Massaroli2, Eric Nguyen1, Daniel Y. Fu1, Tri Dao1, Stephen Baccus1, Yoshua Bengio2, Stefano Ermon1, Christopher Ré1 (1Stanford University 2Mila and Université de Montréal) 慶應義塾⼤学 杉浦孔明研究室 M1 和⽥唯我 Michael Poli et al., “Hyena Hierarchy: Towards Larger Convolutional Language Models”, arXiv preprint arXiv:2302.10866.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
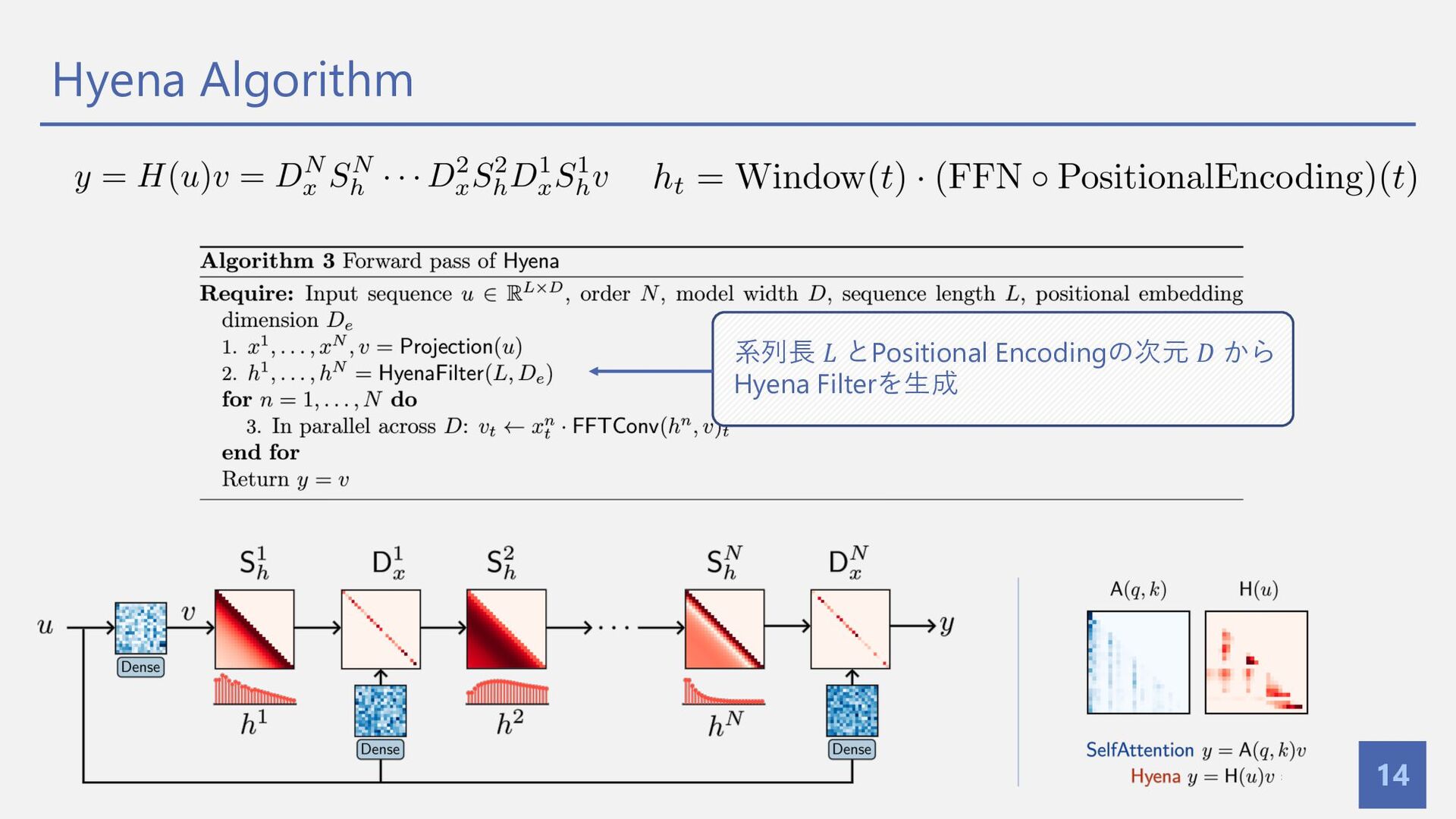{kind=link}
{kind=link}
{kind=link}
{kind=link}
![定量的結果: Hyenaは性能を維持しつつ⾼速に動作 18 • HyenaはFLOPs20%減でGPT[Brown+, NeurIPS20]と同程度のperplexity • 系列⻑64KでAttention / FlashAttention[Dao+,](https://files.speakerdeck.com/presentations/077012d5a555478289f88557809cf6c2/slide_17.jpg){kind=link}
{kind=link}
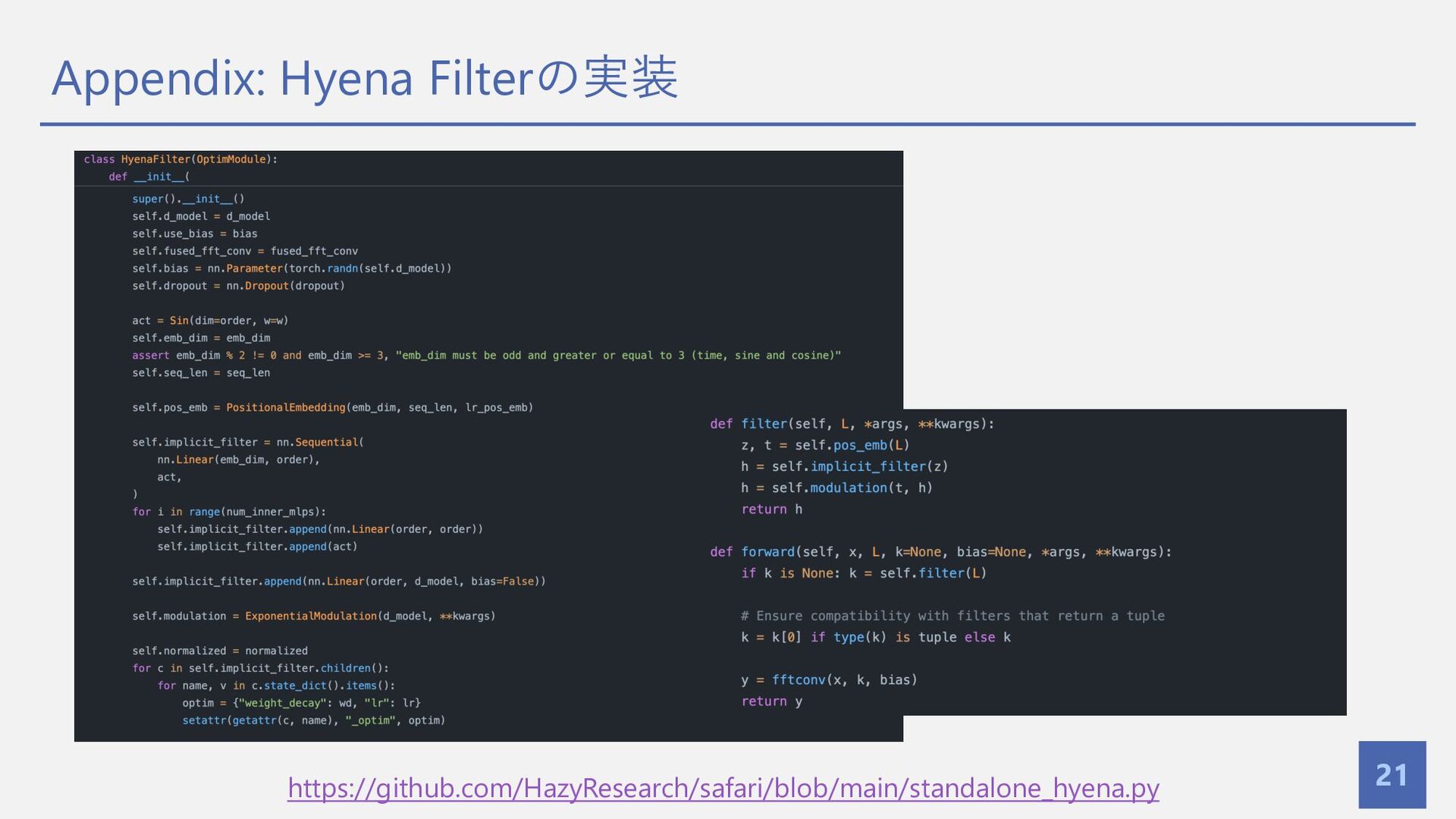{kind=link}
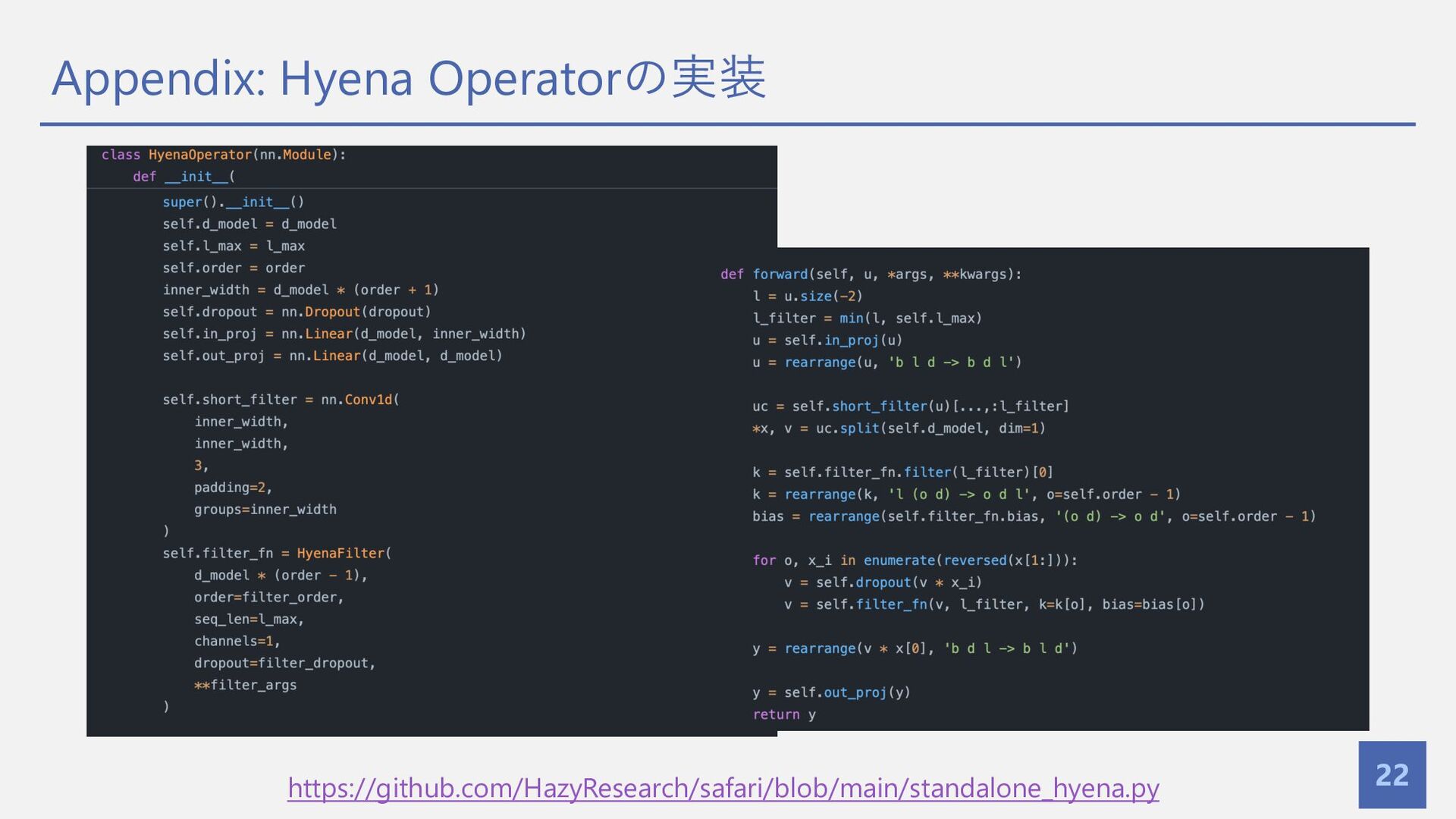{kind=link}
{kind=link}
{kind=link}
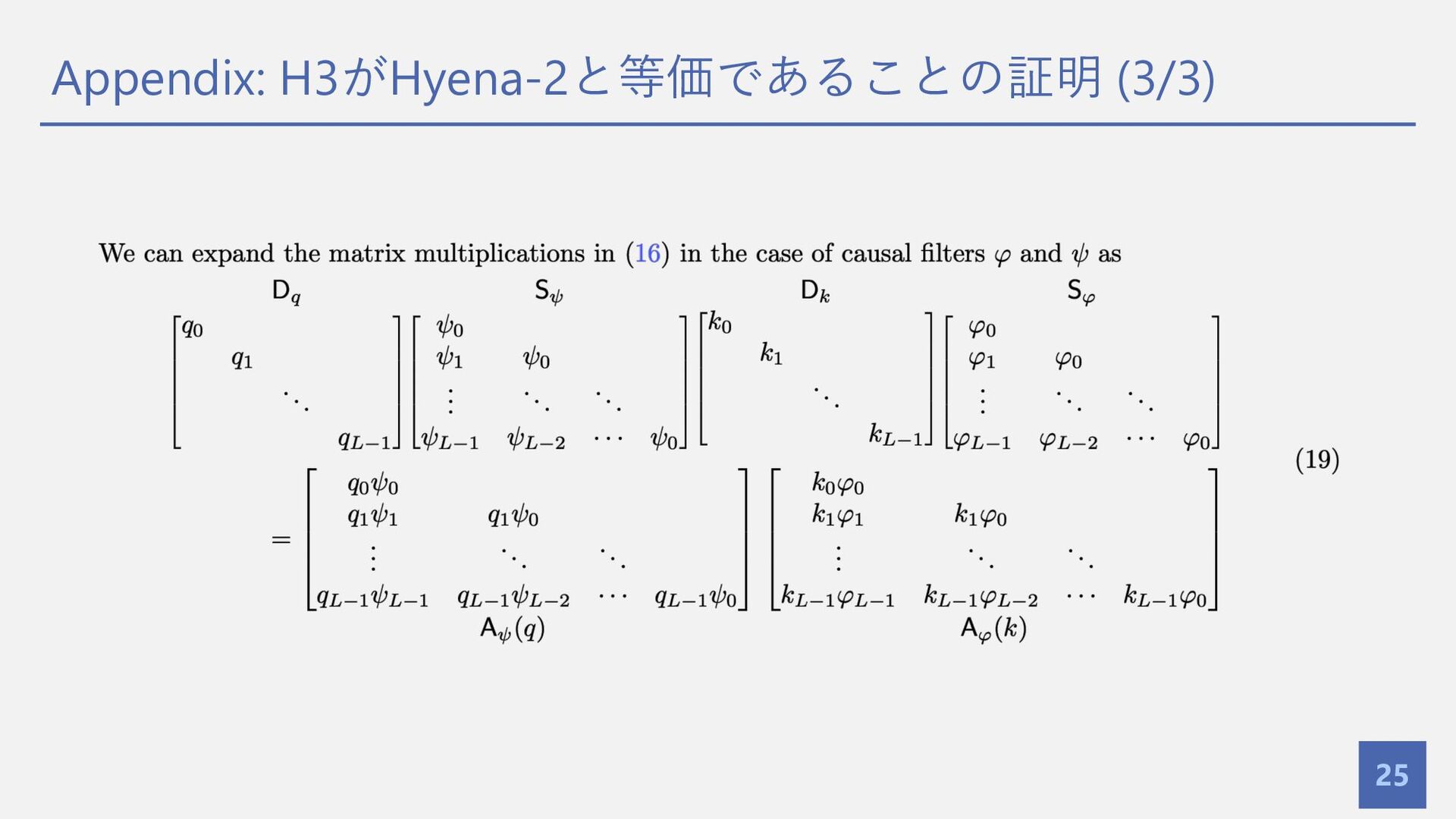{kind=link}
![Appendix: 状態空間モデルについて 26 • LSSL[Gu+, NeurIPS21]における定式化 • ⼊⼒ 𝑢 𝑡](https://files.speakerdeck.com/presentations/077012d5a555478289f88557809cf6c2/slide_24.jpg){kind=link}
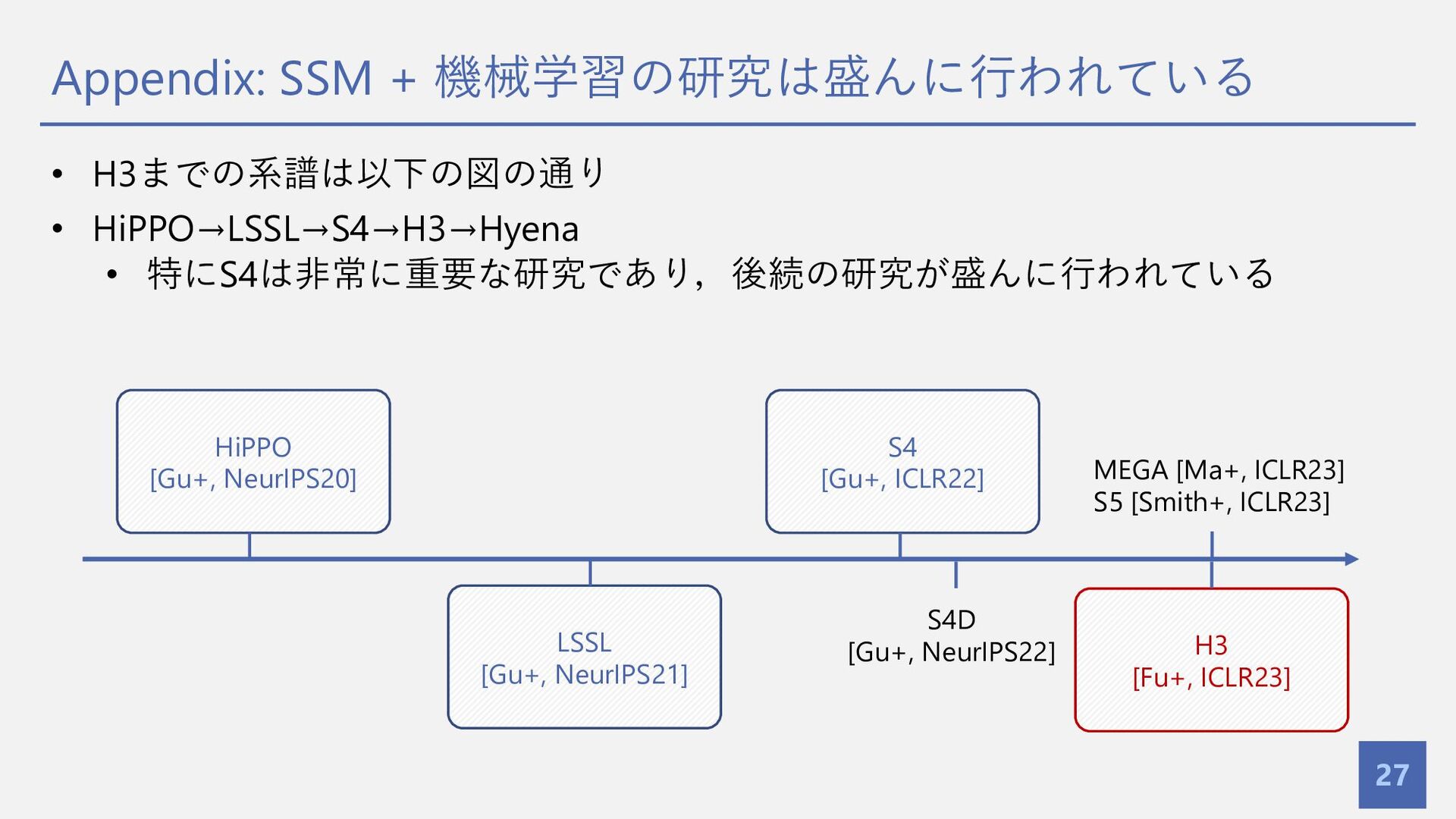{kind=link}
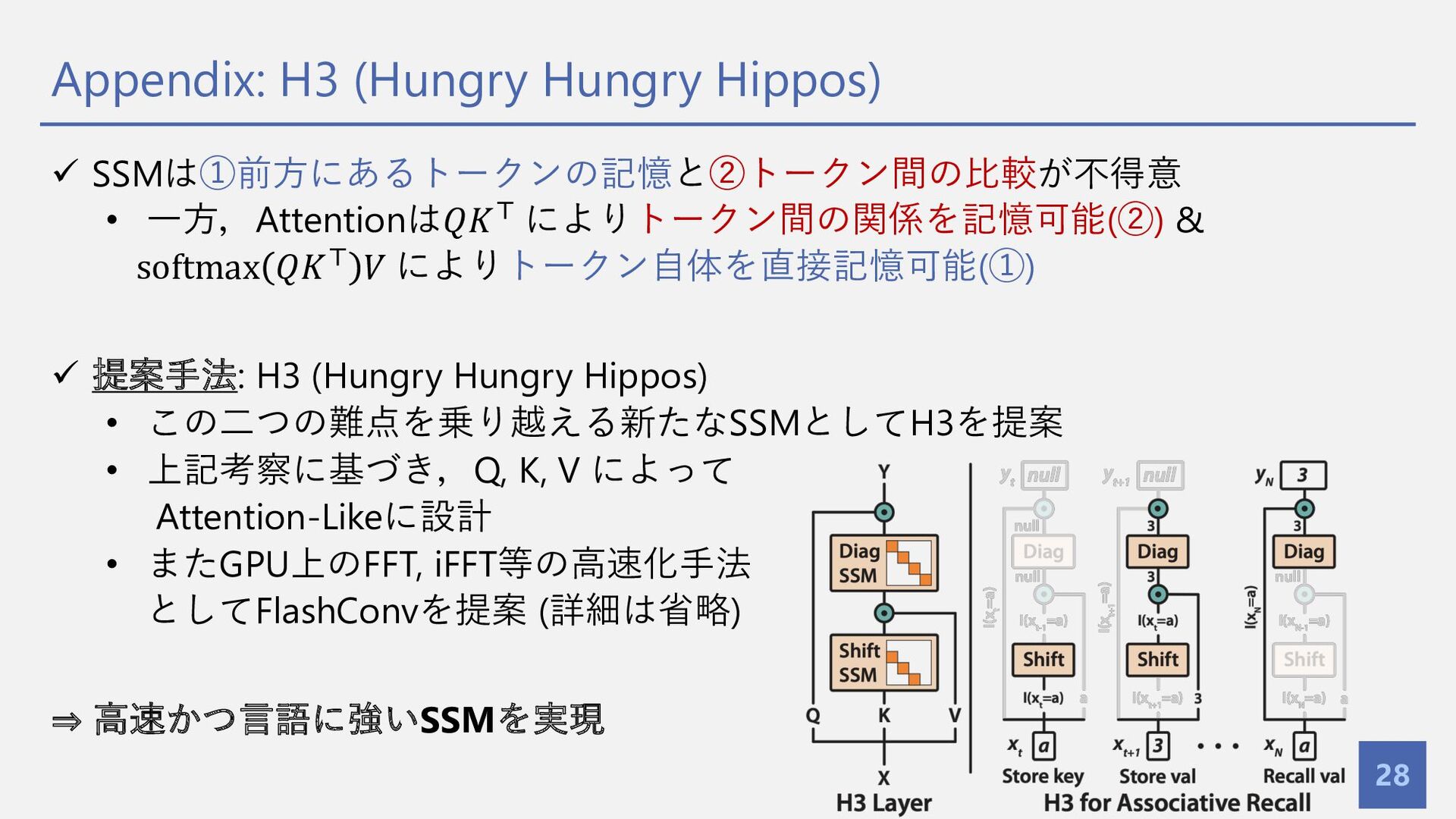{kind=link}