Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
文書生成のための文の並べ替え
Search
Sponsored
·
Your Podcast. Everywhere. Effortlessly.
Share. Educate. Inspire. Entertain. You do you. We'll handle the rest.
→
自然言語処理研究室
March 31, 2009
Research
220
0
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
文書生成のための文の並べ替え
大田 浩志, 山本 和英. 文書生成のための文の並べ替え. 言語処理学会第15回年次大会, pp.813-816 (2009.3)
自然言語処理研究室
March 31, 2009
More Decks by 自然言語処理研究室
See All by 自然言語処理研究室
データサイエンス14_システム.pdf
jnlp
0
410
データサイエンス13_解析.pdf
jnlp
0
530
データサイエンス12_分類.pdf
jnlp
0
370
データサイエンス11_前処理.pdf
jnlp
0
500
Recurrent neural network based language model
jnlp
0
170
自然言語処理研究室 研究概要(2012年)
jnlp
0
160
自然言語処理研究室 研究概要(2013年)
jnlp
0
130
自然言語処理研究室 研究概要(2014年)
jnlp
0
150
自然言語処理研究室 研究概要(2015年)
jnlp
0
230
Other Decks in Research
See All in Research
Claude Code × autoresearch 実践
mathbullet
0
170
セマンティック通信勉強会 6Gに向けたデバイス間効率的な通信の技術紹介・課題・今後展望
satai
3
170
Data Visualization Tools in the Age of AI
flekschas
0
160
COFFEE-Japan PROJECT Impact Report(海ノ向こうコーヒー)
ontheslope
0
2k
適応的スパムフィルタのための軽量な類似メッセージカウンタ / jsai2026-adaptive-spam-filter
monochromegane
0
3.8k
YOLO26_ Key Architectural Enhancements and Performance Benchmarking for Real-Time Object Detection
satai
3
810
[IR Reading 2026春 論文紹介] LLM-based Listwise Reranking under the Effect of Positional Bias (ECIR 2026) /IR-Reading-2026-Spring
koheishinden
PRO
0
120
東京大学工学部計数工学科、計数工学特別講義の説明資料
kikuzo
0
500
Unified Audio Source Separation (Defense Slides)
kohei_1979
1
620
Fukui Shibiten 39 - AI Art
butchi
0
130
2026 東京科学大 情報通信系 研究室紹介 (大岡山)
icttitech
0
3.8k
Can We Teach Logical Reasoning to LLMs? – An Approach Using Synthetic Corpora (AAAI 2026 bridge keynote)
morishtr
1
260
Featured
See All Featured
Hiding What from Whom? A Critical Review of the History of Programming languages for Music
tomoyanonymous
2
870
Pawsitive SEO: Lessons from My Dog (and Many Mistakes) on Thriving as a Consultant in the Age of AI
davidcarrasco
0
170
We Are The Robots
honzajavorek
0
250
世界の人気アプリ100個を分析して見えたペイウォール設計の心得
akihiro_kokubo
PRO
72
40k
Balancing Empowerment & Direction
lara
6
1.2k
Visualization
eitanlees
152
17k
Crafting Experiences
bethany
1
190
Chrome DevTools: State of the Union 2024 - Debugging React & Beyond
addyosmani
10
1.2k
[SF Ruby Conf 2025] Rails X
palkan
2
1.1k
Speed Design
sergeychernyshev
33
1.9k
AI Search: Where Are We & What Can We Do About It?
aleyda
0
7.6k
Templates, Plugins, & Blocks: Oh My! Creating the theme that thinks of everything
marktimemedia
31
2.8k
Transcript
文書生成のための 文の並べ替え 長岡技術科学大学 電気系 大田浩志, 山本和英 1
背景と目的 • 文の並び順は文書の読みやすさに影響をあたえる [Barzilay et al.,02] • 自動で文を尤もらしい順に並べる = 文書生成
文脈を統計的にとらえることを考える 並べ替え対象による異なりを調査する 2
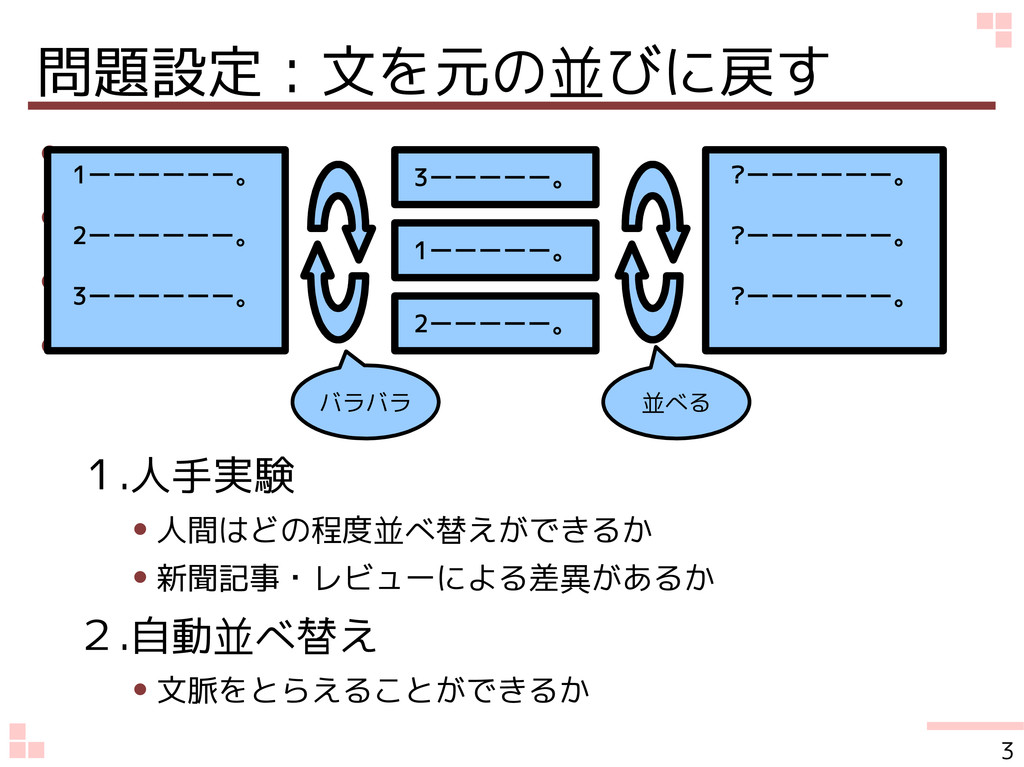
問題設定:文を元の並びに戻す • • • • 1.人手実験 • 人間はどの程度並べ替えができるか • 新聞記事・レビューによる差異があるか
2.自動並べ替え • 文脈をとらえることができるか 3 1ーーーーーー。 2ーーーーーー。 3ーーーーーー。 3ーーーーー。 1ーーーーー。 2ーーーーー。 ?ーーーーーー。 ?ーーーーーー。 ?ーーーーーー。 バラバラ 並べる
関連研究 複数文書要約 • 要約元文書の時間情報等を用いた並べ替え [Mckeown et al.,1999] • 複数の手法を組み合わせることで並べ替え精度向上 [Bollegala
et al.,05] 4
予備実験・人手による文の並べ替え(1) • 目的 • 2つの対象の性質の違いを確認 新聞記事 レビュー • 実験方法 •
文順序をバラバラにして提示、並べ替え • 並べ替えを行ったあと自己評価 5
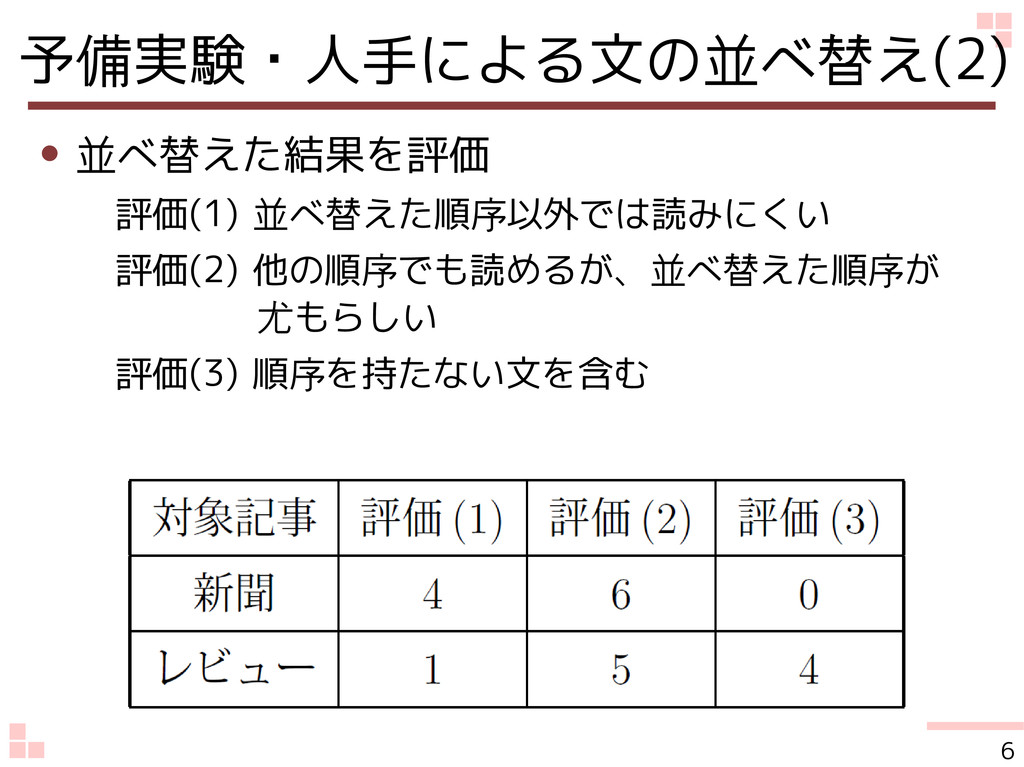
予備実験・人手による文の並べ替え(2) • 並べ替えた結果を評価 評価(1) 並べ替えた順序以外では読みにくい 評価(2) 他の順序でも読めるが、並べ替えた順序が 尤もらしい 評価(3)
順序を持たない文を含む 6
予備実験・人手による文の並べ替え(3) • 相関値:元々の順序 - 並べ替え順序 • ケンドールの順位相関係数τ 文順序の尤もらしさの自動評価に有効[Lapata,05] 7
予備実験・人手による文の並べ替え(4) • レビューは新聞記事と比較して、 • 文の並びの自由度が高い =決まった構成がない(or少ない) • 統計的にとらえることができるもの • 新聞:新聞の構造、文書らしさ
• レビュー:文書らしさ(文脈) 8
既存手法 • 統計による文の並べ替え[Lapata,03] • 文の連接しやすさ • 文の連接確率 を 単語の連接確率の積 で表す
Sentence S i : S j : Word 9
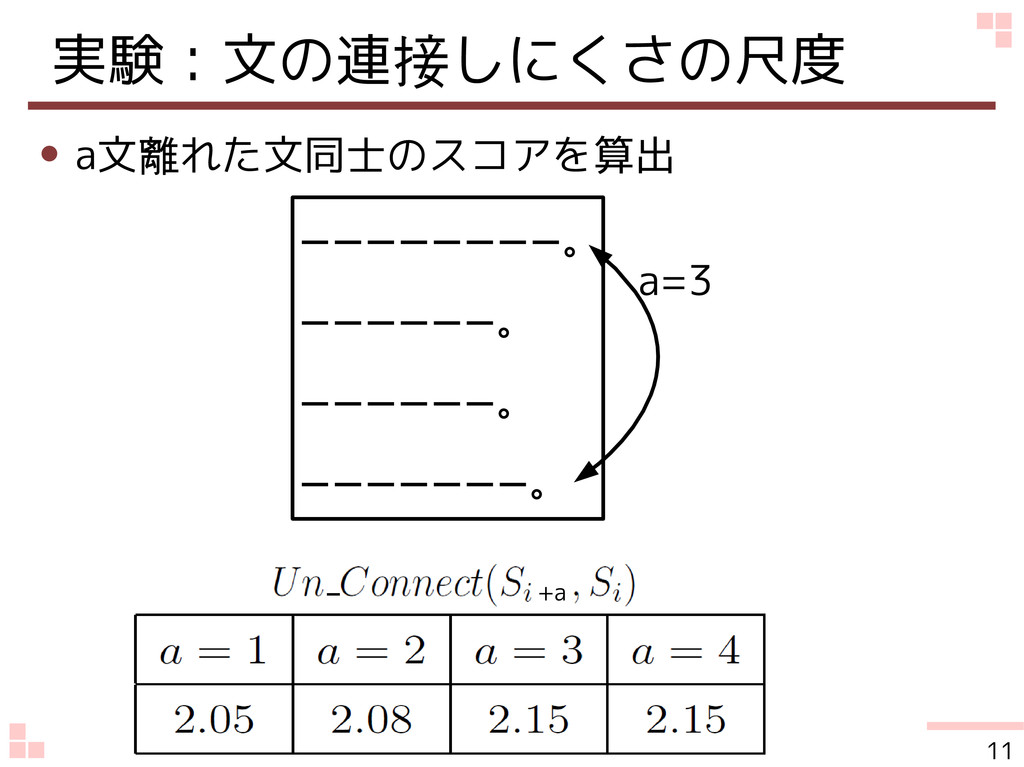
提案:文の連接しにくさの尺度 文の連接しにくさ • 単語の連接しにくさの総加平均 • 単語の連接しにくさ 連続する2文における共起 1文書内での共起 f(a,b): a,bの共起頻度
N:文書数 10
実験:文の連接しにくさの尺度 • a文離れた文同士のスコアを算出 ーーーーーーーー。 ーーーーーー。 ーーーーーー。 ーーーーーーー。 a=3 +a 11
提案手法による文の並べ替え • 文の連接しにくさ だけでは並べ替えはできない • 相互情報量に基づく指標 • 方向を持たない • 単語の連接しやすさと単語の連接しにくさを
併せて用いる 12
実験:異なる文数のレビュー • 学習はレビュー • 相関係数τ 13
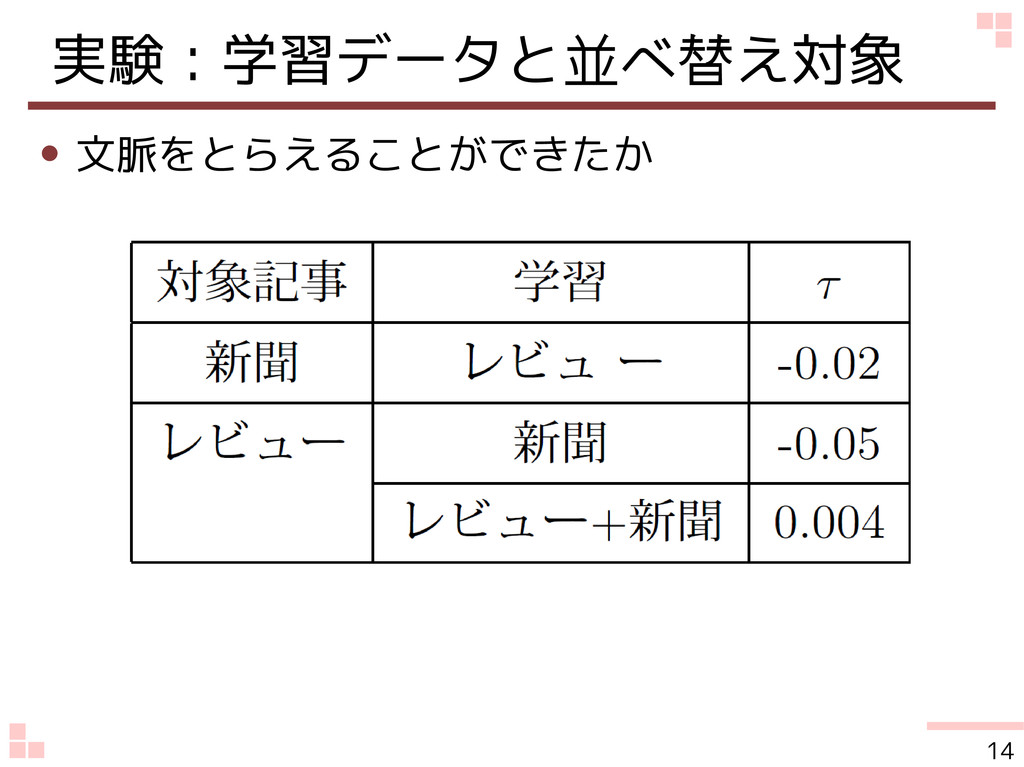
実験:学習データと並べ替え対象 • 文脈をとらえることができたか 14
まとめ • 統計情報を用いた文の並べ替え手法を提案 • 文の連接しにくさの尺度を提案 • 既存手法とは異なる結果 • 新聞記事とレビュー記事を並べ替え •
レビューの文順序は自由度が高い • 生成したい文書を考慮した学習データの選択が必要 15
計算式:ケンドールの順位相関係数 • 文書1:1,2,3 • 文書2:2,1,3 • I=1
計算式:PMI • f(a <i,j> ):i文目のj個目の単語aの出現回数 • N d :文書dの総数
{kind=link}
![背景と目的 • 文の並び順は文書の読みやすさに影響をあたえる [Barzilay et al.,02] • 自動で文を尤もらしい順に並べる = 文書生成](https://files.speakerdeck.com/presentations/203a4200c605013037e12a36d8f42a9e/slide_1.jpg){kind=link}
{kind=link}
![関連研究 複数文書要約 • 要約元文書の時間情報等を用いた並べ替え [Mckeown et al.,1999] • 複数の手法を組み合わせることで並べ替え精度向上 [Bollegala](https://files.speakerdeck.com/presentations/203a4200c605013037e12a36d8f42a9e/slide_3.jpg){kind=link}
{kind=link}
{kind=link}
![予備実験・人手による文の並べ替え(3) • 相関値:元々の順序 - 並べ替え順序 • ケンドールの順位相関係数τ 文順序の尤もらしさの自動評価に有効[Lapata,05] 7](https://files.speakerdeck.com/presentations/203a4200c605013037e12a36d8f42a9e/slide_6.jpg){kind=link}
{kind=link}
![既存手法 • 統計による文の並べ替え[Lapata,03] • 文の連接しやすさ • 文の連接確率 を 単語の連接確率の積 で表す](https://files.speakerdeck.com/presentations/203a4200c605013037e12a36d8f42a9e/slide_8.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}