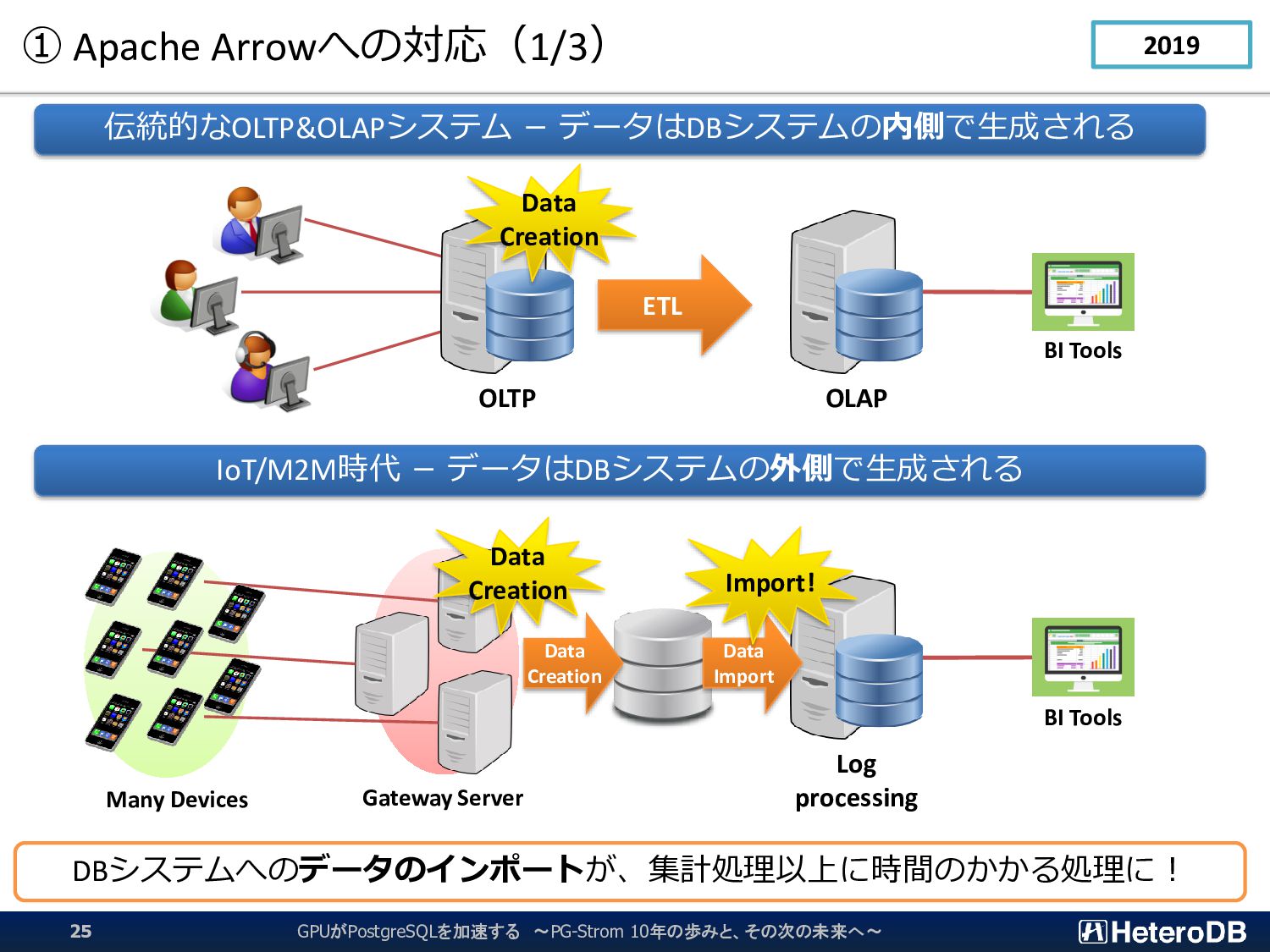
Creation IoT/M2M時代 - データはDBシステムの外側で生成される Log processing BI Tools BI Tools Gateway Server Data Creation Data Creation Many Devices GPUがPostgreSQLを加速する ~PG-Strom 10年の歩みと、その次の未来へ~ 25 DBシステムへのデータのインポートが、集計処理以上に時間のかかる処理に! Data Import Import! 2019
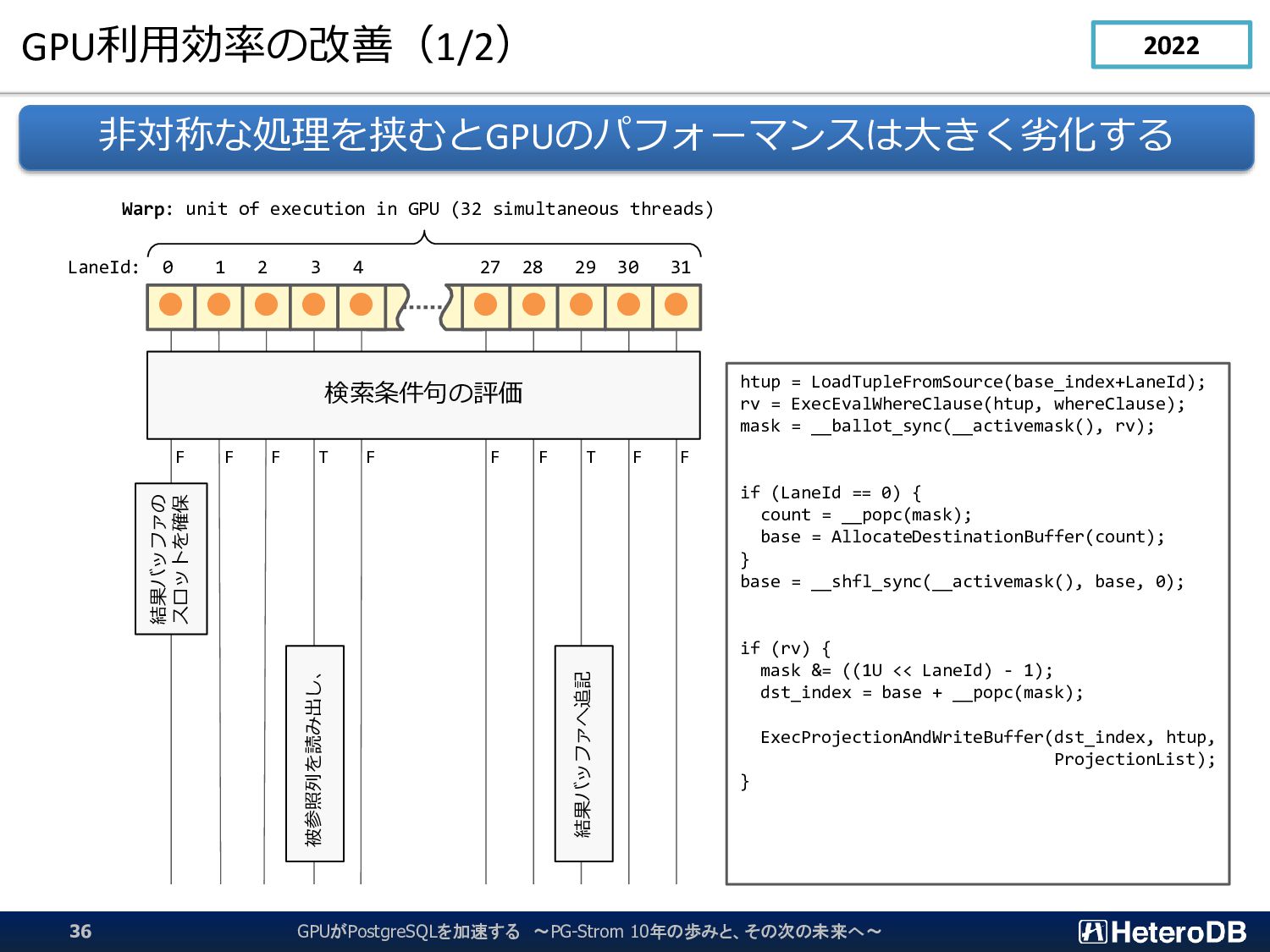
• • LaneId: 0 1 2 3 4 27 28 29 30 31 Warp: unit of execution in GPU (32 simultaneous threads) 検索条件句の評価 F F F T F F F T F F 結果バッファの スロットを確保 被参照列を読み出し、 結果バッファへ追記 htup = LoadTupleFromSource(base_index+LaneId); rv = ExecEvalWhereClause(htup, whereClause); mask = __ballot_sync(__activemask(), rv); if (LaneId == 0) { count = __popc(mask); base = AllocateDestinationBuffer(count); } base = __shfl_sync(__activemask(), base, 0); if (rv) { mask &= ((1U << LaneId) - 1); dst_index = base + __popc(mask); ExecProjectionAndWriteBuffer(dst_index, htup, ProjectionList); } GPUがPostgreSQLを加速する ~PG-Strom 10年の歩みと、その次の未来へ~ 36 2022
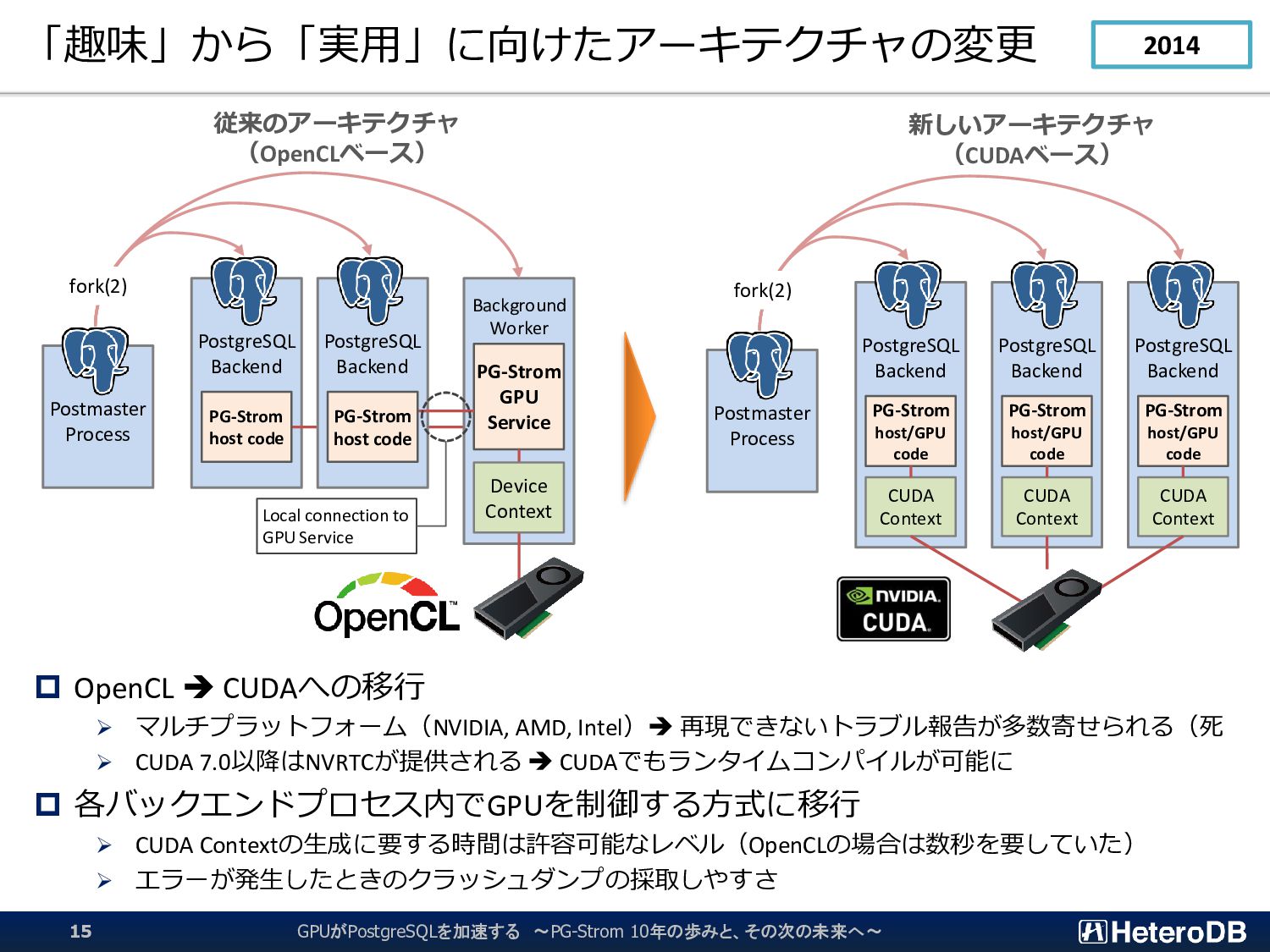
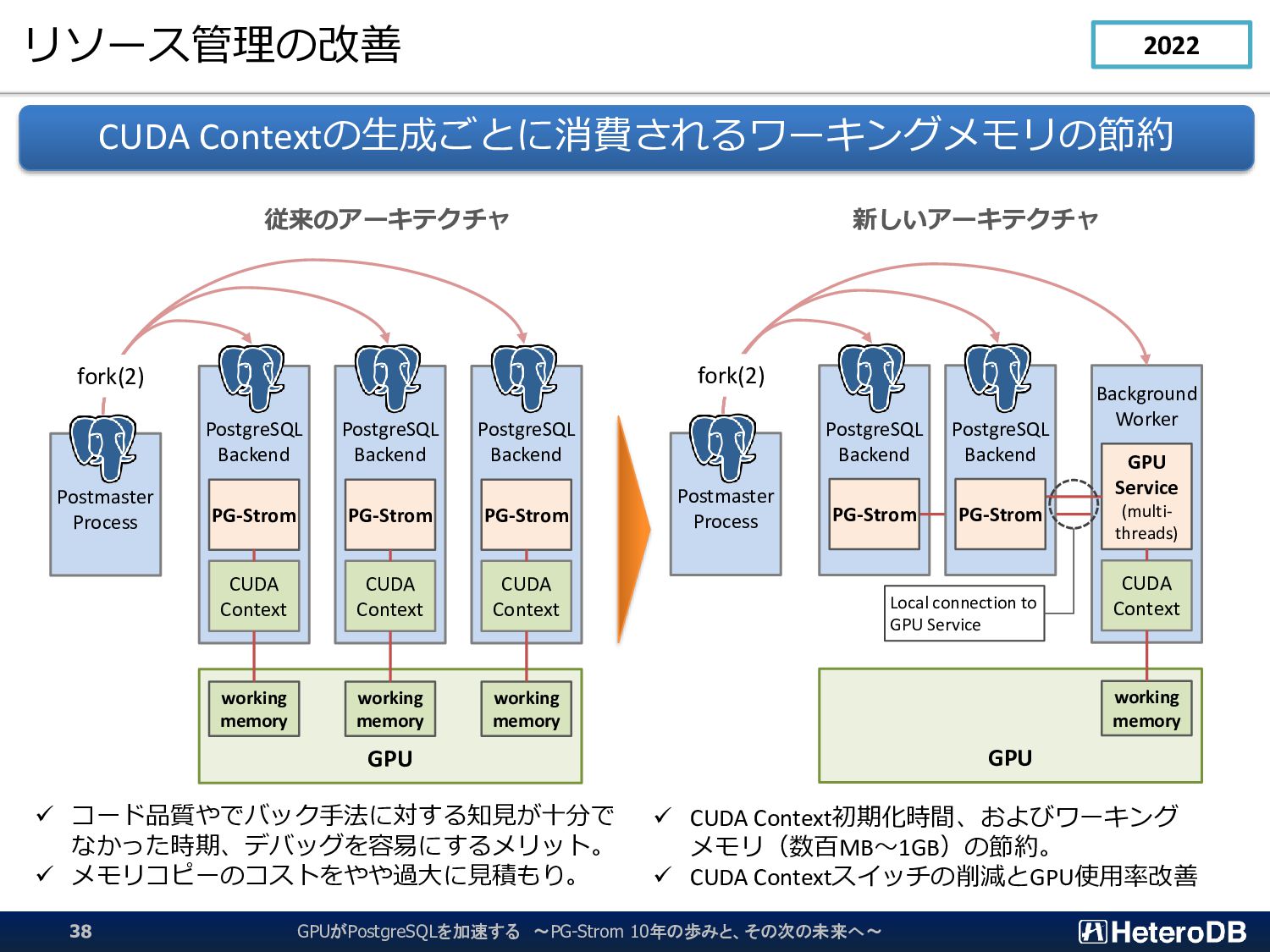
CUDA Context PG-Strom PostgreSQL Backend CUDA Context PG-Strom PostgreSQL Backend CUDA Context PG-Strom Postmaster Process working memory working memory working memory fork(2) GPU PG-Strom PostgreSQL Backend Background Worker CUDA Context GPU Service (multi- threads) Postmaster Process working memory fork(2) PG-Strom Local connection to GPU Service ✓ コード品質やでバック手法に対する知見が十分で なかった時期、デバッグを容易にするメリット。 ✓ メモリコピーのコストをやや過大に見積もり。 ✓ CUDA Context初期化時間、およびワーキング メモリ(数百MB~1GB)の節約。 ✓ CUDA Contextスイッチの削減とGPU使用率改善 GPUがPostgreSQLを加速する ~PG-Strom 10年の歩みと、その次の未来へ~ 38 2022
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![GPUとはどんなプロセッサか?(2/2) GPUがPostgreSQLを加速する ~PG-Strom 10年の歩みと、その次の未来へ~ 8 スレッド同士での同期やデータ交換を低コストで実行できる • item[0] step.1 step.2](https://files.speakerdeck.com/presentations/034713844a744945b9e676f7fa8abc57/slide_7.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
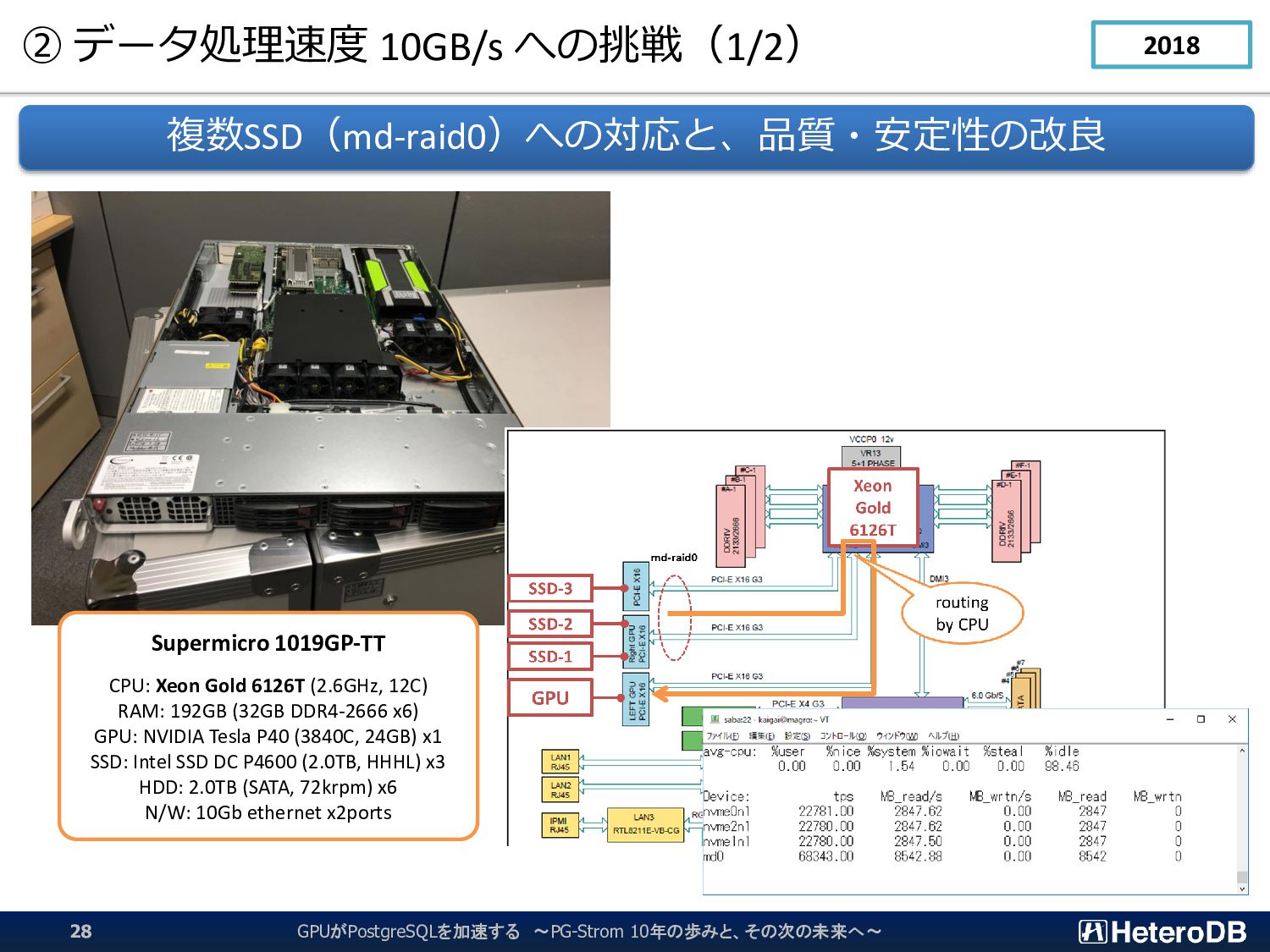{kind=link}
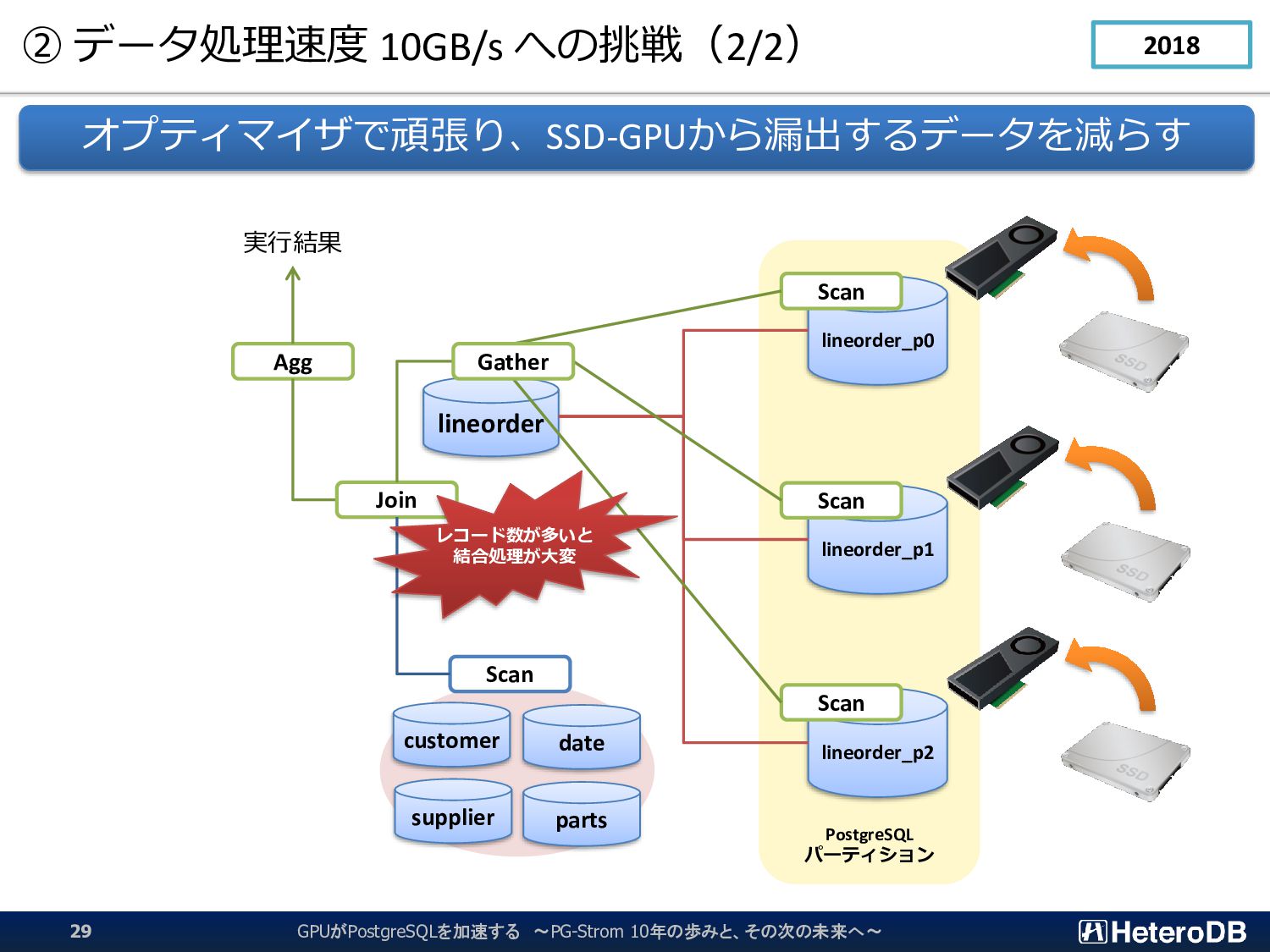{kind=link}
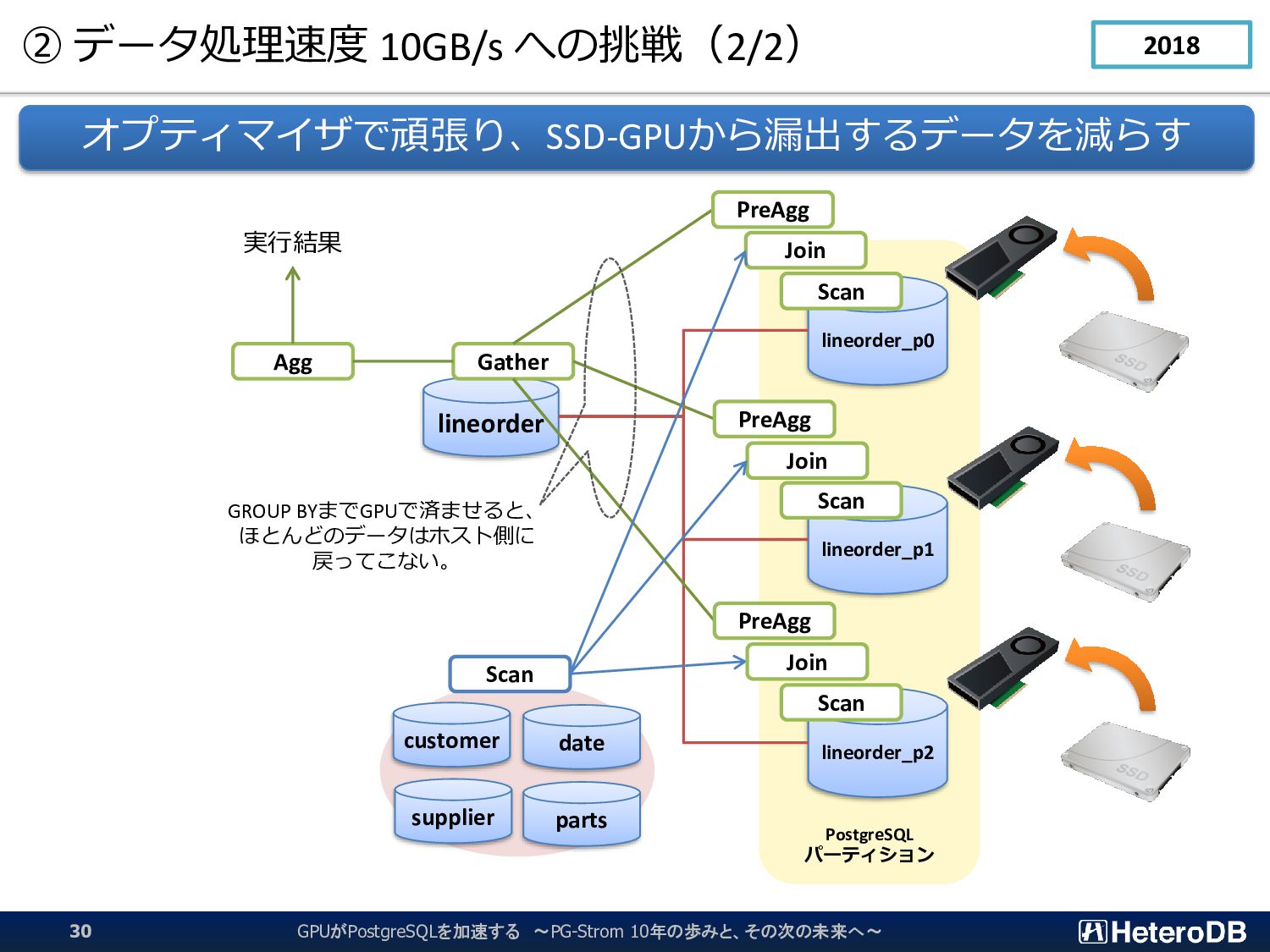{kind=link}
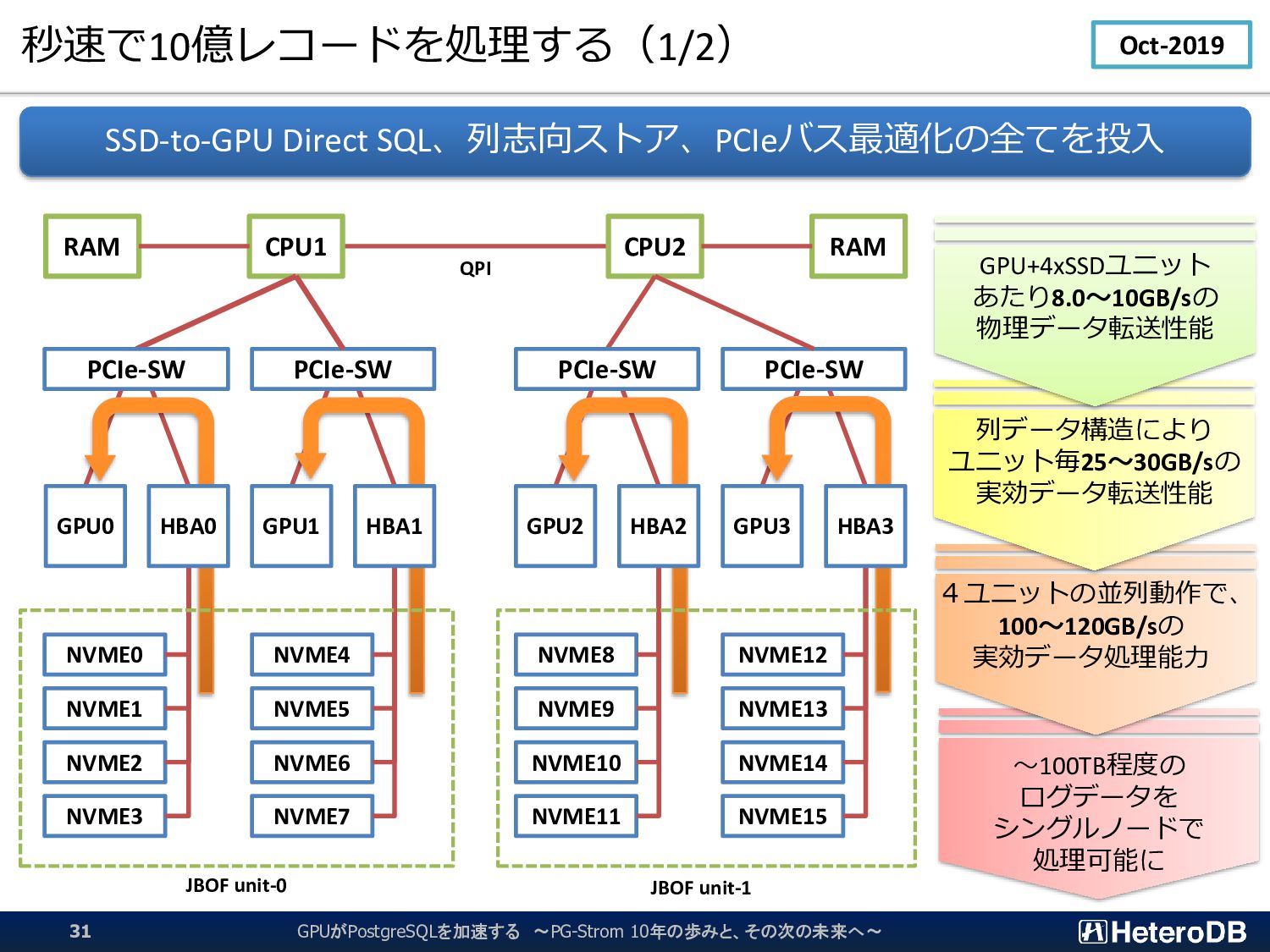{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}