例:𝑣𝑖 = 𝑥𝑖 − 𝑦𝑖 𝑖 = 0 … 7 を計算するケース(模式図) INT Load FP32 INT Store INT Load FP32 INT Store INT Load FP32 INT Store INT Load FP32 INT Store INT Load FP32 INT Store INT Load FP32 INT Store INT Load FP32 INT Store core0 INT Load FP32 INT Store INT Load FP32 INT Store core1 INT Load FP32 INT Store INT Load FP32 INT Store core2 INT Load FP32 INT Store INT Load FP32 INT Store core3 INT Load FP32 INT Store INT Load FP32 INT Store 8要素の処理を4コア/4スレッドで実行 8要素の処理を4コア/8スレッドで実行 Warp Schedulerが、 開いたリソースに 実行待ちのスレッドを 投入する。 ➔ 余剰リソースが減り、 実行時間を短くできる。 ソフトウェアサイエンス特別講義A~OSS基盤の上に実装するGPUデータベース~ 44
![ソフトウェアサイエンス特別講義A OSS基盤の上に実装するGPUデータベース ヘテロDB株式会社 チーフアーキテクト 兼 CEO 海外 浩平 <[email protected]>](https://files.speakerdeck.com/presentations/7ecd84abe6284bd1b8343b71e0aae66e/slide_0.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![[補足] RCU (Read Copy Update) について ソフトウェアサイエンス特別講義A~OSS基盤の上に実装するGPUデータベース~ 6 リストを更新する際にロックを使う場合 RCUによるリスト更新](https://files.speakerdeck.com/presentations/7ecd84abe6284bd1b8343b71e0aae66e/slide_5.jpg){kind=link}
![[補足] RCU (Read Copy Update) について ソフトウェアサイエンス特別講義A~OSS基盤の上に実装するGPUデータベース~ 7 リストを更新する際にロックを使う場合 RCUによるリスト更新](https://files.speakerdeck.com/presentations/7ecd84abe6284bd1b8343b71e0aae66e/slide_6.jpg){kind=link}
![[補足] RCU (Read Copy Update) について ソフトウェアサイエンス特別講義A~OSS基盤の上に実装するGPUデータベース~ 8 リストを更新する際にロックを使う場合 RCUによるリスト更新](https://files.speakerdeck.com/presentations/7ecd84abe6284bd1b8343b71e0aae66e/slide_7.jpg){kind=link}
![[補足] RCU (Read Copy Update) について ソフトウェアサイエンス特別講義A~OSS基盤の上に実装するGPUデータベース~ 9 リストを更新する際にロックを使う場合 RCUによるリスト更新](https://files.speakerdeck.com/presentations/7ecd84abe6284bd1b8343b71e0aae66e/slide_8.jpg){kind=link}
![[補足] RCU (Read Copy Update) について ソフトウェアサイエンス特別講義A~OSS基盤の上に実装するGPUデータベース~ 10 リストを更新する際にロックを使う場合 RCUによるリスト更新](https://files.speakerdeck.com/presentations/7ecd84abe6284bd1b8343b71e0aae66e/slide_9.jpg){kind=link}
![[補足] RCU (Read Copy Update) について ソフトウェアサイエンス特別講義A~OSS基盤の上に実装するGPUデータベース~ 11 リストを更新する際にロックを使う場合 RCUによるリスト更新](https://files.speakerdeck.com/presentations/7ecd84abe6284bd1b8343b71e0aae66e/slide_10.jpg){kind=link}
![[補足] RCU (Read Copy Update) について ソフトウェアサイエンス特別講義A~OSS基盤の上に実装するGPUデータベース~ 12 リストを更新する際にロックを使う場合 RCUによるリスト更新](https://files.speakerdeck.com/presentations/7ecd84abe6284bd1b8343b71e0aae66e/slide_11.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![[補足] Security Barrier ViewとLeakproof関数(1/2) ソフトウェアサイエンス特別講義A~OSS基盤の上に実装するGPUデータベース~ 18 postgres=# SELECT * FROM](https://files.speakerdeck.com/presentations/7ecd84abe6284bd1b8343b71e0aae66e/slide_17.jpg){kind=link}
![[補足] Security Barrier ViewとLeakproof関数(2/2) ソフトウェアサイエンス特別講義A~OSS基盤の上に実装するGPUデータベース~ 19 postgres=> EXPLAIN SELECT *](https://files.speakerdeck.com/presentations/7ecd84abe6284bd1b8343b71e0aae66e/slide_18.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
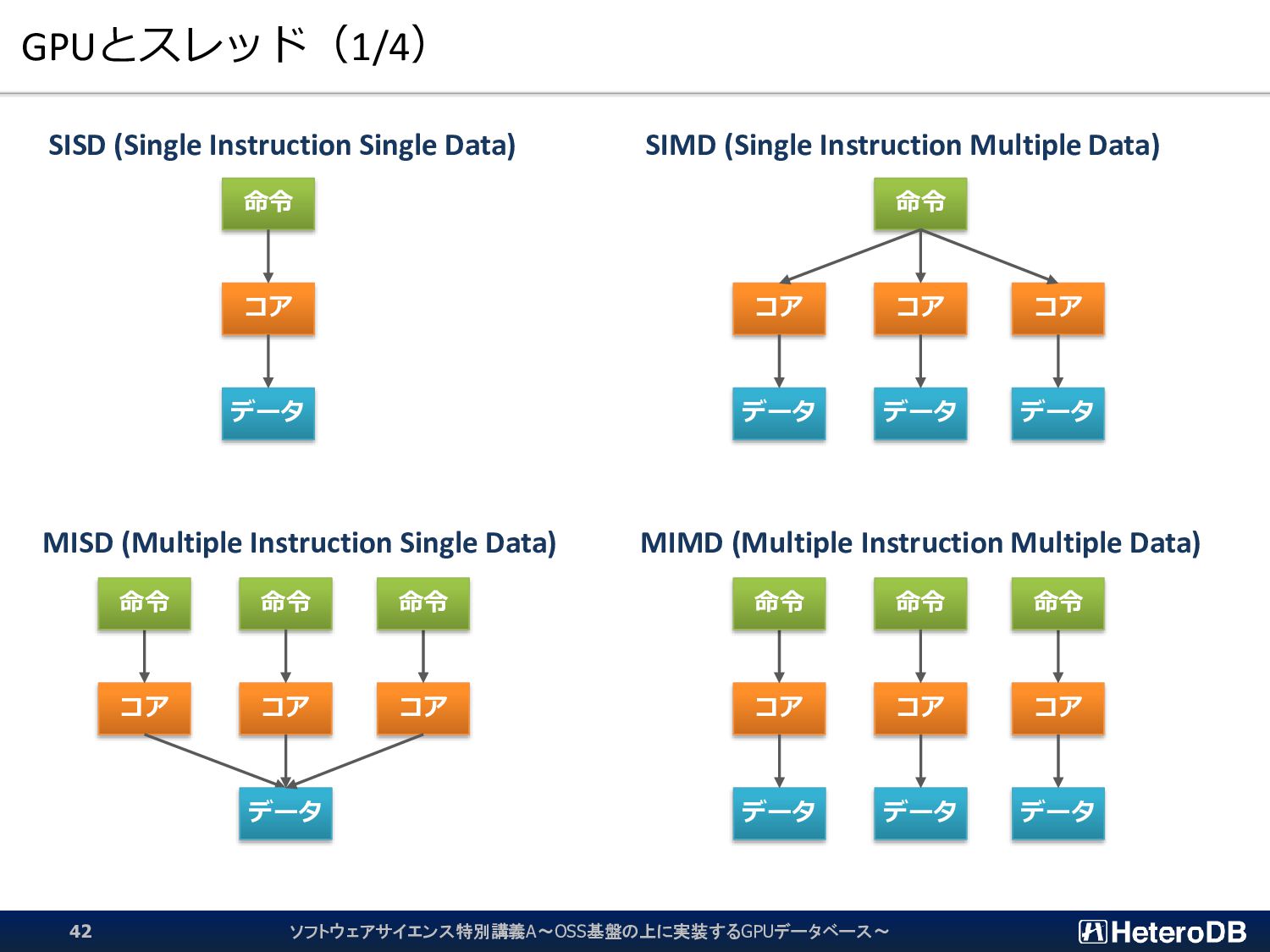{kind=link}
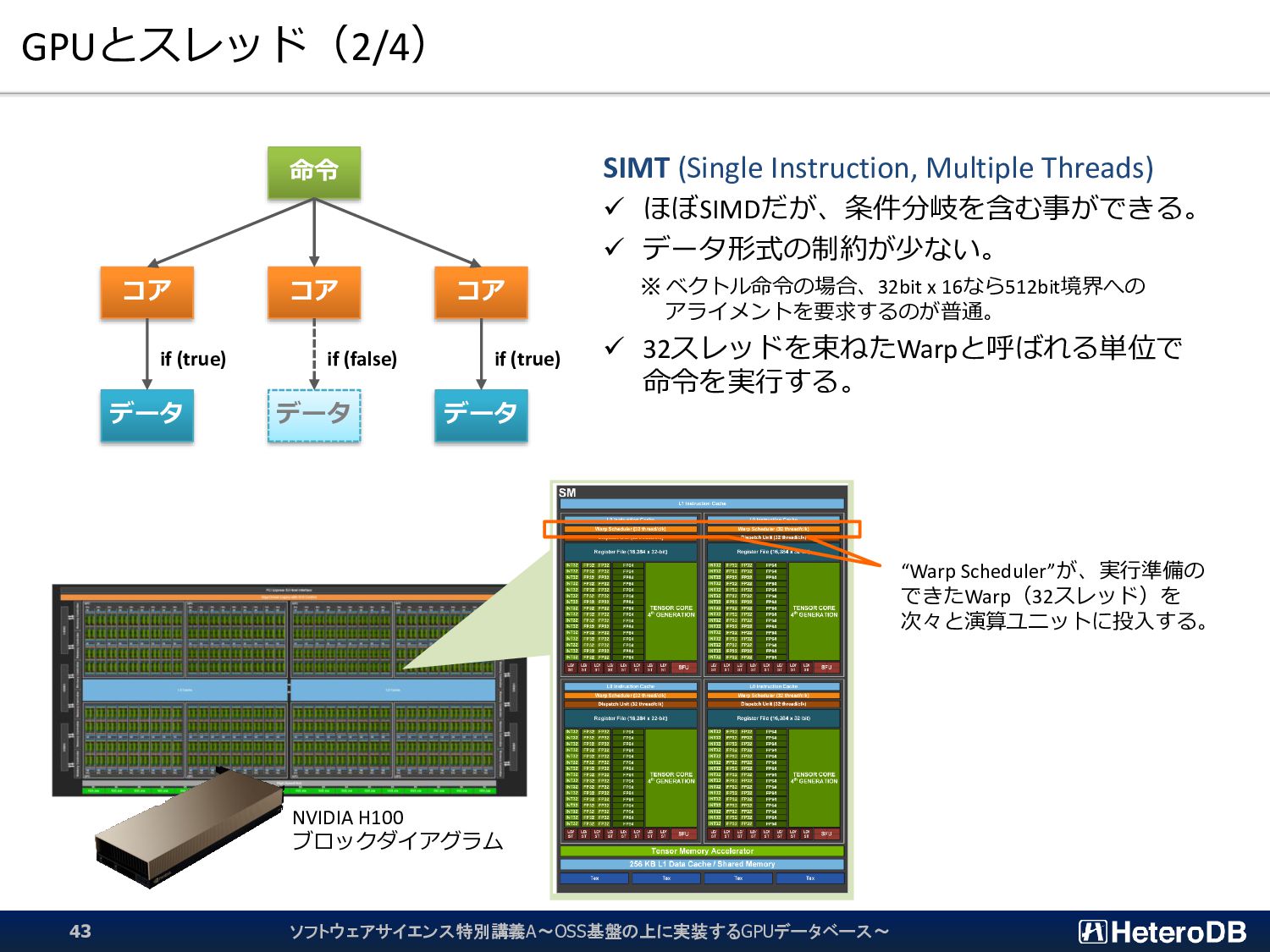{kind=link}
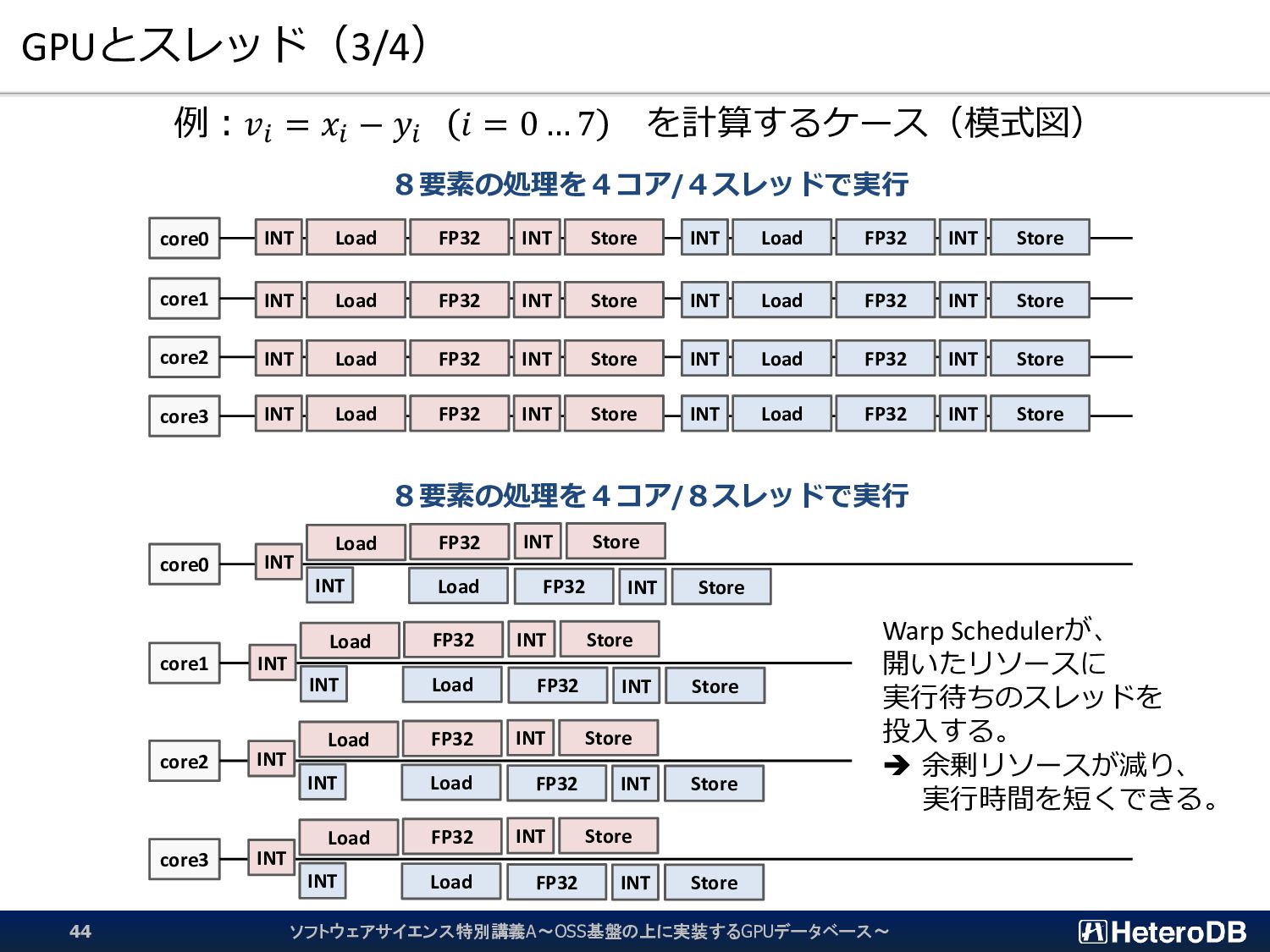{kind=link}
![GPUとスレッド(4/4) ソフトウェアサイエンス特別講義A~OSS基盤の上に実装するGPUデータベース~ 45 NVIDIA H100 [PCI-E] (114SMs) SMあたり INT32: 64](https://files.speakerdeck.com/presentations/7ecd84abe6284bd1b8343b71e0aae66e/slide_44.jpg){kind=link}
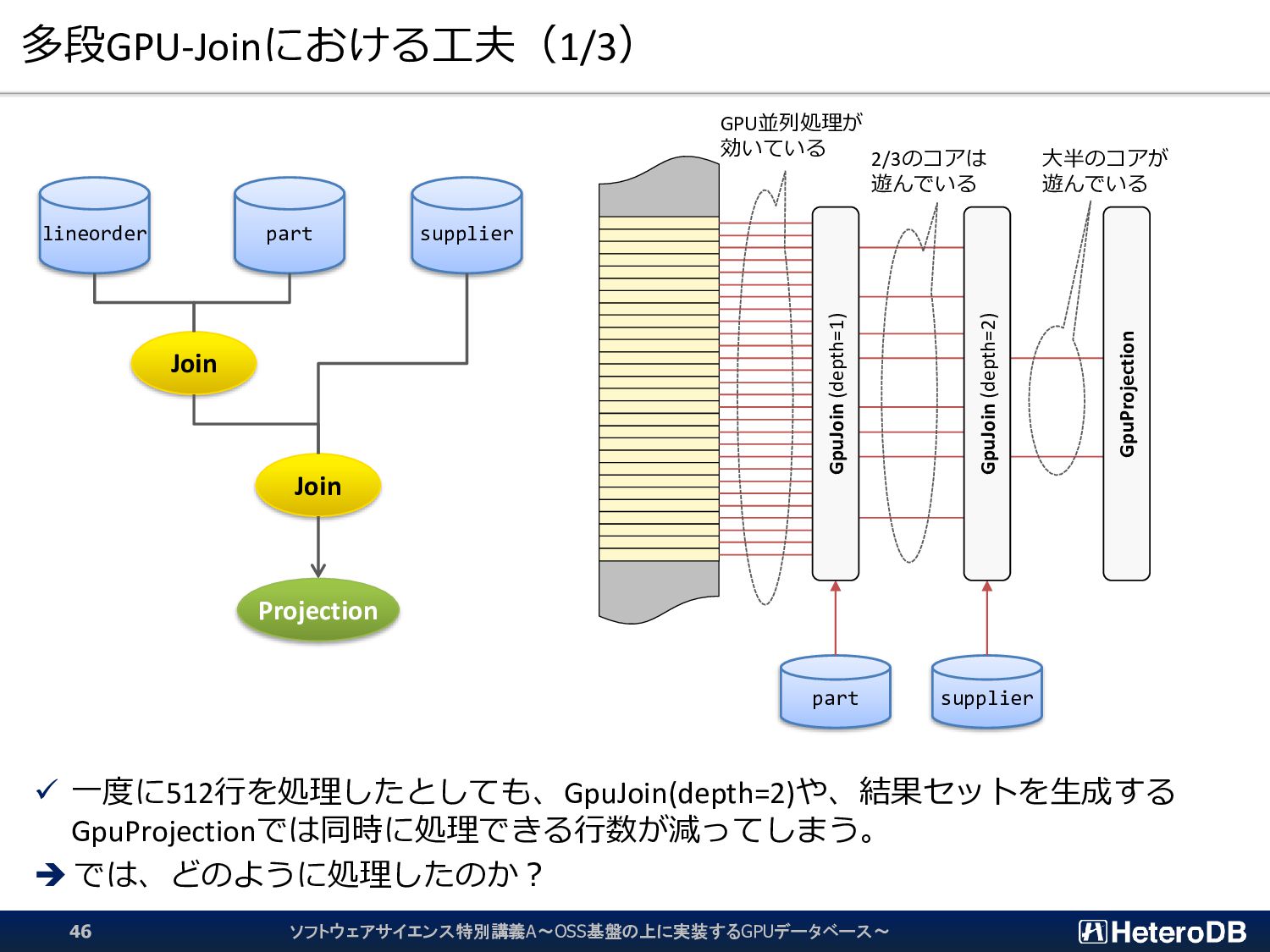{kind=link}
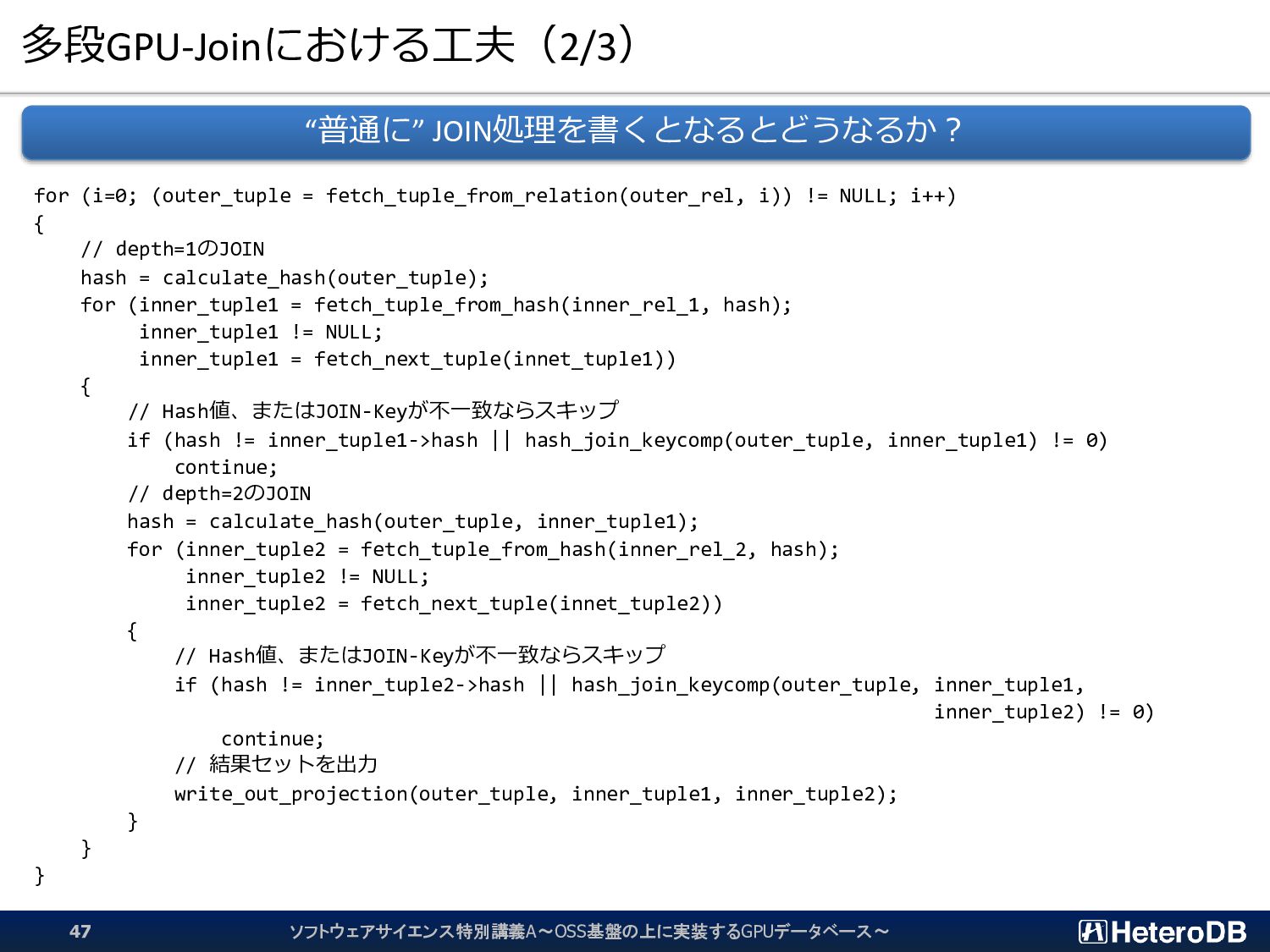{kind=link}
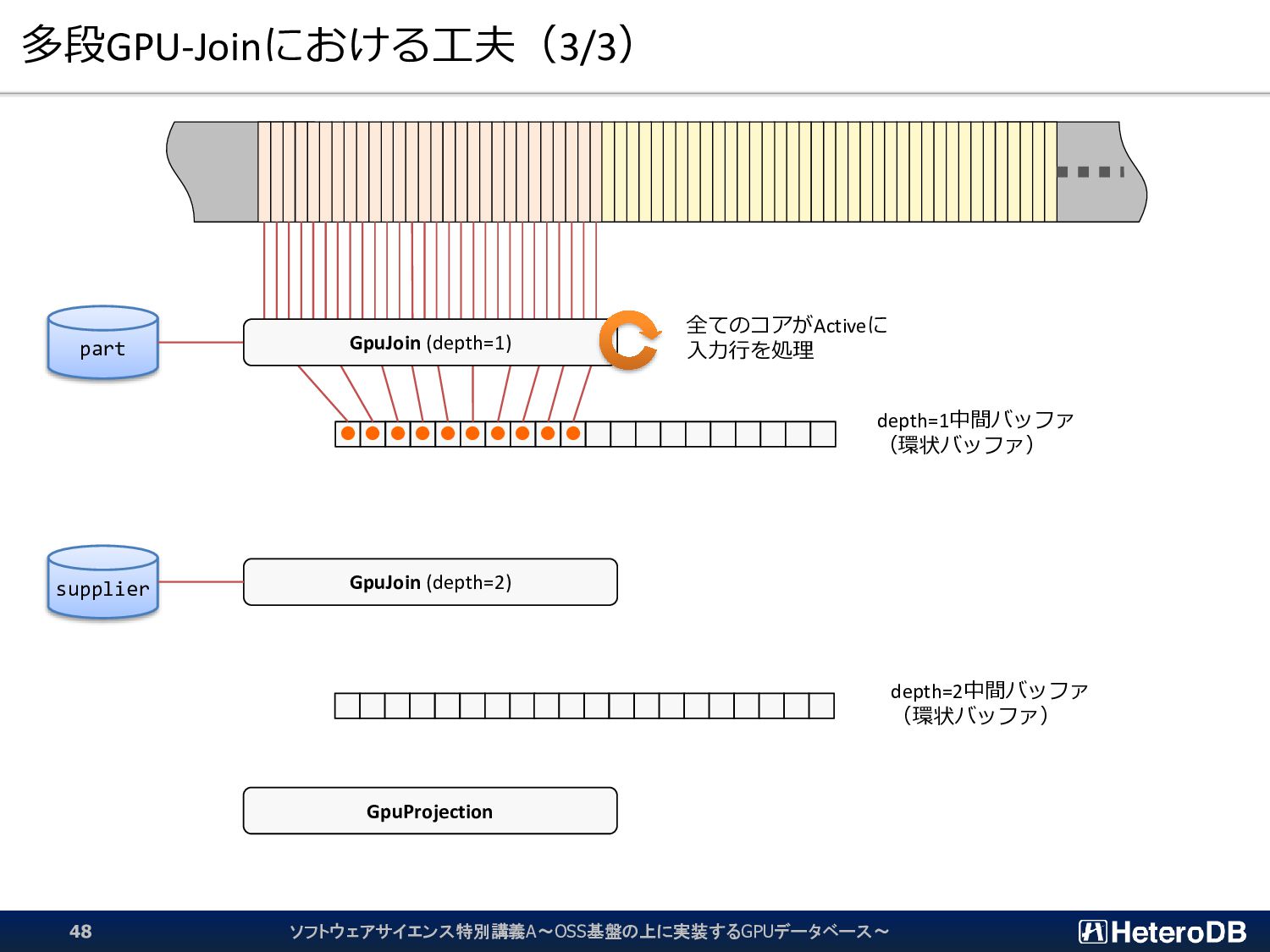{kind=link}
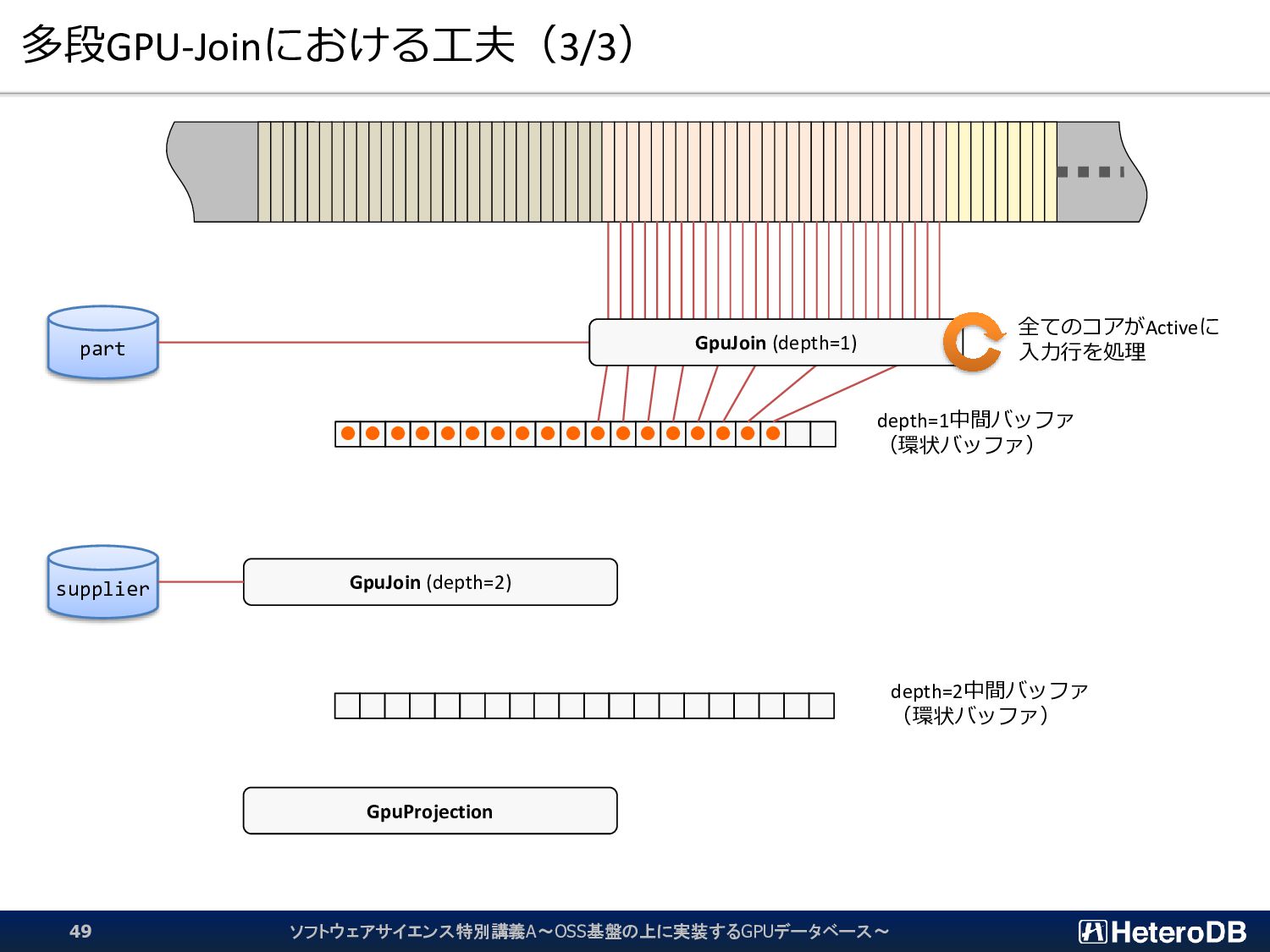{kind=link}
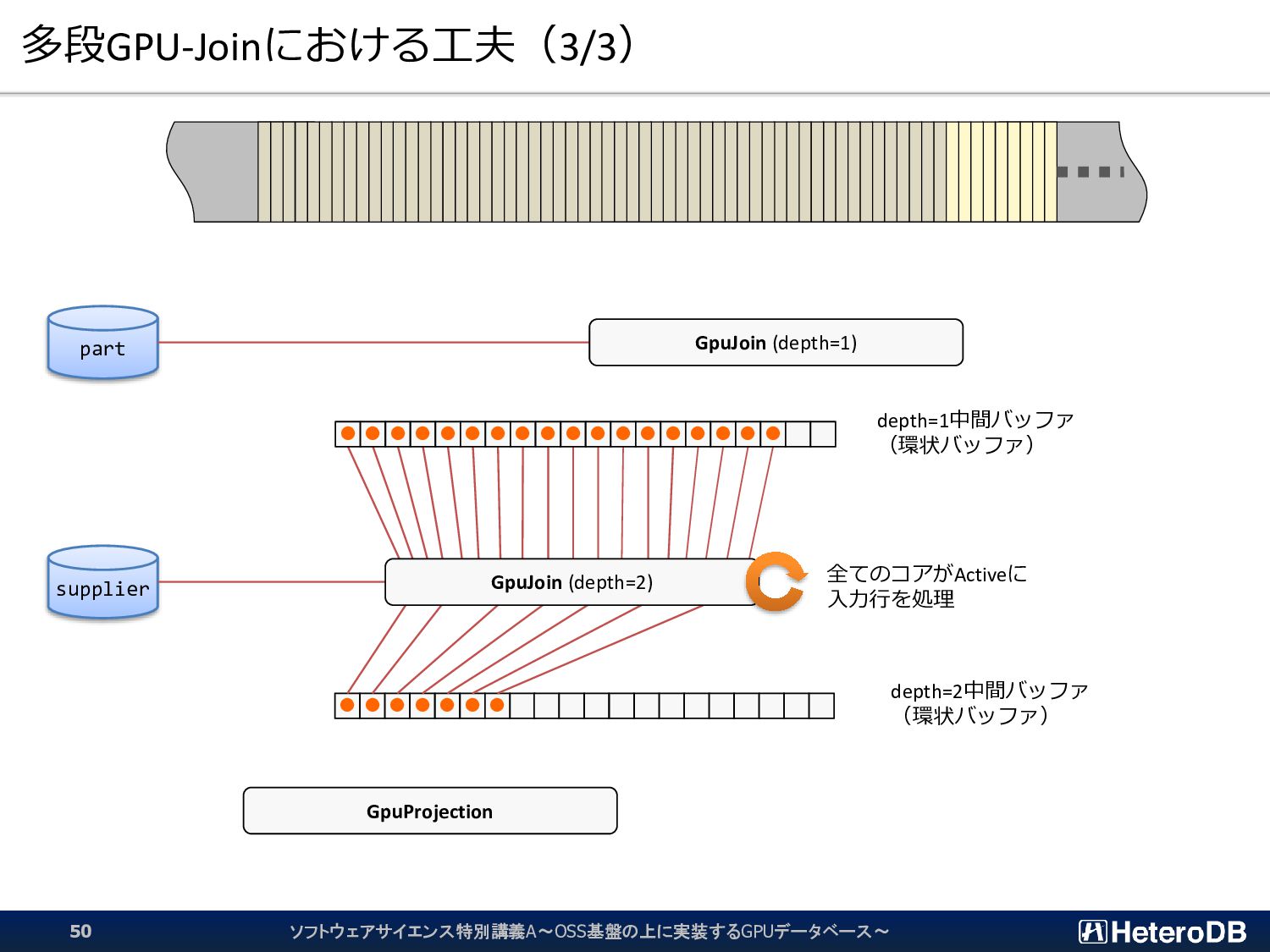{kind=link}
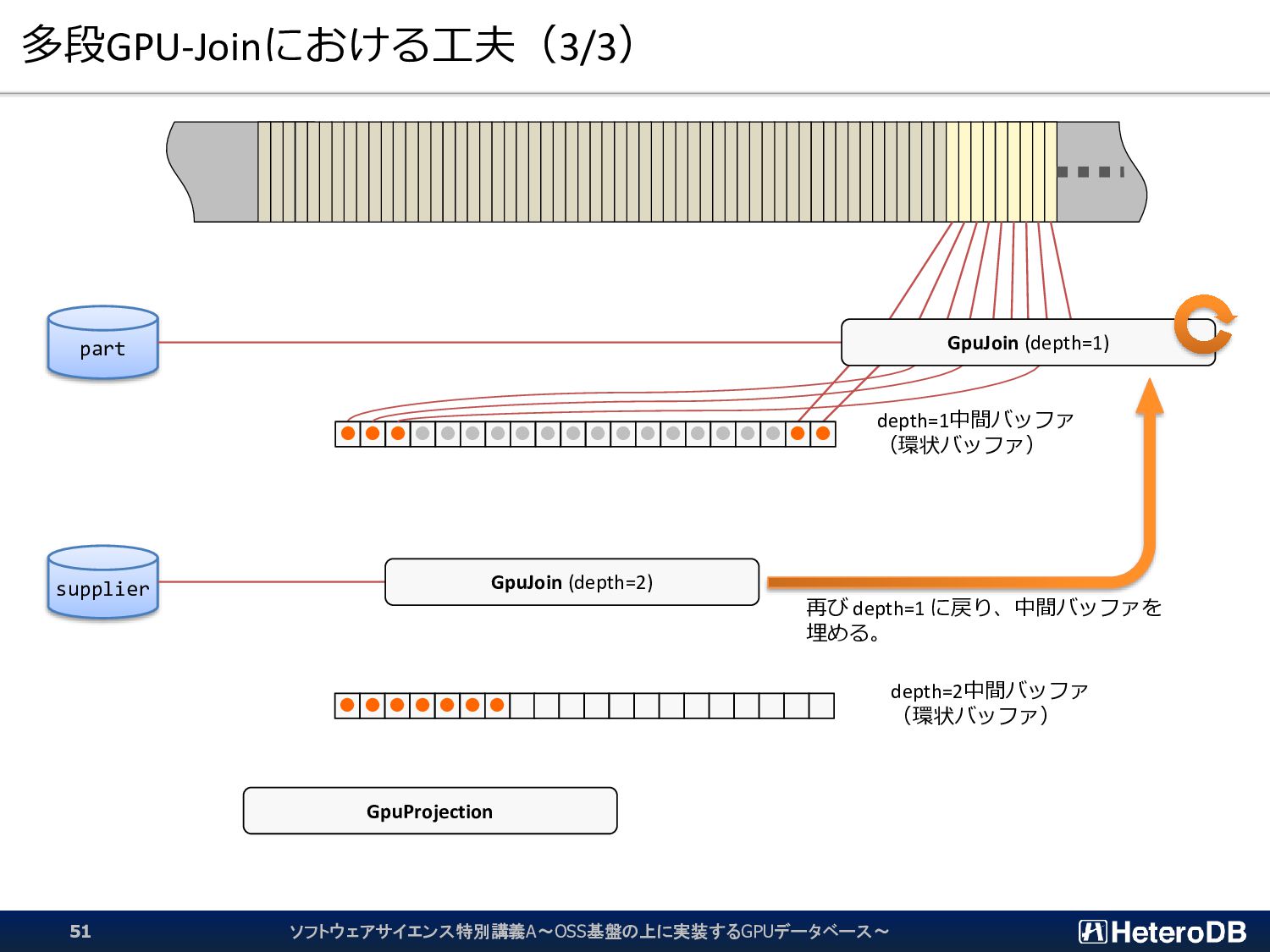{kind=link}
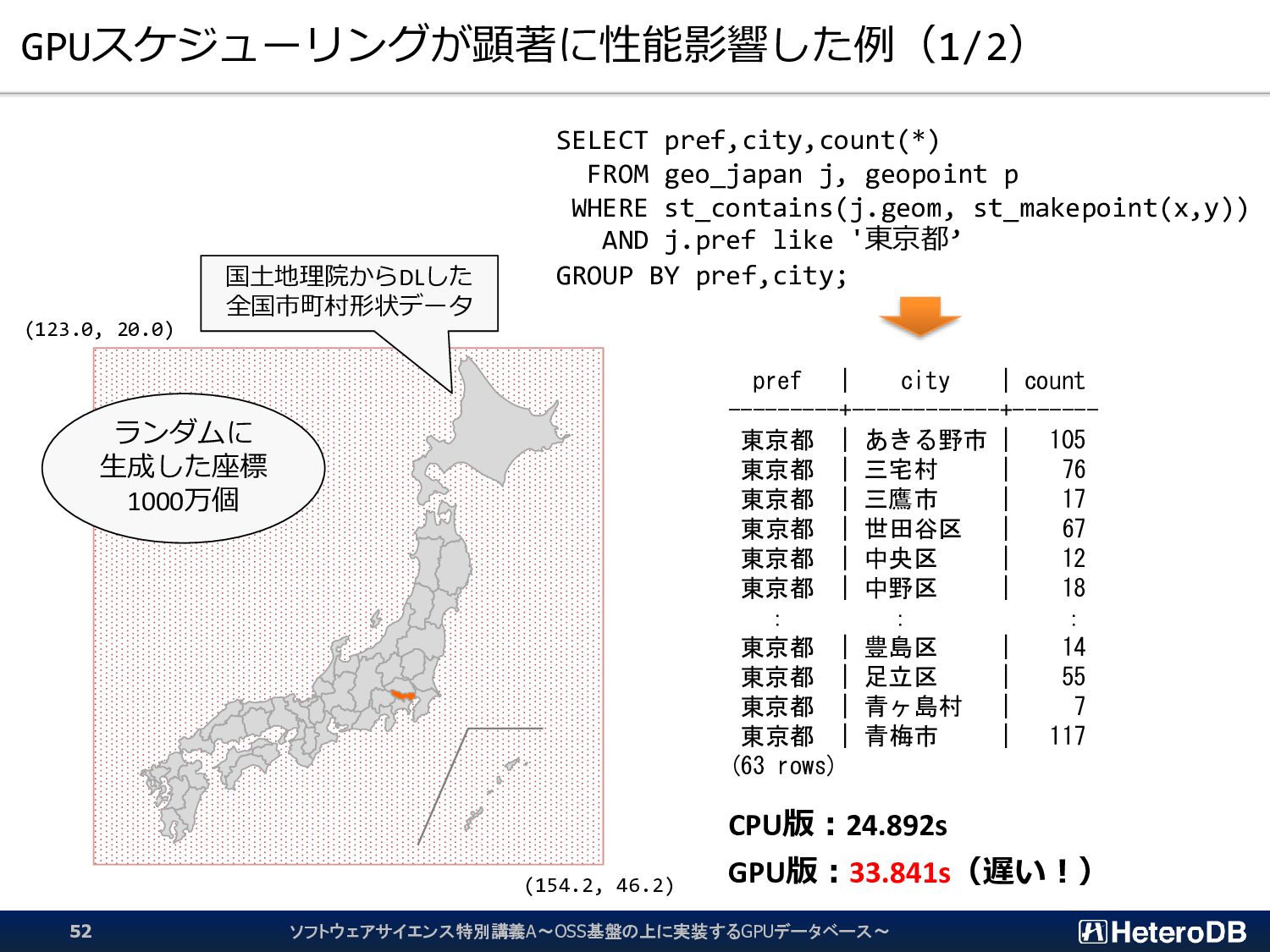{kind=link}
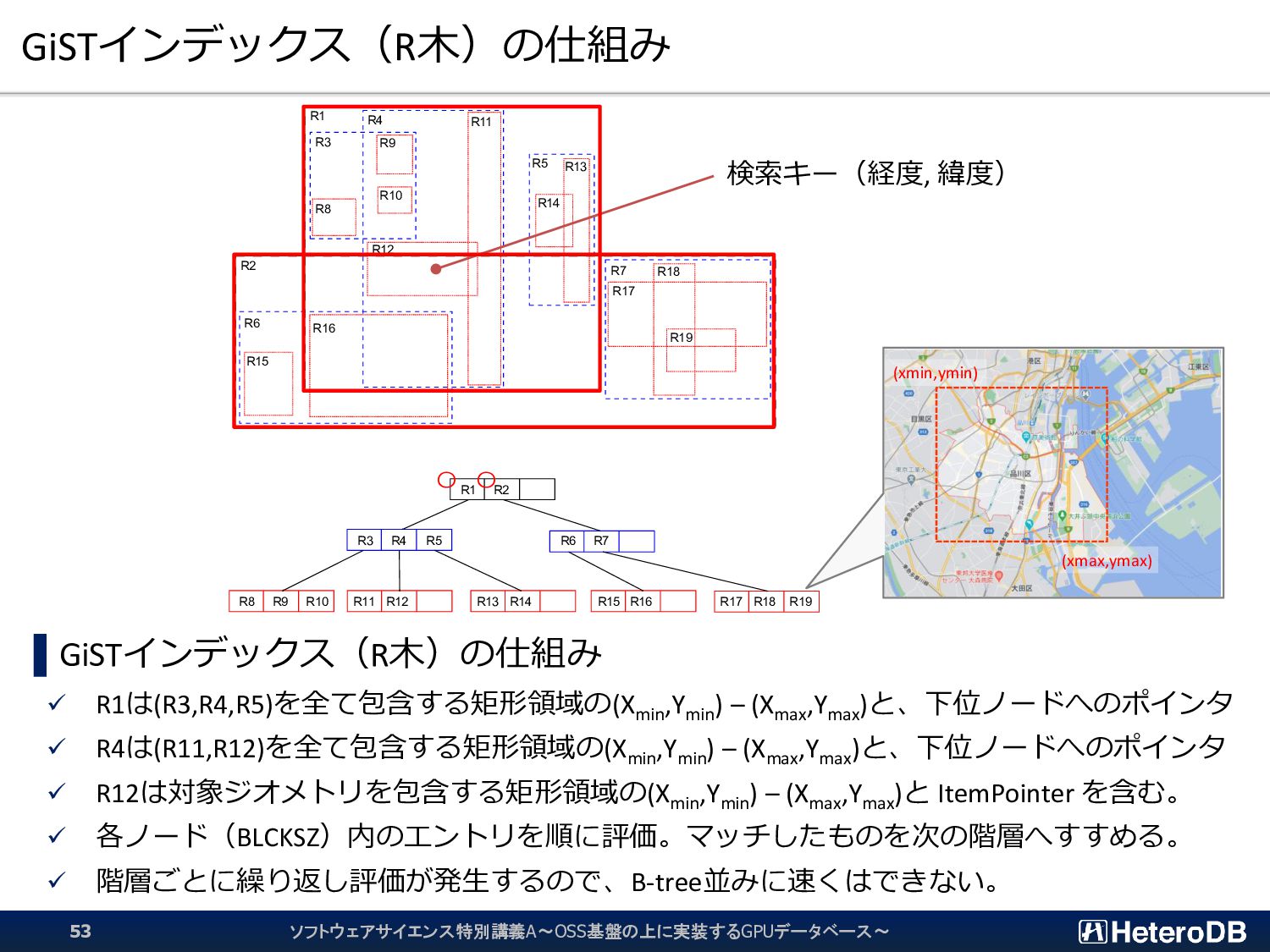{kind=link}
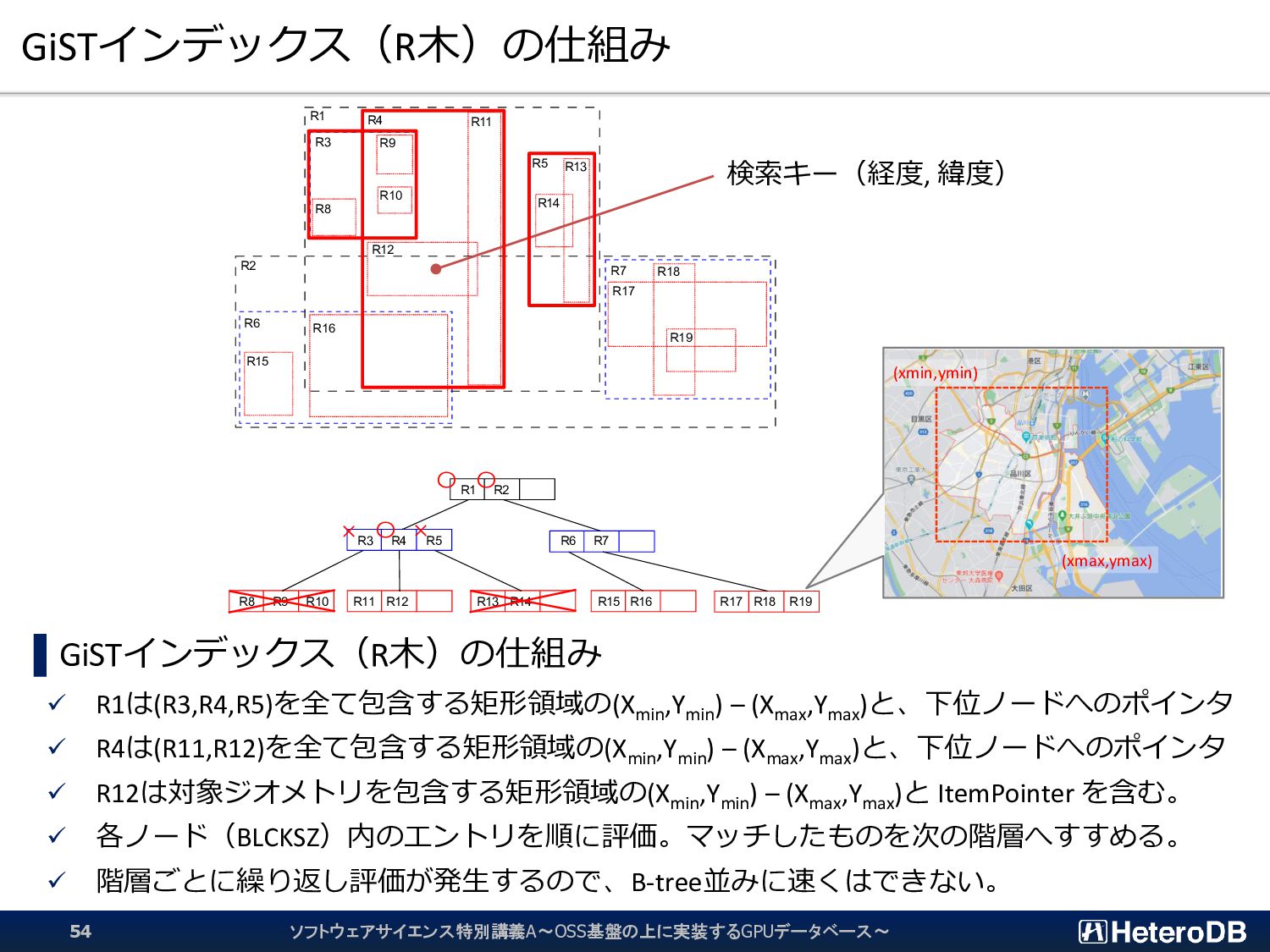{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
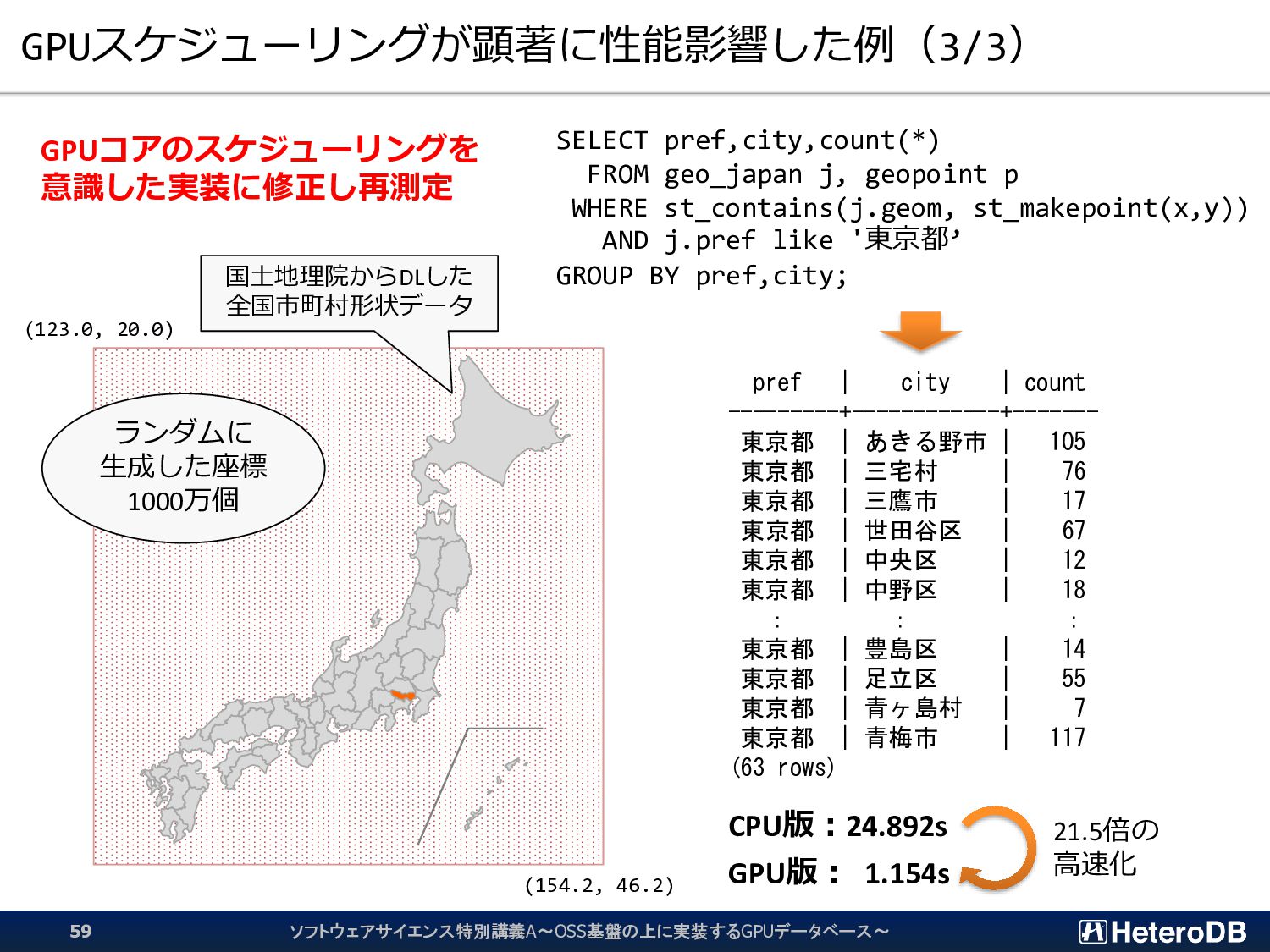{kind=link}
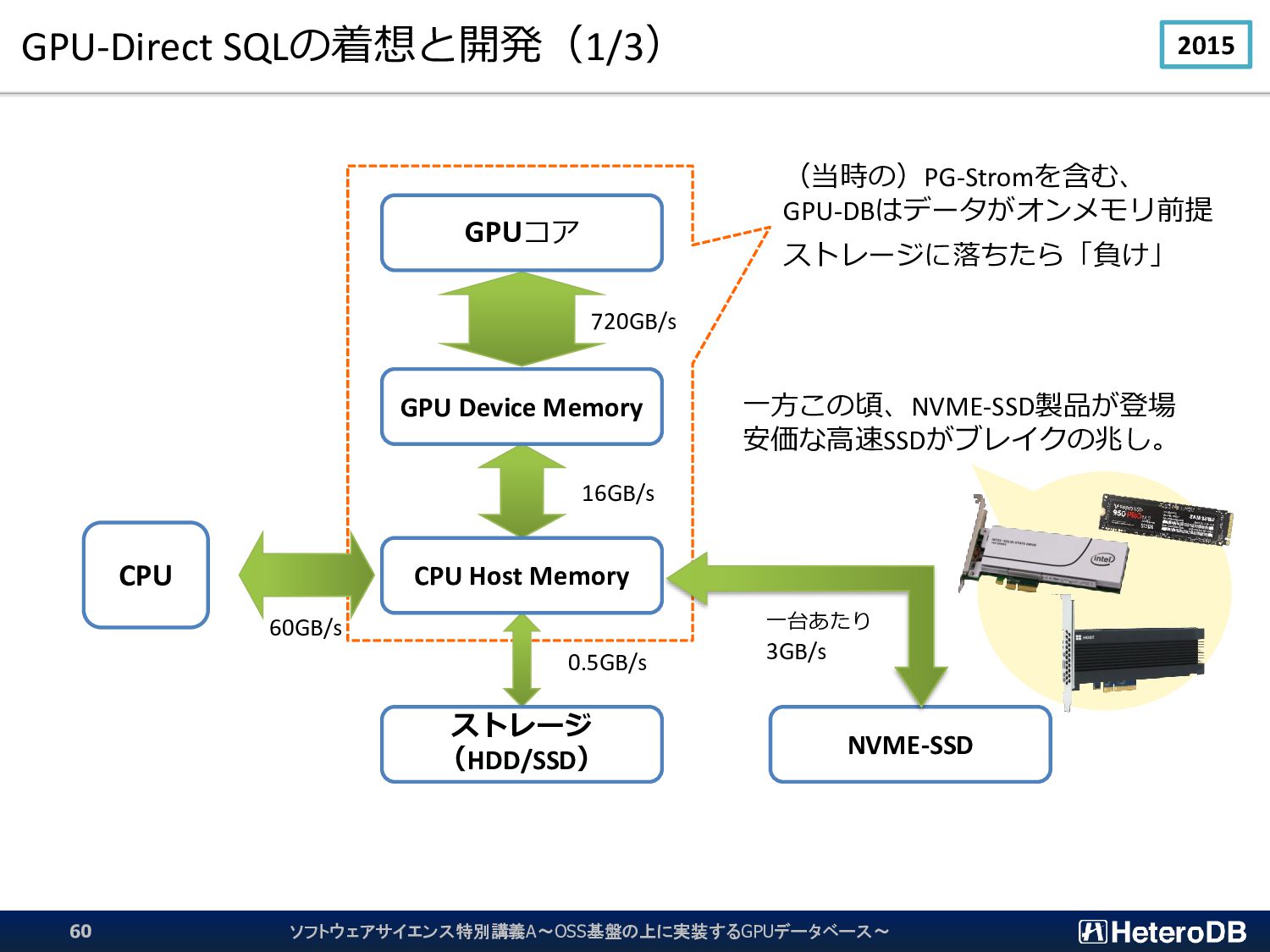{kind=link}
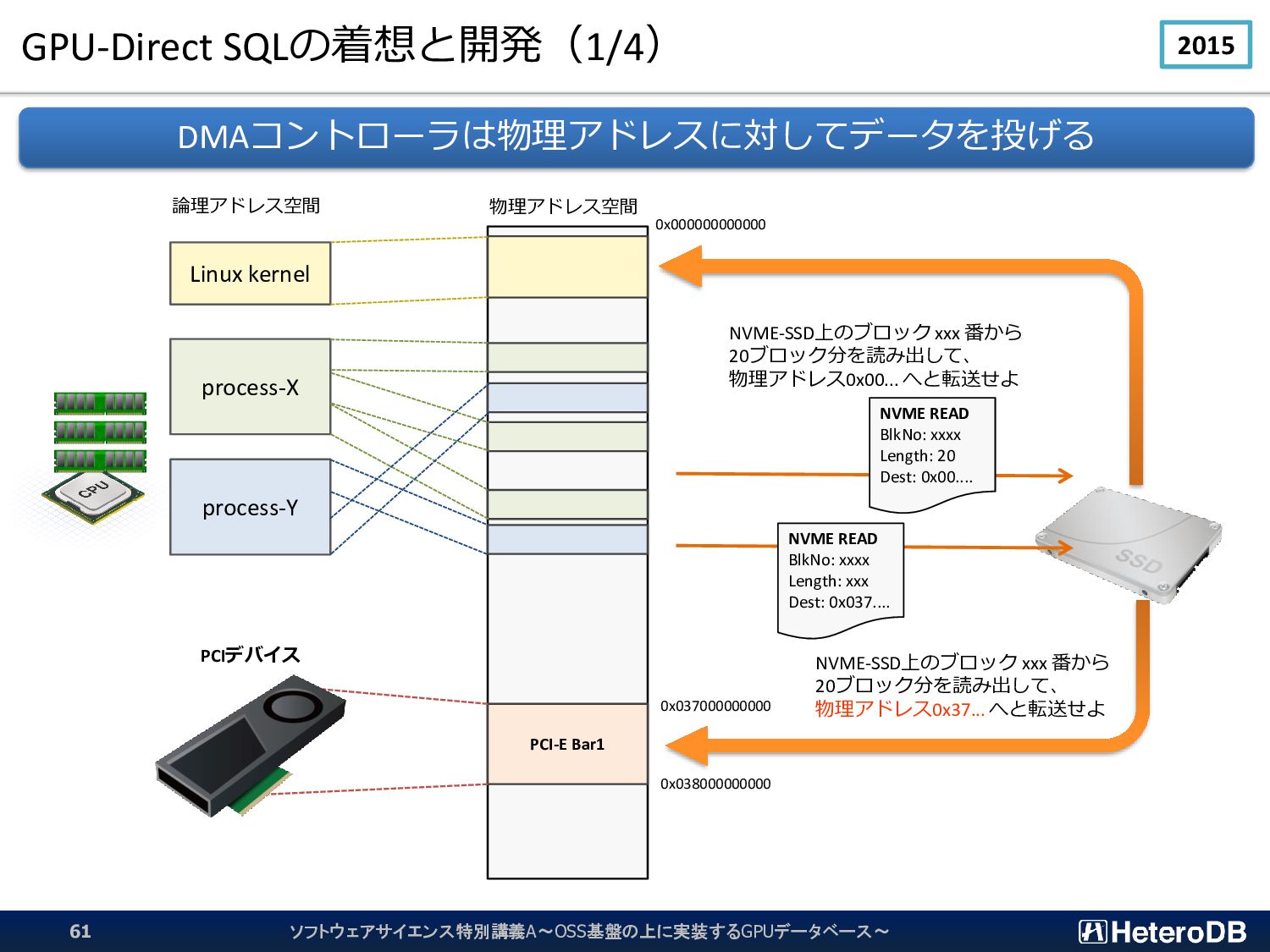{kind=link}
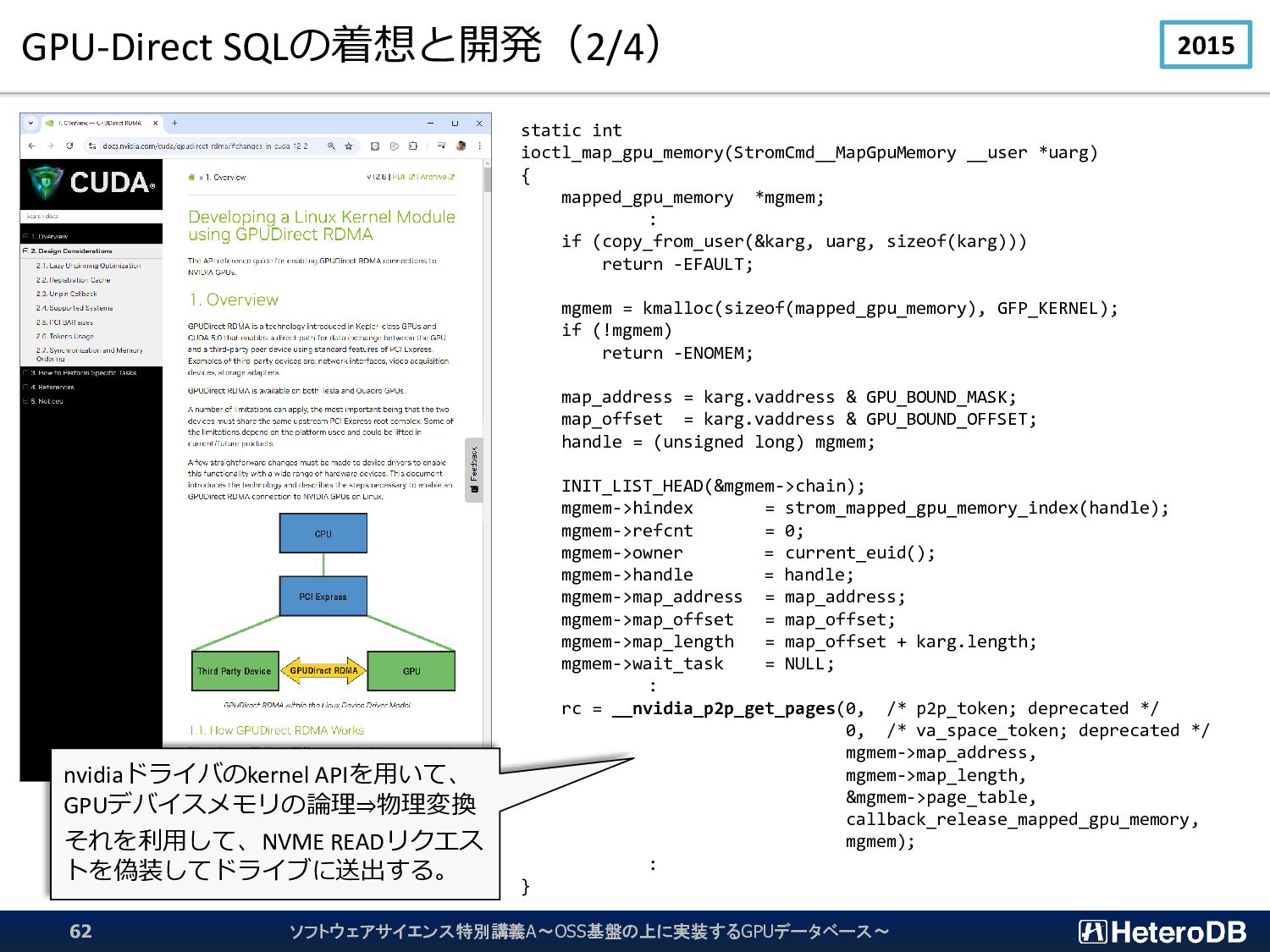{kind=link}
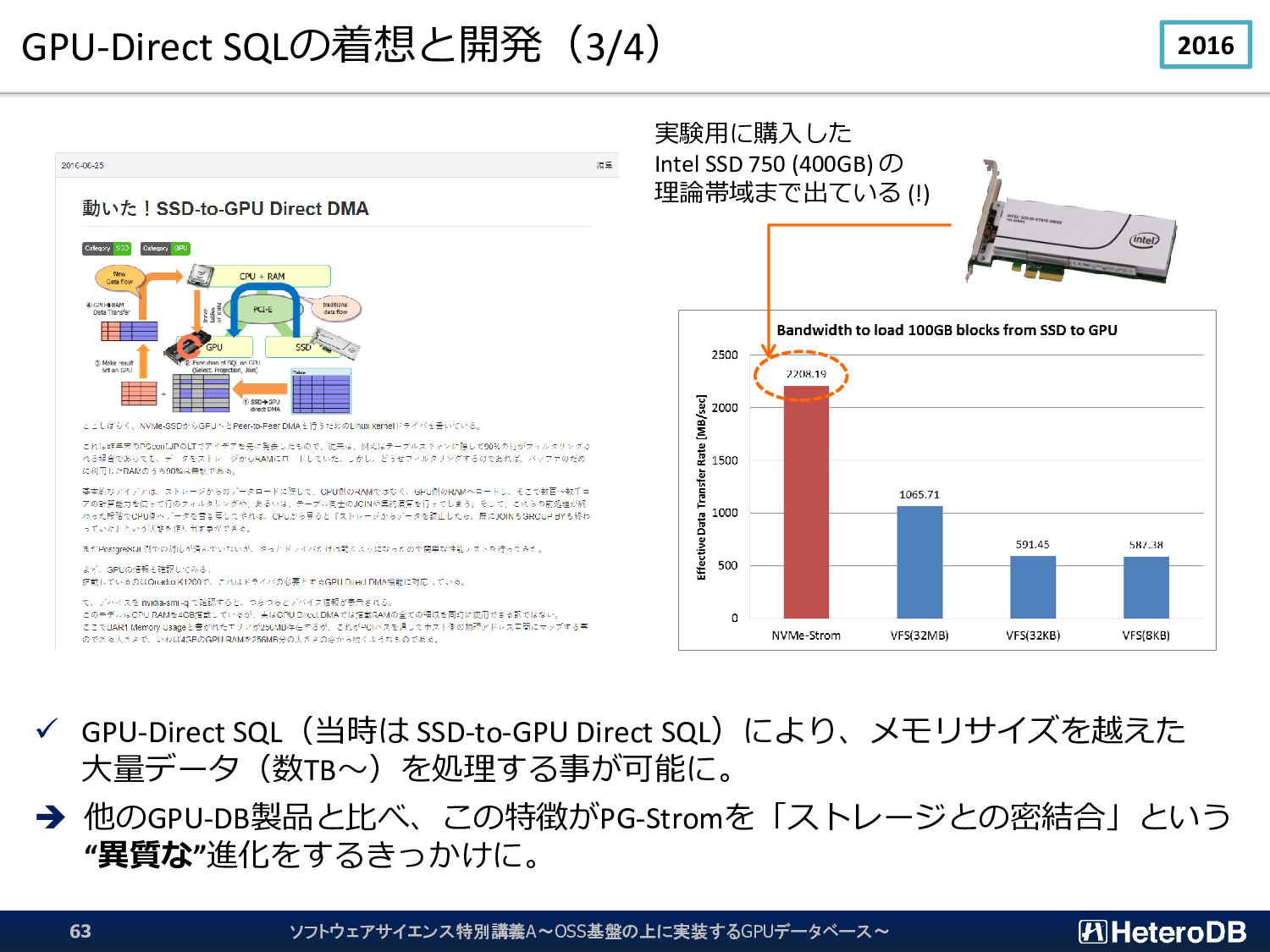{kind=link}
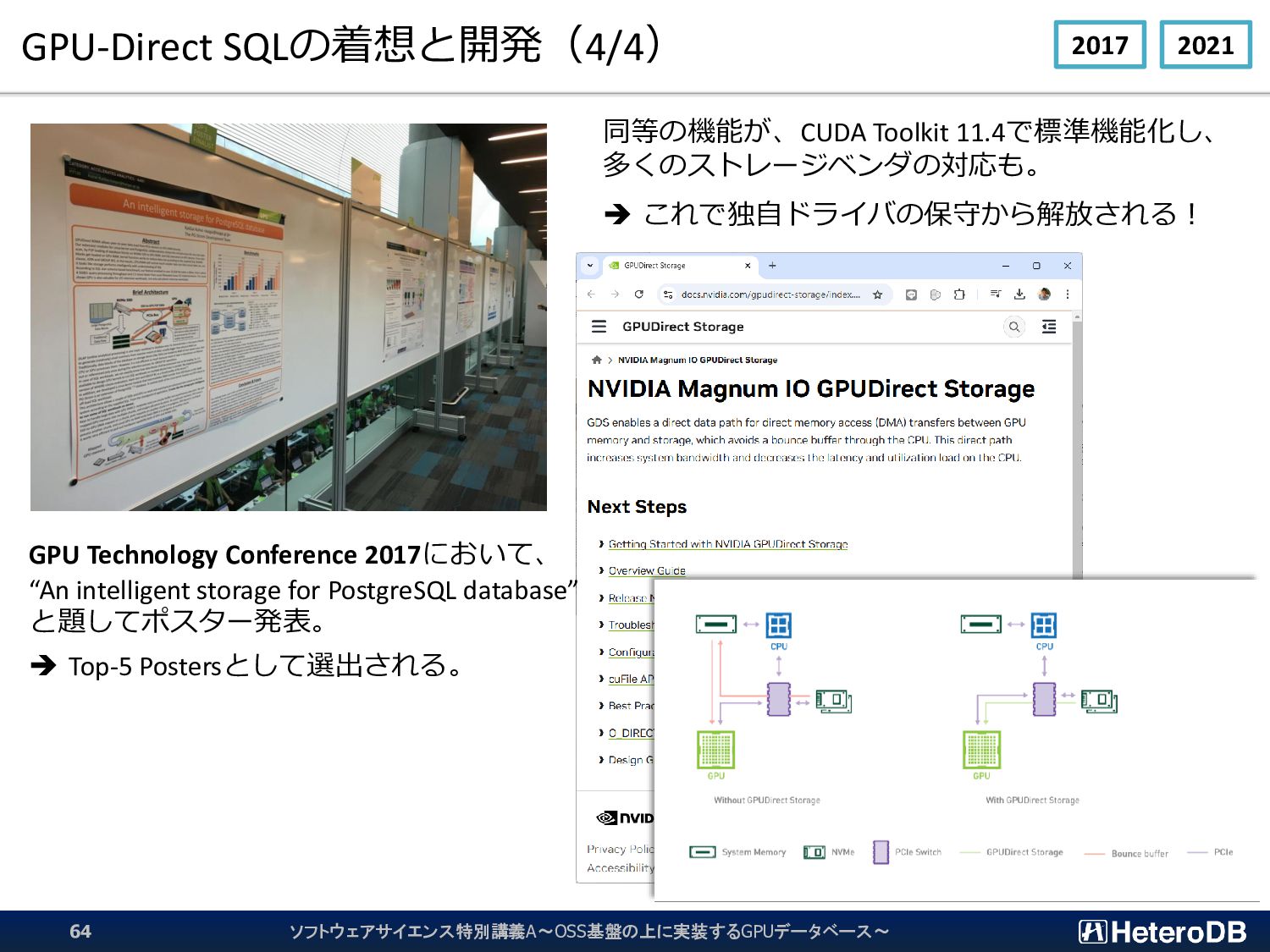{kind=link}
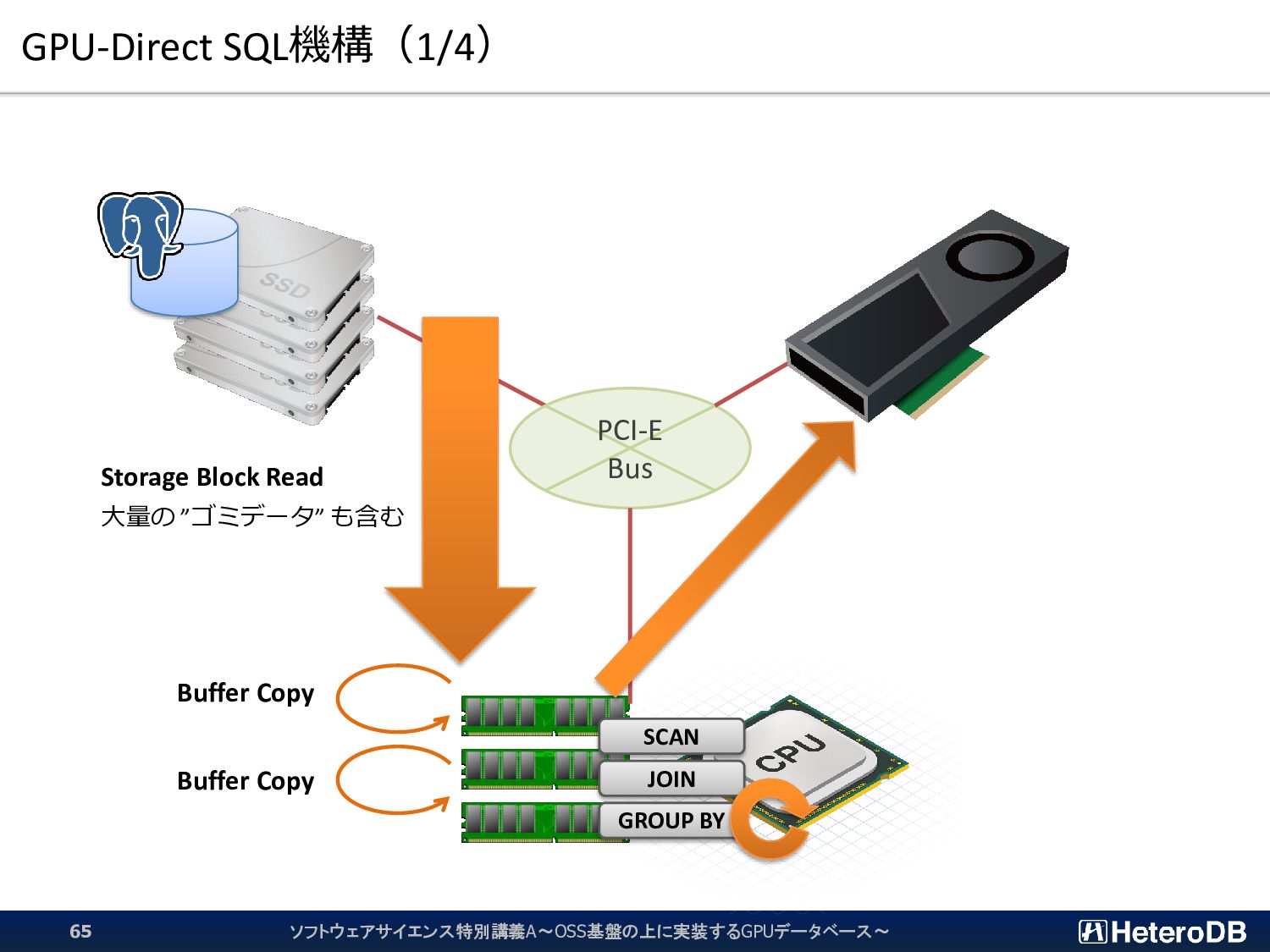{kind=link}
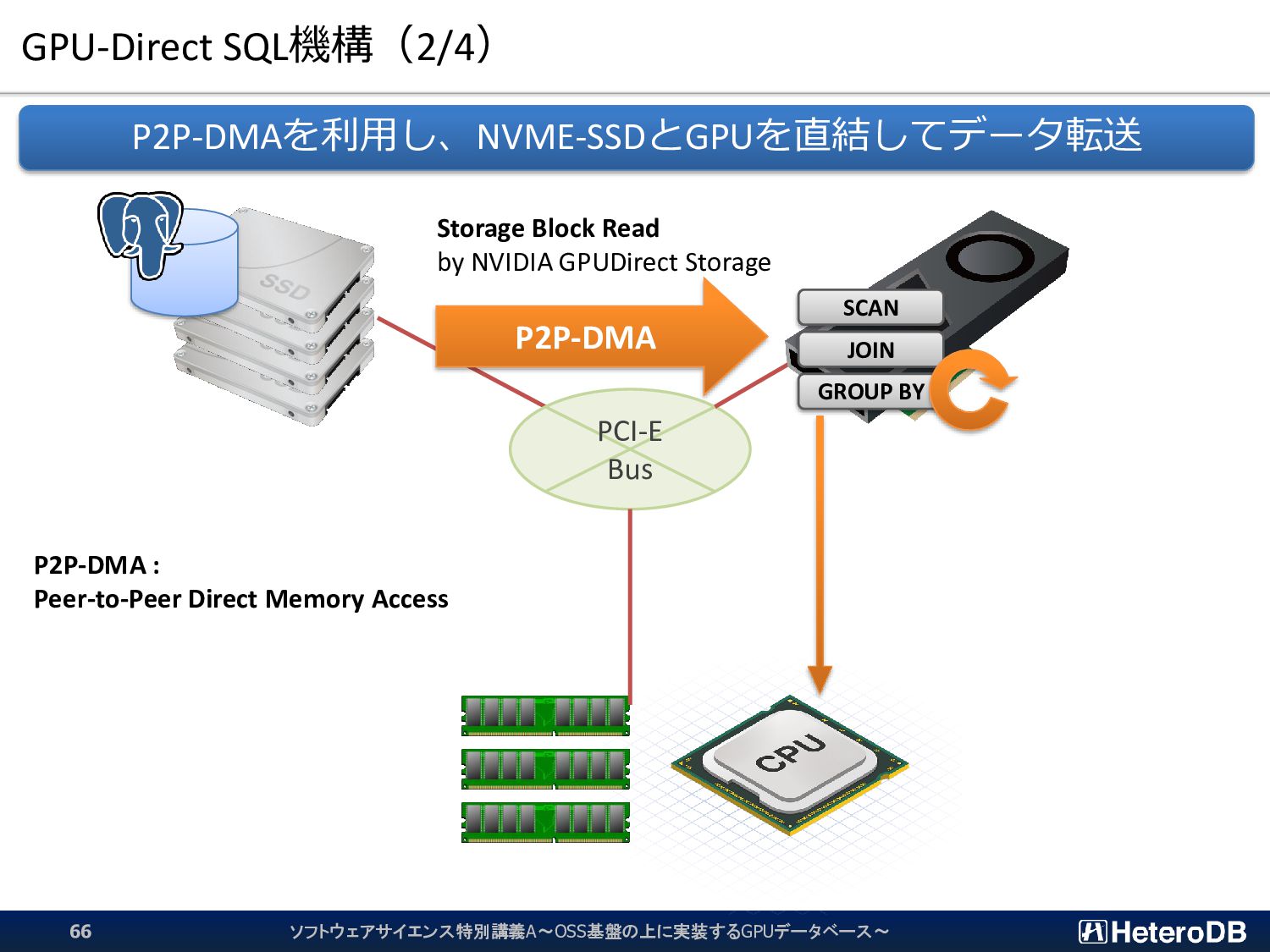{kind=link}
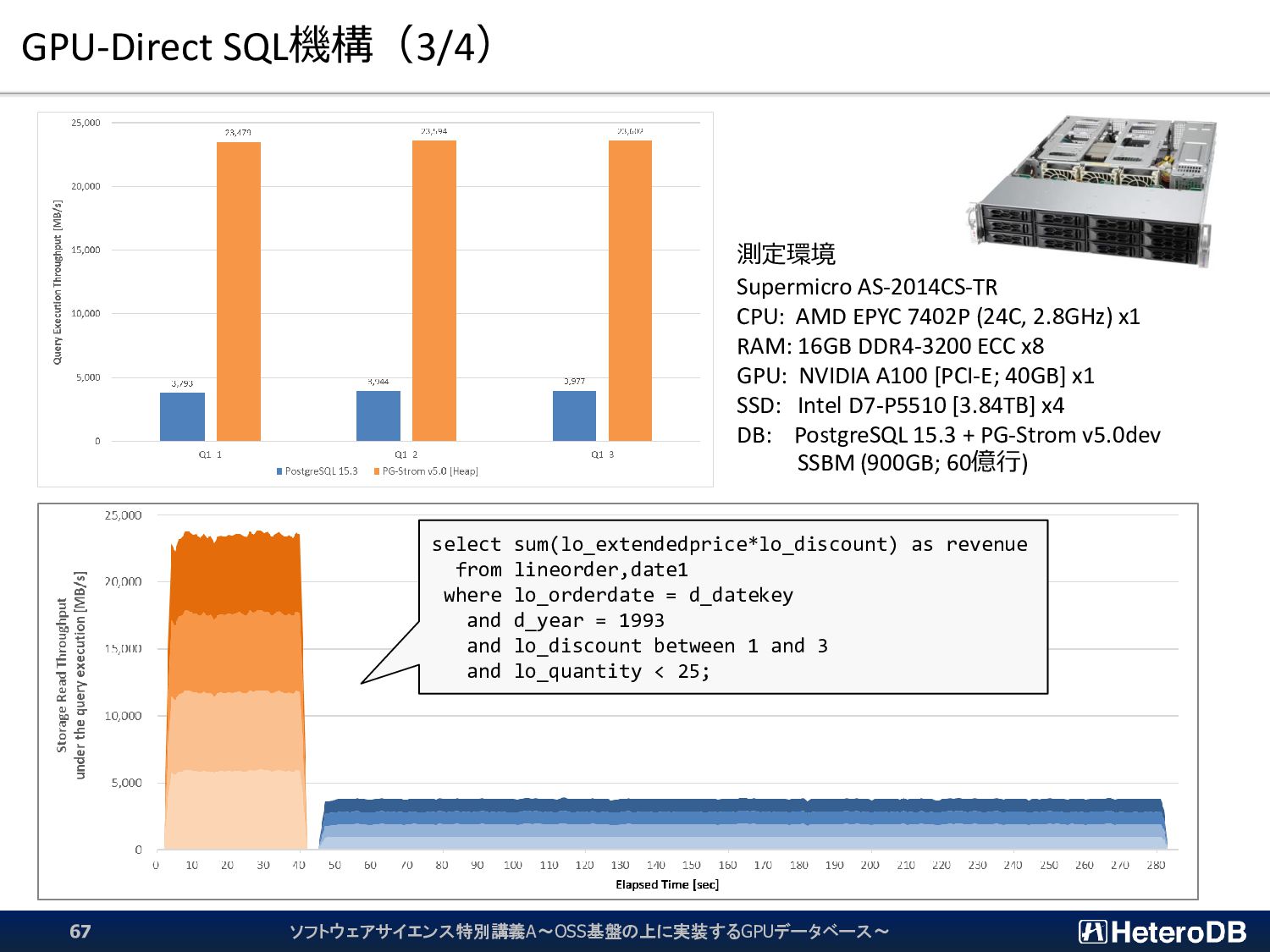{kind=link}
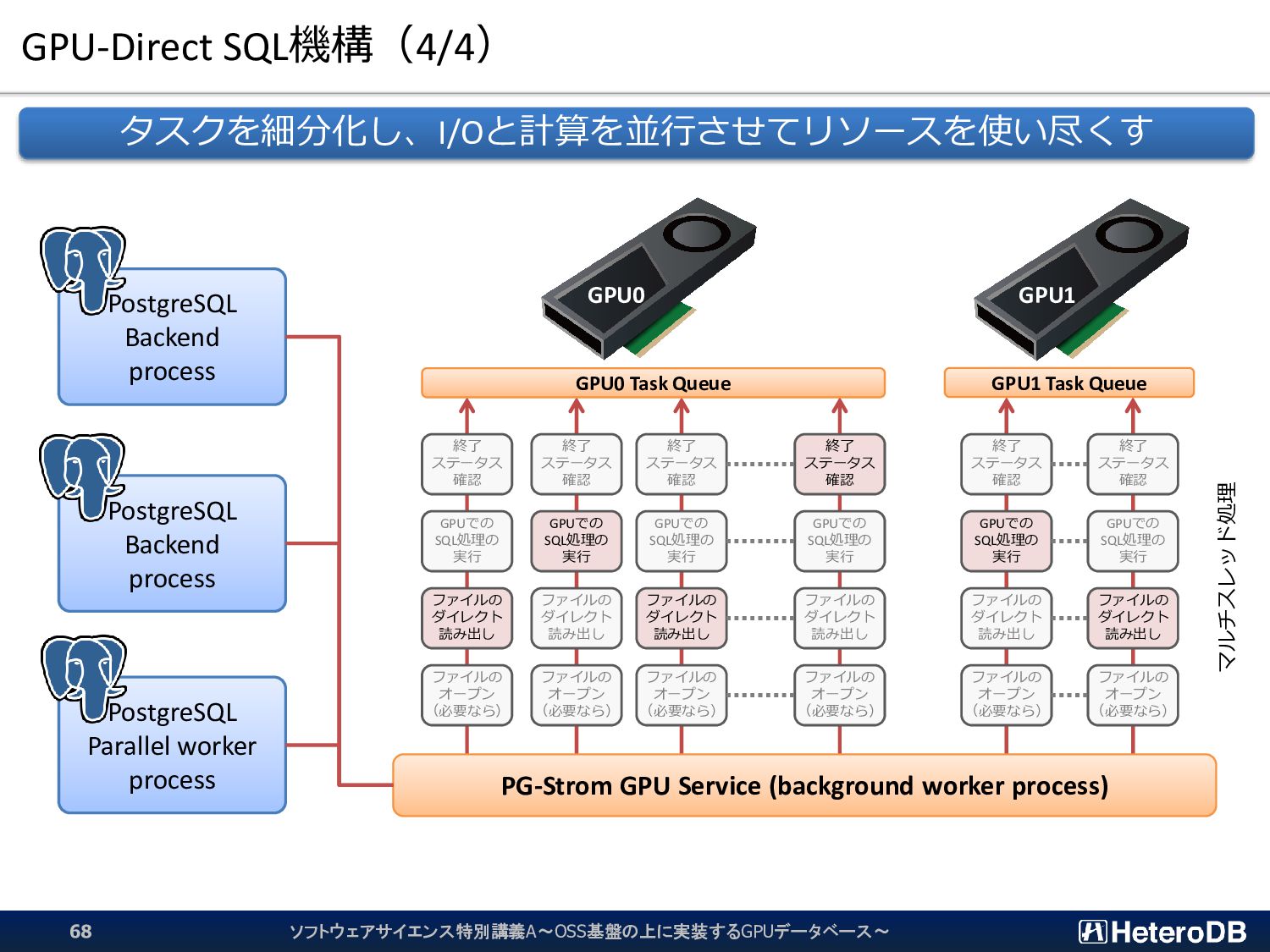{kind=link}
{kind=link}
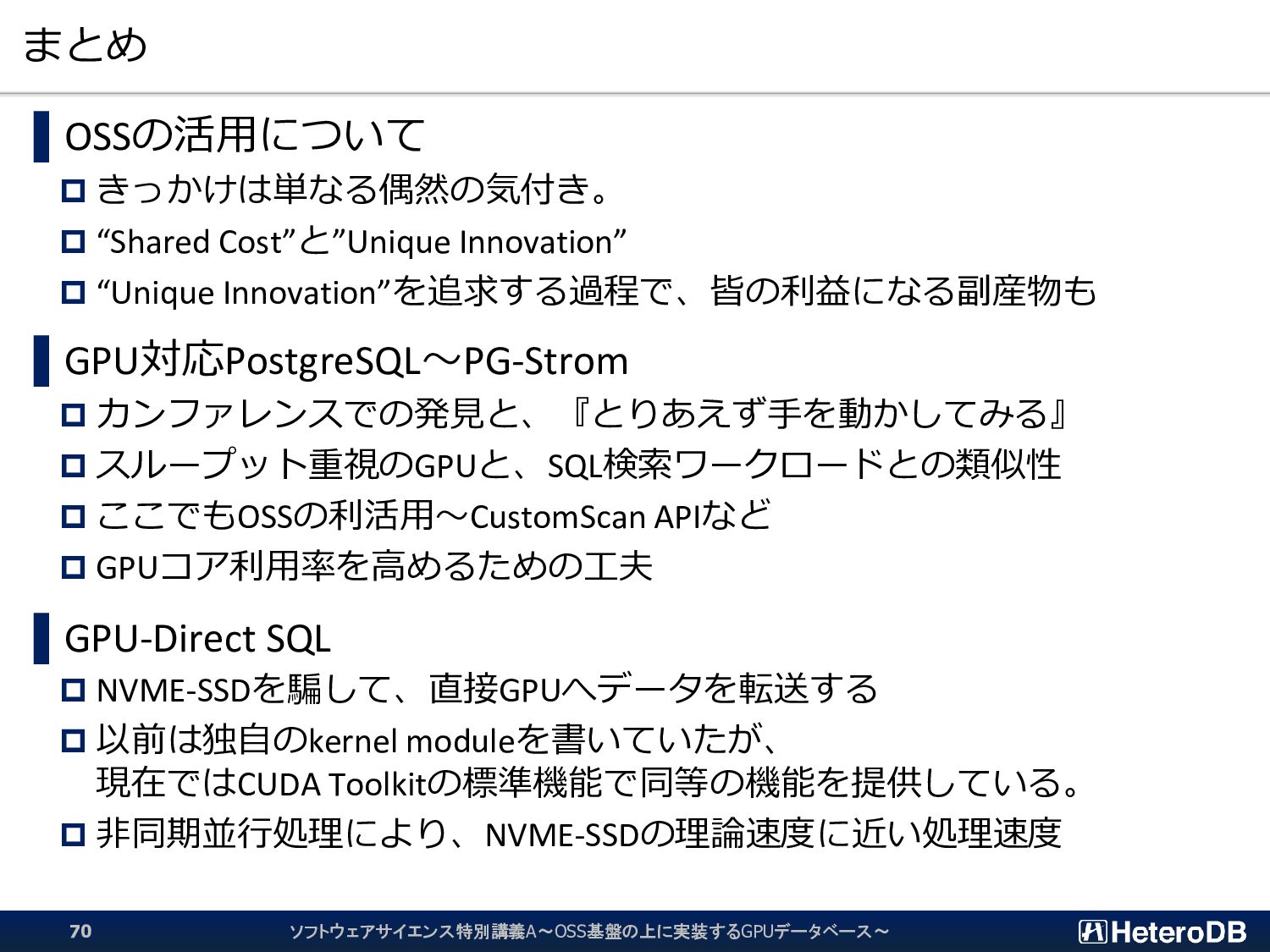{kind=link}
{kind=link}
{kind=link}