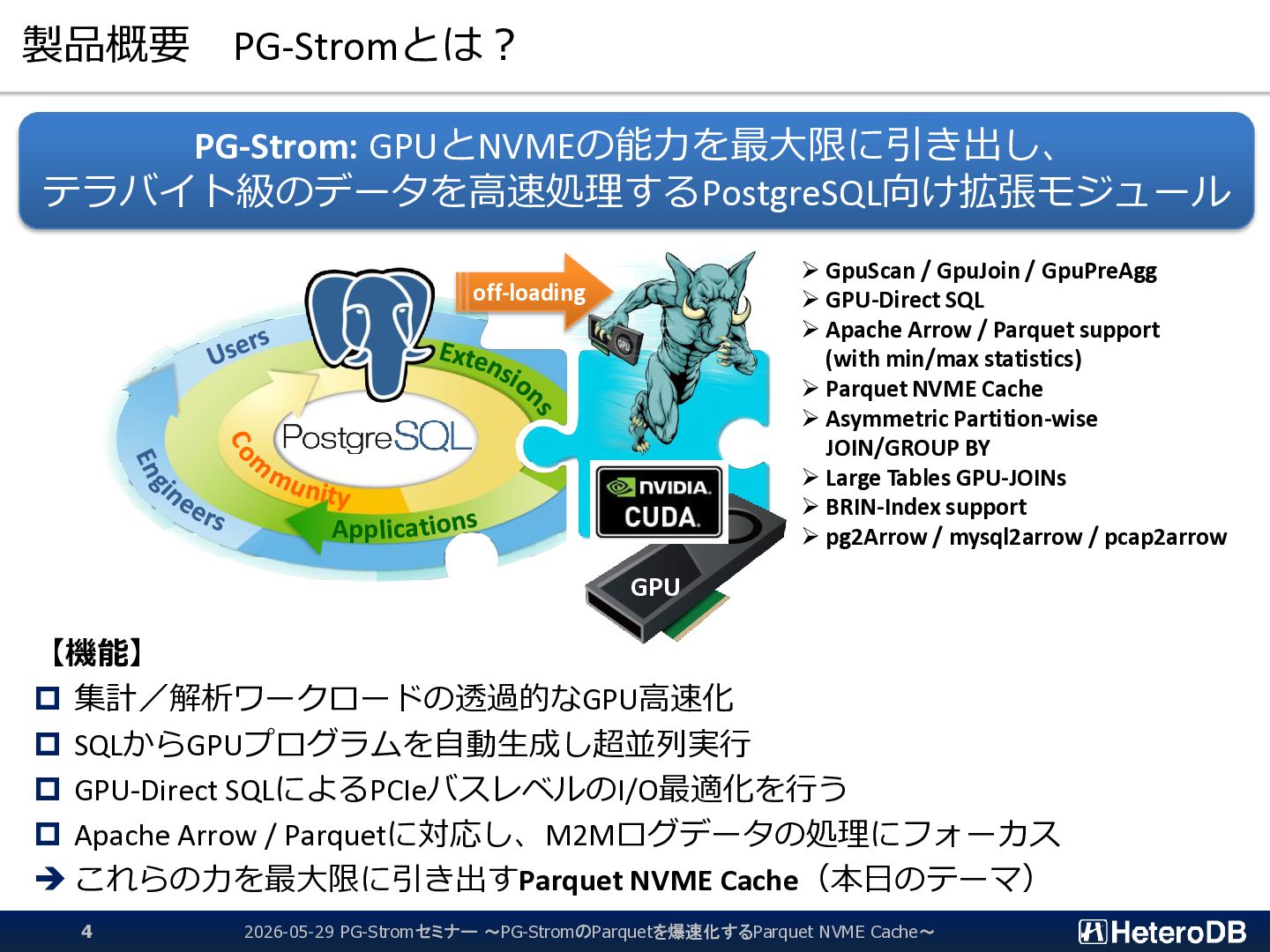
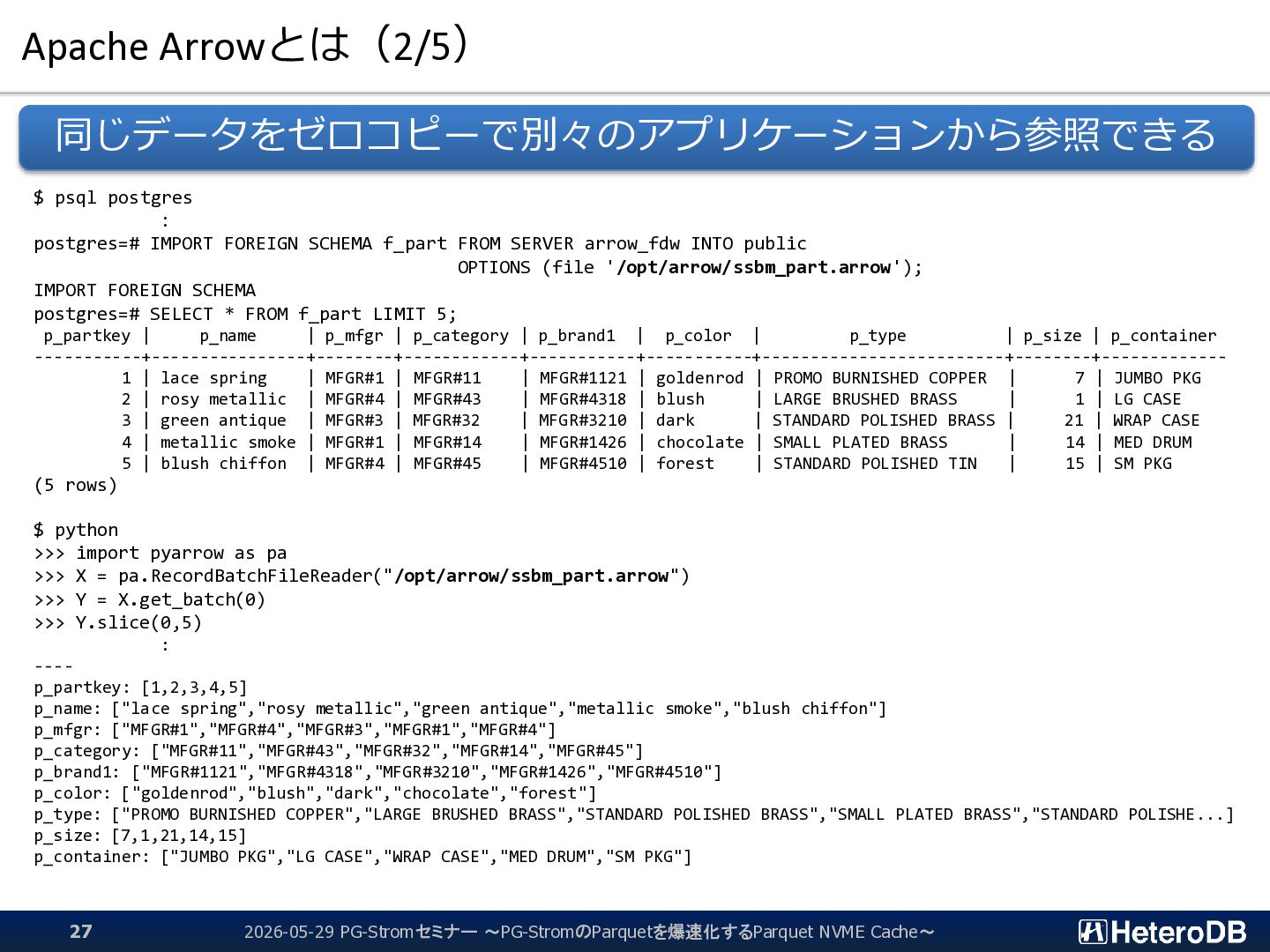
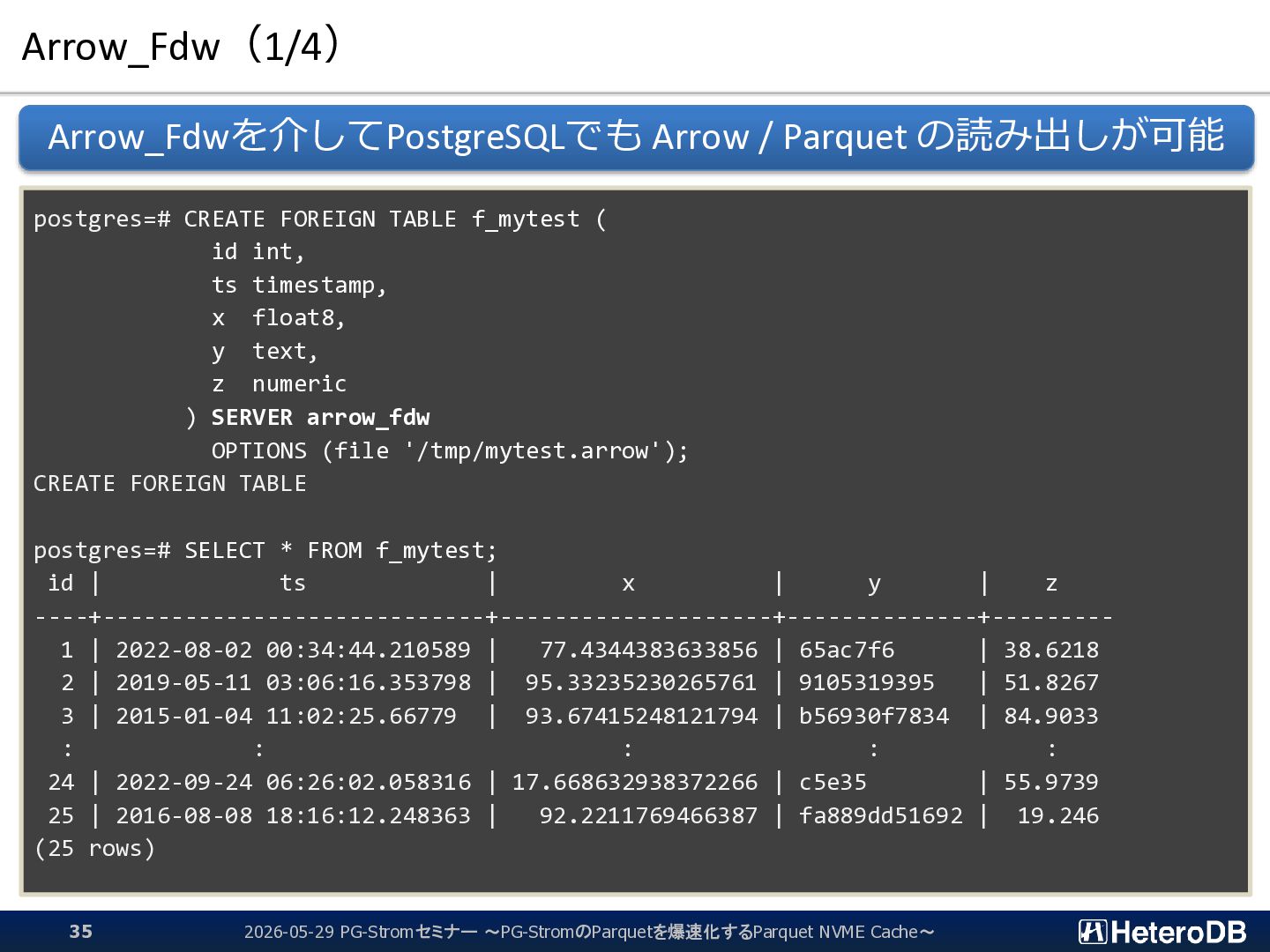
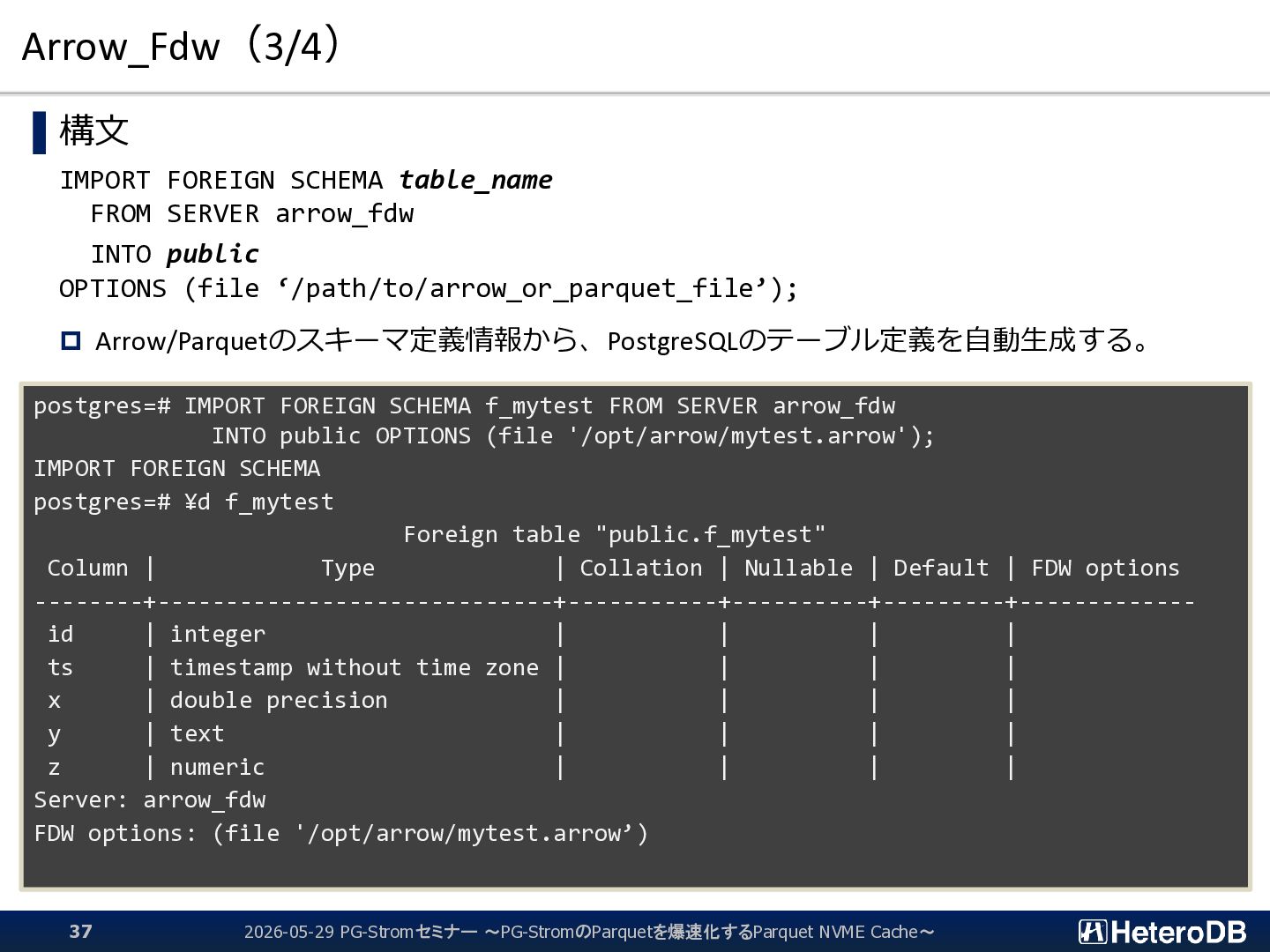
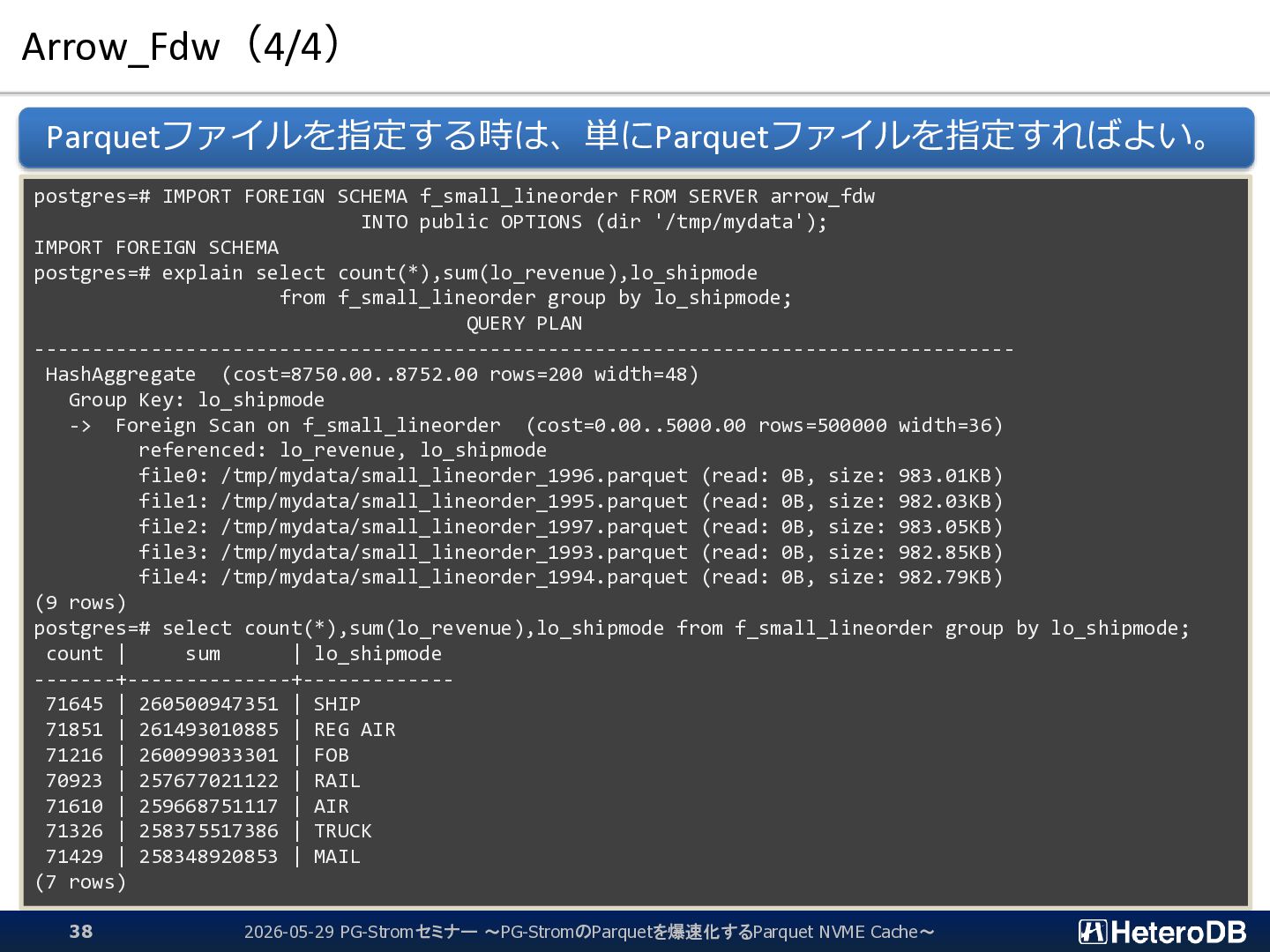
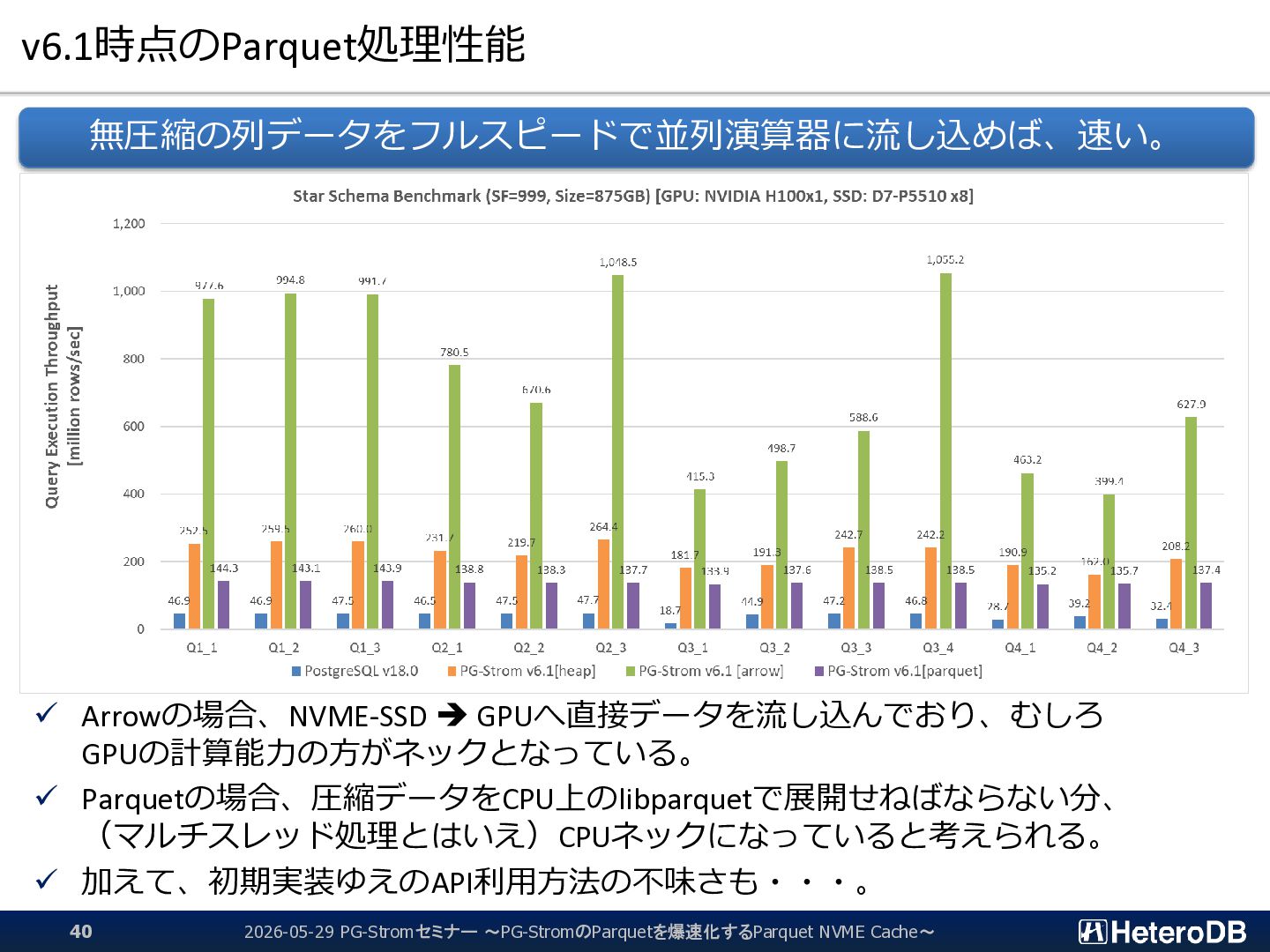
f_part FROM SERVER arrow_fdw INTO public OPTIONS (file '/opt/arrow/ssbm_part.arrow'); IMPORT FOREIGN SCHEMA postgres=# SELECT * FROM f_part LIMIT 5; p_partkey | p_name | p_mfgr | p_category | p_brand1 | p_color | p_type | p_size | p_container -----------+----------------+--------+------------+-----------+-----------+-------------------------+--------+------------- 1 | lace spring | MFGR#1 | MFGR#11 | MFGR#1121 | goldenrod | PROMO BURNISHED COPPER | 7 | JUMBO PKG 2 | rosy metallic | MFGR#4 | MFGR#43 | MFGR#4318 | blush | LARGE BRUSHED BRASS | 1 | LG CASE 3 | green antique | MFGR#3 | MFGR#32 | MFGR#3210 | dark | STANDARD POLISHED BRASS | 21 | WRAP CASE 4 | metallic smoke | MFGR#1 | MFGR#14 | MFGR#1426 | chocolate | SMALL PLATED BRASS | 14 | MED DRUM 5 | blush chiffon | MFGR#4 | MFGR#45 | MFGR#4510 | forest | STANDARD POLISHED TIN | 15 | SM PKG (5 rows) $ python >>> import pyarrow as pa >>> X = pa.RecordBatchFileReader("/opt/arrow/ssbm_part.arrow") >>> Y = X.get_batch(0) >>> Y.slice(0,5) : ---- p_partkey: [1,2,3,4,5] p_name: ["lace spring","rosy metallic","green antique","metallic smoke","blush chiffon"] p_mfgr: ["MFGR#1","MFGR#4","MFGR#3","MFGR#1","MFGR#4"] p_category: ["MFGR#11","MFGR#43","MFGR#32","MFGR#14","MFGR#45"] p_brand1: ["MFGR#1121","MFGR#4318","MFGR#3210","MFGR#1426","MFGR#4510"] p_color: ["goldenrod","blush","dark","chocolate","forest"] p_type: ["PROMO BURNISHED COPPER","LARGE BRUSHED BRASS","STANDARD POLISHED BRASS","SMALL PLATED BRASS","STANDARD POLISHE...] p_size: [7,1,21,14,15] p_container: ["JUMBO PKG","LG CASE","WRAP CASE","MED DRUM","SM PKG"] 同じデータをゼロコピーで別々のアプリケーションから参照できる 2026-05-29 PG-Stromセミナー ~PG-StromのParquetを爆速化するParquet NVME Cache~ 27
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Apache Arrowとは(4/5) 補足:可変長データについて B[0] = ‘dog’ B[1] = ‘panda’ B[2]](https://files.speakerdeck.com/presentations/4688f649120740eea0e3c2b099d552d2/slide_28.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
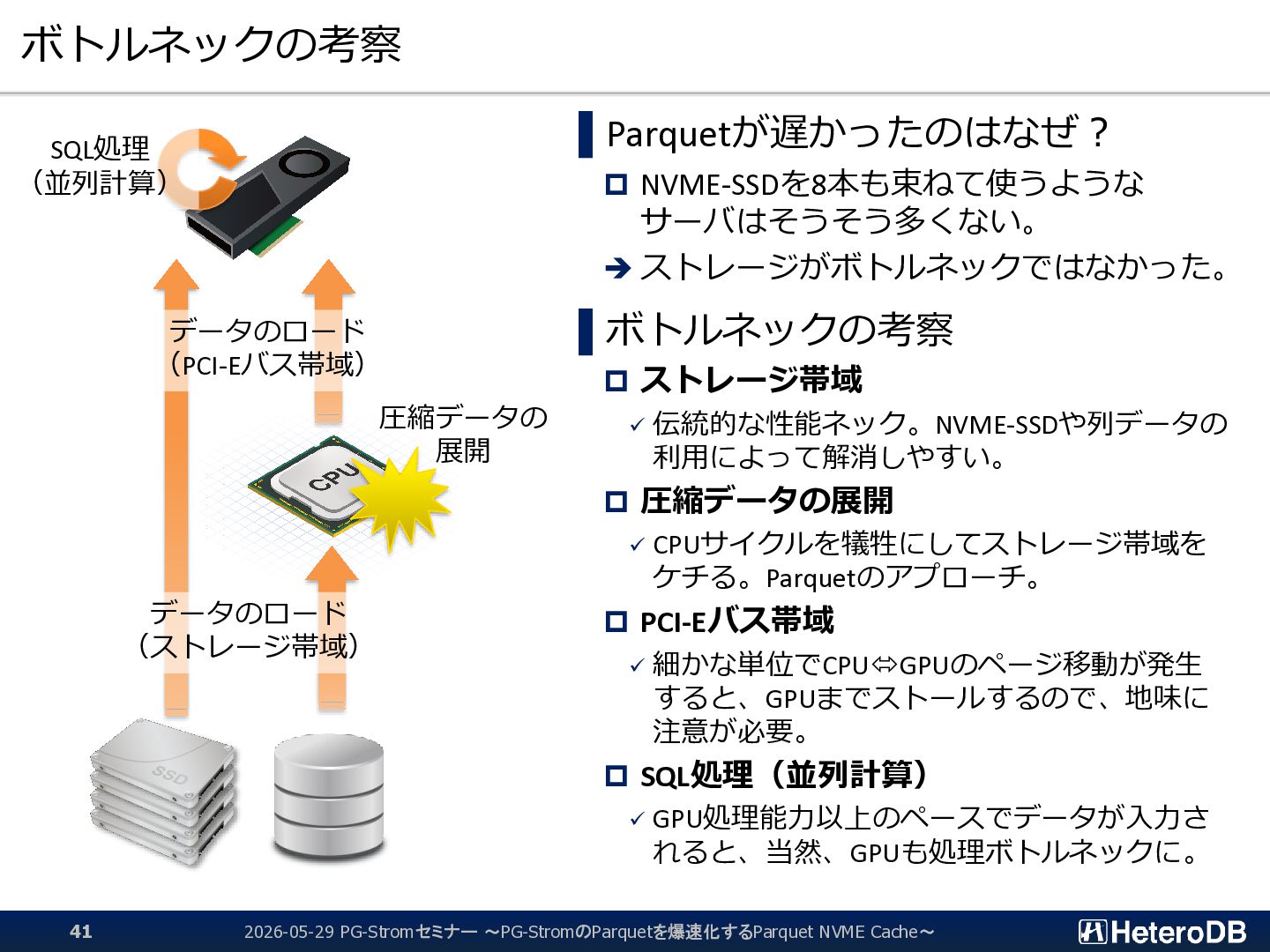{kind=link}
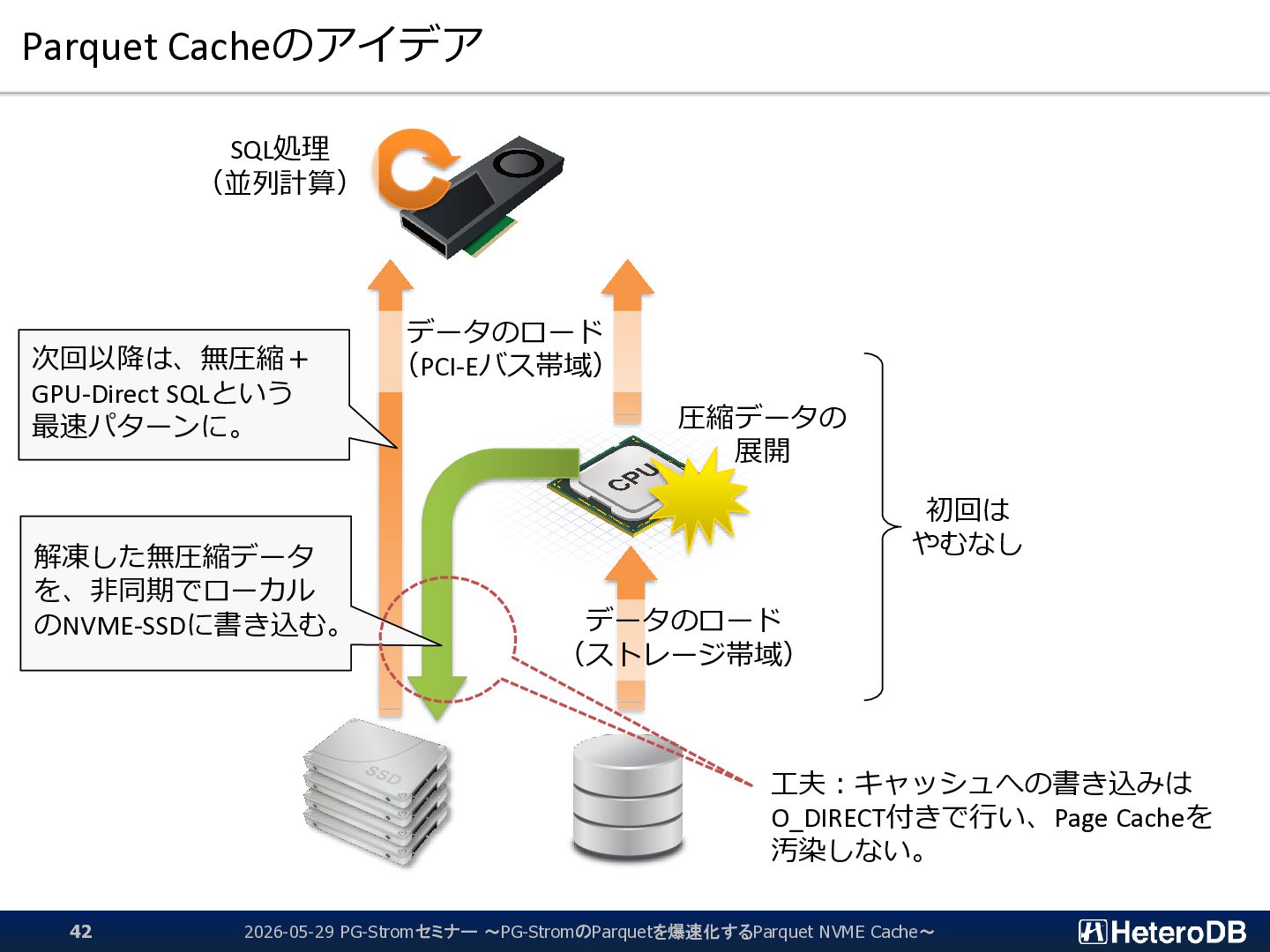{kind=link}
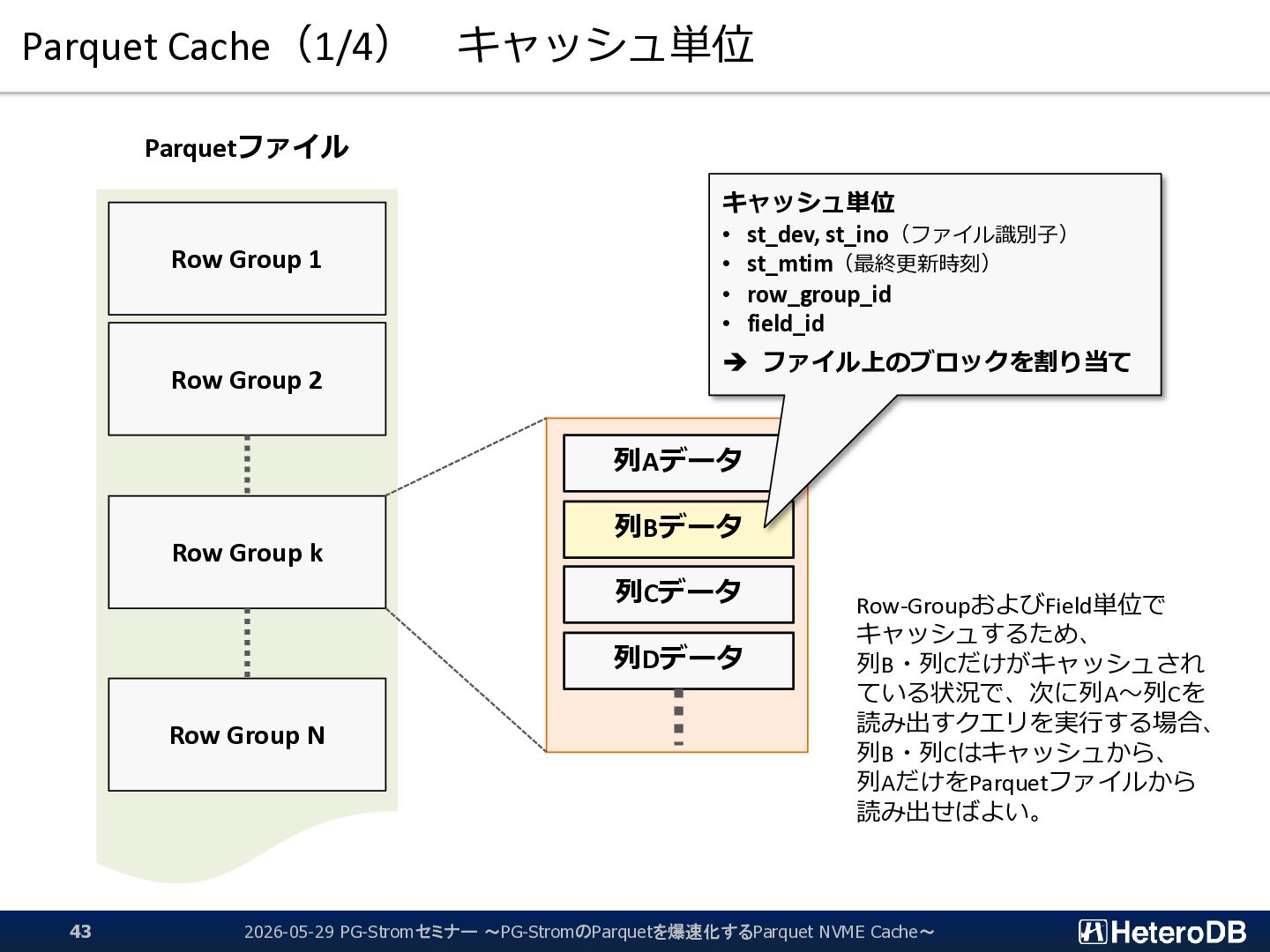{kind=link}
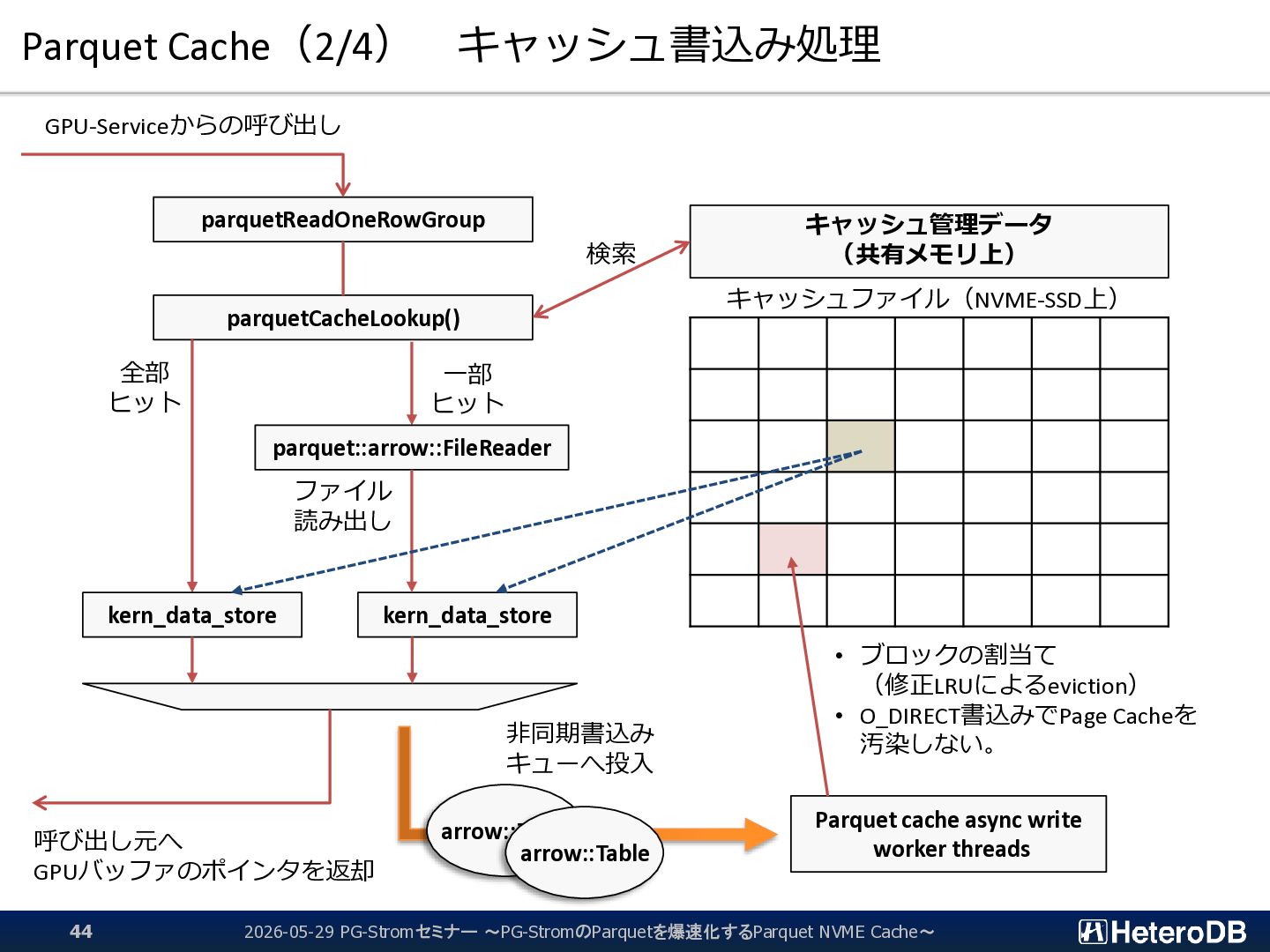{kind=link}
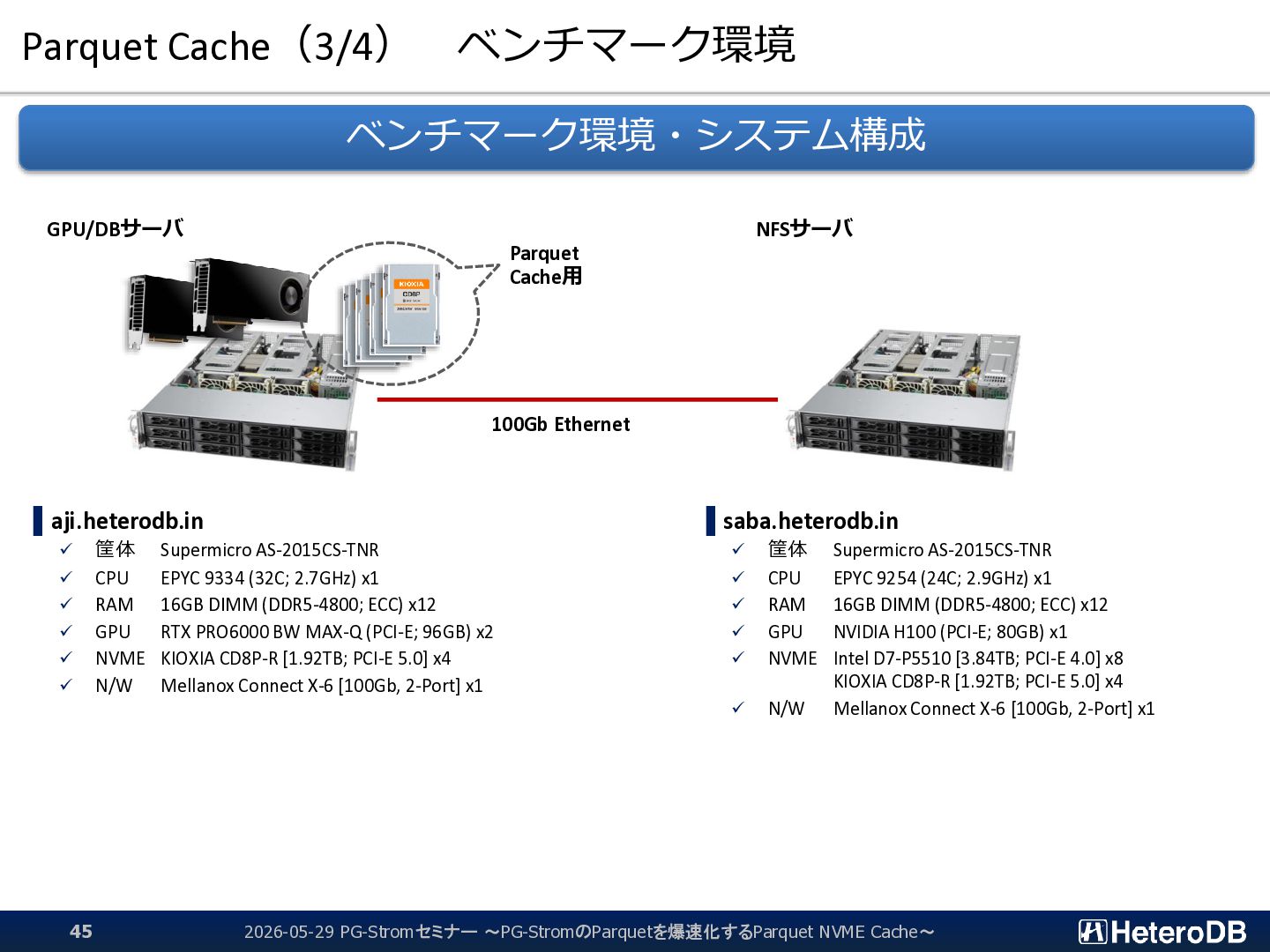{kind=link}
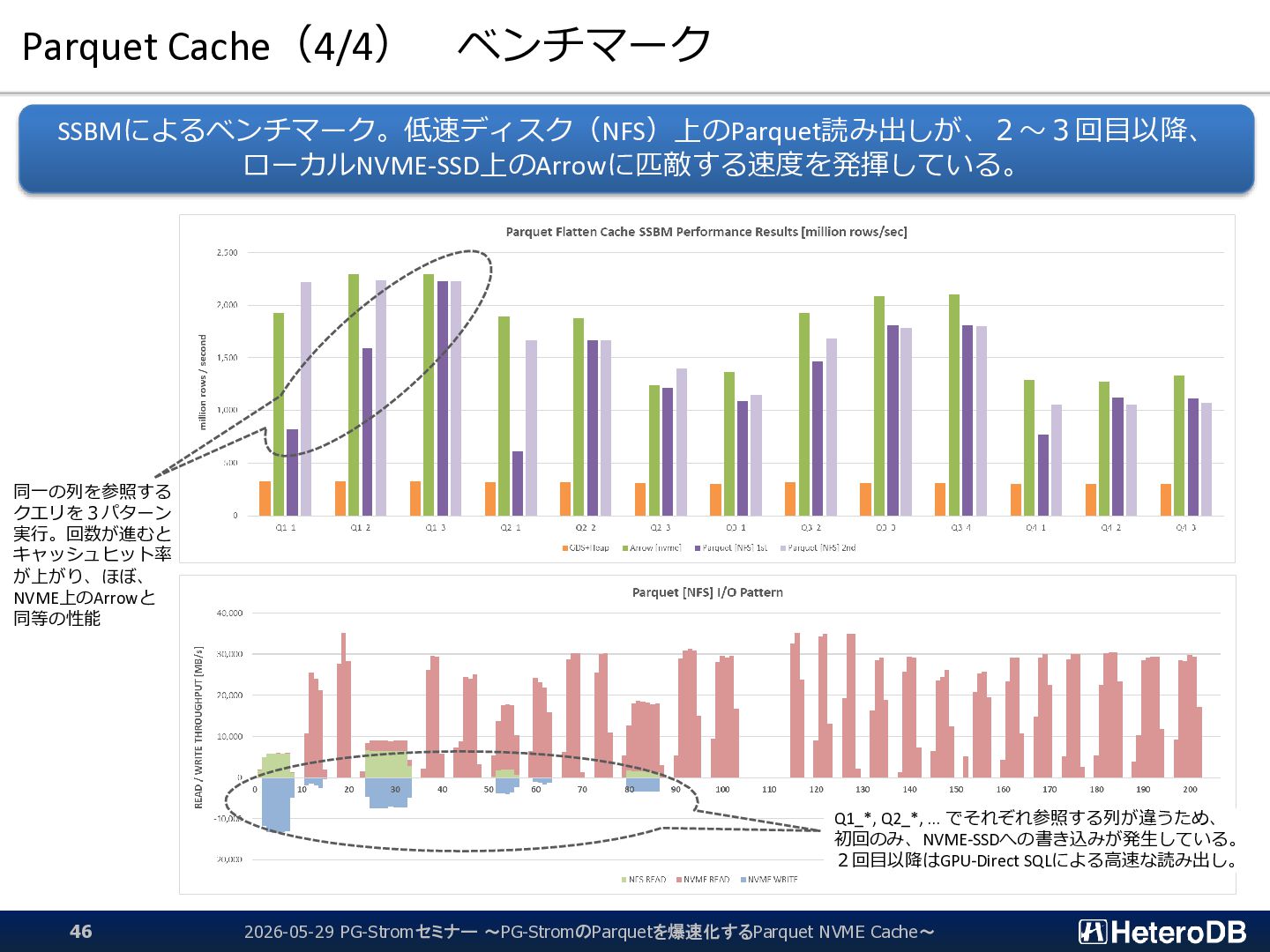{kind=link}
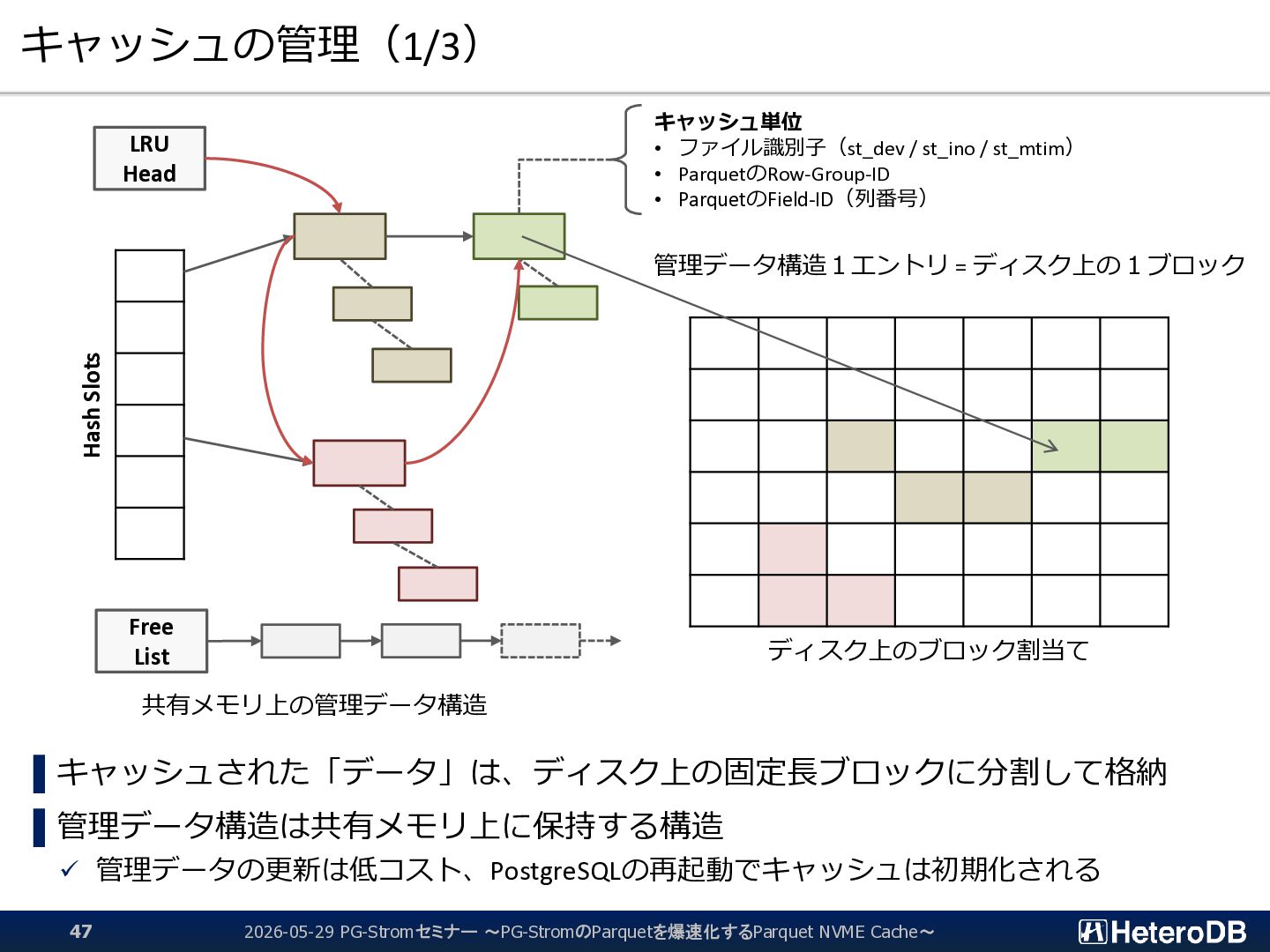{kind=link}
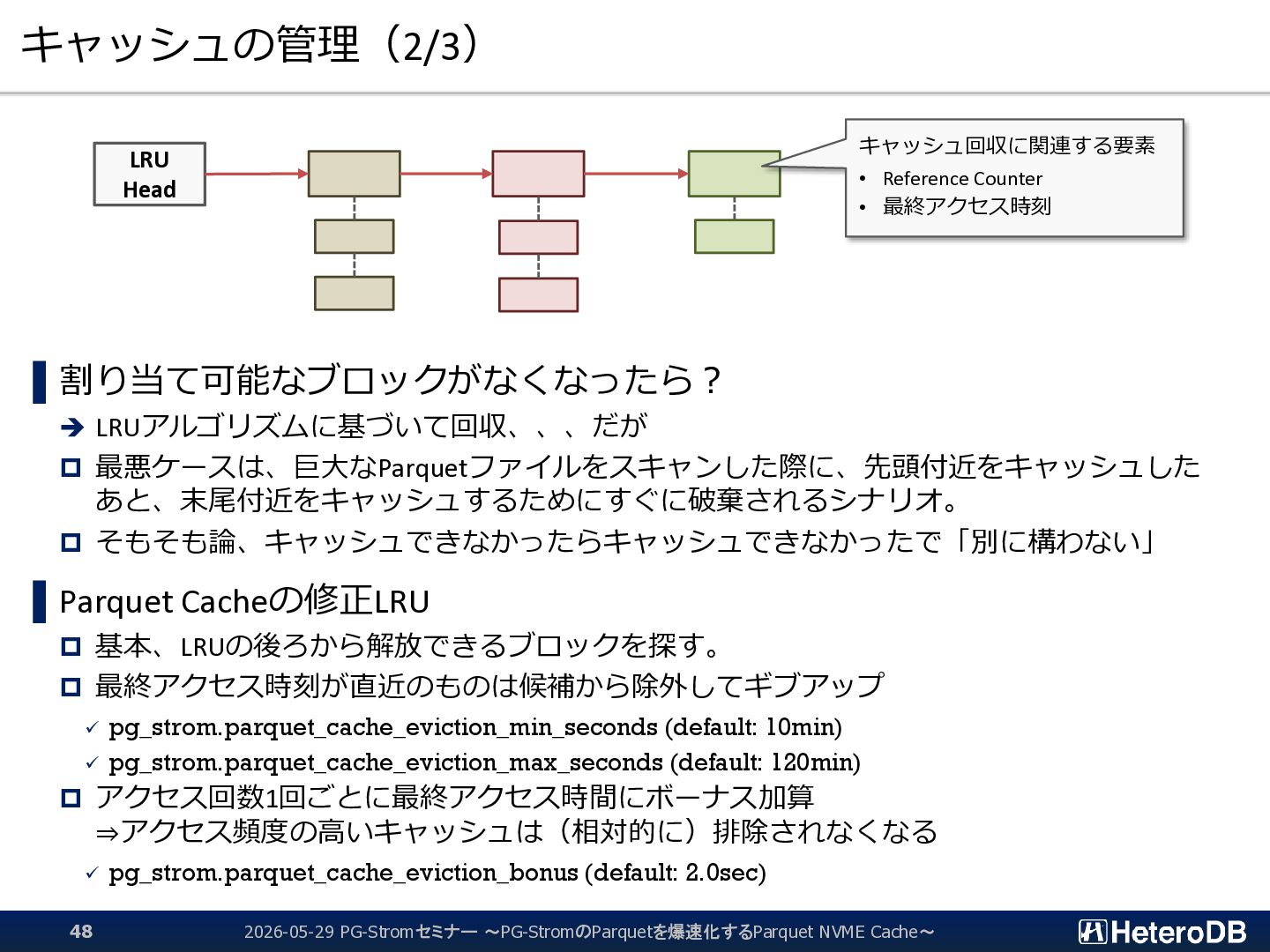{kind=link}
![キャッシュの管理(3/3) $ pg_ctl restart : 2026-05-27 10:42:00.141 JST [2526805] LOG:](https://files.speakerdeck.com/presentations/4688f649120740eea0e3c2b099d552d2/slide_48.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}