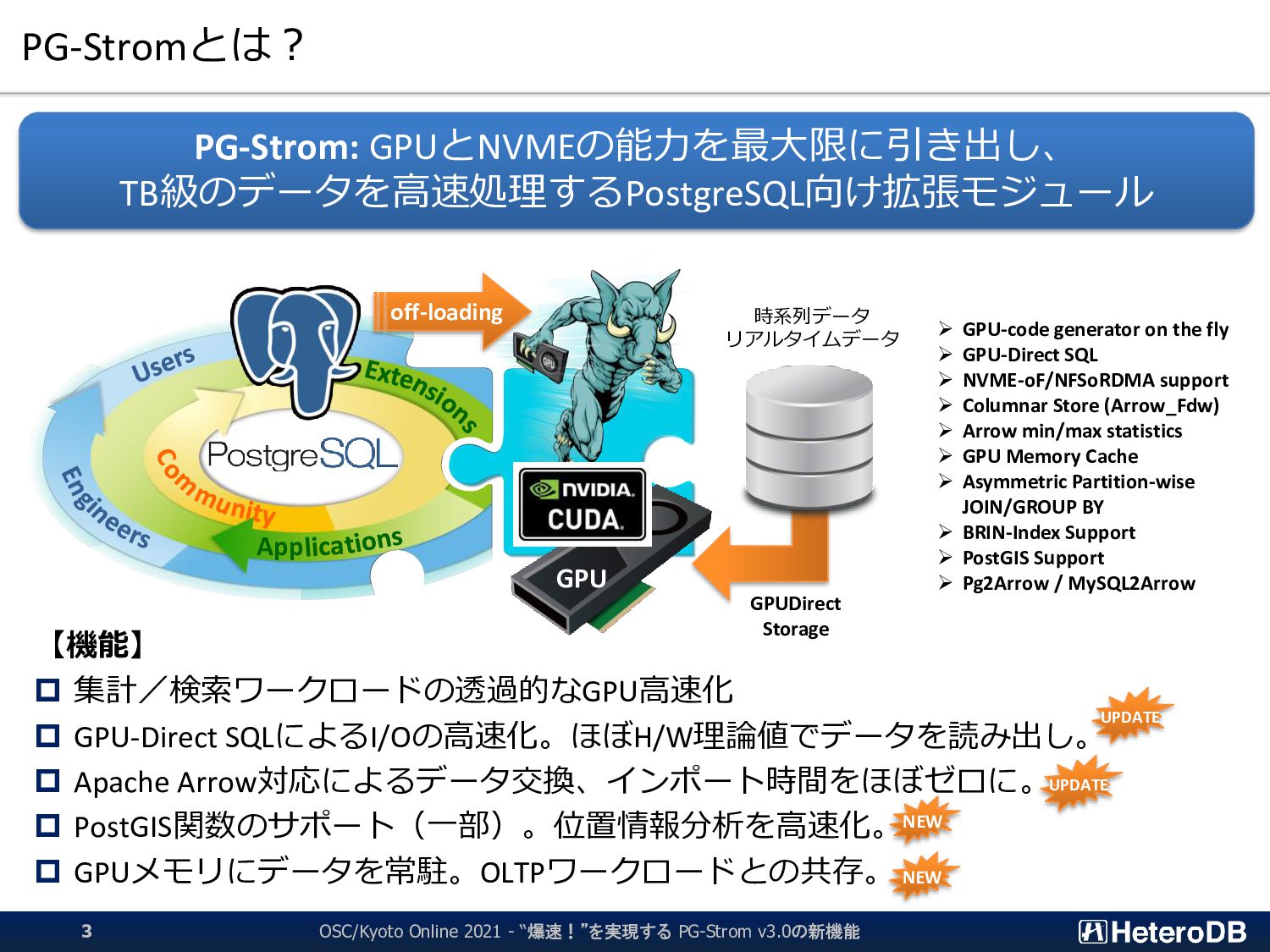
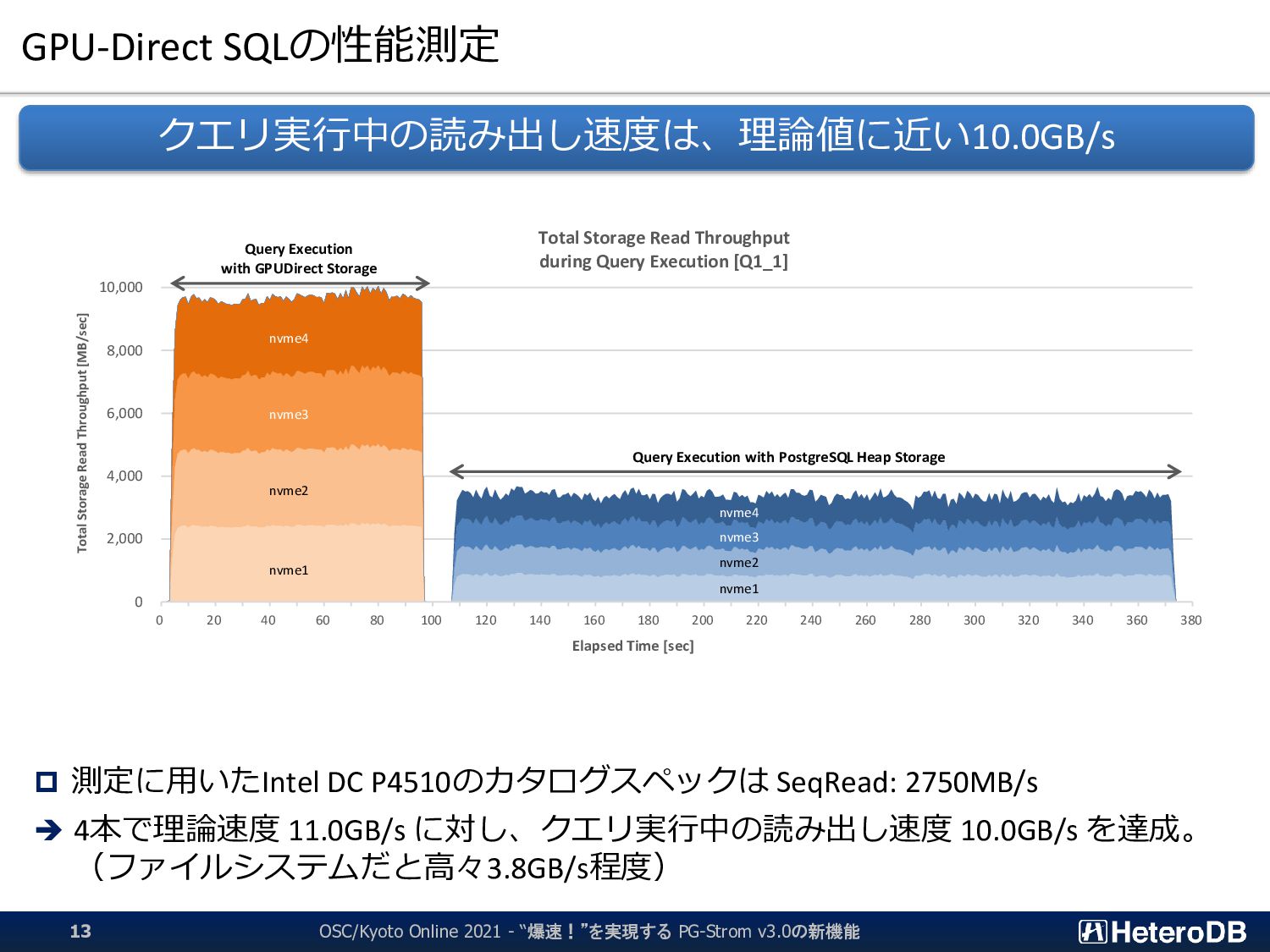
SSD-to-GPU Direct SQLの場合、ハードウェア限界(8.5GB/s)に近い性能を記録 CPU+Filesystemベースの構成と比べて約3倍強の高速化 ➔ 従来のDWH専用機並みの性能を、1Uサーバ上のPostgreSQLで実現 OSC/Kyoto Online 2021 - “爆速!”を実現する PG-Strom v3.0の新機能 10 2,443 2,406 2,400 2,348 2,325 2,337 2,346 2,383 2,355 2,356 2,327 2,333 2,313 8,252 8,266 8,266 8,154 8,158 8,186 7,933 8,094 8,240 8,225 7,975 7,969 8,107 0 1,000 2,000 3,000 4,000 5,000 6,000 7,000 8,000 9,000 Q1_1 Q1_2 Q1_3 Q2_1 Q2_2 Q2_3 Q3_1 Q3_2 Q3_3 Q3_4 Q4_1 Q4_2 Q4_3 Query Execution Throughput [MB/s] Star Schema Benchmark (s=1000, DBsize: 879GB) on Tesla V100 x1 + DC P4600 x3 PostgreSQL 11.5 PG-Strom 2.2 (Row data)
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![背景:SSD-to-GPUダイレクトSQL(2/2) クエリ実行スループット = (879GB DB-size) / (クエリ応答時間 [sec]) ](https://files.speakerdeck.com/presentations/fa3186d4b61c4cd4931a983d8acb3856/slide_9.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
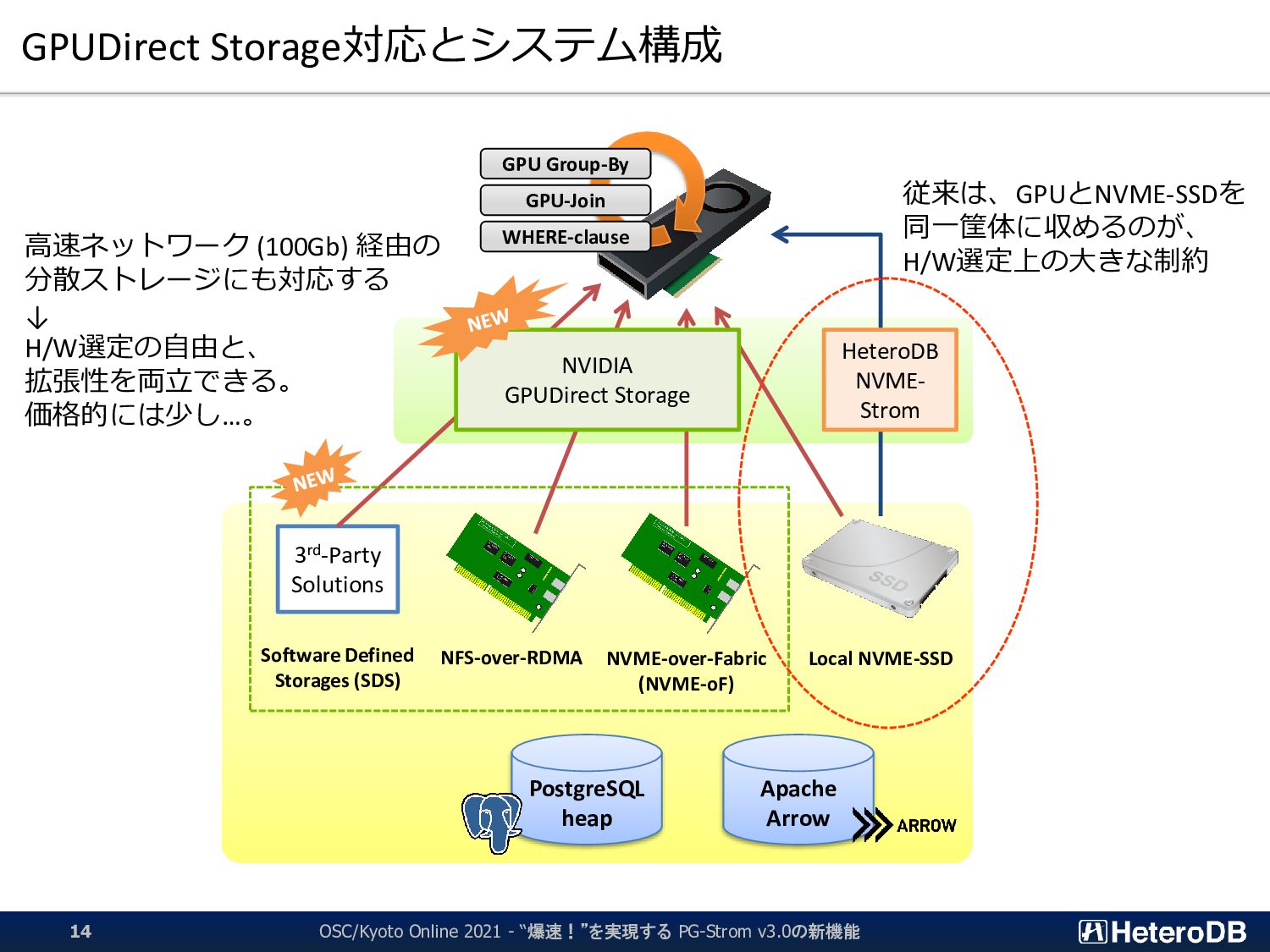{kind=link}
{kind=link}
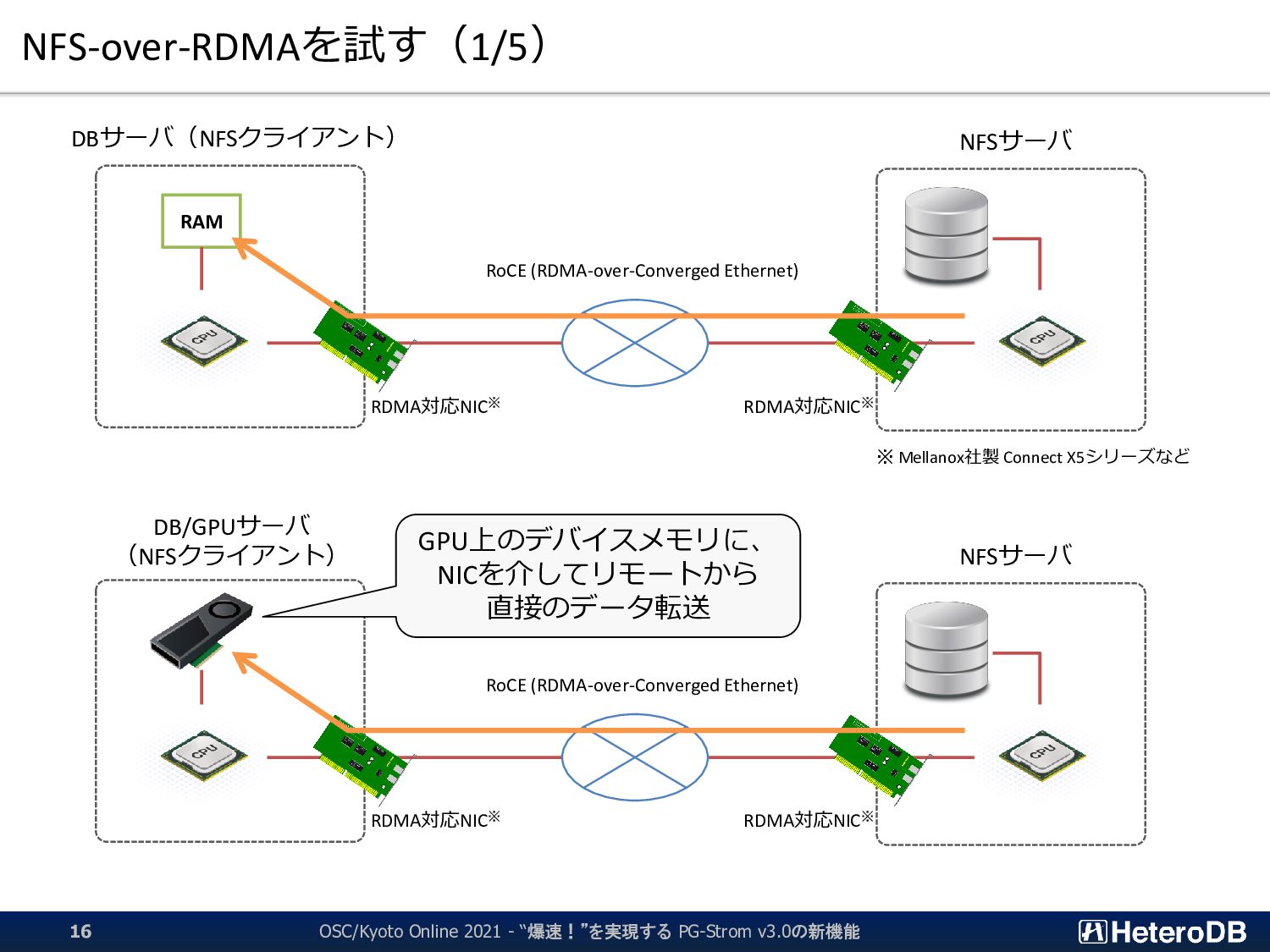{kind=link}
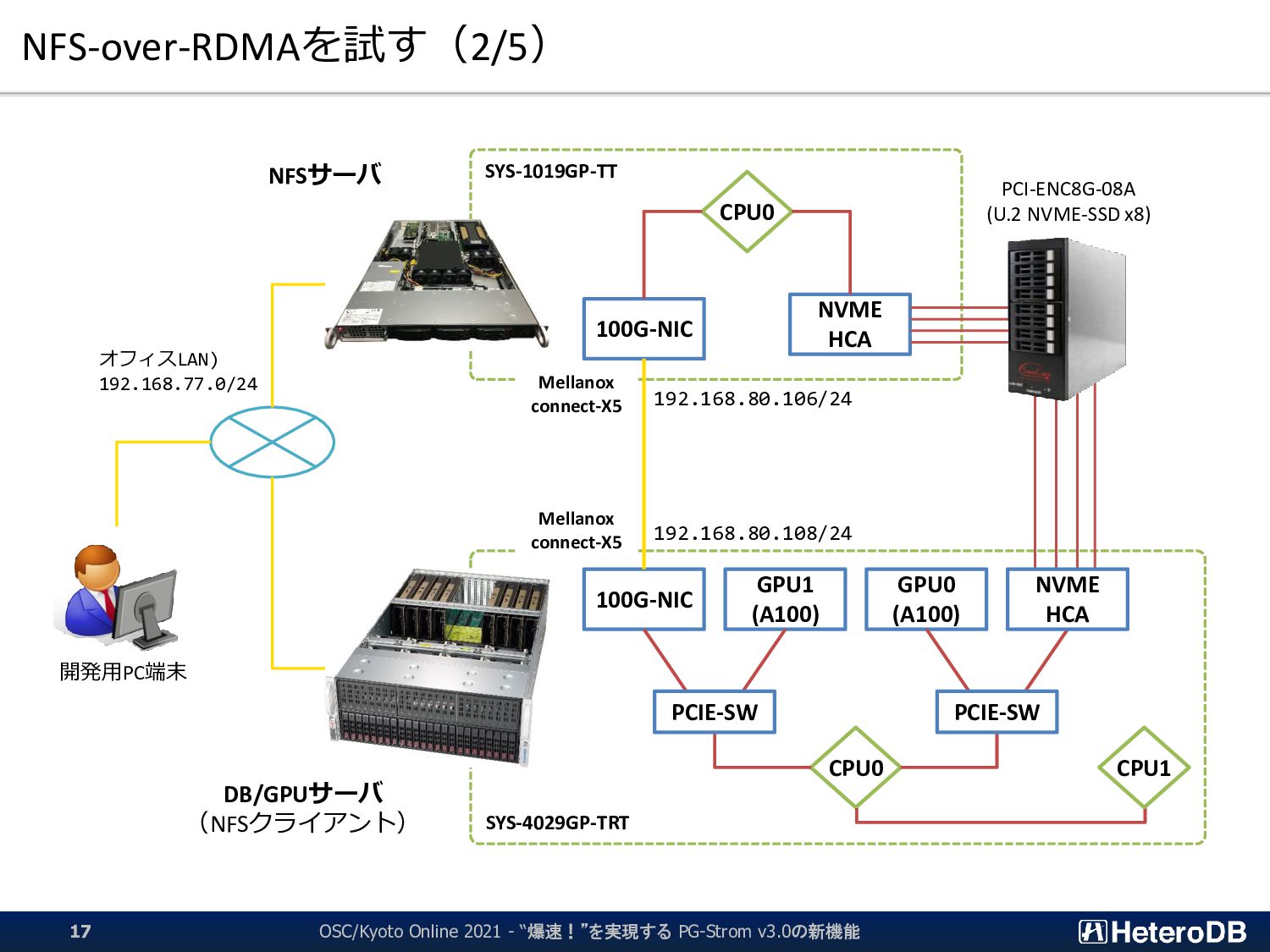{kind=link}
{kind=link}
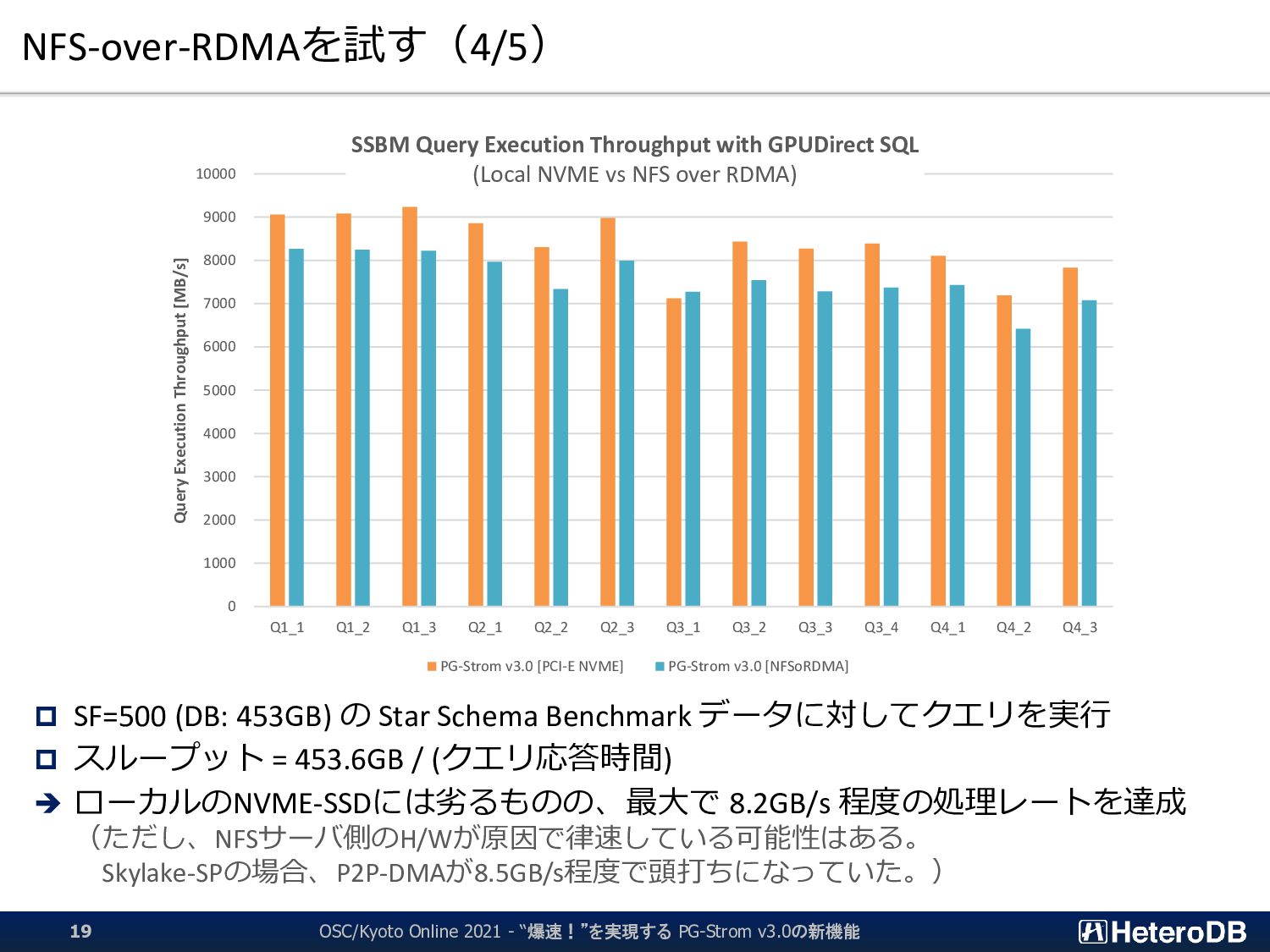{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
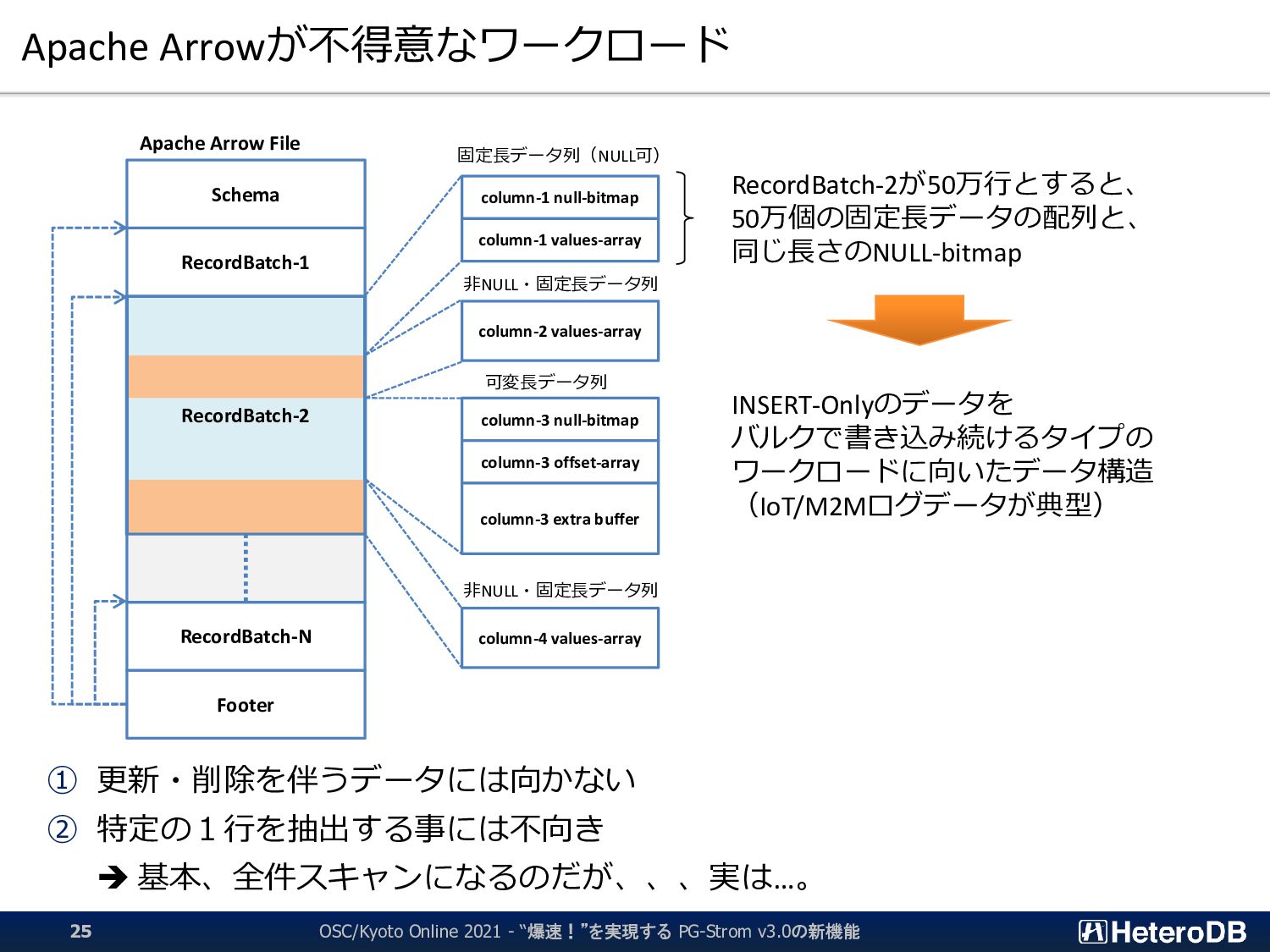{kind=link}
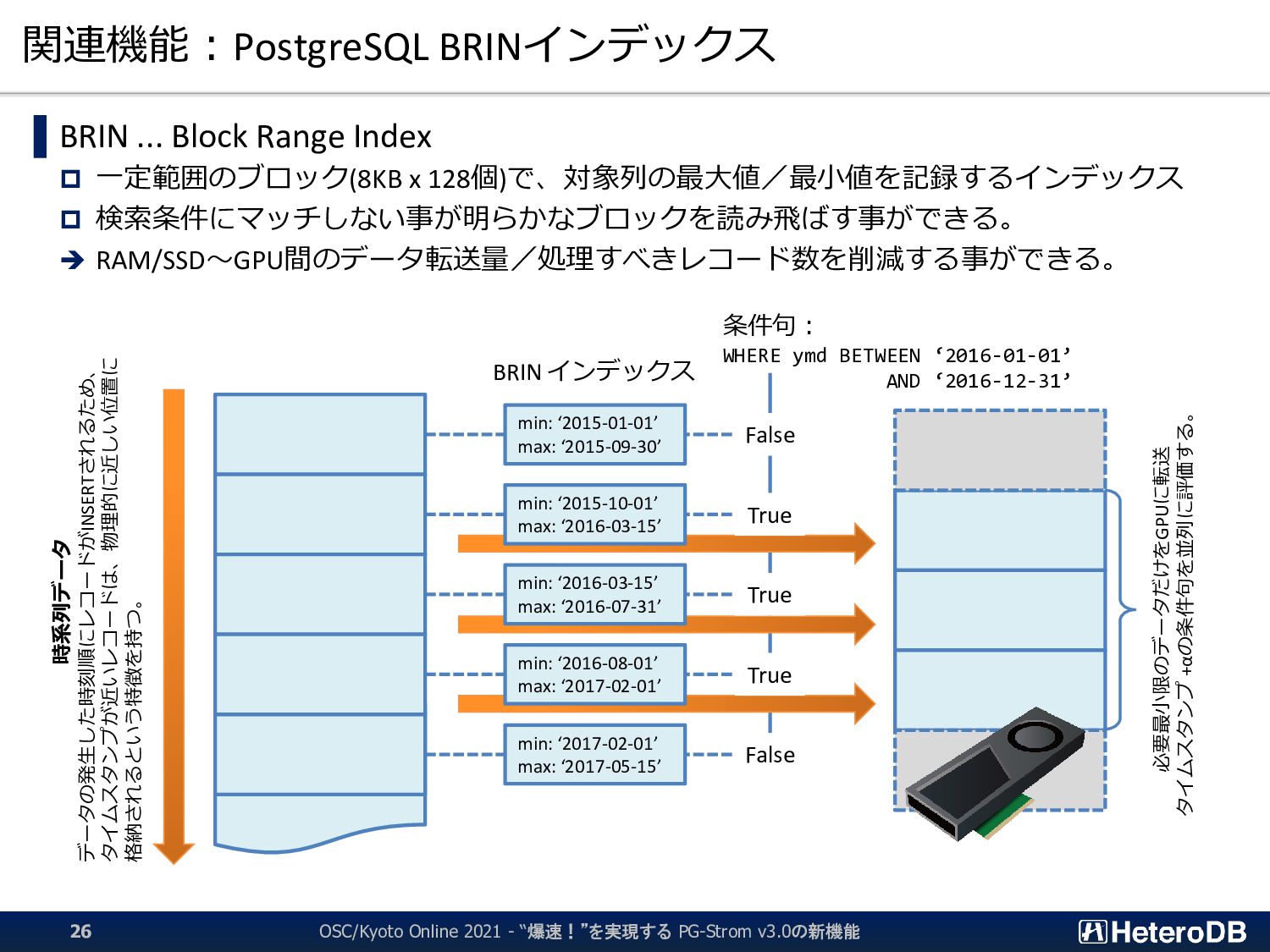{kind=link}
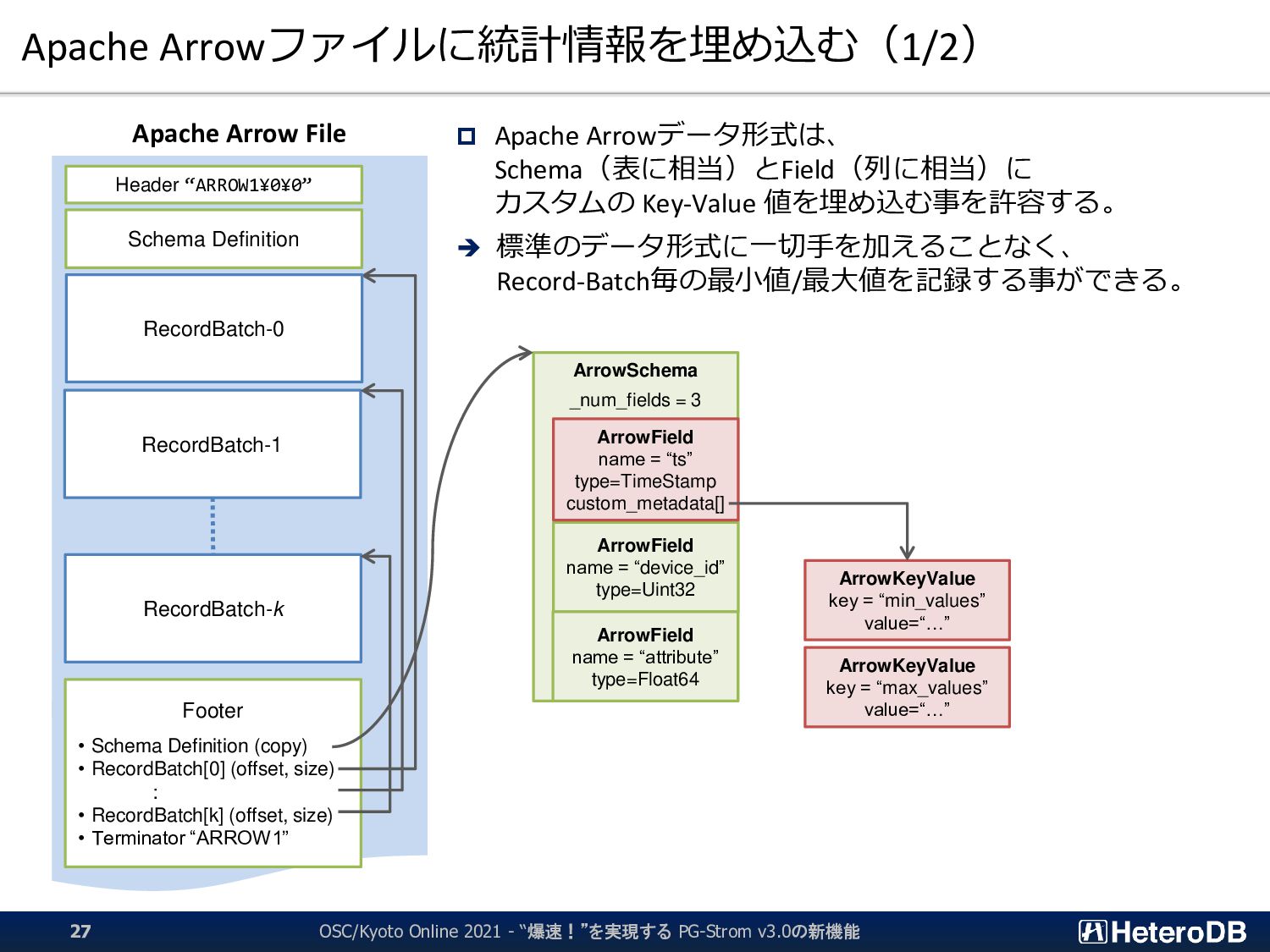{kind=link}
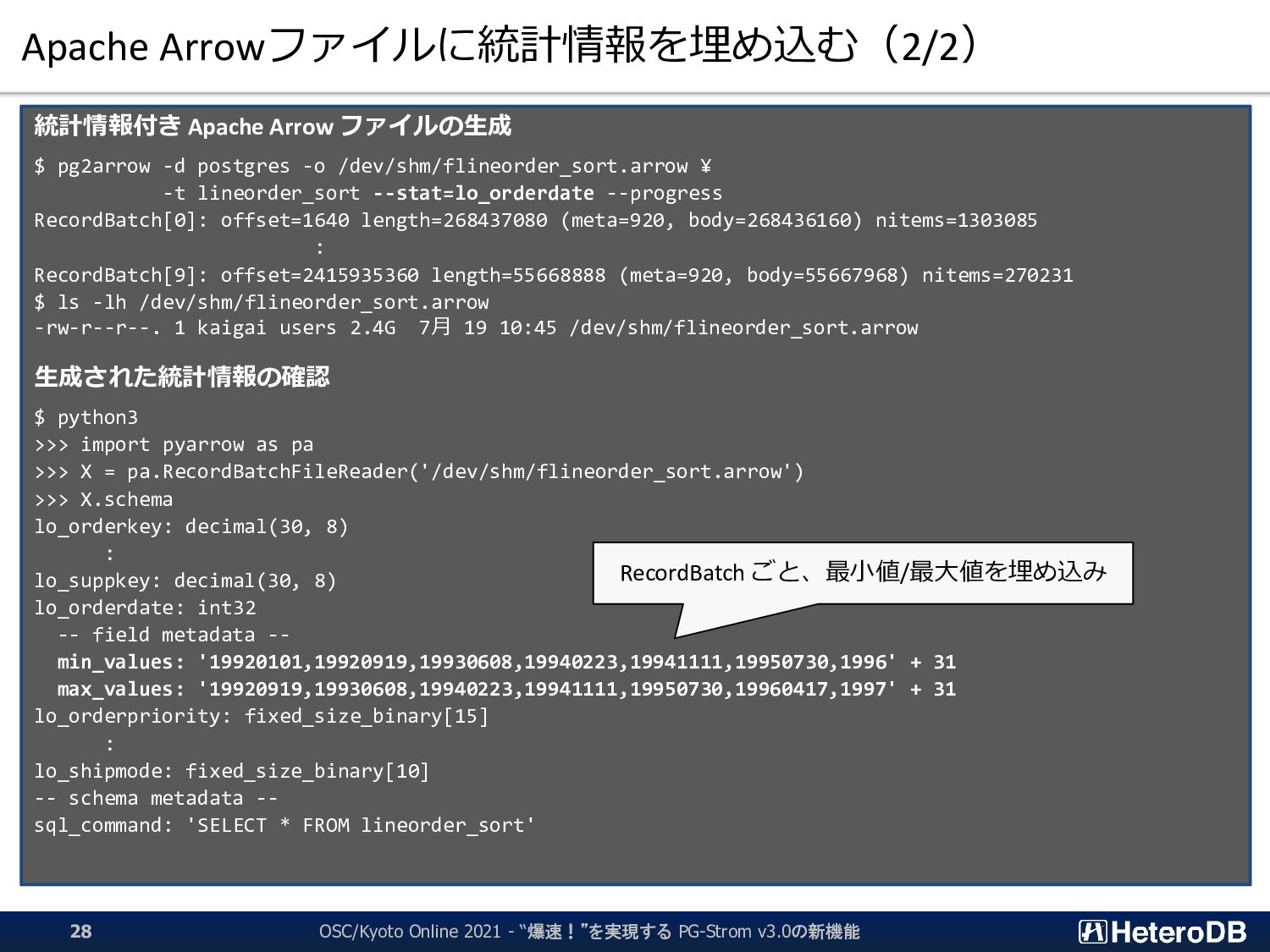{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
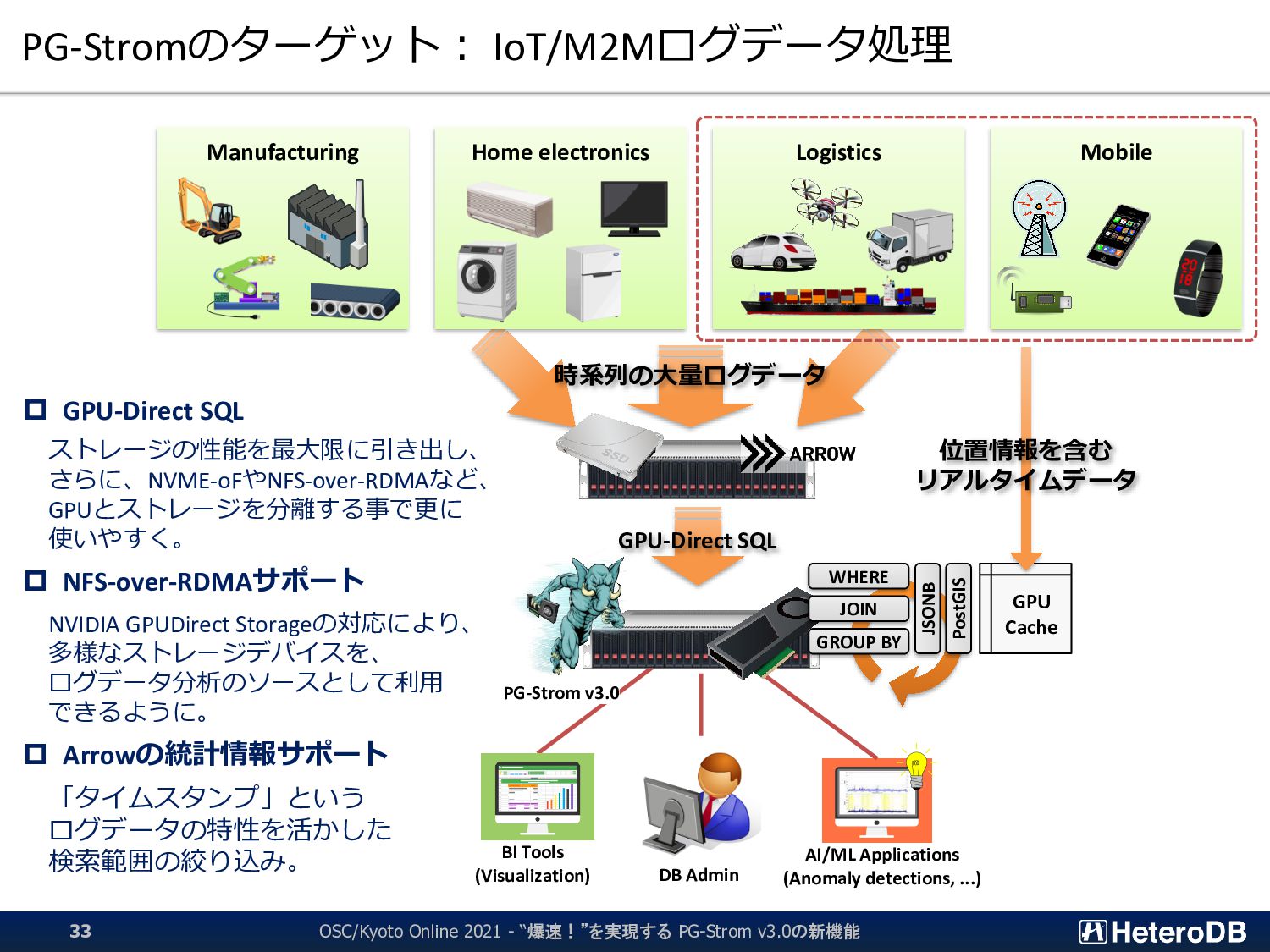{kind=link}
{kind=link}
{kind=link}
{kind=link}