In this session, Kacper Łukawski, from Qdrant will discuss best practices for building LLM-based apps and their integrations. As the adoption of these models becomes more widespread, it's essential to understand the potential technical hurdles that could impact the system's performance and scalability.
During the talk, we will review the existing tools and see how to move from development to production.
This webinar will cover:
📌 Learn about the key considerations when designing applications powered by LLMs, including choosing the right model, understanding the computational requirements, and ensuring data privacy.
📌 Dive into the technical aspects of training and fine-tuning LLMs for your specific application needs.
📌 Discover the best practices for deploying and scaling LLM-based applications, including model versioning, A/B testing.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
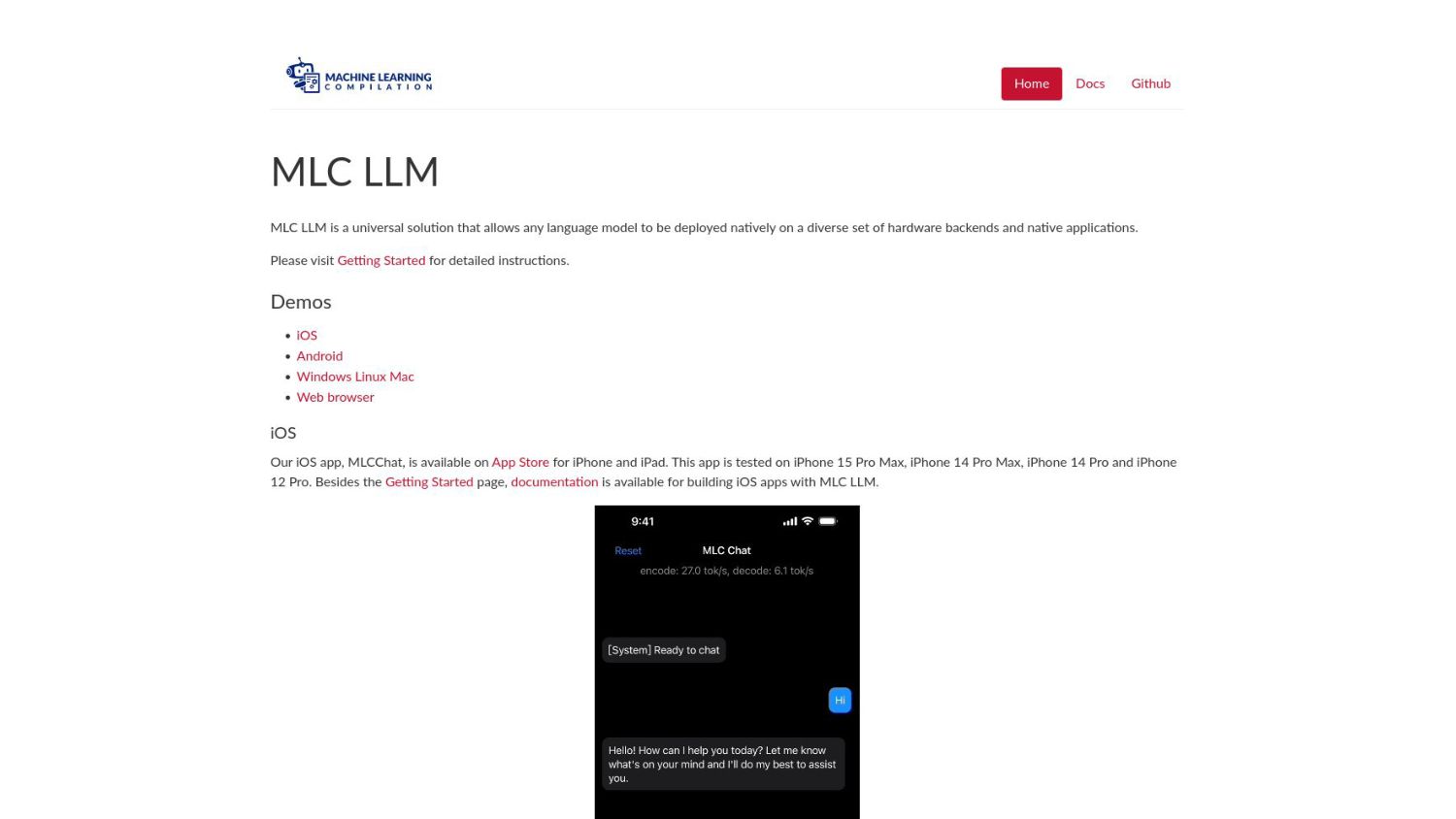{kind=link}
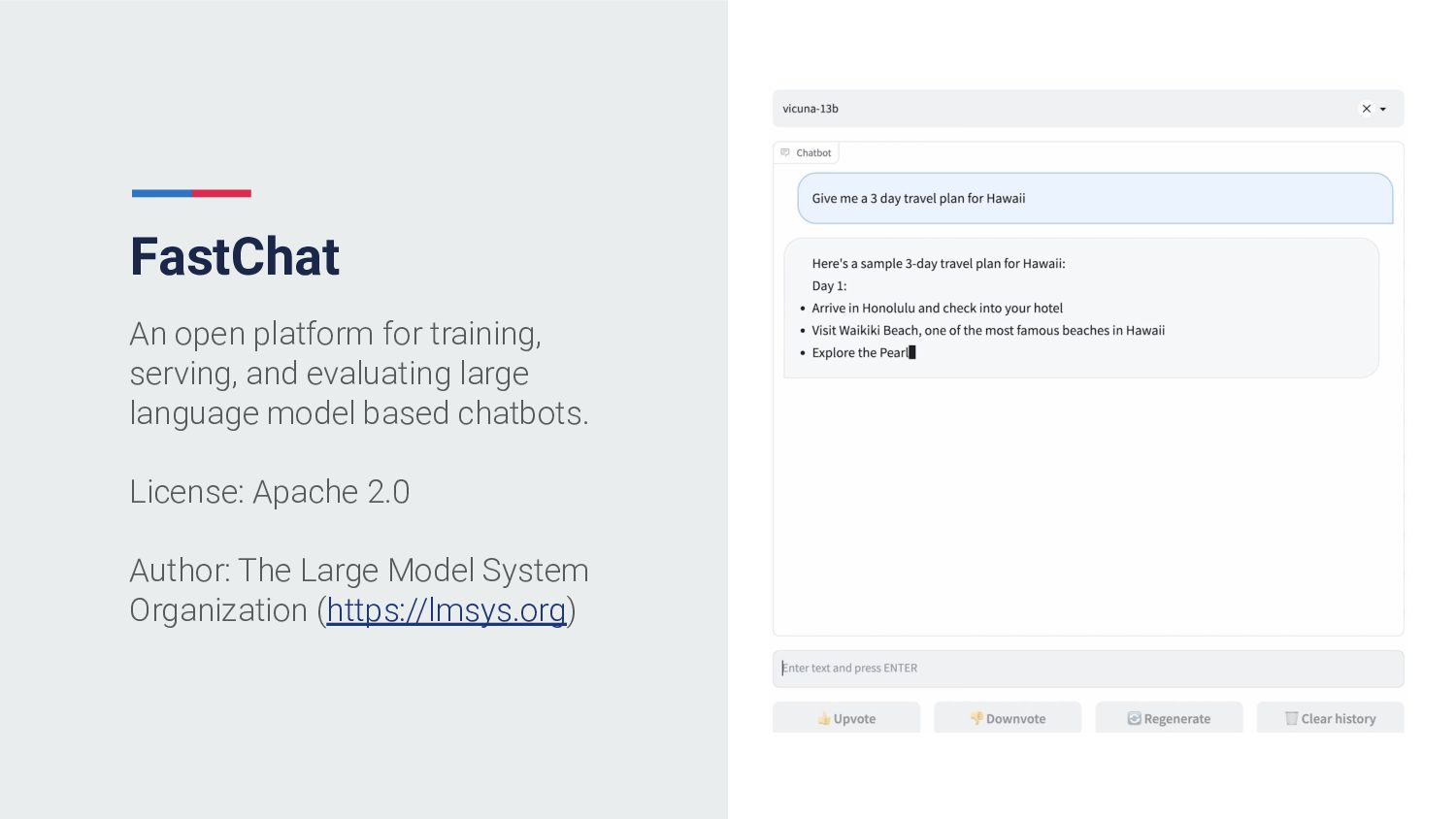{kind=link}
{kind=link}