Machine Learning - Going from concept to a product
A brief introduction to Machine Learning. 5 fundamental questions ML may try to answer and a successful story of preparing a project with the usage of Machine Learning.
social media data - problem definition. ⟶ What are the common tools used in the area? How to make an overview? ⟶ How to proceed if nothing really fits our needs? ⟶ Choosing the best model. What does “the best” mean? ⟶ We are there! How to make our model production ready? ML primers ✓ What kind of problems may ML help to solve? 5 fundamental questions look the answer for.
containing some observations (i.e. images) and a limited set of categories, every observation belongs to, but only to one of them. In other words, for each observation there is only one category assigned.
related to classification algorithms. Such an algorithm chooses the most probable category for given observation. A majority of classification methods will require to provide so called training dataset containing many observations from all the categories. These examples are then used in order to find a generalization for each category, and these generalized categories may be in turn used for the further labeling the observation our model hasn’t seen before. car
have the dataset of some observations collected and we want to detect some anomalies. The underlying assumption is, there is some expected behaviour, and we want to detect any unusual pattern.
numerical value is also quite common. We no longer have a limited number of categories to ask for, but a continuous space that an output may come from. Commonly, we have a set of measurements given and try to find the pattern that will allow us to predict the value in previously unseen conditions.
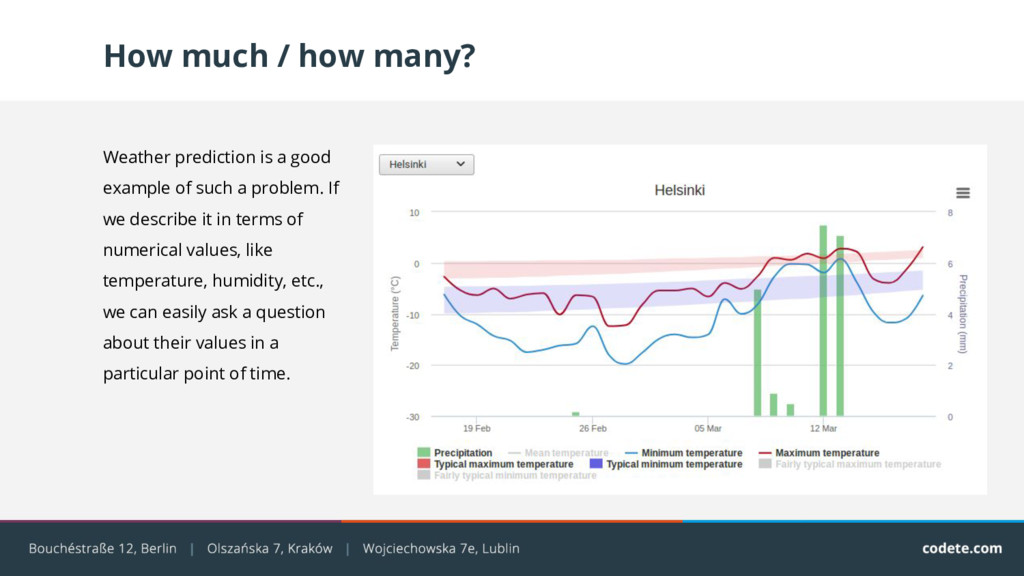
example of such a problem. If we describe it in terms of numerical values, like temperature, humidity, etc., we can easily ask a question about their values in a particular point of time.
be solved with regression algorithms. Their purpose is to predict the numerical value, usually based on the historical values under different conditions.
observations we don’t know too much about. As we would like to have an overview of what is inside, understand it a little bit, we can ask a question if the dataset is organized in any way. The difference to the previous question is - we usually don’t have any labels assigned to the entries of our dataset.
problem is probably the IRIS dataset. It contains the examples of three different kinds of irises - each observation is described in terms of sepal and petal width and length.
help to answer this kind of questions. Such algorithms try to divide the dataset into groups in which the similarity of observations is higher than between two examples coming from two different groups - so called clusters.
model the ongoing process in which there are several small decisions to be taken. It is quite similar to the way our brains work - when we have a goal to achieve, there are usually many different ways to get there - some of which are more effective than the others.
to consider a real life example - a child learning to walk. Usually, every attempt to do that is more successful than the previous one - the child at the beginning tries to do a single step, falls to the ground and tries once more. The process continues for a longer period of time, but finally she or he is able to have the walk on their own. During this process, the child has to decide whether to move left or right feet, if it might be necessary to hold something, etc.
reinforcement learning algorithms is to learn from the experience, through trial-and-error approach. An ML system based on such algorithm is punished or rewarded for every performed action with a goal to maximize the overall reward.
or B? Classification ✓ Is this weird? Anomaly detection ✓ How much / how many? Regression ✓ How is this organized? Clustering ✓ What should I do next? Reinforcement learning
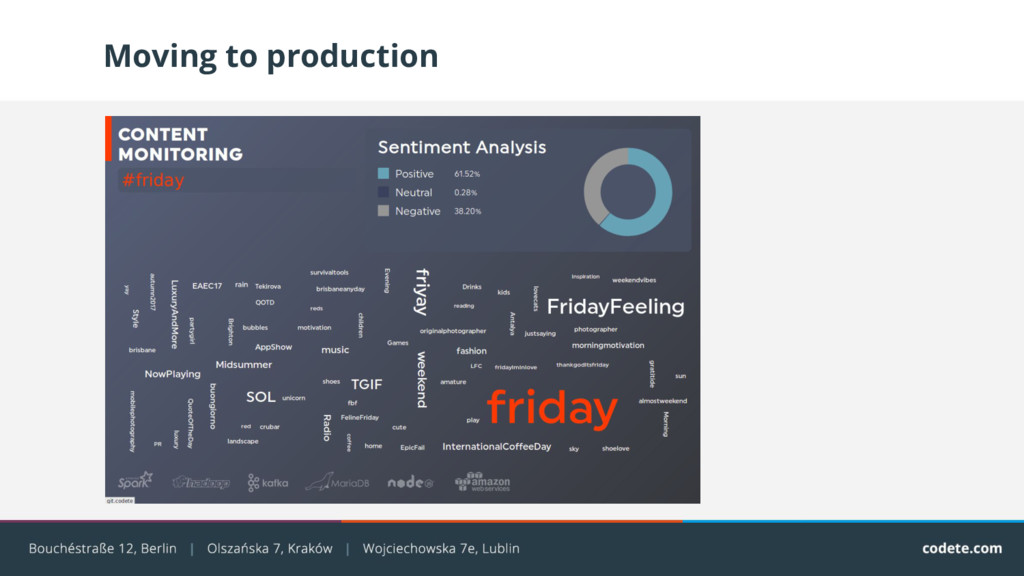
analysis is to predict if, or how much, given text is positive, negative or neutral. It can be, for example, used for continuous monitoring of the brand perception, which is, in turn, very helpful in order to react whenever something goes wrong.
wanted to prepare a showcase for the conferences we attend. This demo application was intended to show the messages about this particular event in real time and aggregate the topics which are often mentioned for it, in order to have on overview of what the conference is about. Additionally, for every appearing message, its sentiment has to be determined, to be then presented globally. It is though to be an indicator of how the audience perceives the event. As a data source we selected Twitter, which has a really good API that returns the data for subscribed phrase (usually a hashtag) in real time manner.
University, is thought to be a state-of-the-art solution in the area of sentiment analysis. In order to reduce the development time, that was our first choice. Surprisingly, the library was not so accurate for our input data and we have to rethink how the problem may be solved in a different way.
found out the following problems: ⟶ Tweets are very short Yeah... ⟶ They contain many hashtags or acronyms which are not officially a part of the language #bigproblem ⟶ The usage of special characters, like emojis, is very high ⟶ And many more...
- there is nothing we can use effortlessly to fulfill the task. There is a need to create our own ML model that will process the data from scratch and allow us to classify the messages in terms of their sentiment.
new introduces several issues or steps necessary to be kept in mind: ⟶ We need to collect a dataset, probably already labelled. ⟶ There is a need to choose a proper architecture that will achieve accuracy which is high enough for our needs. ⟶ The dataset is textual, so for many algorithms it has to be vectorized. ⟶ A research code rarely can be moved to production without any changes.
different classification algorithms: ⟶ Logistic regression ⟶ SVM ⟶ Random forest ⟶ And many more… Every single model was trained with different vectorization algorithms, in order to compare their influence on the results.
similar results - the accuracy on the test dataset was more or less 75% (OpenNLP had about 50%). Unfortunately the model with the highest accuracy was terribly slow to be taught and to be then used in classification. Keeping in mind, the code is intended to be launched in production, not the best model, in terms of accuracy, had been chosen, but Random Forest Classifier, which had the best balance between achieved results and speed.
several applications: ⟶ Spark jobs for reading Twitter data, performing all the analysis and storing the data in a database to be then displayed. ⟶ Frontend application for visualizing the data. ⟶ An API for communication between the output database of Spark jobs and the frontend.
have been introduced to Spark jobs, however it would make the executables really huge and won’t allow to make any changes in the fly. For that purposes, a simple Rest HTTP API in Flask (Python) has been implemented. This application allows to put serialized models which can be then accessed with HTTP calls. Additionally, the model used by Spark jobs, can be updated without any downtime.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}