Work Summarization by paraphrasing Kondo et al.[96] ](https://files.speakerdeck.com/presentations/5a92e0e0c5e5013037e02a36d8f42a9e/slide_3.jpg){kind=link}
{kind=link}
{kind=link}
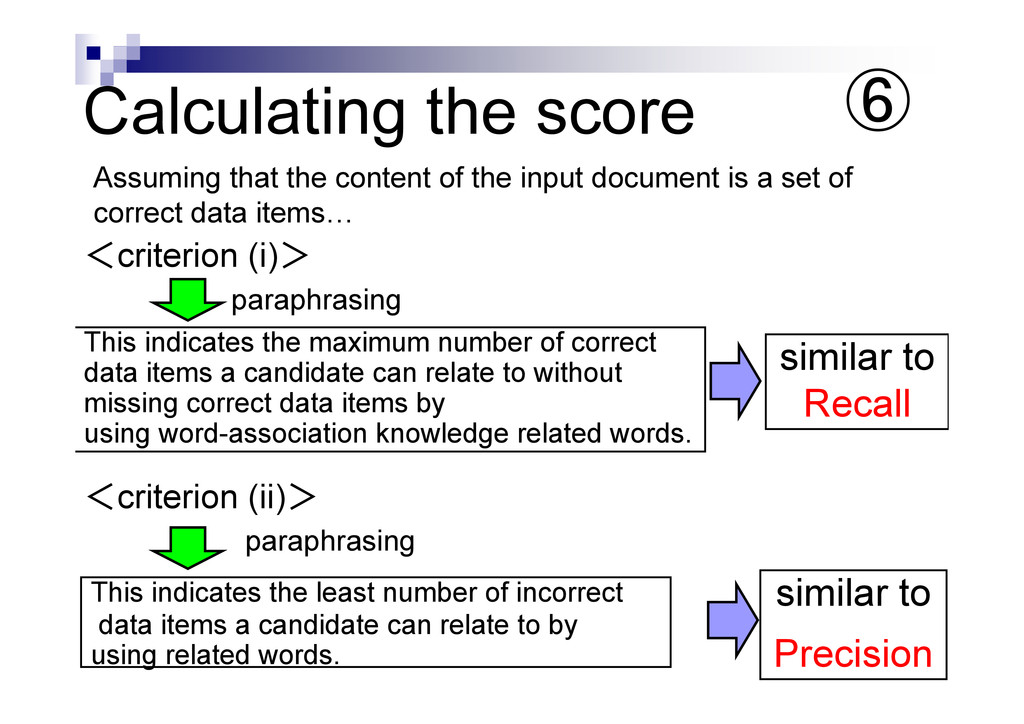{kind=link}
{kind=link}
{kind=link}
{kind=link}
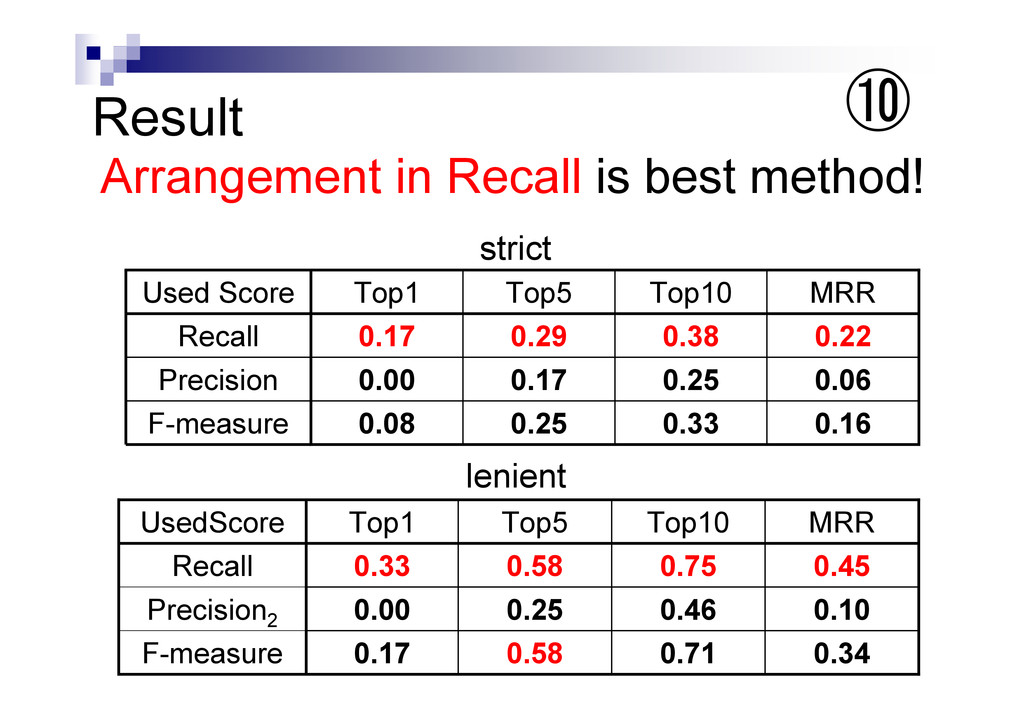{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}