• Kafka Streams & ksqlDB use internal topics to manage their state. • Avoid mirroring these internal topics to another cluster because consistency can be corrupted when launching applications on the destination site. Kafka Connect • Kafka Connect has to maintain consistency among related all settings and states (source system, destination system, Kafka Connect settings ,and running Connectors settings) Approach • Single cluster pattern is much safer for these components. • Running these components as standby on the destination site is another approach. (continue to update state information on the destination site and reduce RTO)
{kind=link}
{kind=link}
{kind=link}
{kind=link}
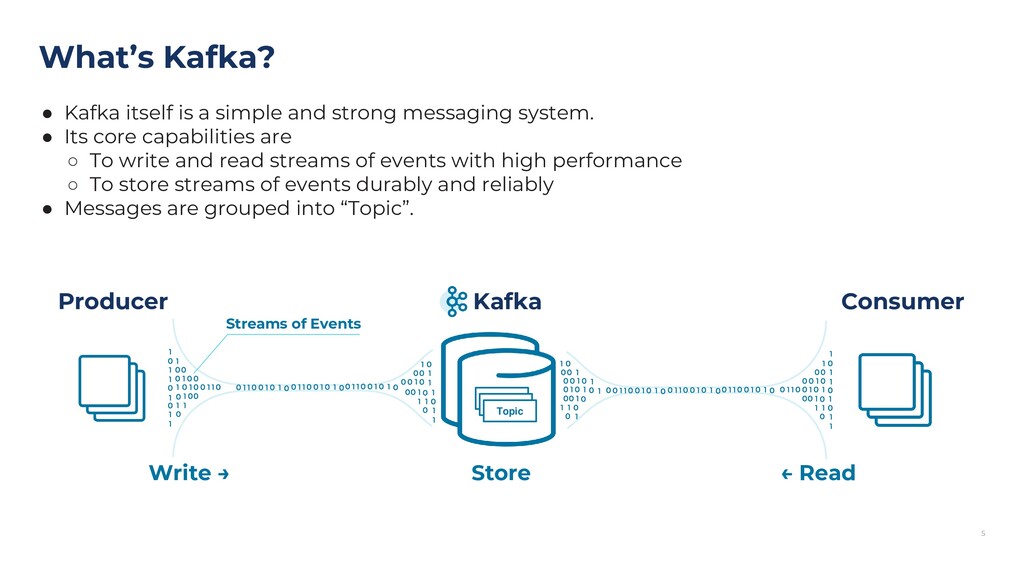{kind=link}
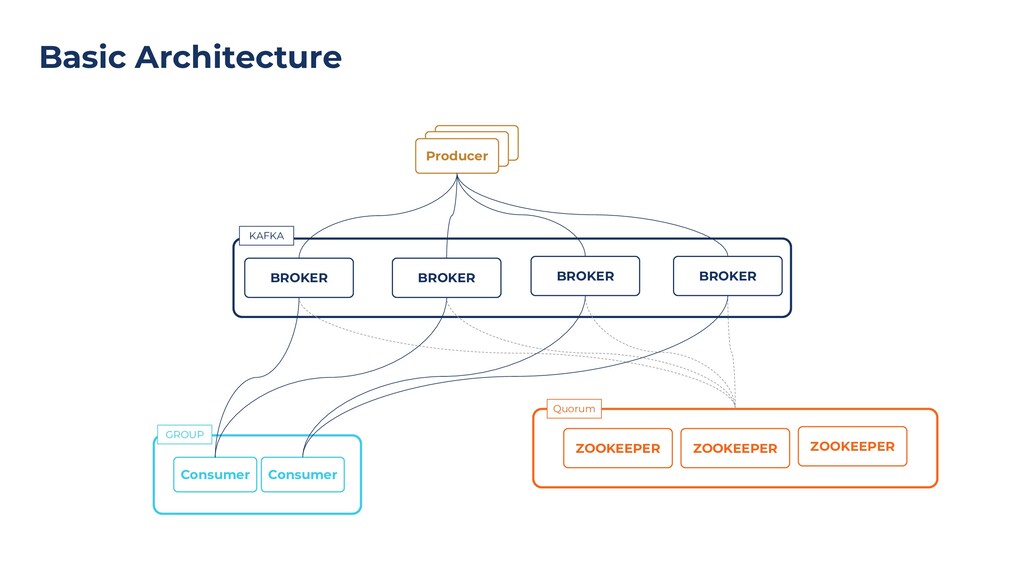{kind=link}
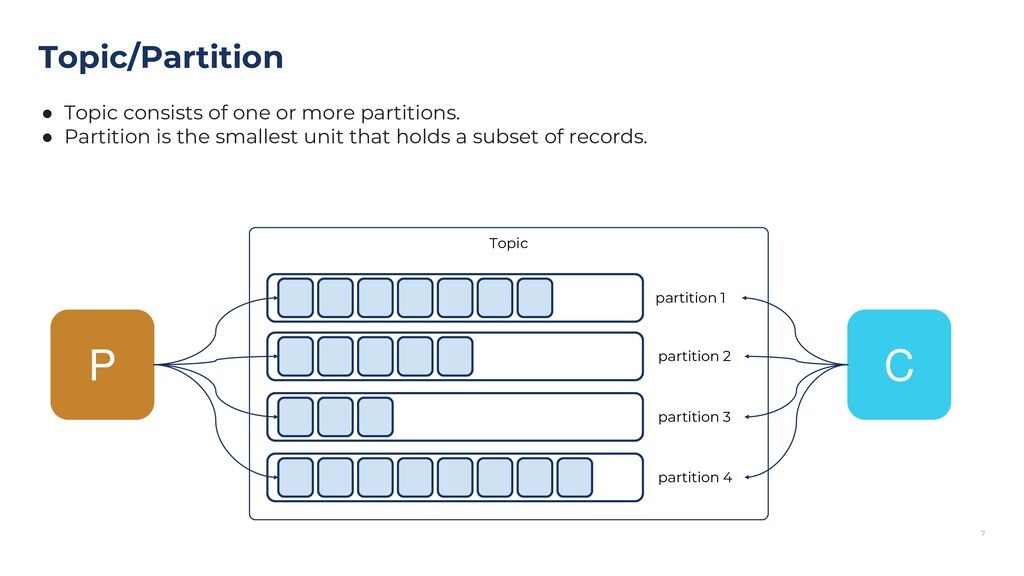{kind=link}
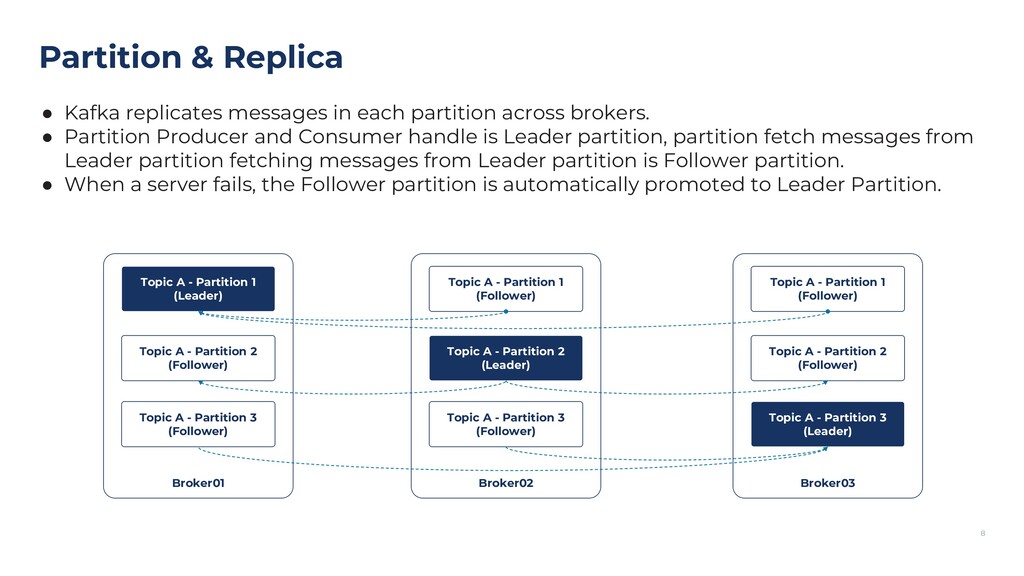{kind=link}
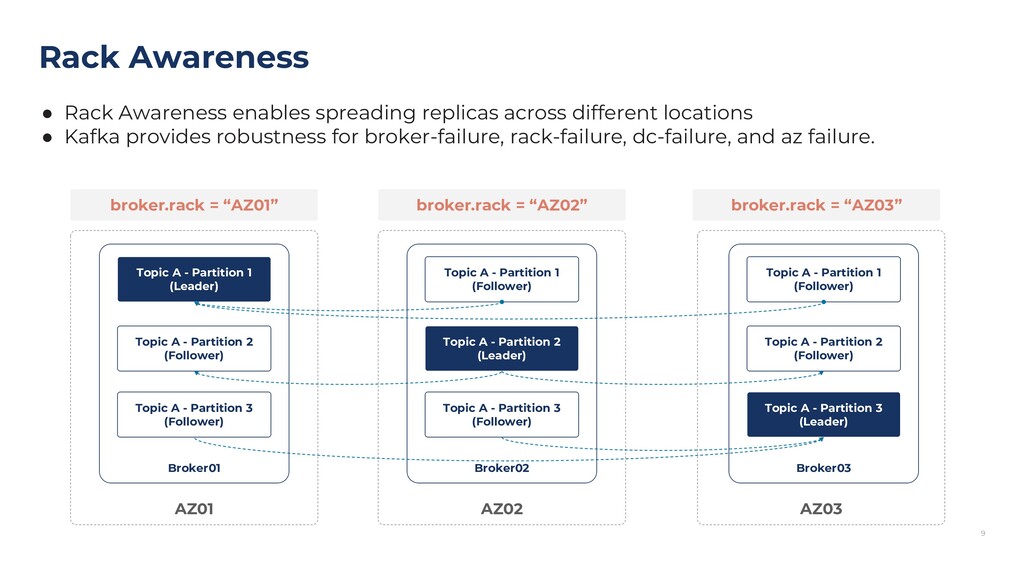{kind=link}
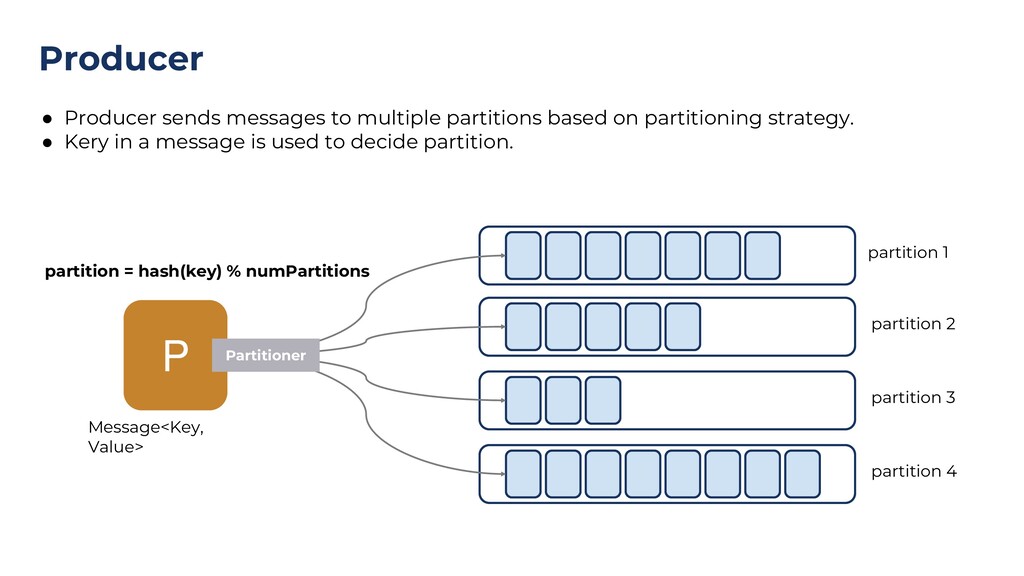{kind=link}
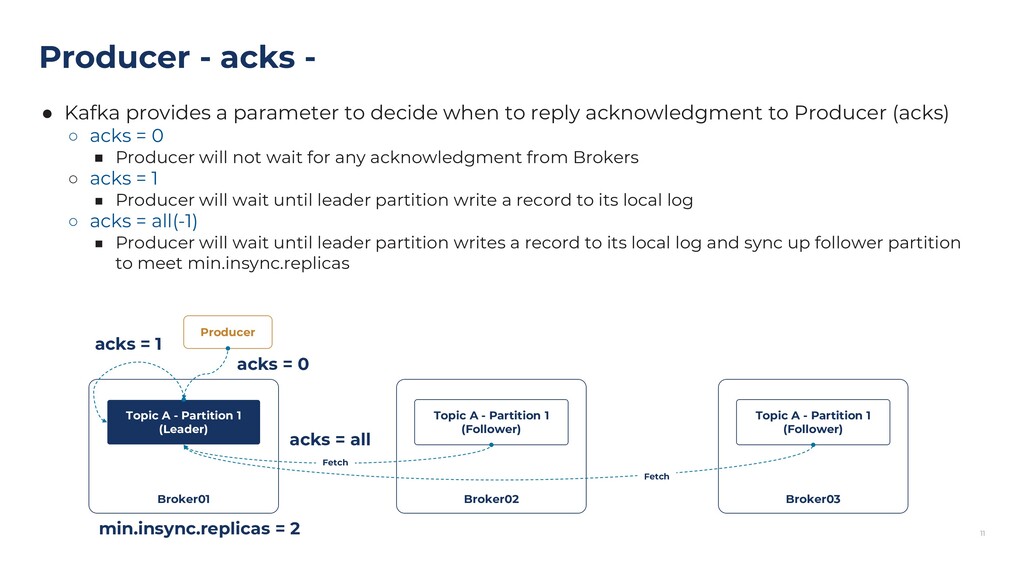{kind=link}
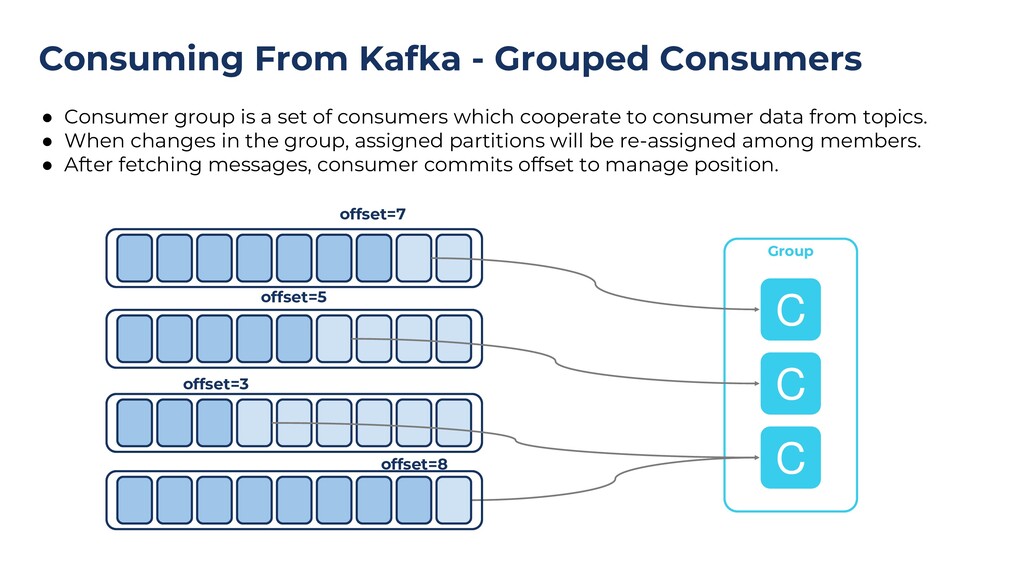{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
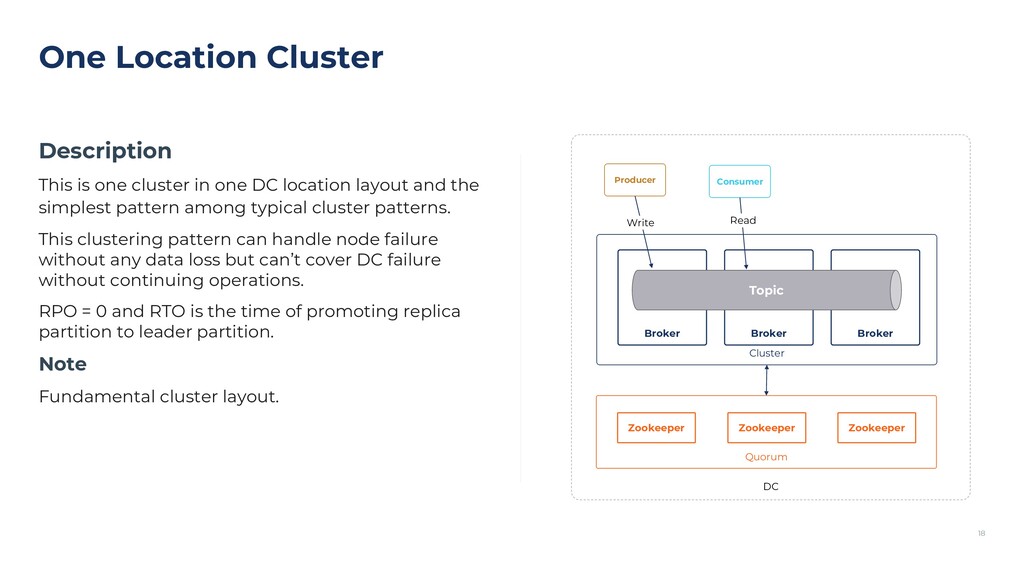{kind=link}
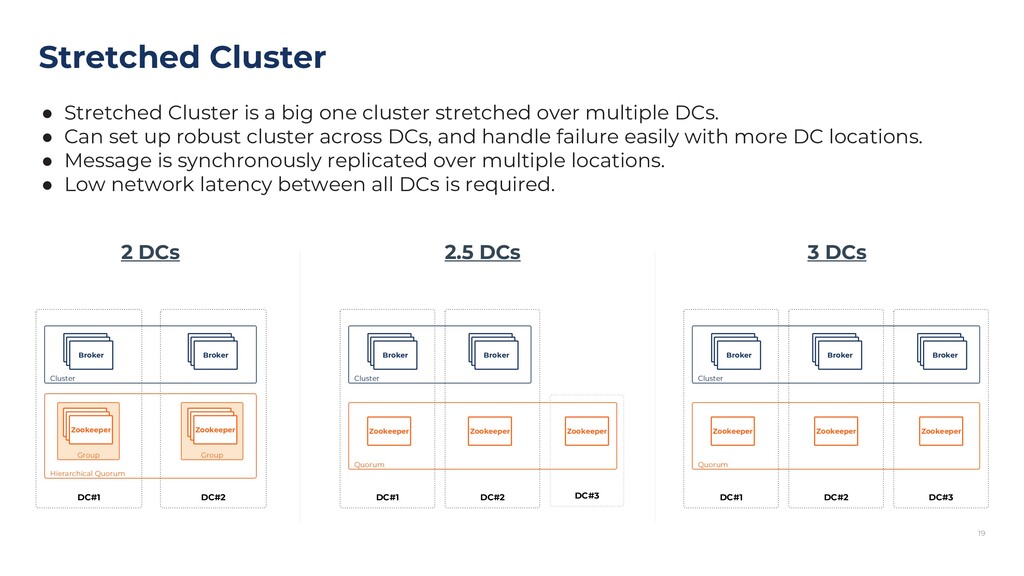{kind=link}
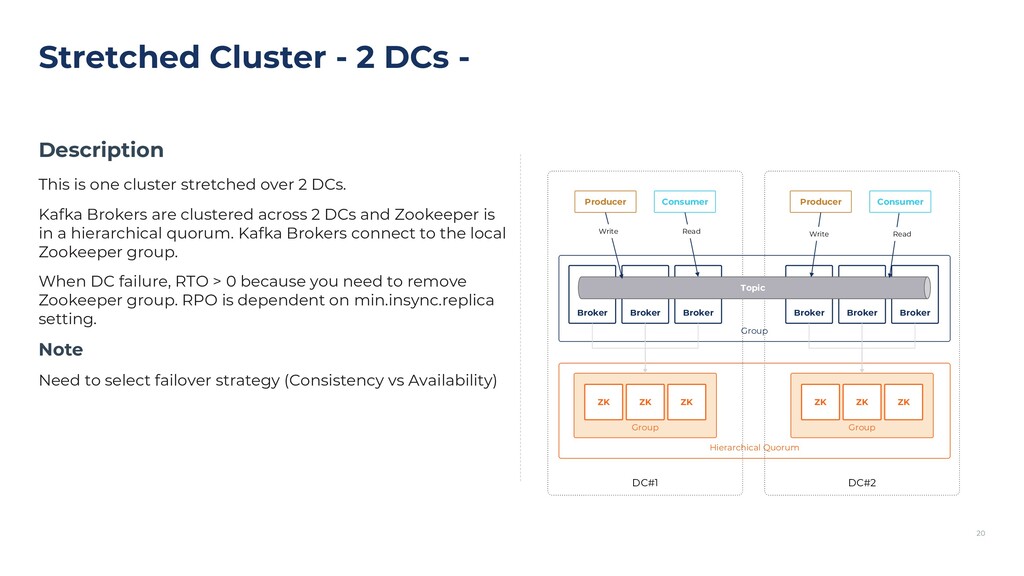{kind=link}
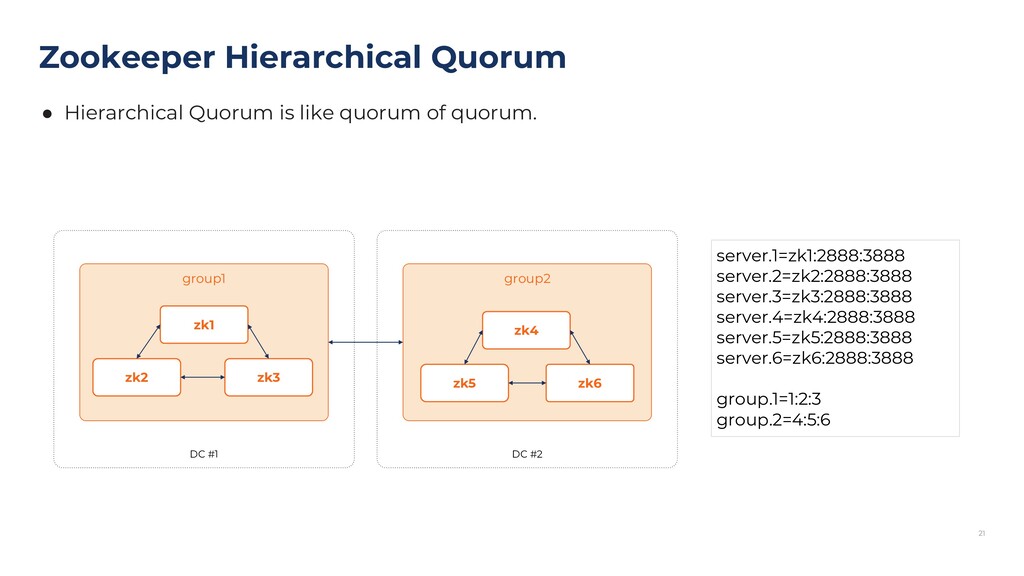{kind=link}
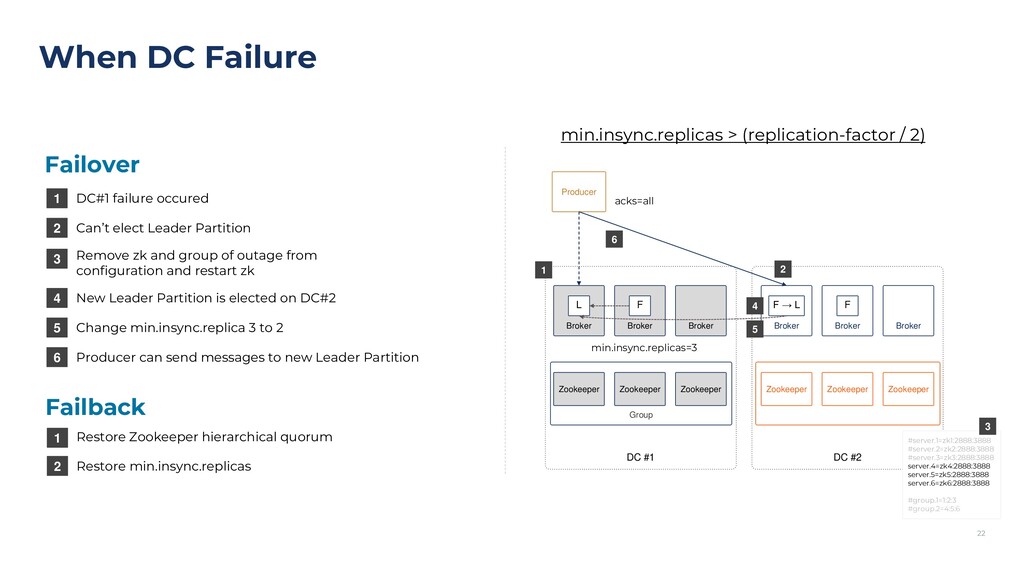{kind=link}
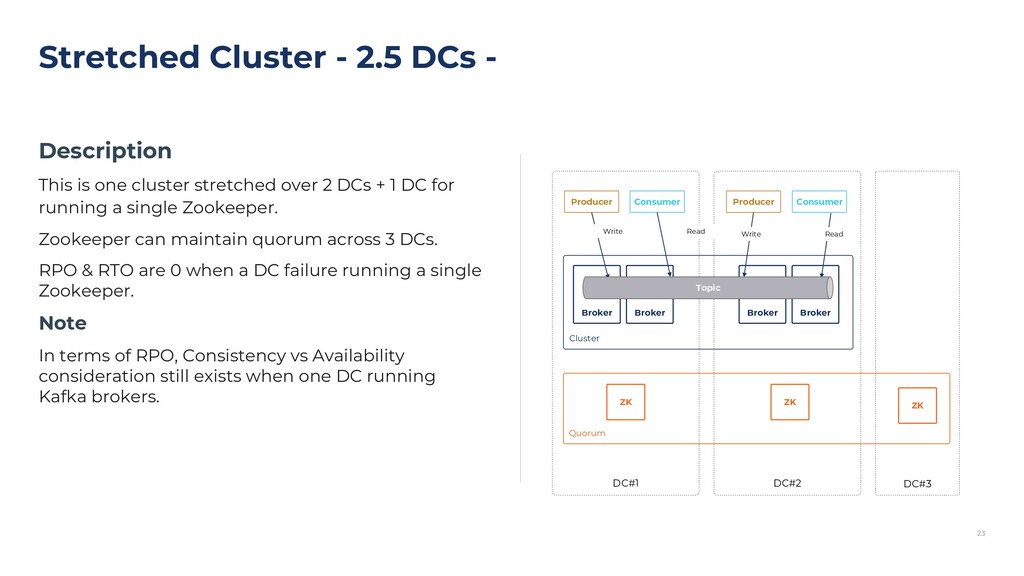{kind=link}
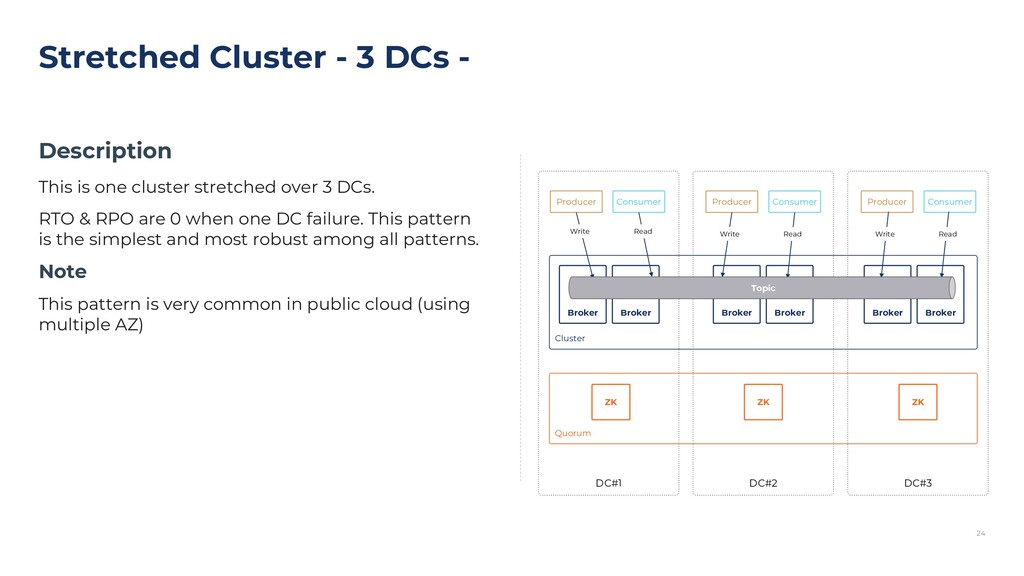{kind=link}
{kind=link}
{kind=link}
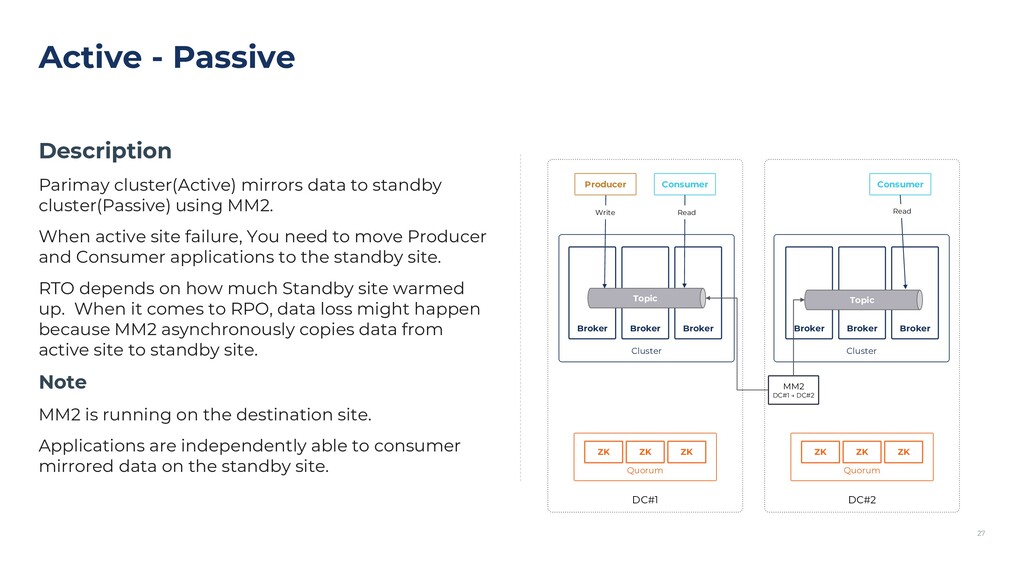{kind=link}
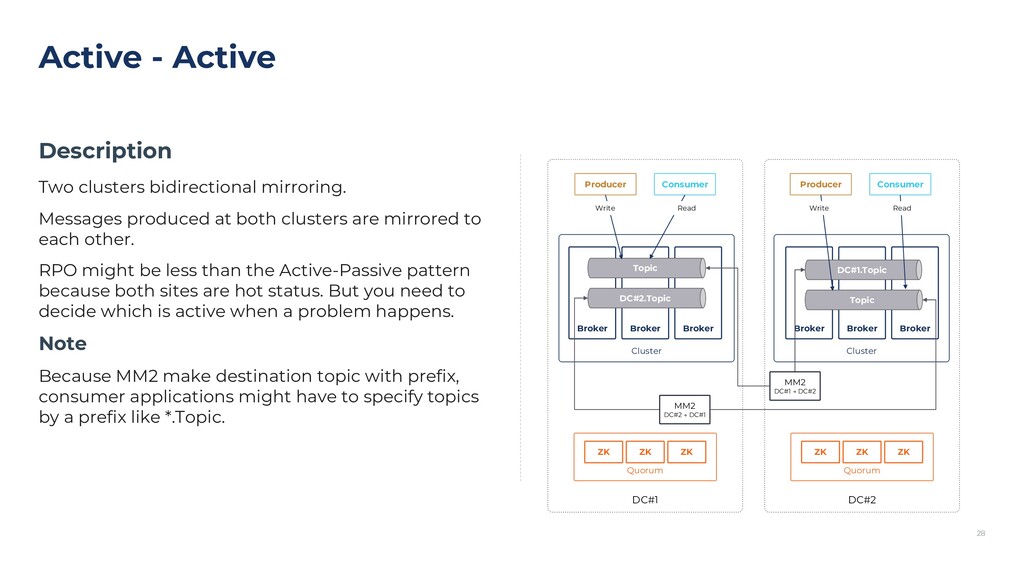{kind=link}
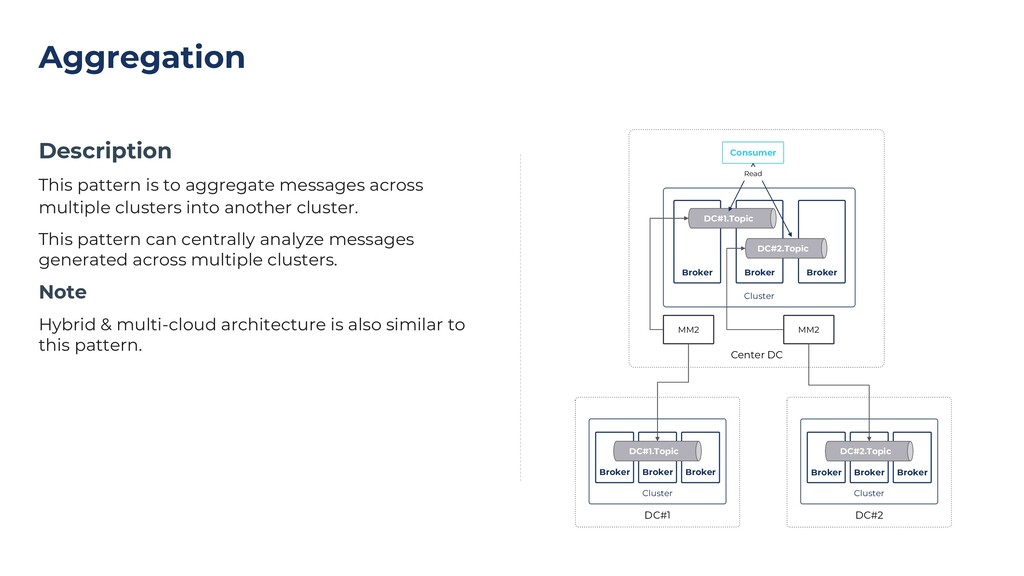{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}