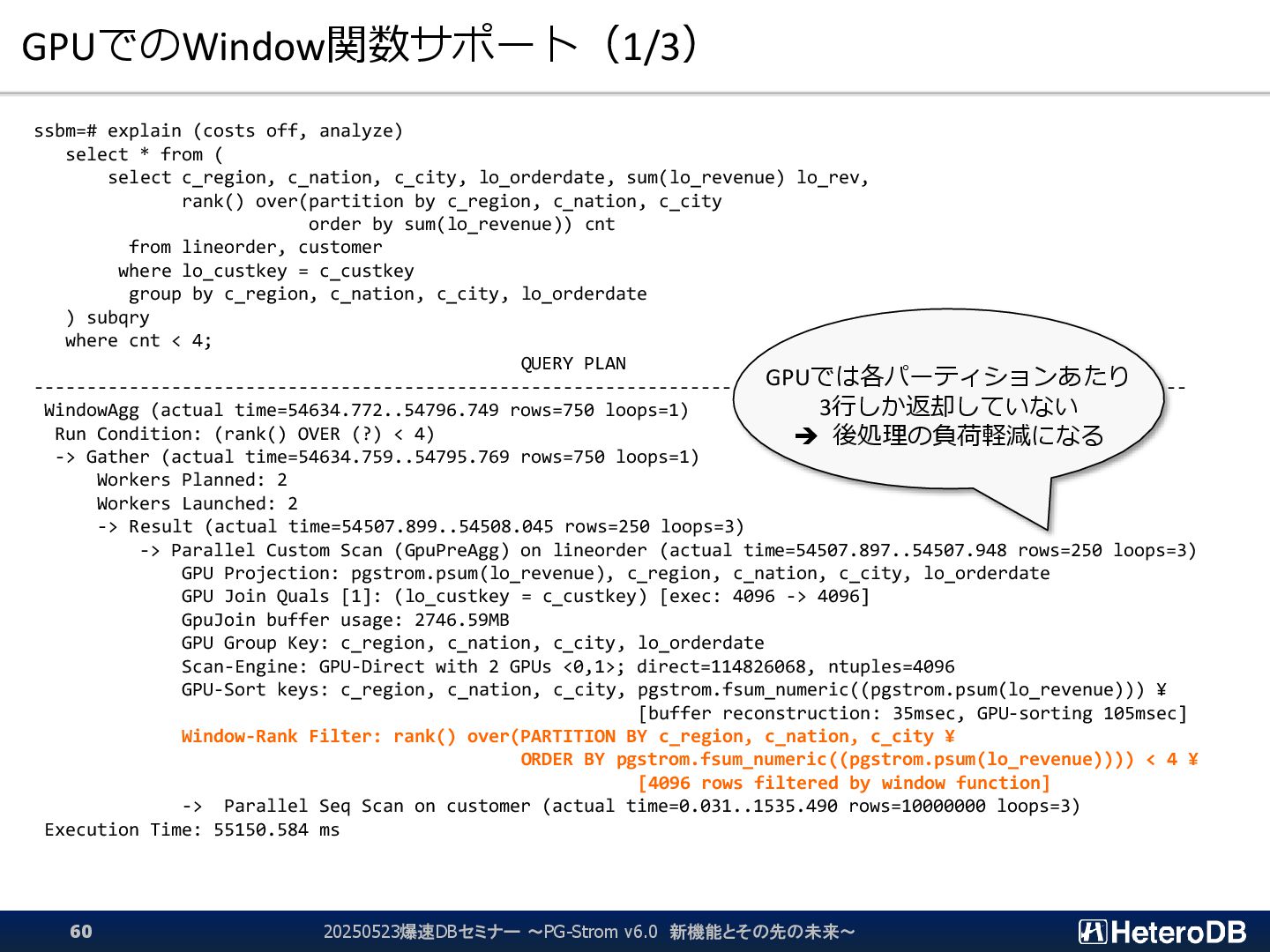
select c_region, c_nation, c_city, lo_orderdate, sum(lo_revenue) lo_rev, rank() over(partition by c_region, c_nation, c_city order by sum(lo_revenue)) cnt from lineorder, customer where lo_custkey = c_custkey group by c_region, c_nation, c_city, lo_orderdate ) subqry where cnt < 4; QUERY PLAN ------------------------------------------------------------------------------------------------------------- WindowAgg (actual time=54634.772..54796.749 rows=750 loops=1) Run Condition: (rank() OVER (?) < 4) -> Gather (actual time=54634.759..54795.769 rows=750 loops=1) Workers Planned: 2 Workers Launched: 2 -> Result (actual time=54507.899..54508.045 rows=250 loops=3) -> Parallel Custom Scan (GpuPreAgg) on lineorder (actual time=54507.897..54507.948 rows=250 loops=3) GPU Projection: pgstrom.psum(lo_revenue), c_region, c_nation, c_city, lo_orderdate GPU Join Quals [1]: (lo_custkey = c_custkey) [exec: 4096 -> 4096] GpuJoin buffer usage: 2746.59MB GPU Group Key: c_region, c_nation, c_city, lo_orderdate Scan-Engine: GPU-Direct with 2 GPUs <0,1>; direct=114826068, ntuples=4096 GPU-Sort keys: c_region, c_nation, c_city, pgstrom.fsum_numeric((pgstrom.psum(lo_revenue))) ¥ [buffer reconstruction: 35msec, GPU-sorting 105msec] Window-Rank Filter: rank() over(PARTITION BY c_region, c_nation, c_city ¥ ORDER BY pgstrom.fsum_numeric((pgstrom.psum(lo_revenue)))) < 4 ¥ [4096 rows filtered by window function] -> Parallel Seq Scan on customer (actual time=0.031..1535.490 rows=10000000 loops=3) Execution Time: 55150.584 ms GPUでは各パーティションあたり 3行しか返却していない ➔ 後処理の負荷軽減になる 20250523爆速DBセミナー ~PG-Strom v6.0 新機能とその先の未来~ 60
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![PG-Stromの歴史(4/4) その後の拡張&改良 ▌PostgreSQLの改良 Custom Background Worker [PgSQL v9.3] ](https://files.speakerdeck.com/presentations/6308784c235b404091ea8052998fbe8e/slide_8.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
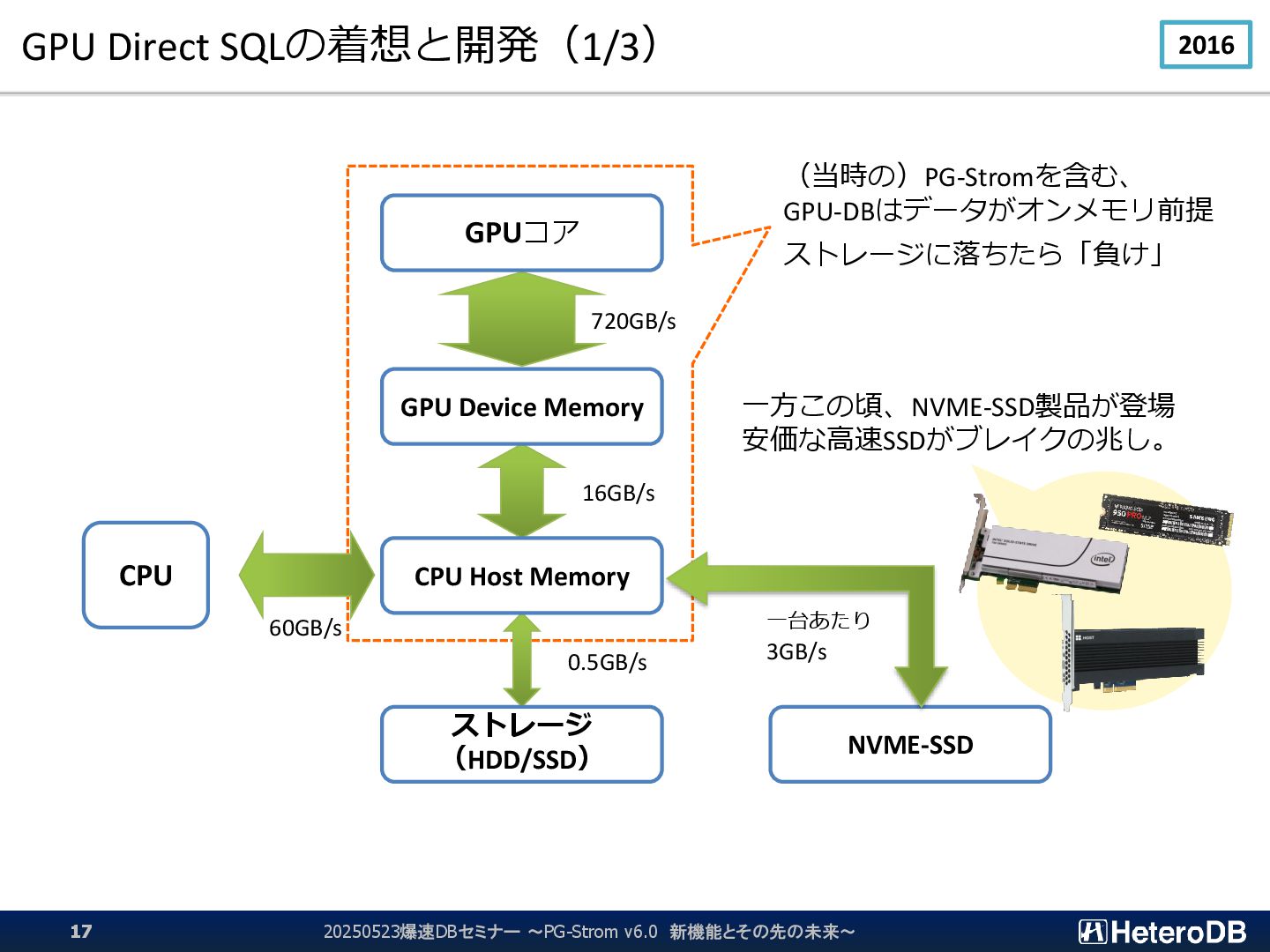{kind=link}
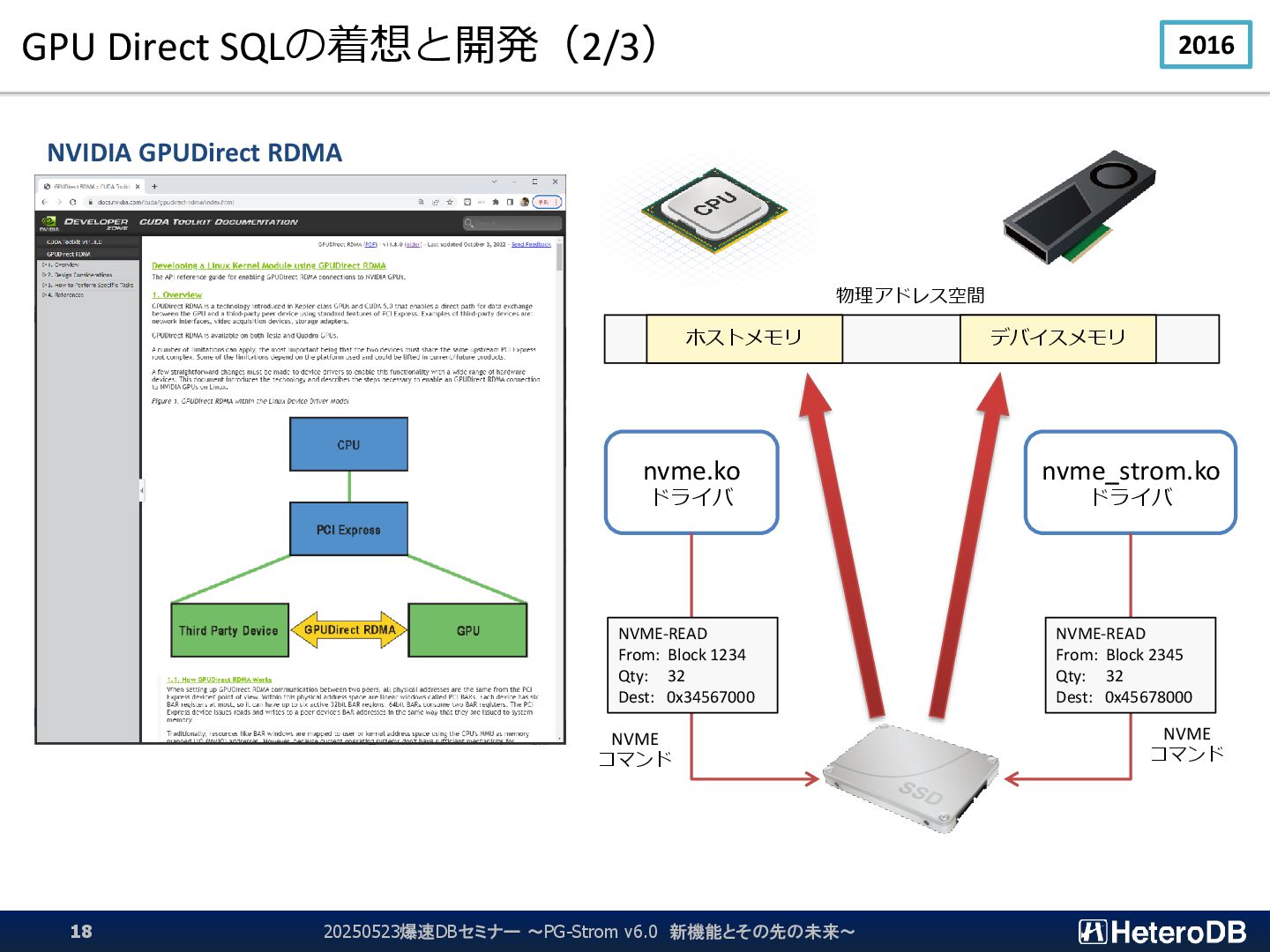{kind=link}
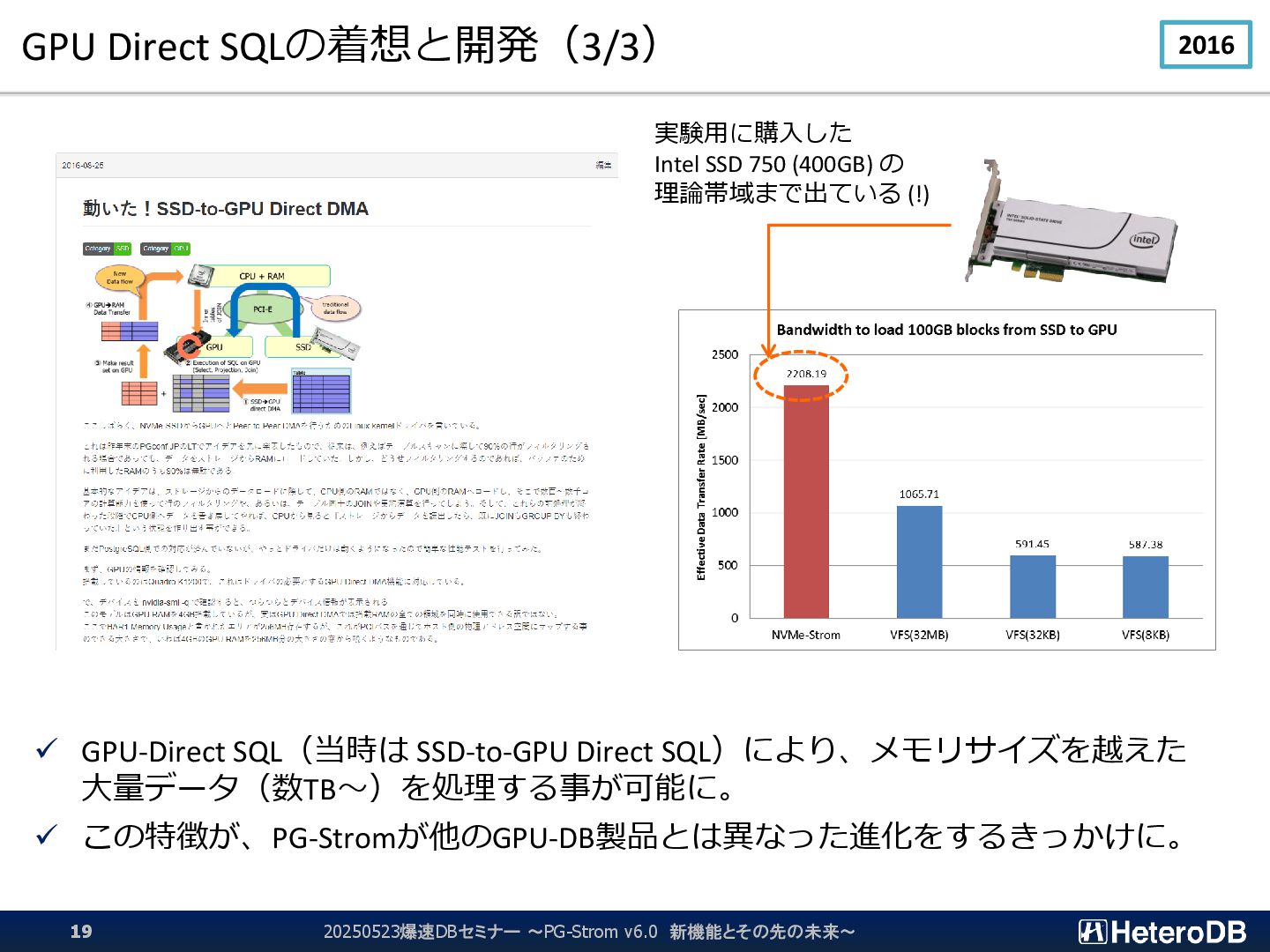{kind=link}
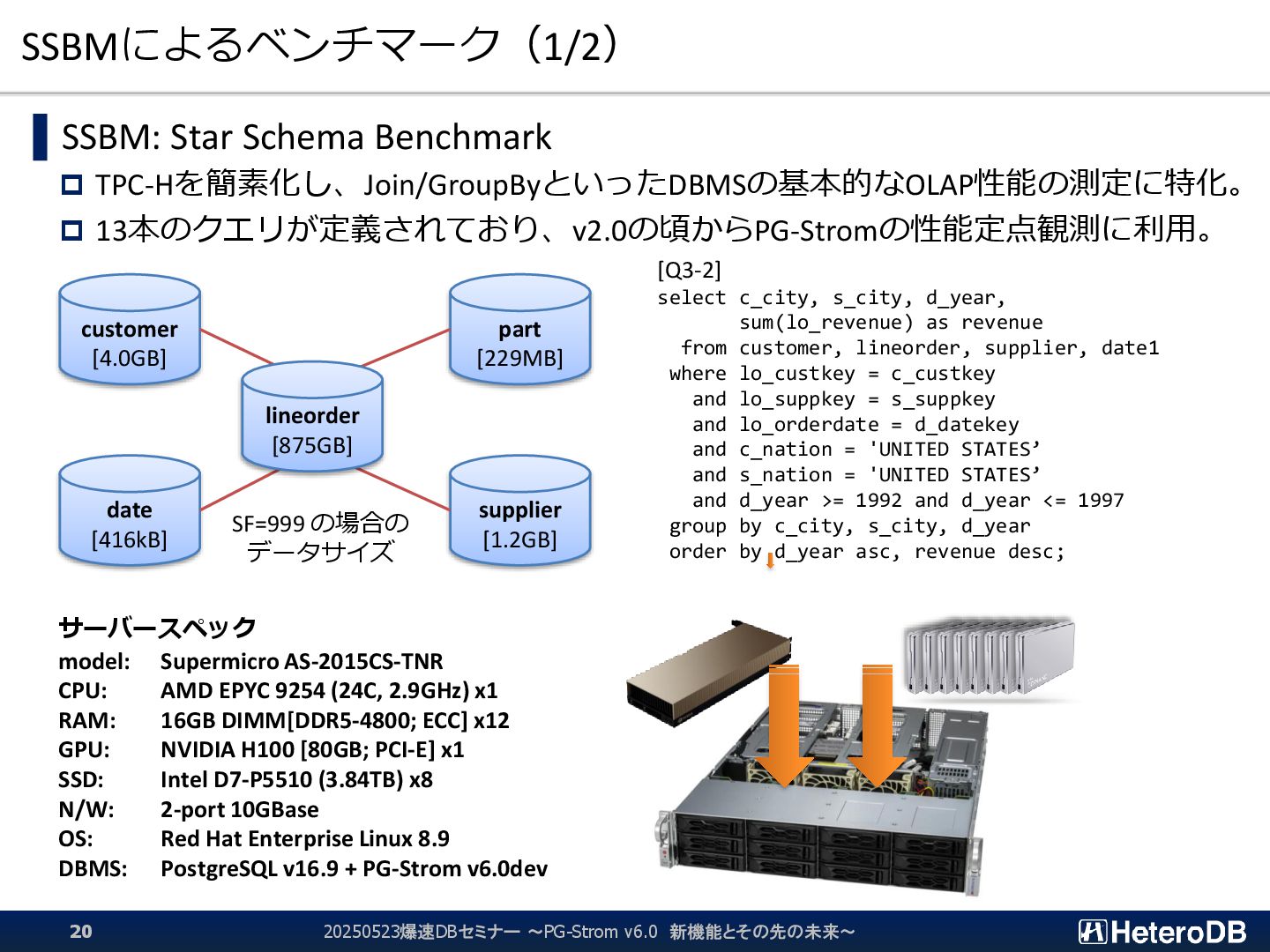{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
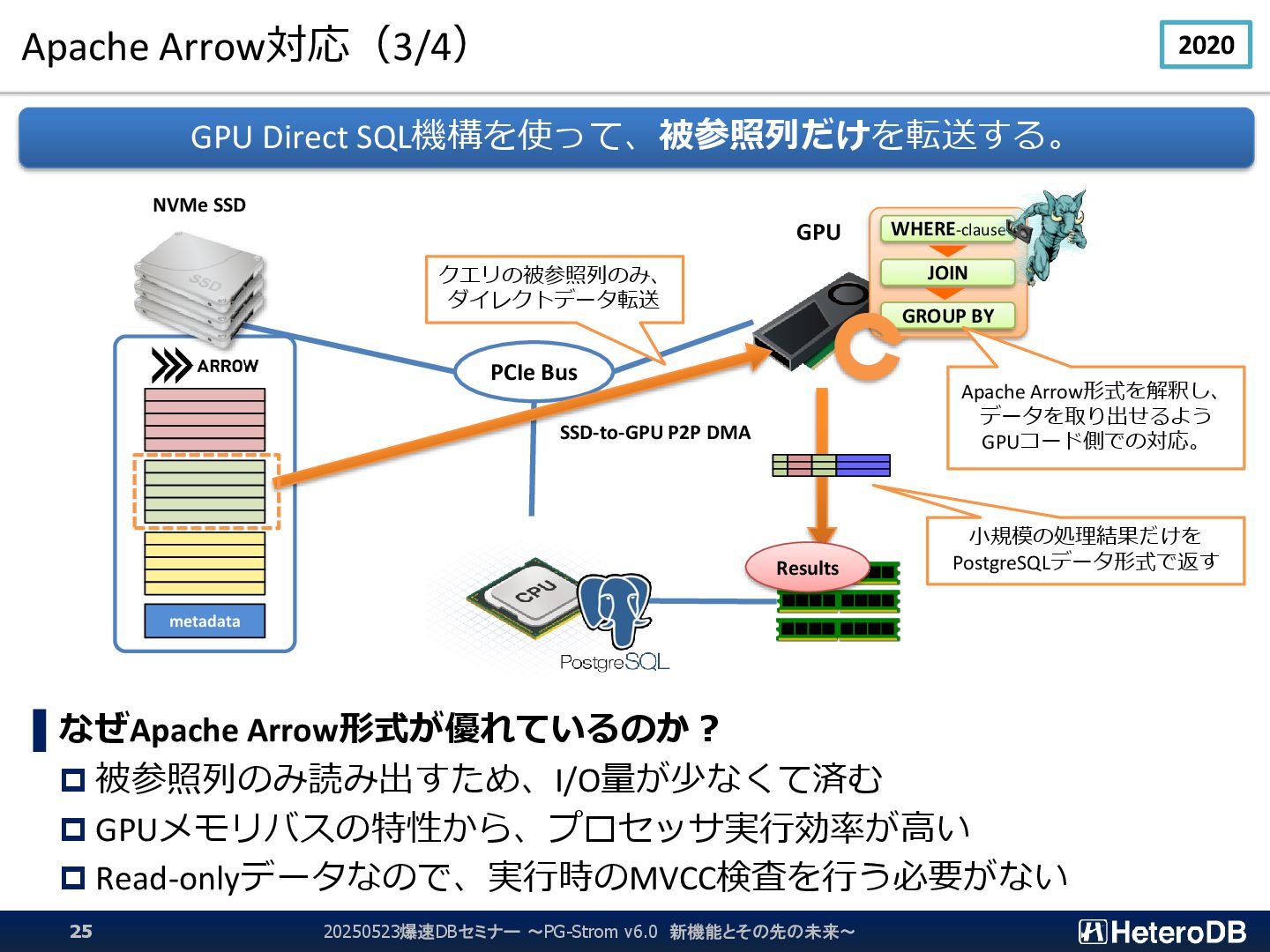{kind=link}
![Apache Arrow対応(4/4) ▌縦軸は [百万行/秒] で単位時間あたりに処理できた行数を示す。 列データなので被参照列の数/幅によってI/Oの負荷は変わる。 列データの場合、律速要因はI/OよりもむしろGPU側。 ➔](https://files.speakerdeck.com/presentations/6308784c235b404091ea8052998fbe8e/slide_24.jpg){kind=link}
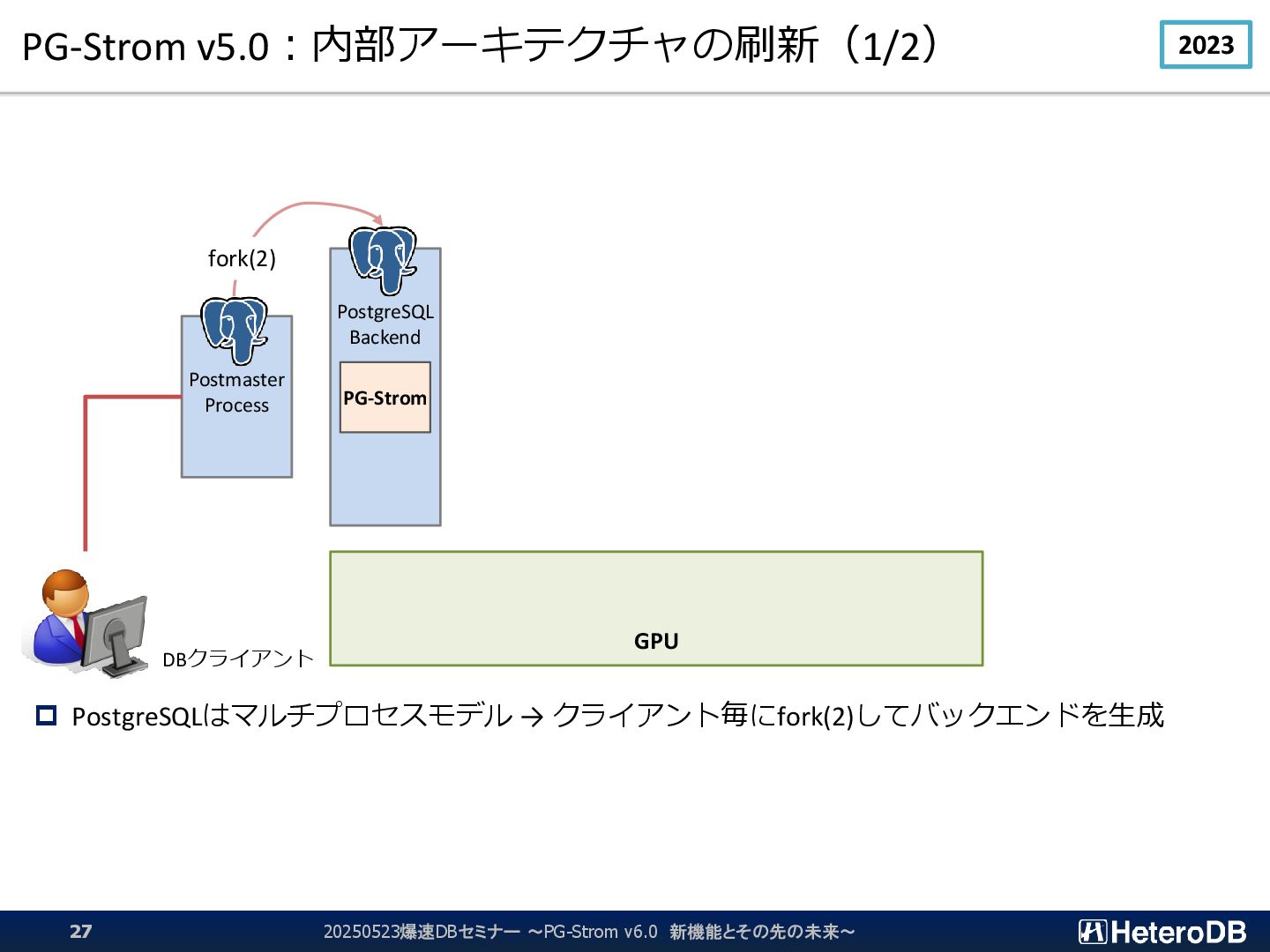{kind=link}
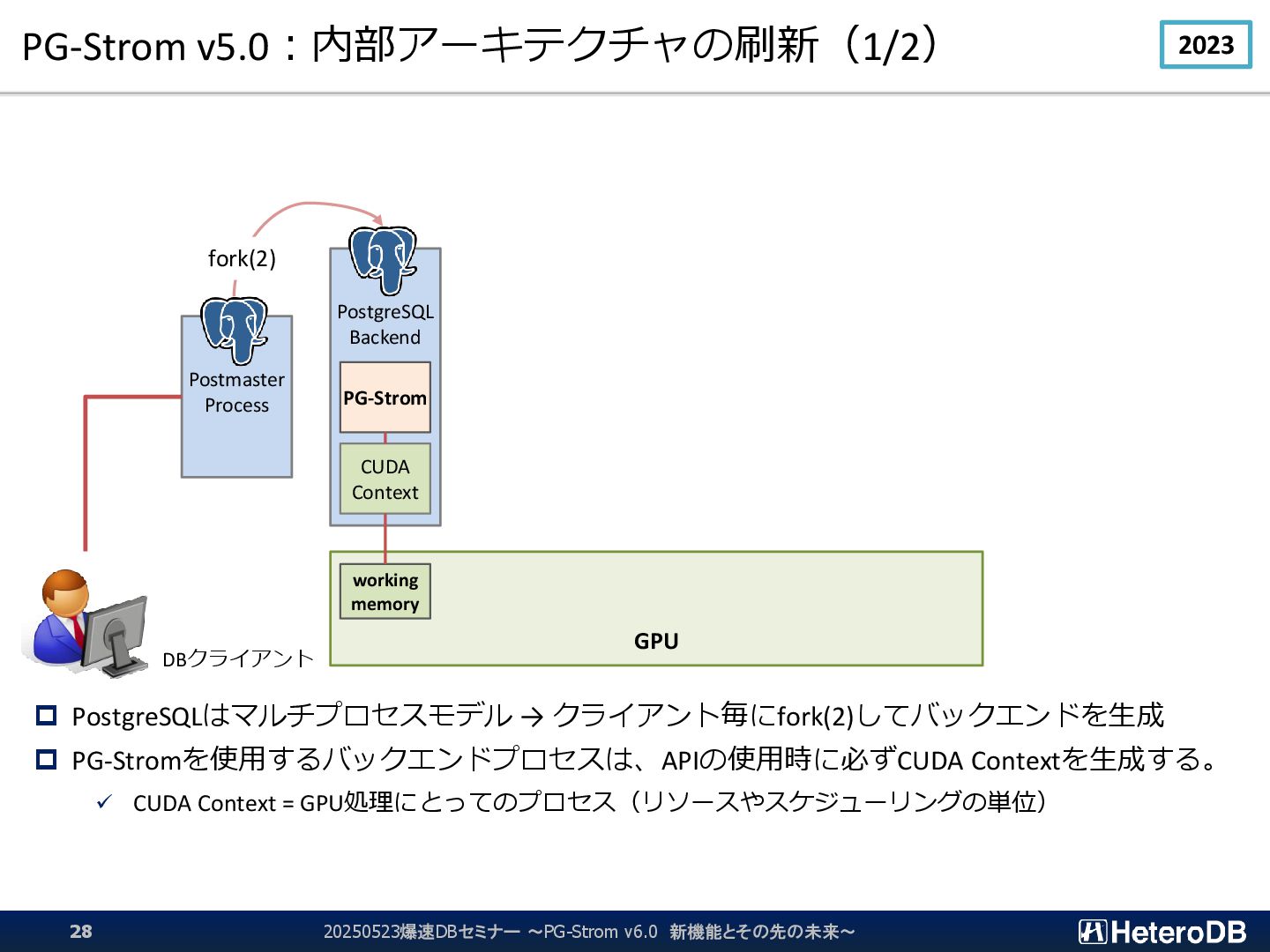{kind=link}
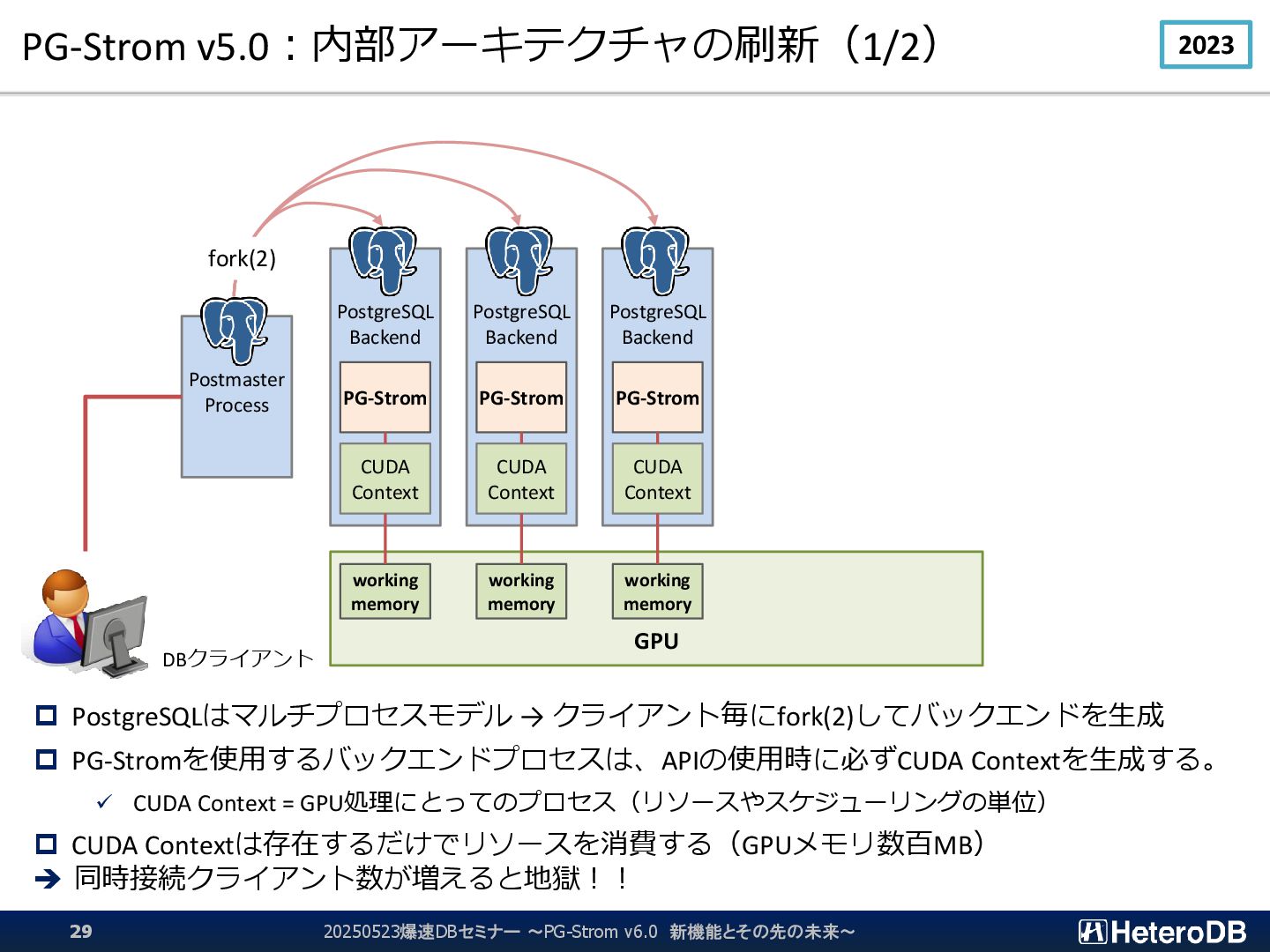{kind=link}
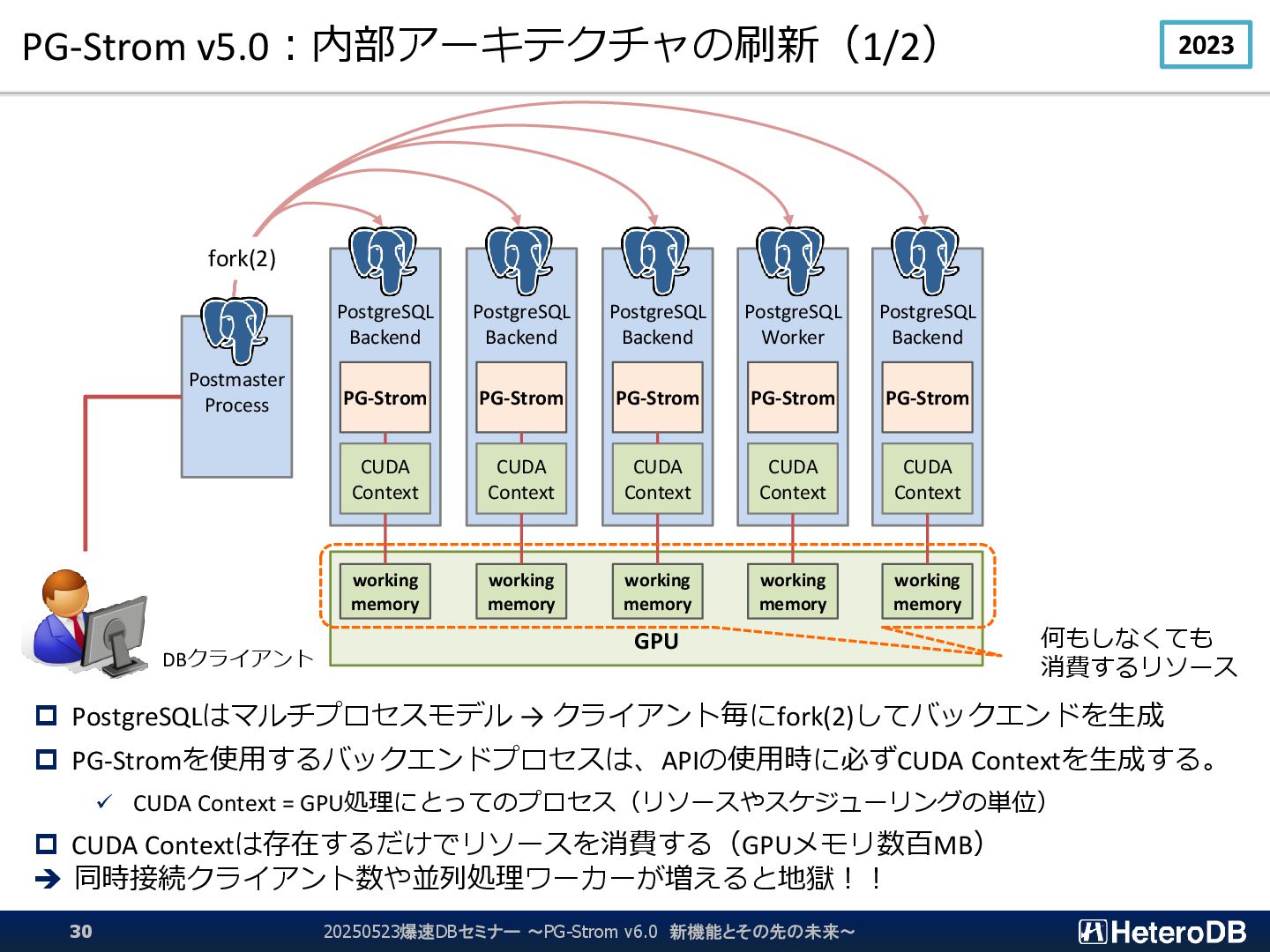{kind=link}
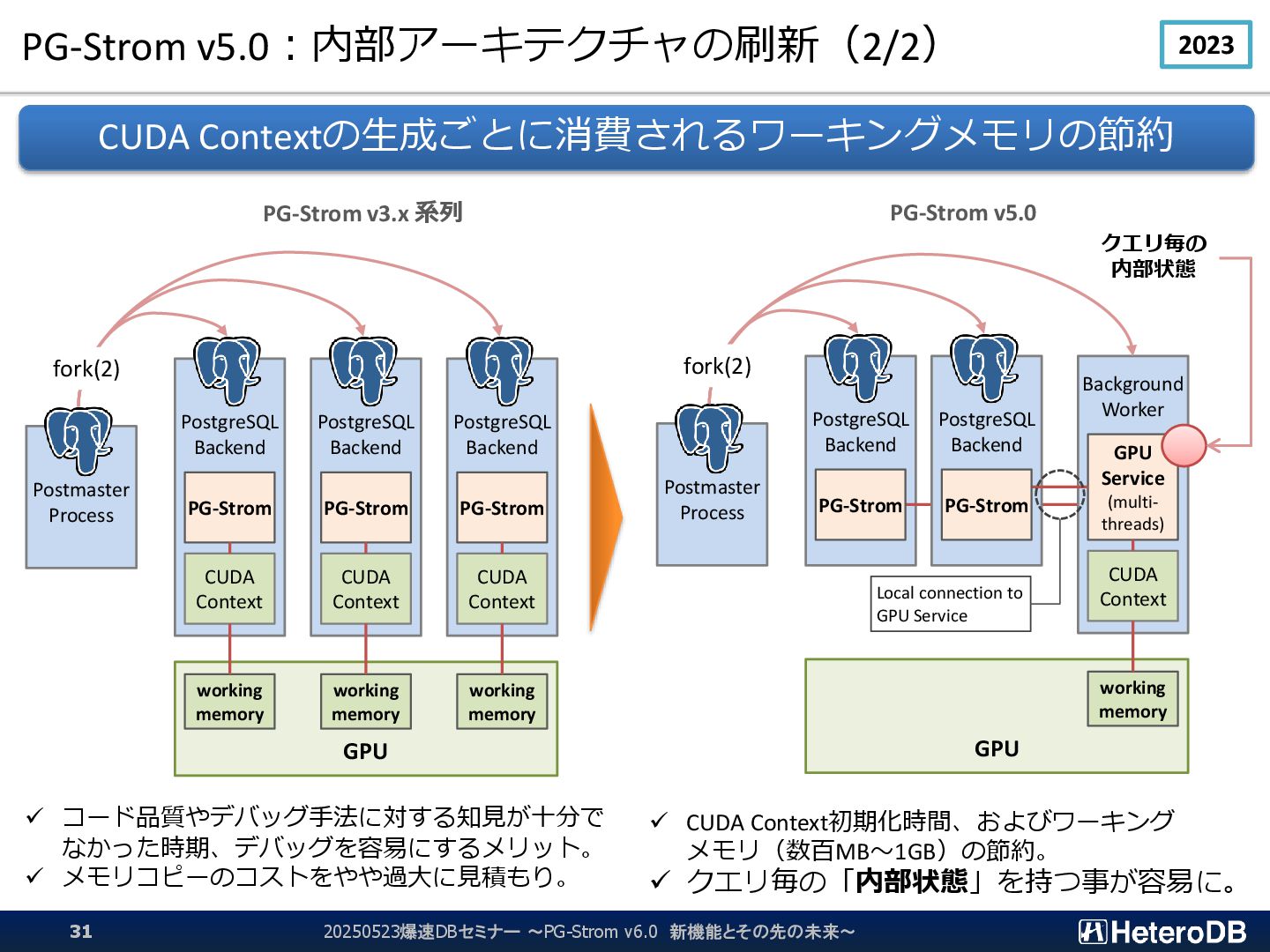{kind=link}
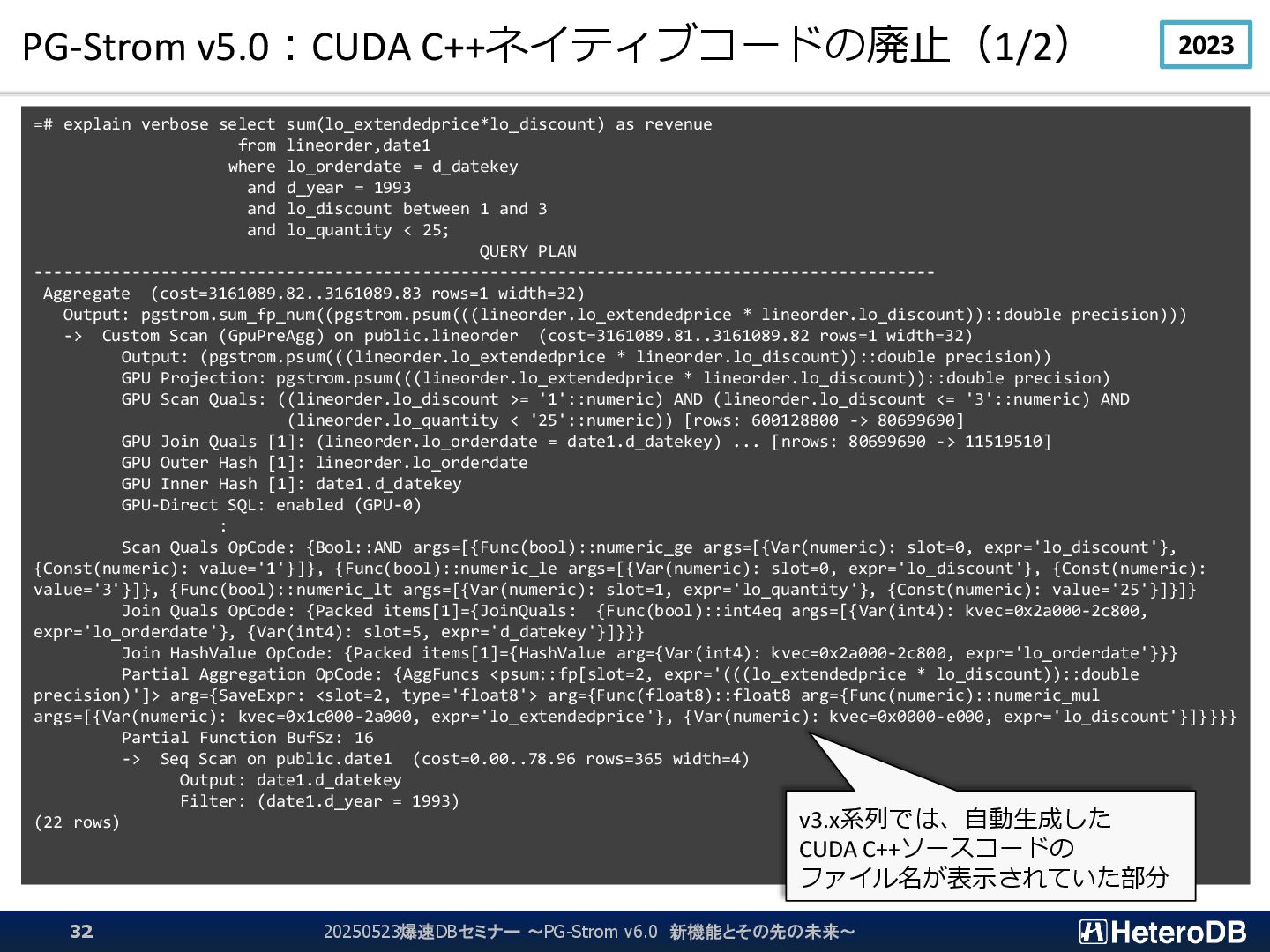{kind=link}
{kind=link}
{kind=link}
{kind=link}
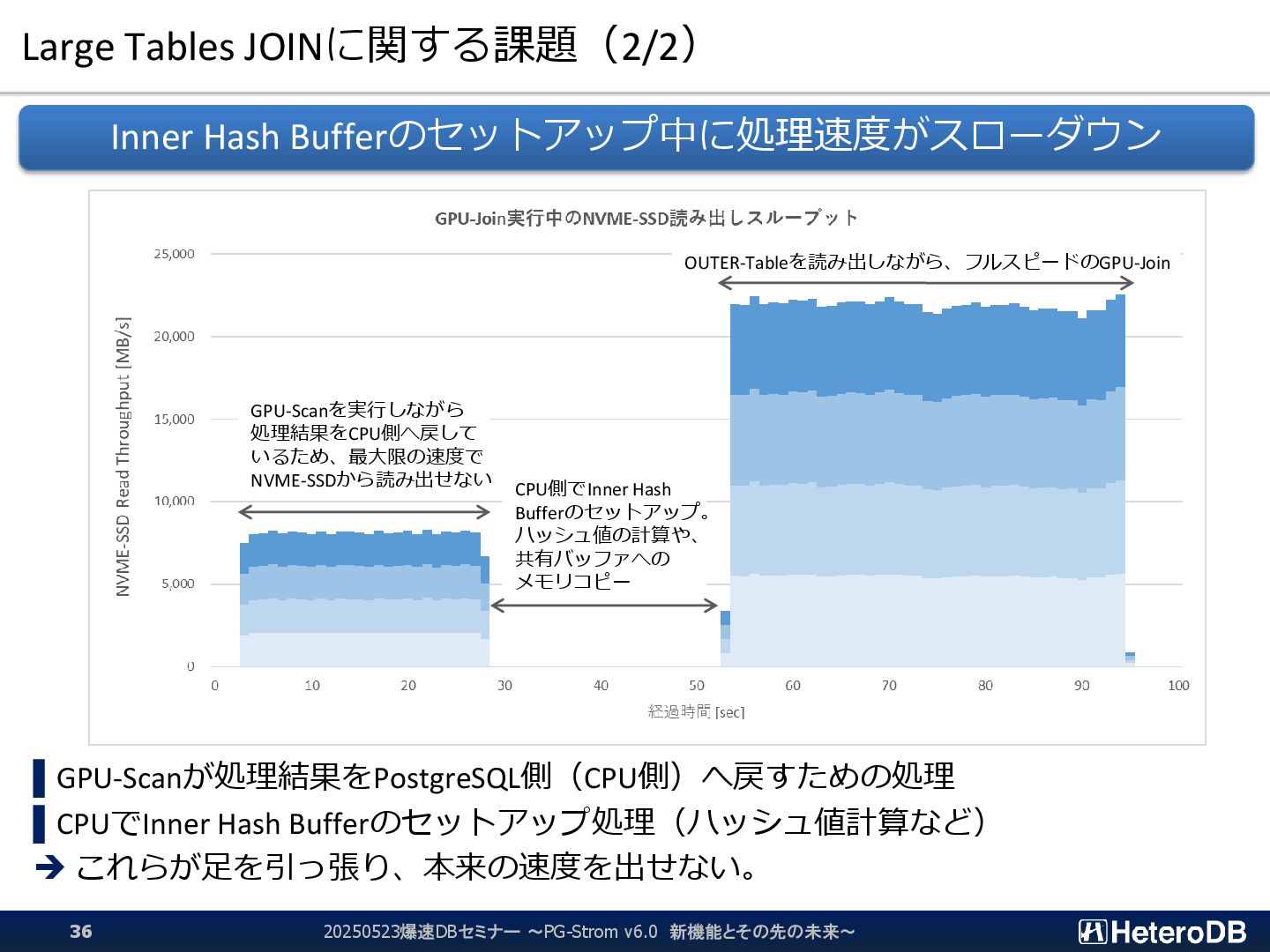{kind=link}
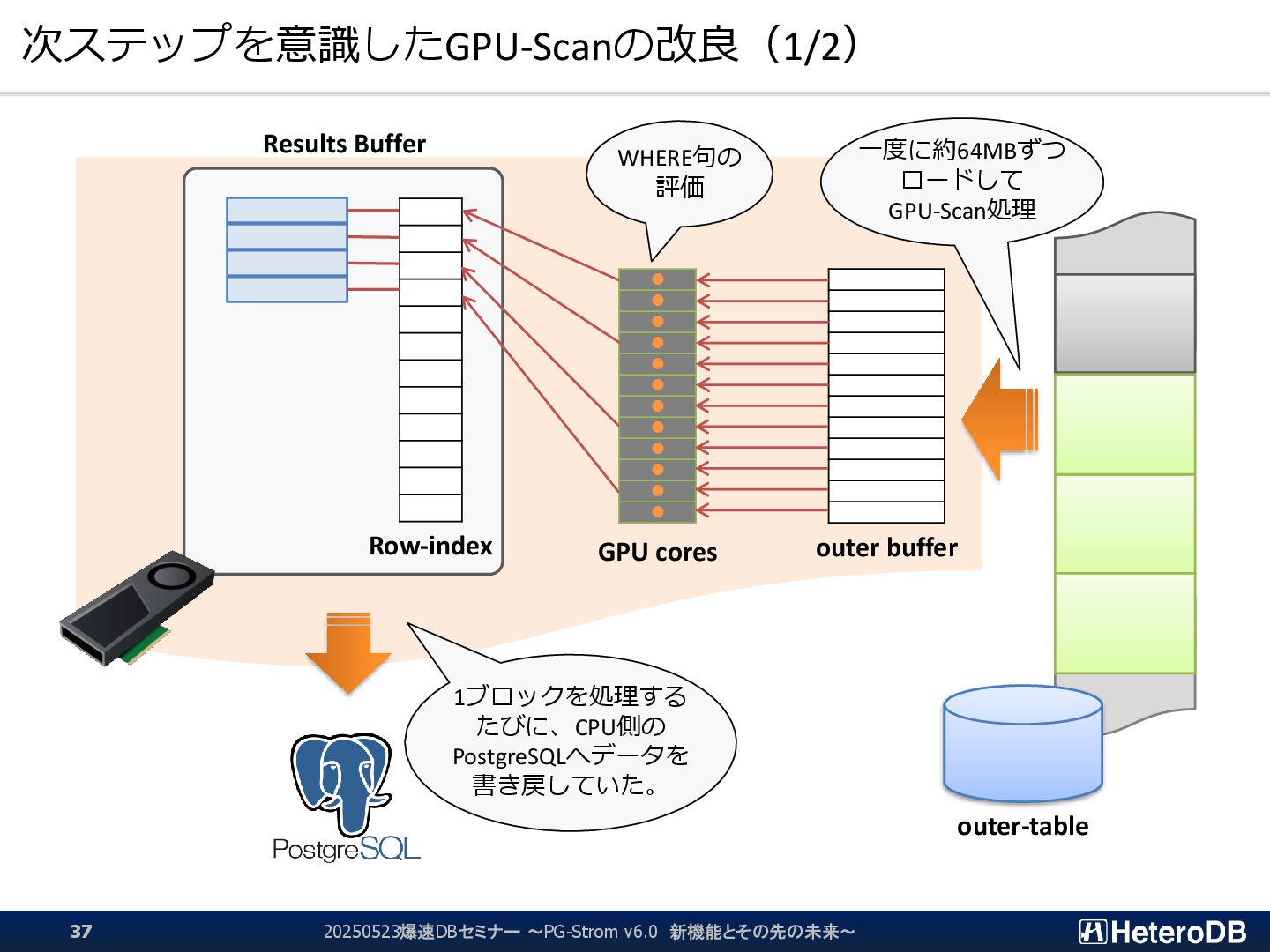{kind=link}
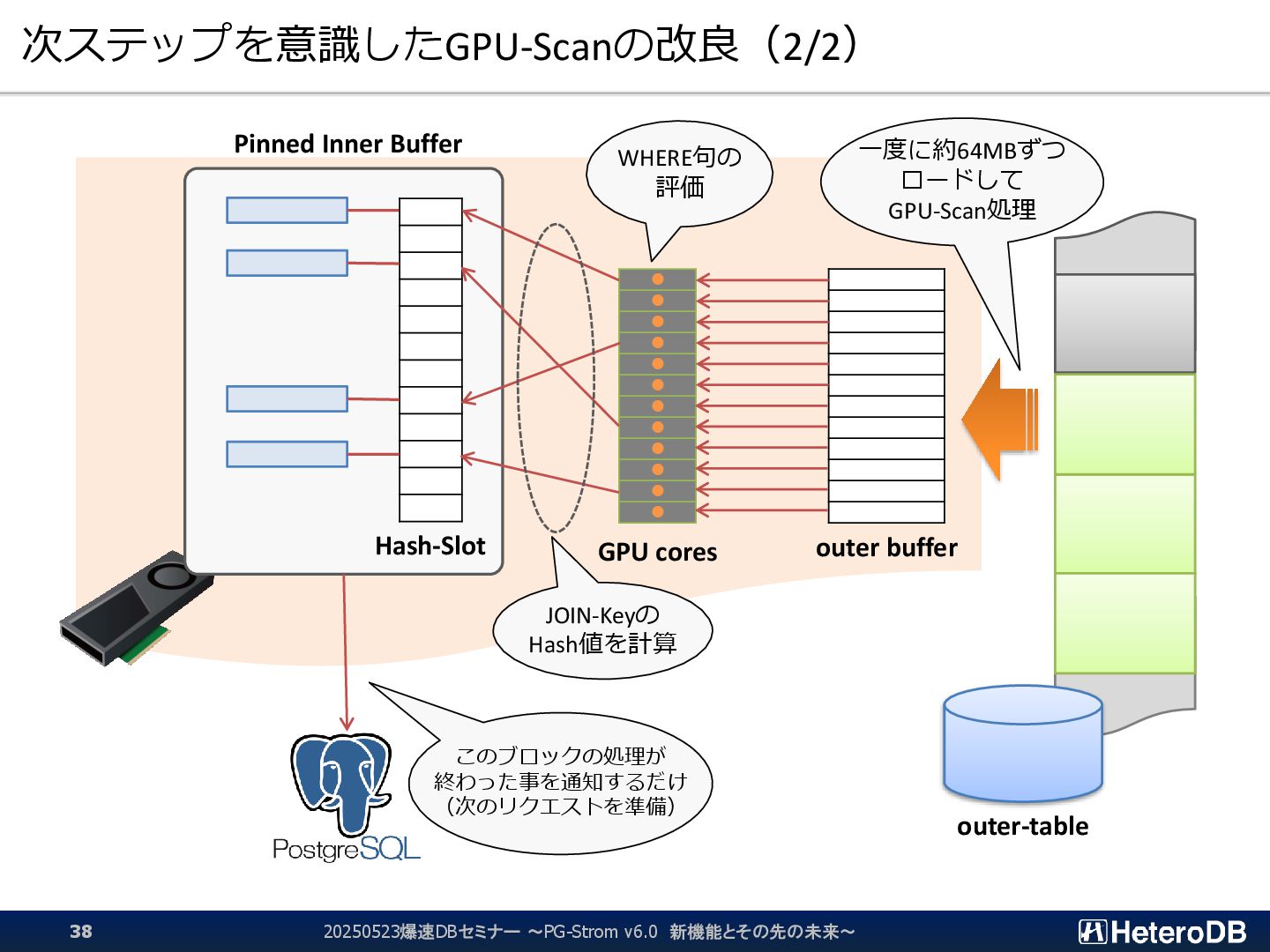{kind=link}
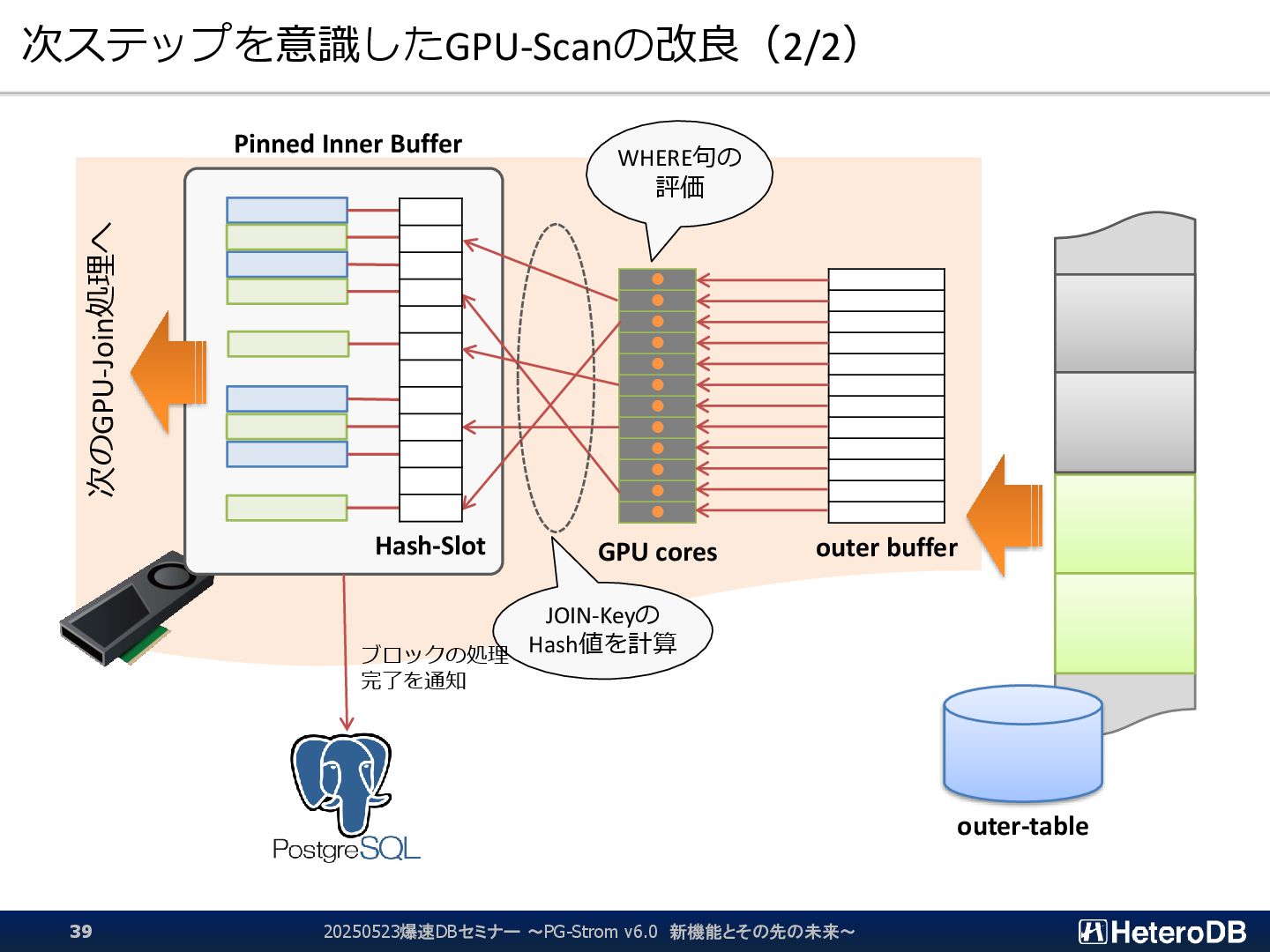{kind=link}
{kind=link}
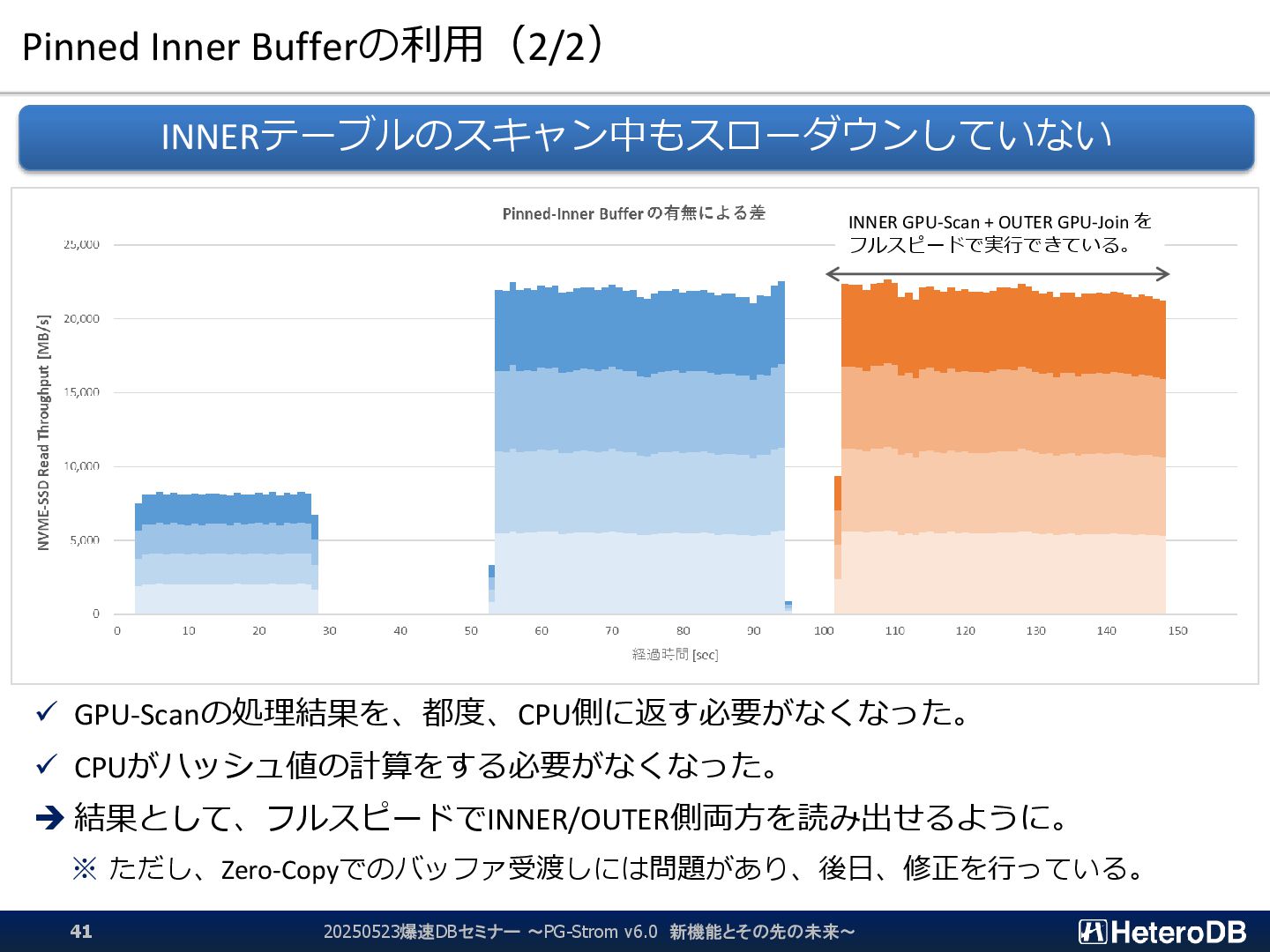{kind=link}
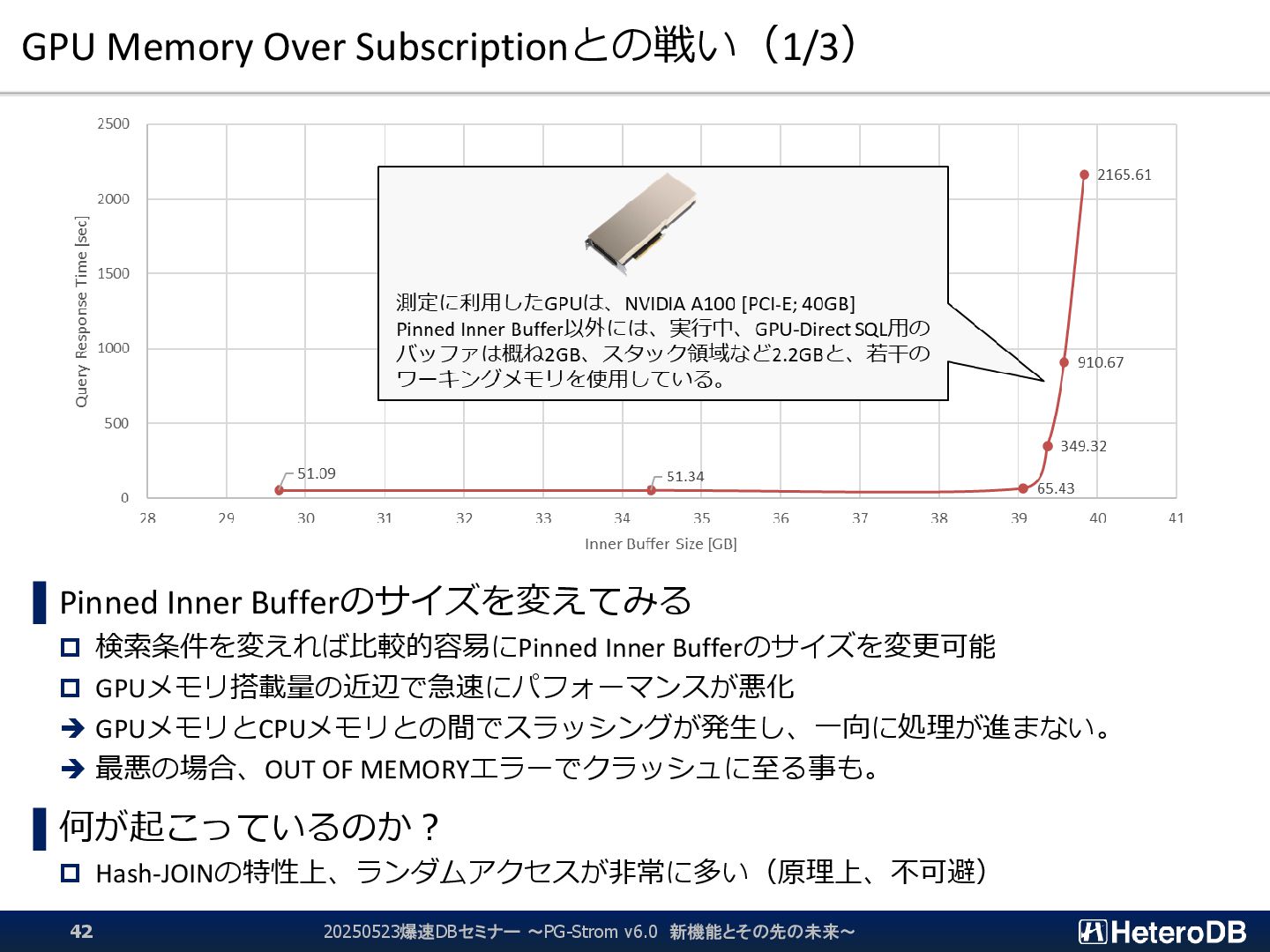{kind=link}
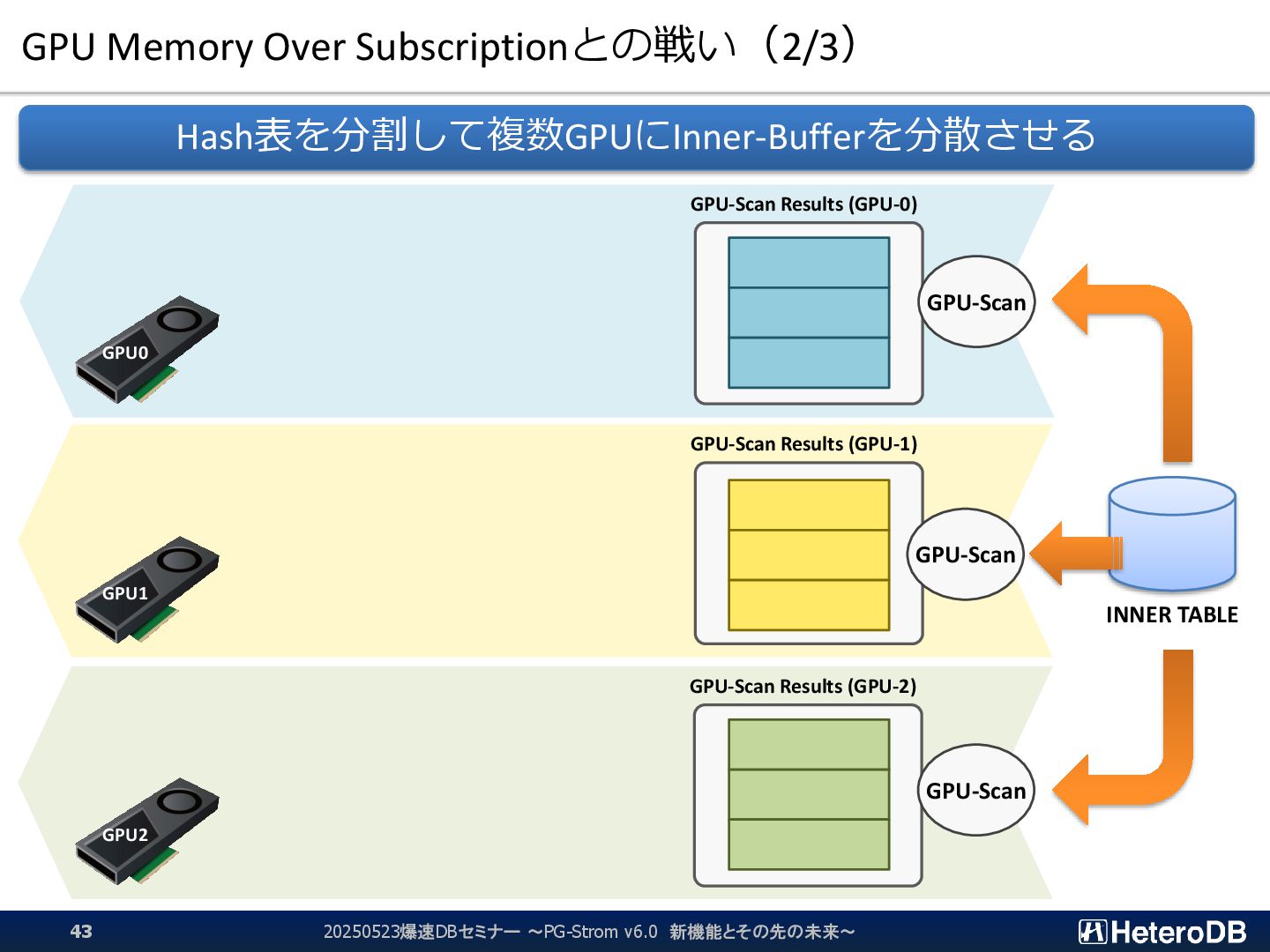{kind=link}
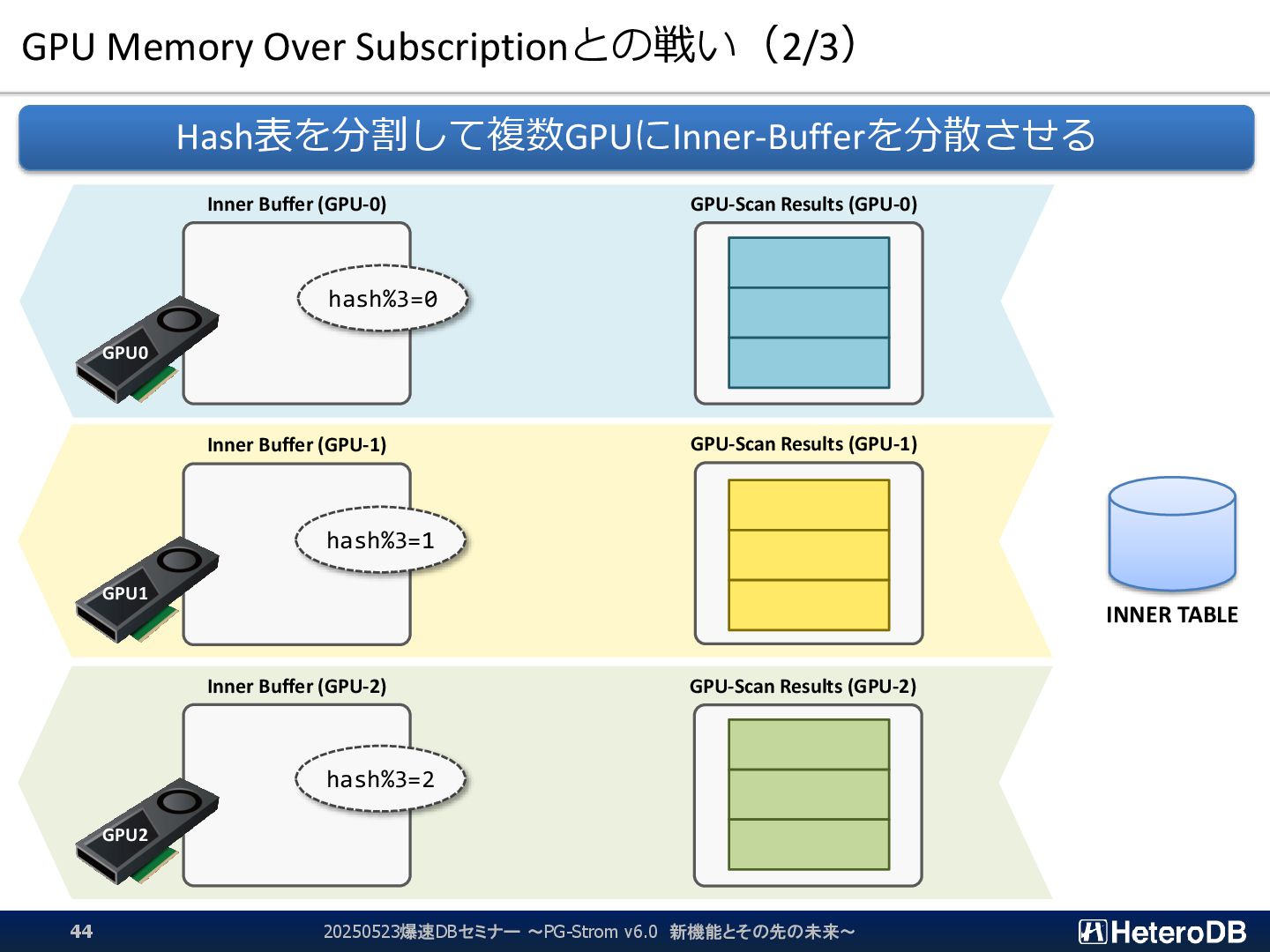{kind=link}
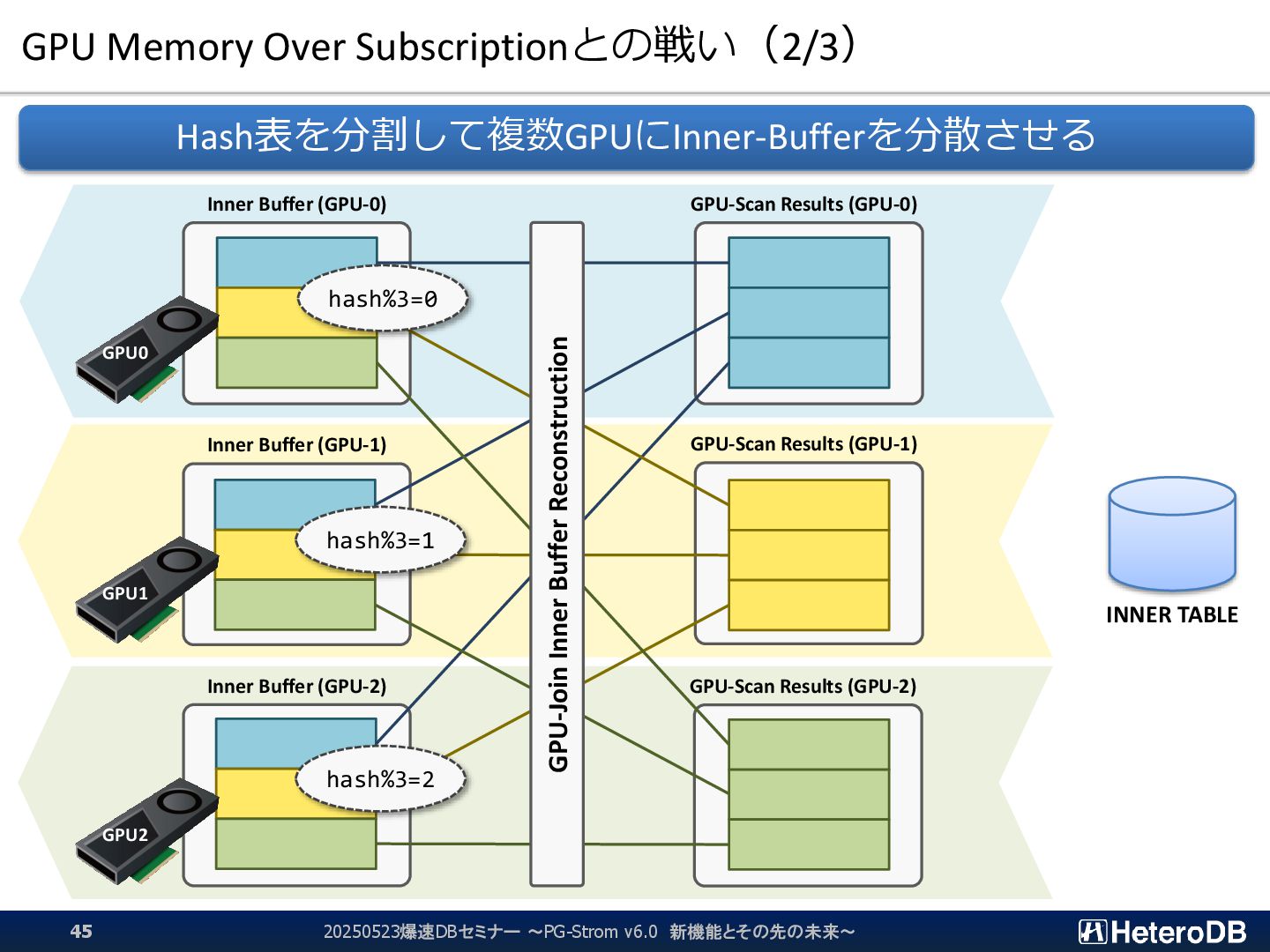{kind=link}
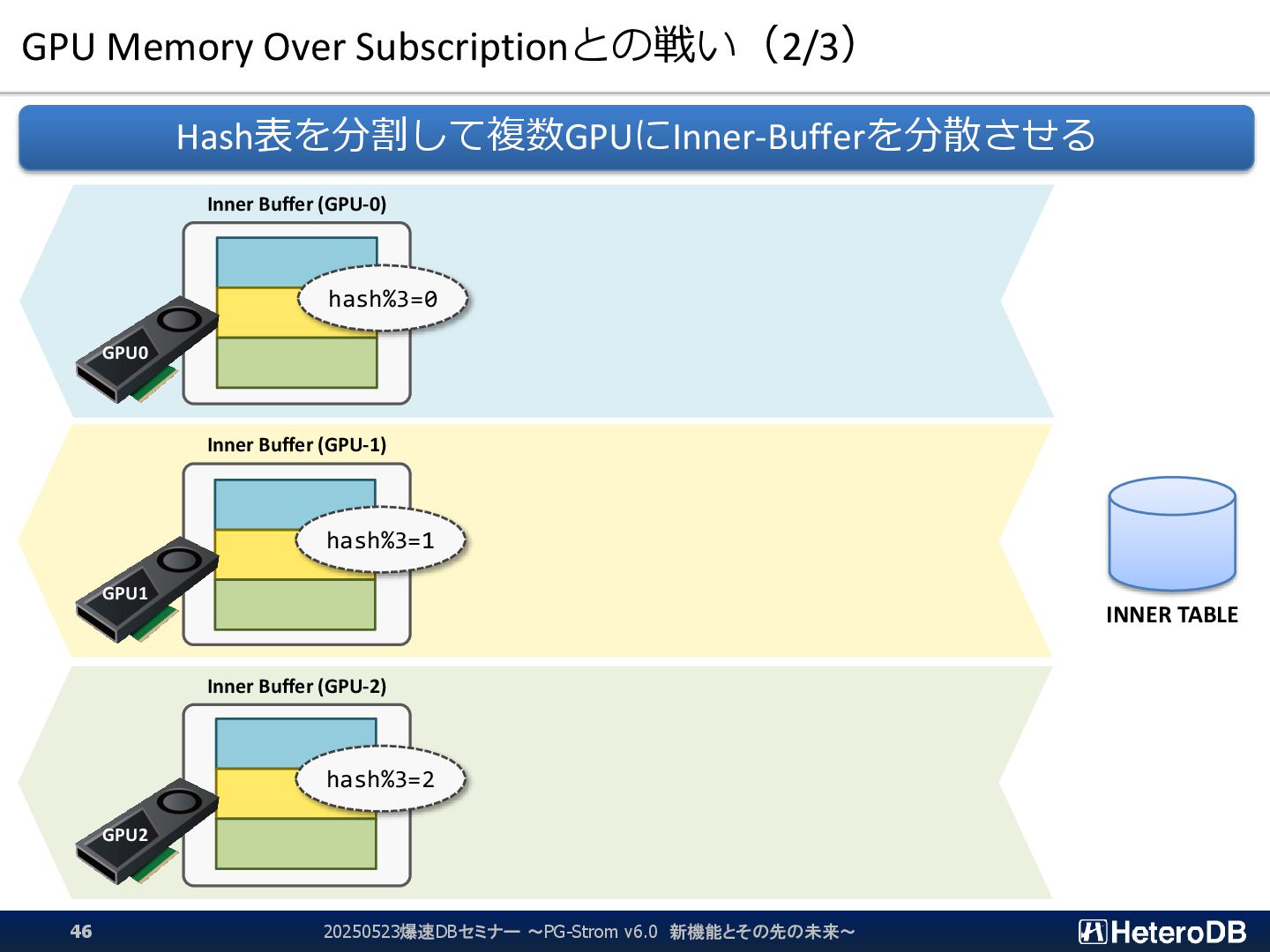{kind=link}
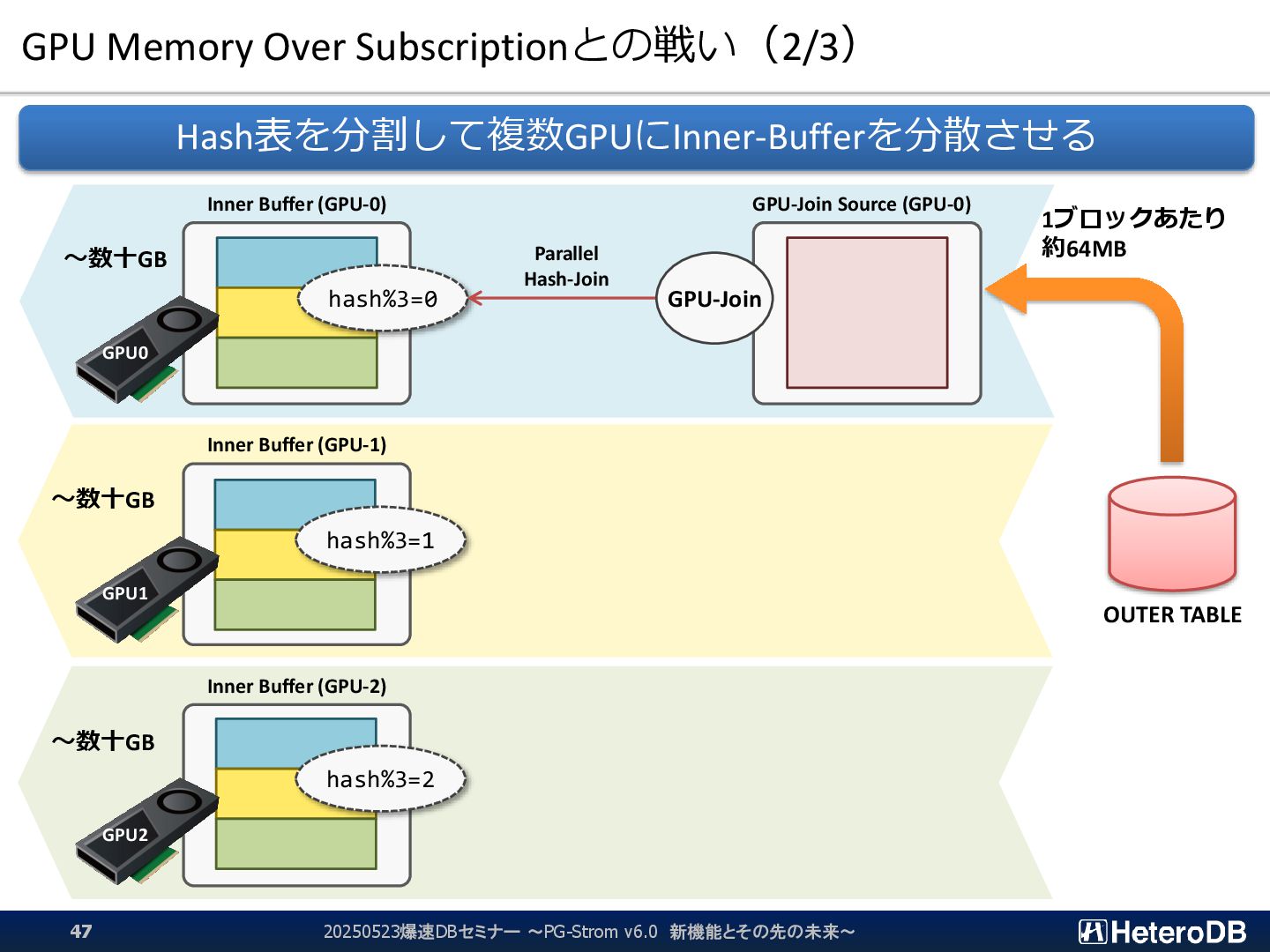{kind=link}
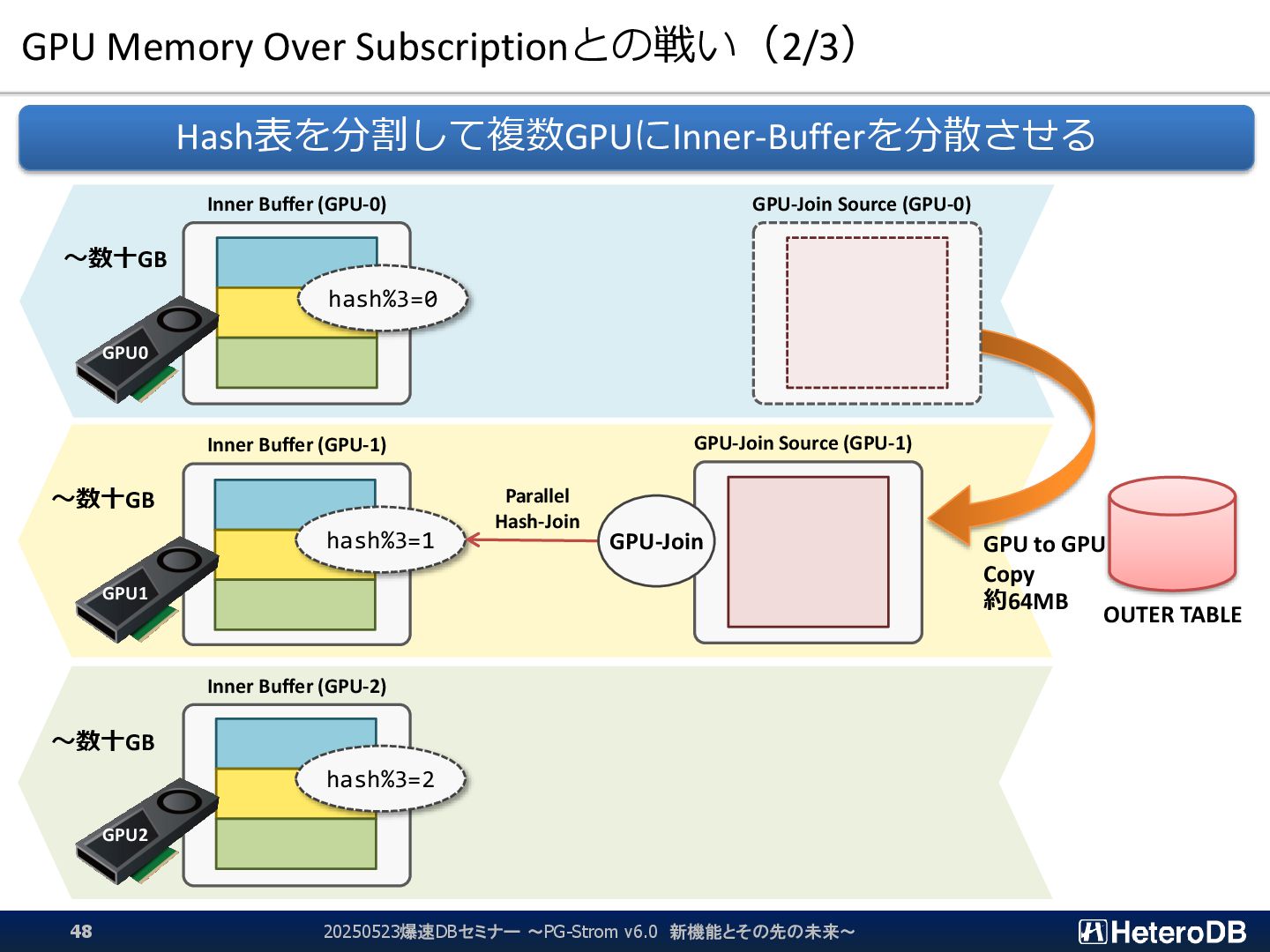{kind=link}
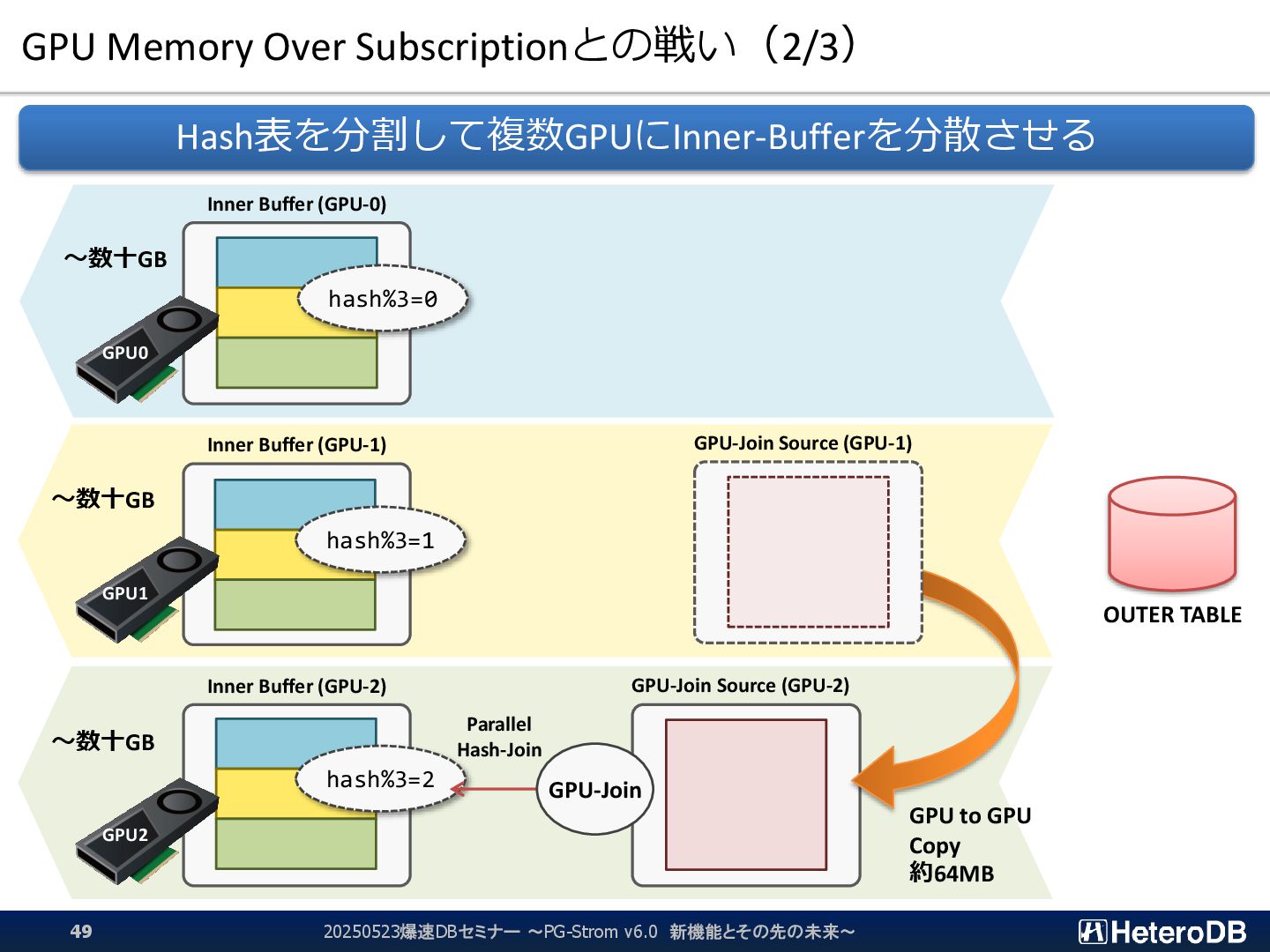{kind=link}
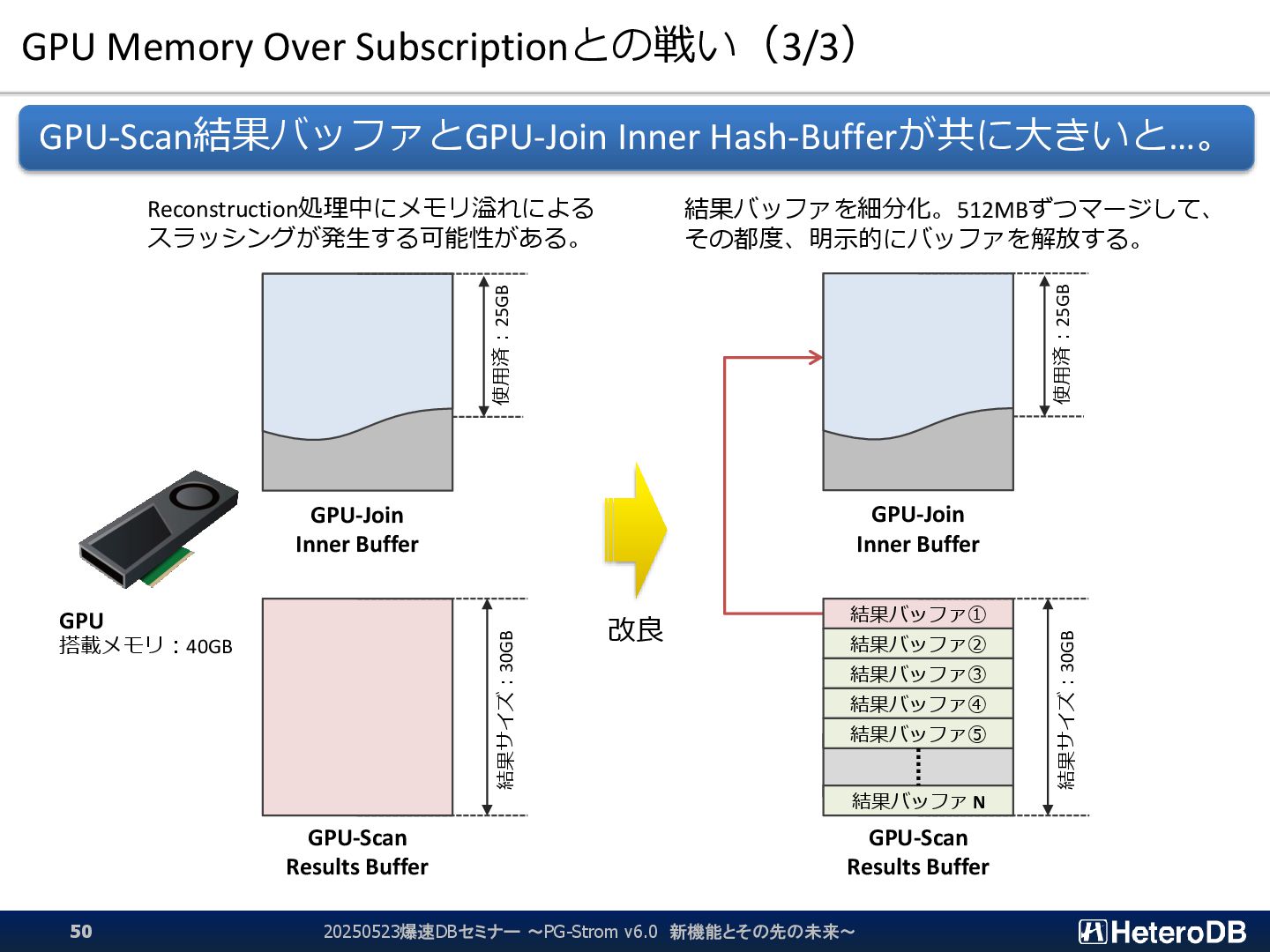{kind=link}
{kind=link}
{kind=link}
{kind=link}
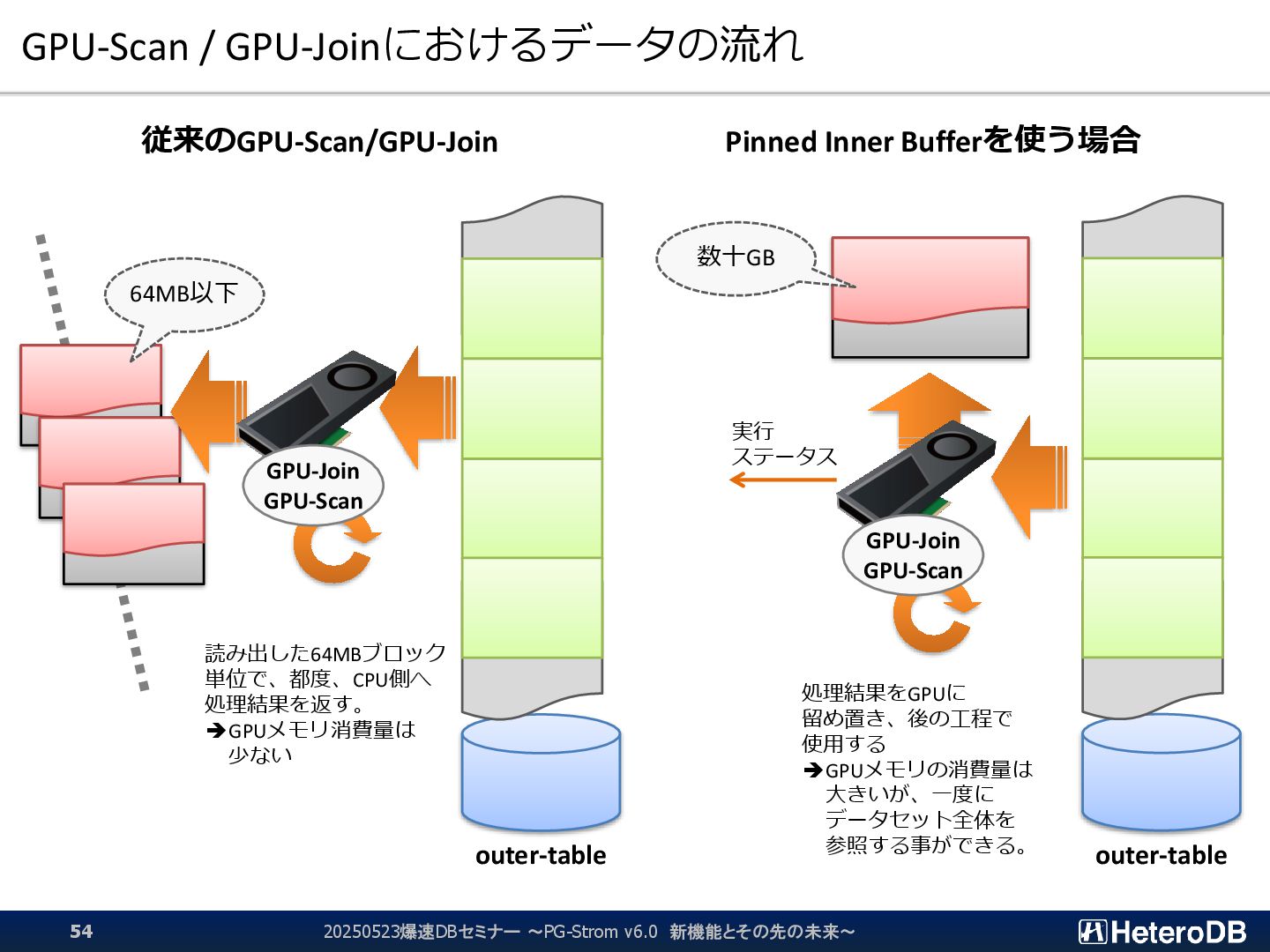{kind=link}
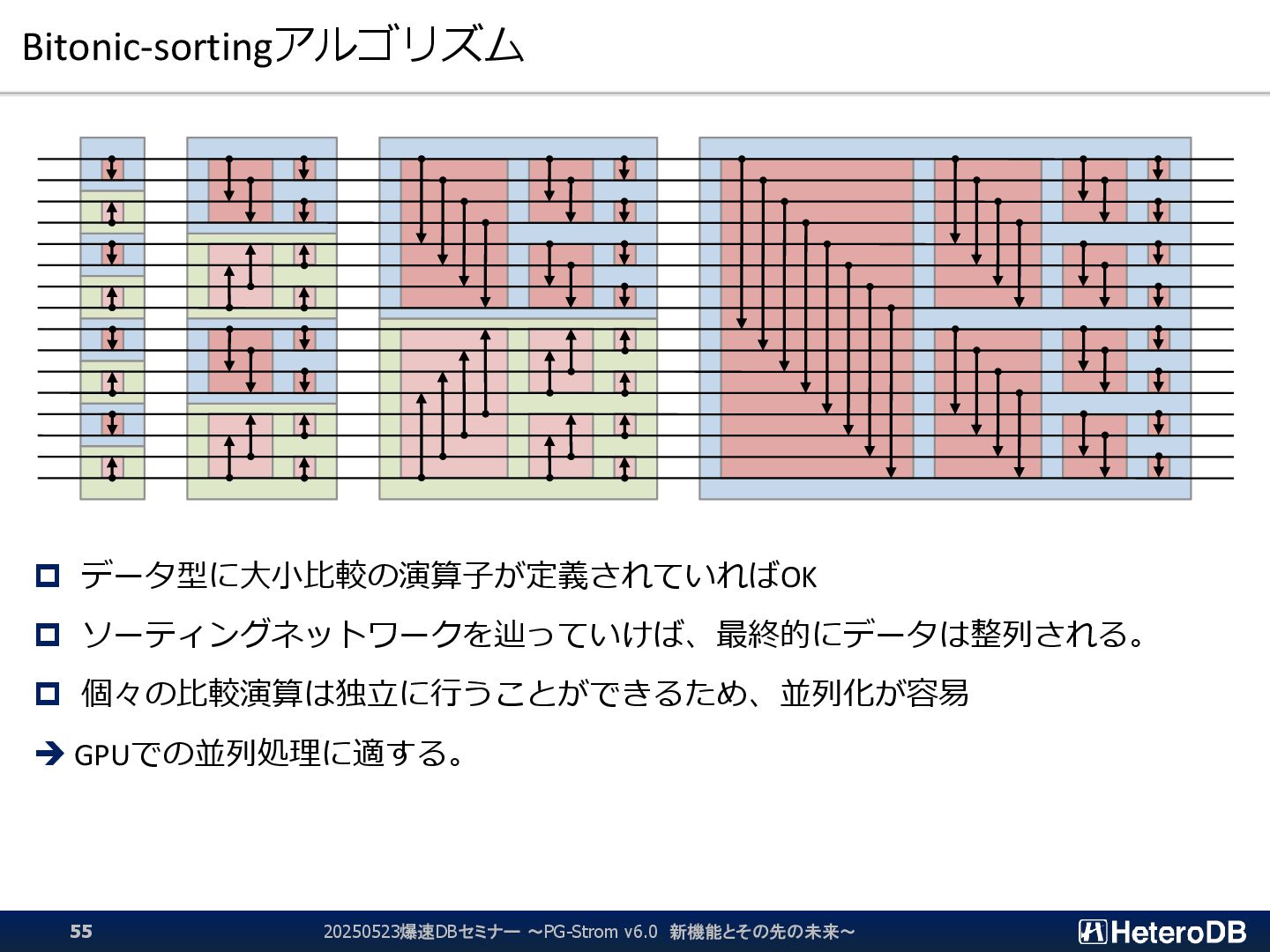{kind=link}
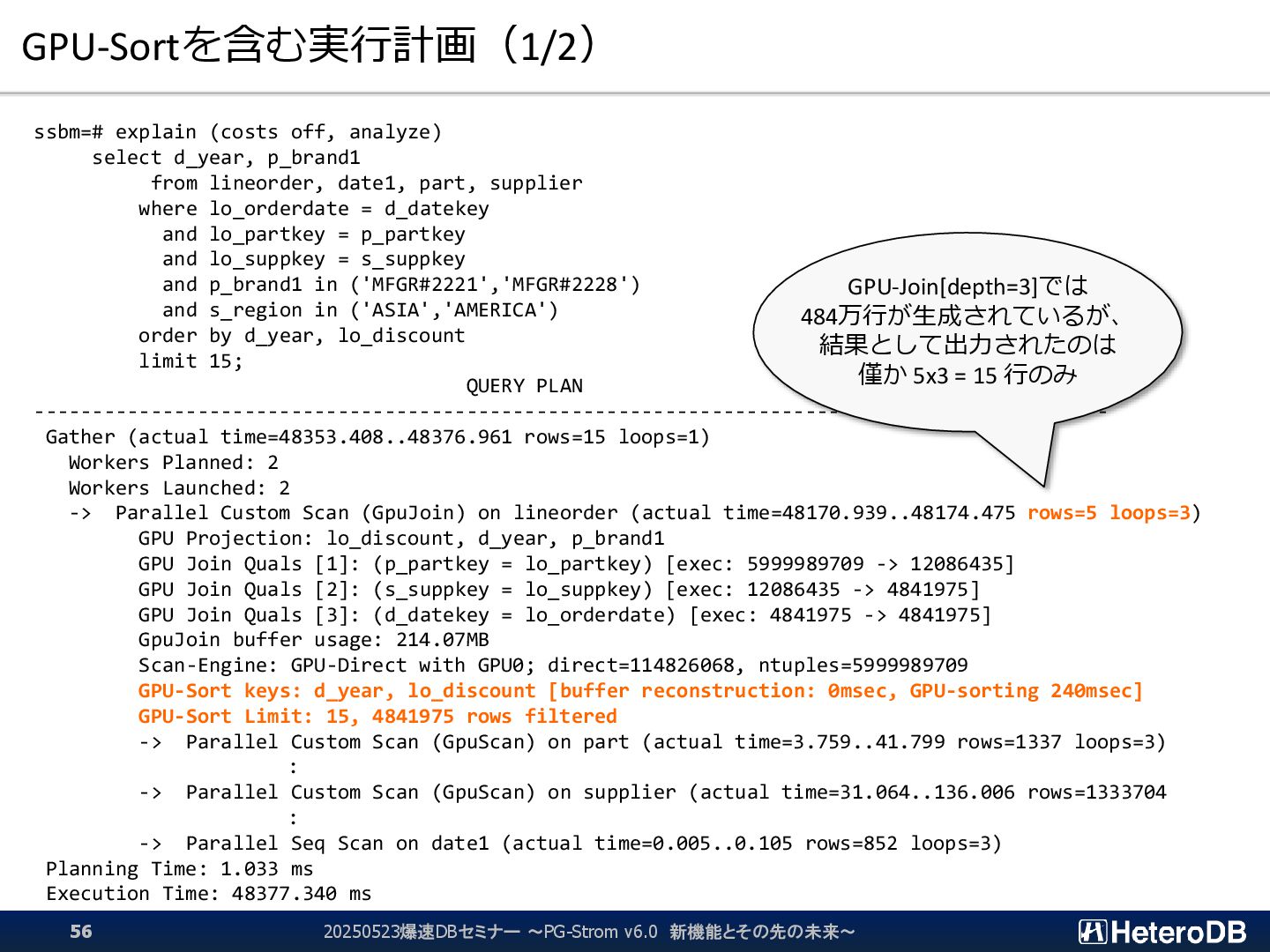{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
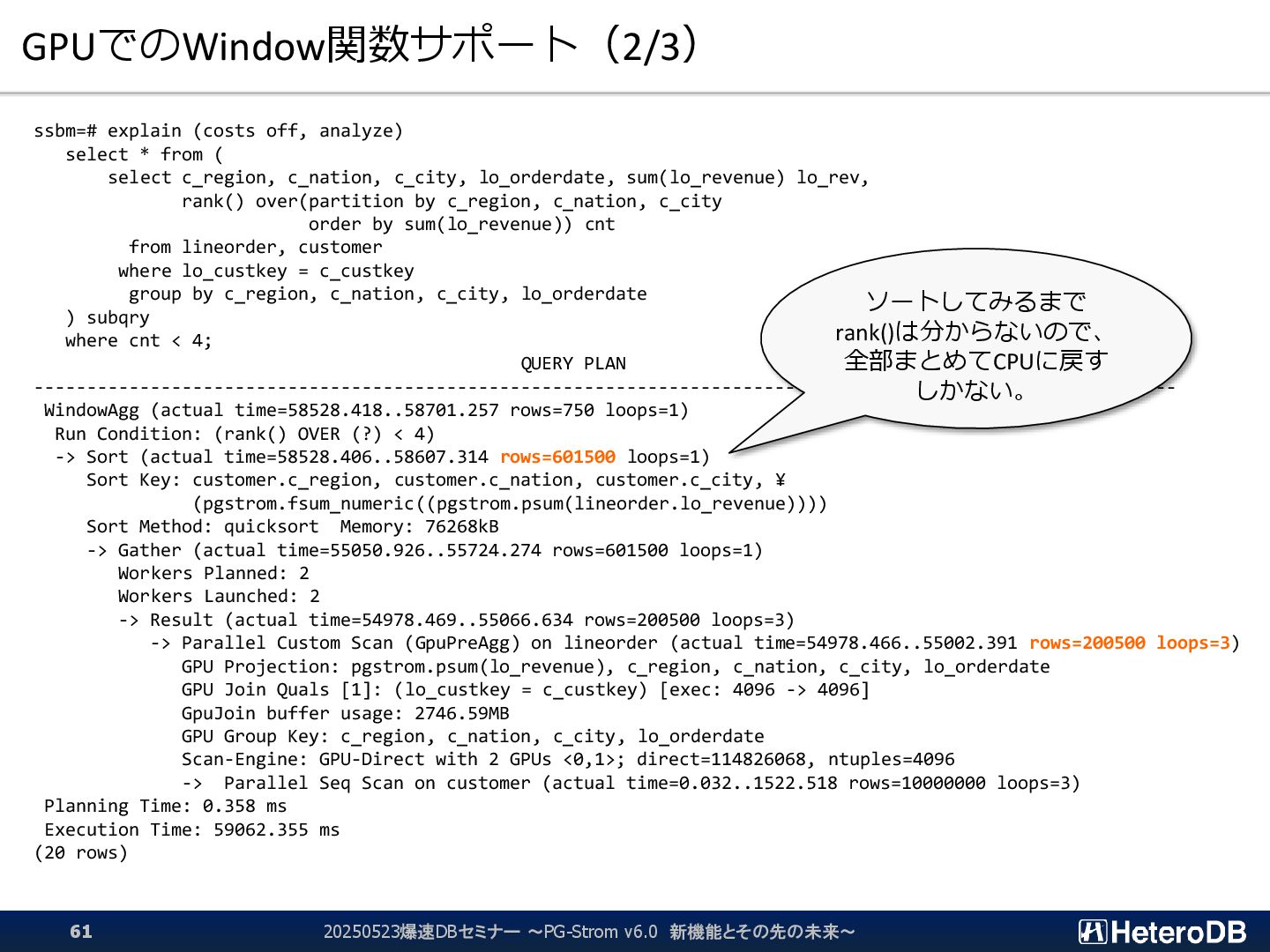{kind=link}
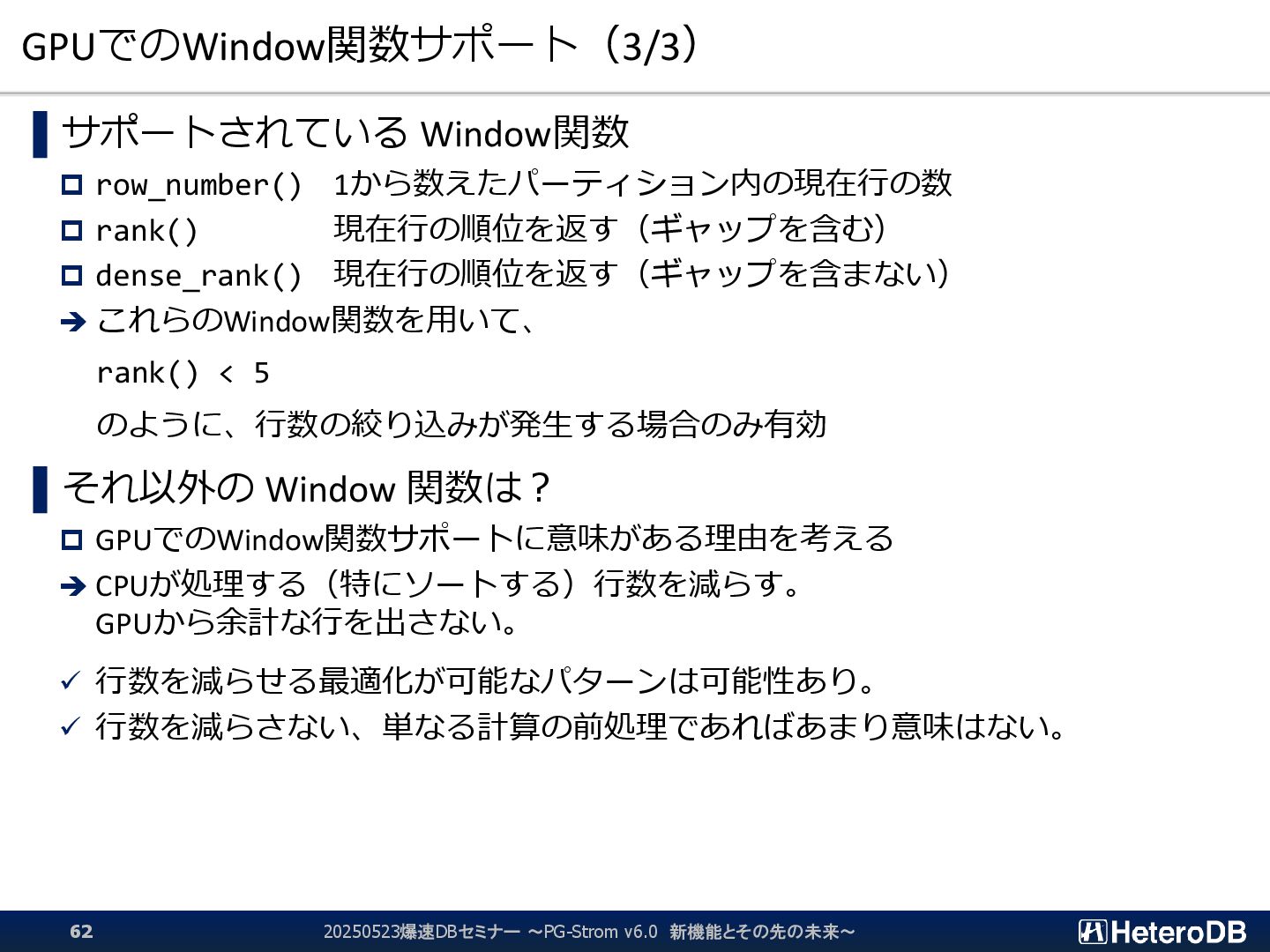{kind=link}
{kind=link}
{kind=link}
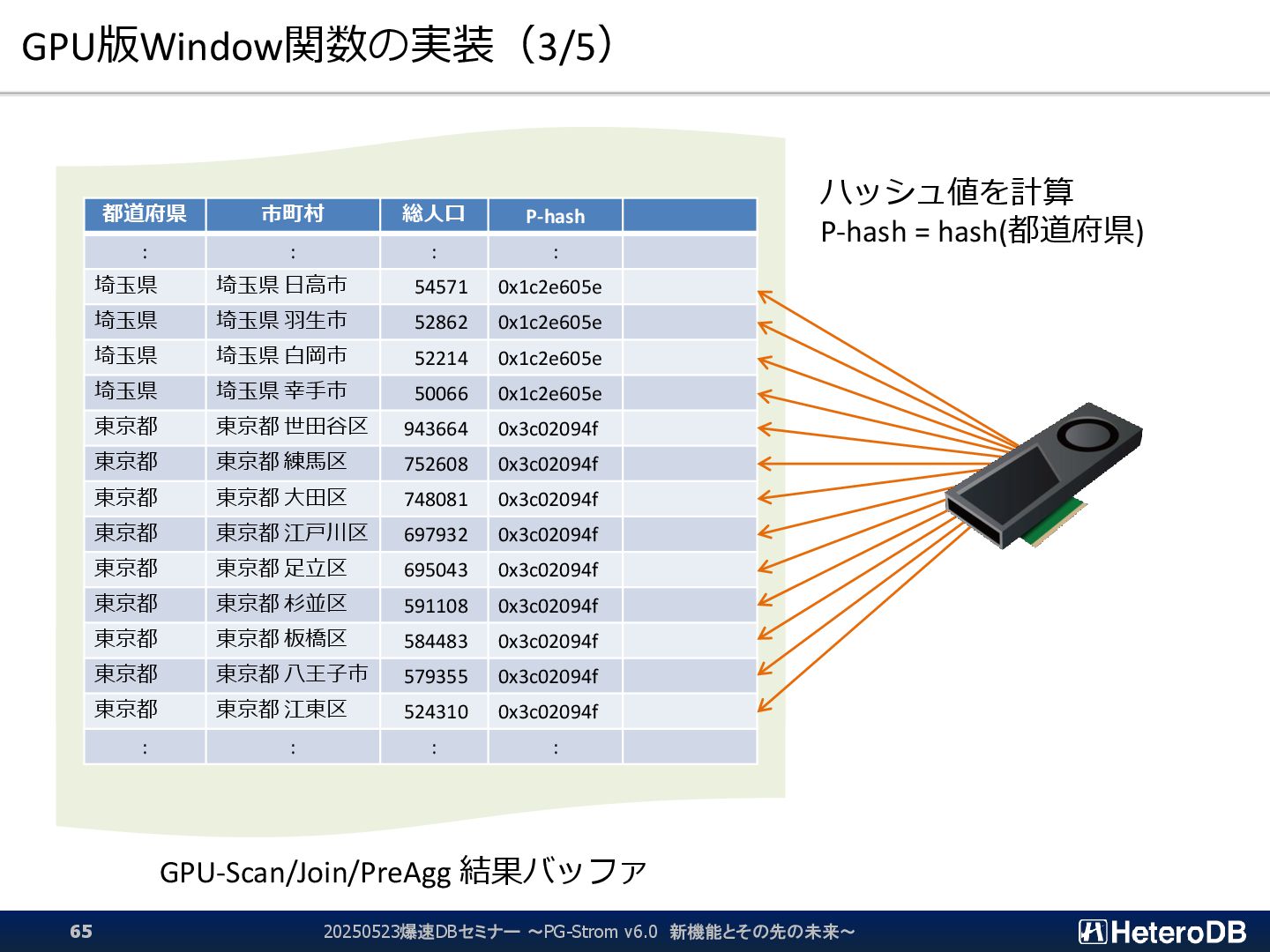{kind=link}
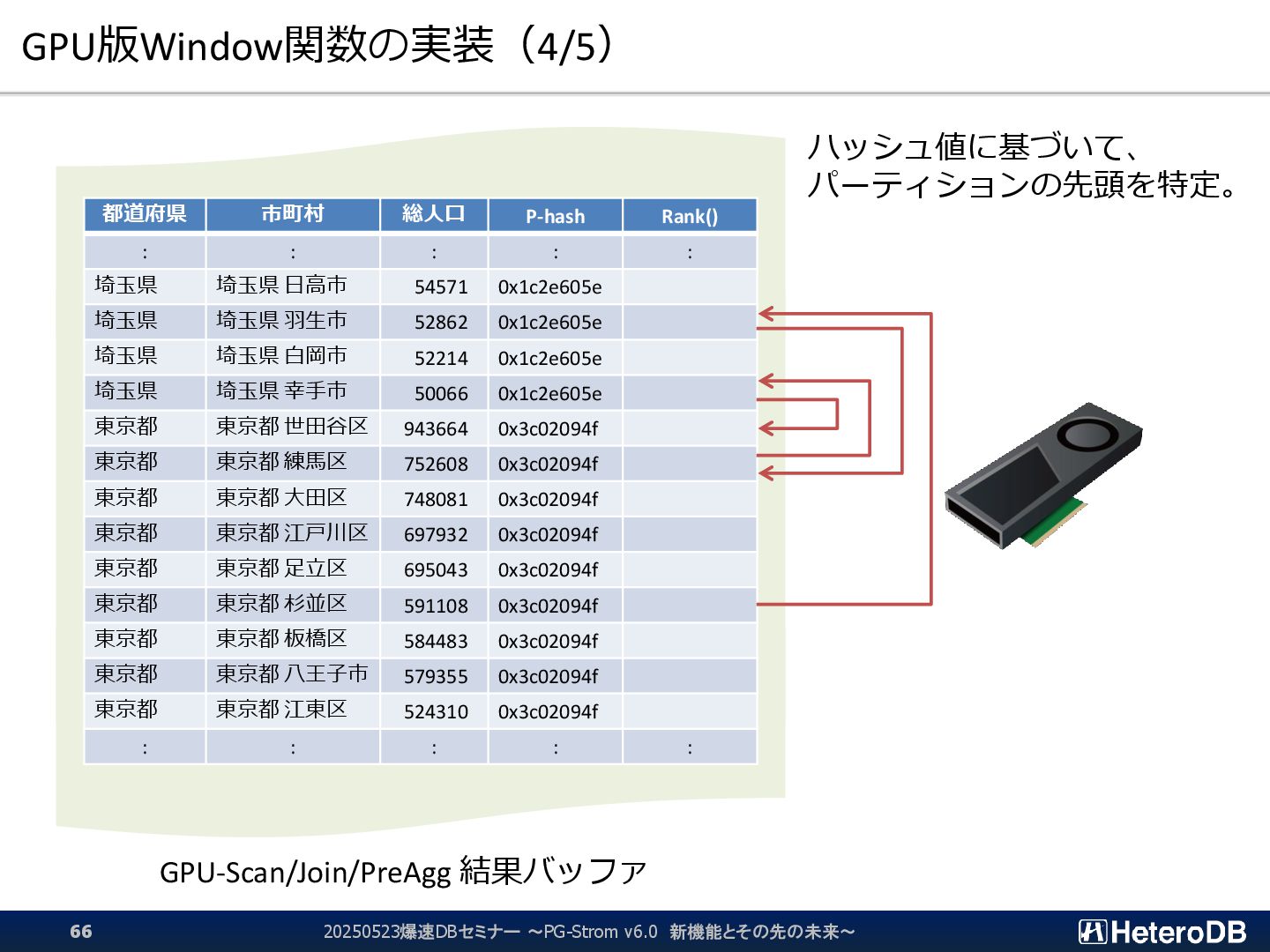{kind=link}
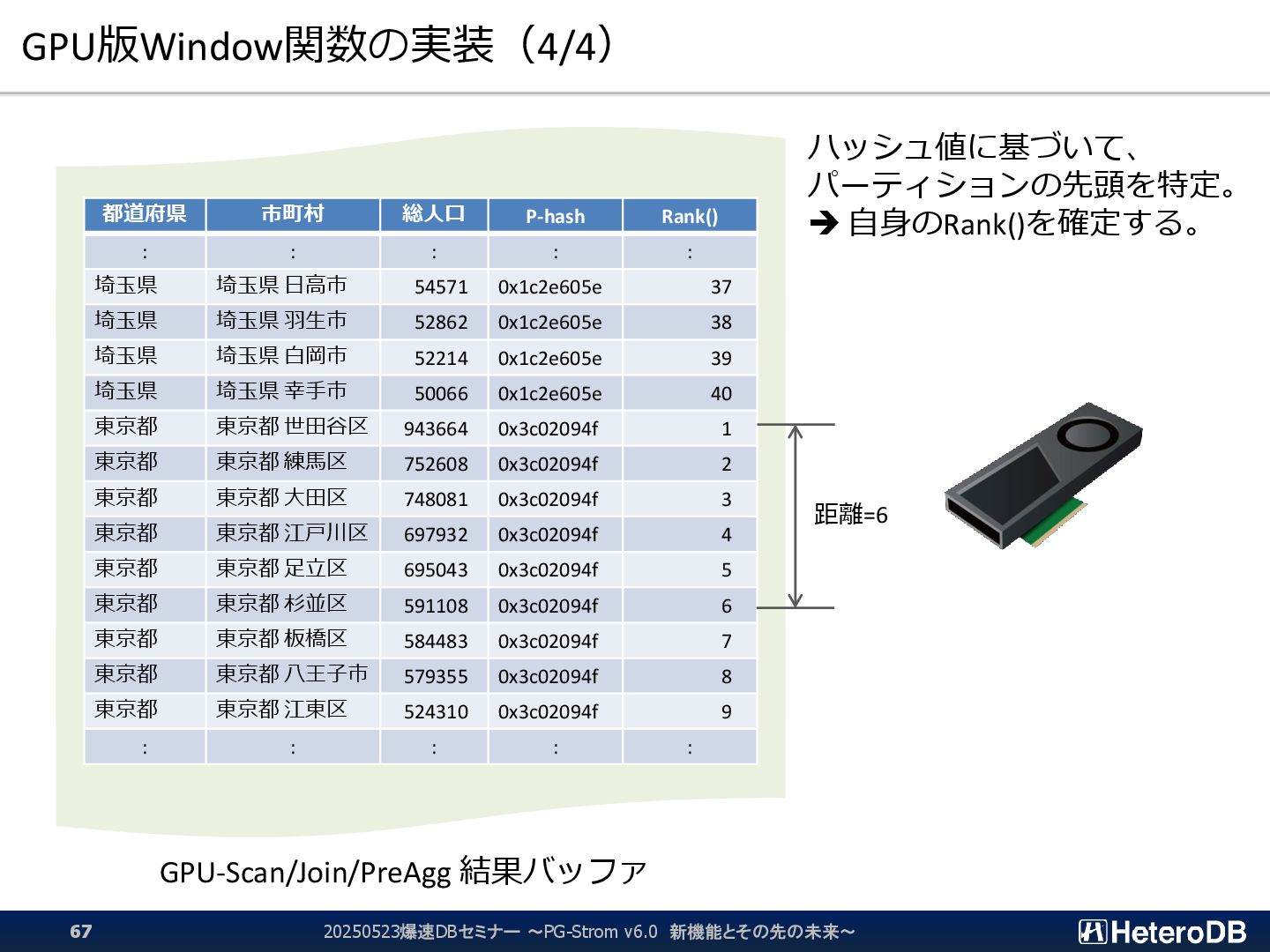{kind=link}
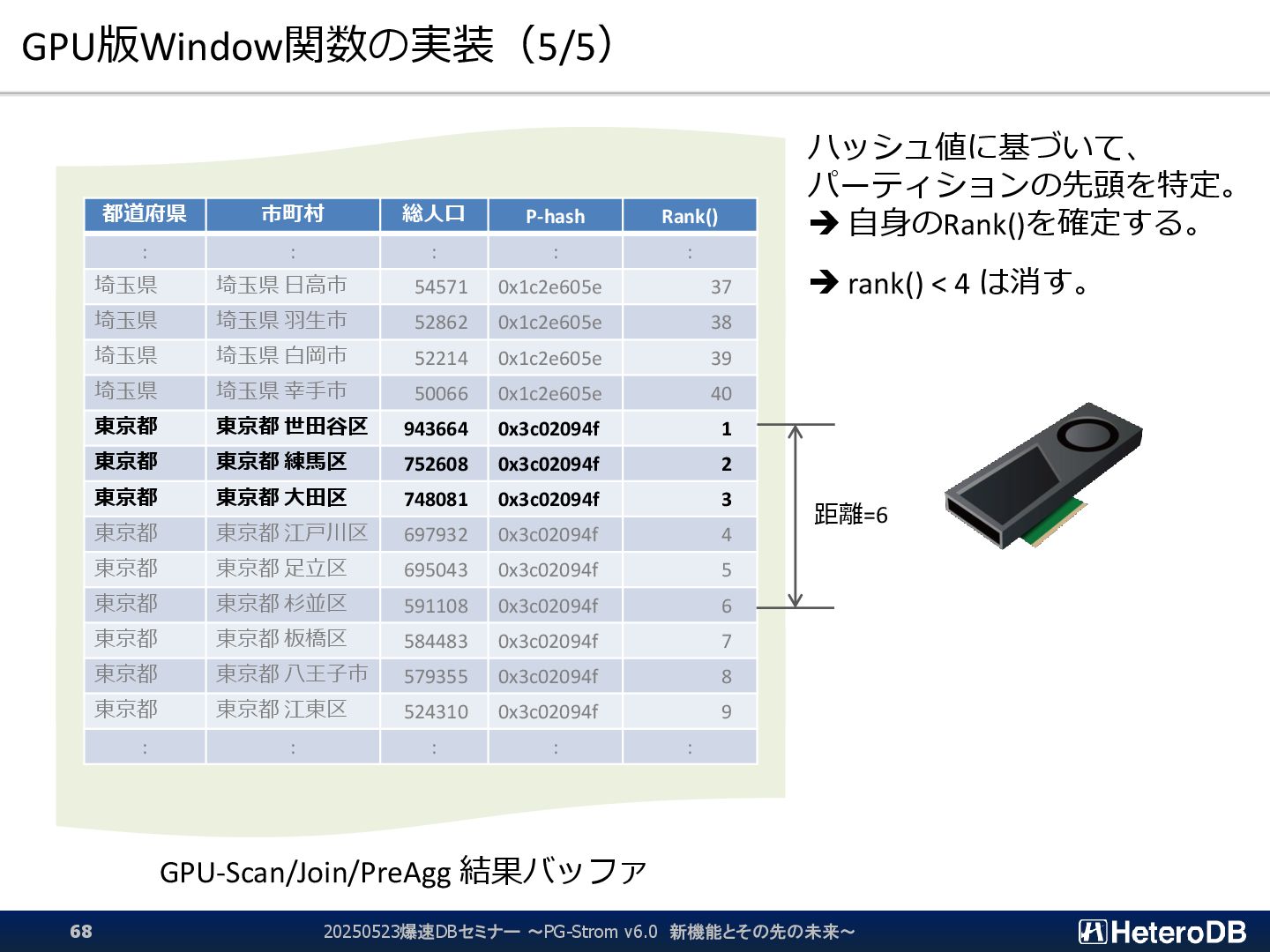{kind=link}
{kind=link}
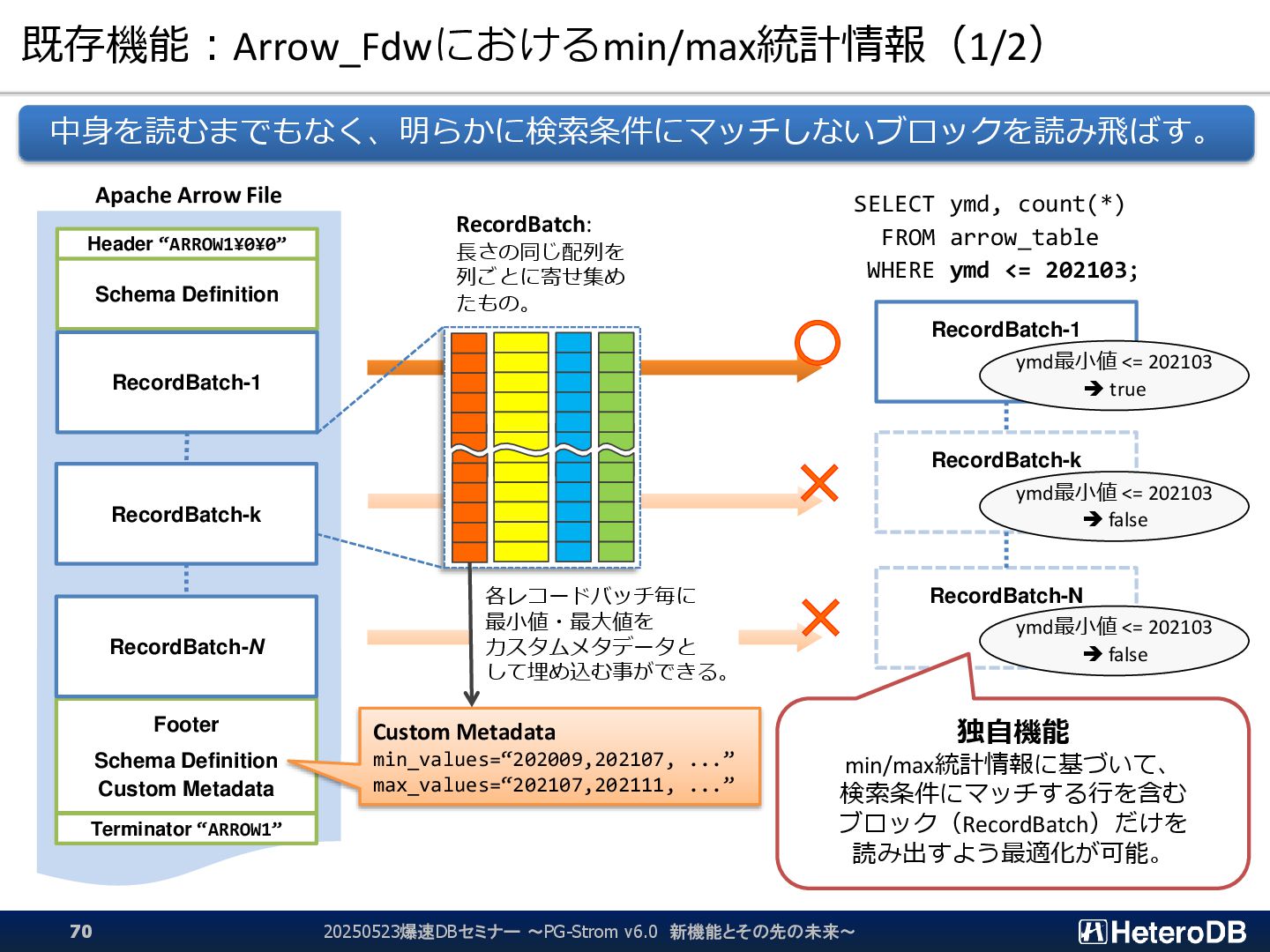{kind=link}
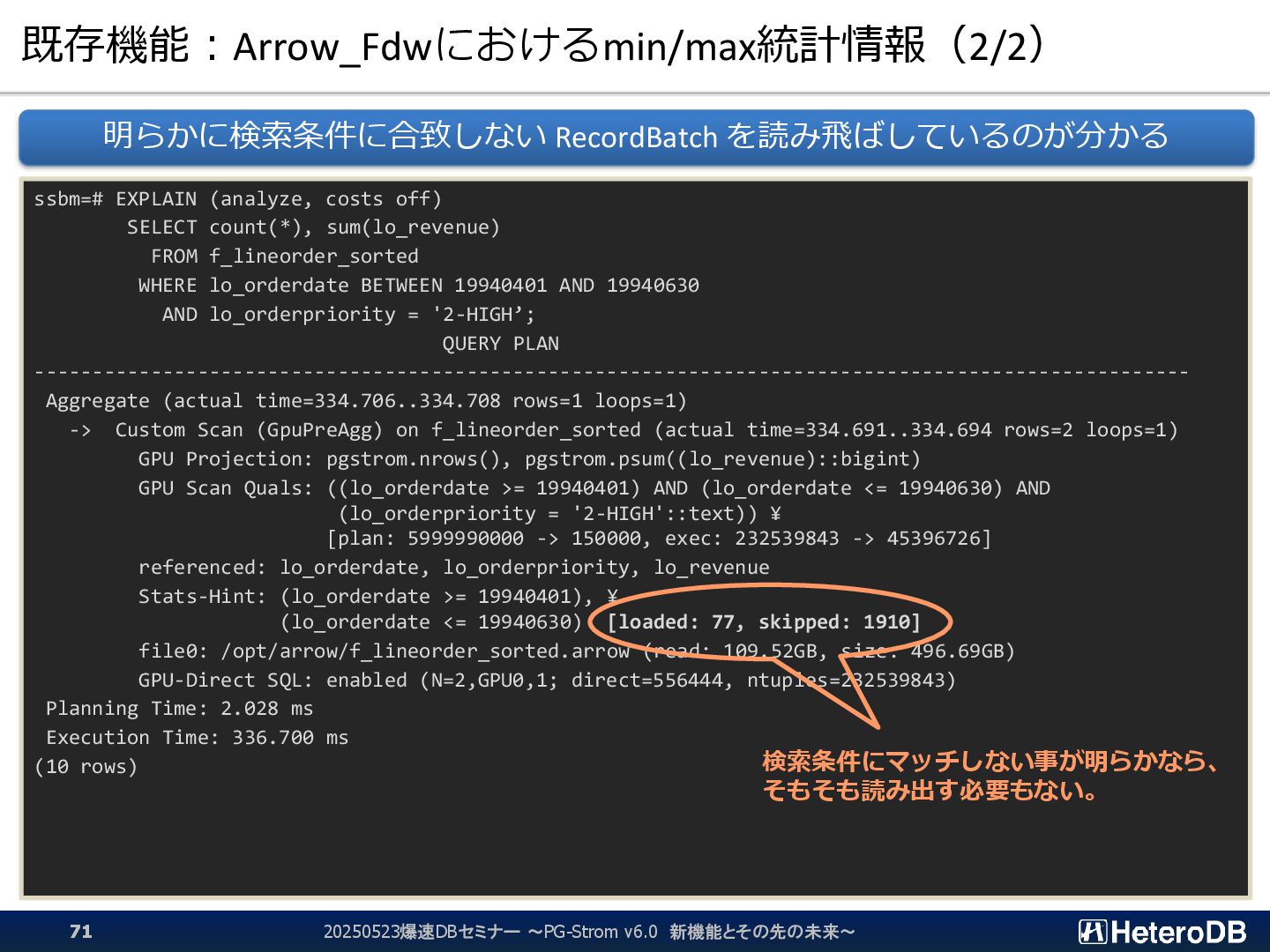{kind=link}
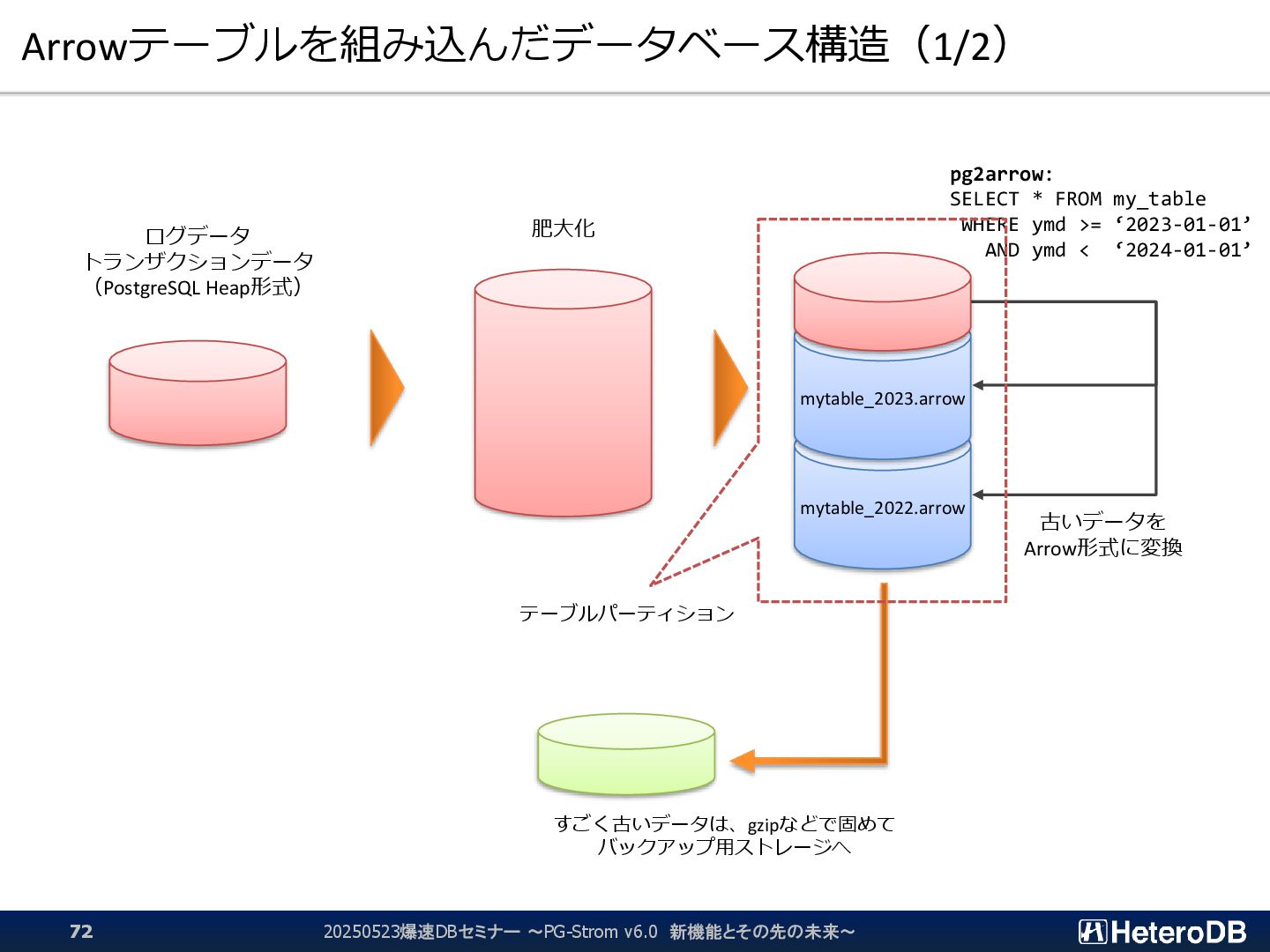{kind=link}
{kind=link}
{kind=link}
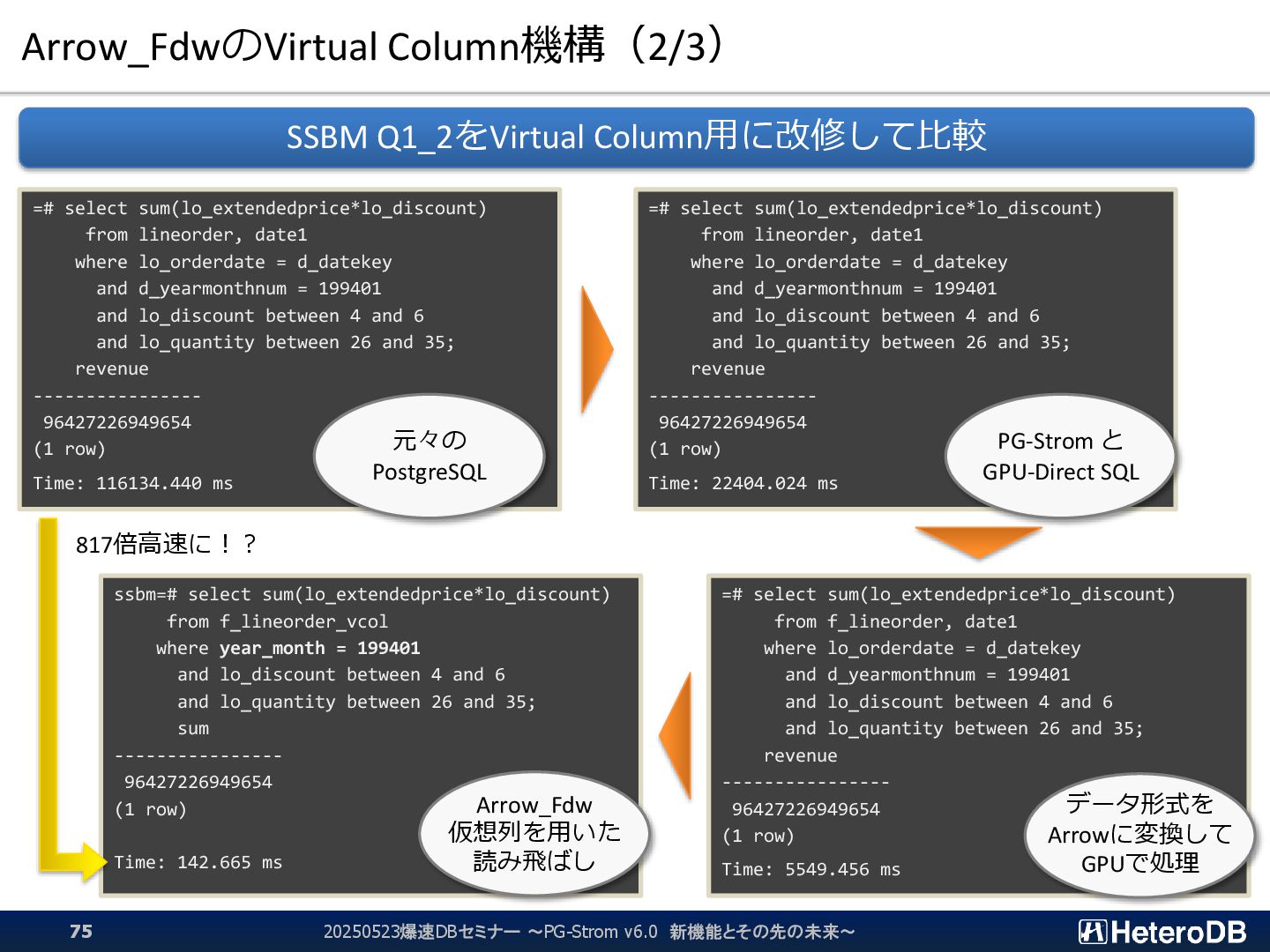{kind=link}
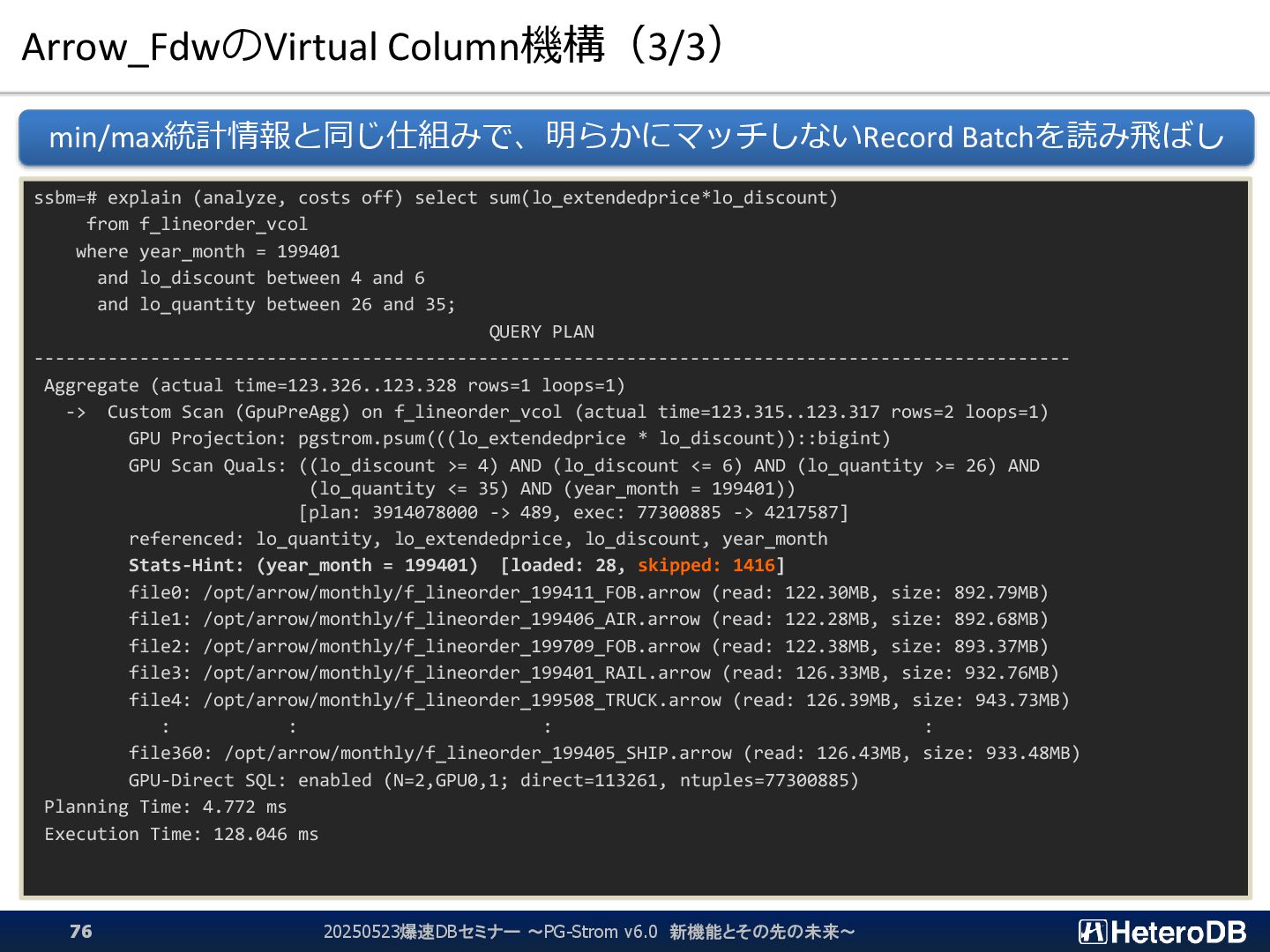{kind=link}
{kind=link}
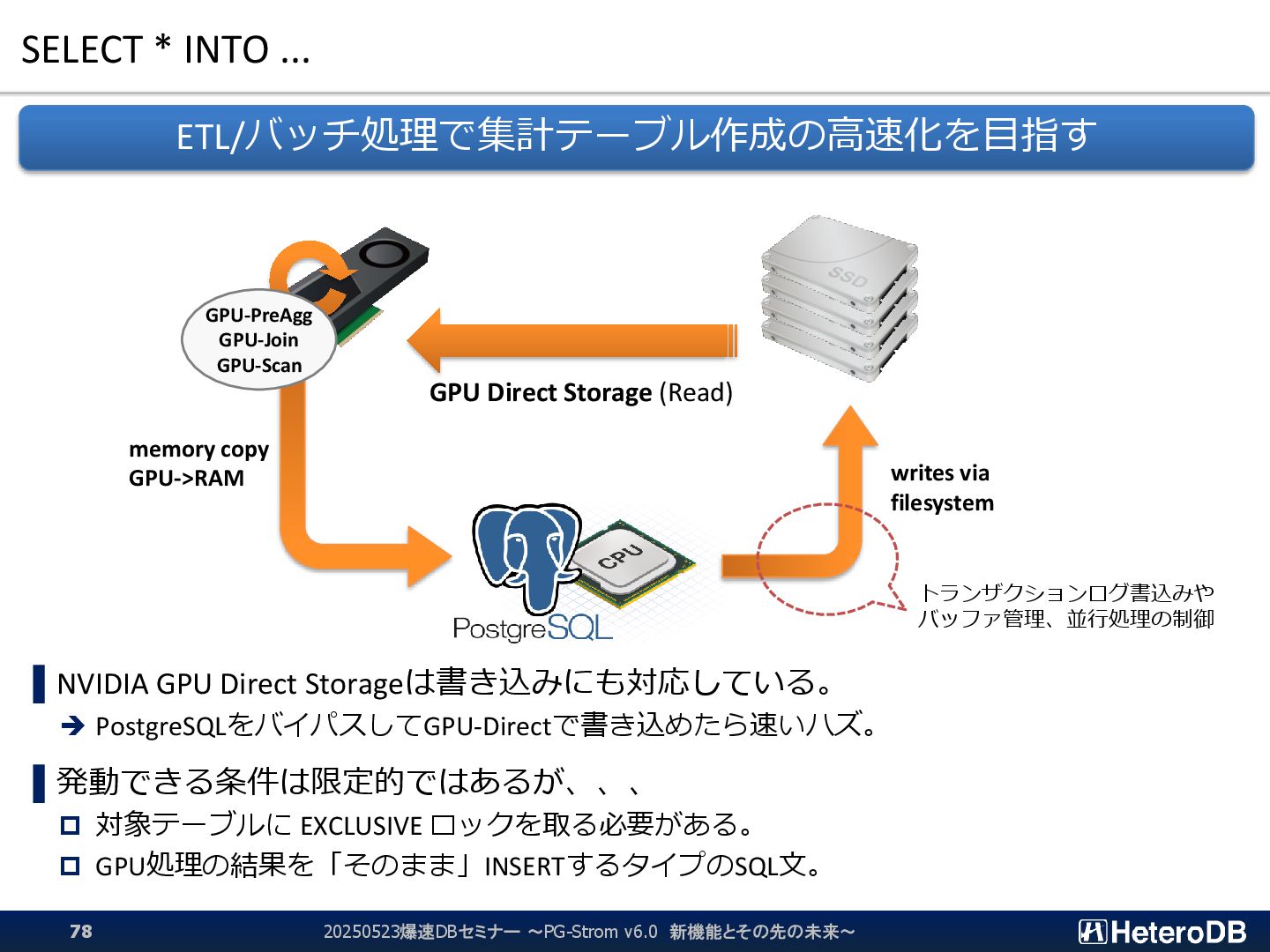{kind=link}
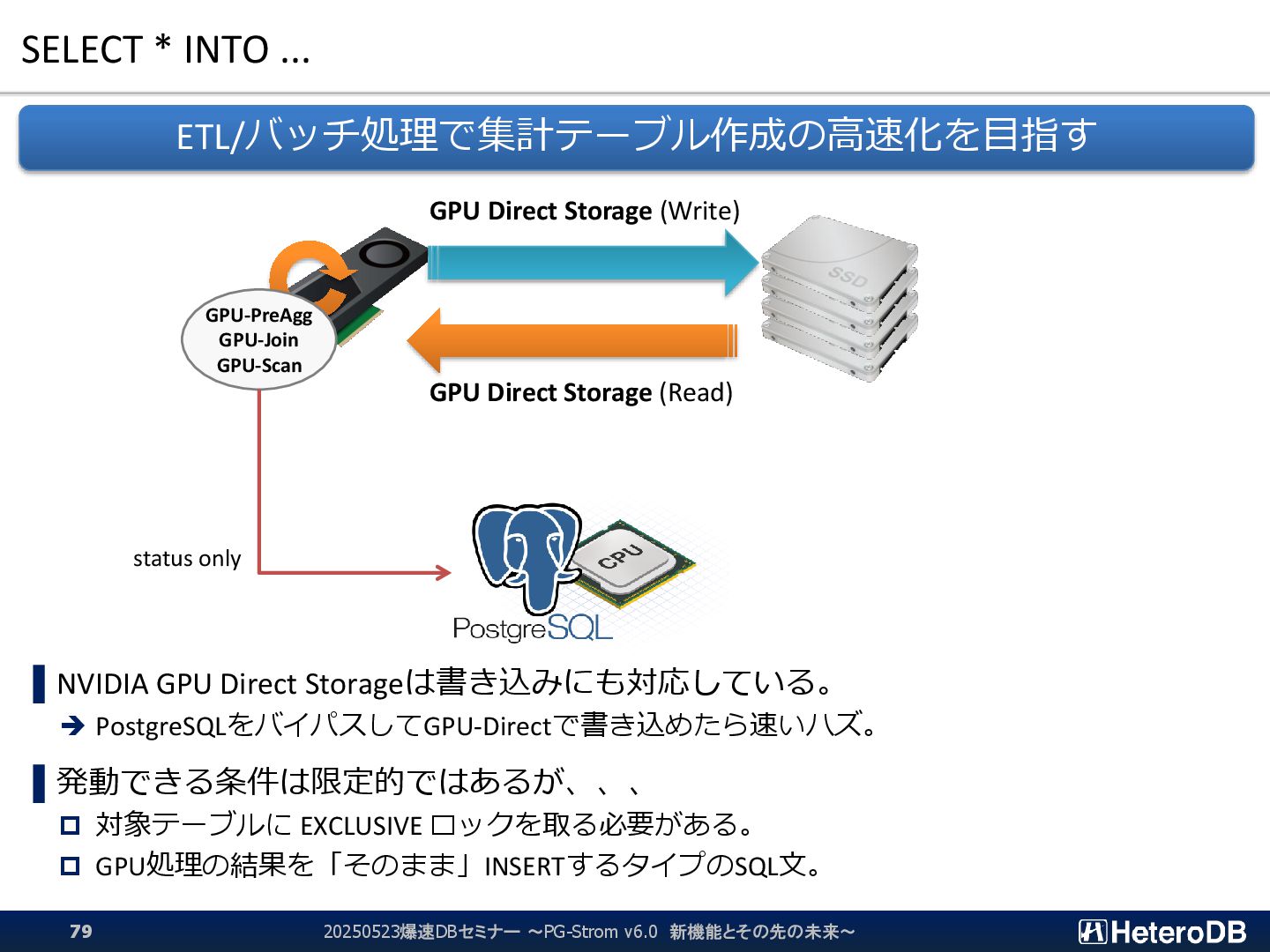{kind=link}
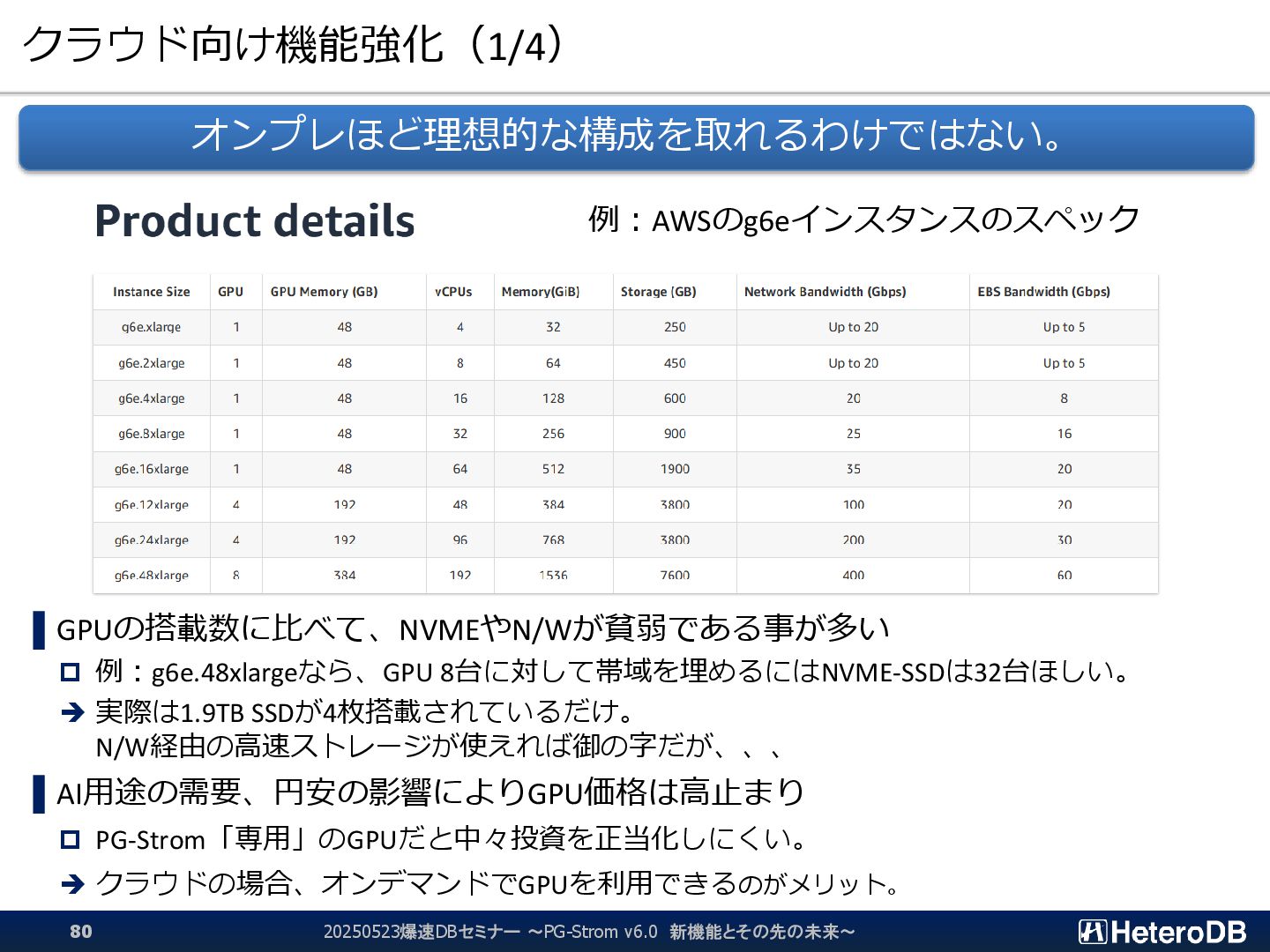{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}