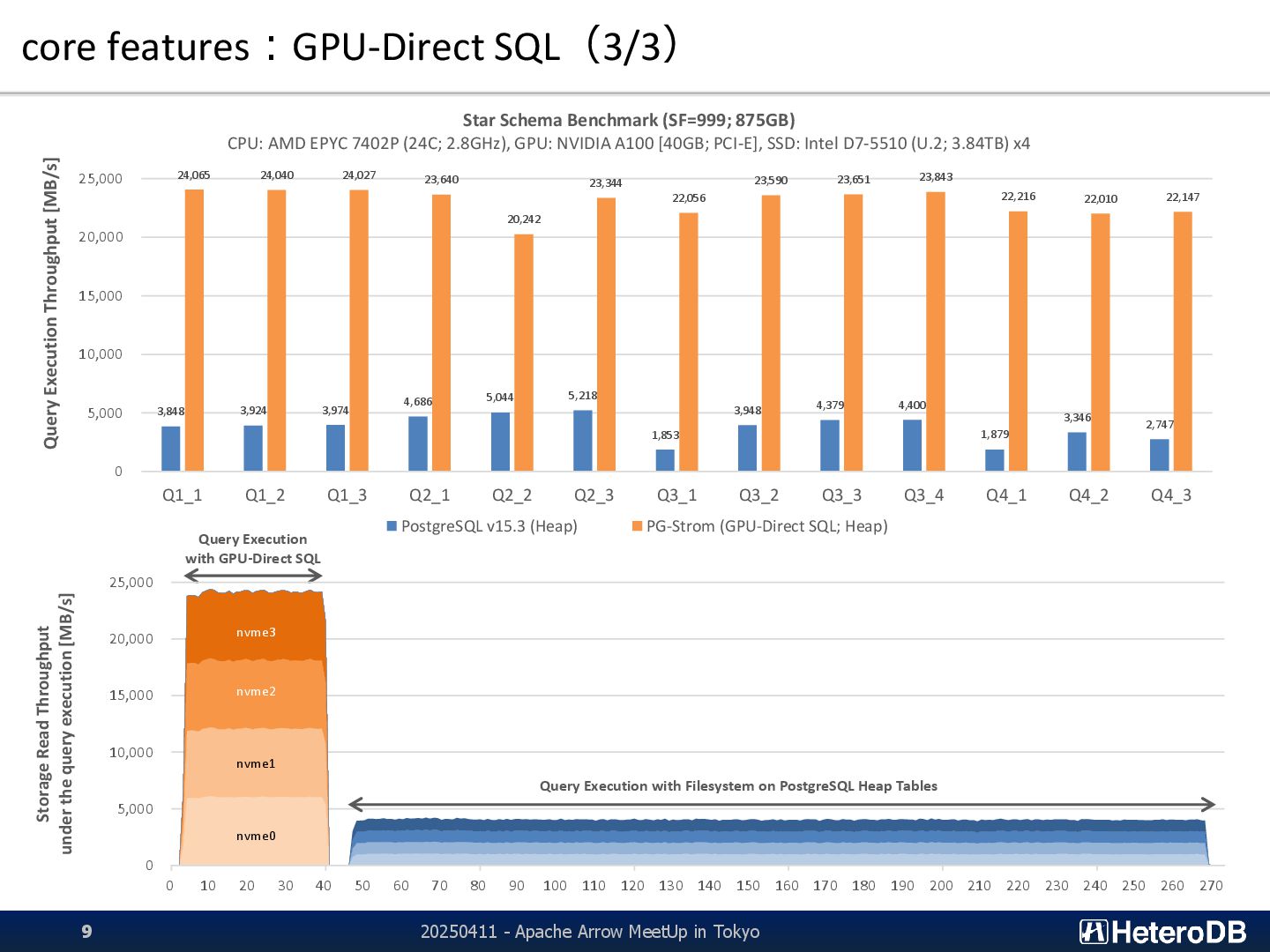
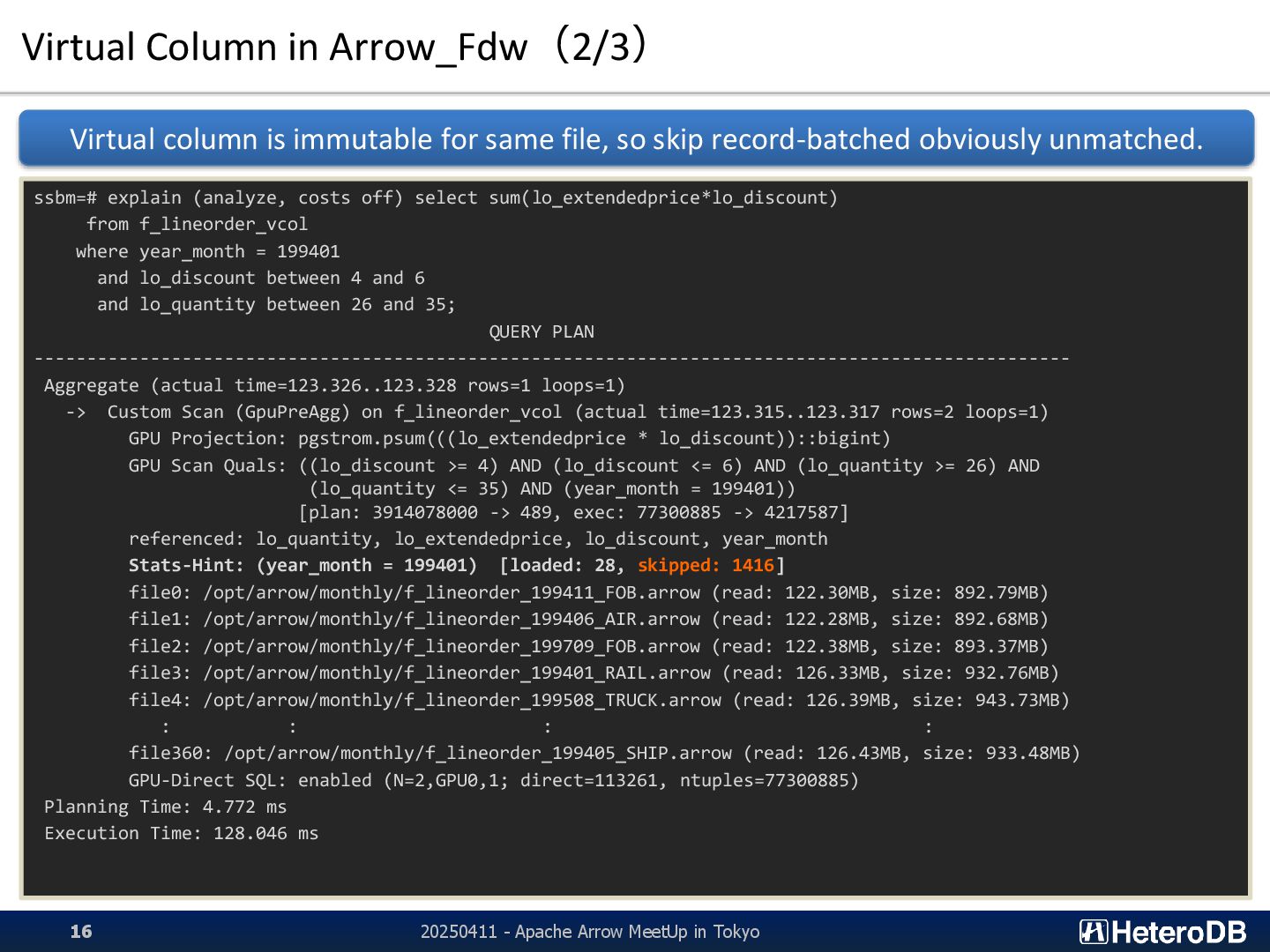
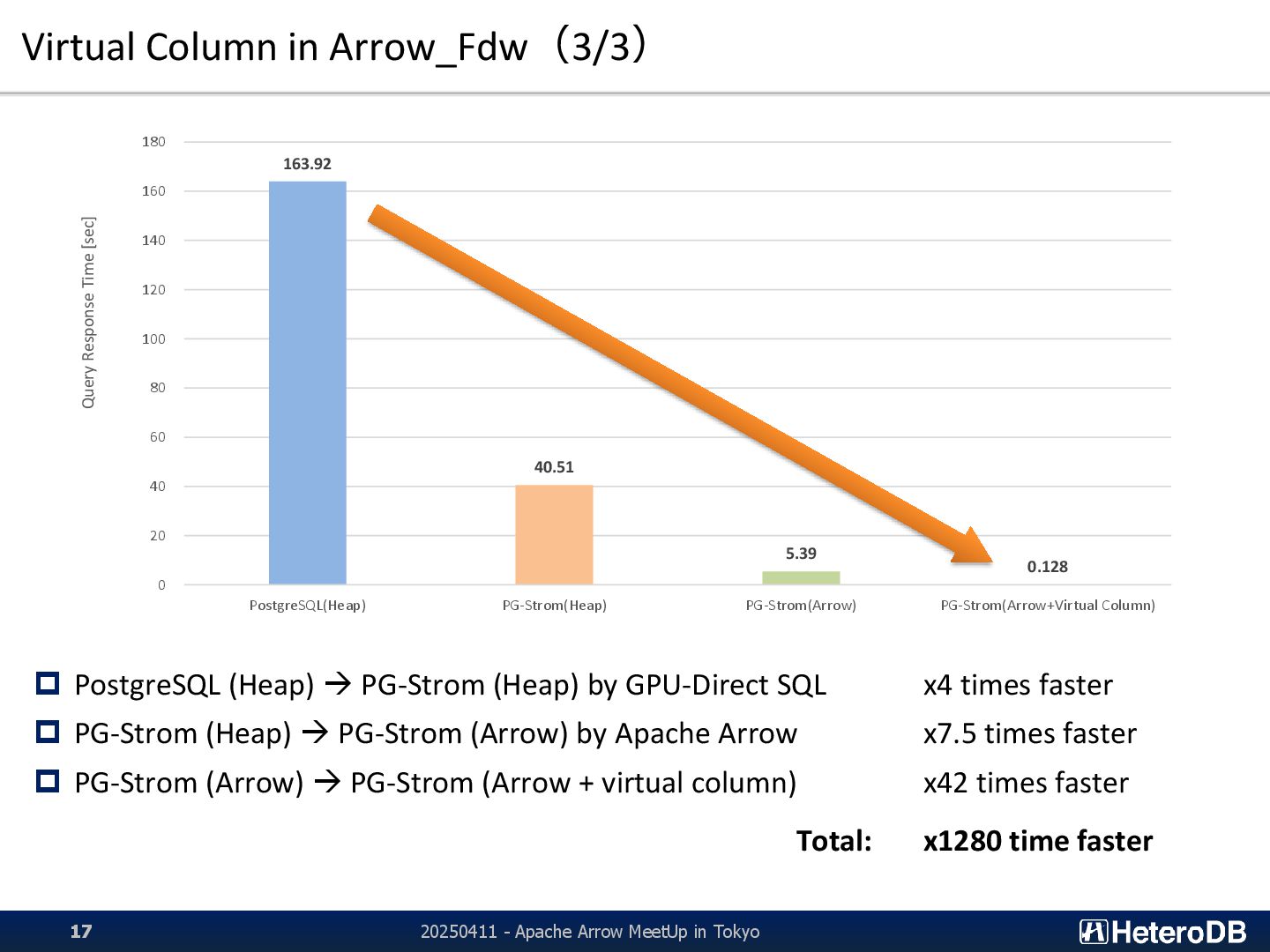
Apache Arrow MeetUp in Tokyo 9 3,848 3,924 3,974 4,686 5,044 5,218 1,853 3,948 4,379 4,400 1,879 3,346 2,747 24,065 24,040 24,027 23,640 20,242 23,344 22,056 23,590 23,651 23,843 22,216 22,010 22,147 0 5,000 10,000 15,000 20,000 25,000 Q1_1 Q1_2 Q1_3 Q2_1 Q2_2 Q2_3 Q3_1 Q3_2 Q3_3 Q3_4 Q4_1 Q4_2 Q4_3 Query Execution Throughput [MB/s] Star Schema Benchmark (SF=999; 875GB) CPU: AMD EPYC 7402P (24C; 2.8GHz), GPU: NVIDIA A100 [40GB; PCI-E], SSD: Intel D7-5510 (U.2; 3.84TB) x4 PostgreSQL v15.3 (Heap) PG-Strom (GPU-Direct SQL; Heap) 0 5,000 10,000 15,000 20,000 25,000 0 10 20 30 40 50 60 70 80 90 100 110 120 130 140 150 160 170 180 190 200 210 220 230 240 250 260 270 Storage Read Throughput under the query execution [MB/s] nvme3 nvme2 nvme1 nvme0 Query Execution with Filesystem on PostgreSQL Heap Tables
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
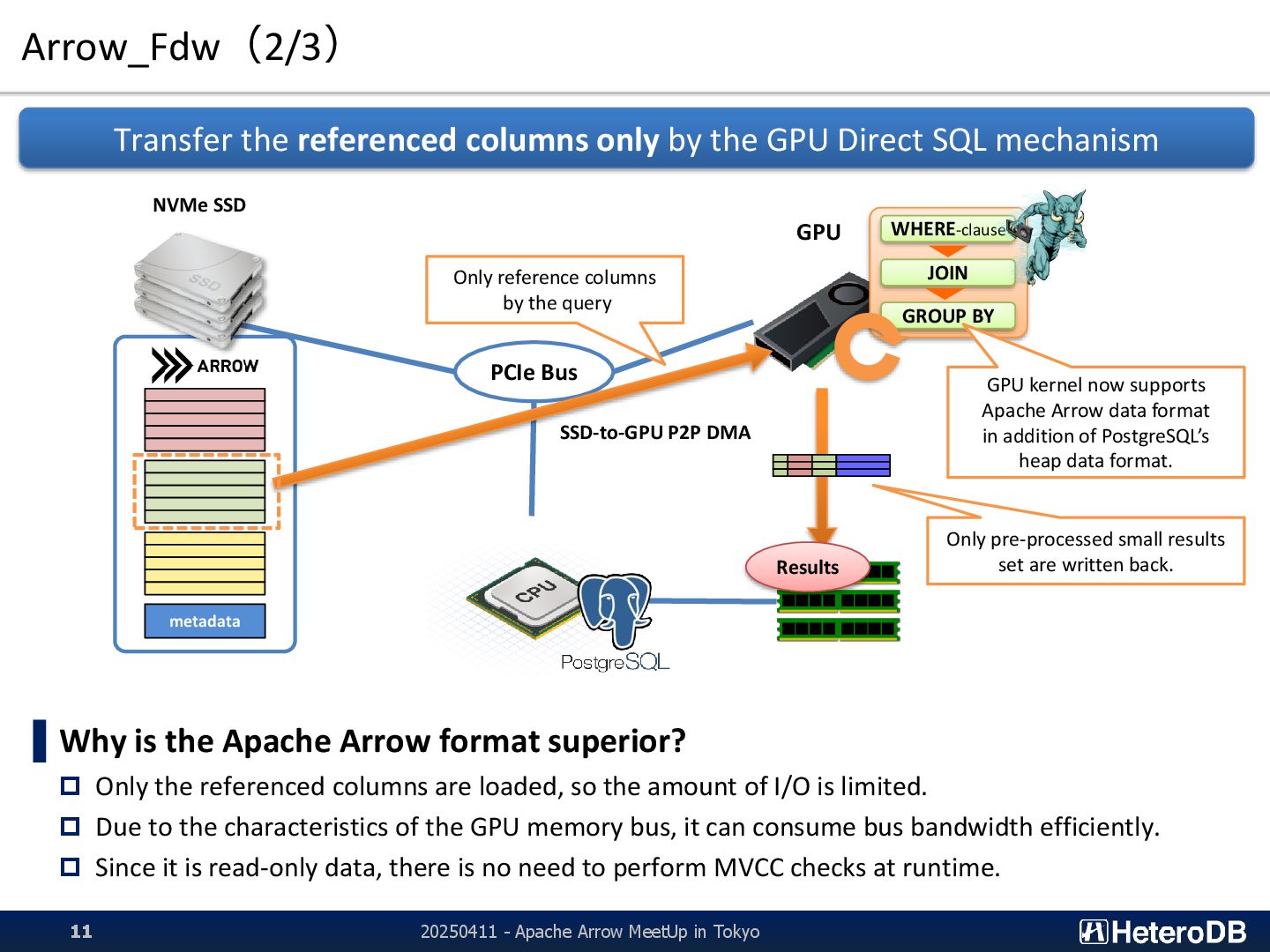{kind=link}
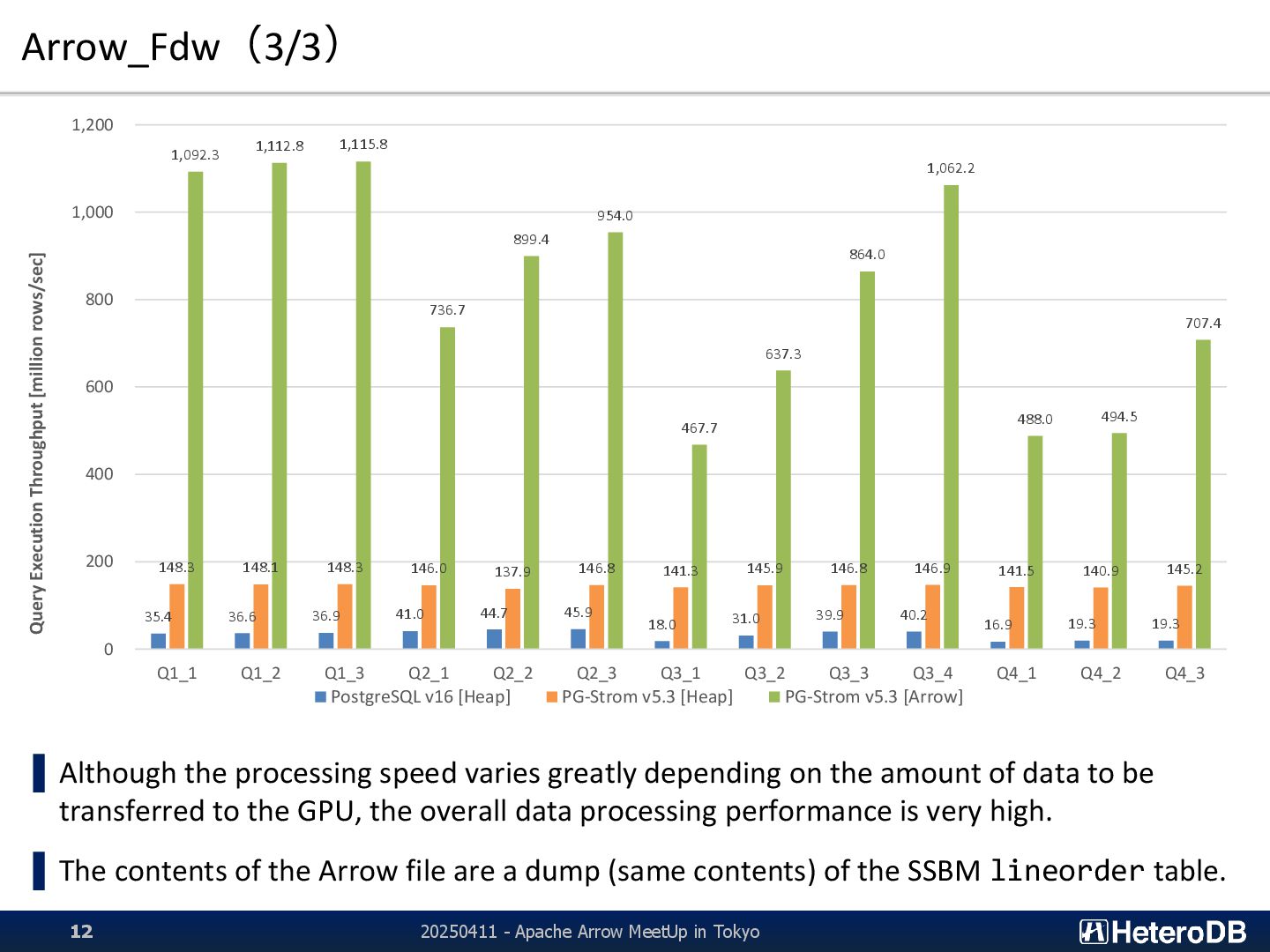{kind=link}
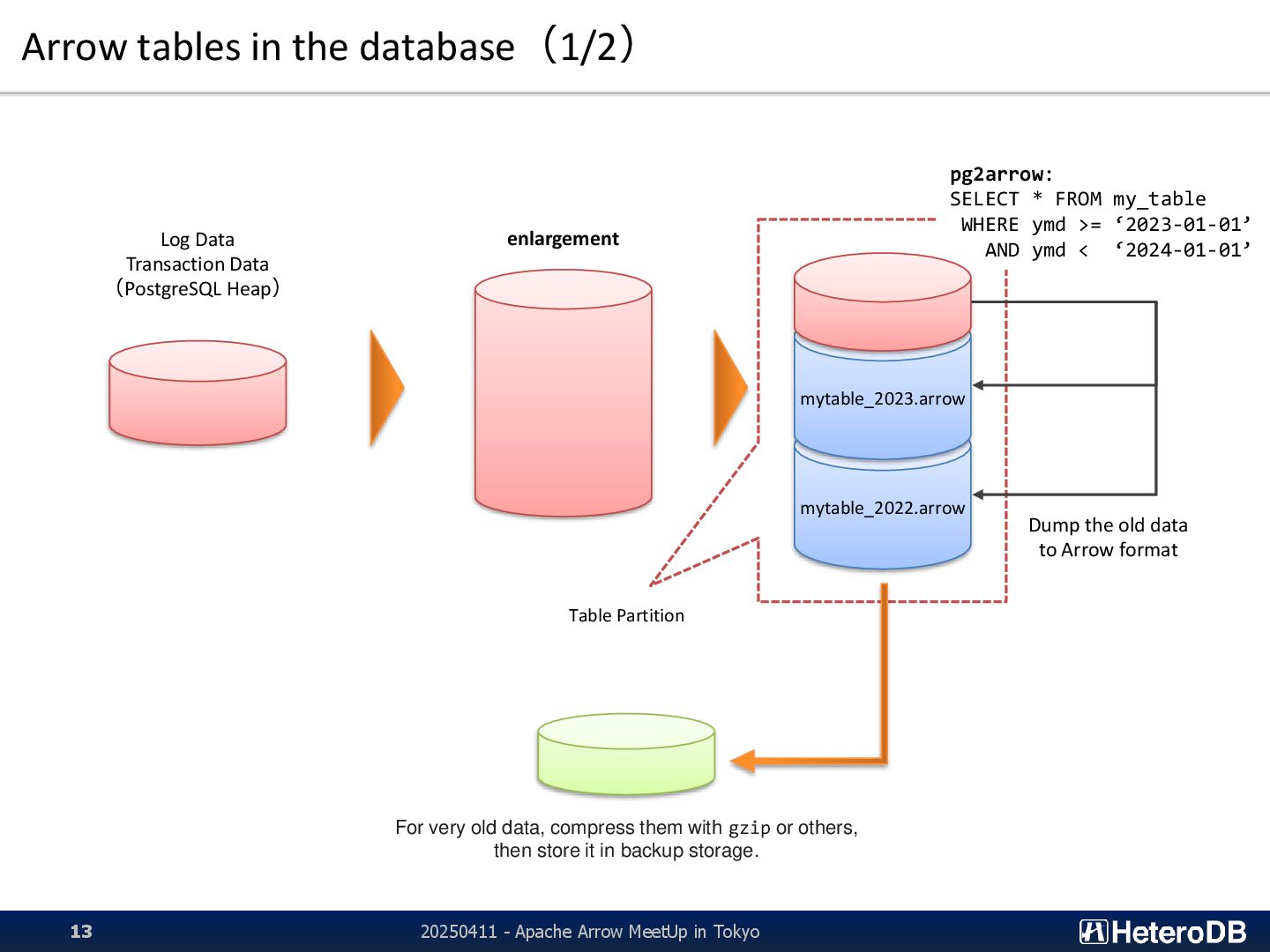{kind=link}
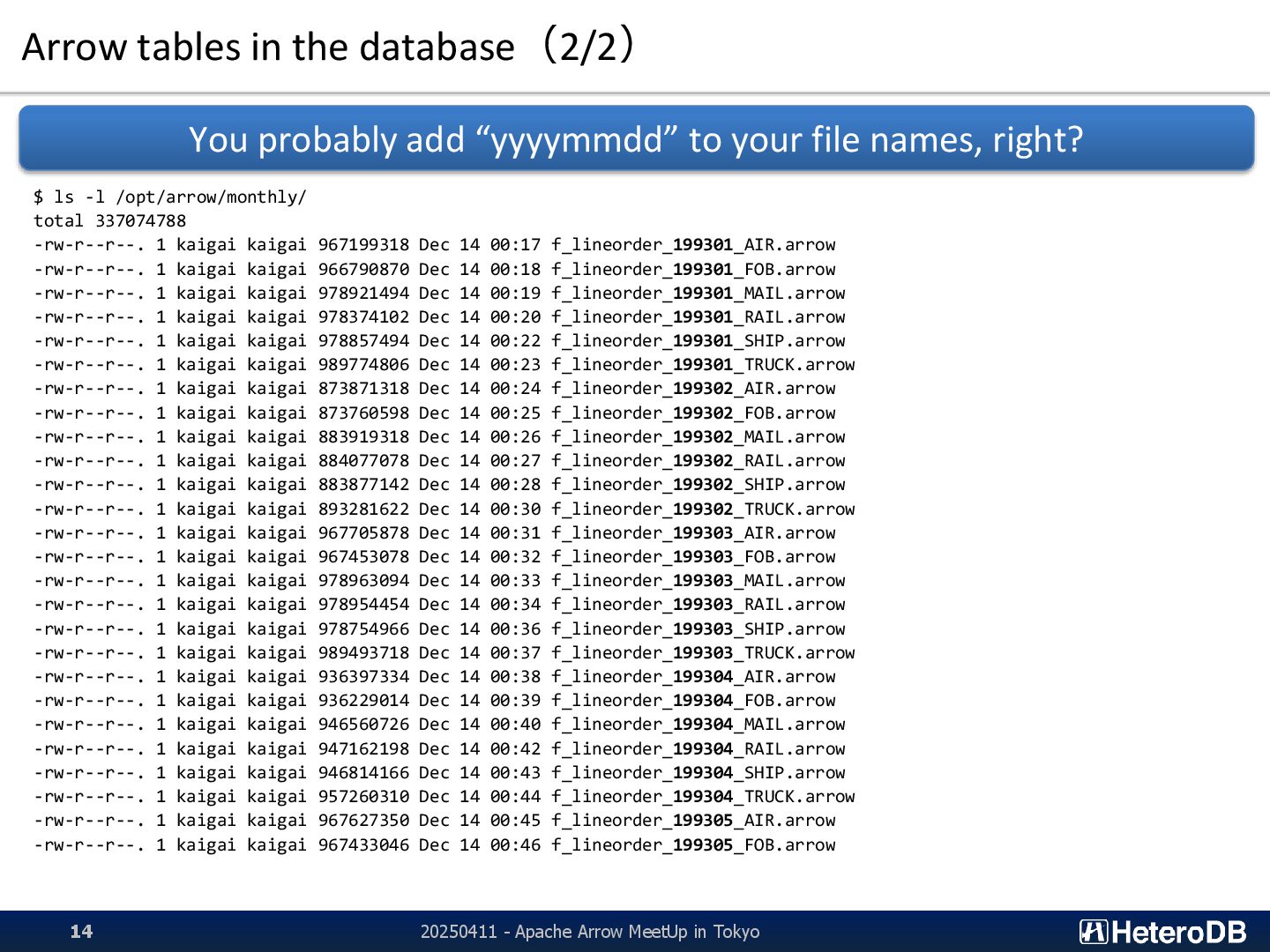{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}