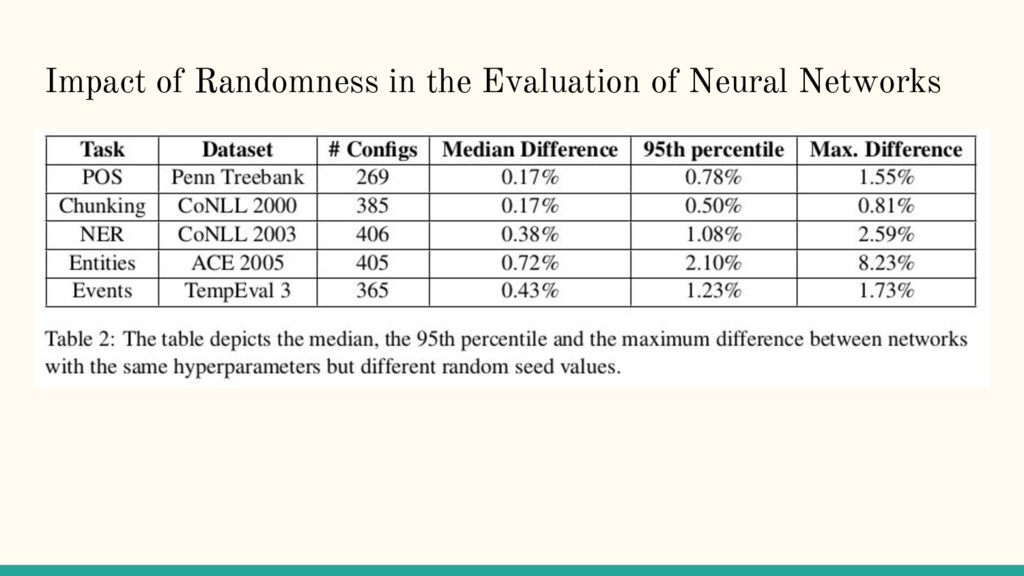
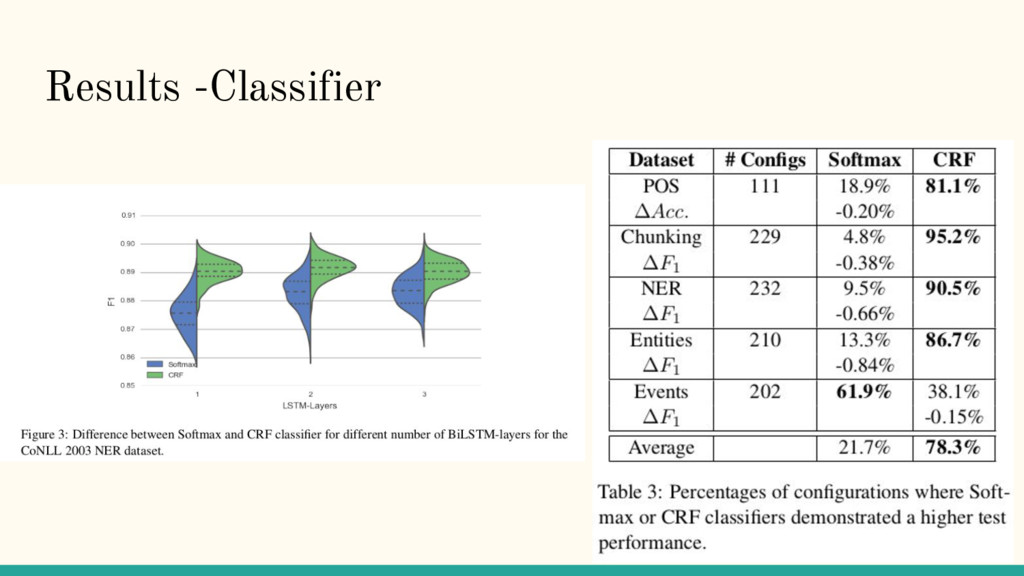
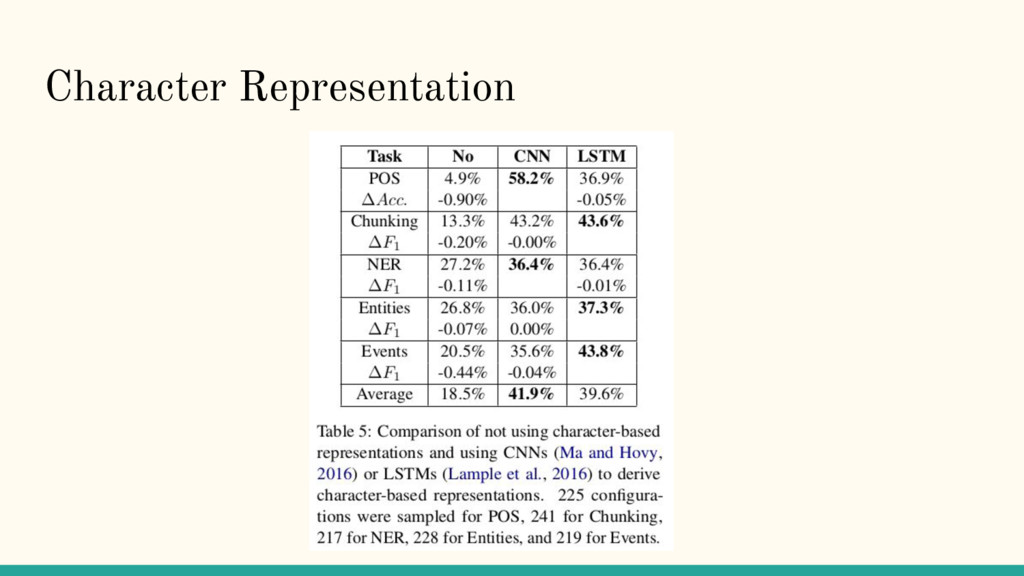
Difference: Performance Study of LSTM-networks for Sequence Tagging Nils Reimers and Iryna Gurevych, Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pages 338–348.
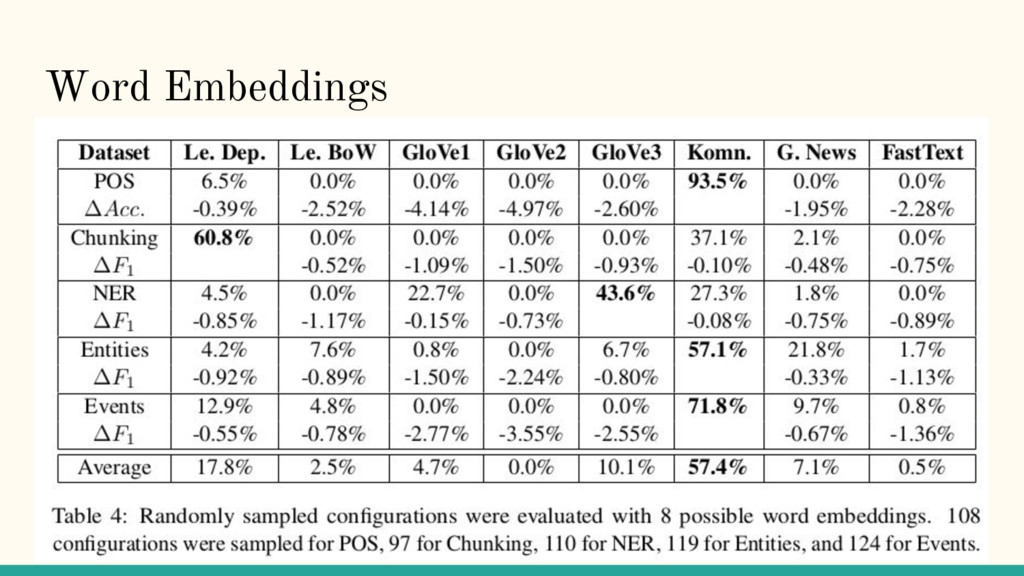
News) ◦ the Bag of Words (Le.BoW) ◦ the dependency based embeddings (Le. Dep.) ◦ GloVe embeddings ▪ Wikipedia 2014+ Gigaword 5 (GloVe1 with 100 dimensions and GloVe2 with 300 dimensions) ▪ Common Crawl (GloVe3) ◦ the Komninos and Manandhar (2016) embeddings (Komn.) ◦ Bojanowski et al. (2016) (Fast-Text)
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}