Share
この資料は「第28回Machine Learning 15minutes! 」(https://machine-learning15minutes.connpass.com/event/97195/) で発表した内容になります。
{kind=link}
{kind=link}
![What is Counterfactual ML? ※Counterfactual ML (Machine Learning) [1]](https://files.speakerdeck.com/presentations/cd652aa0675b41c8b5e70b73db3c23f9/slide_2.jpg){kind=link}
{kind=link}
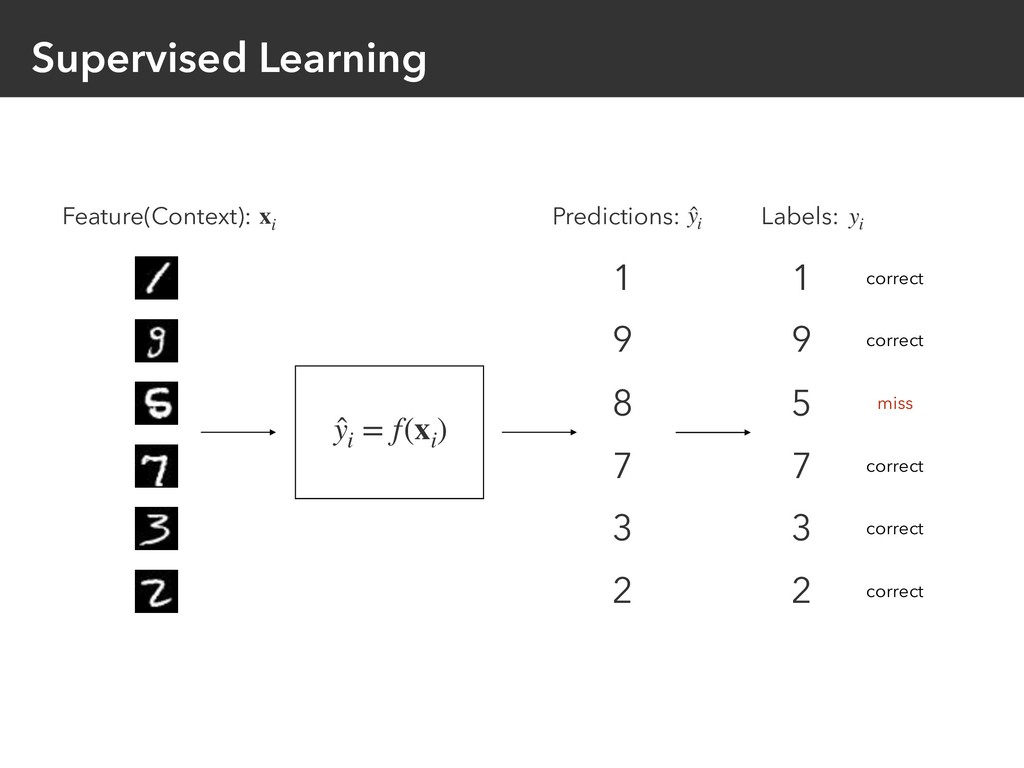{kind=link}
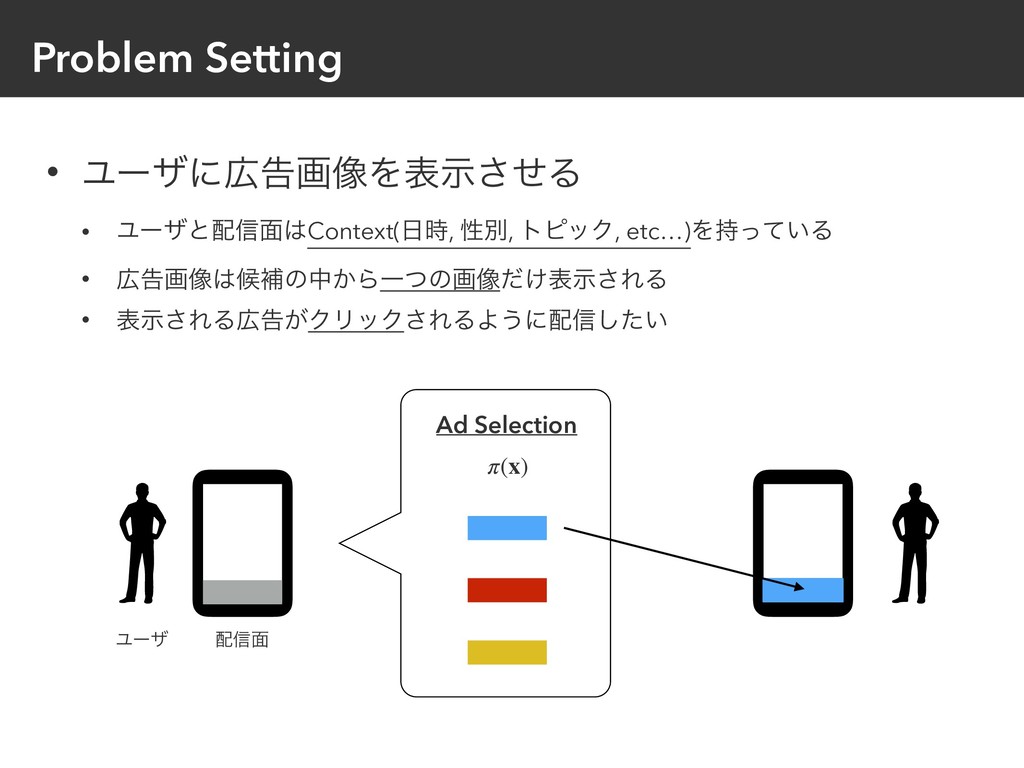{kind=link}
![Interactive Learning [2] Feature(Context): xi ai = π(xi ) Action:](https://files.speakerdeck.com/presentations/cd652aa0675b41c8b5e70b73db3c23f9/slide_6.jpg){kind=link}
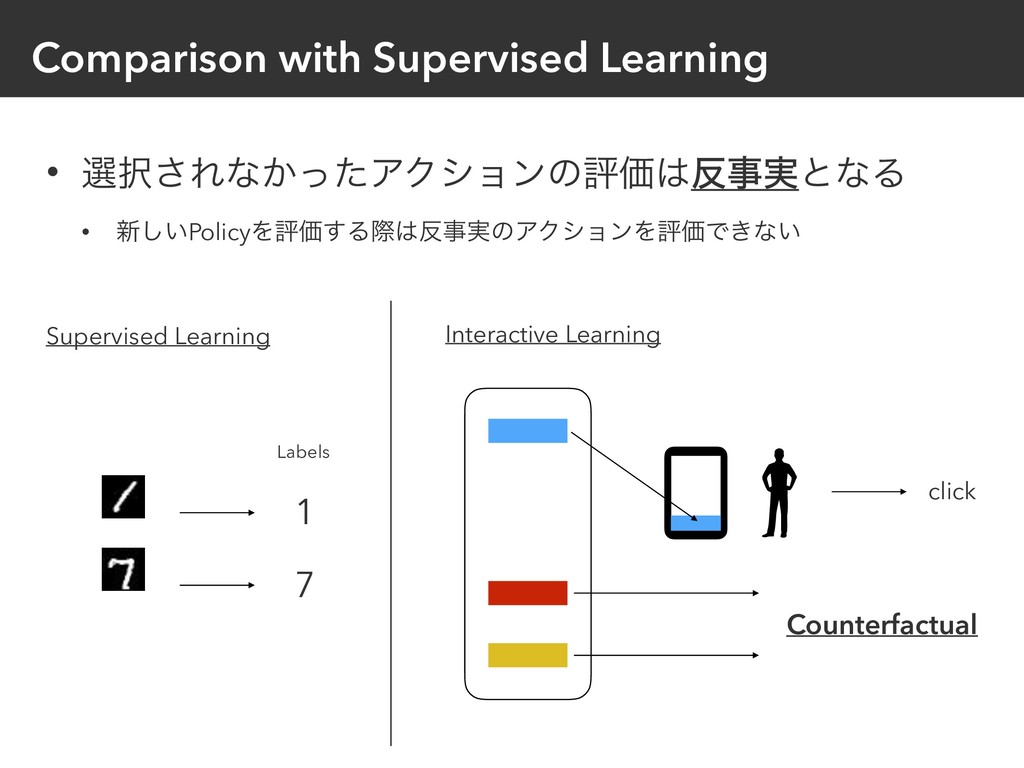{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![• classificationͱಉ༷ͷpolicy (ઢܗ + softmax) • ҎԼͷࣜͷ௨Γʹֶश POEM [5] π(y|x)](https://files.speakerdeck.com/presentations/cd652aa0675b41c8b5e70b73db3c23f9/slide_13.jpg){kind=link}
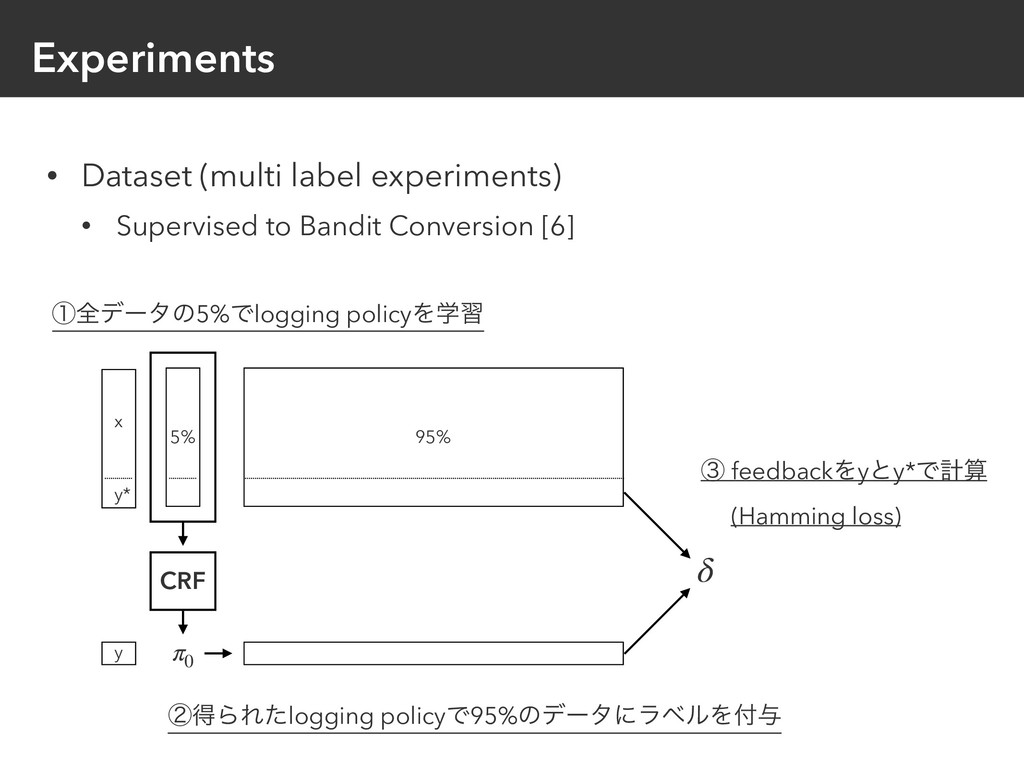{kind=link}
![Experimental Results [5] • Test set Hamming Loss • Computational](https://files.speakerdeck.com/presentations/cd652aa0675b41c8b5e70b73db3c23f9/slide_15.jpg){kind=link}
{kind=link}
![More • [5]ͷݚڀνʔϜ͕ܧଓతʹݚڀΛൃද • ”The Self-Normalized Estimator for Counterfactual Learning”](https://files.speakerdeck.com/presentations/cd652aa0675b41c8b5e70b73db3c23f9/slide_17.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}