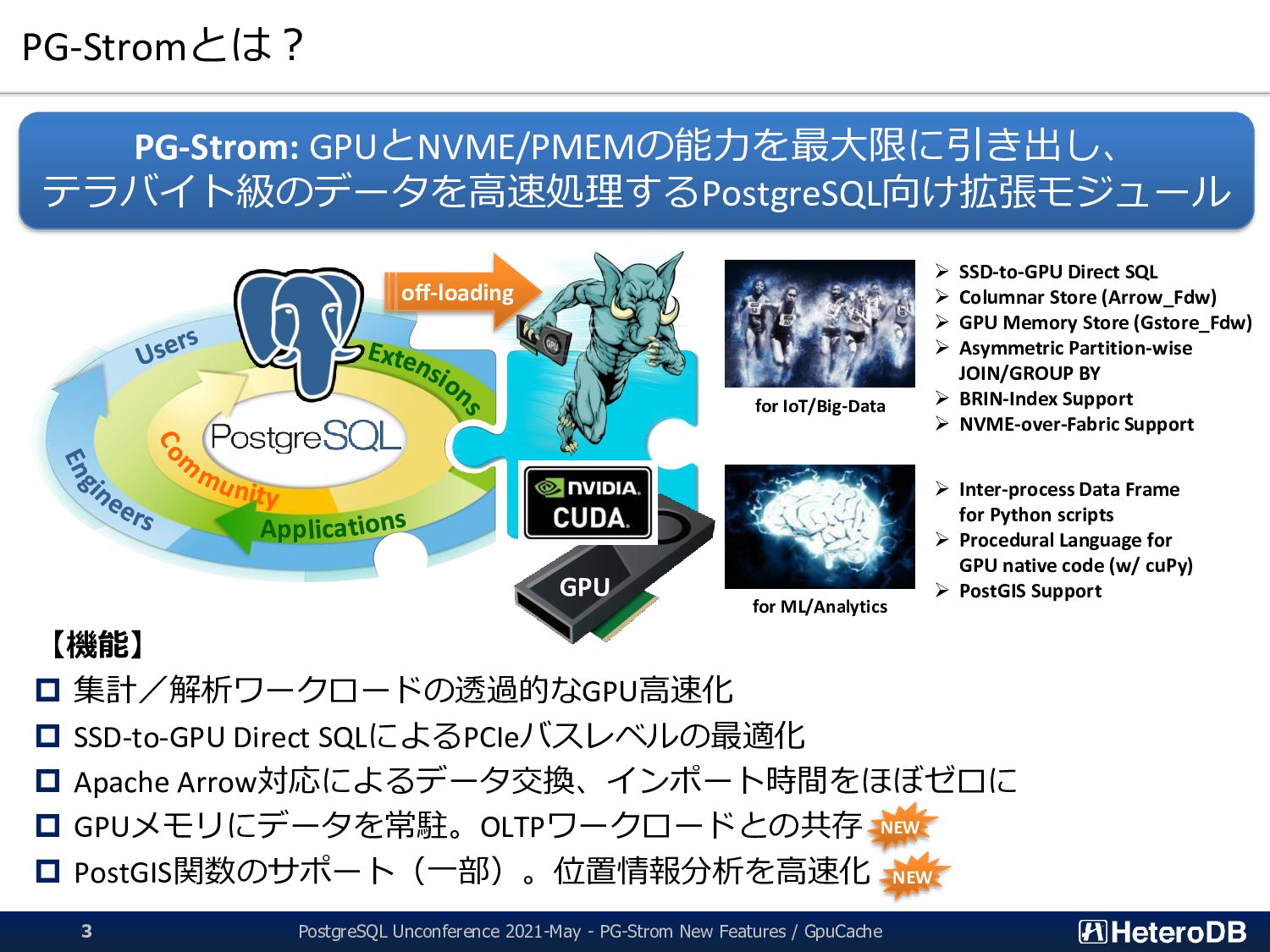
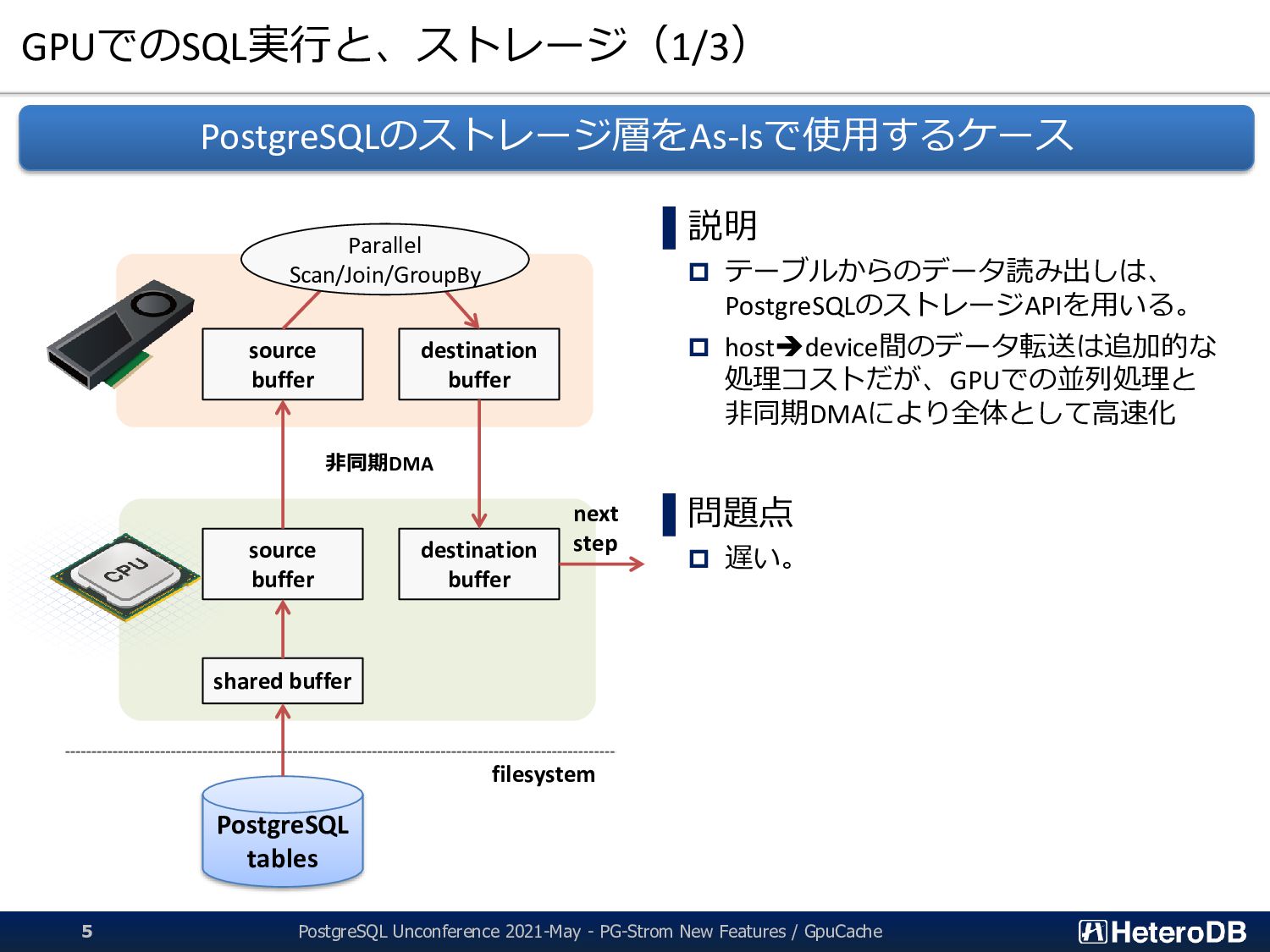
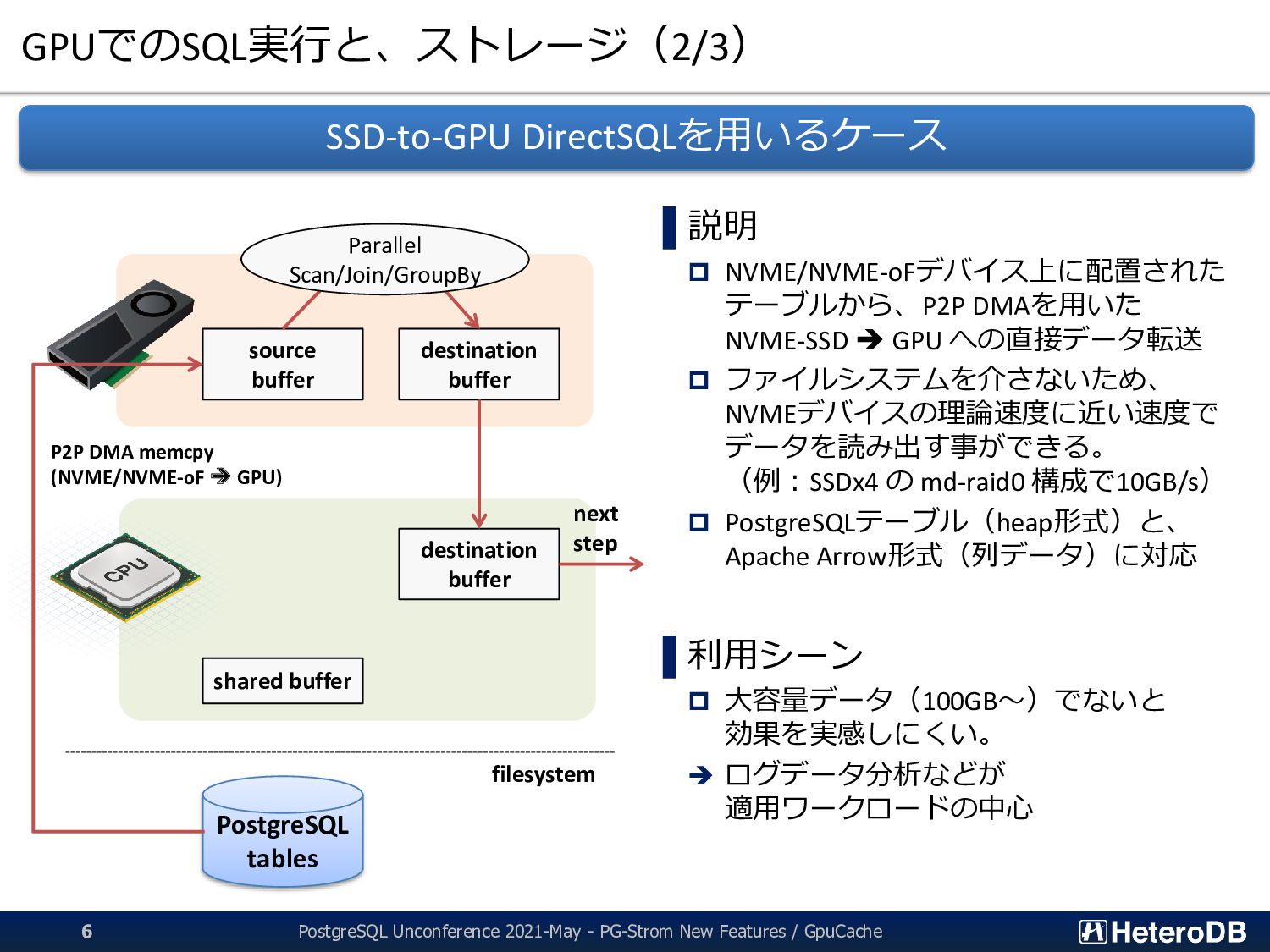
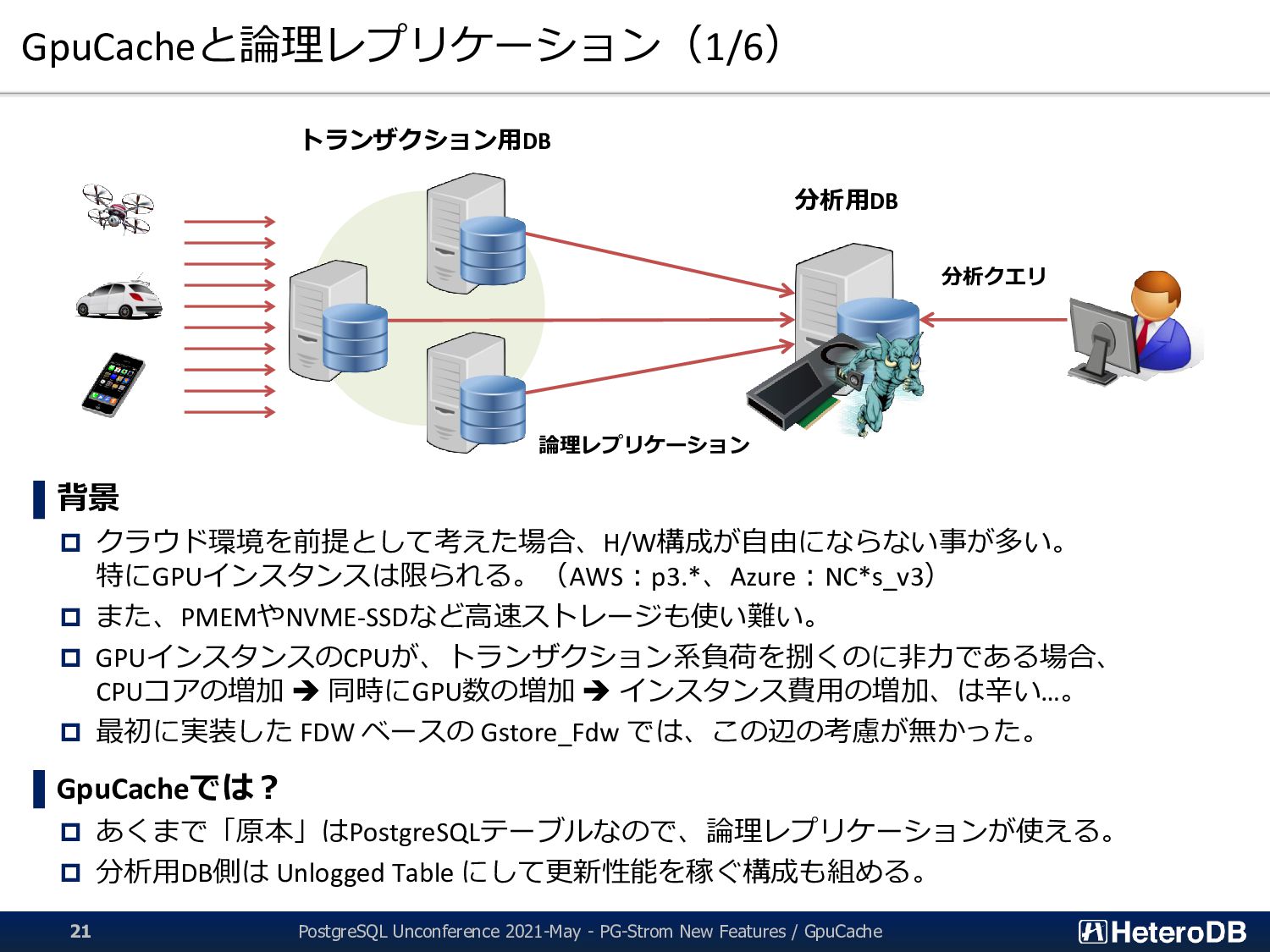
3 【機能】 集計/解析ワークロードの透過的なGPU高速化 SSD-to-GPU Direct SQLによるPCIeバスレベルの最適化 Apache Arrow対応によるデータ交換、インポート時間をほぼゼロに GPUメモリにデータを常駐。OLTPワークロードとの共存 PostGIS関数のサポート(一部)。位置情報分析を高速化 PG-Strom: GPUとNVME/PMEMの能力を最大限に引き出し、 テラバイト級のデータを高速処理するPostgreSQL向け拡張モジュール App GPU off-loading for IoT/Big-Data for ML/Analytics ➢ SSD-to-GPU Direct SQL ➢ Columnar Store (Arrow_Fdw) ➢ GPU Memory Store (Gstore_Fdw) ➢ Asymmetric Partition-wise JOIN/GROUP BY ➢ BRIN-Index Support ➢ NVME-over-Fabric Support ➢ Inter-process Data Frame for Python scripts ➢ Procedural Language for GPU native code (w/ cuPy) ➢ PostGIS Support NEW NEW
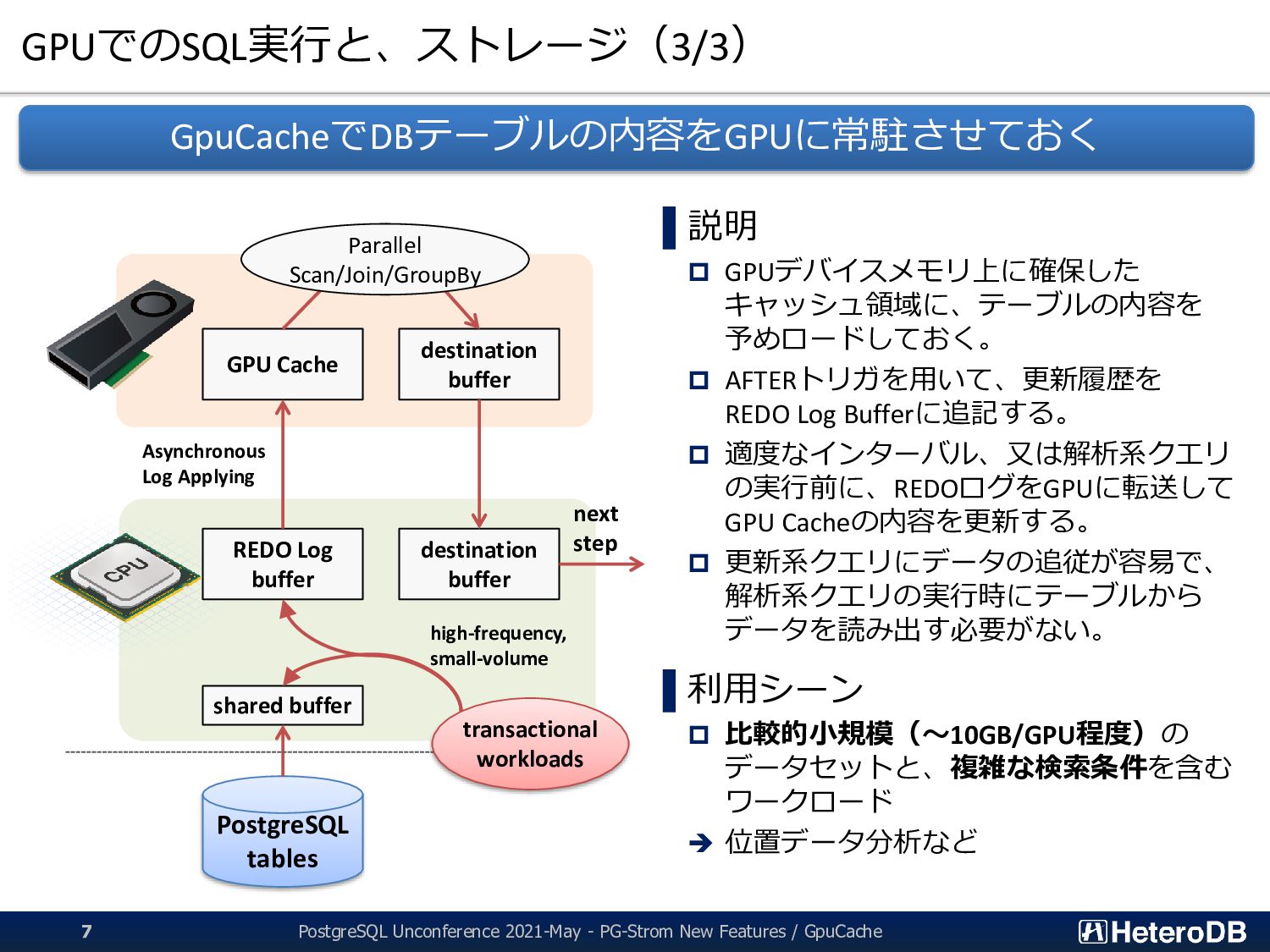
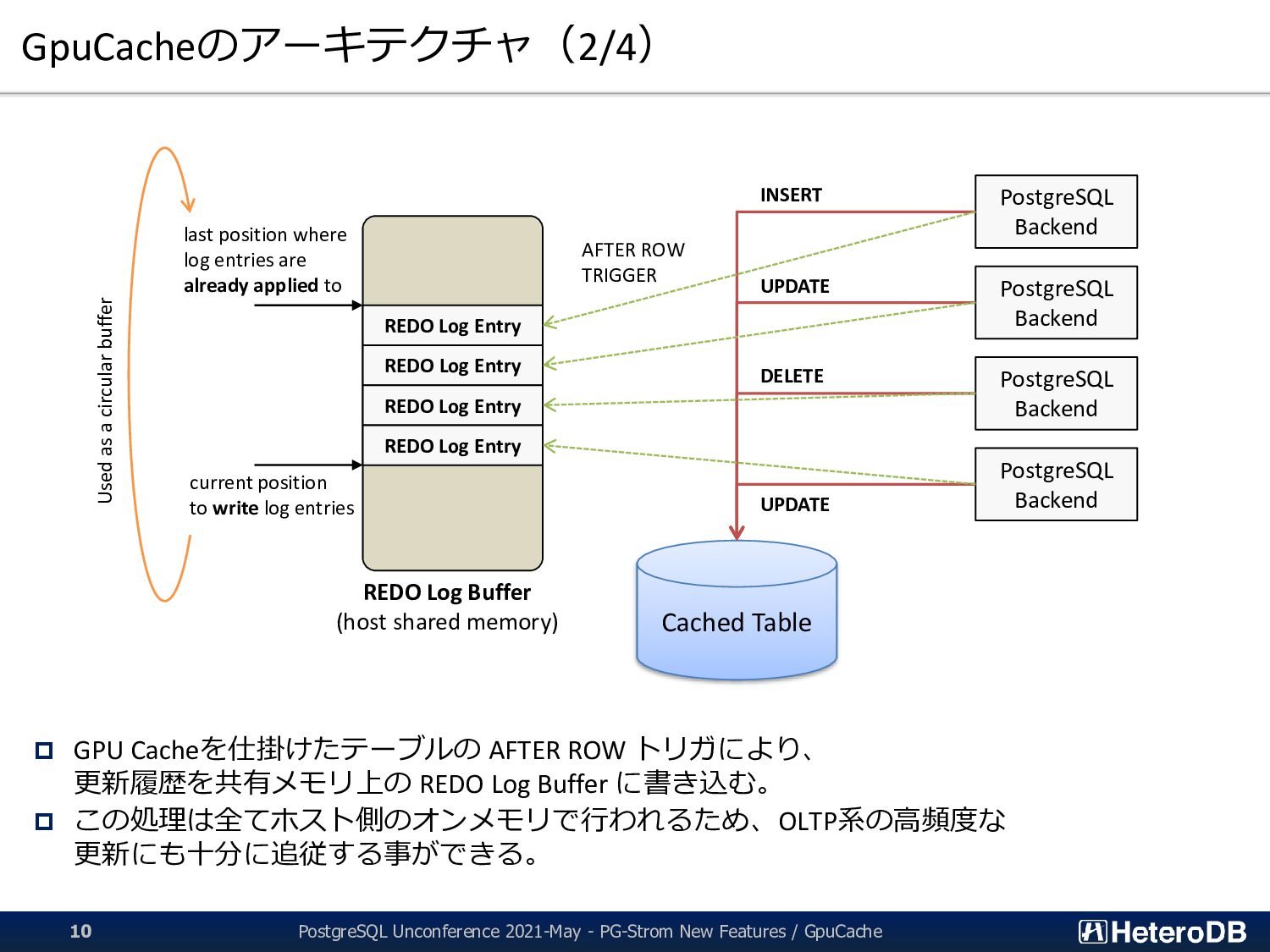
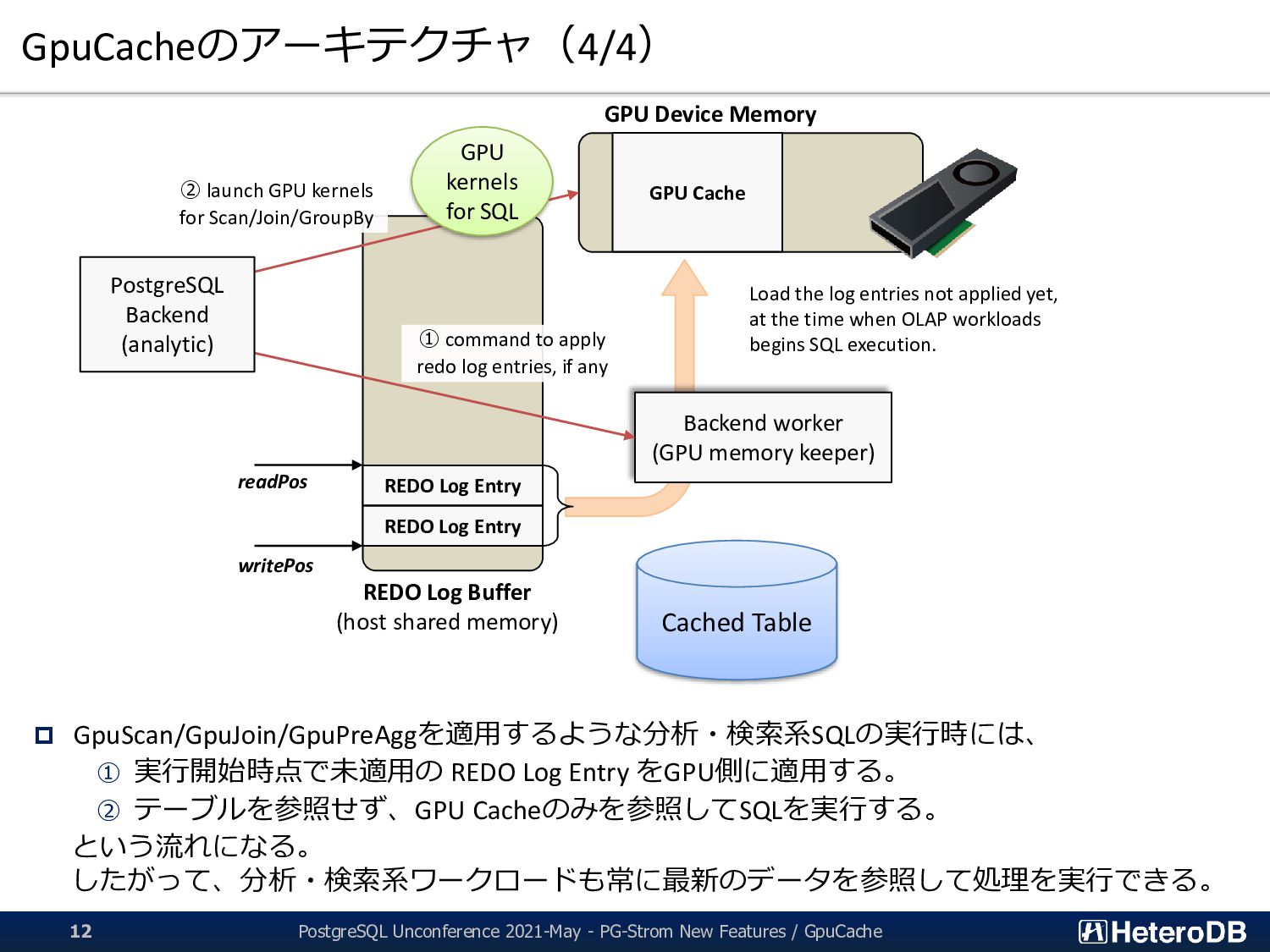
Buffer に書き込む。 この処理は全てホスト側のオンメモリで行われるため、OLTP系の高頻度な 更新にも十分に追従する事ができる。 Cached Table REDO Log Buffer (host shared memory) PostgreSQL Backend PostgreSQL Backend PostgreSQL Backend PostgreSQL Backend REDO Log Entry REDO Log Entry REDO Log Entry REDO Log Entry current position to write log entries last position where log entries are already applied to Used as a circular buffer AFTER ROW TRIGGER INSERT UPDATE DELETE UPDATE PostgreSQL Unconference 2021-May - PG-Strom New Features / GpuCache 10
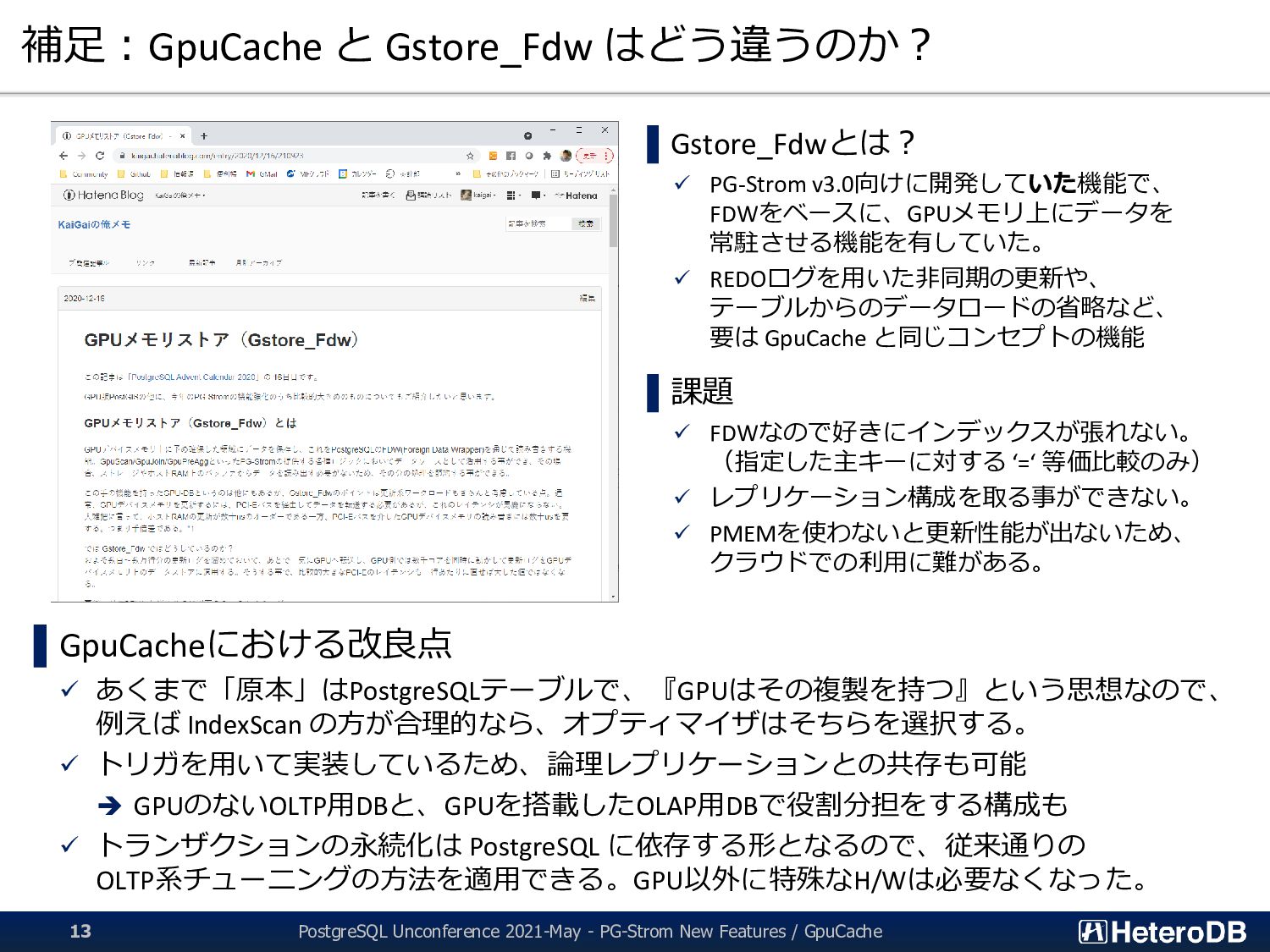
FOR ROW で、 pgstrom.gpucache_sync_trigger() を実行するトリガが設定されている。 テーブルに AFTER TRUNCATE FOR STATEMENT で、 pgstrom.gpucache_sync_trigger() を実行するトリガが設定されている。 (論理レプリケーションの場合は更に) レプリケーション先でも上記トリガを実行するよう設定されている。 ▌設定例 # create trigger row_sync after insert or update or delete on mytest for each row execute function pgstrom.gpucache_sync_trigger(); # create trigger stmt_sync after truncate on mytest for each statement execute function pgstrom.gpucache_sync_trigger(); # alter table mytest enable always trigger row_sync; # alter table mytest enable always trigger stmt_sync; PostgreSQL Unconference 2021-May - PG-Strom New Features / GpuCache 14
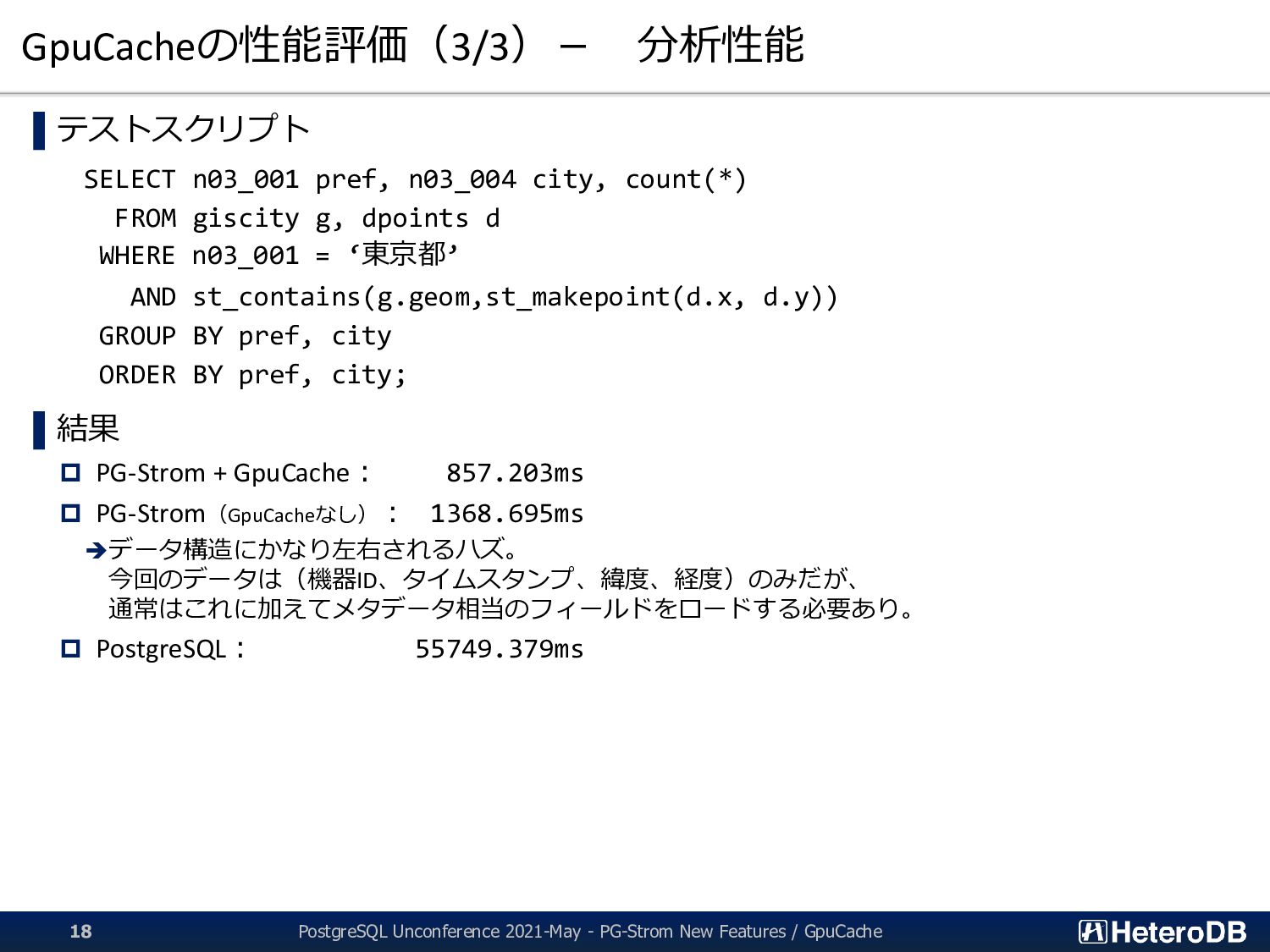
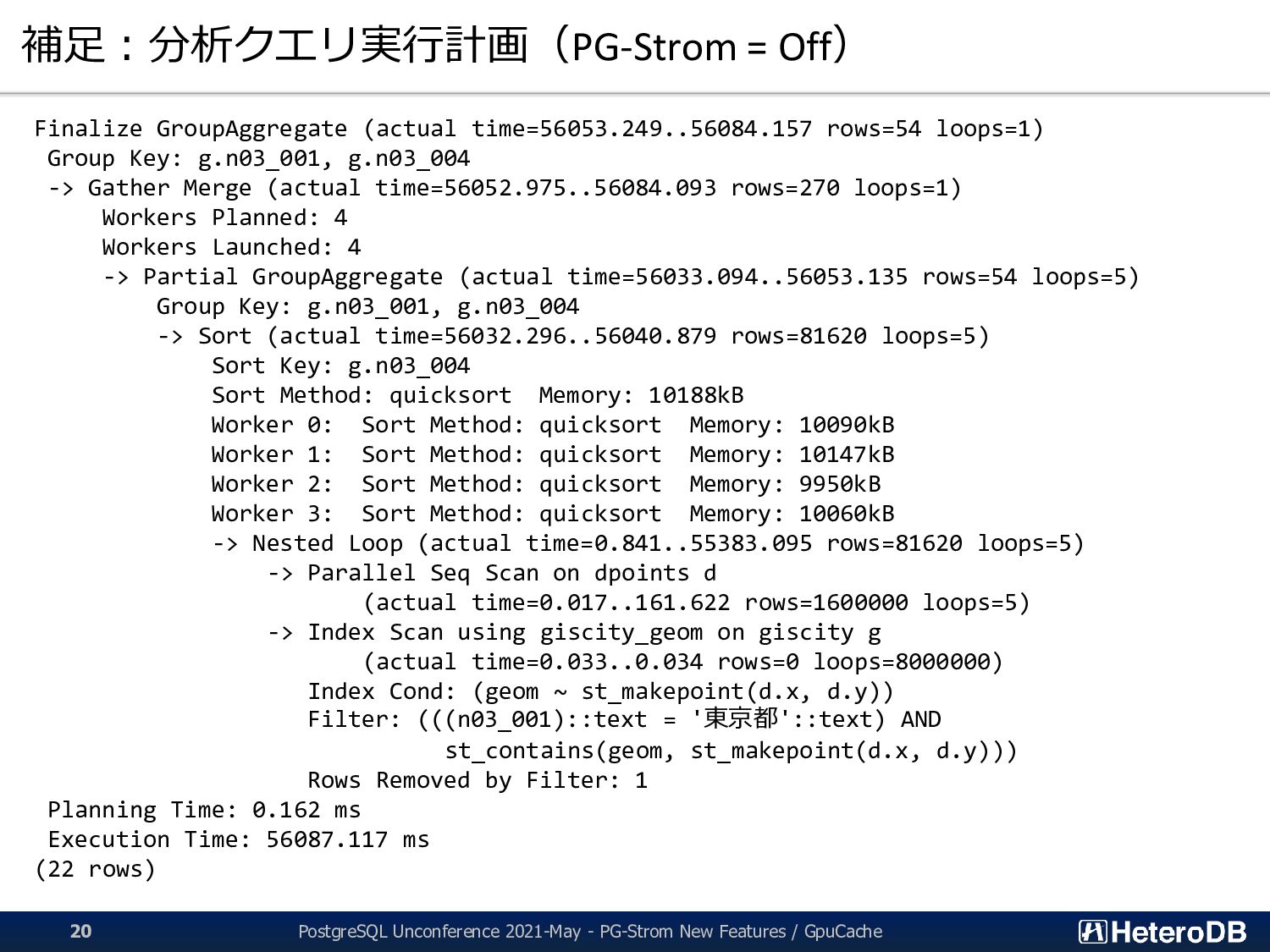
giscity g, dpoints d WHERE n03_001 = ‘東京都’ AND st_contains(g.geom,st_makepoint(d.x, d.y)) GROUP BY pref, city ORDER BY pref, city; ▌結果 PG-Strom + GpuCache: 857.203ms PG-Strom(GpuCacheなし): 1368.695ms ➔データ構造にかなり左右されるハズ。 今回のデータは(機器ID、タイムスタンプ、緯度、経度)のみだが、 通常はこれに加えてメタデータ相当のフィールドをロードする必要あり。 PostgreSQL: 55749.379ms PostgreSQL Unconference 2021-May - PG-Strom New Features / GpuCache 18
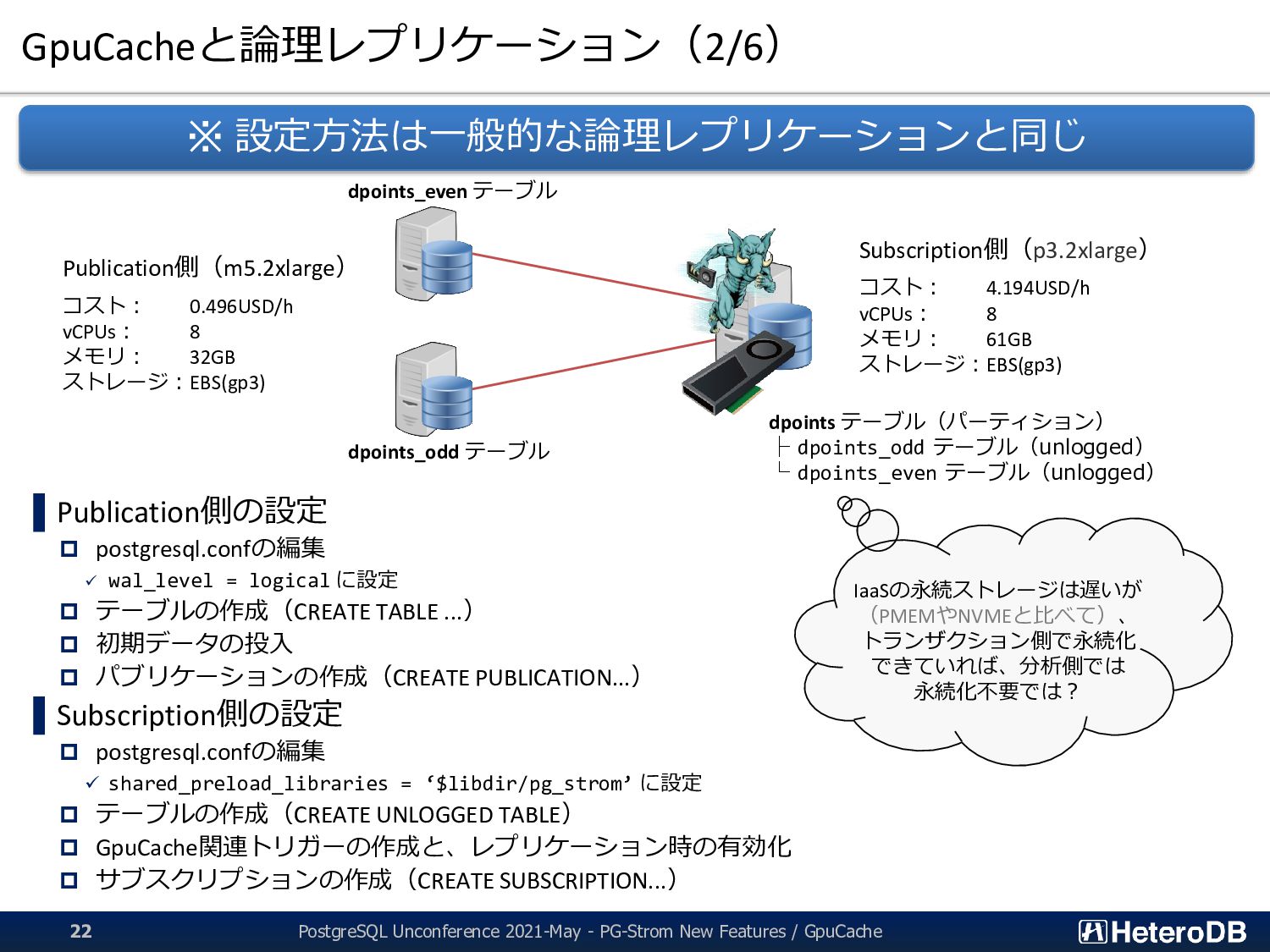
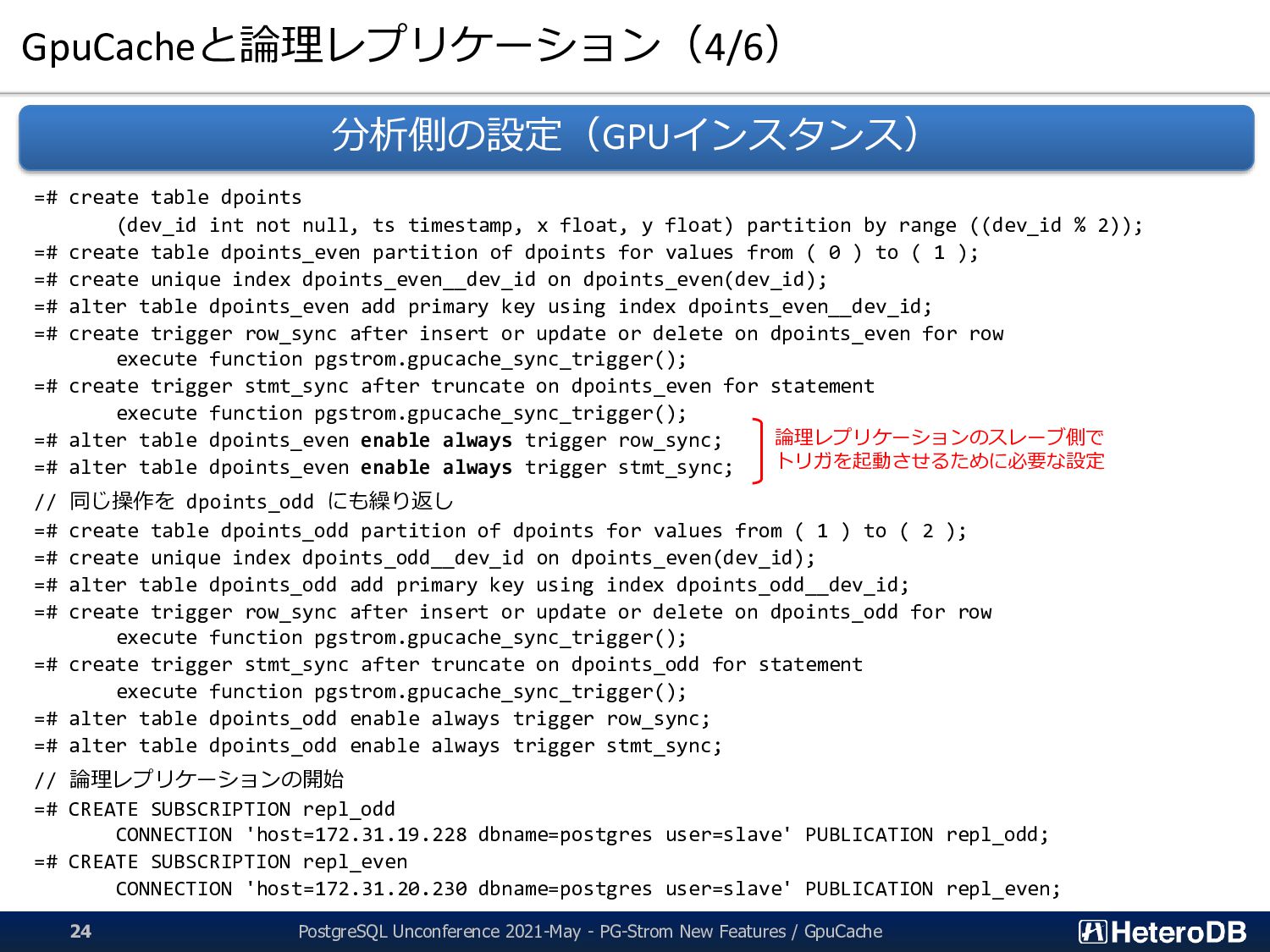
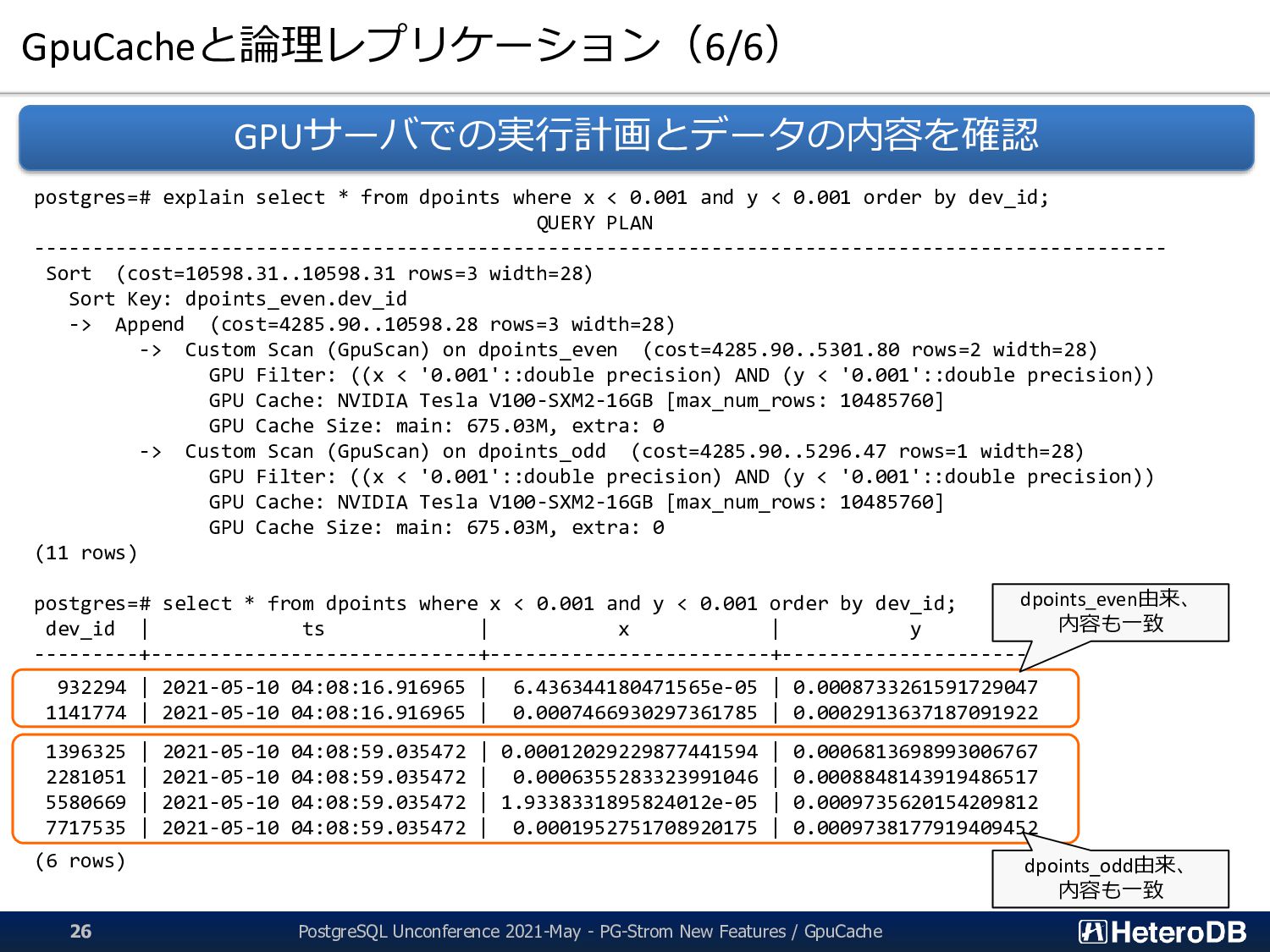
timestamp, x float, y float) partition by range ((dev_id % 2)); =# create table dpoints_even partition of dpoints for values from ( 0 ) to ( 1 ); =# create unique index dpoints_even__dev_id on dpoints_even(dev_id); =# alter table dpoints_even add primary key using index dpoints_even__dev_id; =# create trigger row_sync after insert or update or delete on dpoints_even for row execute function pgstrom.gpucache_sync_trigger(); =# create trigger stmt_sync after truncate on dpoints_even for statement execute function pgstrom.gpucache_sync_trigger(); =# alter table dpoints_even enable always trigger row_sync; =# alter table dpoints_even enable always trigger stmt_sync; // 同じ操作を dpoints_odd にも繰り返し =# create table dpoints_odd partition of dpoints for values from ( 1 ) to ( 2 ); =# create unique index dpoints_odd__dev_id on dpoints_even(dev_id); =# alter table dpoints_odd add primary key using index dpoints_odd__dev_id; =# create trigger row_sync after insert or update or delete on dpoints_odd for row execute function pgstrom.gpucache_sync_trigger(); =# create trigger stmt_sync after truncate on dpoints_odd for statement execute function pgstrom.gpucache_sync_trigger(); =# alter table dpoints_odd enable always trigger row_sync; =# alter table dpoints_odd enable always trigger stmt_sync; // 論理レプリケーションの開始 =# CREATE SUBSCRIPTION repl_odd CONNECTION 'host=172.31.19.228 dbname=postgres user=slave' PUBLICATION repl_odd; =# CREATE SUBSCRIPTION repl_even CONNECTION 'host=172.31.20.230 dbname=postgres user=slave' PUBLICATION repl_even; 分析側の設定(GPUインスタンス) 論理レプリケーションのスレーブ側で トリガを起動させるために必要な設定 PostgreSQL Unconference 2021-May - PG-Strom New Features / GpuCache 24
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}