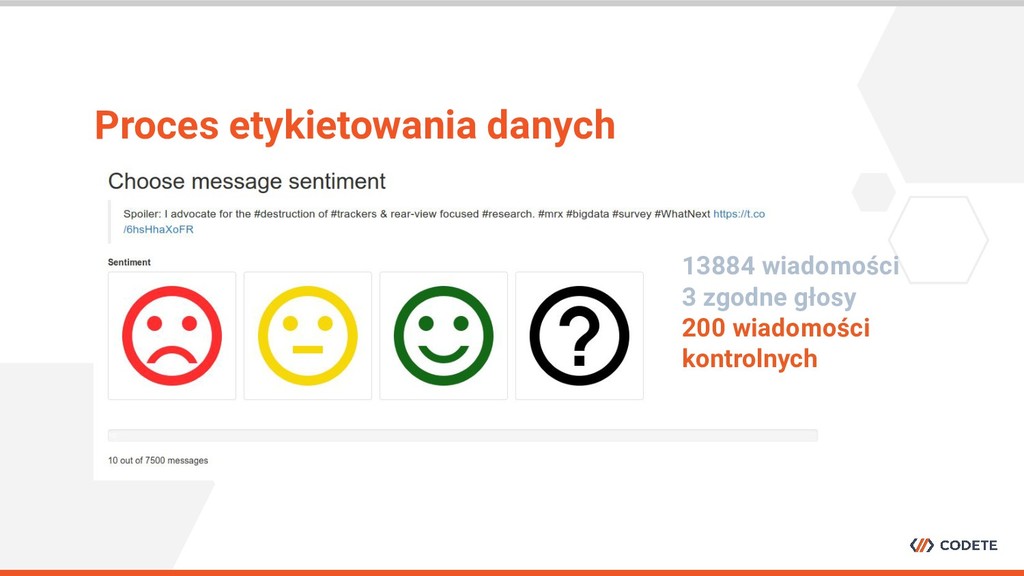
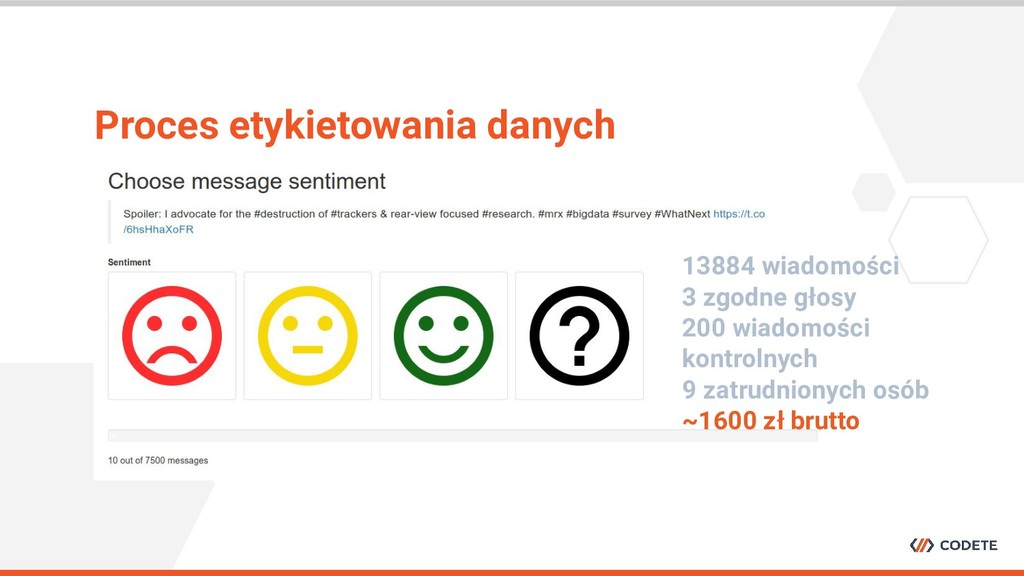
• Do nauczania modeli ML potrzebujemy danych • W przypadku niektórych modeli ciągle potrzebujemy mieć poetykietowane przykłady • Crowdsourcing to proces wykorzystywania mądrości tłumu Czym tak właściwie jest crowdsourcing?
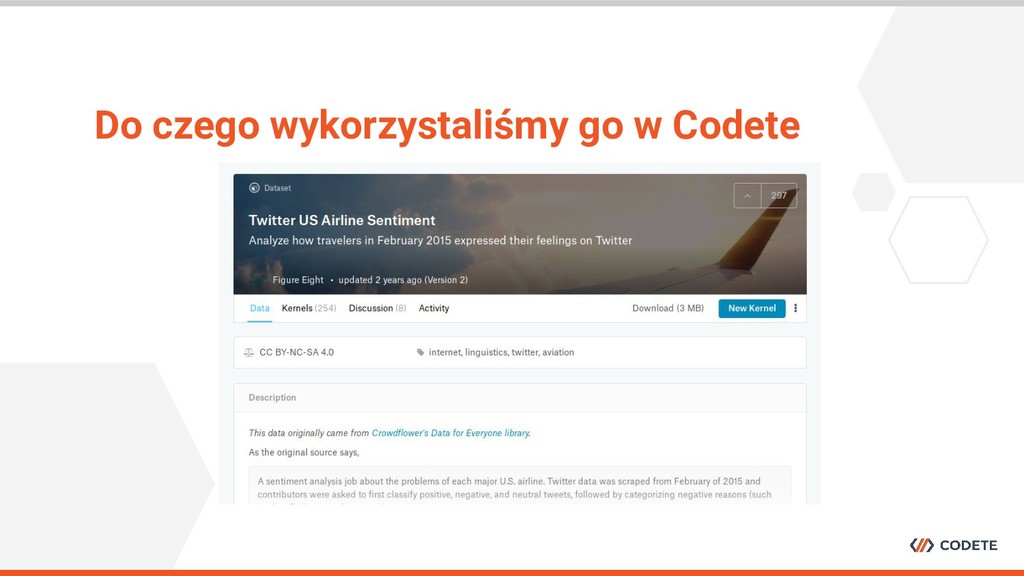
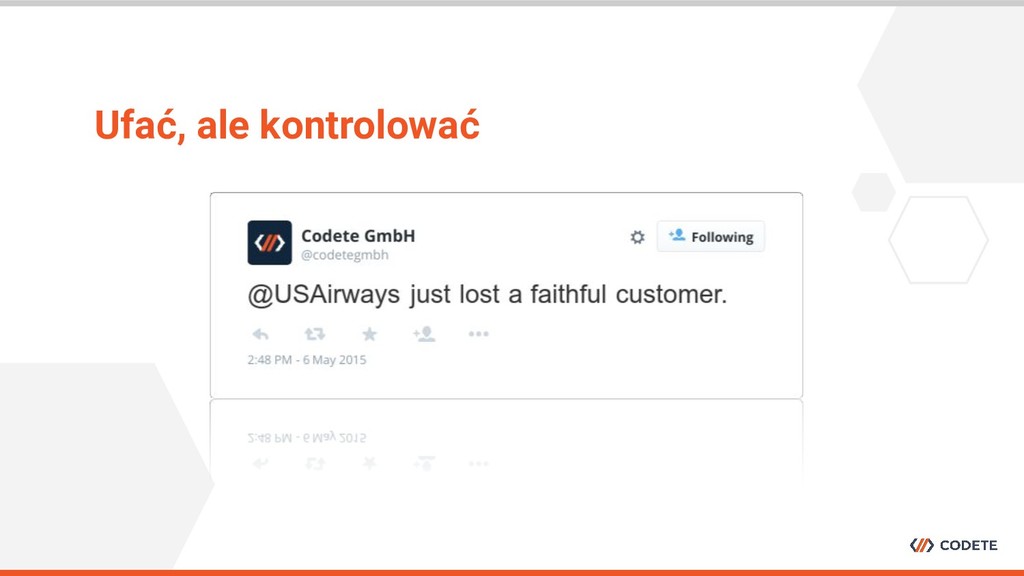
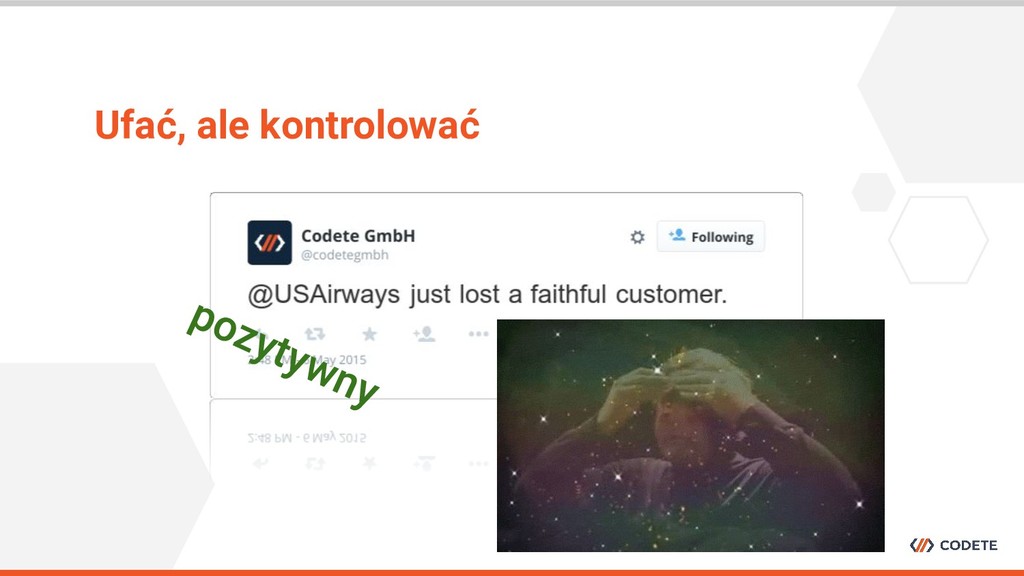
konferencjach IT - wybór padł na monitorowanie mediów społecznościowych w celu analizowania tego w jaki sposób postrzegane jest dane wydarzenie. Do czego wykorzystaliśmy go w Codete
gotowych narzędzi do analizy sentymentu (OpenNLP) • Faza druga: Napiszemy własne rozwiązanie, ale wykorzystamy publiczne dane • Faza trzecia: Potrzebujemy danych dopasowanych do problemu. Zbierzmy je sami! Nie można wymagać od systemu opartego o ML, że nauczy się generalizować i rozpoznawać język którego nigdy nie widział.
gotowych narzędzi do analizy sentymentu (OpenNLP) • Faza druga: Napiszemy własne rozwiązanie, ale wykorzystamy publiczne dane • Faza trzecia: Potrzebujemy danych dopasowanych do problemu. Zbierzmy je sami! Nie można wymagać od systemu opartego o ML, że nauczy się generalizować i rozpoznawać język którego nigdy nie widział.
gotowych narzędzi do analizy sentymentu (OpenNLP) • Faza druga: Napiszemy własne rozwiązanie, ale wykorzystamy publiczne dane • Faza trzecia: Potrzebujemy danych dopasowanych do problemu. Zbierzmy je sami! Nie można wymagać od systemu opartego o ML, że nauczy się generalizować i rozpoznawać język którego nigdy nie widział.
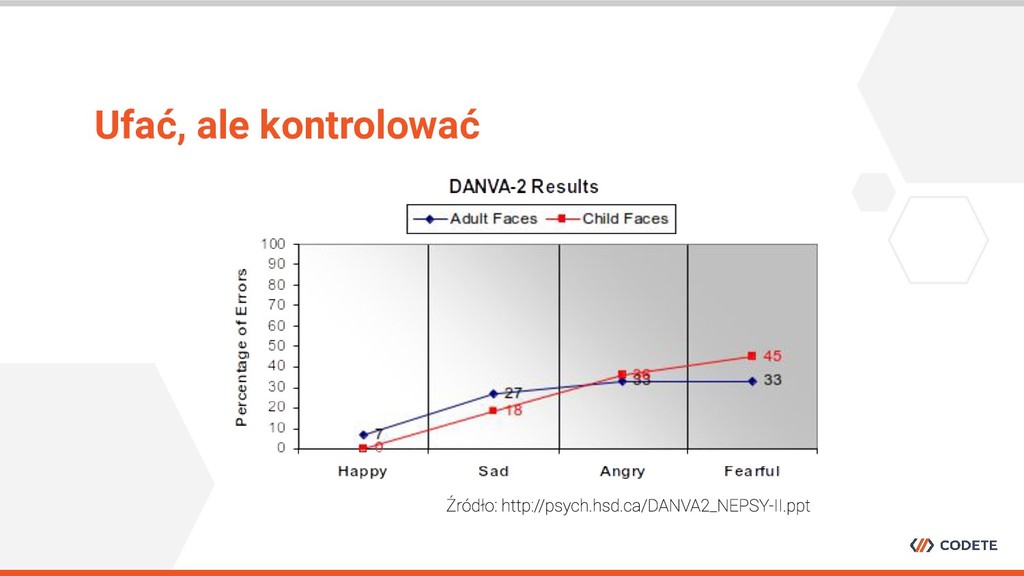
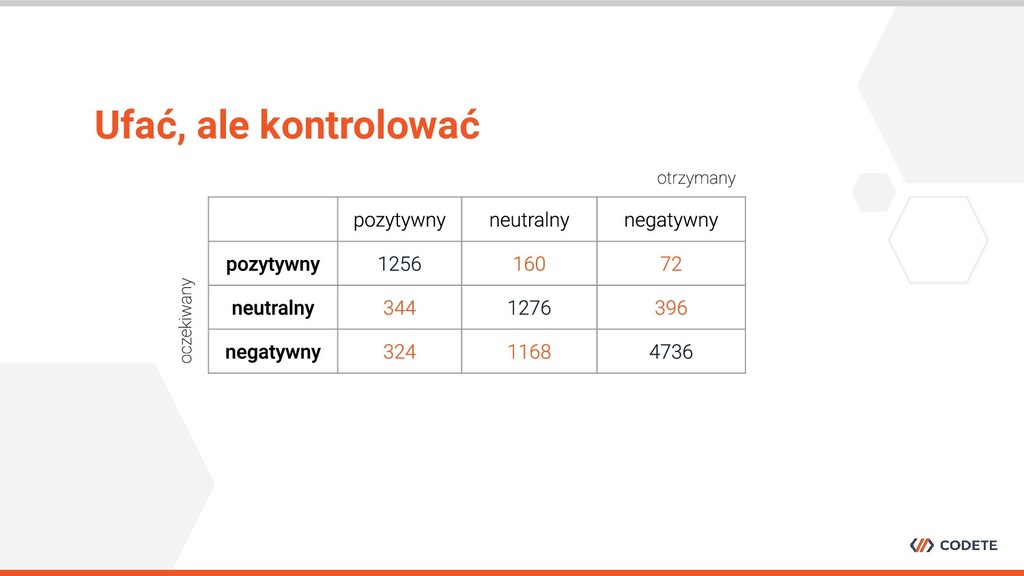
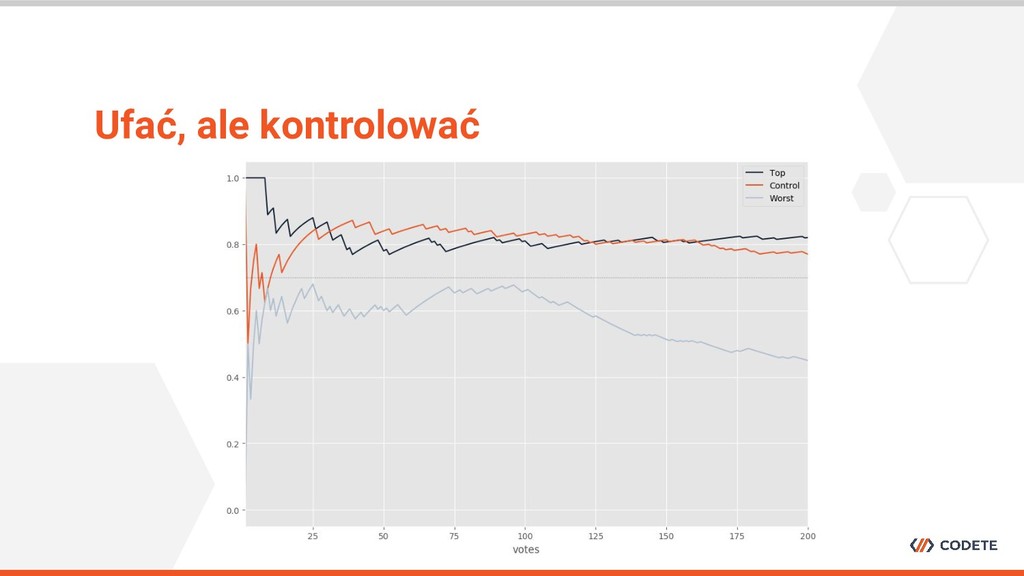
specjalistycznej wiedzy • Wstępna selekcja osób jest wymagana • Kontrola procesu w trakcie jego trwania jest niezbędna Jak zaprojektować dobry crowdsourcing?
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Dziękuję! Kacper Łukawski [email protected]](https://files.speakerdeck.com/presentations/57d851d371c44d78a7b3971510902b3a/slide_30.jpg){kind=link}
{kind=link}