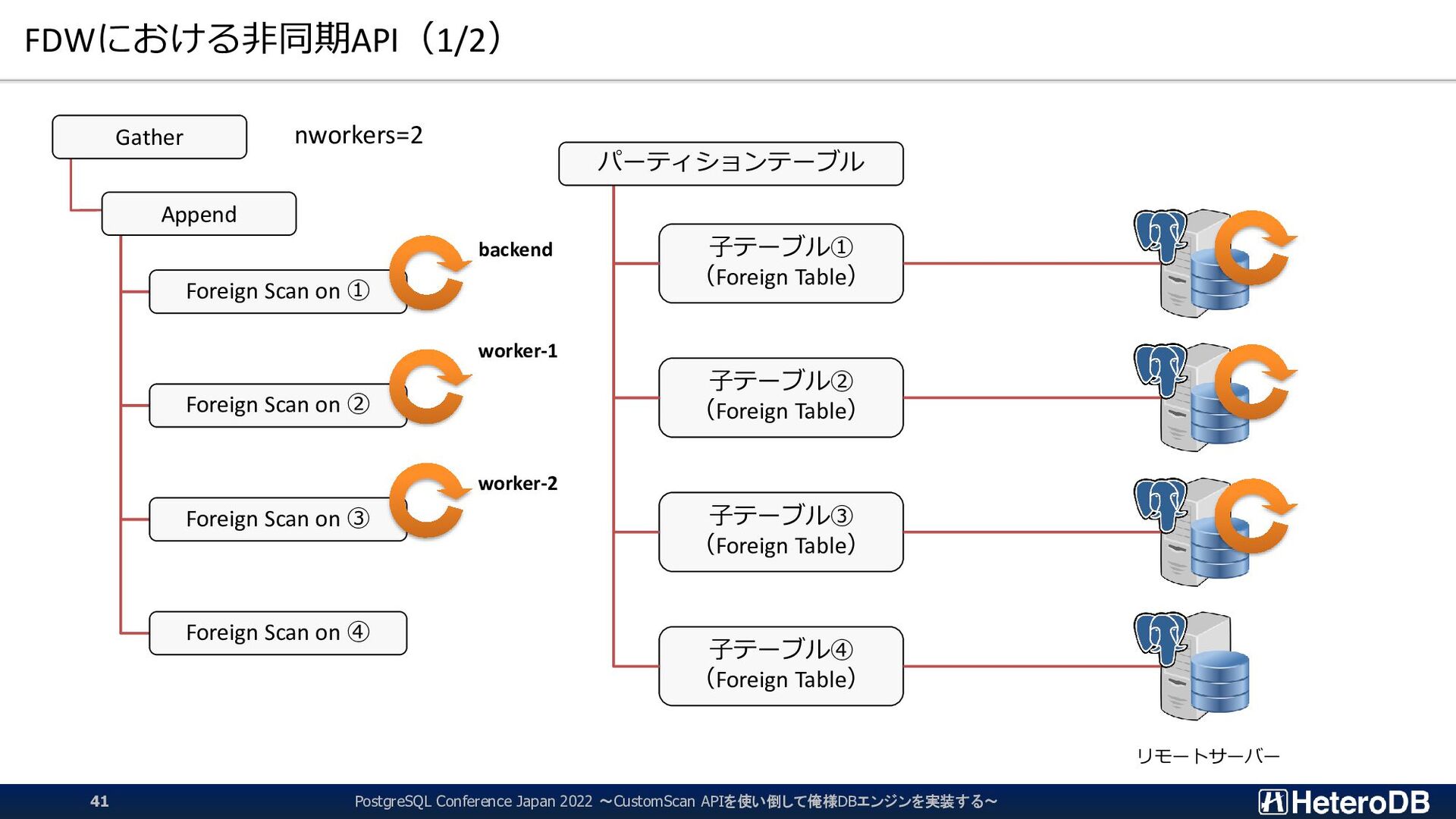
Table) 子テーブル② (Foreign Table) 子テーブル③ (Foreign Table) 子テーブル④ (Foreign Table) リモートサーバー Gather Append Foreign Scan on ① Foreign Scan on ② Foreign Scan on ③ Foreign Scan on ④ パーティションテーブル nworkers=2 backend worker-1 worker-2
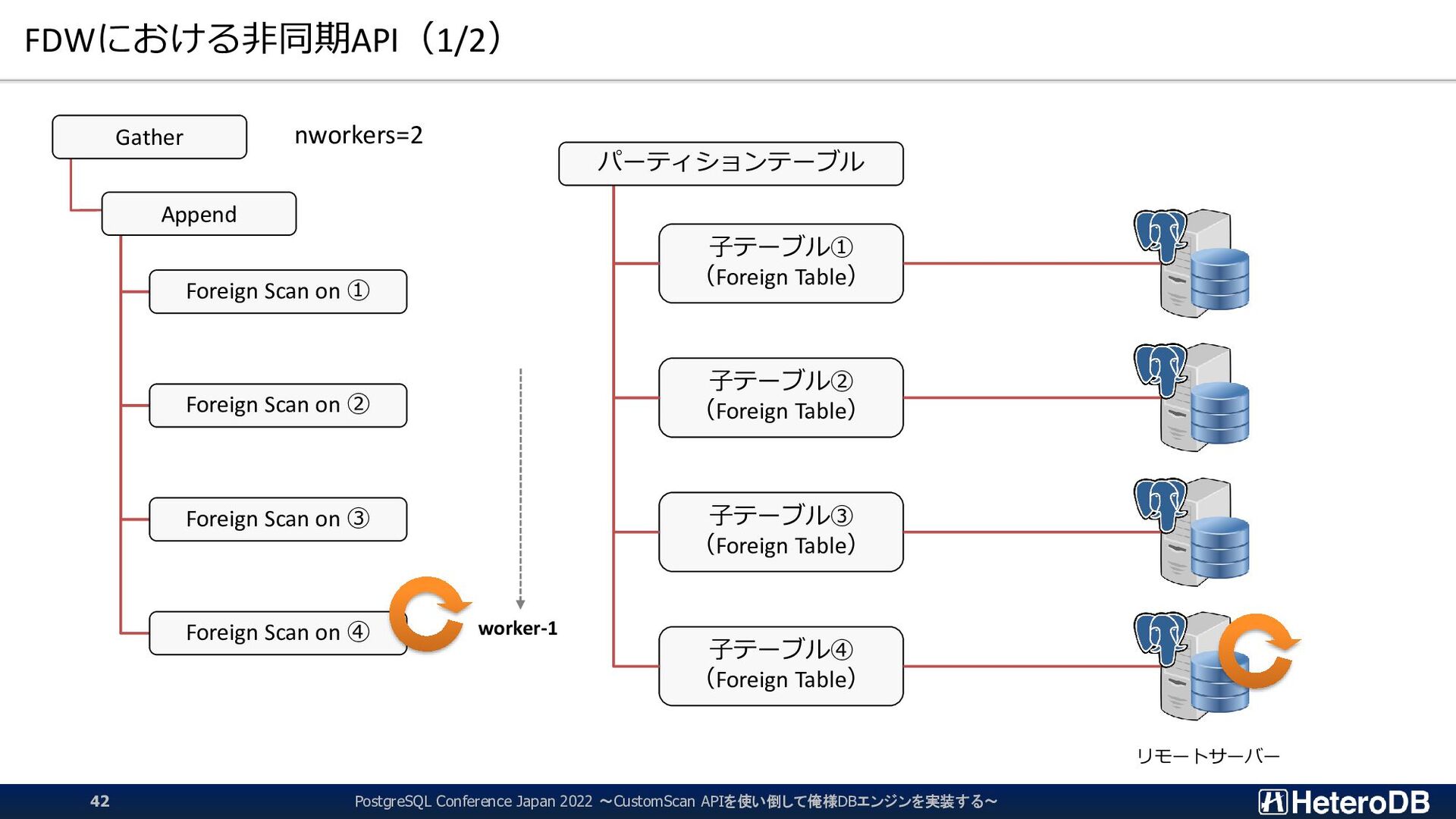
Table) 子テーブル② (Foreign Table) 子テーブル③ (Foreign Table) 子テーブル④ (Foreign Table) リモートサーバー Gather Append Foreign Scan on ① Foreign Scan on ② Foreign Scan on ③ Foreign Scan on ④ パーティションテーブル nworkers=2 worker-1
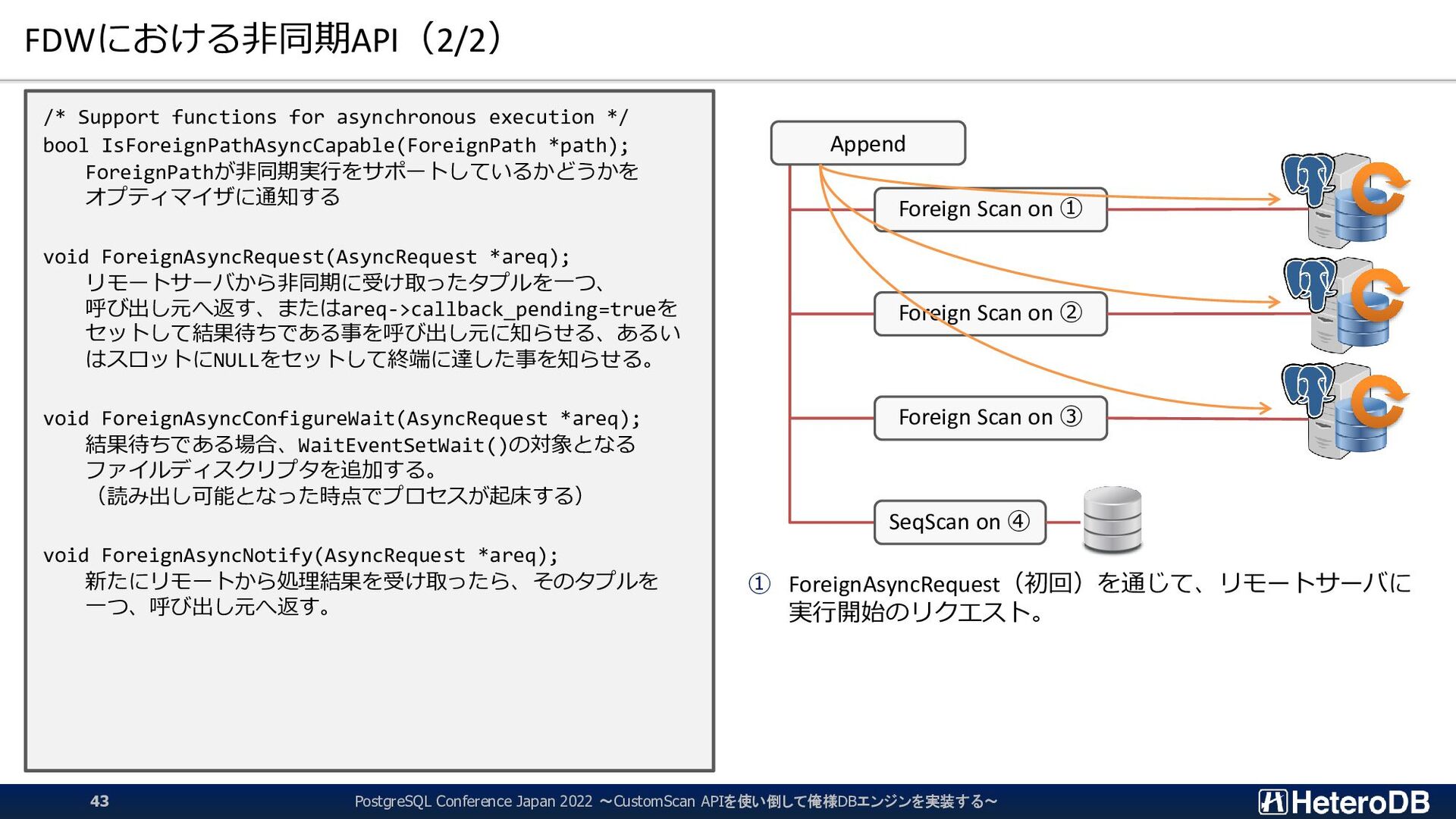
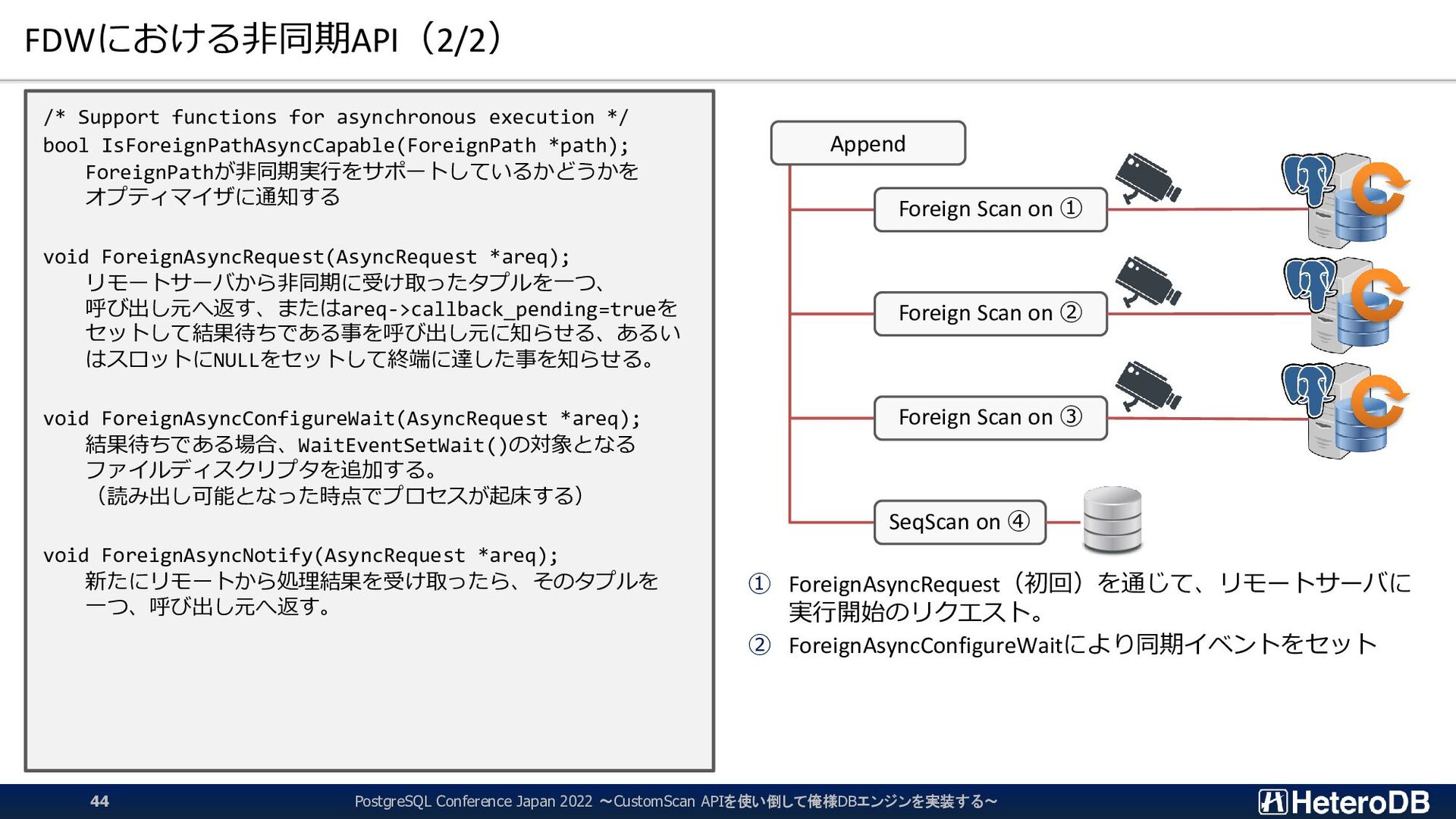
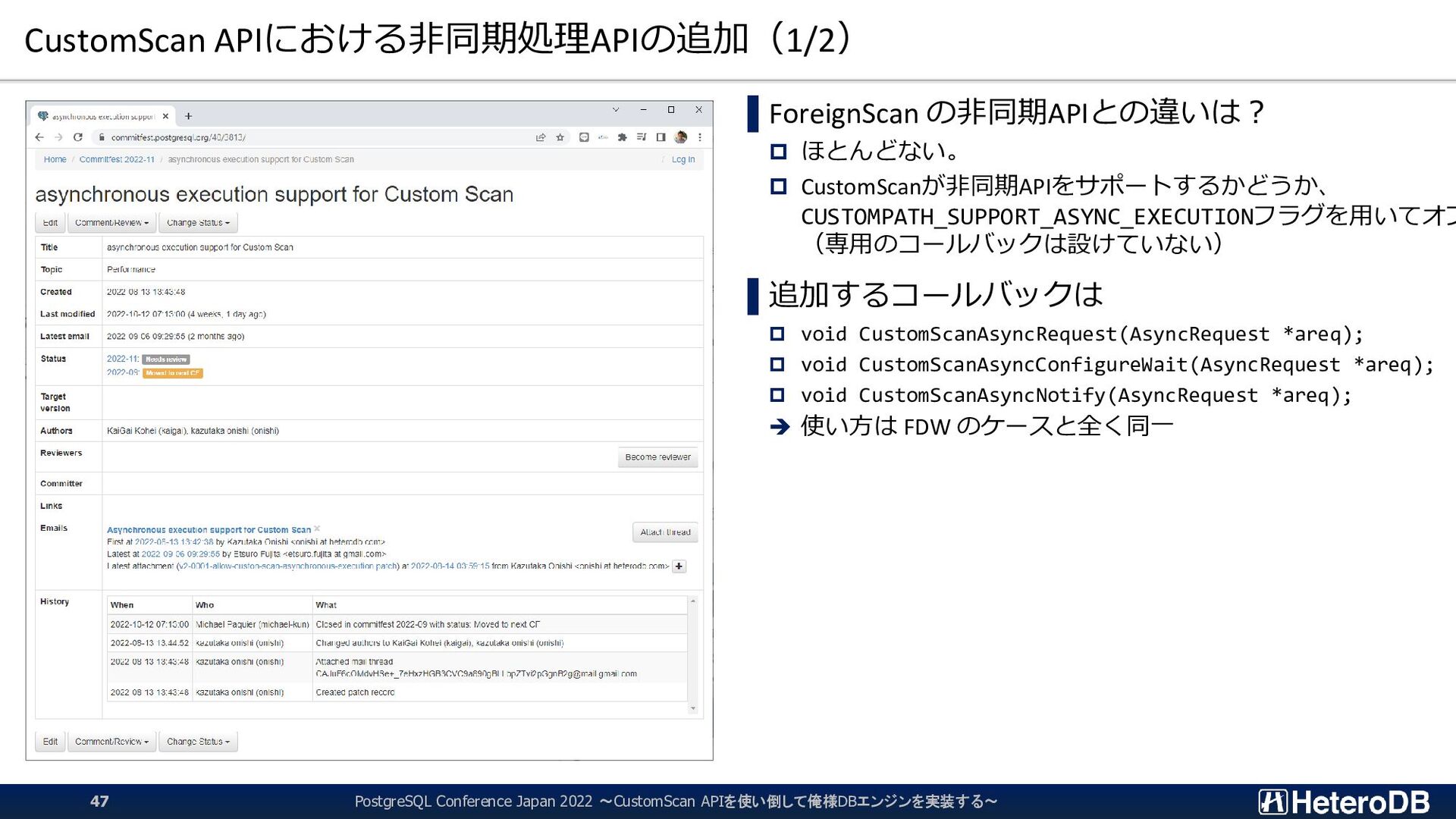
functions for asynchronous execution */ bool IsForeignPathAsyncCapable(ForeignPath *path); ForeignPathが非同期実行をサポートしているかどうかを オプティマイザに通知する void ForeignAsyncRequest(AsyncRequest *areq); リモートサーバから非同期に受け取ったタプルを一つ、 呼び出し元へ返す、またはareq->callback_pending=trueを セットして結果待ちである事を呼び出し元に知らせる、あるい はスロットにNULLをセットして終端に達した事を知らせる。 void ForeignAsyncConfigureWait(AsyncRequest *areq); 結果待ちである場合、WaitEventSetWait()の対象となる ファイルディスクリプタを追加する。 (読み出し可能となった時点でプロセスが起床する) void ForeignAsyncNotify(AsyncRequest *areq); 新たにリモートから処理結果を受け取ったら、そのタプルを 一つ、呼び出し元へ返す。 ① ForeignAsyncRequest(初回)を通じて、リモートサーバに 実行開始のリクエスト。 ② ForeignAsyncConfigureWaitにより同期イベントをセット Append Foreign Scan on ① Foreign Scan on ② Foreign Scan on ③ SeqScan on ④
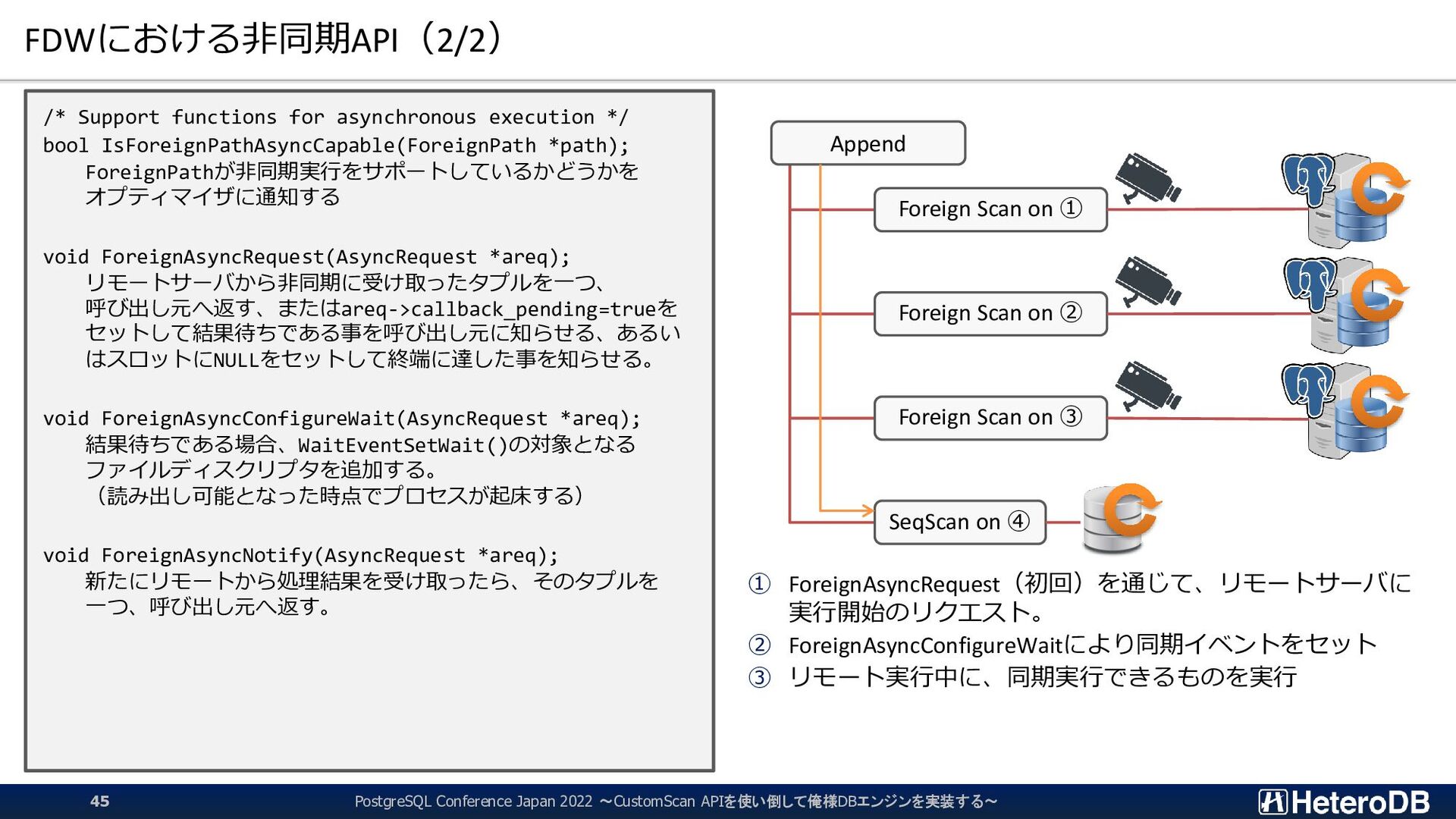
functions for asynchronous execution */ bool IsForeignPathAsyncCapable(ForeignPath *path); ForeignPathが非同期実行をサポートしているかどうかを オプティマイザに通知する void ForeignAsyncRequest(AsyncRequest *areq); リモートサーバから非同期に受け取ったタプルを一つ、 呼び出し元へ返す、またはareq->callback_pending=trueを セットして結果待ちである事を呼び出し元に知らせる、あるい はスロットにNULLをセットして終端に達した事を知らせる。 void ForeignAsyncConfigureWait(AsyncRequest *areq); 結果待ちである場合、WaitEventSetWait()の対象となる ファイルディスクリプタを追加する。 (読み出し可能となった時点でプロセスが起床する) void ForeignAsyncNotify(AsyncRequest *areq); 新たにリモートから処理結果を受け取ったら、そのタプルを 一つ、呼び出し元へ返す。 ① ForeignAsyncRequest(初回)を通じて、リモートサーバに 実行開始のリクエスト。 ② ForeignAsyncConfigureWaitにより同期イベントをセット ③ リモート実行中に、同期実行できるものを実行 Append Foreign Scan on ① Foreign Scan on ② Foreign Scan on ③ SeqScan on ④
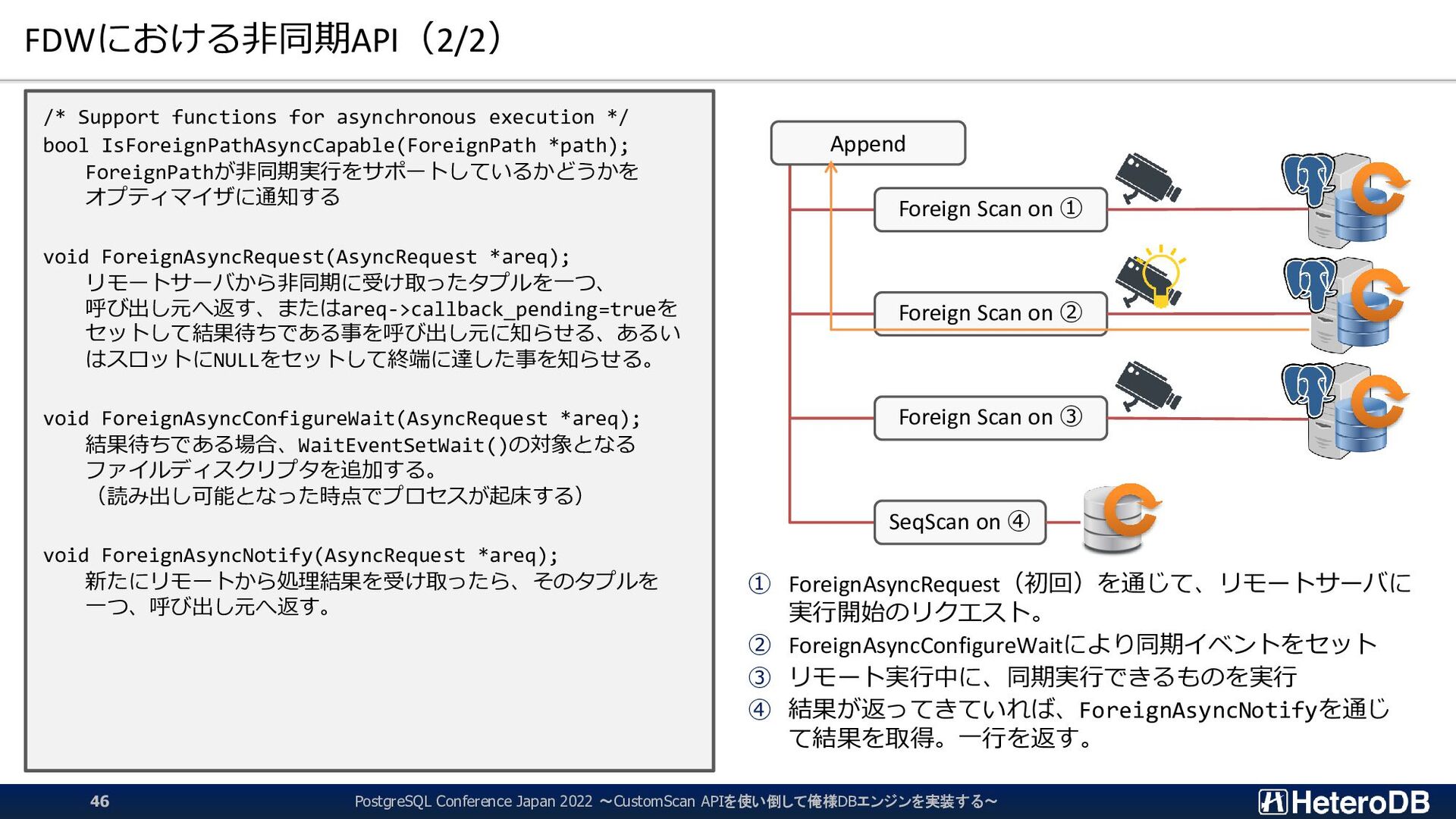
functions for asynchronous execution */ bool IsForeignPathAsyncCapable(ForeignPath *path); ForeignPathが非同期実行をサポートしているかどうかを オプティマイザに通知する void ForeignAsyncRequest(AsyncRequest *areq); リモートサーバから非同期に受け取ったタプルを一つ、 呼び出し元へ返す、またはareq->callback_pending=trueを セットして結果待ちである事を呼び出し元に知らせる、あるい はスロットにNULLをセットして終端に達した事を知らせる。 void ForeignAsyncConfigureWait(AsyncRequest *areq); 結果待ちである場合、WaitEventSetWait()の対象となる ファイルディスクリプタを追加する。 (読み出し可能となった時点でプロセスが起床する) void ForeignAsyncNotify(AsyncRequest *areq); 新たにリモートから処理結果を受け取ったら、そのタプルを 一つ、呼び出し元へ返す。 ① ForeignAsyncRequest(初回)を通じて、リモートサーバに 実行開始のリクエスト。 ② ForeignAsyncConfigureWaitにより同期イベントをセット ③ リモート実行中に、同期実行できるものを実行 ④ 結果が返ってきていれば、ForeignAsyncNotifyを通じ て結果を取得。一行を返す。 Append Foreign Scan on ① Foreign Scan on ② Foreign Scan on ③ SeqScan on ④
![CustomScan APIを使い倒して俺様DBエンジンを実装する ヘテロDB株式会社 チーフアーキテクト 兼 CEO 海外 浩平 <[email protected]>](https://files.speakerdeck.com/presentations/c2a03c398b8440ca947e965022e46abd/slide_0.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}