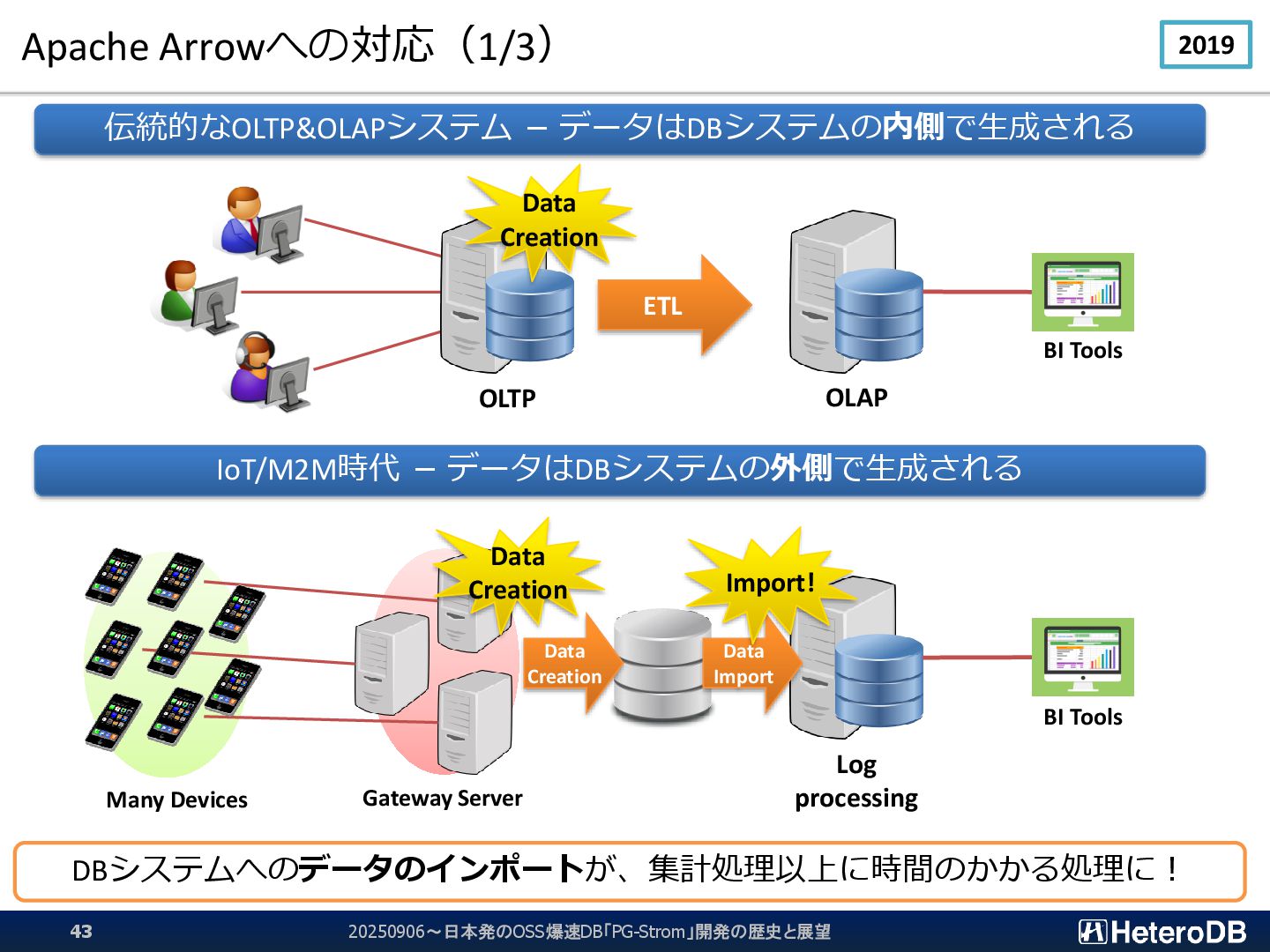
IoT/M2M時代 - データはDBシステムの外側で生成される Log processing BI Tools BI Tools Gateway Server Data Creation Data Creation Many Devices 20250906~日本発のOSS爆速DB「PG-Strom」開発の歴史と展望 43 DBシステムへのデータのインポートが、集計処理以上に時間のかかる処理に! Data Import Import! 2019
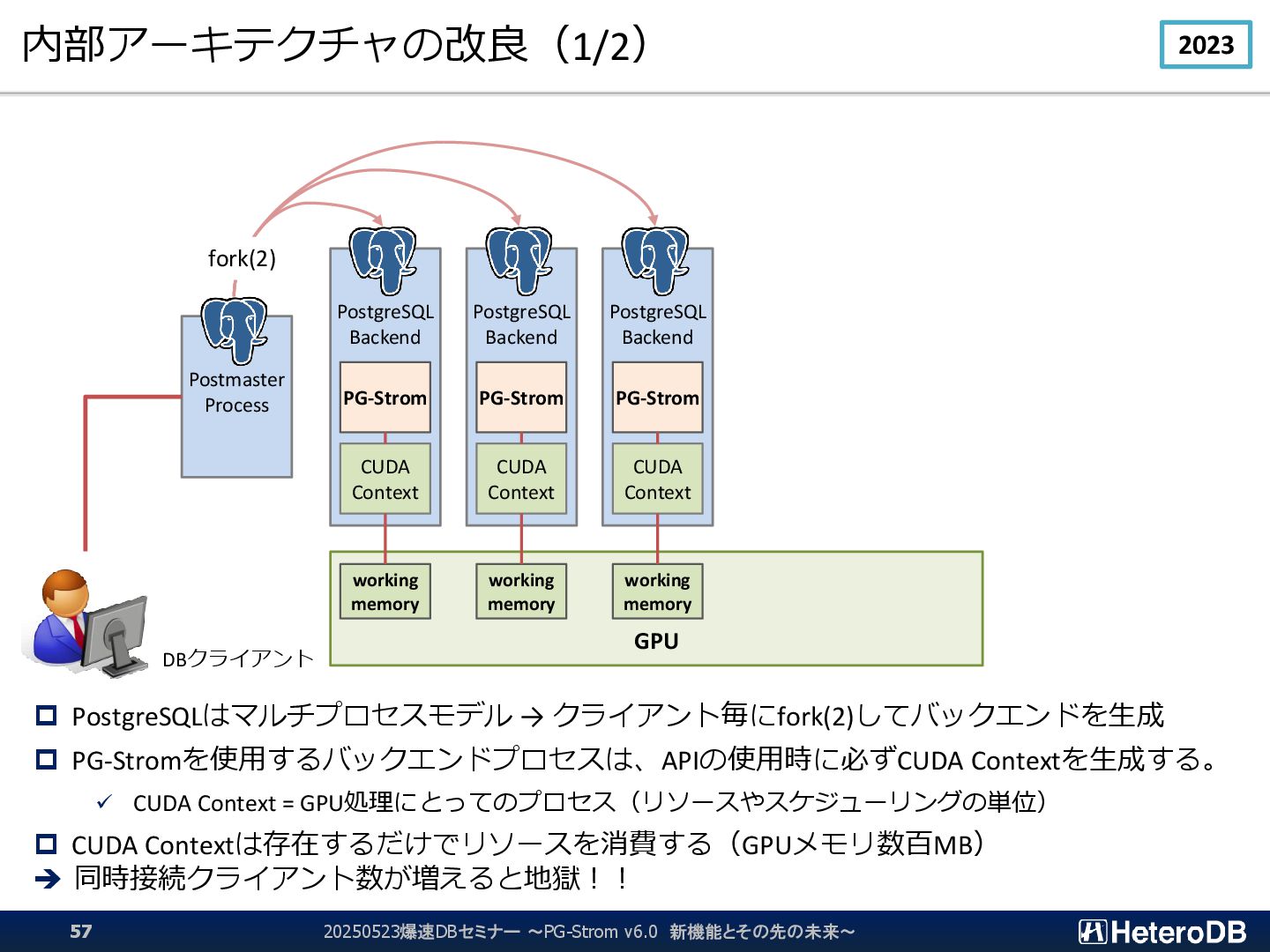
Context = GPU処理にとってのプロセス(リソースやスケジューリングの単位) CUDA Contextは存在するだけでリソースを消費する(GPUメモリ数百MB) ➔ 同時接続クライアント数が増えると地獄!! GPU PostgreSQL Backend CUDA Context PG-Strom PostgreSQL Backend CUDA Context PG-Strom PostgreSQL Backend CUDA Context PG-Strom Postmaster Process working memory working memory working memory fork(2) DBクライアント 20250523爆速DBセミナー ~PG-Strom v6.0 新機能とその先の未来~ 57 2023
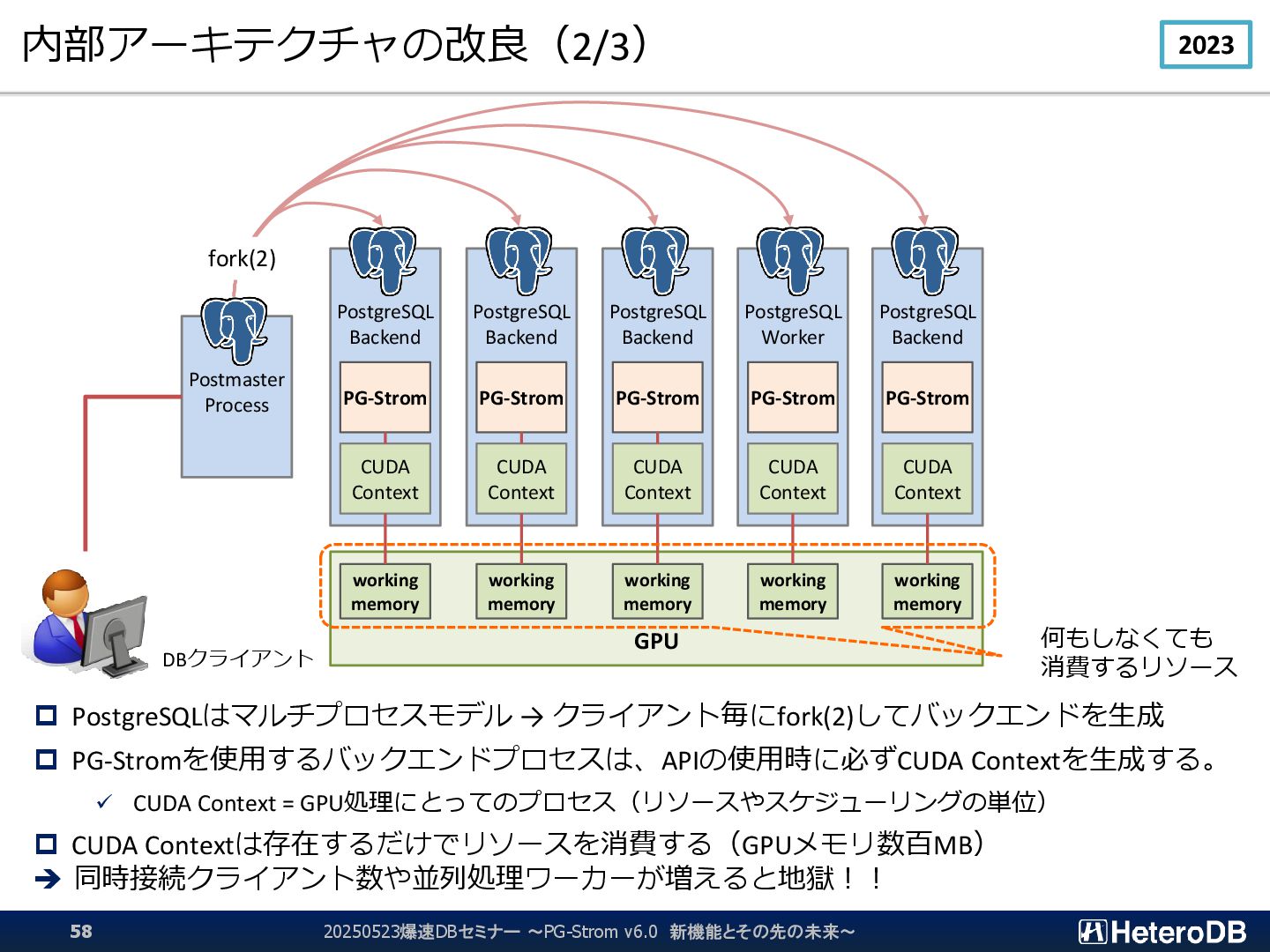
Context = GPU処理にとってのプロセス(リソースやスケジューリングの単位) CUDA Contextは存在するだけでリソースを消費する(GPUメモリ数百MB) ➔ 同時接続クライアント数や並列処理ワーカーが増えると地獄!! GPU PostgreSQL Backend CUDA Context PG-Strom PostgreSQL Backend CUDA Context PG-Strom PostgreSQL Backend CUDA Context PG-Strom Postmaster Process working memory working memory working memory PostgreSQL Worker CUDA Context PG-Strom PostgreSQL Backend CUDA Context PG-Strom working memory working memory fork(2) 何もしなくても 消費するリソース DBクライアント 20250523爆速DBセミナー ~PG-Strom v6.0 新機能とその先の未来~ 58 2023
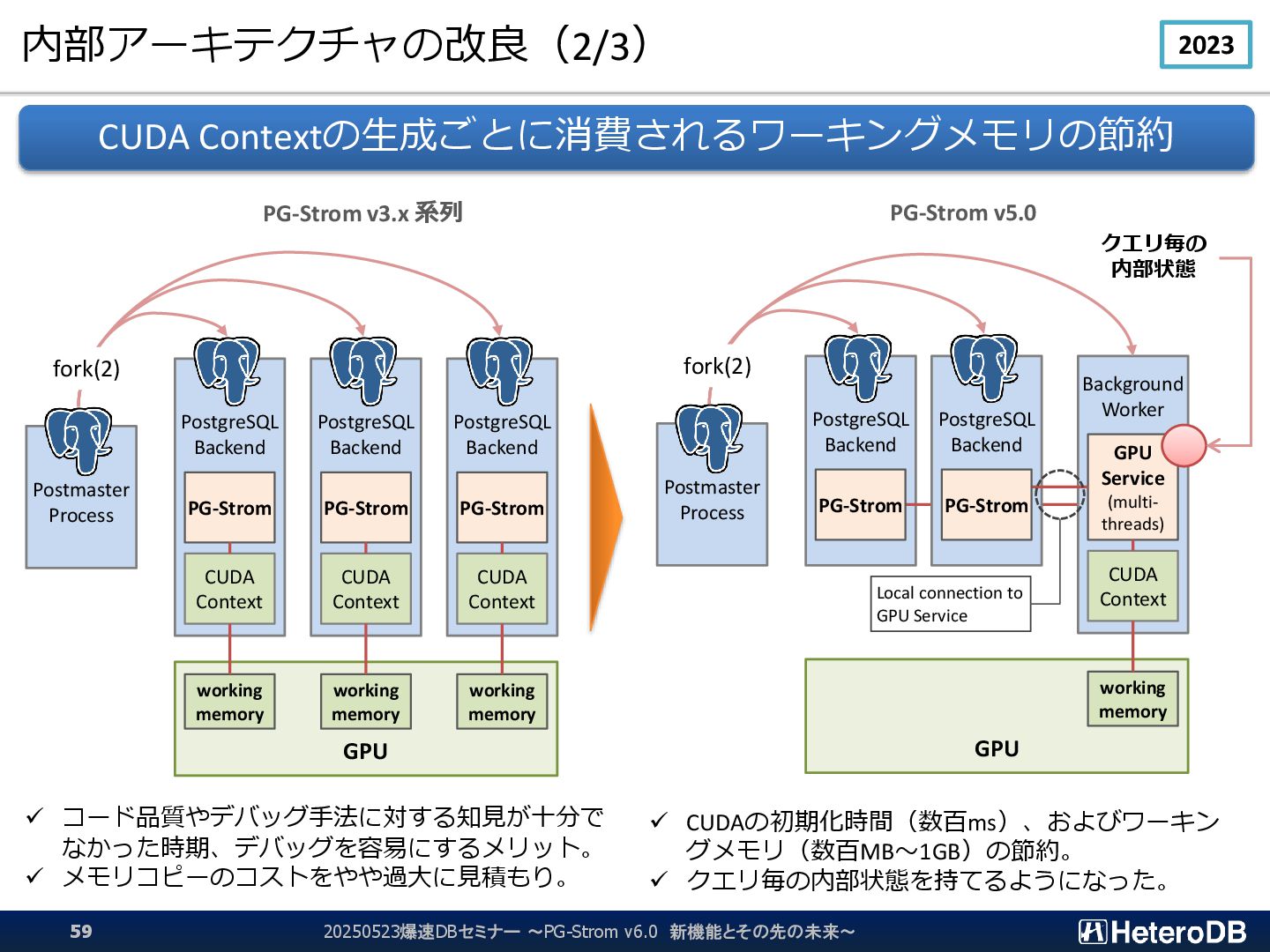
GPU PostgreSQL Backend CUDA Context PG-Strom PostgreSQL Backend CUDA Context PG-Strom PostgreSQL Backend CUDA Context PG-Strom Postmaster Process working memory working memory working memory fork(2) GPU PG-Strom PostgreSQL Backend Background Worker CUDA Context GPU Service (multi- threads) Postmaster Process working memory fork(2) PG-Strom Local connection to GPU Service ✓ コード品質やデバッグ手法に対する知見が十分で なかった時期、デバッグを容易にするメリット。 ✓ メモリコピーのコストをやや過大に見積もり。 ✓ CUDAの初期化時間(数百ms)、およびワーキン グメモリ(数百MB~1GB)の節約。 ✓ クエリ毎の内部状態を持てるようになった。 20250523爆速DBセミナー ~PG-Strom v6.0 新機能とその先の未来~ 59 2023 クエリ毎の 内部状態
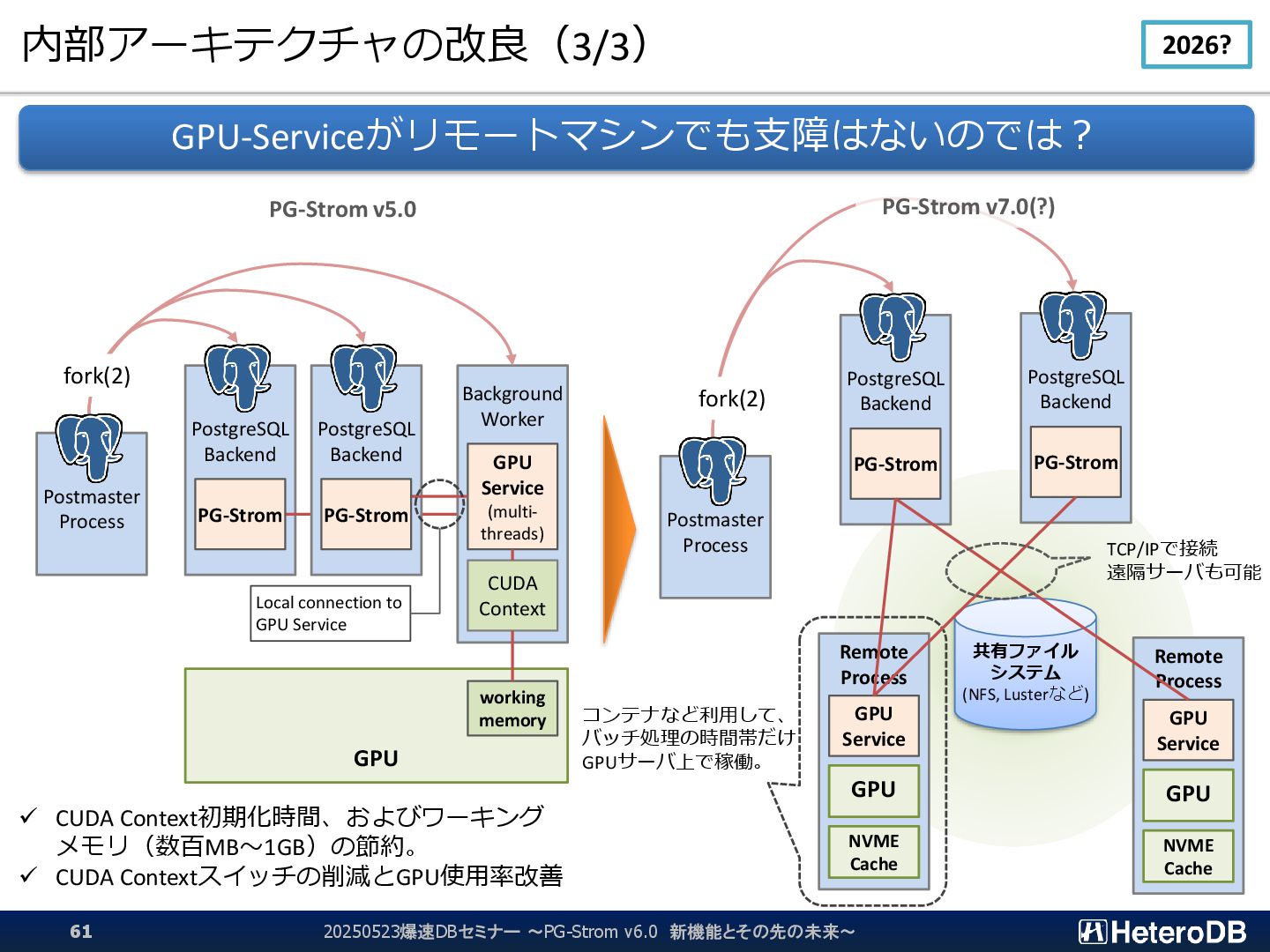
Backend Background Worker CUDA Context GPU Service (multi- threads) Postmaster Process working memory fork(2) PG-Strom Local connection to GPU Service ✓ CUDA Context初期化時間、およびワーキング メモリ(数百MB~1GB)の節約。 ✓ CUDA Contextスイッチの削減とGPU使用率改善 PostgreSQL Backend PG-Strom PostgreSQL Backend Postmaster Process fork(2) PG-Strom PG-Strom v7.0(?) Remote Process GPU Service GPU NVME Cache Remote Process GPU Service GPU NVME Cache 共有ファイル システム (NFS, Lusterなど) コンテナなど利用して、 バッチ処理の時間帯だけ GPUサーバ上で稼働。 TCP/IPで接続 遠隔サーバも可能 20250523爆速DBセミナー ~PG-Strom v6.0 新機能とその先の未来~ 2026?
![日本発のOSS爆速DB 「PG-Strom」開発の歴史と展望 ヘテロDB株式会社 チーフアーキテクト 兼 CEO 海外 浩平 <[email protected]>](https://files.speakerdeck.com/presentations/38bad2e1b2c645ff882c6bfcd34a4c90/slide_0.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![[補足] RCU (Read Copy Update) について 20250906~日本発のOSS爆速DB「PG-Strom」開発の歴史と展望 6 リストを更新する際にロックを使う場合 RCUによるリスト更新](https://files.speakerdeck.com/presentations/38bad2e1b2c645ff882c6bfcd34a4c90/slide_5.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
![[補足] Security Barrier ViewとLeakproof関数(1/2) 20250906~日本発のOSS爆速DB「PG-Strom」開発の歴史と展望 10 postgres=# SELECT * FROM](https://files.speakerdeck.com/presentations/38bad2e1b2c645ff882c6bfcd34a4c90/slide_9.jpg){kind=link}
![[補足] Security Barrier ViewとLeakproof関数(2/2) 20250906~日本発のOSS爆速DB「PG-Strom」開発の歴史と展望 11 postgres=> EXPLAIN SELECT *](https://files.speakerdeck.com/presentations/38bad2e1b2c645ff882c6bfcd34a4c90/slide_10.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
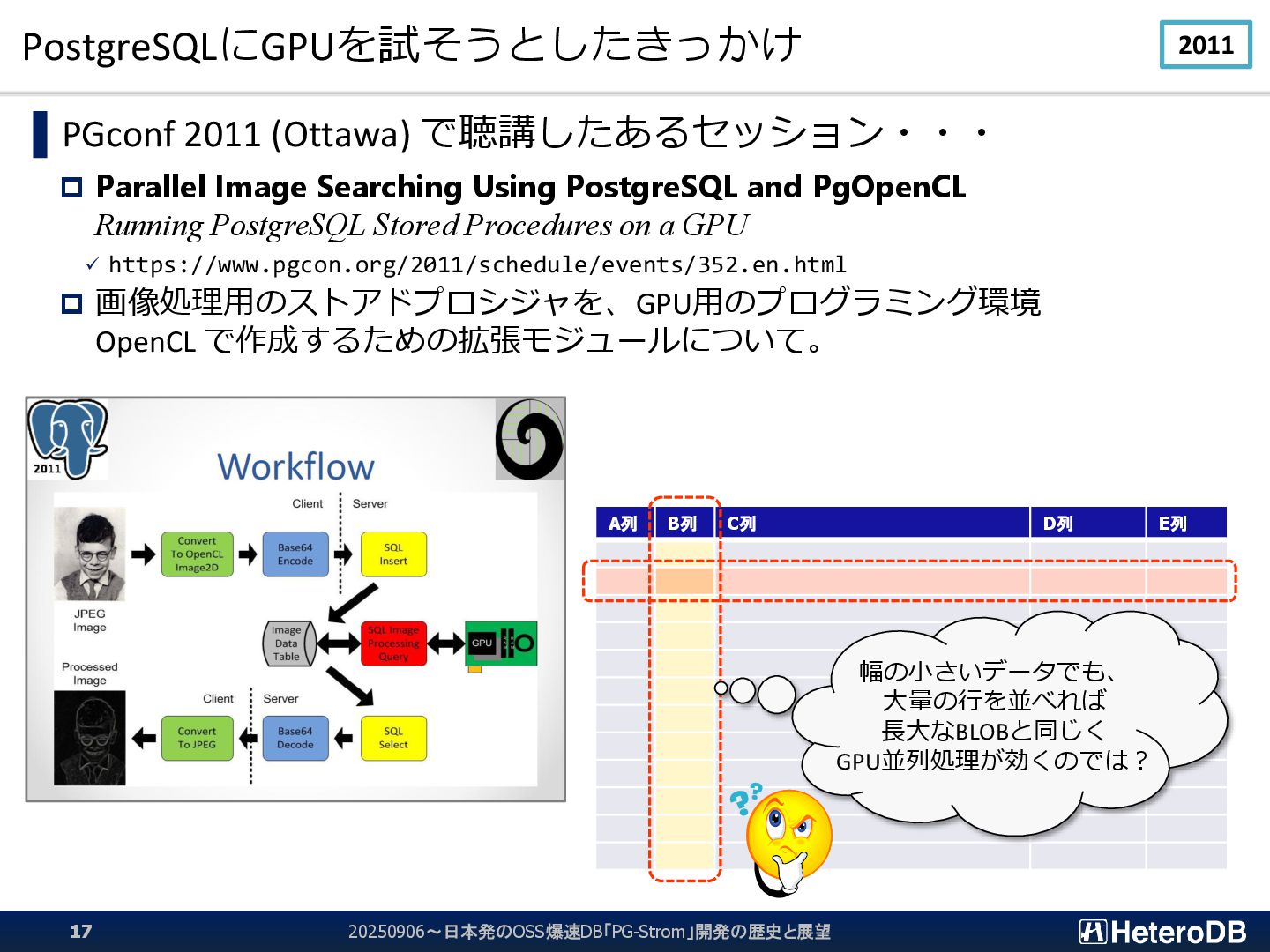{kind=link}
{kind=link}
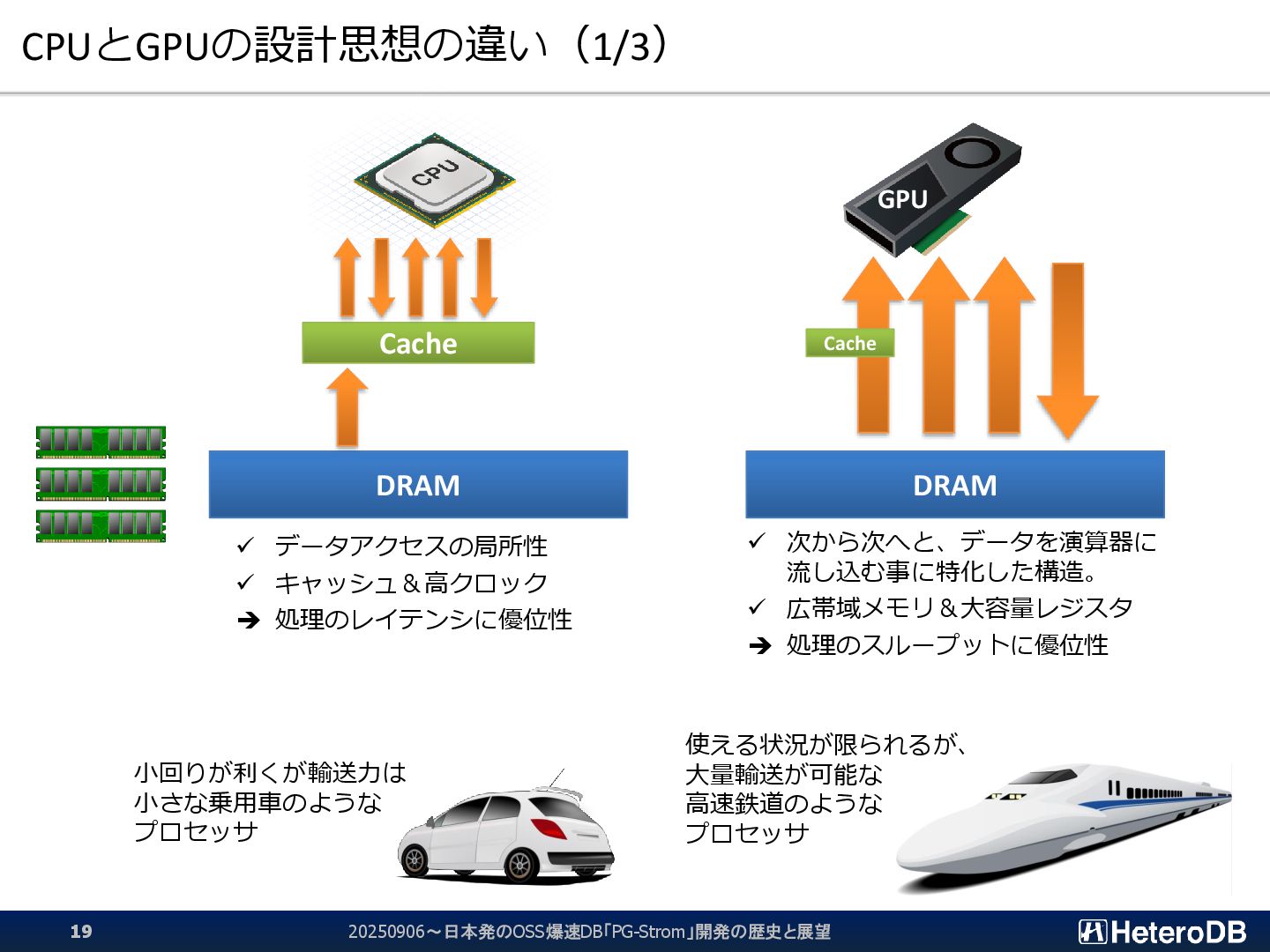{kind=link}
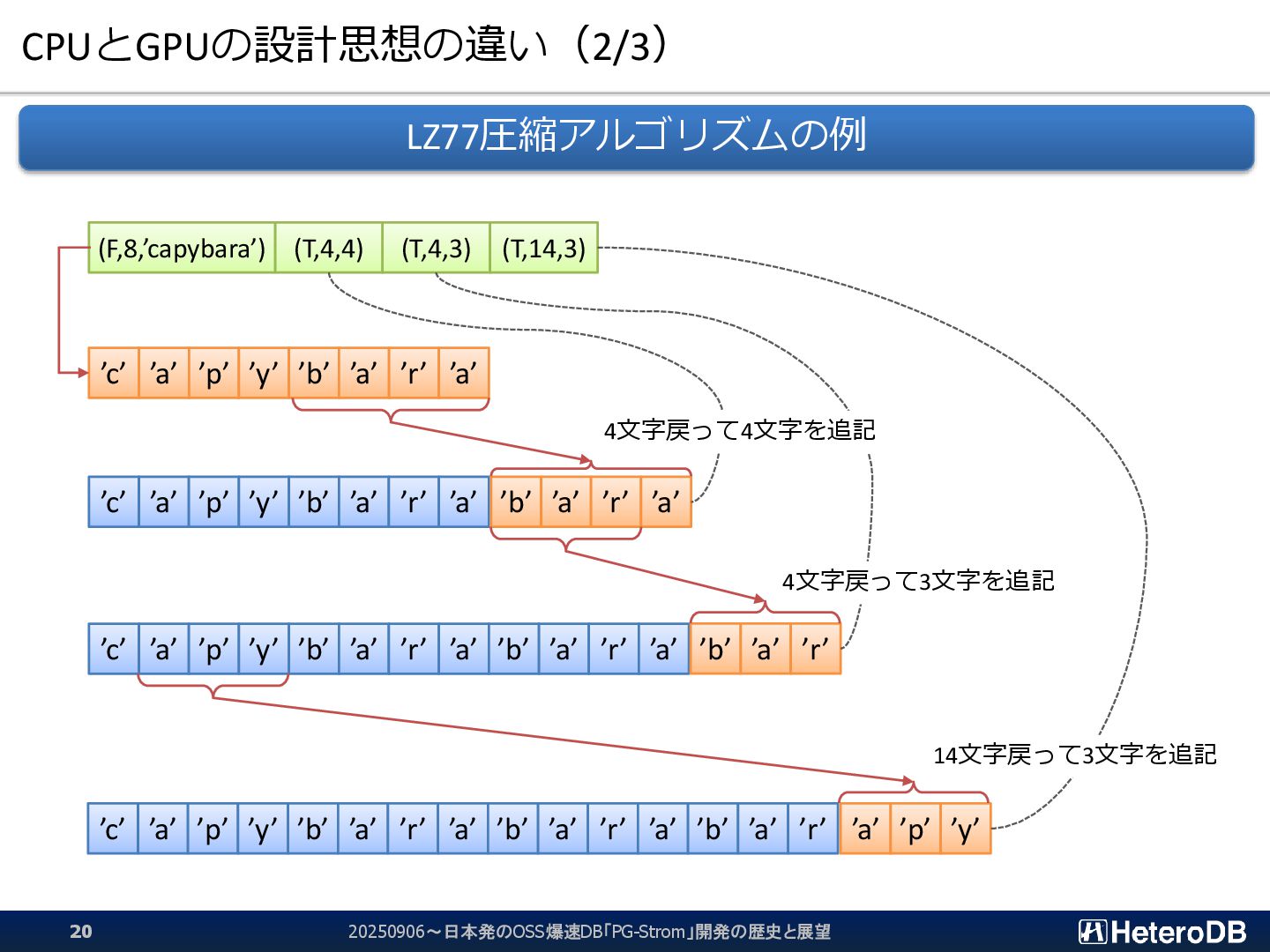{kind=link}
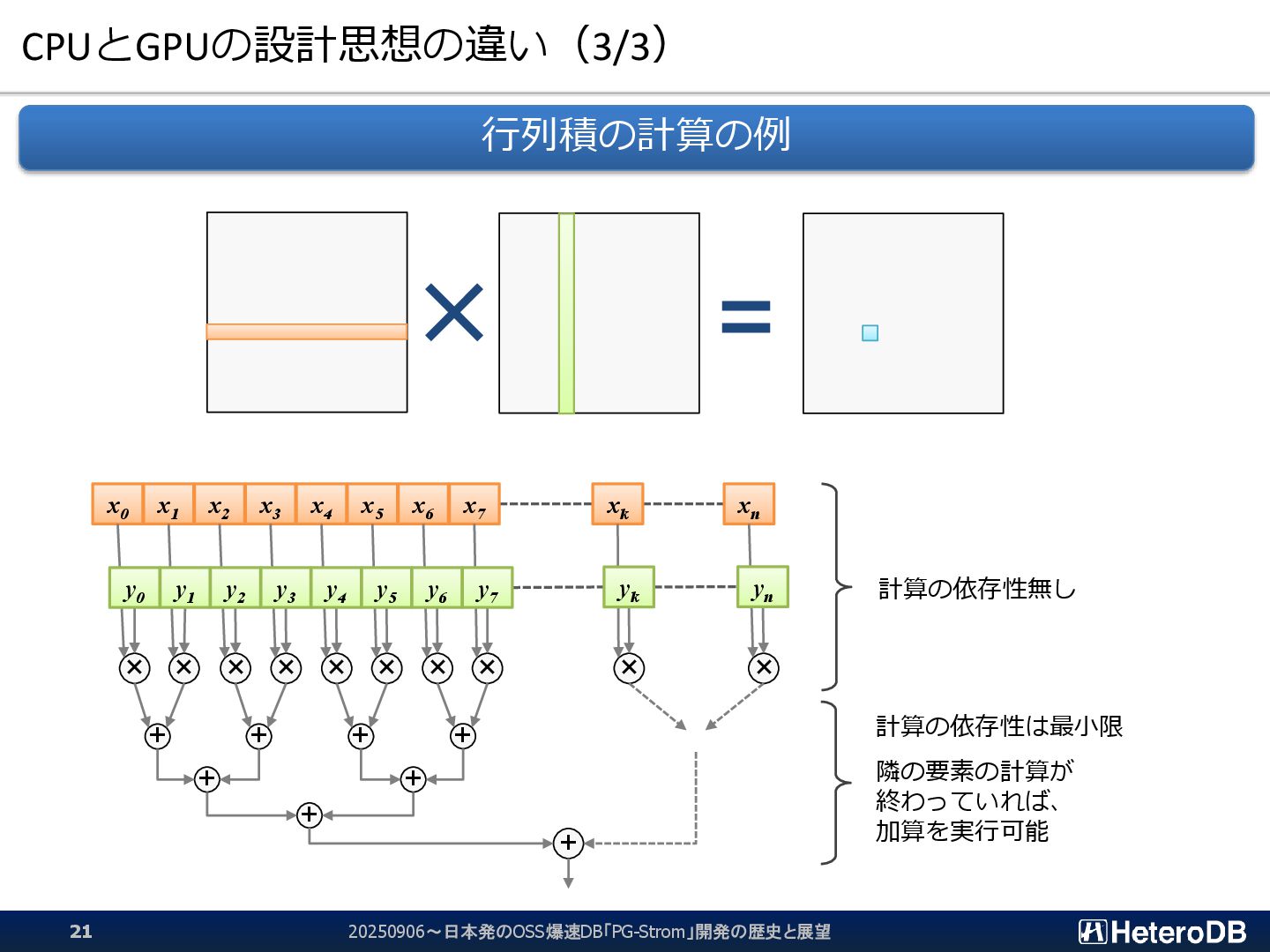{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
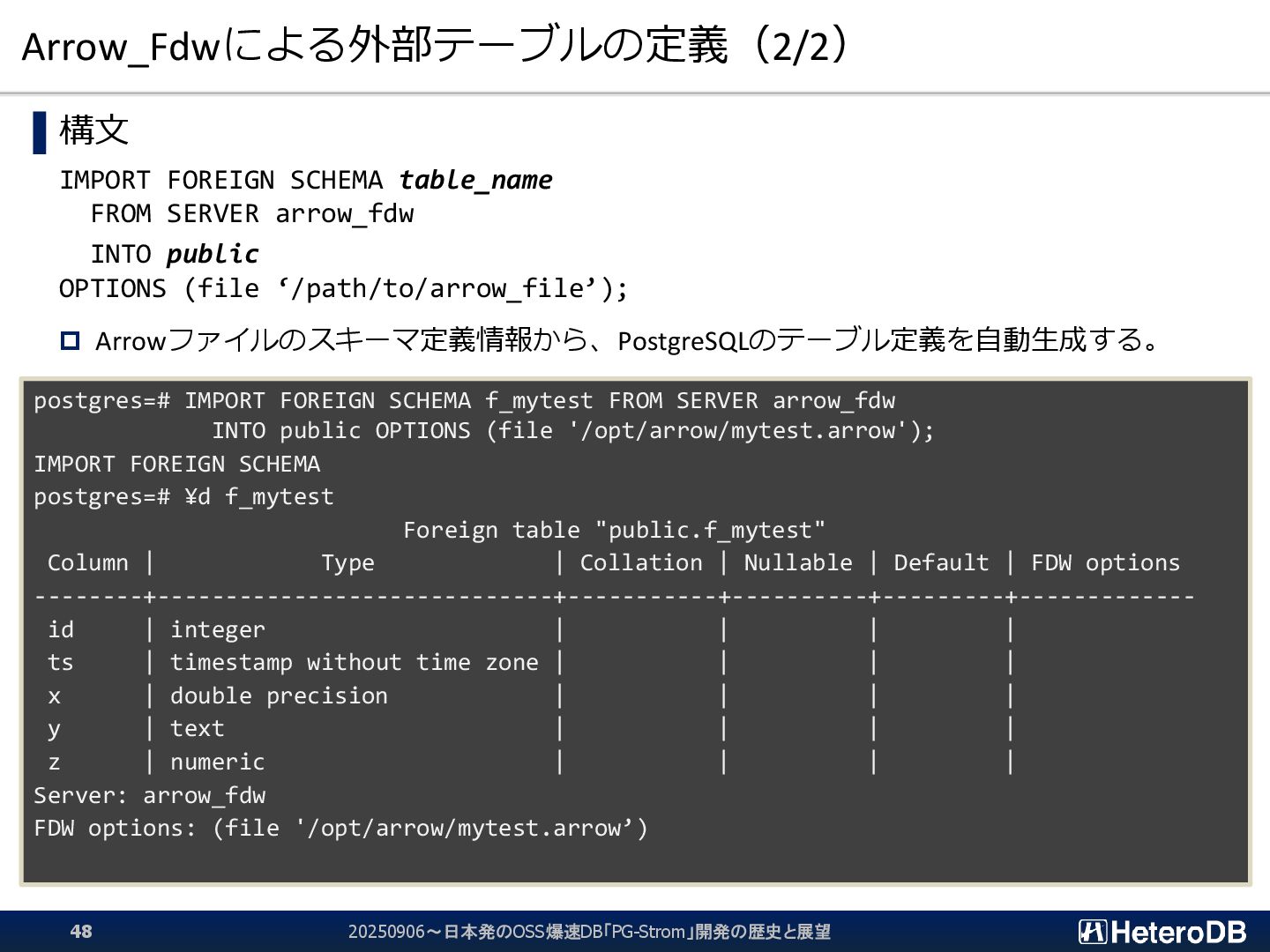{kind=link}
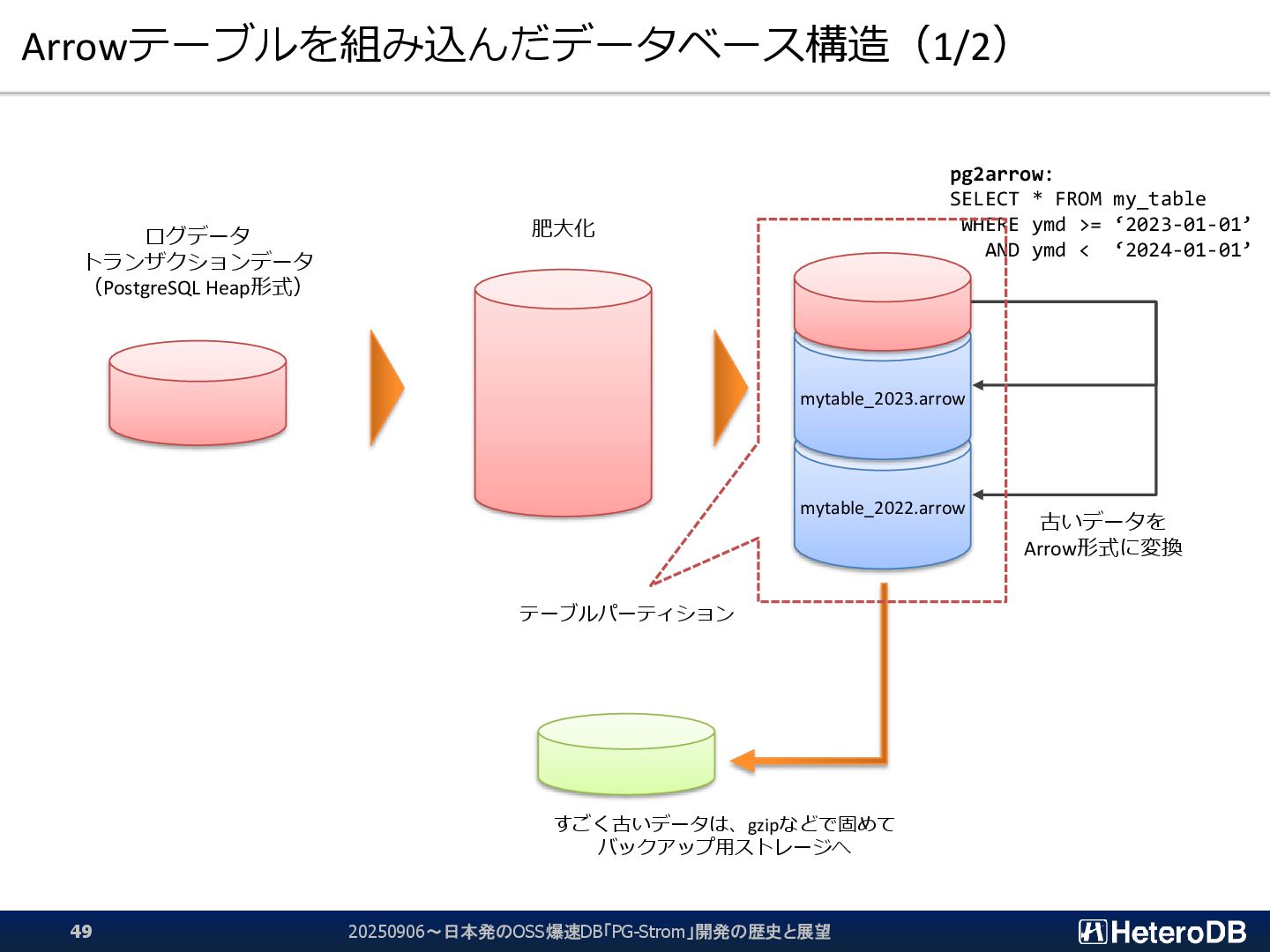{kind=link}
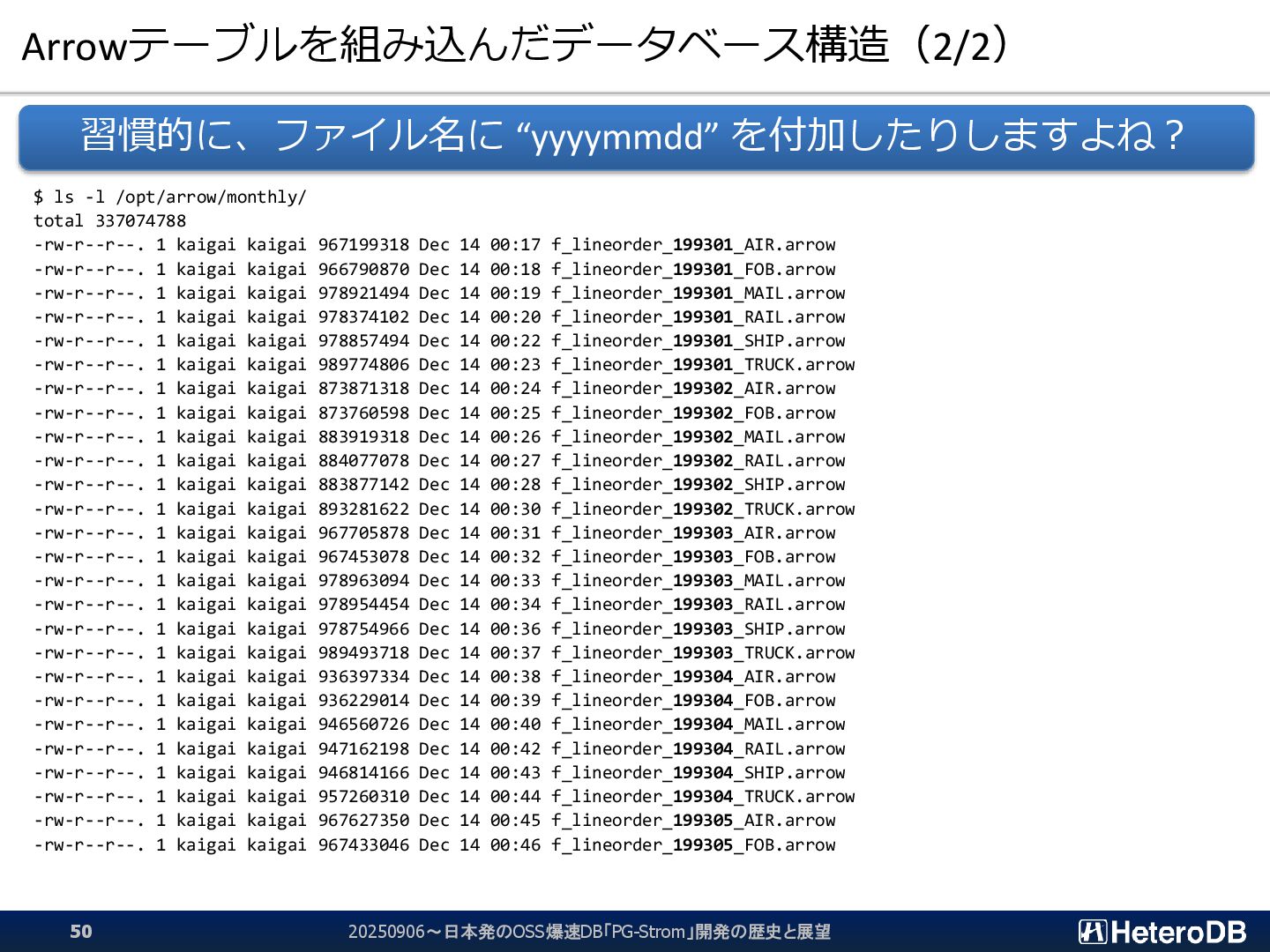{kind=link}
{kind=link}
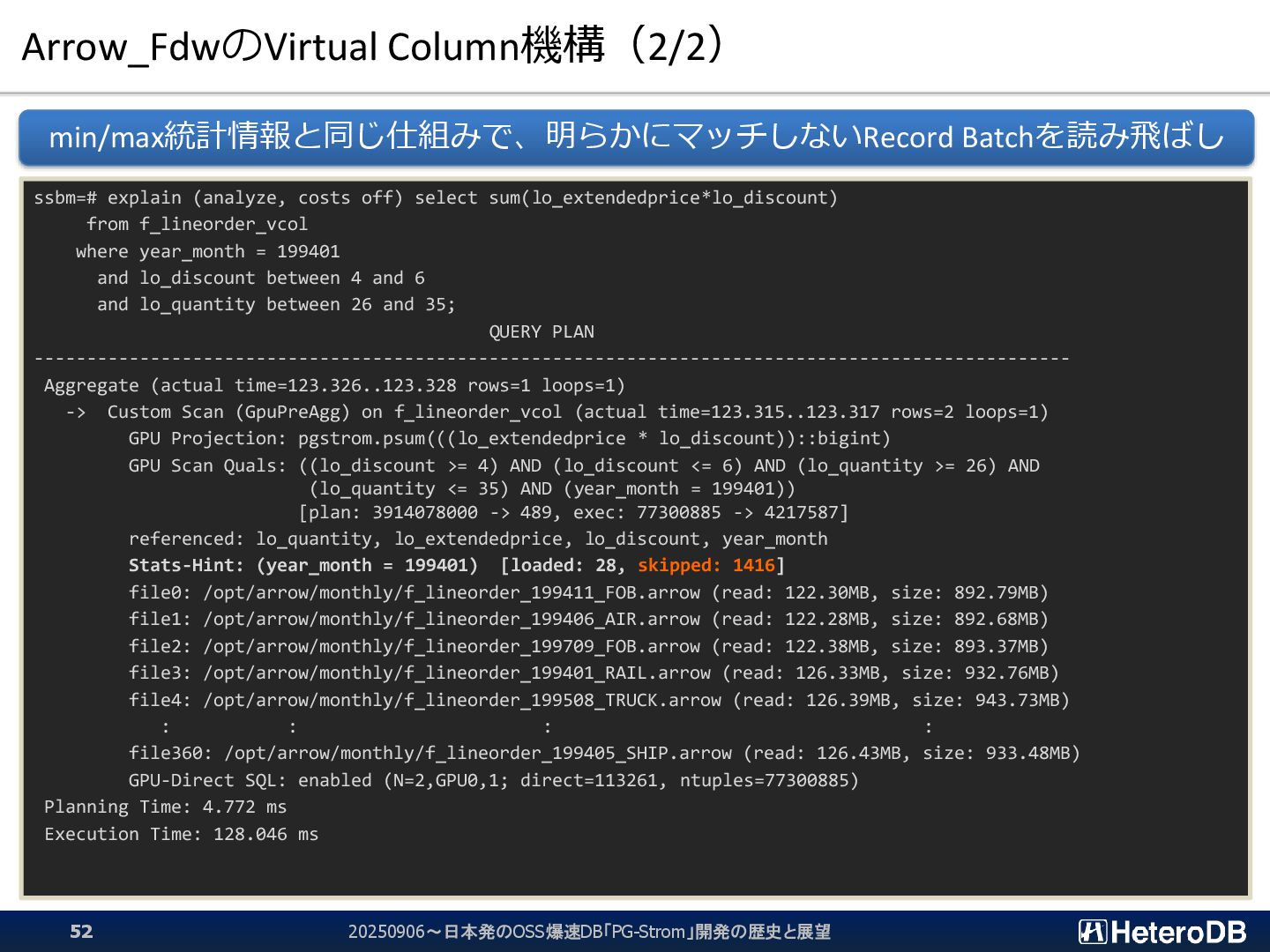{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![[補足] 内部状態を持てるようになると何が嬉しいか? 20250906~日本発のOSS爆速DB「PG-Strom」開発の歴史と展望 60 GPU-Scanしながら作成したハッシュ表を、次のGPU-Joinで使える](https://files.speakerdeck.com/presentations/38bad2e1b2c645ff882c6bfcd34a4c90/slide_59.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}