User behaviour modeling for data prefetching in web applications
A description of method which can be used for reducing the latency in web applications and speculative prefetching. Method proposed by Codete in an internal research project.
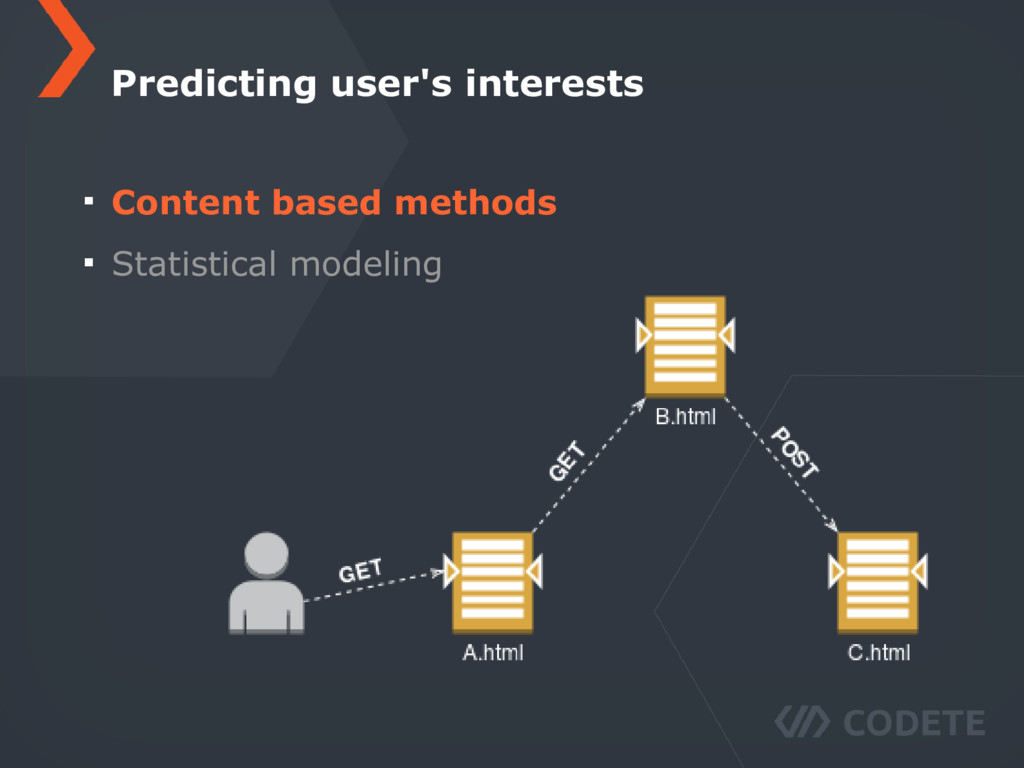
similar manner over time A majority of modern web application uses multiple HTTP calls to fully generate the content Each request increases total latency perceived by a particular user
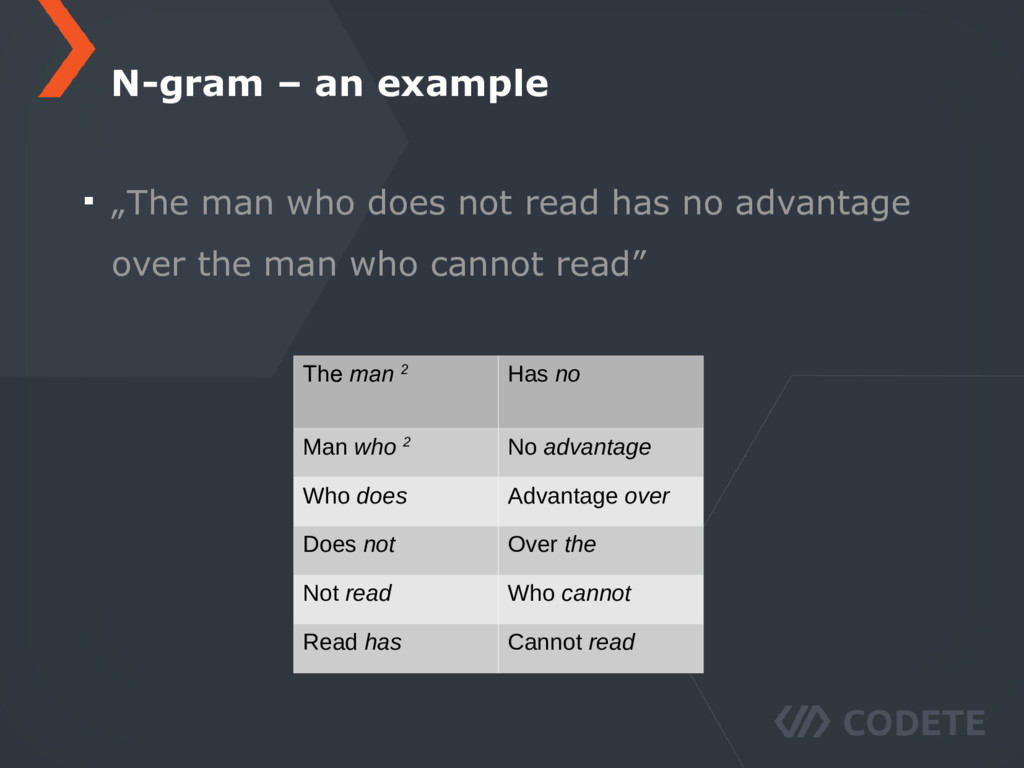
has no advantage over the man who cannot read” The man 2 Has no Man who 2 No advantage Who does Advantage over Does not Over the Not read Who cannot Read has Cannot read
done in standard n-gram architecture But this time, n is a minimal length of a sequence, not a fixed length Such strategy usually leads to more accurate predictions N-gram+
has no advantage over the man who cannot read” The man who does not read has no advantage over the man who cannot read The man Has no The man who does not read cannot Man who No advantage Man who does not read has no advantage over the man who cannot read Who does Advantage over ... Does not Over the ... Not read Who cannot ... Read has Cannot read
protocol HTTP delivers 9 methods – each one has a different meaning (GET, HEAD, PUT, POST, DELETE, OPTIONS, TRACE, CONNECT, PATCH) A proposal of extension
one session: ➔ No relation at all ➔ Request or response tokens of second action are taken from the first one ➔ Tokens are filled using some external knowledge ➔ Value of the token in the second action might be calculated from the values of the first one A proposal of extension - relations
one session: ➔ No relation at all ➔ Request or response tokens of second action are taken from the first one ➔ Tokens are filled using some external knowledge ➔ Value of the token in the second action might be calculated from the values of the first one A proposal of extension - relations
action performed by the user Try to find the relations between the actions that often take place in the similar order Use only the actions that do not change anything (GET, HEAD) A proposal of extension - contd
used to process them Tokenize each request and response Using some n-gram-like architecture, try to find the relations within the subsequences (request/response request) → Collect the statistics of token values in the requests A proposal of extension – an algorithm
endpoint that will be used in the next step Having the endpoint, fill the tokens using relations to previous actions If not all the tokens can be filled, use the statistics of the values Perform the action(s) using predicted values of tokens Send aggregated responses at once A proposal of extension – an algorithm
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}