Yunfan Jiang 1, Agrim Gupta 1, Zichen Zhang 2, Guanzhi Wang 3,4, Yongqiang Dou 5, Yanjun Chen 1, Li Fei-Fei 1, Anima Anandkumar 3,4, Yuke Zhu 3,6, Linxi Fan 3 1Stanford, 2Macalester College, now at Allen Institute for AI, 3NVIDIA, 4Caltech, 5Tsinghua, 6UT Austin ICML 2023 Jiang, Y., Gupta, A., Zhang, Z., Wang, G., Dou, Y., Chen, Y., et al. "Vima: General Robot Manipulation with Multimodal Prompts." ICML 2023.
{kind=link}
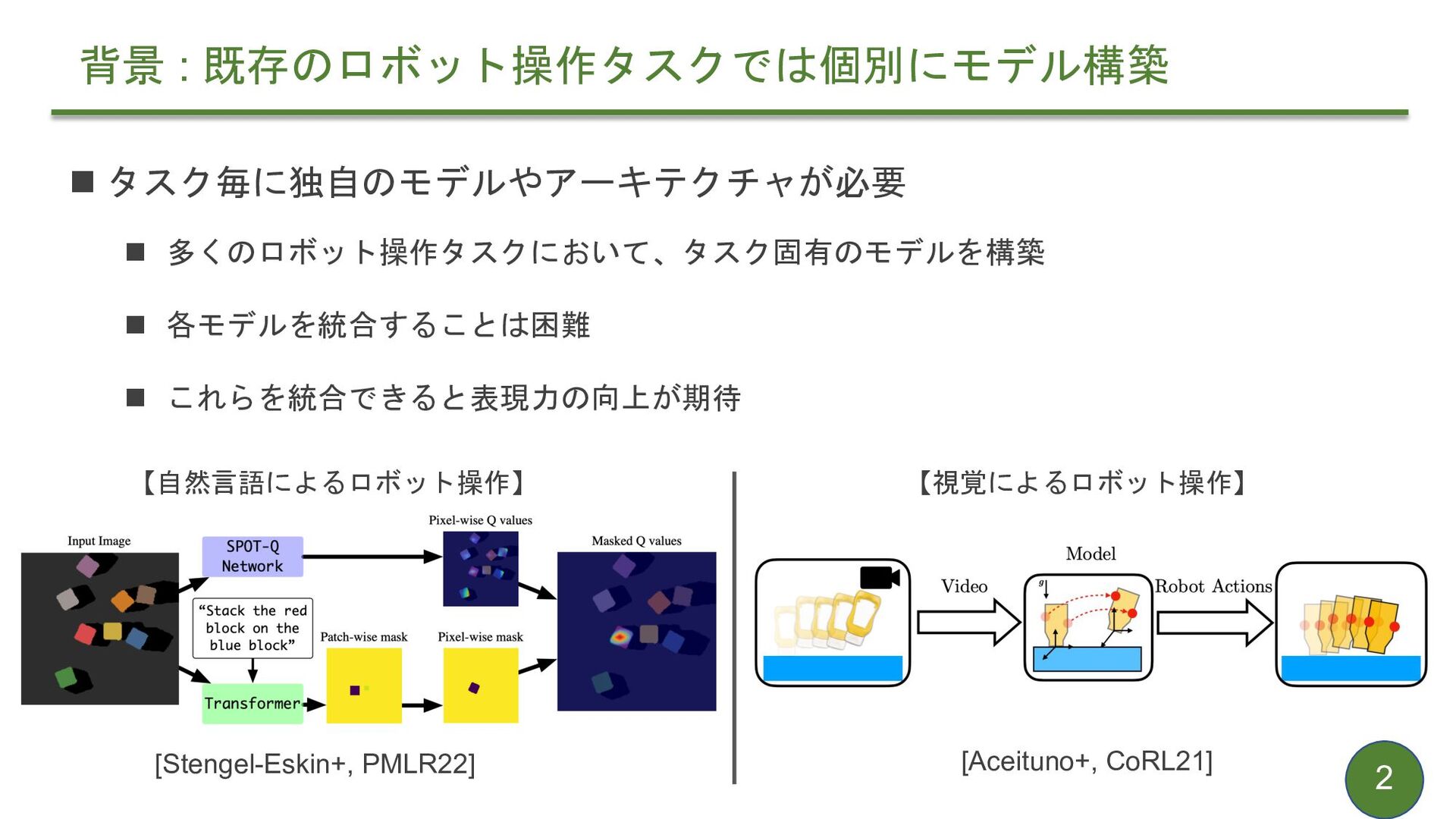{kind=link}
![関連研究 : 自然言語文(プロンプト)を入力とする手法が多い 3 手法 概要 CLIPort [Shridhar+, CoRL 21]](https://files.speakerdeck.com/presentations/14d84afe91f94d66b1e39b79941b227e/slide_2.jpg){kind=link}
{kind=link}
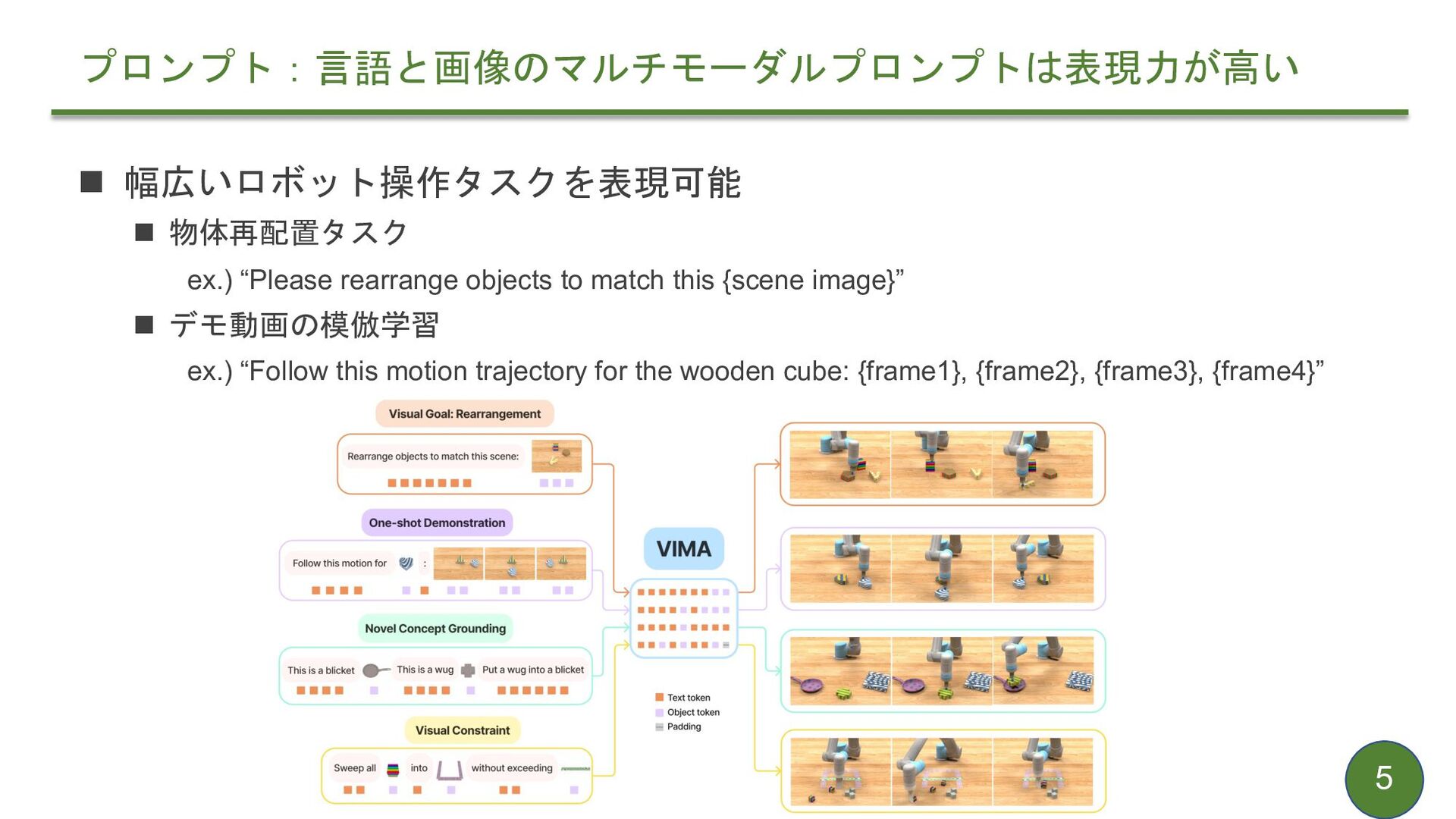{kind=link}
{kind=link}
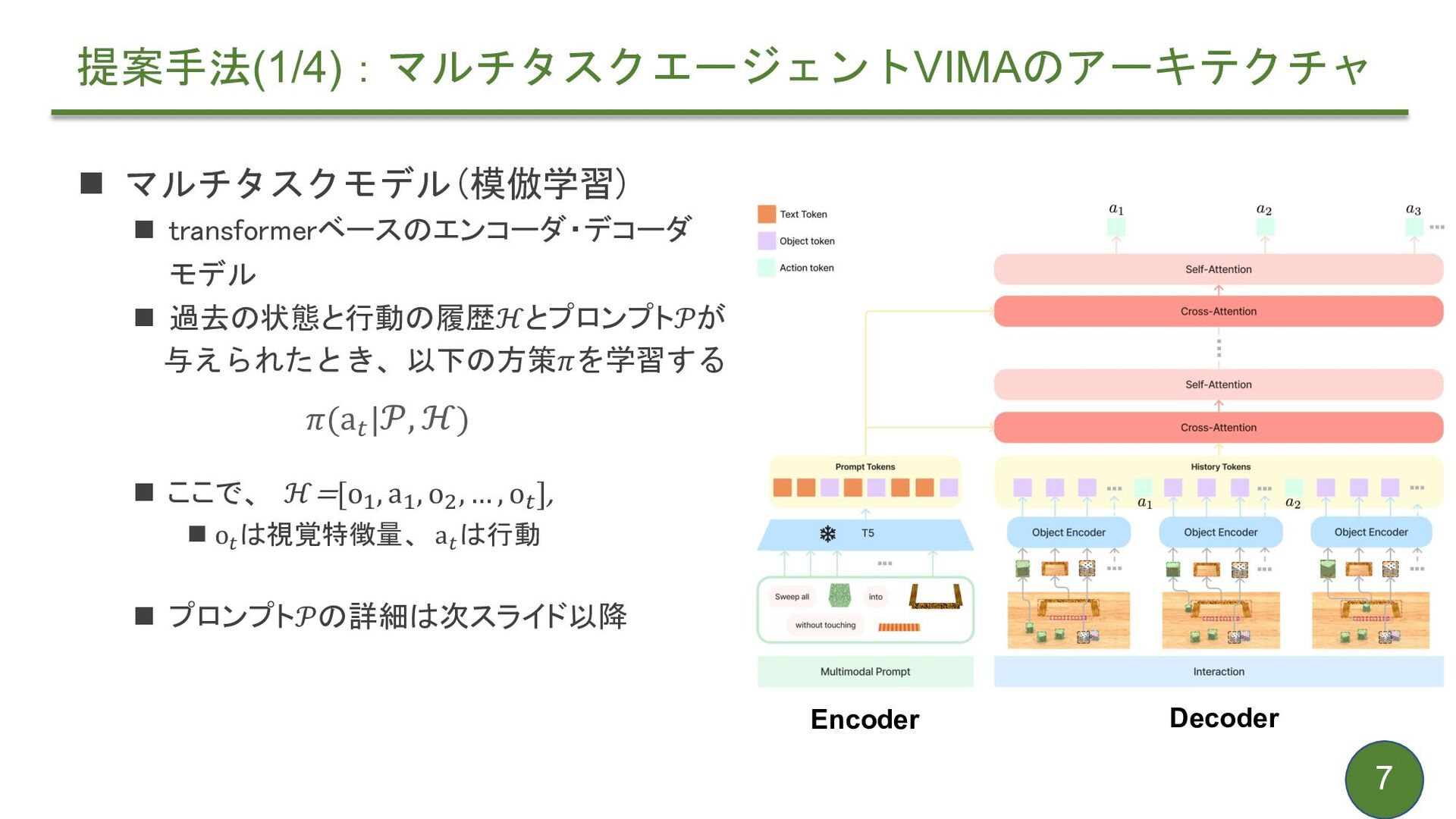{kind=link}
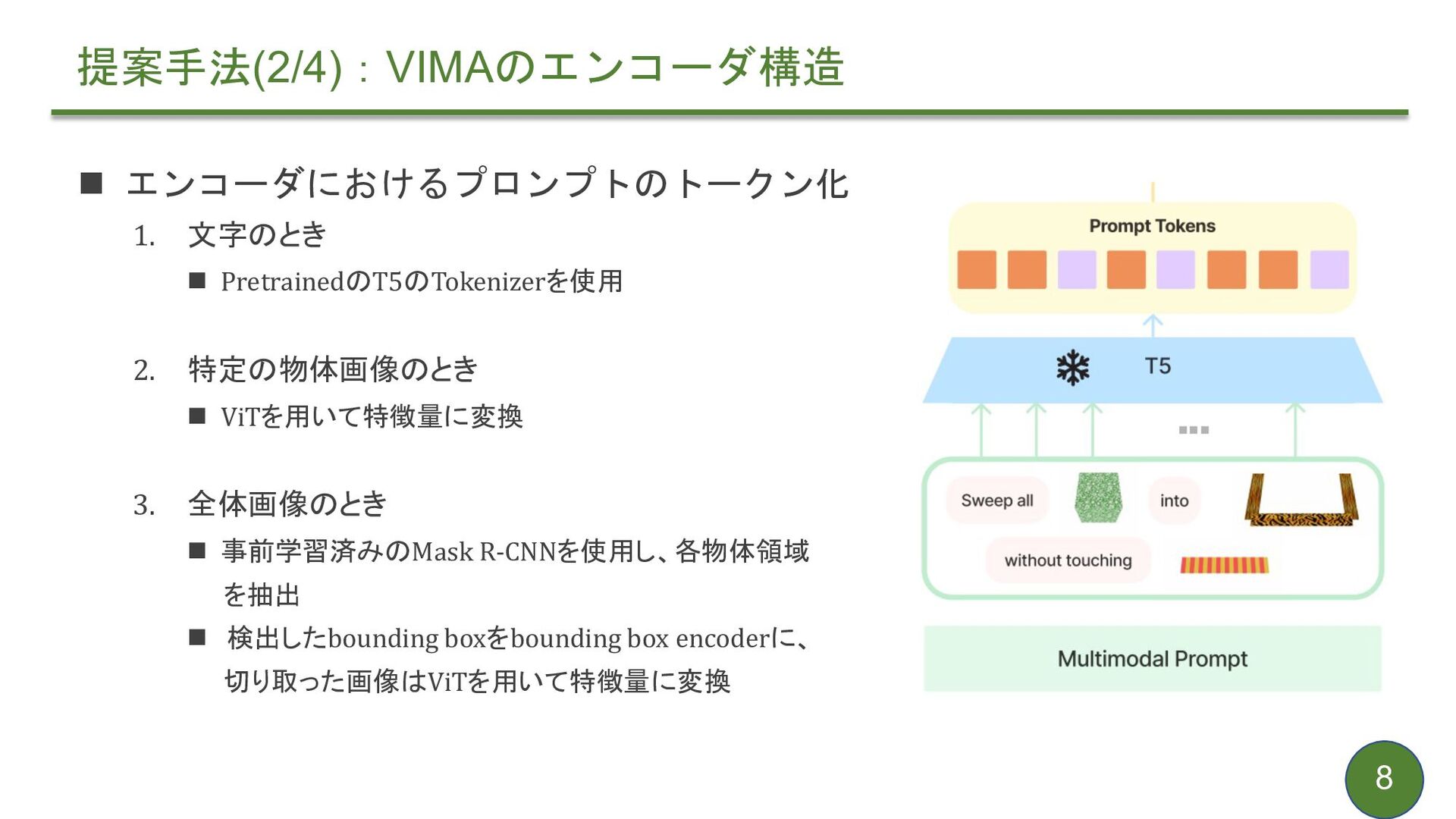{kind=link}
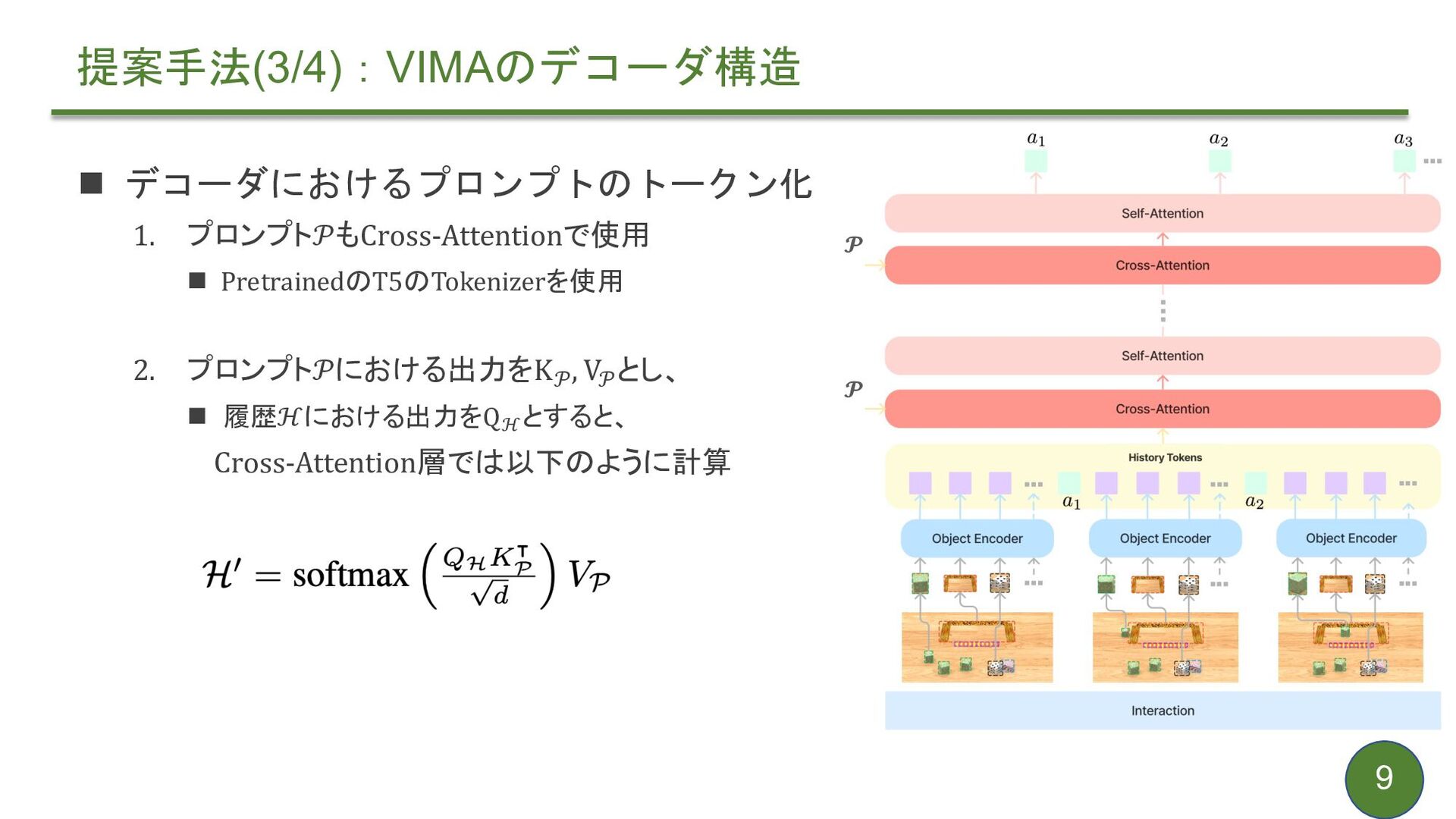{kind=link}
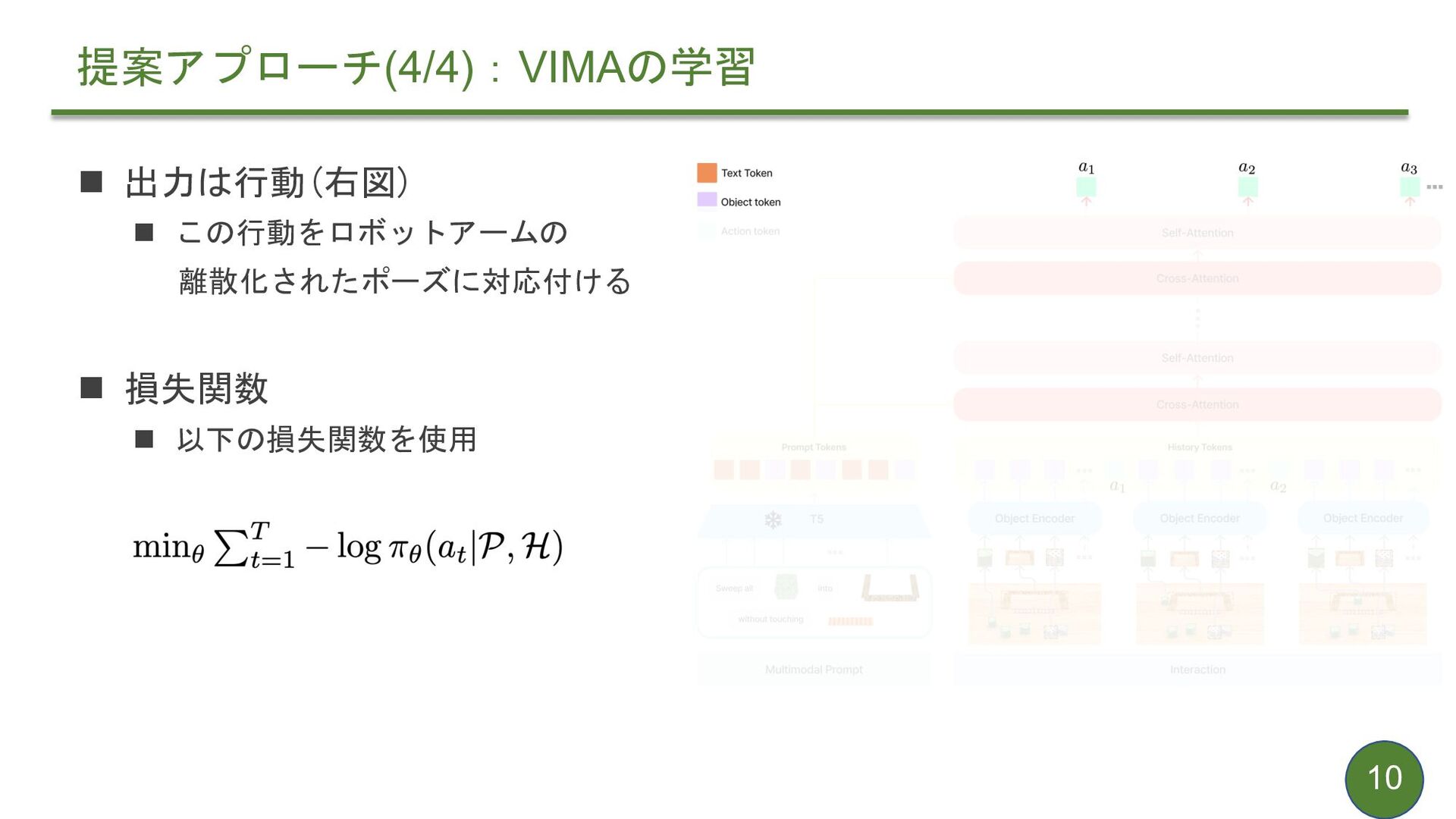{kind=link}
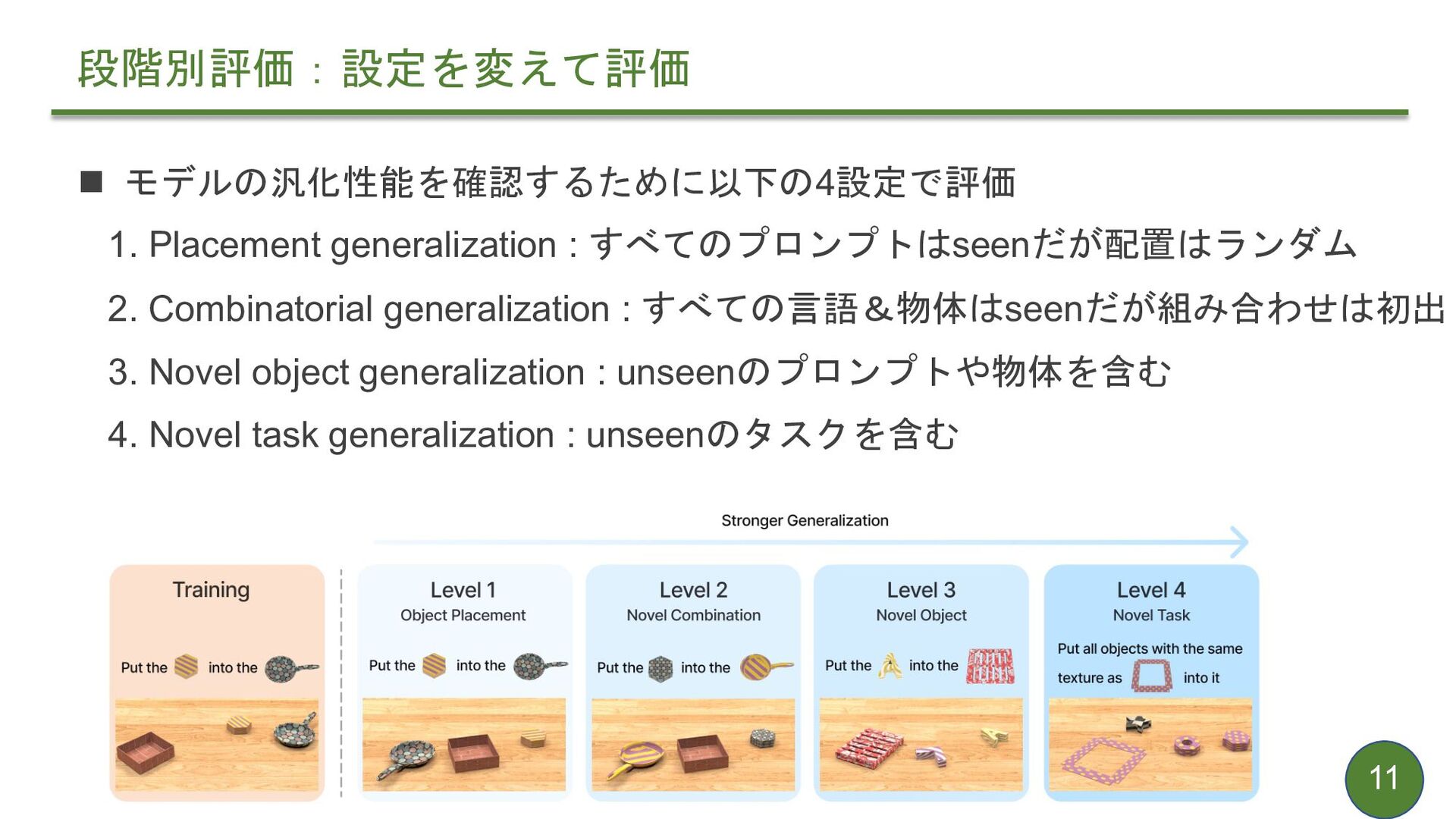{kind=link}
{kind=link}
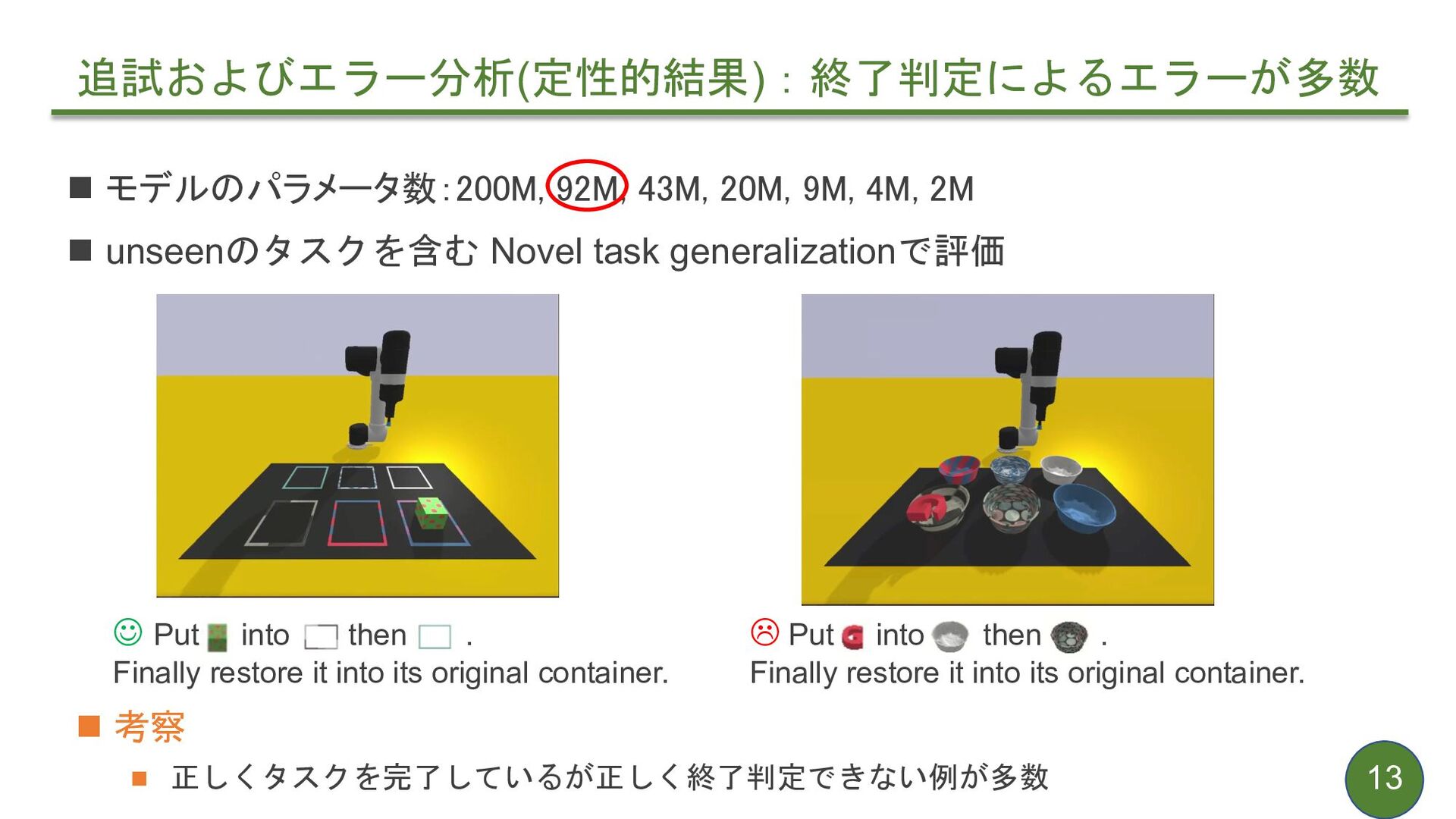{kind=link}
{kind=link}
{kind=link}
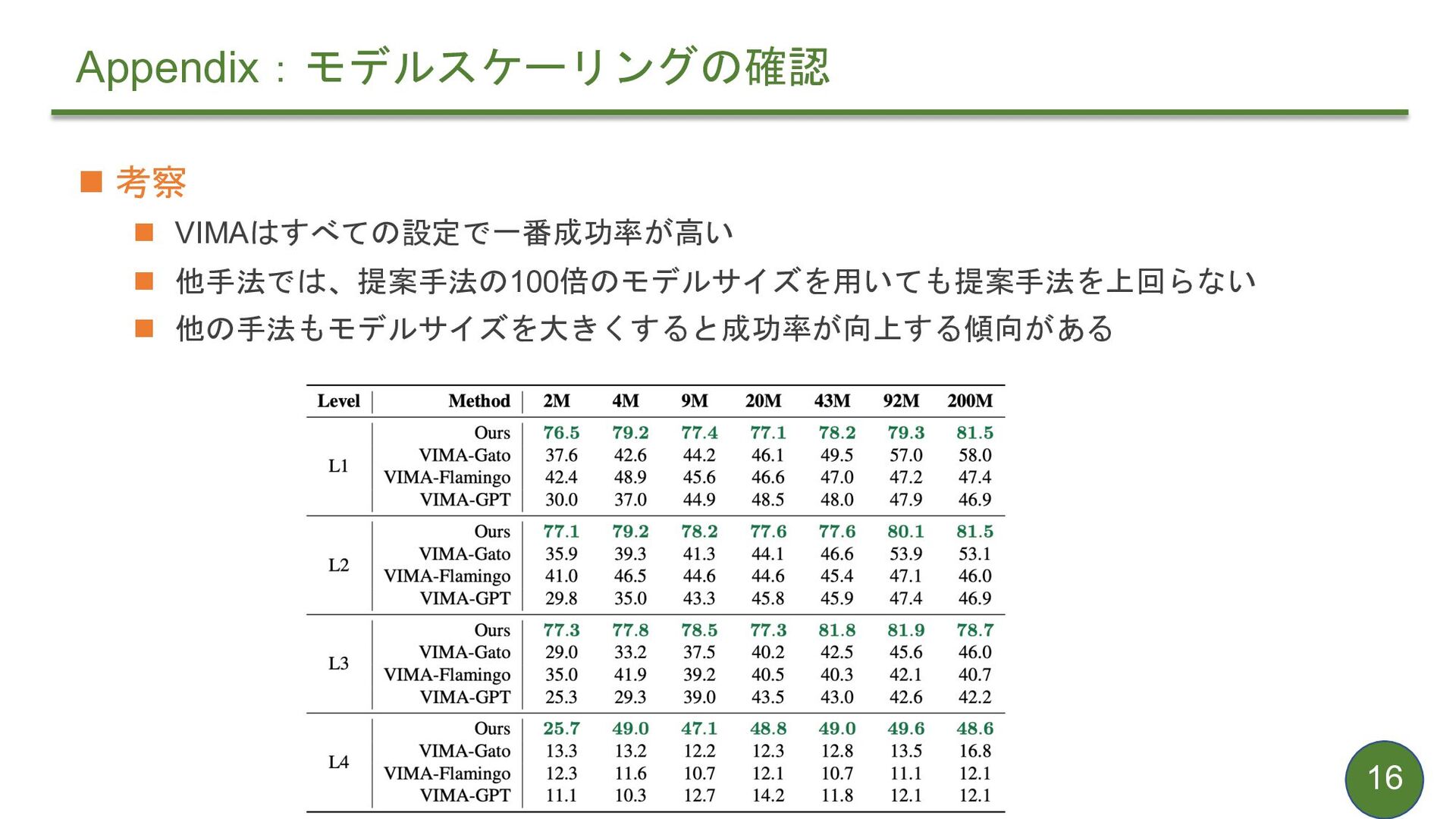{kind=link}
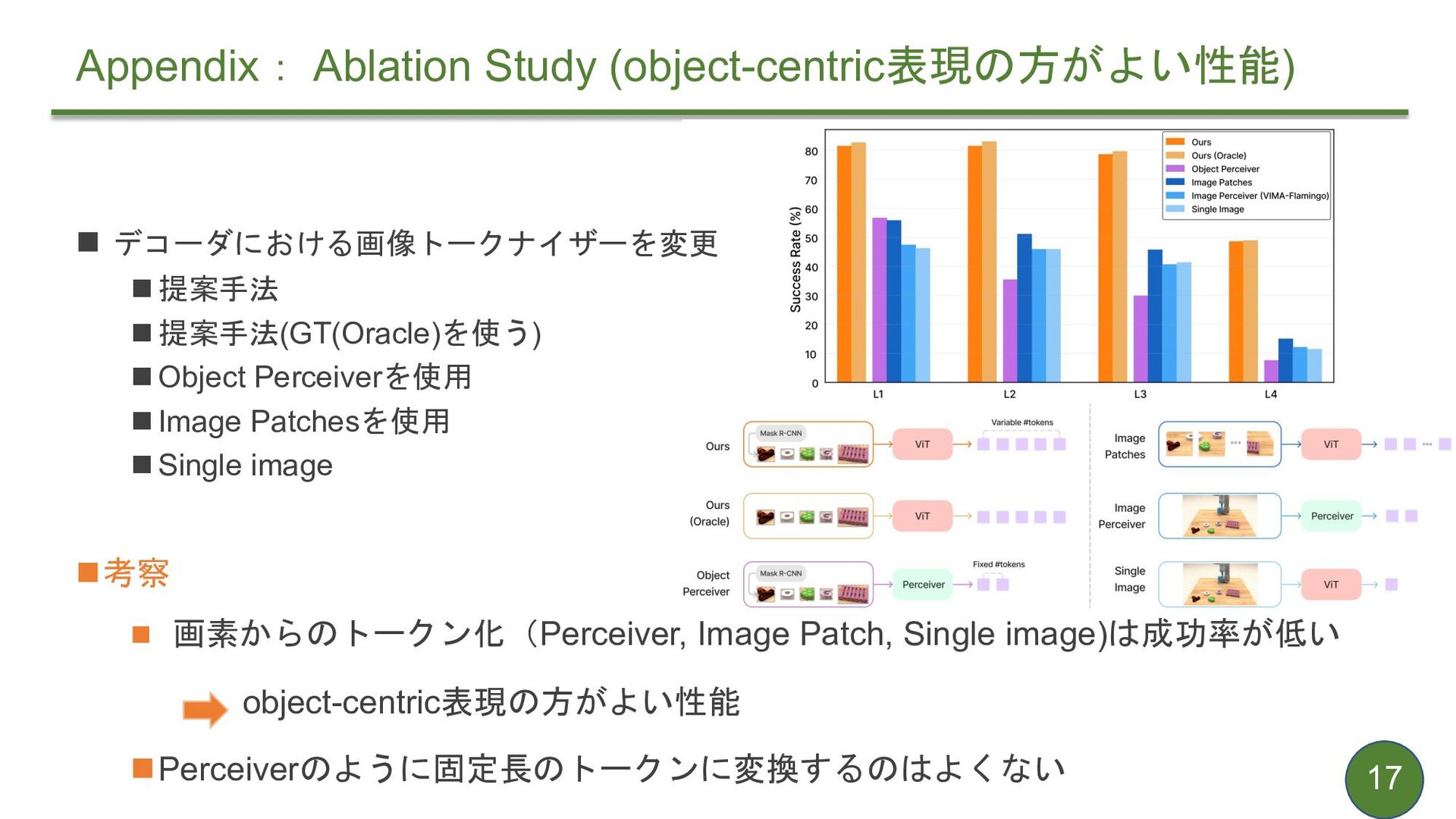{kind=link}
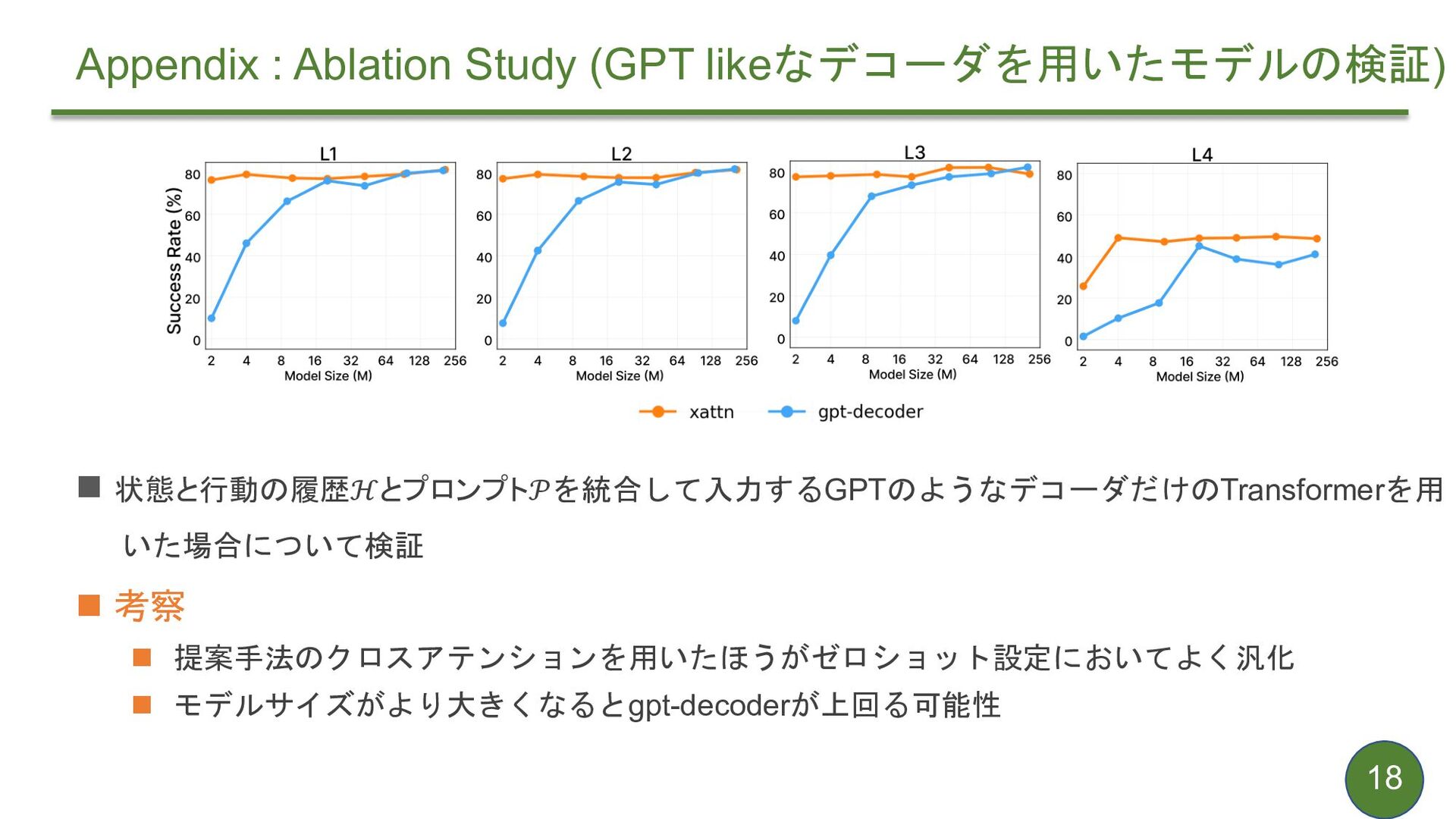{kind=link}