F., & Schmidhuber, J. (2006, June). Connectionist temporal classification: labelling unsegmented sequence data with recurrent neural networks. In Proceedings of the 23rd international conference on Machine learning (pp. 369-376). 2. Dahl, G. E., Yu, D., Deng, L., & Acero, A. (2011). Context-dependent pre-trained deep neural networks for large-vocabulary speech recognition. IEEE Transactions on audio, speech, and language processing, 20(1), 30-42. 3. Hannun, A., Case, C., Casper, J., Catanzaro, B., Diamos, G., Elsen, E., ... & Ng, A. Y. (2014). Deep speech: Scaling up end-to-end speech recognition. arXiv preprint arXiv:1412.5567. 4. Girshick, R., Donahue, J., Darrell, T., & Malik, J. (2014). Rich feature hierarchies for accurate object detection and semantic segmentation. In Proceedings of the IEEE conference on computer vision and pattern recognition (pp. 580-587). 5. Vinyals, O., Toshev, A., Bengio, S., & Erhan, D. (2015). Show and tell: A neural image caption generator. In Proceedings of the IEEE conference on computer vision and pattern recognition (pp. 3156-3164). 6. Ren, S., He, K., Girshick, R., & Sun, J. (2015). Faster r-cnn: Towards real-time object detection with region proposal networks. Advances in neural information processing systems, 28, 91-99. 7. Wu, Y., Schuster, M., Chen, Z., Le, Q. V., Norouzi, M., Macherey, W., ... & Dean, J. (2016). Google's neural machine translation system: Bridging the gap between human and machine translation. arXiv preprint arXiv:1609.08144. 8. Liu, W., Anguelov, D., Erhan, D., Szegedy, C., Reed, S., Fu, C. Y., & Berg, A. C. (2016, October). Ssd: Single shot multibox detector. In European conference on computer vision (pp. 21-37). Springer, Cham.
![情報工学科 教授 杉浦孔明 [email protected] 慶應義塾大学理工学部 機械学習基礎 第10回 応用と評価](https://files.speakerdeck.com/presentations/042016da4e514477b252ee10b801c111/slide_0.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
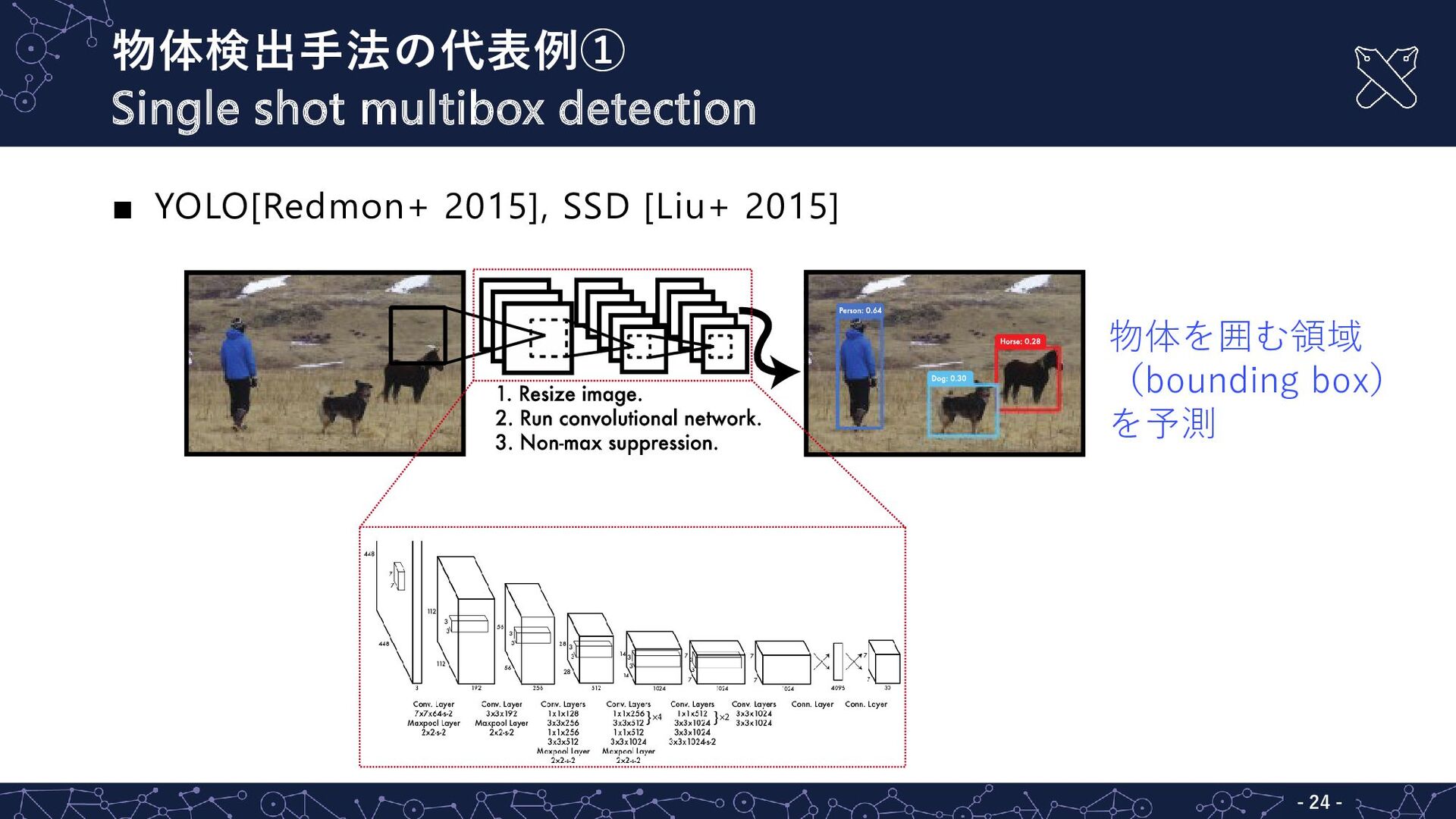
![物体検出手法の代表例② - - 25 ▪ R-CNN(region-based CNN)[Girshick+ 2014], Faster R-CNN[Ren+](https://files.speakerdeck.com/presentations/042016da4e514477b252ee10b801c111/slide_18.jpg){kind=link}
![セマンティックセグメンテーション手法の代表例 - - 26 ▪ Mask R-CNN [He+ 2017] ▪](https://files.speakerdeck.com/presentations/042016da4e514477b252ee10b801c111/slide_19.jpg){kind=link}
![姿勢推定手法の代表例① - - 27 ▪ OpenPose [Cao+ 2017] https://github.com/CMU-Perceptual-Computing-Lab/openpose](https://files.speakerdeck.com/presentations/042016da4e514477b252ee10b801c111/slide_20.jpg){kind=link}
![姿勢推定手法の代表例② - - 28 ▪ DensePose [Güler+ 2018] https://github.com/facebookresearch/detectron2/blob/main/projects/DensePose/doc/DENSEPOSE_CSE.md](https://files.speakerdeck.com/presentations/042016da4e514477b252ee10b801c111/slide_21.jpg){kind=link}
{kind=link}
{kind=link}
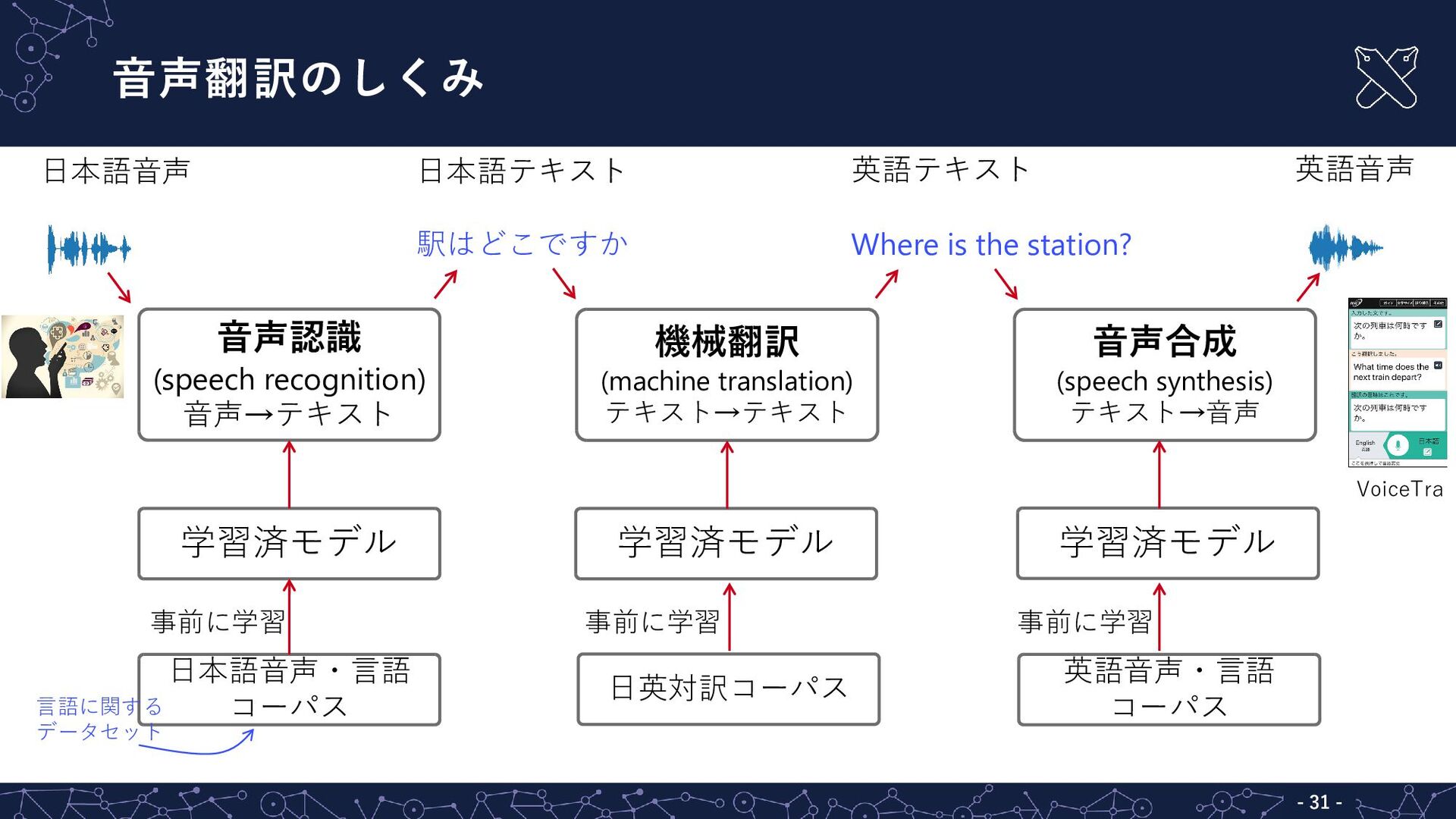{kind=link}
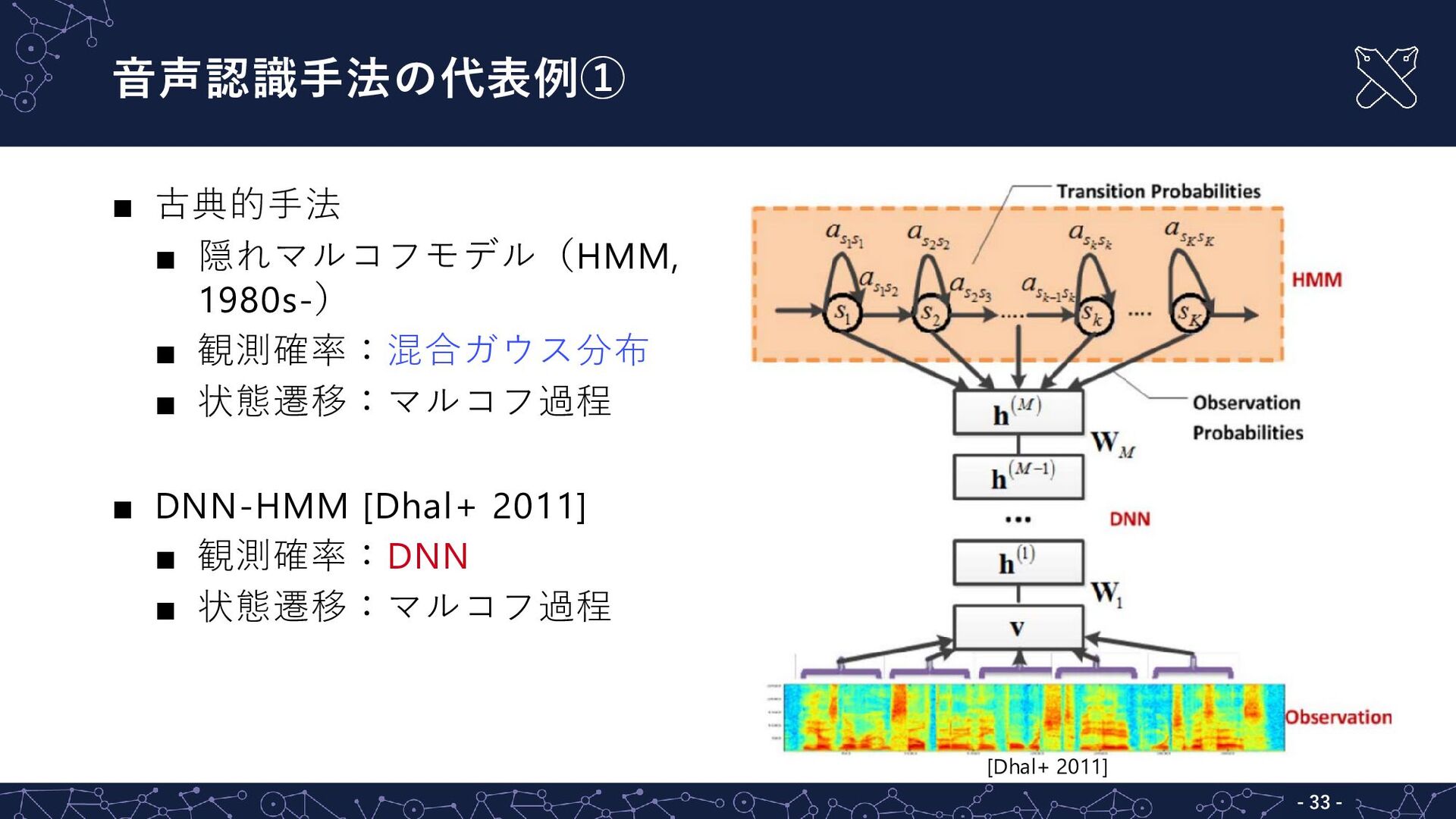{kind=link}
![音声認識手法の代表例② CTC [Hannun+ 2014] - - 34 ▪ 深層学習時代より前に提案 [Graves](https://files.speakerdeck.com/presentations/042016da4e514477b252ee10b801c111/slide_26.jpg){kind=link}
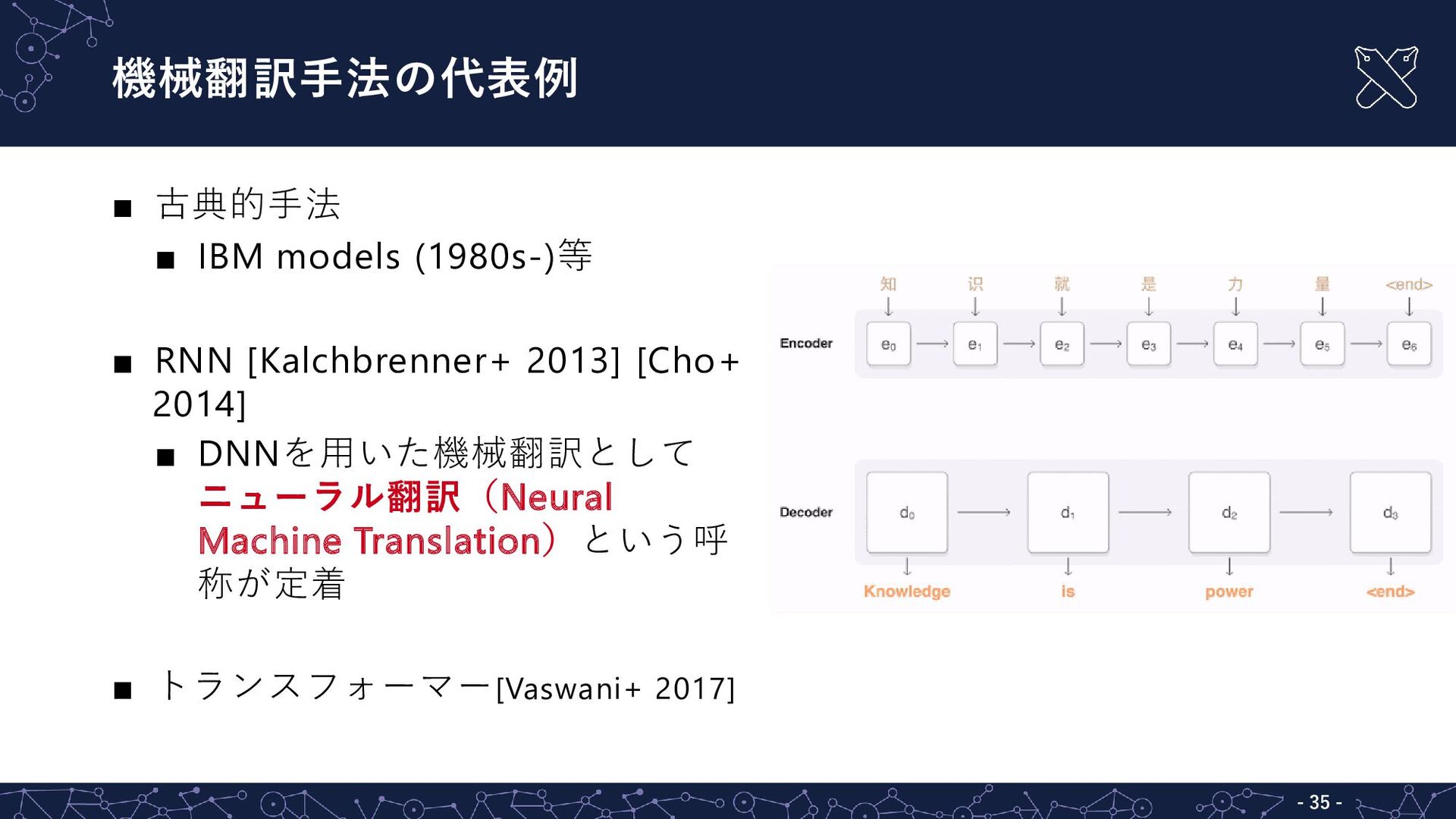{kind=link}
![音声合成手法の代表例: WaveNet [van den Oord+ 2016b] - - 36 ▪](https://files.speakerdeck.com/presentations/042016da4e514477b252ee10b801c111/slide_28.jpg){kind=link}
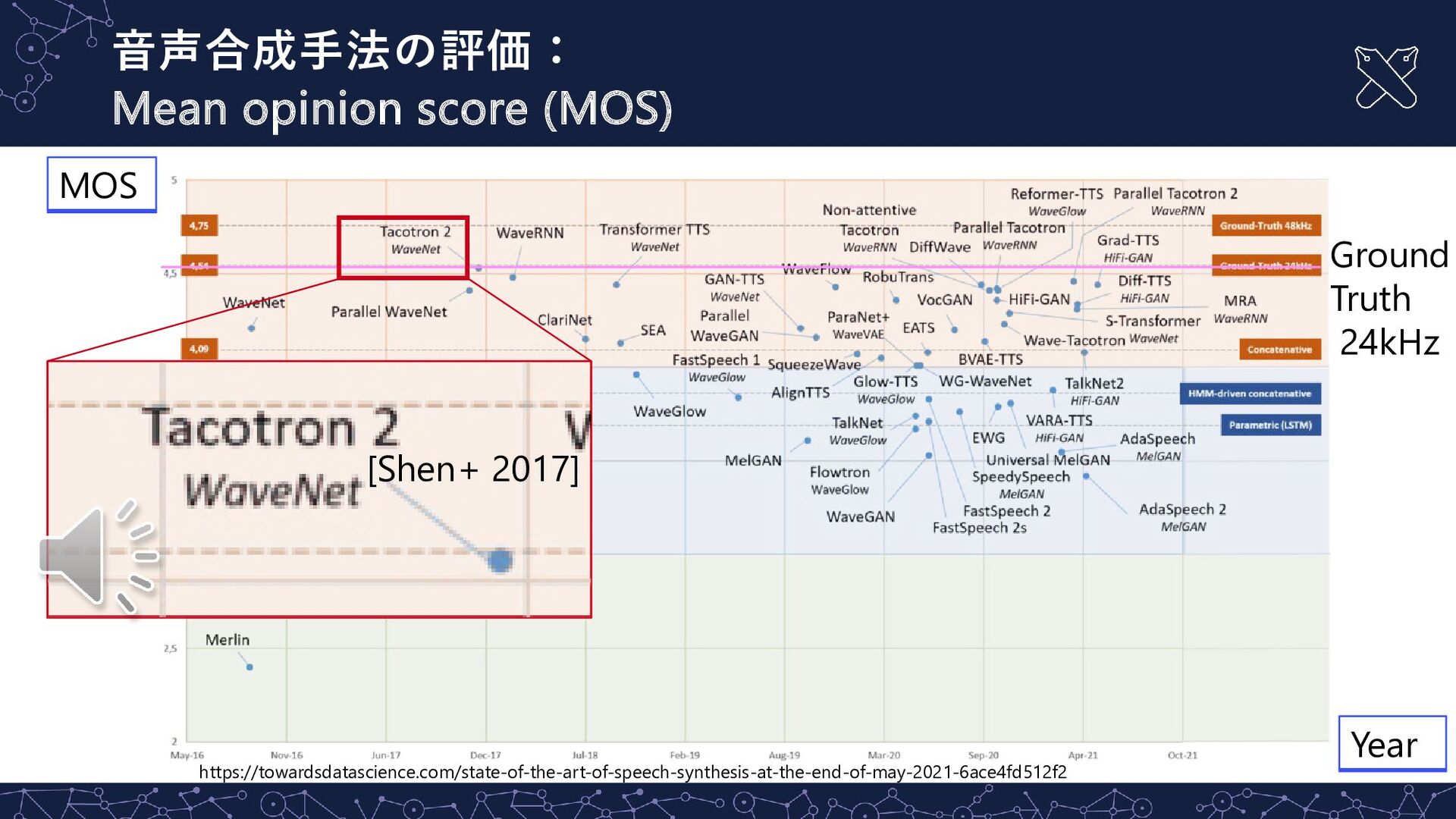{kind=link}
{kind=link}
{kind=link}
{kind=link}
![画像キャプショニングの代表例: Show and tell [Vinayls+ 2015] - - 41 ▪](https://files.speakerdeck.com/presentations/042016da4e514477b252ee10b801c111/slide_33.jpg){kind=link}
![VQAの代表例: [Agrawal+ 2015] - - 42 ▪ VGGを用いて画像を潜在表現に変換 ▪ LSTMを用いて質問を潜在表現に変換](https://files.speakerdeck.com/presentations/042016da4e514477b252ee10b801c111/slide_34.jpg){kind=link}
![CLIP [Radford+ 2021] - - 43 ▪ ウェブから収集された4億組の画像・テキストを使用 ▪ 正しい画像とテキストの組を予測できるように学習](https://files.speakerdeck.com/presentations/042016da4e514477b252ee10b801c111/slide_35.jpg){kind=link}
![2022年、マルチモーダル言語処理が爆発的に拡大① Text-to-image ▪ DALL·E 2 [Aditya (OpenAI) + 2022/4] ▪](https://files.speakerdeck.com/presentations/042016da4e514477b252ee10b801c111/slide_36.jpg){kind=link}
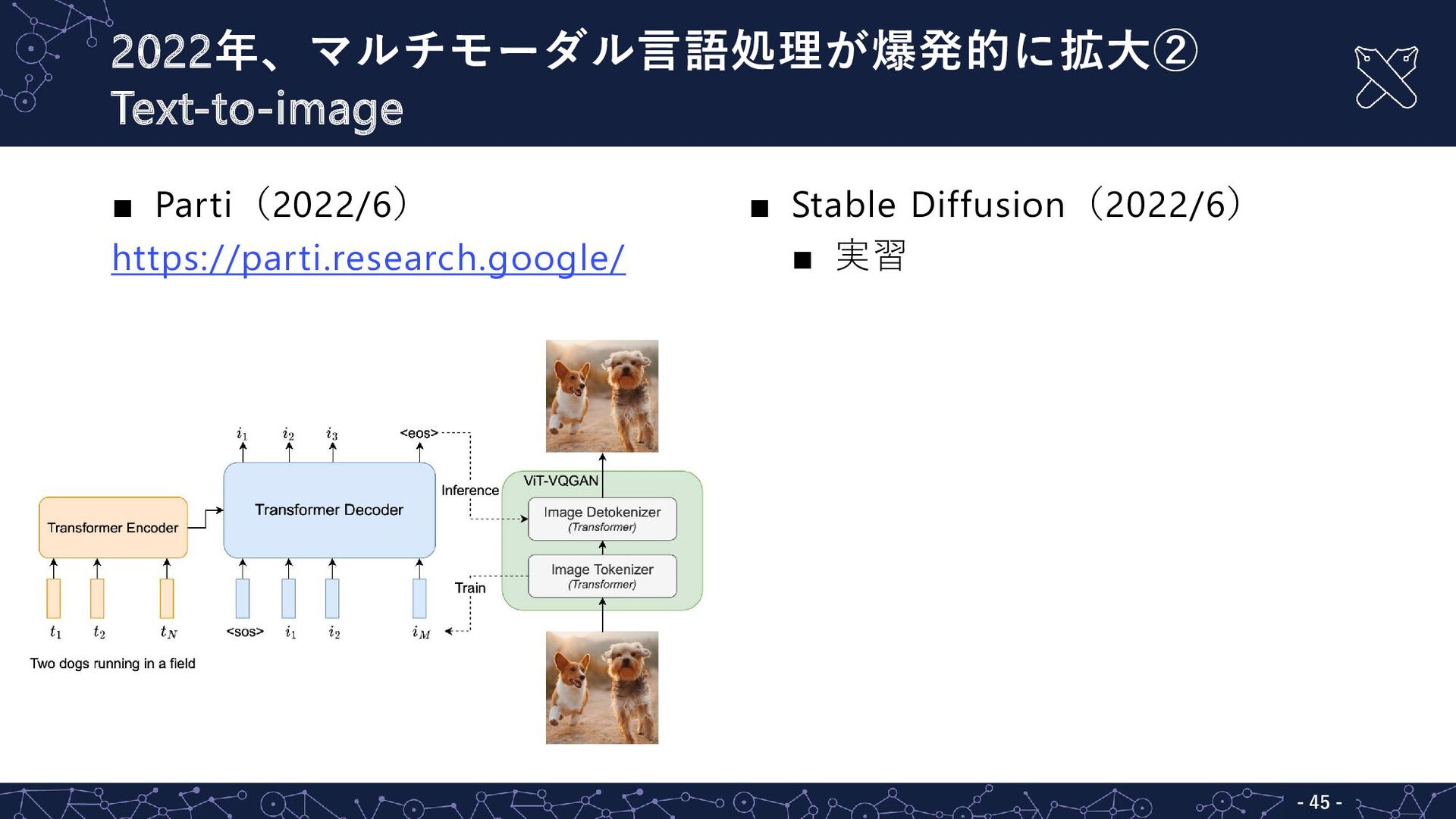{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}