Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
n-gramを用いた日本語テキスト含意認識の検討
Search
自然言語処理研究室
March 31, 2010
Research
130
0
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
n-gramを用いた日本語テキスト含意認識の検討
宇髙 邦弘, 山本 和英. n-gramを用いた日本語テキスト含意認識の検討. 言語処理学会第16回年次大会, pp.462-465 (2010.3)
自然言語処理研究室
March 31, 2010
More Decks by 自然言語処理研究室
See All by 自然言語処理研究室
データサイエンス14_システム.pdf
jnlp
0
420
データサイエンス13_解析.pdf
jnlp
0
530
データサイエンス12_分類.pdf
jnlp
0
370
データサイエンス11_前処理.pdf
jnlp
0
500
Recurrent neural network based language model
jnlp
0
170
自然言語処理研究室 研究概要(2012年)
jnlp
0
160
自然言語処理研究室 研究概要(2013年)
jnlp
0
130
自然言語処理研究室 研究概要(2014年)
jnlp
0
150
自然言語処理研究室 研究概要(2015年)
jnlp
0
230
Other Decks in Research
See All in Research
Spatial Active Noise Control Based on Sound Field Interpolation Incorporating Physical Constraints
skoyamalab
0
120
ScoreMatchingRiesz for Automatic Debiased Machine Learning and Policy Path Estimation with an Application to Japanese Monetary Policy Evaluation
masakat0
0
300
COFFEE-Japan PROJECT Impact Report(Uminomukou Coffee)
ontheslope
0
220
AY 2026 Guide to Academic Writing Using Generative AI - Workshop
ks91
PRO
0
130
通時的な類似度行列に基づく単語の意味変化の分析
rudorudo11
0
330
Anthropic が提案する LLM の内部状態を自然言語で説明可能にした Natural Language Autoencoders / Natural Language Autoencoders Produce Unsupervised Explanations of LLM Activations
shunk031
0
140
敵対生成プロンプト同時探索による内省型プロンプト最適化
kinoue_smarthr
0
280
[BlackHatAsia2026] Hidden Telemetry: Uncovering TraceLogging ETW Providers You're Not Using (Yet)
asuna_jp
1
570
SOTAのさらに先へ:厳しい推論制約下での高性能モデルのPost-Training
analokmaus
0
1.3k
LLM の Attention 機構まとめ — 数式・計算量・メモリ
puwaer
8
2.2k
Φ-Sat-2のAutoEncoderによる情報圧縮系論文
satai
4
820
Fukui Shibiten 39 - AI Art
butchi
0
140
Featured
See All Featured
Why Your Marketing Sucks and What You Can Do About It - Sophie Logan
marketingsoph
0
180
JAMstack: Web Apps at Ludicrous Speed - All Things Open 2022
reverentgeek
1
490
Designing Experiences People Love
moore
143
24k
Information Architects: The Missing Link in Design Systems
soysaucechin
0
1k
Visualization
eitanlees
152
17k
Exploring the relationship between traditional SERPs and Gen AI search
raygrieselhuber
PRO
2
4.1k
The SEO identity crisis: Don't let AI make you average
varn
0
510
Fantastic passwords and where to find them - at NoRuKo
philnash
52
3.8k
Navigating the Design Leadership Dip - Product Design Week Design Leaders+ Conference 2024
apolaine
1
370
Have SEOs Ruined the Internet? - User Awareness of SEO in 2025
akashhashmi
0
380
Public Speaking Without Barfing On Your Shoes - THAT 2023
reverentgeek
1
450
The Language of Interfaces
destraynor
162
27k
Transcript
n-gramを用いた テキスト含意認識の検討 長岡技術科学大学 電気系 山本研究室 宇高 邦弘,山本 和英 ① このPDFはpdfFactory試用版で作成されました
www.nsd.co.jp/share/pdffact
テキスト含意認識とは ・言語表現Aが言語表現Bの意味を含むか (=含意)を判断するタスク ・言語表現Aを「テキスト」,言語表現Bを「仮説」 テキスト :「日本の大豆生産量は世界16位だ」 仮説 :「日本は大豆を生産している」 含意認識 :含意
② このPDFはpdfFactory試用版で作成されました www.nsd.co.jp/share/pdffact
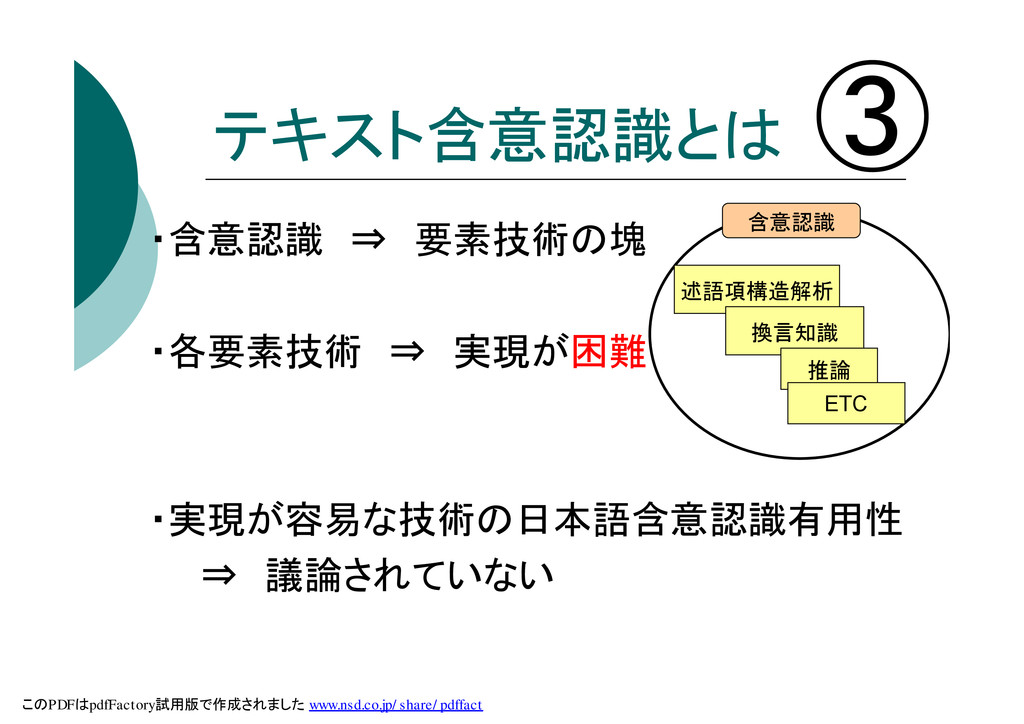
テキスト含意認識とは ・含意認識 ⇒ 要素技術の塊 ・各要素技術 ⇒ 実現が困難 ・実現が容易な技術の日本語含意認識有用性 ⇒ 議論されていない
述語項構造解析 換言知識 推論 含意認識 ETC ③ このPDFはpdfFactory試用版で作成されました www.nsd.co.jp/share/pdffact
n-gramを用いた テキスト含意認識 ・n-gramによるテキスト比較 ⇒ 実装が容易 ・日本語テキスト含意認識において, n-gramのみを用いた含意認識研究はない n-gramから得られる情報のみを利用して 含意認識 ⇒
認識精度評価 ④ このPDFはpdfFactory試用版で作成されました www.nsd.co.jp/share/pdffact
・言い換え表現の述語項構造解析への正規化と テキスト含意関係認識での利用 [小谷ら 09] ・言語表現を述語項構造に正規化 「数学を勉強する」 → 勉強する <ヲ格>数学 ・述語項構造を単位に2文間の一致をとる
先行研究 ⑤ このPDFはpdfFactory試用版で作成されました www.nsd.co.jp/share/pdffact
使用するn-gram ・単語,自立語,文節の3つの要素を使用 言語表現「私は働く」 1)単語 → 私 は 働く 2)自立語 →
私 働く 3)文節 → 私は 働く ・要素数(n) 1~3まで使用 ⑥ このPDFはpdfFactory試用版で作成されました www.nsd.co.jp/share/pdffact
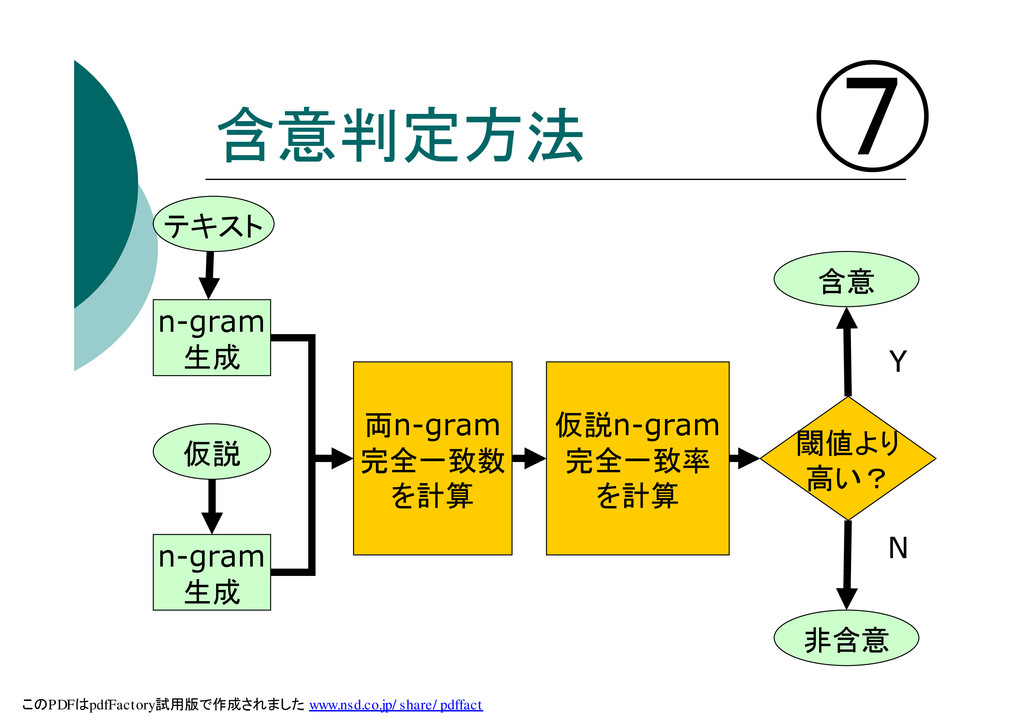
含意判定方法 ⑦ テキスト n-gram 生成 n-gram 生成 仮説 両n-gram 完全一致数
を計算 仮説n-gram 完全一致率 を計算 閾値より 高い? 含意 非含意 Y N このPDFはpdfFactory試用版で作成されました www.nsd.co.jp/share/pdffact
本システムでの 含意認識例 テキスト :太郎 に 本 を 借り た が
無く し た 仮説 :太郎 に 本 を 借り た 単語2グラム,閾値50%の場合 a h a:両n-gram完全一致数 h:完全一致するn-gramと仮説n-gramの被覆数 ⑧ ×100 = 100 > 50 含意している このPDFはpdfFactory試用版で作成されました www.nsd.co.jp/share/pdffact
評価実験 ・テストセットを人手で作成 (テキストと仮説のペアを104個作成) ・テストセットは予め人間によって含意判定済み (含意,非含意ペア52個ずつで構成) ・閾値は10%~100%まで10%刻みで設定 ⑨ このPDFはpdfFactory試用版で作成されました www.nsd.co.jp/share/pdffact
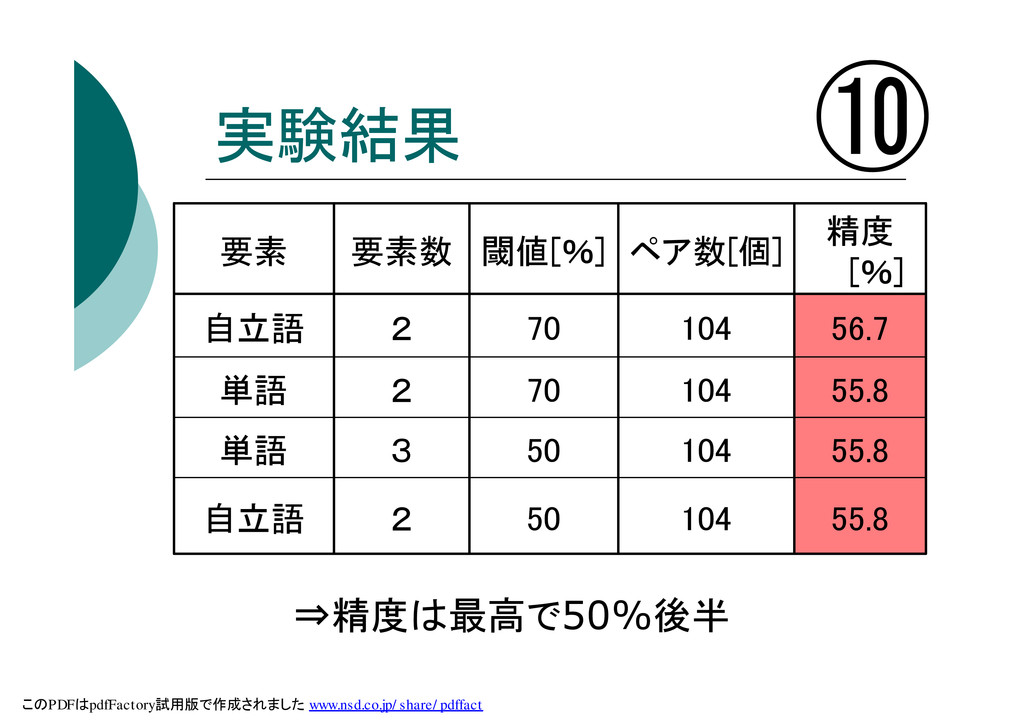
実験結果 ⑩ 55.8 104 50 2 自立語 55.8 104 50
3 単語 55.8 104 70 2 単語 56.7 104 70 2 自立語 精度 [%] ペア数[個] 閾値[%] 要素数 要素 ⇒精度は最高で50%後半 このPDFはpdfFactory試用版で作成されました www.nsd.co.jp/share/pdffact
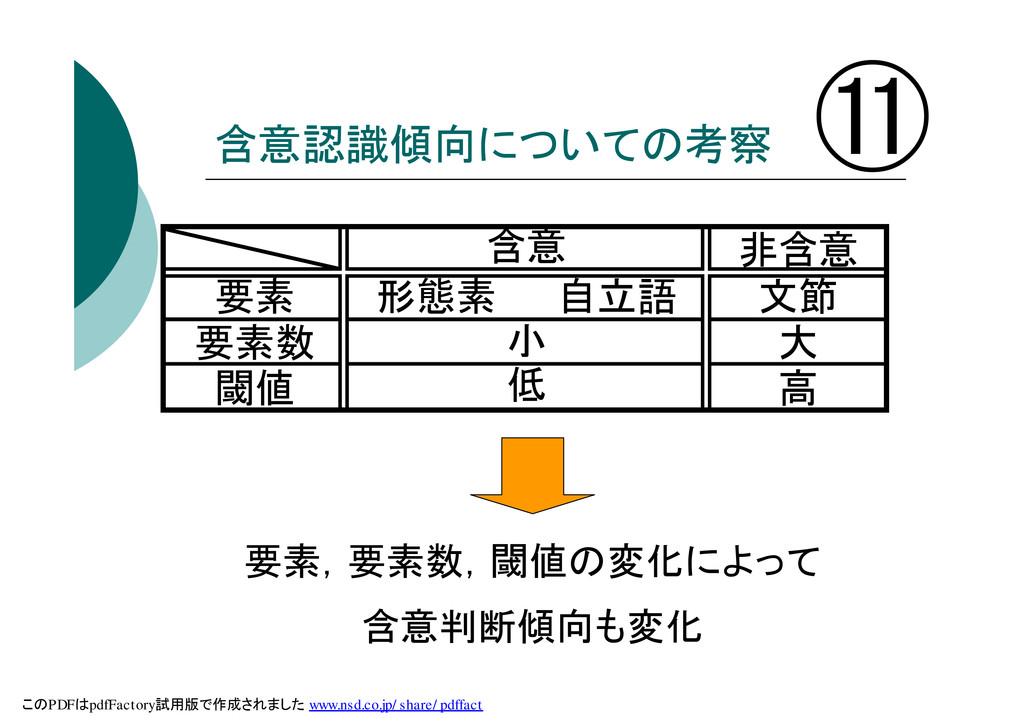
含意認識傾向についての考察 ⑪ 非含意 要素 形態素 自立語 文節 要素数 大 閾値
高 含意 小 低 要素,要素数,閾値の変化によって 含意判断傾向も変化 このPDFはpdfFactory試用版で作成されました www.nsd.co.jp/share/pdffact
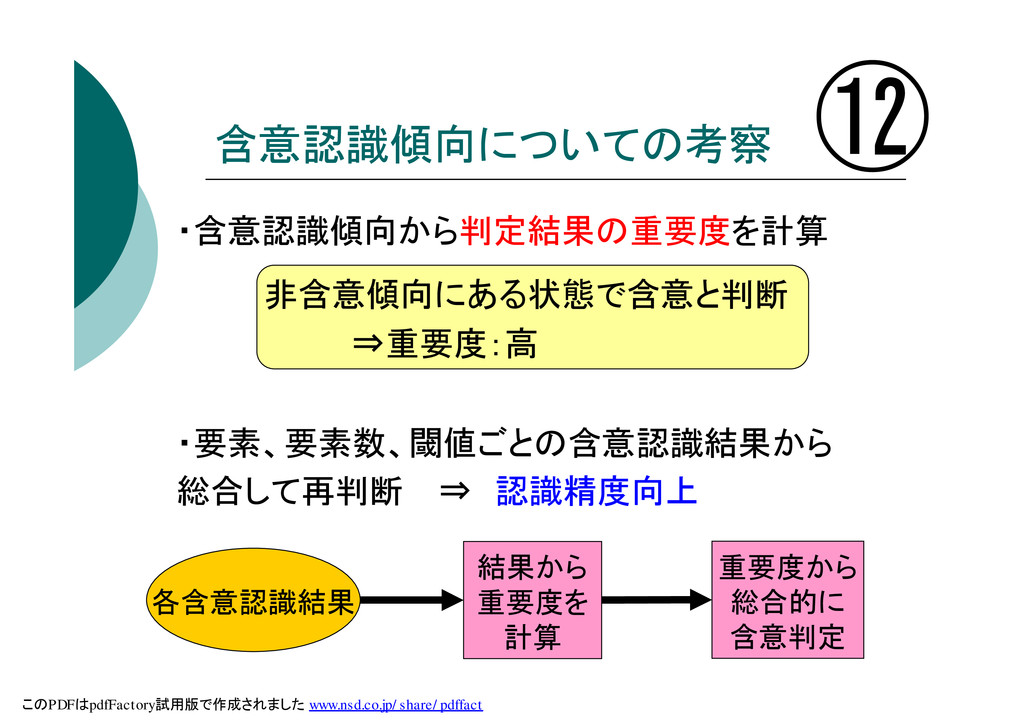
含意認識傾向についての考察 ・含意認識傾向から判定結果の重要度を計算 非含意傾向にある状態で含意と判断 ⇒重要度:高 ・要素、要素数、閾値ごとの含意認識結果から 総合して再判断 ⇒ 認識精度向上 ⑫ 結果から
重要度を 計算 重要度から 総合的に 含意判定 各含意認識結果 このPDFはpdfFactory試用版で作成されました www.nsd.co.jp/share/pdffact
認識失敗例についての考察 ・換言知識を必要とする例 テキスト:芭蕉布作りは労多くて骨の折れる仕事です 仮説 :芭蕉布は作るのが難しい ・否定表現が存在する例 テキスト :岡下さんに大きな怪我はなかった 仮説 :岡下さんは大きな怪我をした
⇒共に特別な処理,知識を必要とする ⑬ このPDFはpdfFactory試用版で作成されました www.nsd.co.jp/share/pdffact
結論 ・n-gramを用いてテキスト含意認識を行った →精度は最高で5割程度 ・生じる問題を理解 →換言関係や否定表現などの問題 今回の検討を下に,更なる精度向上を 目指す ⑭ このPDFはpdfFactory試用版で作成されました www.nsd.co.jp/share/pdffact
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![・言い換え表現の述語項構造解析への正規化と テキスト含意関係認識での利用 [小谷ら 09] ・言語表現を述語項構造に正規化 「数学を勉強する」 → 勉強する <ヲ格>数学 ・述語項構造を単位に2文間の一致をとる](https://files.speakerdeck.com/presentations/db2d8130c6030130c09b7a88047019d1/slide_4.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}