Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
[FIT22]Flare Transformer Regressor: Solar Flare...
Search
Sponsored
·
SiteGround - Reliable hosting with speed, security, and support you can count on.
→
Semantic Machine Intelligence Lab., Keio Univ.
PRO
September 11, 2022
Technology
1.2k
0
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
[FIT22]Flare Transformer Regressor: Solar Flare Prediction Based on Masked Autoencoder and Informer Decoder
Semantic Machine Intelligence Lab., Keio Univ.
PRO
September 11, 2022
More Decks by Semantic Machine Intelligence Lab., Keio Univ.
See All by Semantic Machine Intelligence Lab., Keio Univ.
[Journal club] Predict Before You Explore: Predictive Planning with Specialized Memory for Embodied Question Answering
keio_smilab
PRO
0
81
[Journal club] PHyCLIP: 𝒍𝟏-Product of Hyperbolic Factors Unifies Hierarchy and Compositionality in Vision-Language Representation Learning
keio_smilab
PRO
0
86
[Journal club] ReMEmbR: Building and Reasoning Over Long-Horizon Spatio-Temporal Memory for Robot Navigation
keio_smilab
PRO
0
110
[Journal club] ReLaGS: Relational Language Gaussian Splatting
keio_smilab
PRO
0
120
[Journal club] Flow as the Cross-Domain Manipulation Interface
keio_smilab
PRO
0
98
Mobi-𝜋: Mobilizing Your Robot Learning Policy
keio_smilab
PRO
0
160
A Gentle Introduction to Transformers
keio_smilab
PRO
16
7k
FlowAR: Scale-wise Autoregressive Image Generation Meets Flow Matching
keio_smilab
PRO
0
60
[Journal club] VLA-Adapter: An Effective Paradigm for Tiny-Scale Vision-Language-Action Model
keio_smilab
PRO
1
150
Other Decks in Technology
See All in Technology
JAWS_ICEBERG_BASECAMP
iqbocchi
2
110
Alphaモジュール使っていいのかい!?いけないのかい!?どっちなんだいっ!?
watany
1
320
発表と総括 / Presentations and Summary
ks91
PRO
0
190
AIが当たり前の組織で エンジニアはどう育つか
nishihira
1
970
Type-safe IaC for Dart
coborinai
0
180
Multicaで30個のミニプロジェクトをAIエージェント運用して見えてきたこと
eiei114
1
630
インシデント事例と パッケージの全量解析に学ぶ ソフトウェアサプライチェーンの守り方 / supply-chain-attack-defense
flatt_security
0
890
伝票作成AIエージェントを支える、LLMOpsとインフラの選択肢 / AICon2026_takeda
rakus_dev
0
260
プロダクト開発組織の現在地(Ver.2026/07) / product-organization
kaonavi
0
400
データと地図で読む 大井町の「かわるもの、かわらないもの」
yoshiyama_hana
0
140
CDKで書くECSのベストプラクティス、 改めて考え直す2026 #cdkconf2026
makies
3
940
Devsumi 2026 Summer 人もAIも使える共通基盤を事業の加速装置にする~デザインシステム運用に学ぶ組織レバレッジ~ 渡辺 凌央
legalontechnologies
PRO
1
280
Featured
See All Featured
AI Search: Where Are We & What Can We Do About It?
aleyda
0
7.7k
Navigating Team Friction
lara
192
16k
Embracing the Ebb and Flow
colly
88
5.1k
Effective software design: The role of men in debugging patriarchy in IT @ Voxxed Days AMS
baasie
0
450
Heart Work Chapter 1 - Part 1
lfama
PRO
8
36k
XXLCSS - How to scale CSS and keep your sanity
sugarenia
249
1.3M
Have SEOs Ruined the Internet? - User Awareness of SEO in 2025
akashhashmi
0
400
[RailsConf 2023] Rails as a piece of cake
palkan
59
6.8k
Odyssey Design
rkendrick25
PRO
2
730
Docker and Python
trallard
47
4k
Bridging the Design Gap: How Collaborative Modelling removes blockers to flow between stakeholders and teams @FastFlow conf
baasie
0
620
Sam Torres - BigQuery for SEOs
techseoconnect
PRO
0
440
Transcript
Flare Transformer Regressor: Masked Autoencoderと Informer Decoderに基づく 太陽フレア予測 九曜克之1 和⽥唯我1
, 兼⽥寛⼤ 1, 飯⽥紡 1, ⻄塚直⼈ 2, 久保勇樹 2, 杉浦孔明 1 1 慶應義塾⼤学,2 NICT
背景:⼤規模な太陽フレアは甚⼤な被害をもたらす - 2 - 太陽フレア:太陽表⾯上の⿊点周辺で発⽣する爆発現象 太陽フレアによる被害 発⽣を事前に予測できれば, 被害を最⼩限に抑えることが可能 1989年 カナダ・ケベック州の⼤規模停電
2003年 ⼩惑星探査機はやぶさに損傷 2022年 SpaceXの衛星49基中40基が落下 (⽇経新聞2022/4/26) 保険会社による被害予想額 ⇒ 約1600億ドル@北⽶ 太陽フレア予測は⾮常に重要 NASA, https://svs.gsfc.nasa.gov/4491
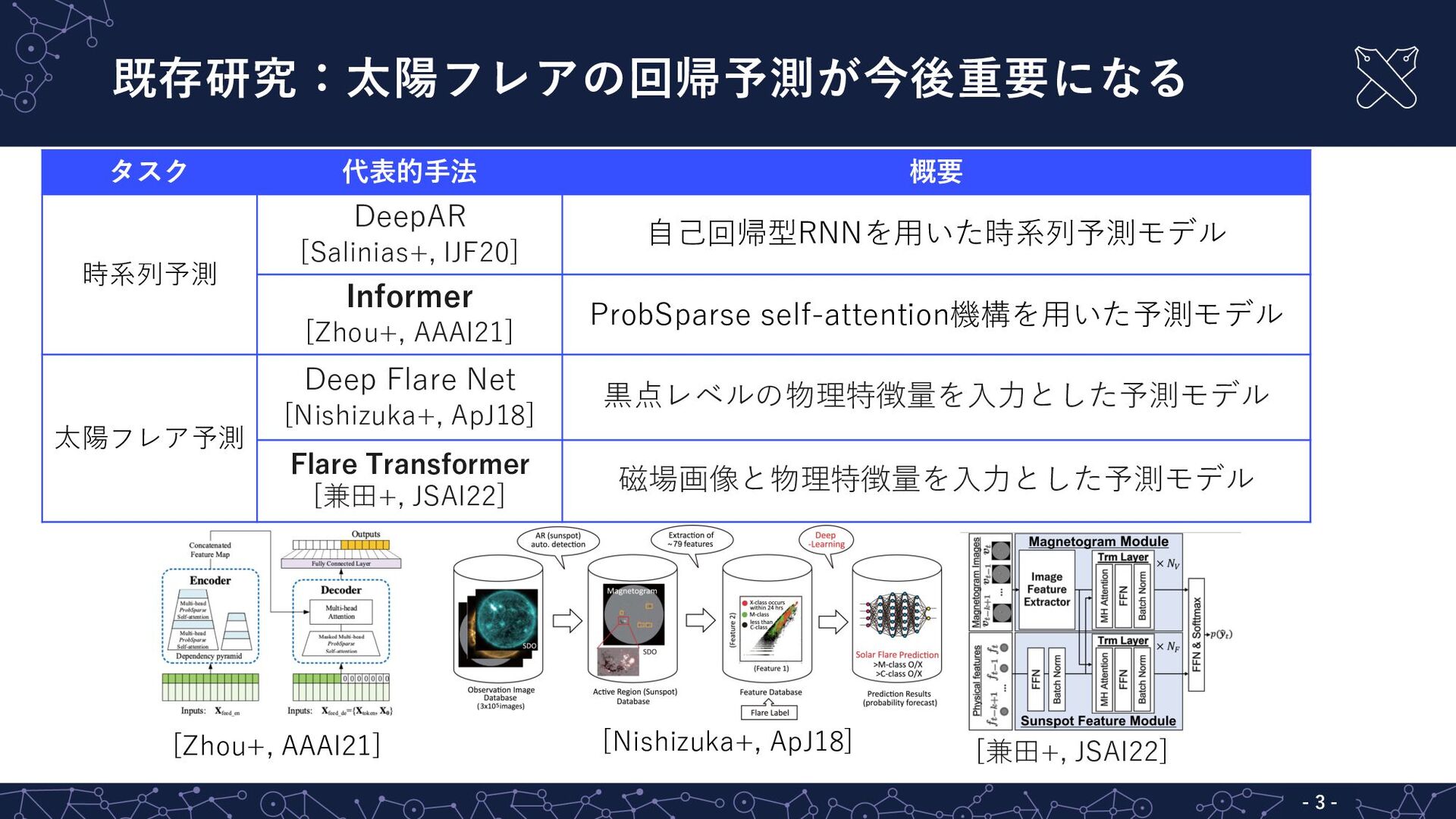
既存研究:太陽フレアの回帰予測が今後重要になる - 3 - タスク 代表的⼿法 概要 時系列予測 DeepAR [Salinias+,
IJF20] ⾃⼰回帰型RNNを⽤いた時系列予測モデル Informer [Zhou+, AAAI21] ProbSparse self-attention機構を⽤いた予測モデル 太陽フレア予測 Deep Flare Net [Nishizuka+, ApJ18] ⿊点レベルの物理特徴量を⼊⼒とした予測モデル Flare Transformer [兼⽥+, JSAI22] 磁場画像と物理特徴量を⼊⼒とした予測モデル [Zhou+, AAAI21] [Nishizuka+, ApJ18] [兼⽥+, JSAI22]
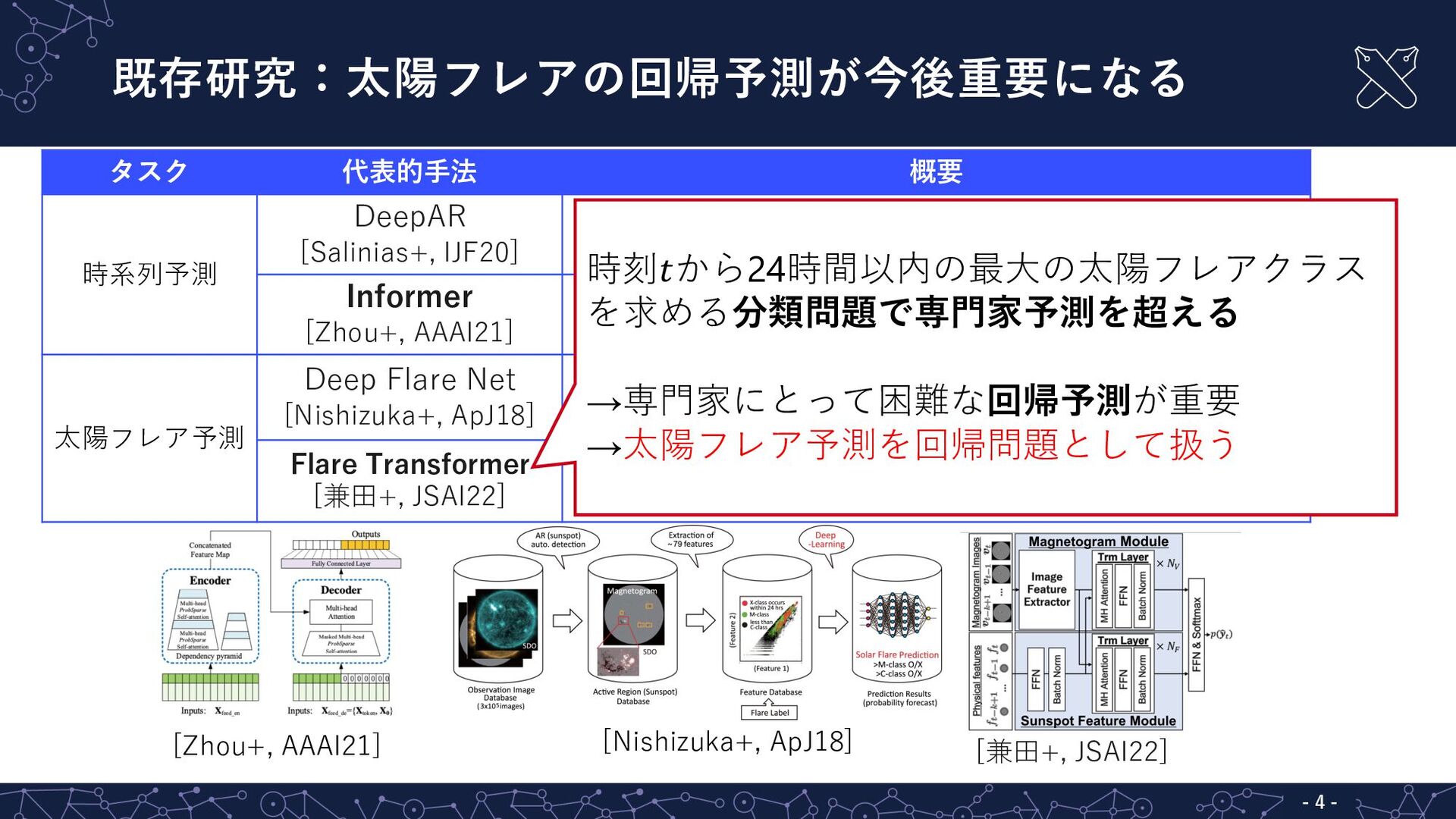
既存研究:太陽フレアの回帰予測が今後重要になる - 4 - タスク 代表的⼿法 概要 時系列予測 DeepAR [Salinias+,
IJF20] ⾃⼰回帰型RNNを⽤いた時系列予測モデル Informer [Zhou+, AAAI21] ProbSparse self-attention機構を⽤いた予測モデル 太陽フレア予測 Deep Flare Net [Nishizuka+, ApJ18] ⿊点レベルの物理特徴量を⼊⼒とした予測モデル Flare Transformer [兼⽥+, JSAI22] 磁場画像と物理特徴量を⼊⼒とした予測モデル [Zhou+, AAAI21] [Nishizuka+, ApJ18] [兼⽥+, JSAI22] 時刻𝑡から24時間以内の最⼤の太陽フレアクラス を求める分類問題で専⾨家予測を超える →専⾨家にとって困難な回帰予測が重要 →太陽フレア予測を回帰問題として扱う
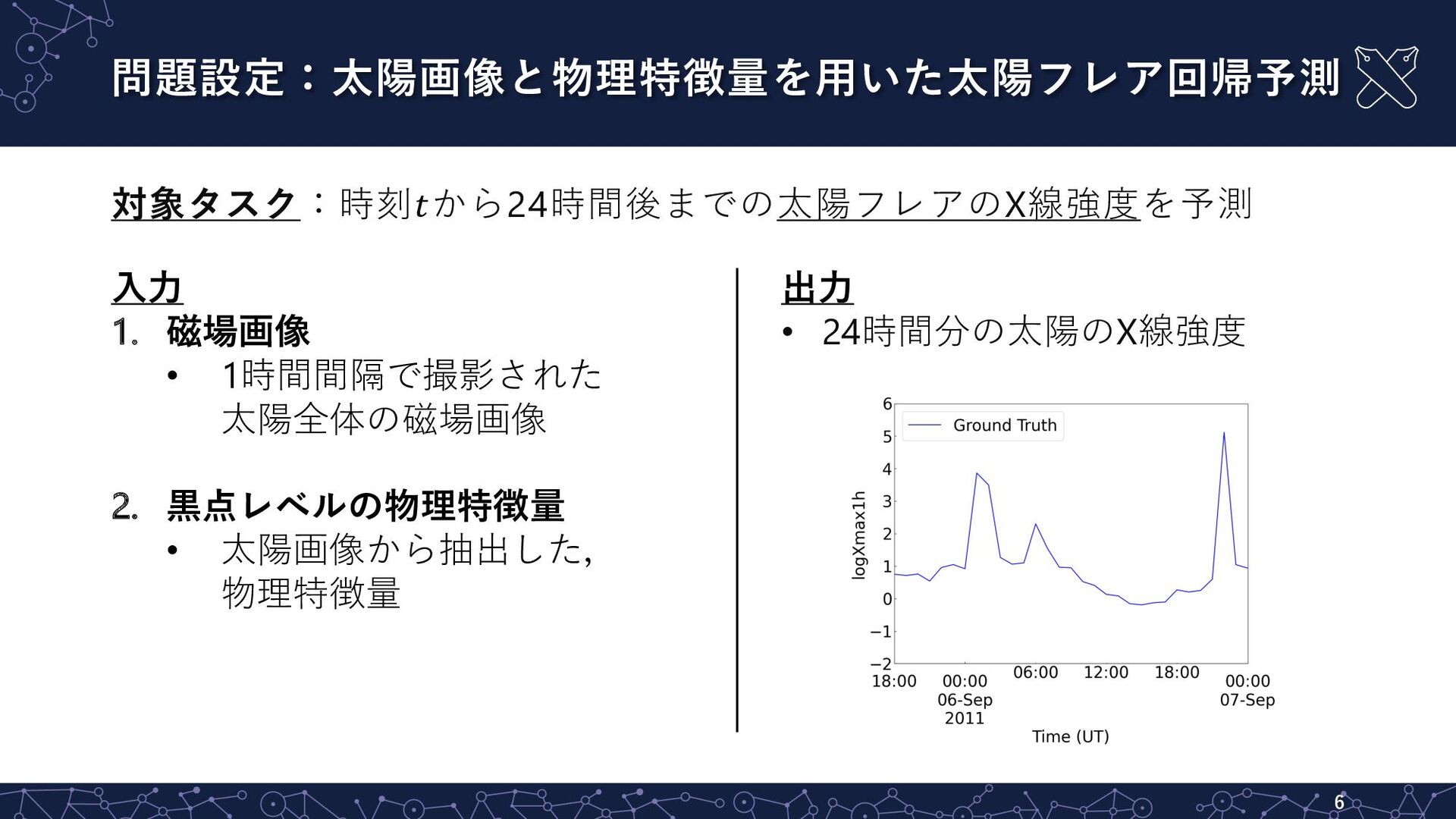
問題設定:太陽画像と物理特徴量を⽤いた太陽フレア回帰予測 5 対象タスク:時刻𝑡から24時間後までの太陽フレアのX線強度を予測 ⼊⼒ 1. 磁場画像 • 1時間間隔で撮影された 太陽全体の磁場画像 2.
⿊点レベルの物理特徴量 • 太陽画像から抽出した, 物理特徴量
出⼒ • 24時間分の太陽のX線強度 問題設定:太陽画像と物理特徴量を⽤いた太陽フレア回帰予測 6 対象タスク:時刻𝑡から24時間後までの太陽フレアのX線強度を予測 ⼊⼒ 1. 磁場画像 •
1時間間隔で撮影された 太陽全体の磁場画像 2. ⿊点レベルの物理特徴量 • 太陽画像から抽出した, 物理特徴量
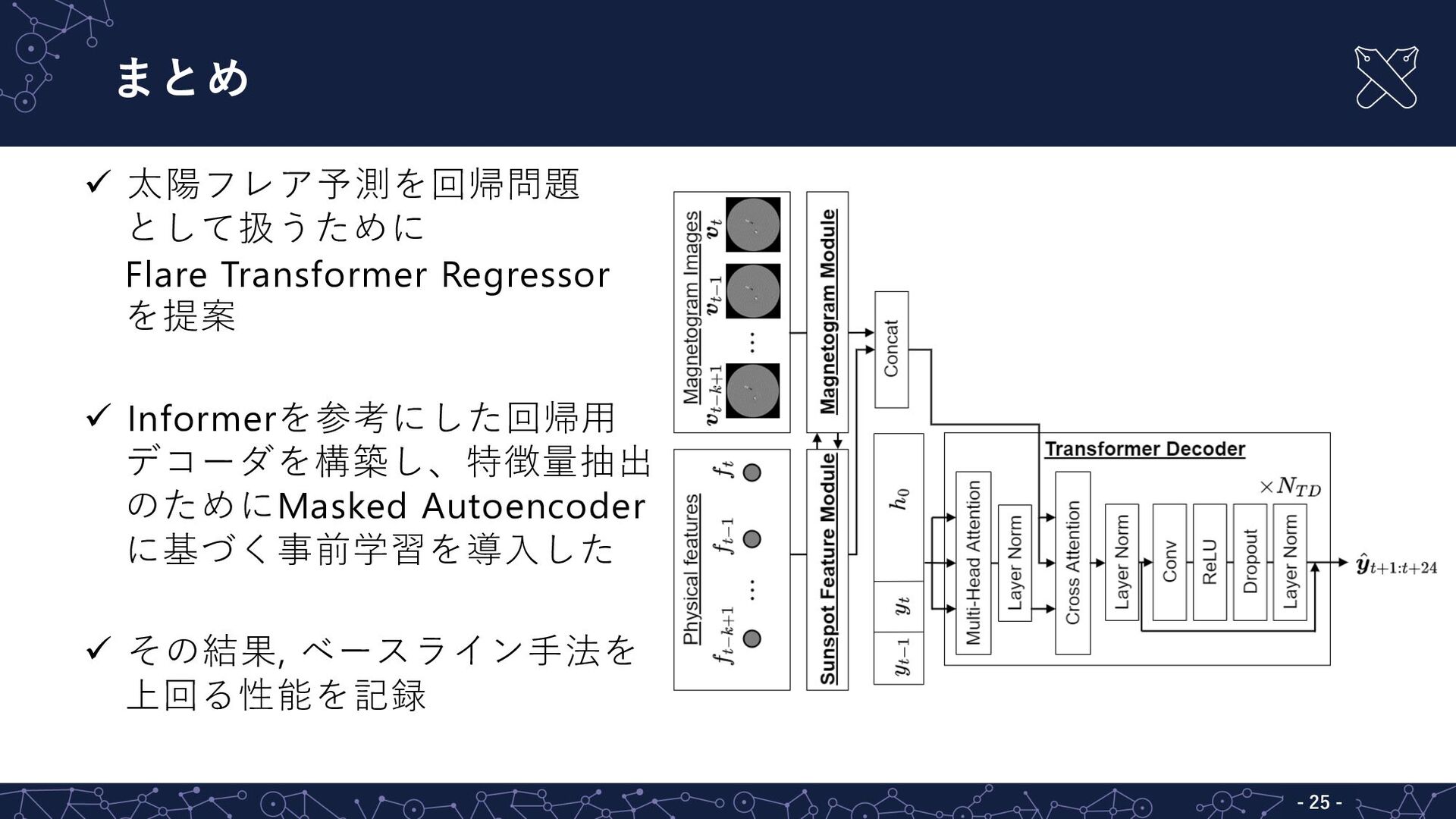
提案⼿法:Flare Transformer Regressor 7 新規性 1. Masked Autoencoder[He+, CVPR22]で事前学習したVision Transformer[Dosovitskiy+,
ICLR21]を導⼊ 2. Informer[Zhou+, AAAI21]を参考にした回帰⽤デコーダを 構築
提案⼿法:Flare Transformer Regressor 8 新規性 1. Masked Autoencoder[He+, CVPR22]で事前学習したVision Transformer[Dosovitskiy+,
ICLR21]を導⼊ 2. Informer[Zhou+, AAAI21]を参考にした回帰⽤デコーダを 構築
提案⼿法:Flare Transformer Regressor 9 新規性 1. Masked Autoencoder[He+, CVPR22]で事前学習したVision Transformer[Dosovitskiy+,
ICLR21]を導⼊ 2. Informer[Zhou+, AAAI21]を参考にした回帰⽤デコーダを 構築
磁場画像と物理特徴量を⼊⼒,24時間後までのX線強度を出⼒ - ⼊⼒ 時刻 から に おける磁場画像および 90種類の物理特徴量 10 -
出⼒ 時刻𝑡から24時間後まで におけるX線強度の 対数値
• Masked Autoencoder(MAE)[He+, CVPR22]に基づき磁場画像の再構成を⾏う • 画像パッチの⼀部を除去(⿊い部分)して元画像を再構成 • [He+, CVPR22]と異なり,画像パッチ内の標準偏差をもとに除去するパッチを選択する 新規性①:パッチ内の標準偏差に基づき再構成する事前学習
Lスパースな重要領域の情報が⽋如 パッチサイズに対し重要領域は⼩さいため 周囲の情報から再構成することは極めて困難 Jスパースな重要領域が 除去されにくい 元画像 ランダムで除去 [He+, CVPR22] パッチ内標準偏差を基に除去 重要領域
• Masked Autoencoder(MAE)[He+, CVPR22]に基づき磁場画像の再構成を⾏う • 画像パッチの⼀部を除去(⿊い部分)して元画像を再構成 • [He+, CVPR22]と異なり,画像パッチ内の標準偏差をもとに除去するパッチを選択する 新規性①:パッチ内の標準偏差に基づき再構成する事前学習
元画像 ランダムで除去 [He+, CVPR22] パッチ内標準偏差を基に除去 重要領域
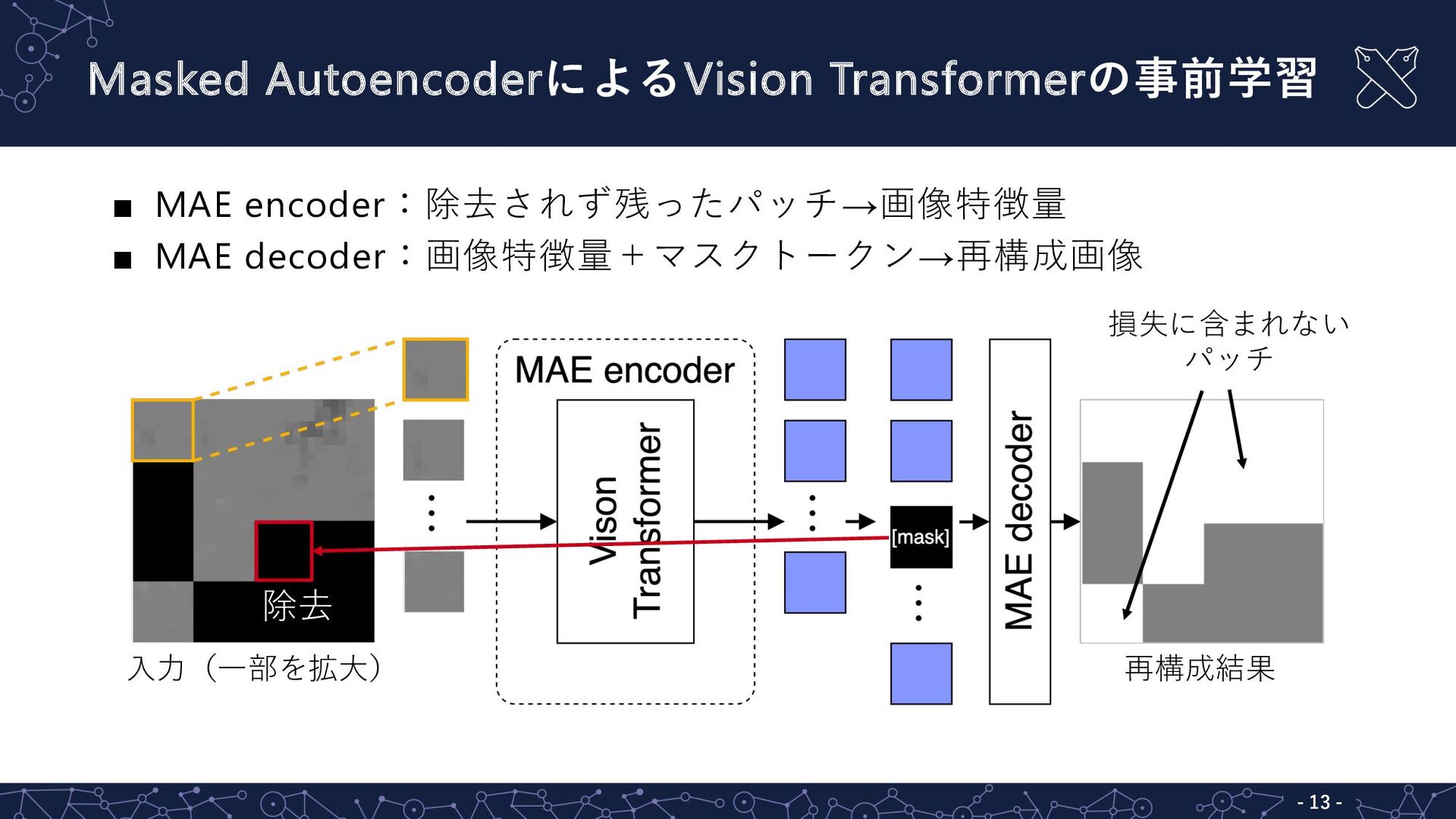
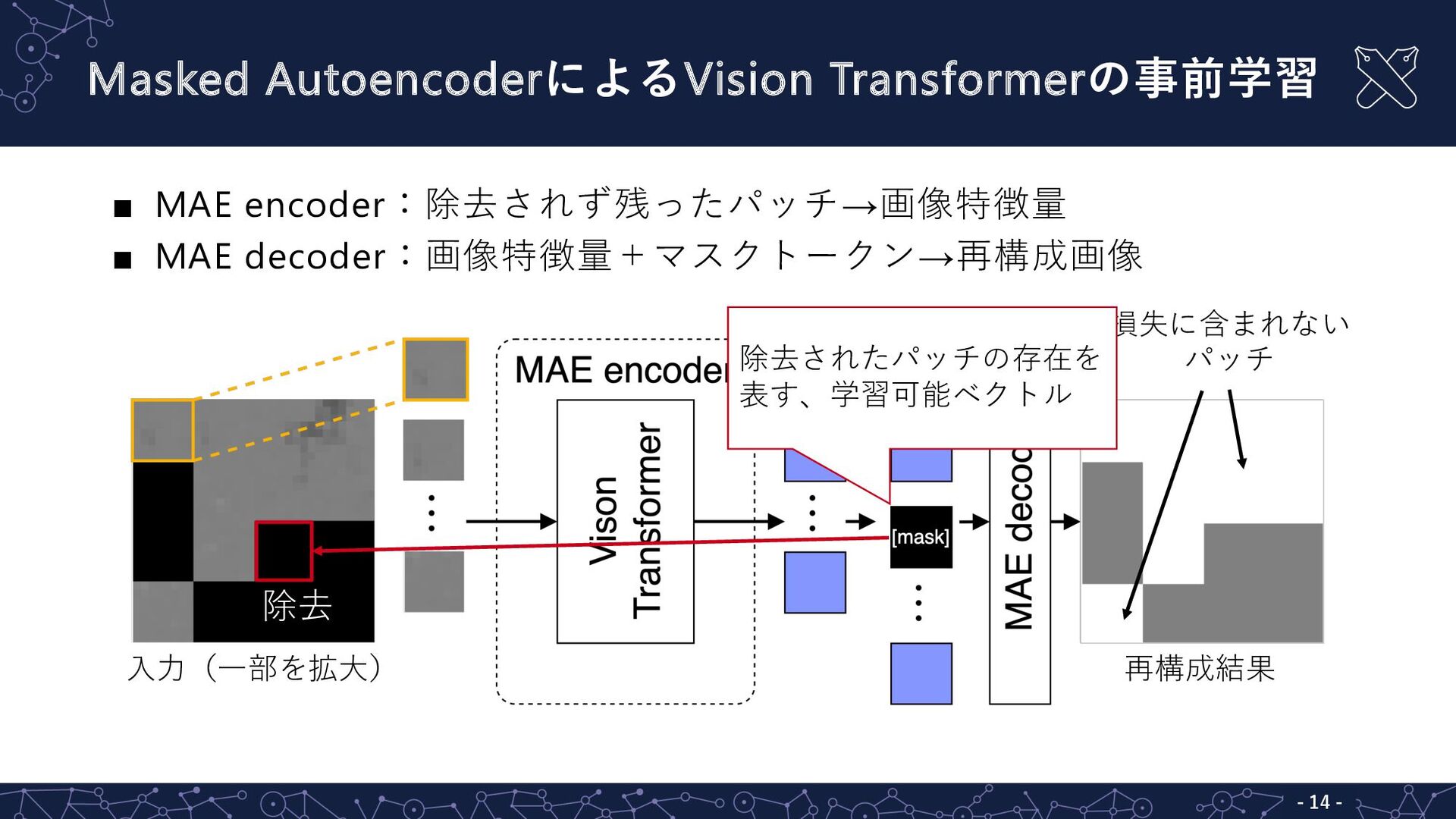
損失に含まれない パッチ Masked AutoencoderによるVision Transformerの事前学習 - 13 - ▪ MAE
encoder:除去されず残ったパッチ→画像特徴量 ▪ MAE decoder:画像特徴量+マスクトークン→再構成画像 ⼊⼒(⼀部を拡⼤) 再構成結果 除去
損失に含まれない パッチ Masked AutoencoderによるVision Transformerの事前学習 - 14 - ▪ MAE
encoder:除去されず残ったパッチ→画像特徴量 ▪ MAE decoder:画像特徴量+マスクトークン→再構成画像 ⼊⼒(⼀部を拡⼤) 再構成結果 除去 除去されたパッチの存在を 表す、学習可能ベクトル
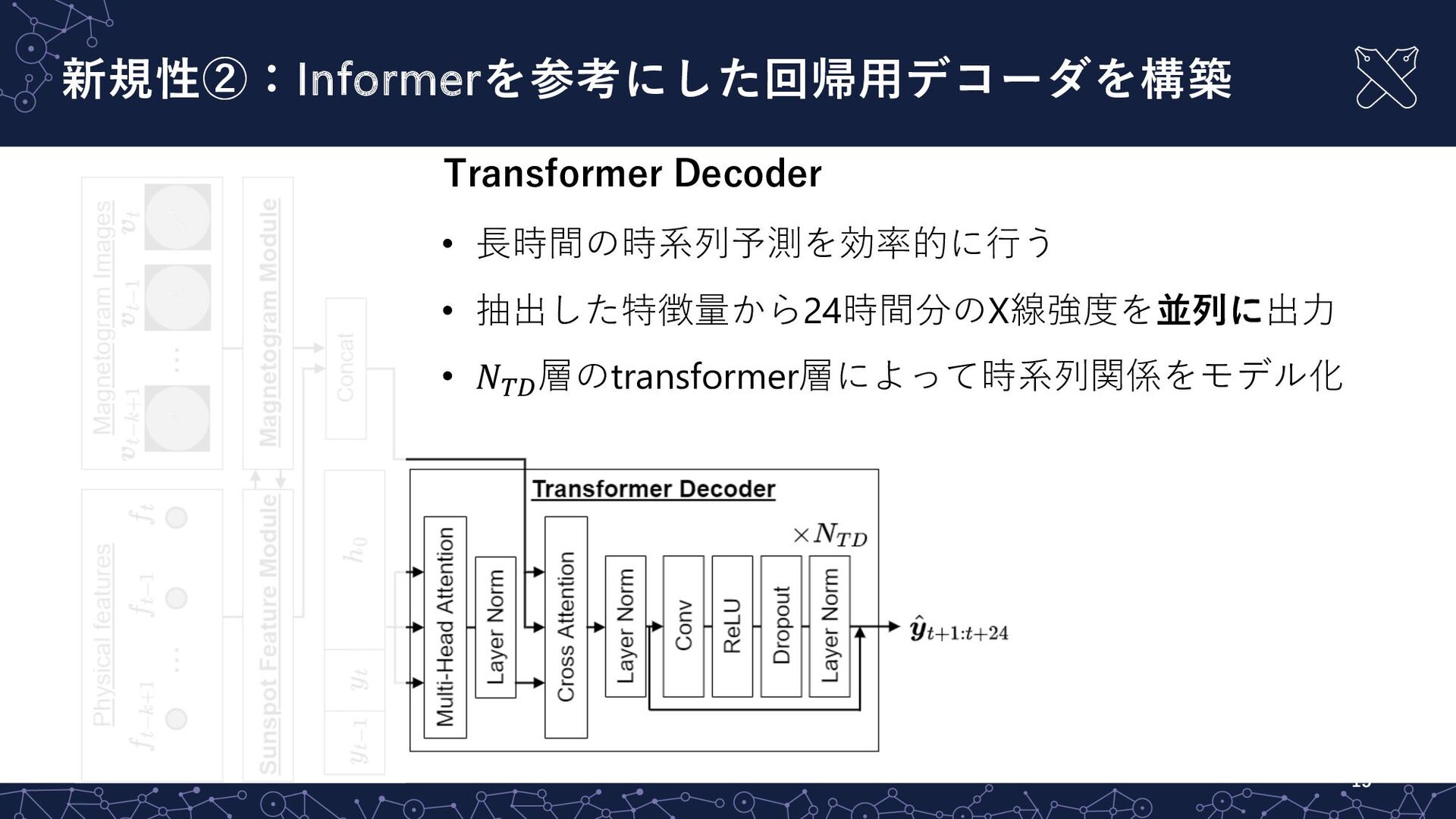
新規性②:Informerを参考にした回帰⽤デコーダを構築 15 Transformer Decoder • ⻑時間の時系列予測を効率的に⾏う • 抽出した特徴量から24時間分のX線強度を並列に出⼒ • 𝑁!"
層のtransformer層によって時系列関係をモデル化
実験設定:テスト集合は必ず訓練集合より未来のデータ 16 ▪ 2010-2017年における合計61315サンプル ▪ 1h間隔の磁場画像と90種の物理特徴量のセット ▪ 時系列交差検証[Tashman+, 00]をベースとした分割 Training
Set Validation Set Test Set 期間 サンプル数 期間 サンプル数 期間 サンプル数 2010-2013 29247 2014 8127 2015 8155 2010-2014 37374 2015 8155 2016 7795 2010-2015 45529 2016 7795 2017 7991 磁場画像 物理特徴量
定量的結果:ベースラインを上回る予測性能を達成 17 平均予測軌道誤差において, ベースライン⼿法であるFlare Transformerを上回る性能を達成 平均予測軌道誤差↓ Flare Transformer[Kaneda+, JSAI22] 1.06±0.44
提案⼿法 0.48±0.03 提案⼿法(修正版) 0.41±0.04 平均予測軌道誤差 " 𝐸!"#:!"%& (𝑁:サンプル数) " 𝐸!"#:!"%& = 1 24𝑁 ) '(# ) ) *(# %& (Ground Truth)!"* (') −(予測値)!"* (') J0.65pt 改善
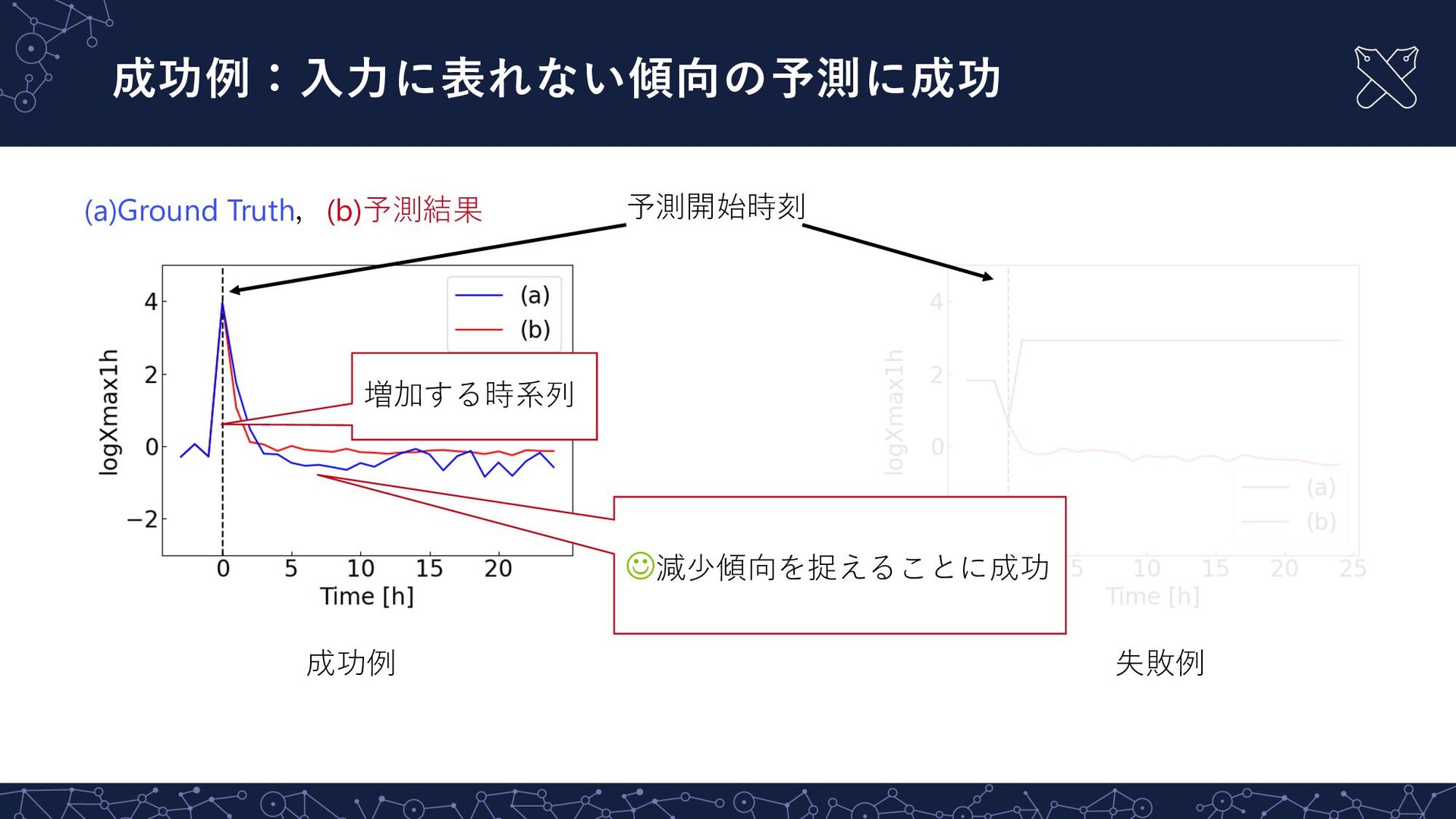
成功例:⼊⼒に表れない傾向の予測に成功 (a)Ground Truth,(b)予測結果 増加する時系列 成功例 失敗例 J減少傾向を捉えることに成功 予測開始時刻
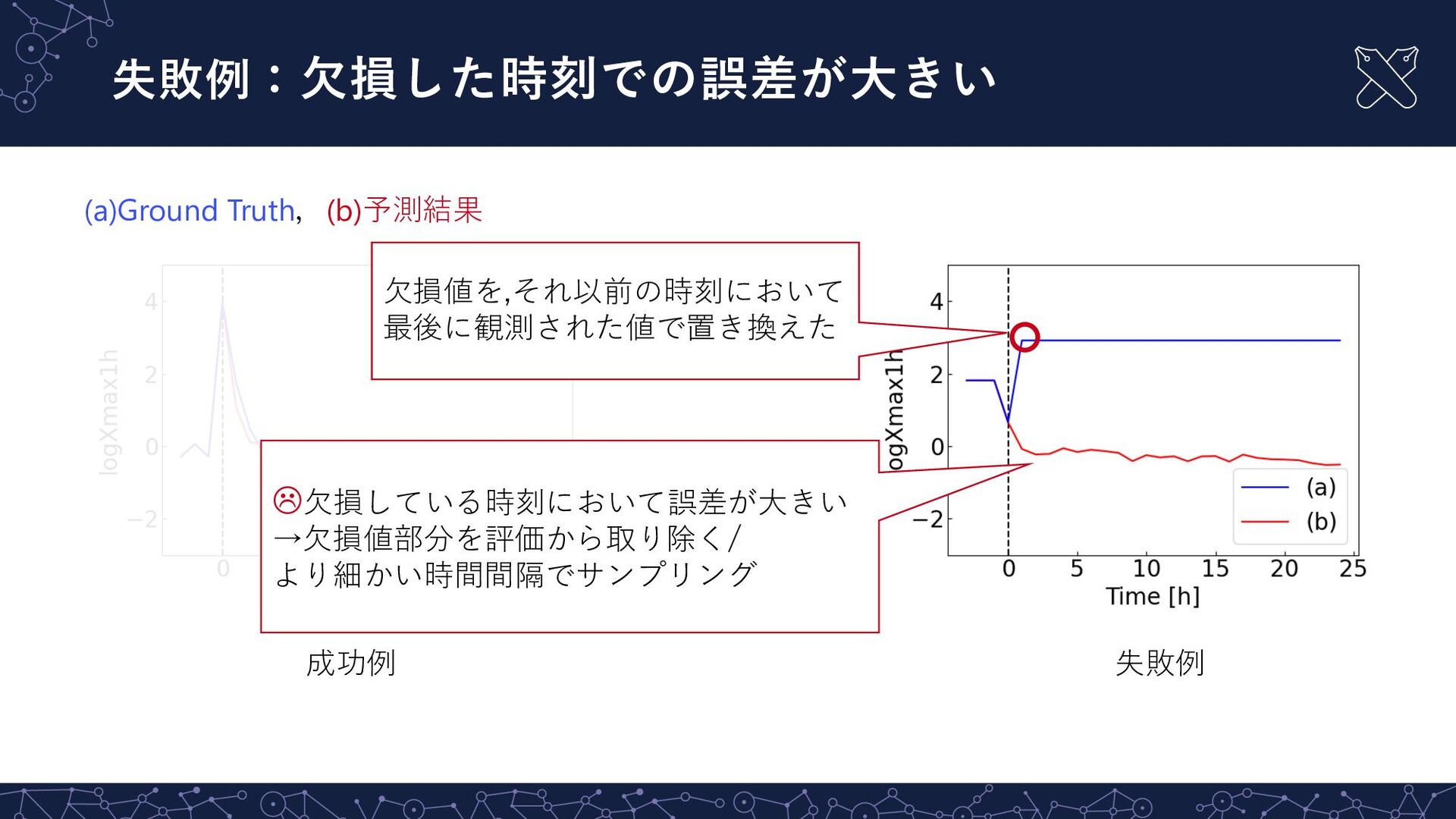
失敗例:⽋損した時刻での誤差が⼤きい (a)Ground Truth,(b)予測結果 ⽋損値を,それ以前の時刻において 最後に観測された値で置き換えた 成功例 失敗例 L⽋損している時刻において誤差が⼤きい →⽋損値部分を評価から取り除く/ より細かい時間間隔でサンプリング
Ablation Studies:ViTの導⼊が性能向上に寄与 20 Attention ⼊⼒系列⻑ 平均予測軌道誤差↓ 提案⼿法(修正版) Full 4 0.41±0.04
(a)ViT→CNN Full 4 0.54±0.12 (b) Full 8 0.41±0.04 (c) Full 12 0.42±0.04 (d) ProbSparse 4 0.44±0.03 (e) ProbSparse 8 0.41±0.04 (f) ProbSparse 12 0.41±0.04 L0.13pt 悪化 Ablation(a):ViTを,Frare TransformerにおけるCNNで構成される特徴抽出器 へと置き換えた場合 →MAEで事前学習を⾏ったViTを導⼊したことが性能向上に寄与
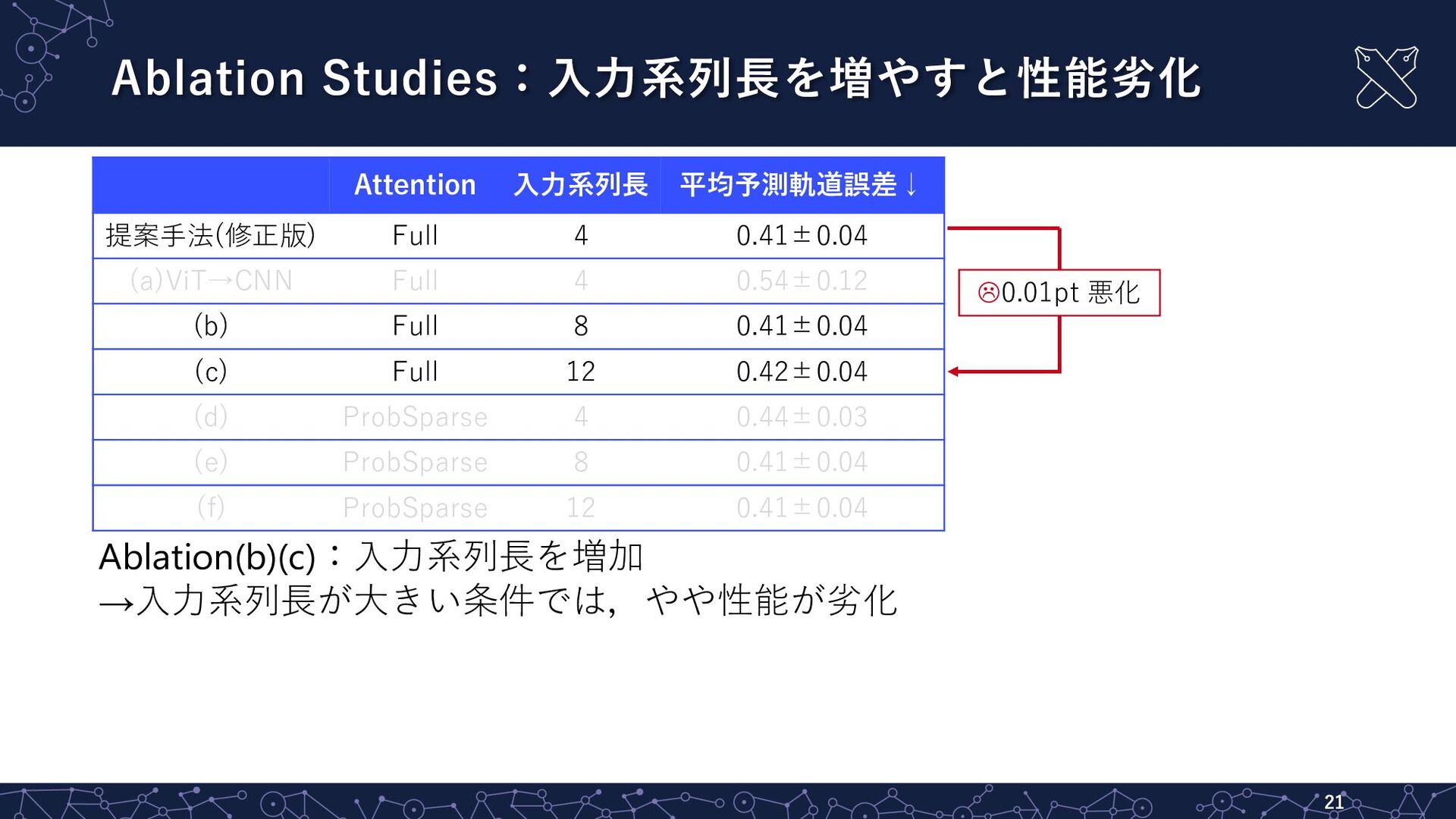
Ablation Studies:⼊⼒系列⻑を増やすと性能劣化 21 Attention ⼊⼒系列⻑ 平均予測軌道誤差↓ 提案⼿法(修正版) Full 4 0.41±0.04
(a)ViT→CNN Full 4 0.54±0.12 (b) Full 8 0.41±0.04 (c) Full 12 0.42±0.04 (d) ProbSparse 4 0.44±0.03 (e) ProbSparse 8 0.41±0.04 (f) ProbSparse 12 0.41±0.04 Ablation(b)(c):⼊⼒系列⻑を増加 →⼊⼒系列⻑が⼤きい条件では,やや性能が劣化 L0.01pt 悪化
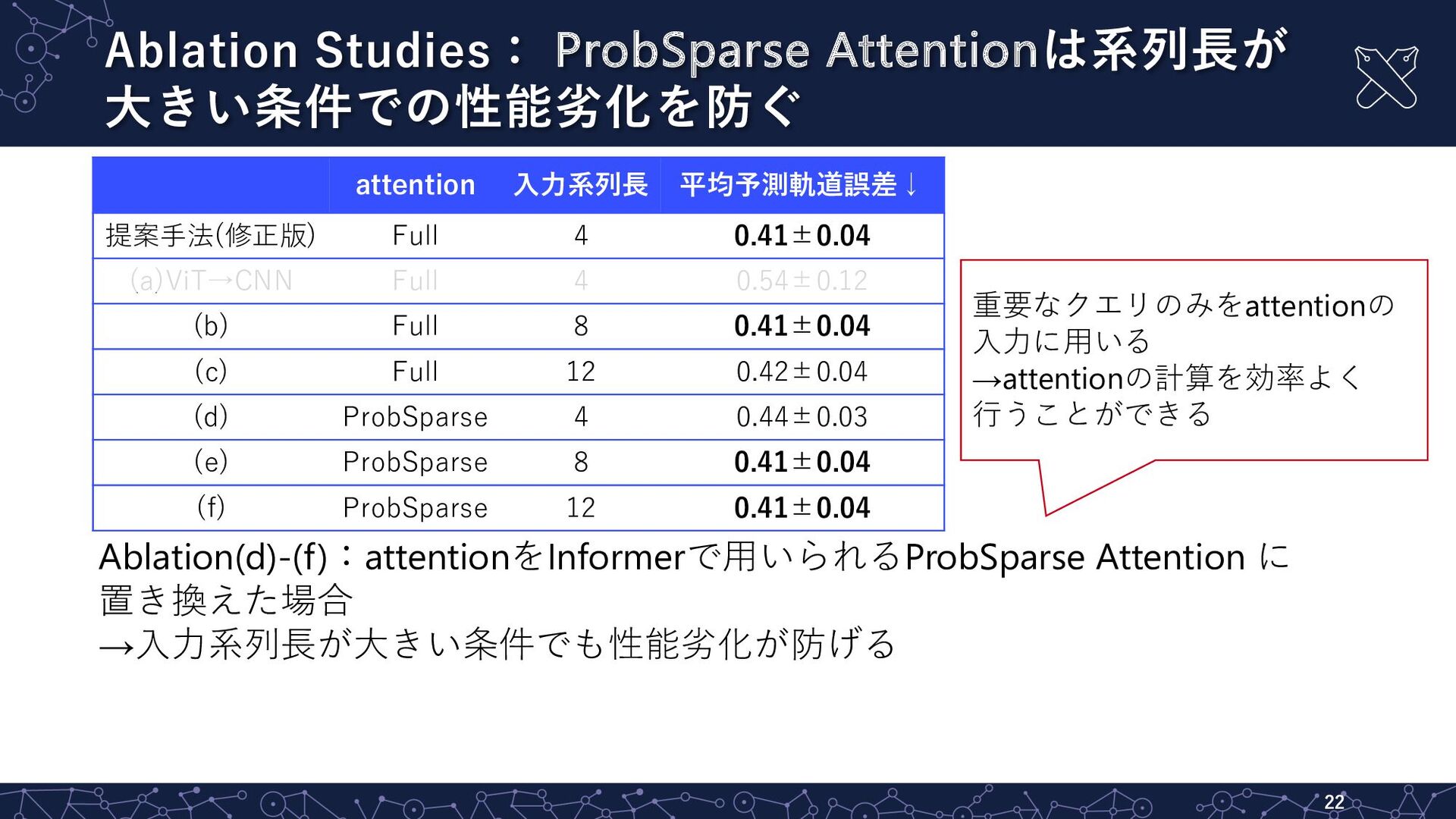
Ablation Studies: ProbSparse Attentionは系列⻑が ⼤きい条件での性能劣化を防ぐ 22 attention ⼊⼒系列⻑ 平均予測軌道誤差↓ 提案⼿法(修正版)
Full 4 0.41±0.04 (a)ViT→CNN Full 4 0.54±0.12 (b) Full 8 0.41±0.04 (c) Full 12 0.42±0.04 (d) ProbSparse 4 0.44±0.03 (e) ProbSparse 8 0.41±0.04 (f) ProbSparse 12 0.41±0.04 Ablation(d)-(f):attentionをInformerで⽤いられるProbSparse Attention に 置き換えた場合 →⼊⼒系列⻑が⼤きい条件でも性能劣化が防げる 重要なクエリのみをattentionの ⼊⼒に⽤いる →attentionの計算を効率よく ⾏うことができる
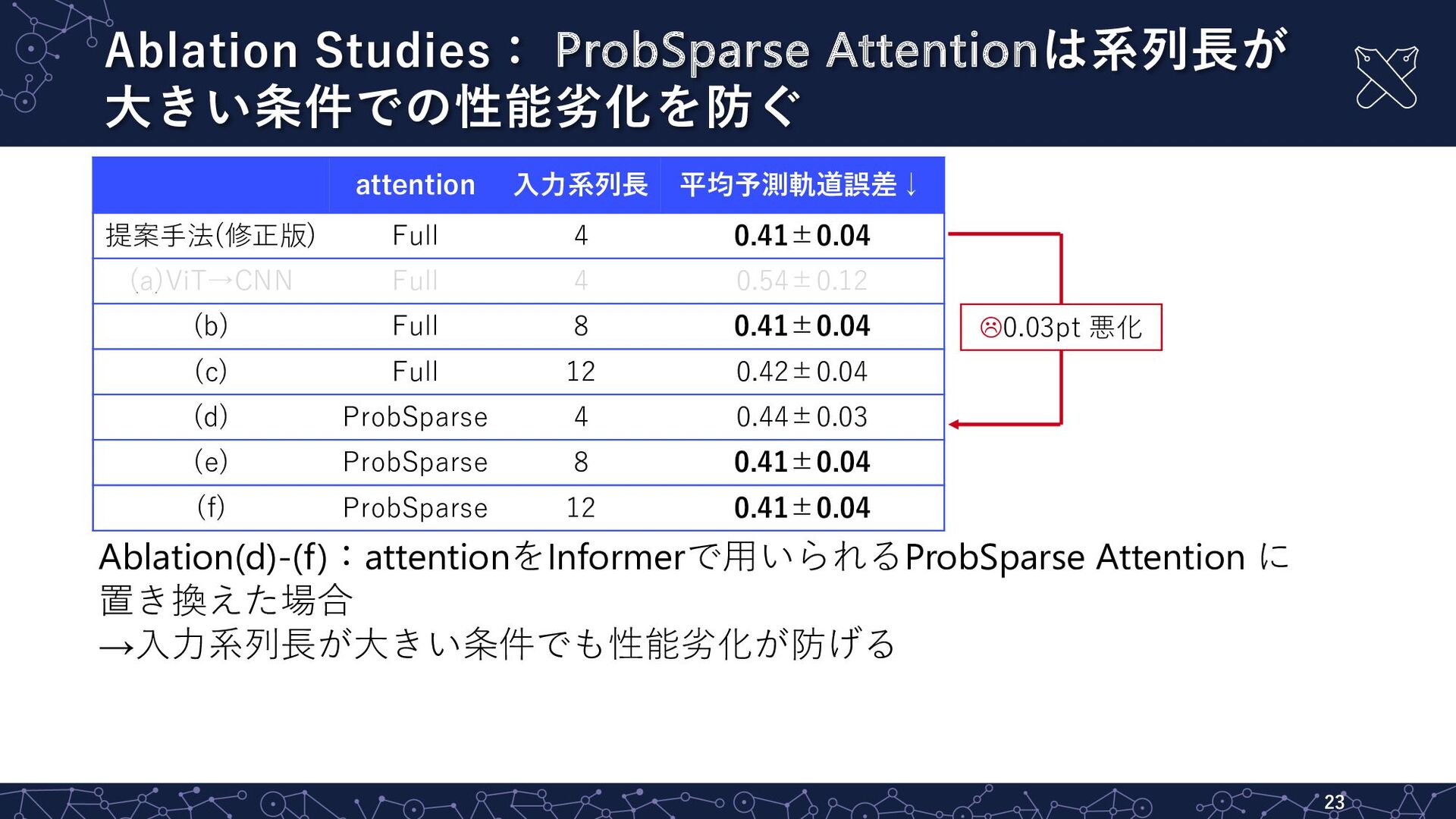
Ablation Studies: ProbSparse Attentionは系列⻑が ⼤きい条件での性能劣化を防ぐ 23 attention ⼊⼒系列⻑ 平均予測軌道誤差↓ 提案⼿法(修正版)
Full 4 0.41±0.04 (a)ViT→CNN Full 4 0.54±0.12 (b) Full 8 0.41±0.04 (c) Full 12 0.42±0.04 (d) ProbSparse 4 0.44±0.03 (e) ProbSparse 8 0.41±0.04 (f) ProbSparse 12 0.41±0.04 Ablation(d)-(f):attentionをInformerで⽤いられるProbSparse Attention に 置き換えた場合 →⼊⼒系列⻑が⼤きい条件でも性能劣化が防げる L0.03pt 悪化
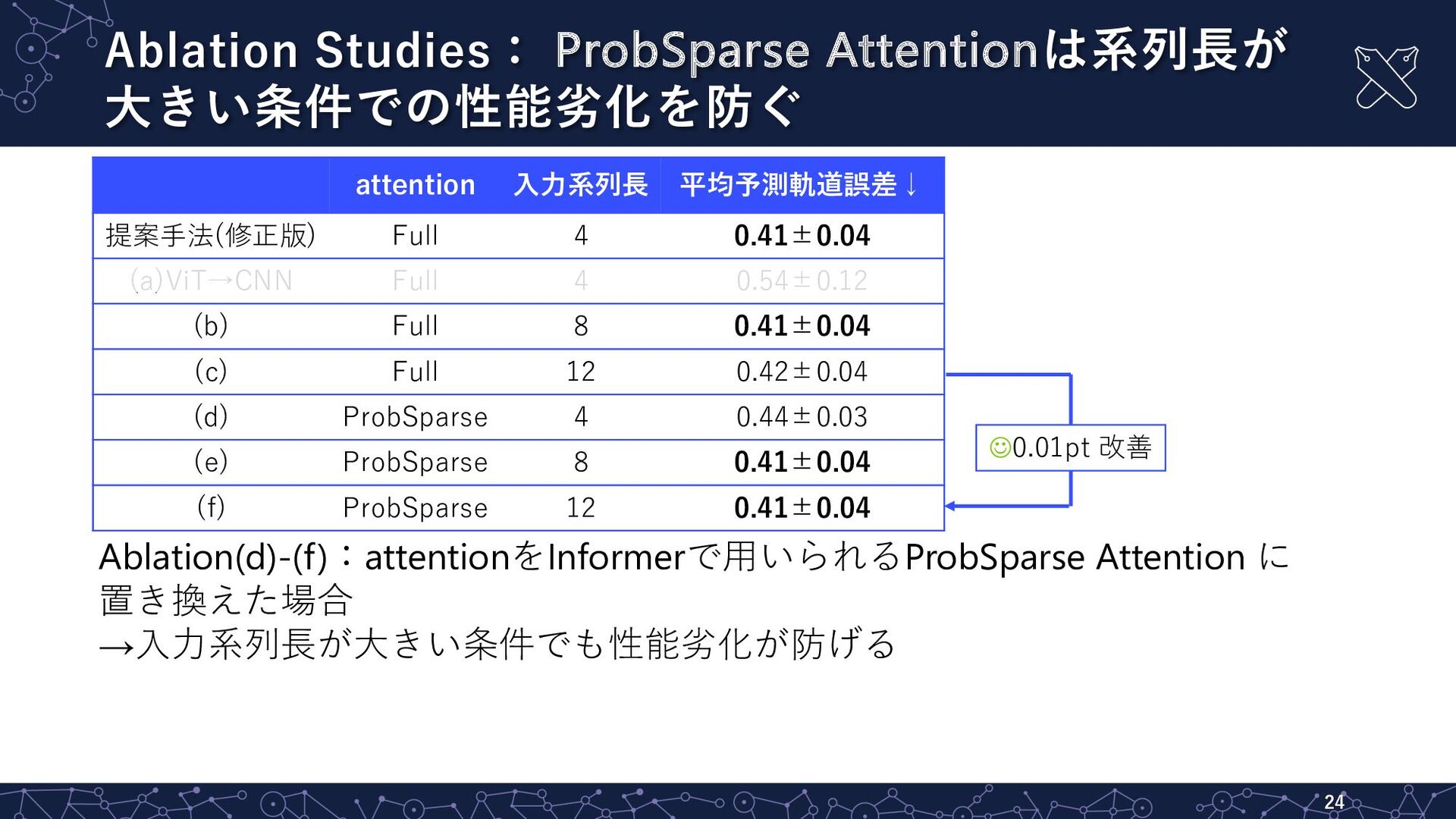
Ablation Studies: ProbSparse Attentionは系列⻑が ⼤きい条件での性能劣化を防ぐ 24 attention ⼊⼒系列⻑ 平均予測軌道誤差↓ 提案⼿法(修正版)
Full 4 0.41±0.04 (a)ViT→CNN Full 4 0.54±0.12 (b) Full 8 0.41±0.04 (c) Full 12 0.42±0.04 (d) ProbSparse 4 0.44±0.03 (e) ProbSparse 8 0.41±0.04 (f) ProbSparse 12 0.41±0.04 Ablation(d)-(f):attentionをInformerで⽤いられるProbSparse Attention に 置き換えた場合 →⼊⼒系列⻑が⼤きい条件でも性能劣化が防げる J0.01pt 改善
まとめ - 25 - ü 太陽フレア予測を回帰問題 として扱うために Flare Transformer Regressor
を提案 ü Informerを参考にした回帰⽤ デコーダを構築し、特徴量抽出 のためにMasked Autoencoder に基づく事前学習を導⼊した ü その結果, ベースライン⼿法を 上回る性能を記録
補⾜:ProbSparse Attention - 26 - ProbSparse Attention 以下のSpacity measurement 𝑀を⽤いて上位𝑢個のクエリのみをAttentionの
計算に使⽤. →系列⻑ L に対して計算量𝑂(𝐿 log 𝐿 ) で計算 できる.𝑞# ,𝑘# はそれぞれ ク エリ⾏列,キー⾏列の𝑖⾏⽬を表す. 𝑀 𝑞# , 𝐾 = max $ 𝑞#𝑘% ! 𝑑 − 1 𝐿& 8 %'( )! 𝑞#𝑘% ! 𝑑
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![提案⼿法:Flare Transformer Regressor 7 新規性 1. Masked Autoencoder[He+, CVPR22]で事前学習したVision Transformer[Dosovitskiy+,](https://files.speakerdeck.com/presentations/d848352fa4fa46208e00f5eba65fc919/slide_6.jpg){kind=link}
![提案⼿法:Flare Transformer Regressor 8 新規性 1. Masked Autoencoder[He+, CVPR22]で事前学習したVision Transformer[Dosovitskiy+,](https://files.speakerdeck.com/presentations/d848352fa4fa46208e00f5eba65fc919/slide_7.jpg){kind=link}
![提案⼿法:Flare Transformer Regressor 9 新規性 1. Masked Autoencoder[He+, CVPR22]で事前学習したVision Transformer[Dosovitskiy+,](https://files.speakerdeck.com/presentations/d848352fa4fa46208e00f5eba65fc919/slide_8.jpg){kind=link}
{kind=link}
![• Masked Autoencoder(MAE)[He+, CVPR22]に基づき磁場画像の再構成を⾏う • 画像パッチの⼀部を除去(⿊い部分)して元画像を再構成 • [He+, CVPR22]と異なり,画像パッチ内の標準偏差をもとに除去するパッチを選択する 新規性①:パッチ内の標準偏差に基づき再構成する事前学習](https://files.speakerdeck.com/presentations/d848352fa4fa46208e00f5eba65fc919/slide_10.jpg){kind=link}
![• Masked Autoencoder(MAE)[He+, CVPR22]に基づき磁場画像の再構成を⾏う • 画像パッチの⼀部を除去(⿊い部分)して元画像を再構成 • [He+, CVPR22]と異なり,画像パッチ内の標準偏差をもとに除去するパッチを選択する 新規性①:パッチ内の標準偏差に基づき再構成する事前学習](https://files.speakerdeck.com/presentations/d848352fa4fa46208e00f5eba65fc919/slide_11.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
![実験設定:テスト集合は必ず訓練集合より未来のデータ 16 ▪ 2010-2017年における合計61315サンプル ▪ 1h間隔の磁場画像と90種の物理特徴量のセット ▪ 時系列交差検証[Tashman+, 00]をベースとした分割 Training](https://files.speakerdeck.com/presentations/d848352fa4fa46208e00f5eba65fc919/slide_15.jpg){kind=link}
![定量的結果:ベースラインを上回る予測性能を達成 17 平均予測軌道誤差において, ベースライン⼿法であるFlare Transformerを上回る性能を達成 平均予測軌道誤差↓ Flare Transformer[Kaneda+, JSAI22] 1.06±0.44](https://files.speakerdeck.com/presentations/d848352fa4fa46208e00f5eba65fc919/slide_16.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}