Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
Segmentation-Free Word Embedding for Unsegmente...
Search
Sponsored
·
Your Podcast. Everywhere. Effortlessly.
Share. Educate. Inspire. Entertain. You do you. We'll handle the rest.
→
katsutan
August 27, 2018
Technology
140
1
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
Segmentation-Free Word Embedding for Unsegmented Languages ∗
文献紹介 勝田 哲弘
http://aclweb.org/anthology/D17-1080
katsutan
August 27, 2018
More Decks by katsutan
See All by katsutan
What does BERT learn about the structure of language?
katsutan
0
270
Simple and Effective Paraphrastic Similarity from Parallel Translations
katsutan
0
230
Simple task-specific bilingual word embeddings
katsutan
0
230
Retrofitting Contextualized Word Embeddings with Paraphrases
katsutan
0
290
Character Eyes: Seeing Language through Character-Level Taggers
katsutan
1
250
Improving Word Embeddings Using Kernel PCA
katsutan
0
250
Better Word Embeddings by Disentangling Contextual n-Gram Information
katsutan
0
350
Rotational Unit of Memory: A Novel Representation Unit for RNNs with Scalable Applications
katsutan
0
290
A robust self-learning method for fully unsupervised cross-lingual mappings of word embeddings
katsutan
0
320
Other Decks in Technology
See All in Technology
AICoEでAIネイティブ組織への進化
yukiogawa
0
210
AIツールを導入しても生産性はあがらない? カオナビが直面した 3つの壁と乗り越え方。/ Overcoming 3 Barriers to AI-Driven Productivity at kaonavi
kaonavi
0
150
Amazon Quick 入門!
ysuzuki
2
130
なぜ、あなたのエージェントは言うことを聞かないのか
segavvy
1
340
「休む」重要さ
smt7174
6
1.6k
AI、CDK と協働する Full TypeScript アプリケーション開発 / Full TypeScript Application with AI and CDK
geekplus_tech
2
470
非定型なドキュメントを効率よくリファクタする 〜えぇ!?仕様書27本の移行が1日で終わったって!?〜
subroh0508
2
610
10年目を迎えた「ABEMA」がどのように AI 活用を推進して、AI 駆動開発にシフトしているのか / How ABEMA, entering its 10th year, is promoting the use of AI and shifting toward AI-driven development
miyukki
0
360
AI時代の開発生産性は、個人技からチーム設計へ
moongift
PRO
4
2.5k
GoでCコンパイラを作った話
repunit
0
150
CDKで書くECSのベストプラクティス、 改めて考え直す2026 #cdkconf2026
makies
3
930
AI工学特論: MLOps・継続的評価
asei
4
540
Featured
See All Featured
Building Adaptive Systems
keathley
44
3.1k
Ecommerce SEO: The Keys for Success Now & Beyond - #SERPConf2024
aleyda
1
2.1k
AI Search: Implications for SEO and How to Move Forward - #ShenzhenSEOConference
aleyda
1
1.3k
Making the Leap to Tech Lead
cromwellryan
135
10k
Templates, Plugins, & Blocks: Oh My! Creating the theme that thinks of everything
marktimemedia
31
2.8k
VelocityConf: Rendering Performance Case Studies
addyosmani
333
25k
Site-Speed That Sticks
csswizardry
13
1.3k
Building an army of robots
kneath
306
46k
A Soul's Torment
seathinner
6
3.1k
The Pragmatic Product Professional
lauravandoore
37
7.4k
Rails Girls Zürich Keynote
gr2m
96
14k
Digital Projects Gone Horribly Wrong (And the UX Pros Who Still Save the Day) - Dean Schuster
uxyall
1
2.1k
Transcript
Segmentation-Free Word Embedding for Unsegmented Languages ∗ Takamasa Oshikiri Proceedings
of the 2017 Conference on Empirical Methods in Natural Language Processing, pages 767–772 長岡技術科学大学 自然言語処理研究室 修士1年 勝田 哲弘
Abstract • 単語分割されていない言語に対して、前処理として単語分割を必要としない単語ベ クトルの獲得方法の提案 ◦ segmentation-free word embedding • 基本的に、中国語や日本語のようにスペースで区切られない言語では単語の分割
が必要になるが、人手によるリソースが必要になる。 • 文字ngramによる共起情報をもとに分割を行い、Twitter、Weibo、Wikipediaでの 名詞カテゴリ予測タスクでは、従来のアプローチより優れていることが示されていま す。
Introduction • NLPでは大規模なコーパスから単語ベクトルを獲得するword embeddingが注目さ れている。前処理としてセグメントが必要。 ◦ 英語やスペイン語などの言語では、単純なルールベースと共起ベースのアプローチがとられる。 ◦ 中国語、日本語、タイ語などのセグメント化されていない言語では、機械学習ベースのアプローチ がNLPで広く使用されています。(
Kudo et al。、2004; Tseng et al。、2005) ▪ 辞書が必要、固有名詞が苦手 • 文字nグラムに基づいて可能なすべてのセグメント化を列挙し、共起頻度からnグラ ム・ベクトルを学習する 枠組みを提案
Related Work セグメントに依存しないモデル • character-based RNN model ◦ Dhingra et
al. (2016) • learns n-gram vectors from the corpus that segmented randomly ◦ Schütze (2017) これらの手法は、テキストまたは系列のベクトル表現を学習することを目的としている。
Conventional Approaches to Word Embeddings skip-gram model with negative sampling
(SGNS) (Mikolov et al., 2013) 以下の単語、コンテキストの目的関数を最小にするベクトルの学習を行う。
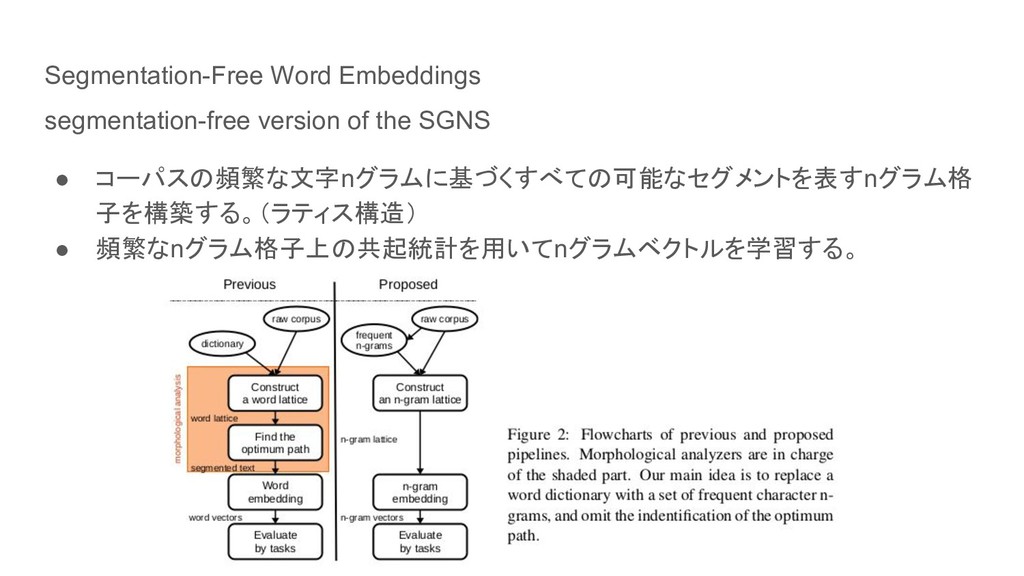
Segmentation-Free Word Embeddings segmentation-free version of the SGNS • コーパスの頻繁な文字nグラムに基づくすべての可能なセグメントを表すnグラム格
子を構築する。(ラティス構造) • 頻繁なnグラム格子上の共起統計を用いてnグラムベクトルを学習する。
Experiment Twitter、Weibo、Wikipediaのコーパスにおける名詞カテゴリ予測タスクを用いて評価す る。 • Wikipedia (Japanese), Wikipedia (Chinese), Twitter (Japanese),
and Weibo (Chinese) • ngram = 1-8 for Japanese • ngram = 1-7 for Chinese • C-SVM(Hastie et al., 2009)
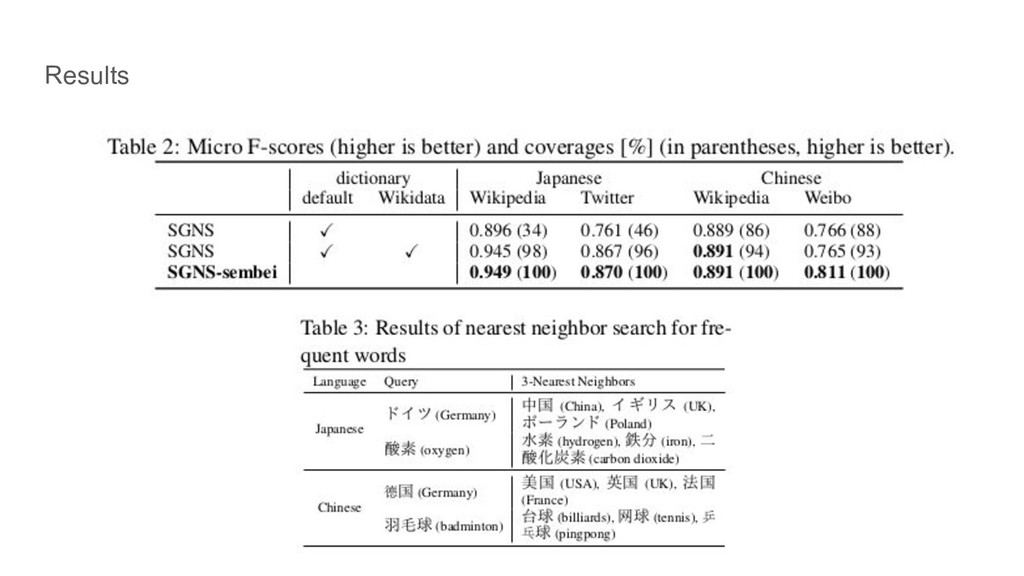
Results
Conclusion • 人手でアノテーションされたリソースに依存しない手法でその リソースに依存する手法を上回った。 • 将来的には別の手法を活用する ◦ the Stanford Word
Segmenter (Tseng et al., 2005) with k-best segmentations
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}