Kevin McCarthy will present a gentle introduction to Machine Learning*.
Have you ever wished your computer could do more than what you tell it
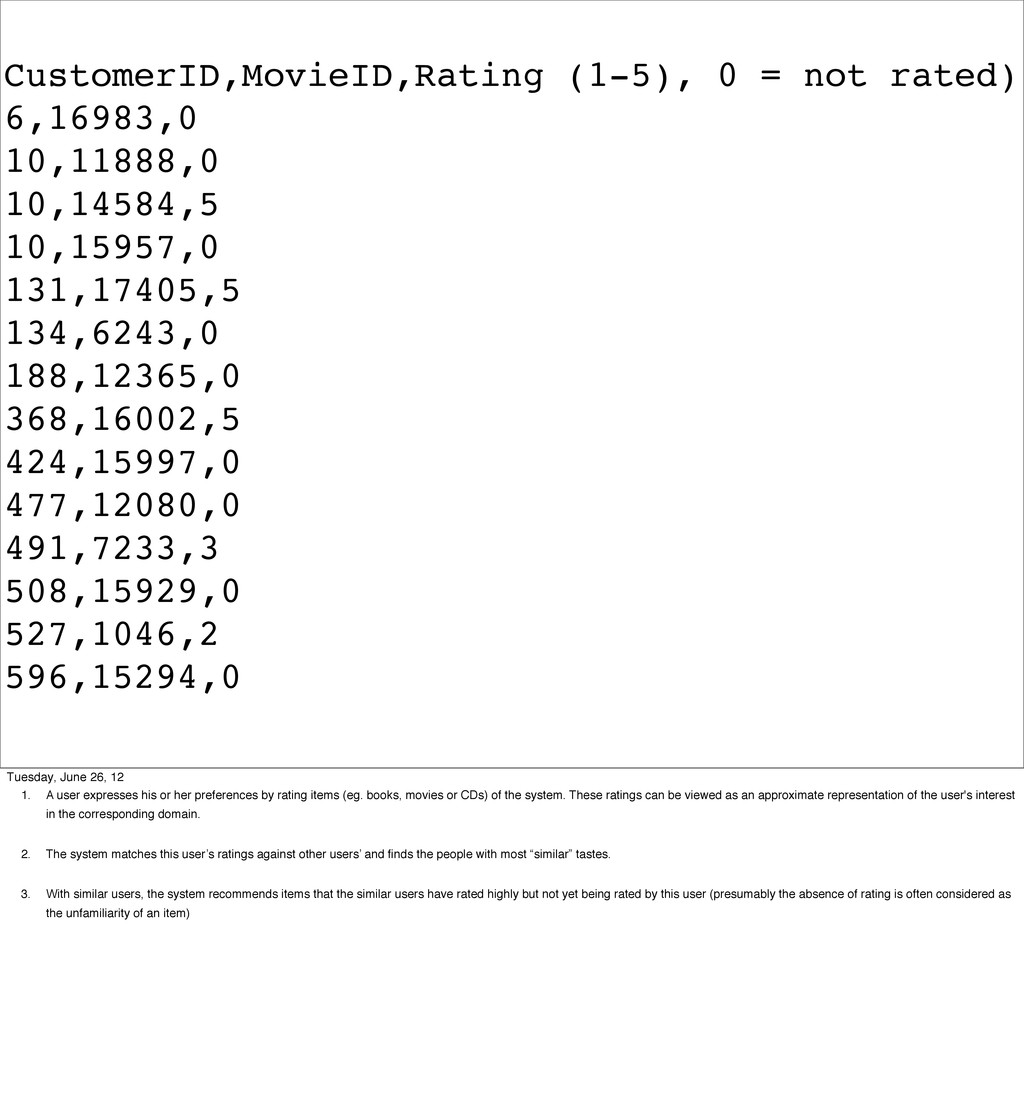
to do explicitly? Maybe you want to write a recommendation engine
like the one Amazon and Netflix use to recommend similar products, or
maybe you just want to build Skynet. The goal of this talk is to
give a broad but shallow overview of machine learning techniques and
applications. Topics covered will (probably) include:
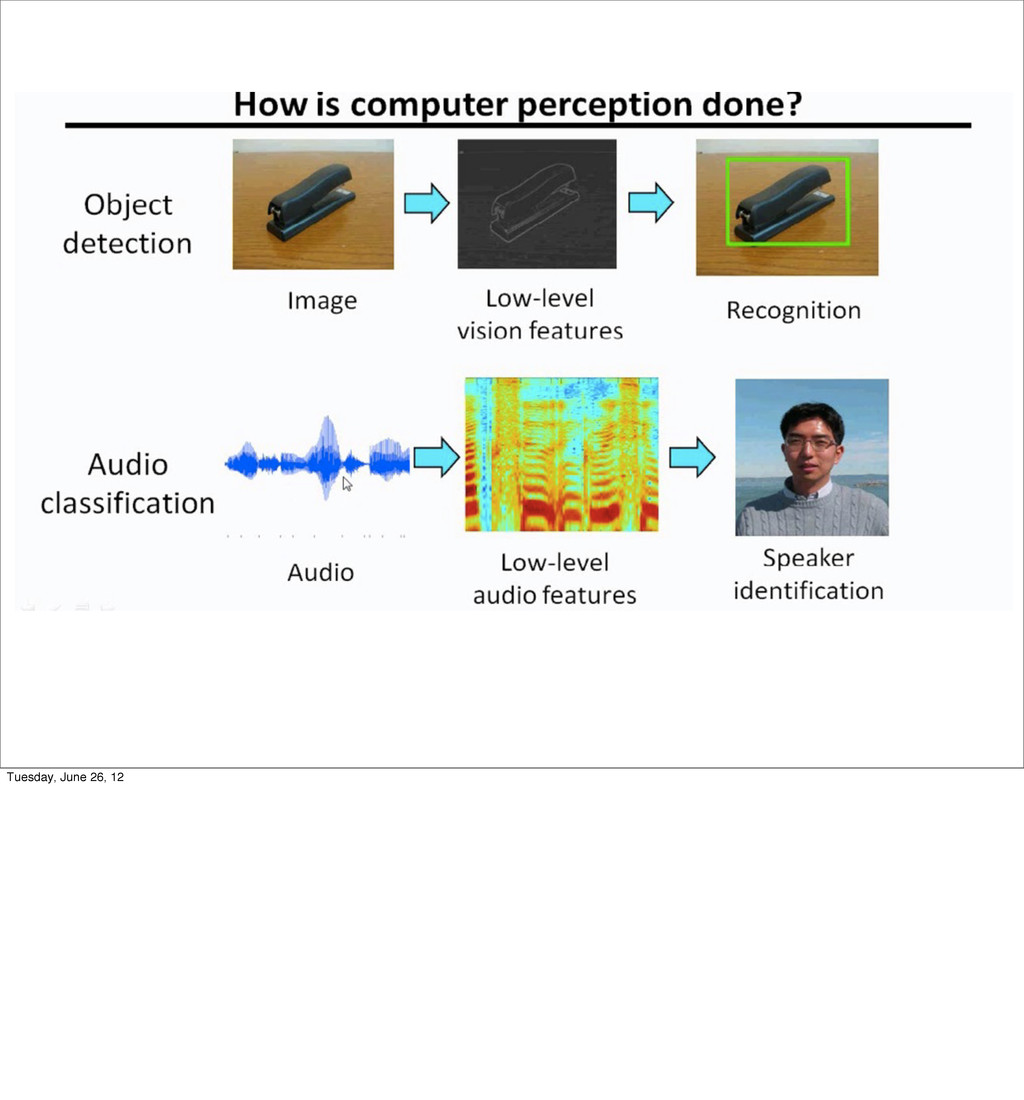
- What is machine learning?
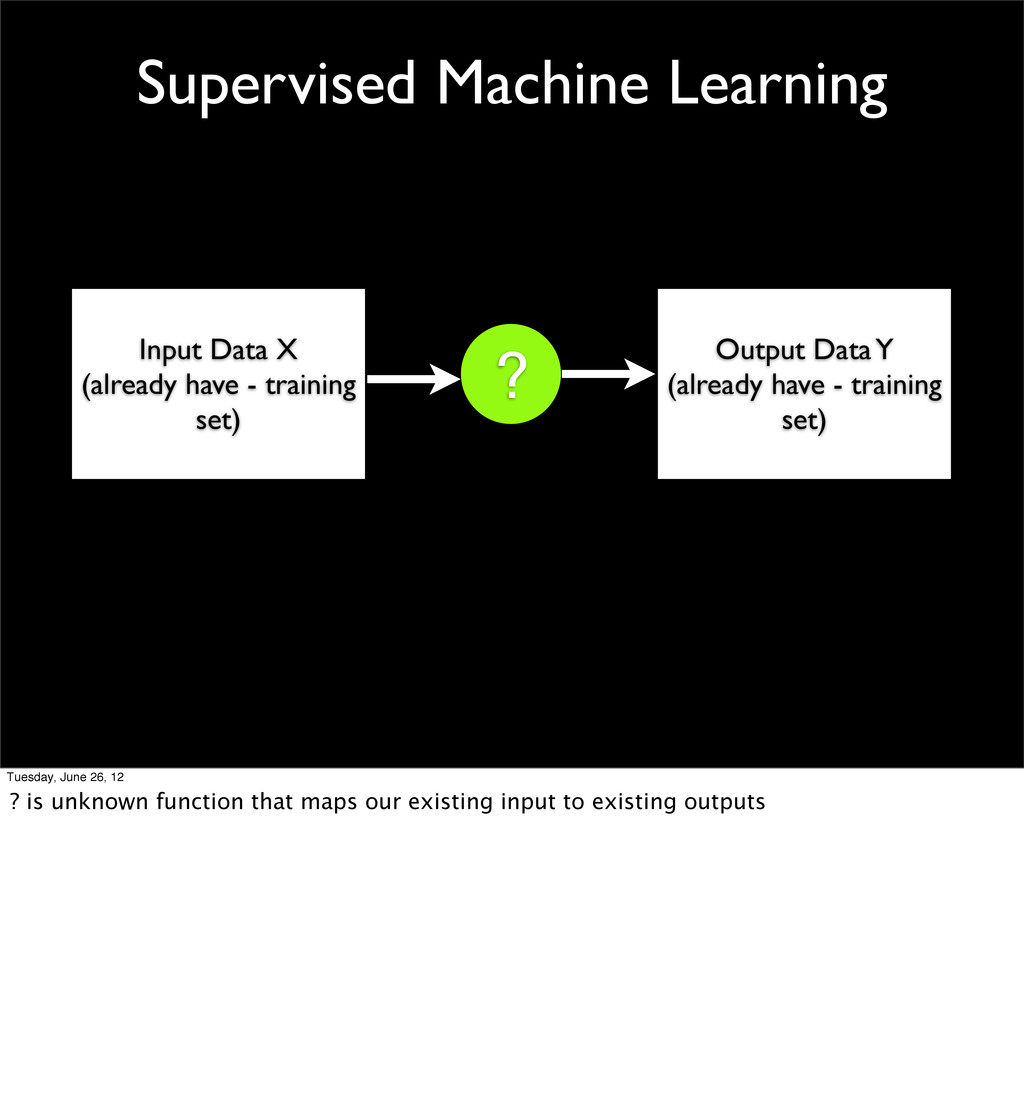
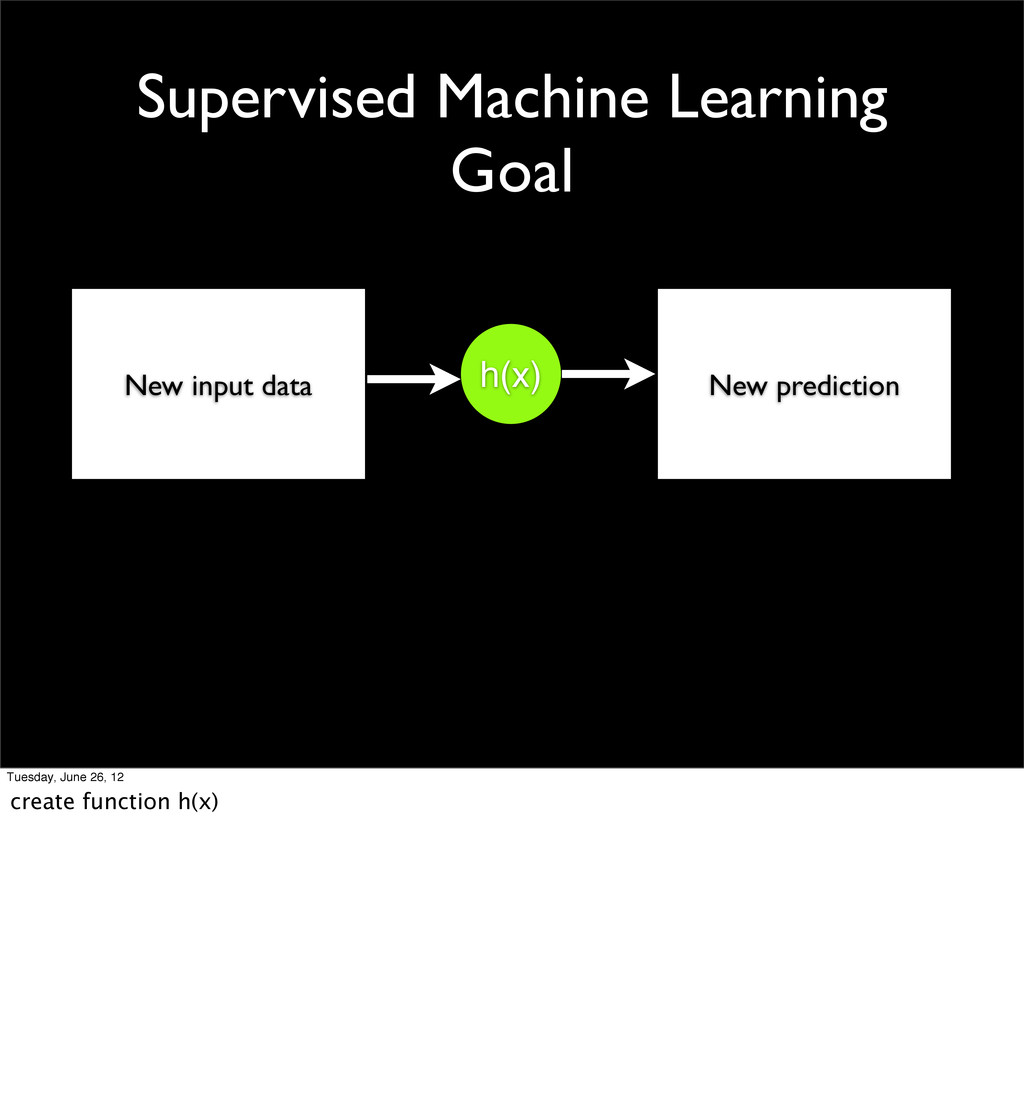
- Supervised vs unsupervised machine learning
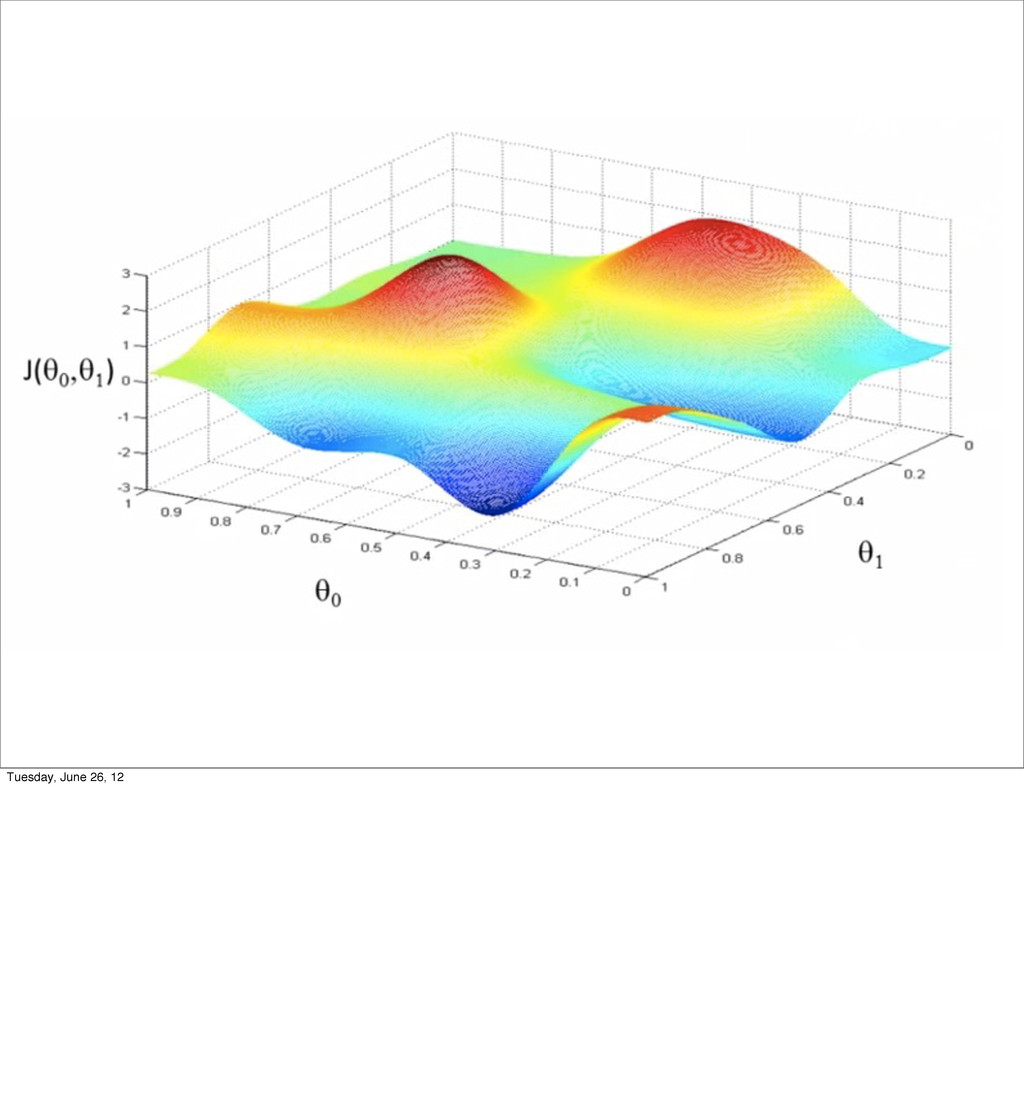
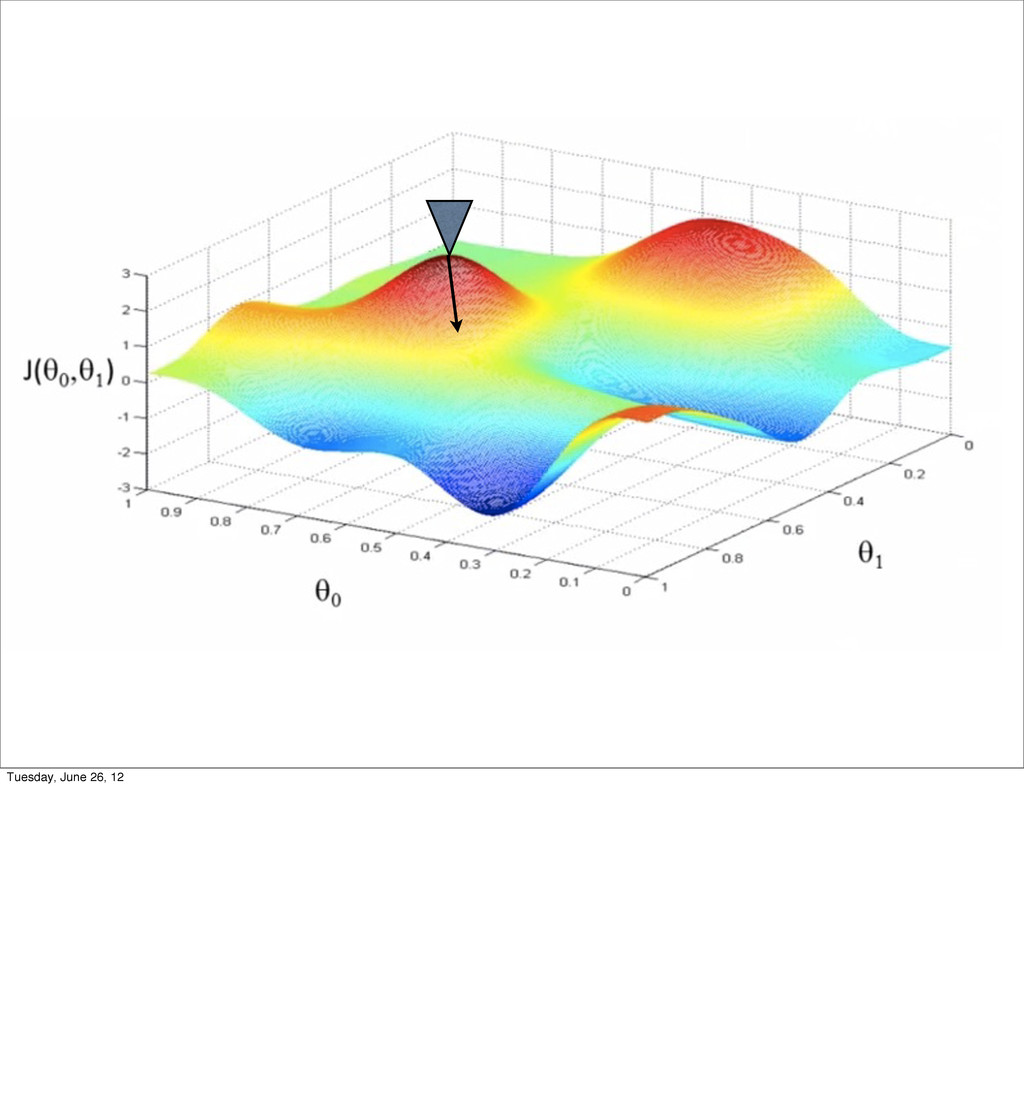
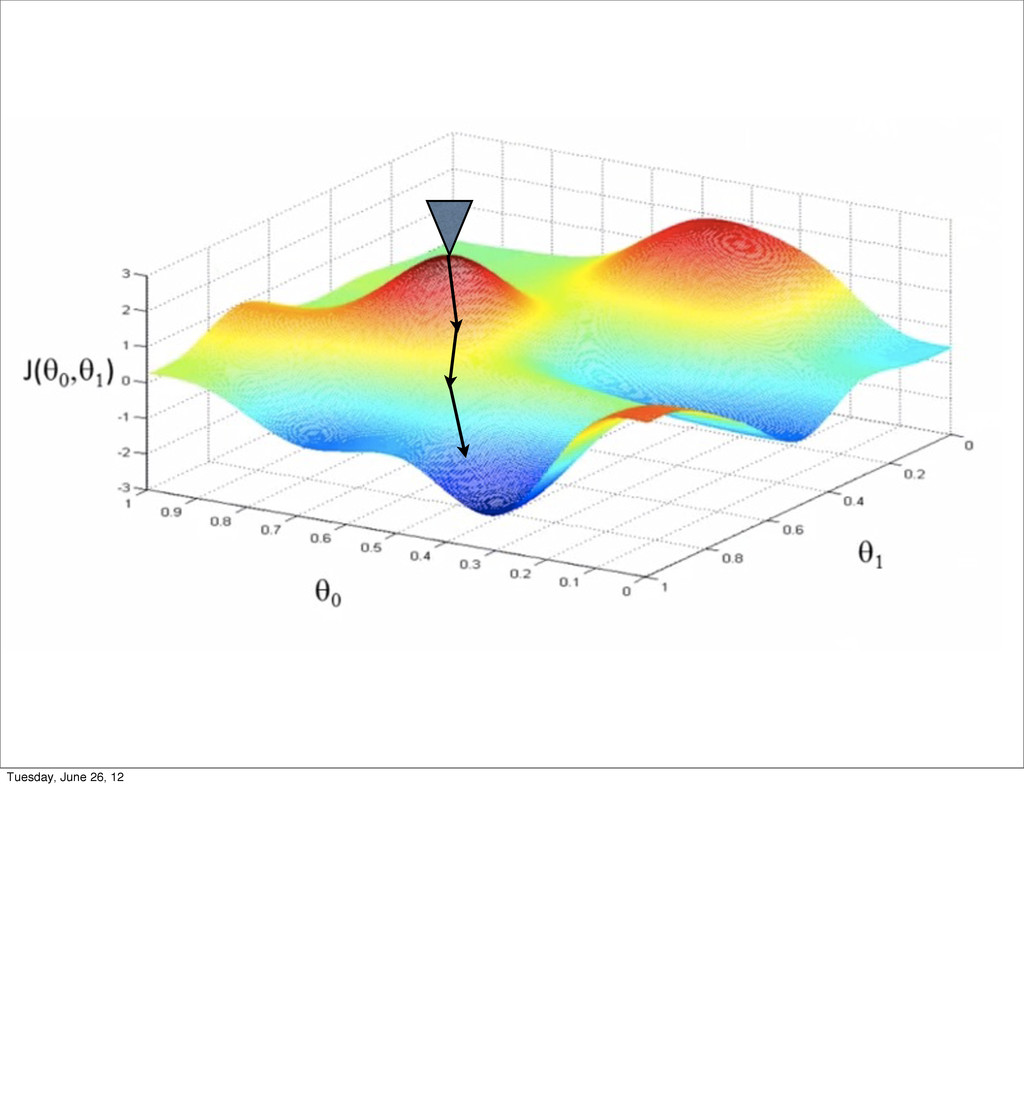
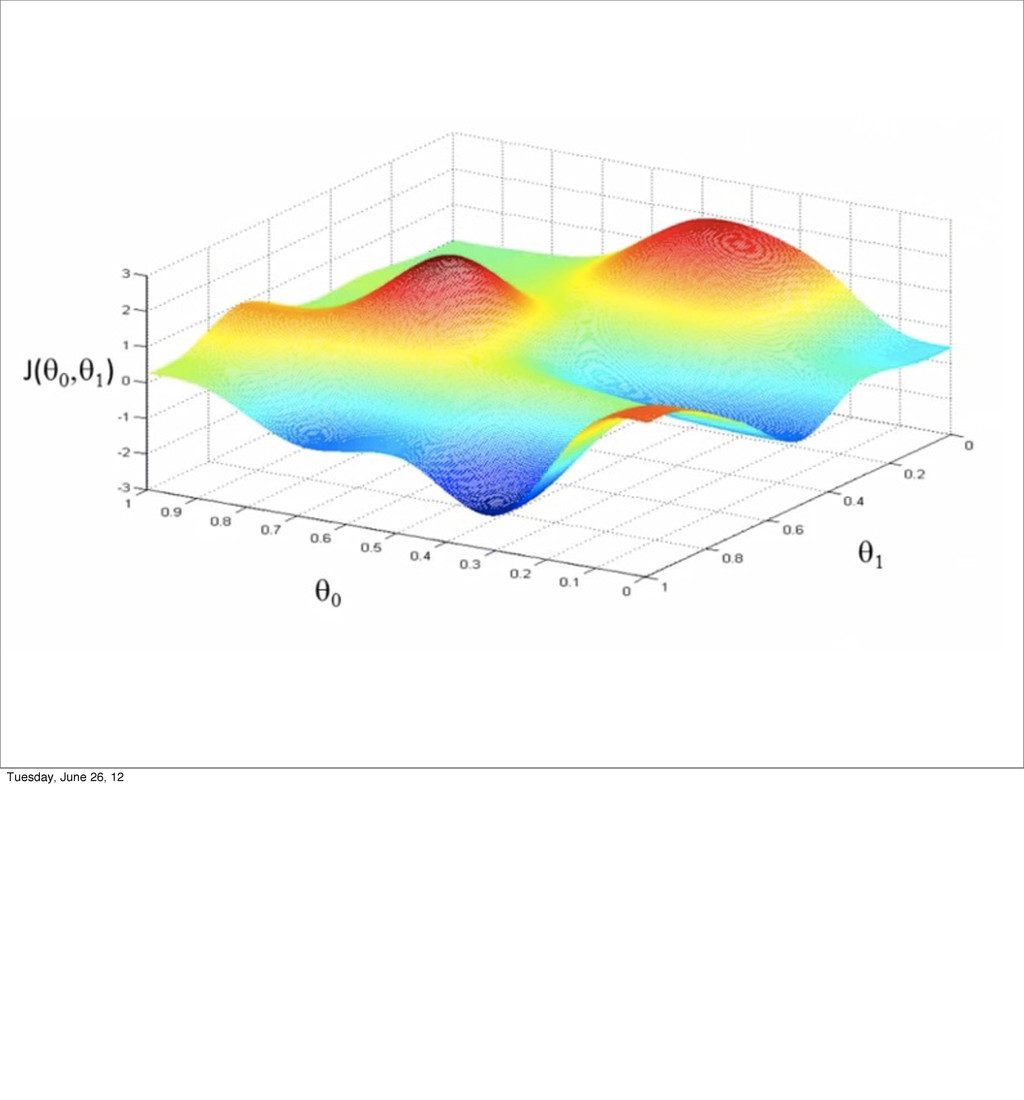
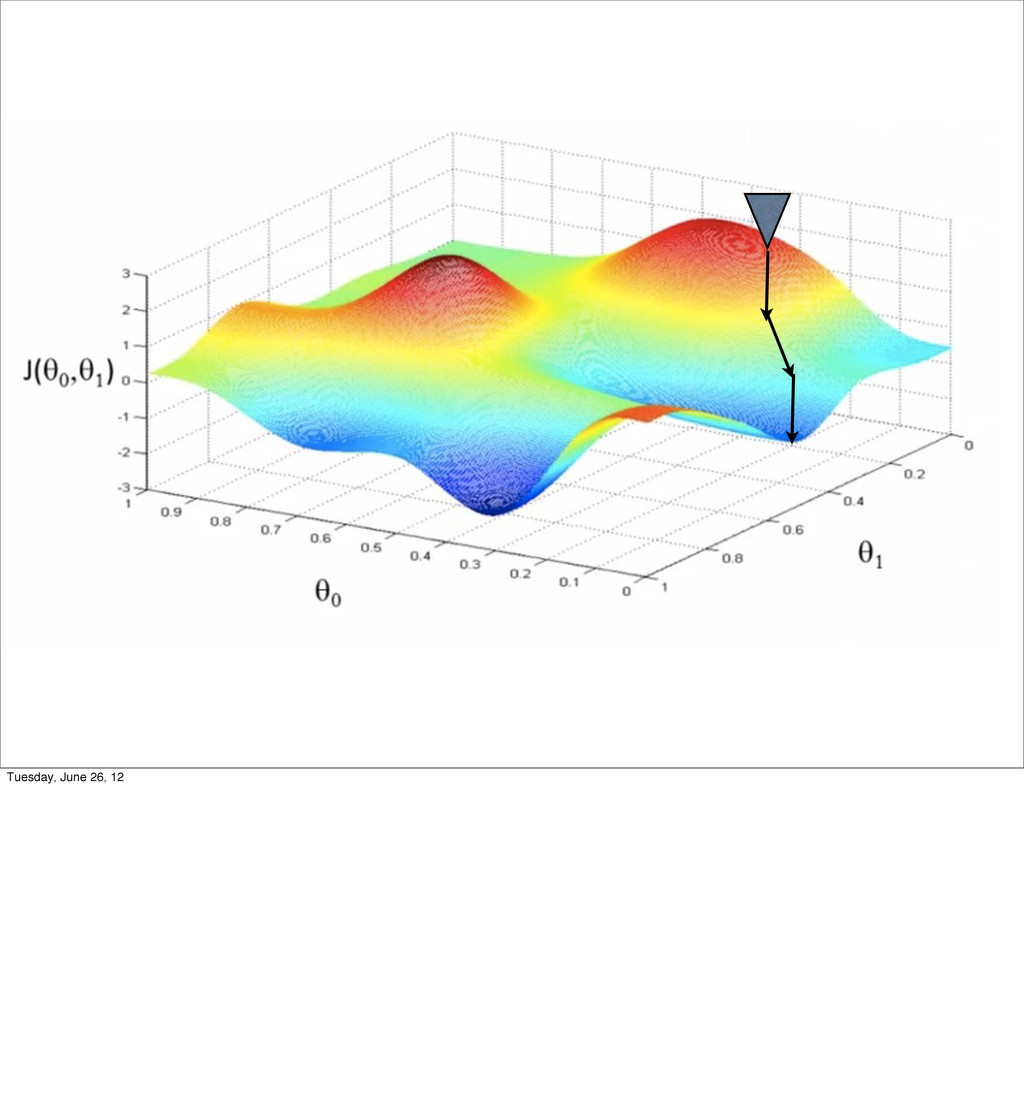
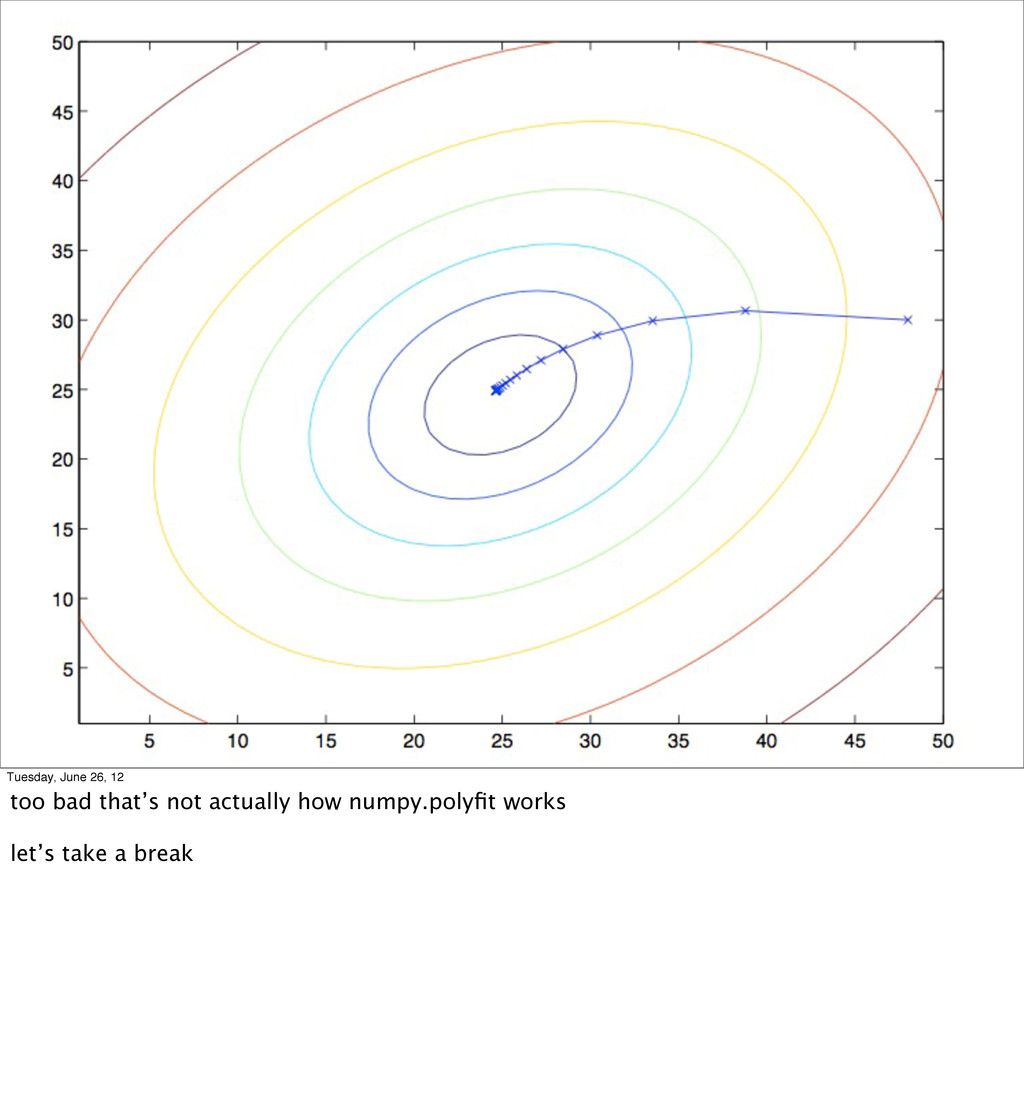
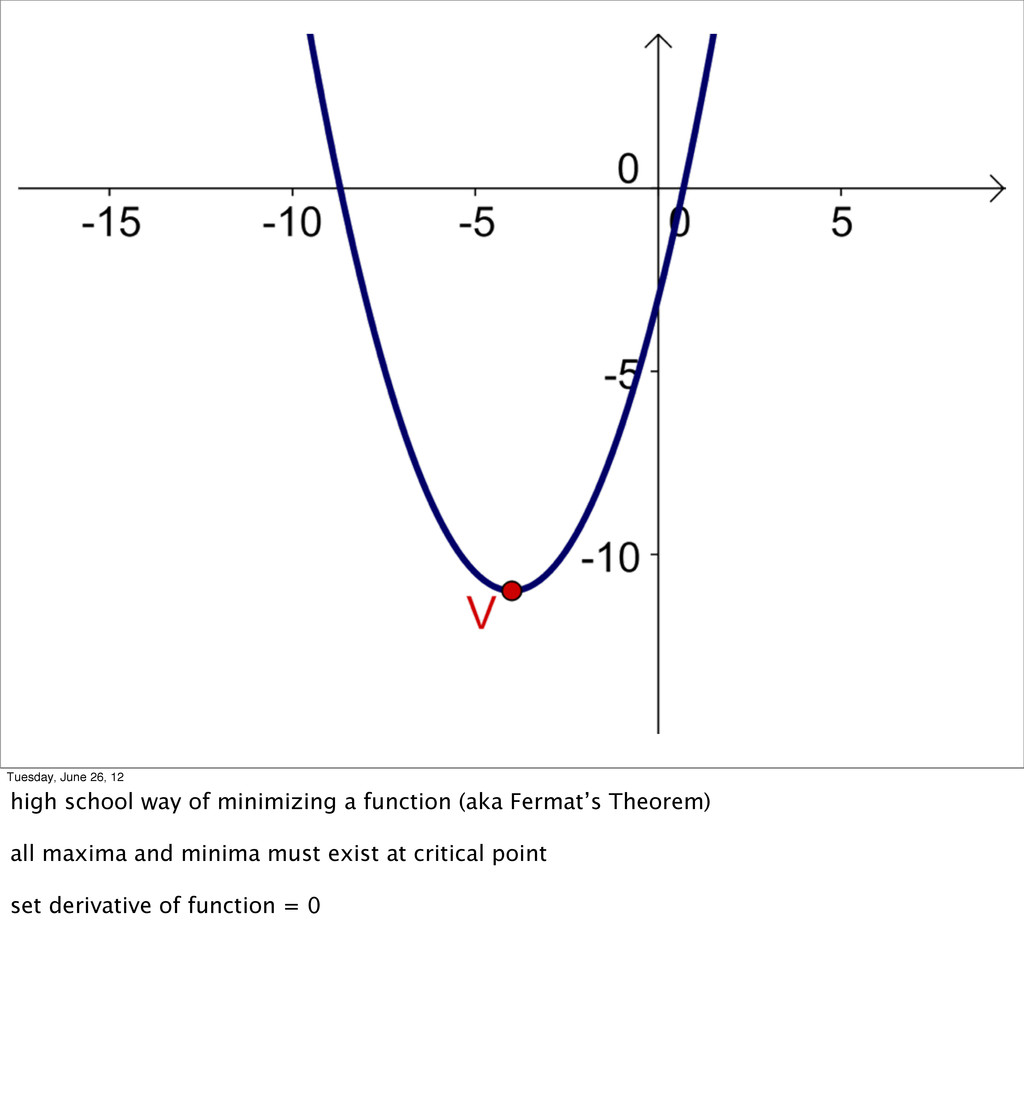
- Linear Regression
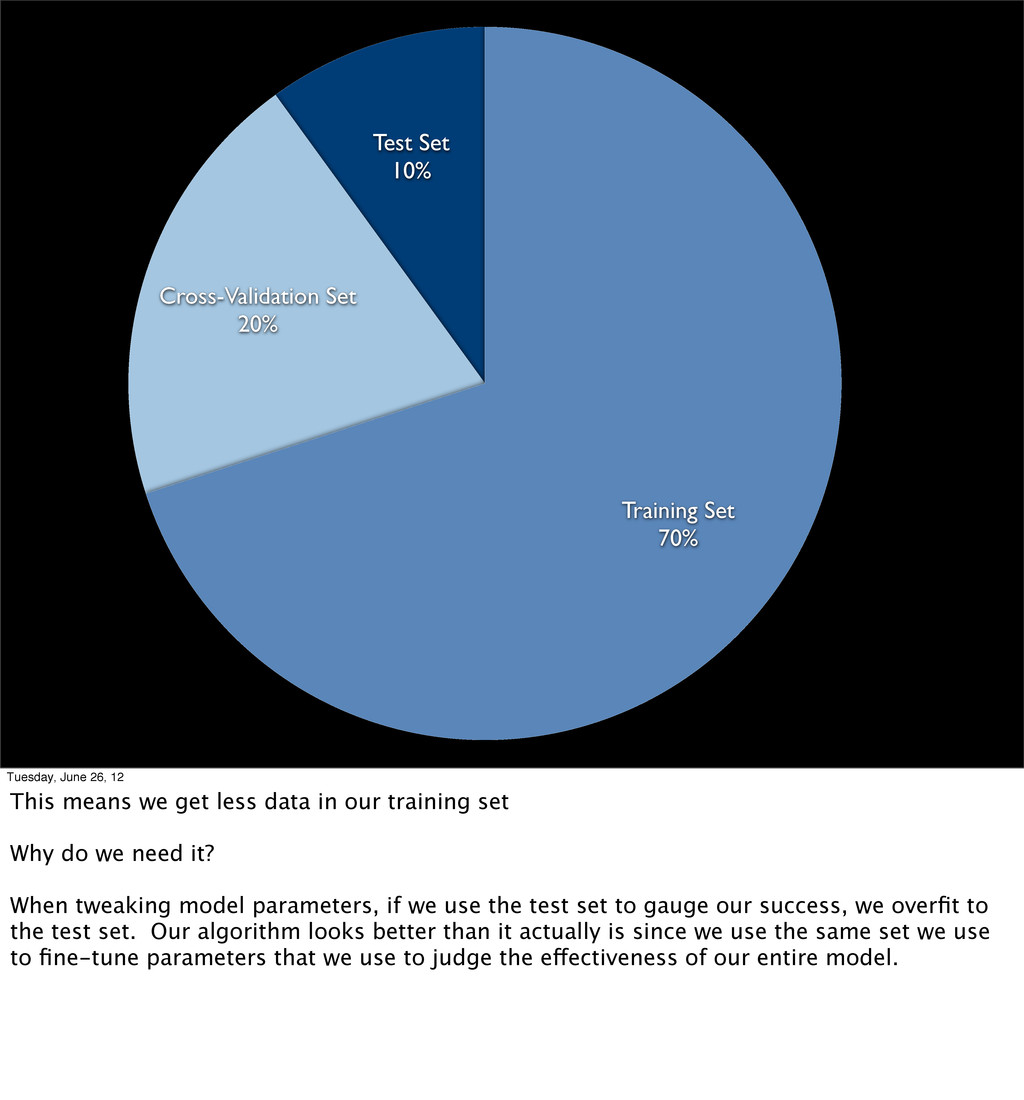
- Partitioning your data into training, test, and cross-validation sets
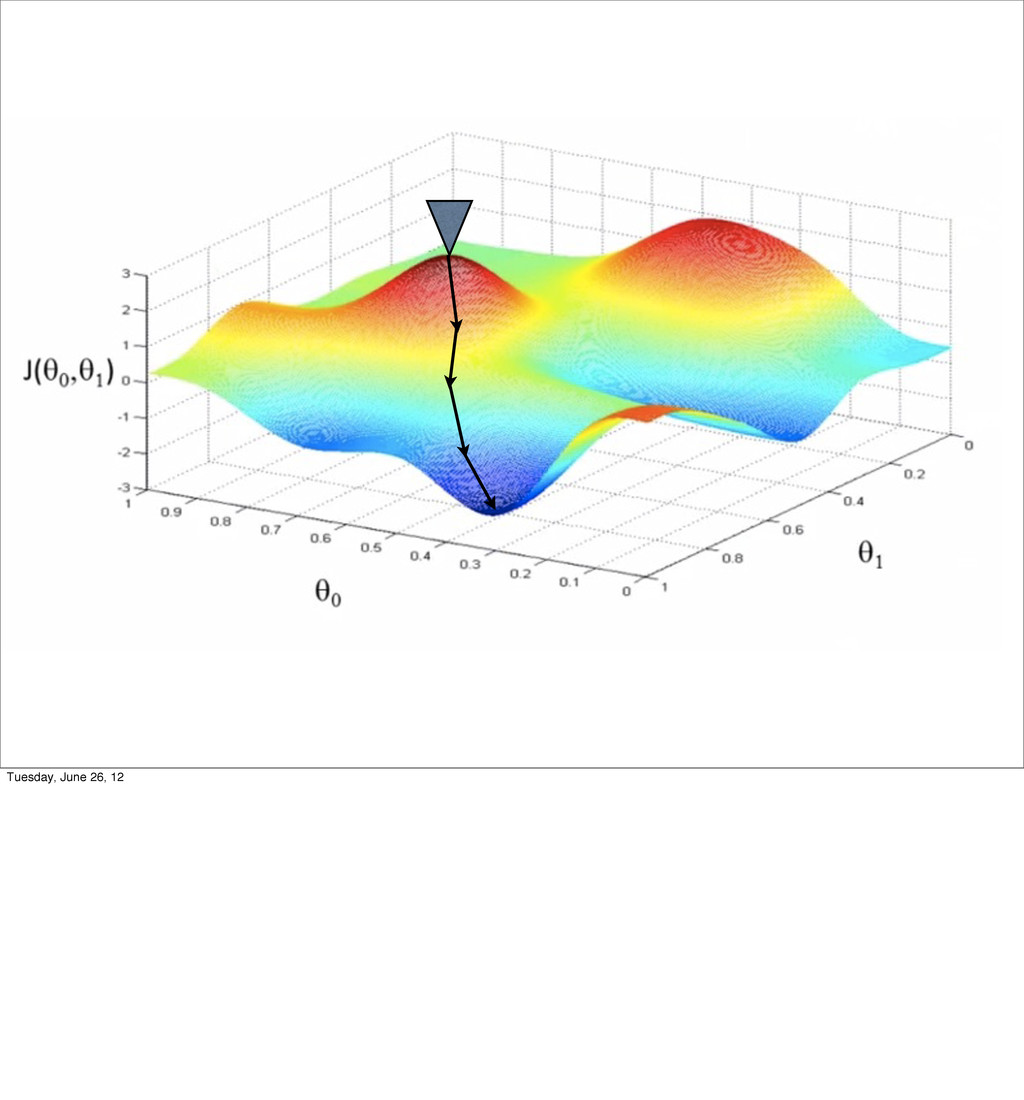
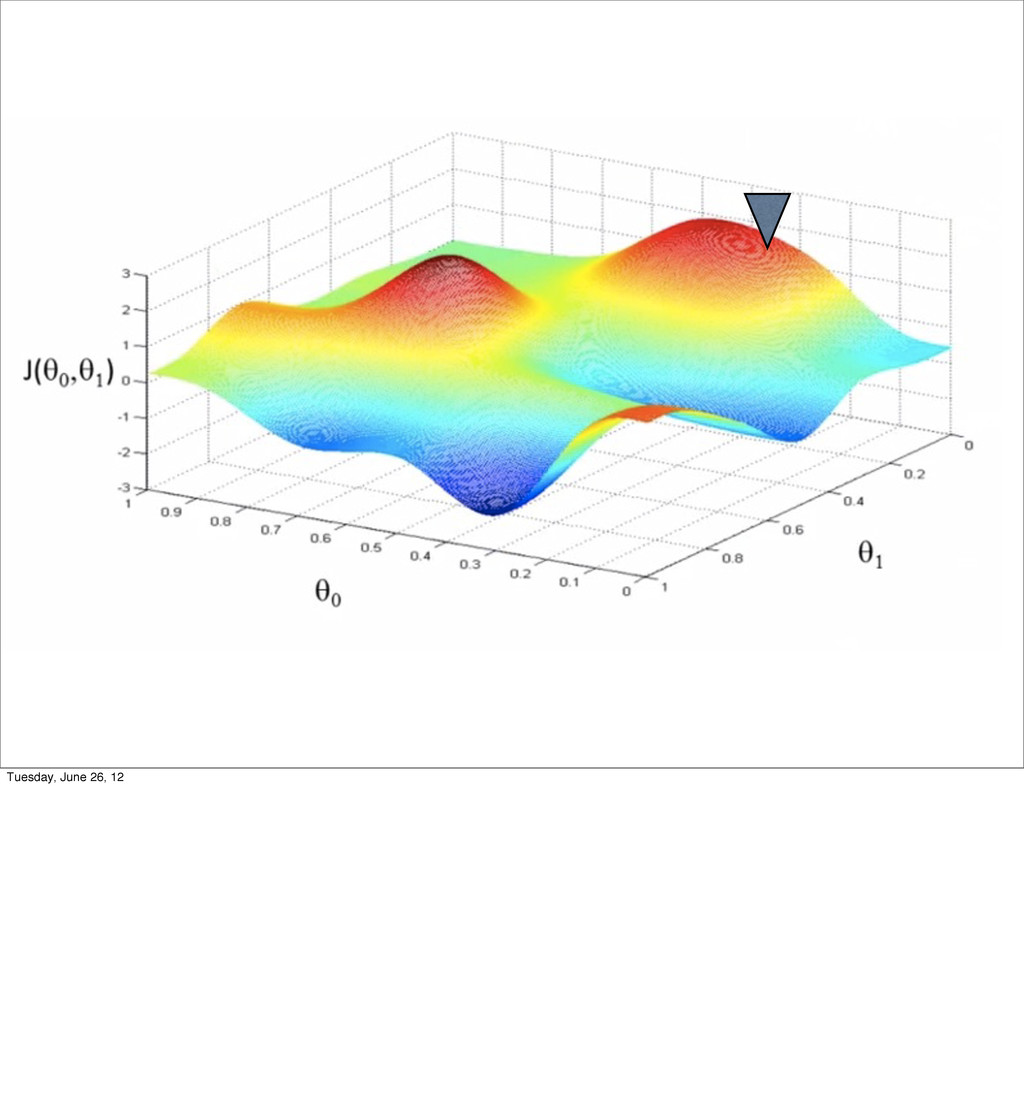
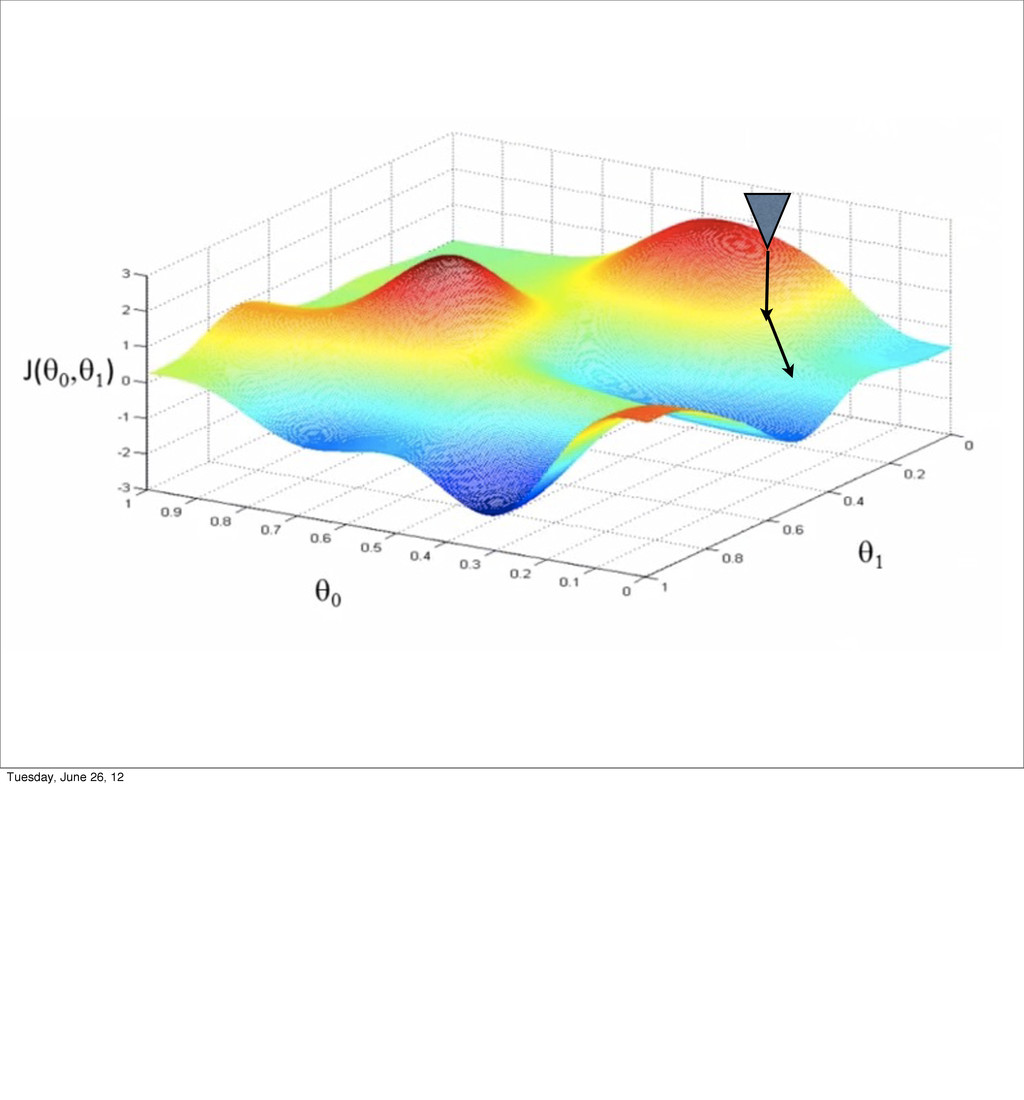
- Bias/variance tradeoff
- Regularization
- Logistic Regression
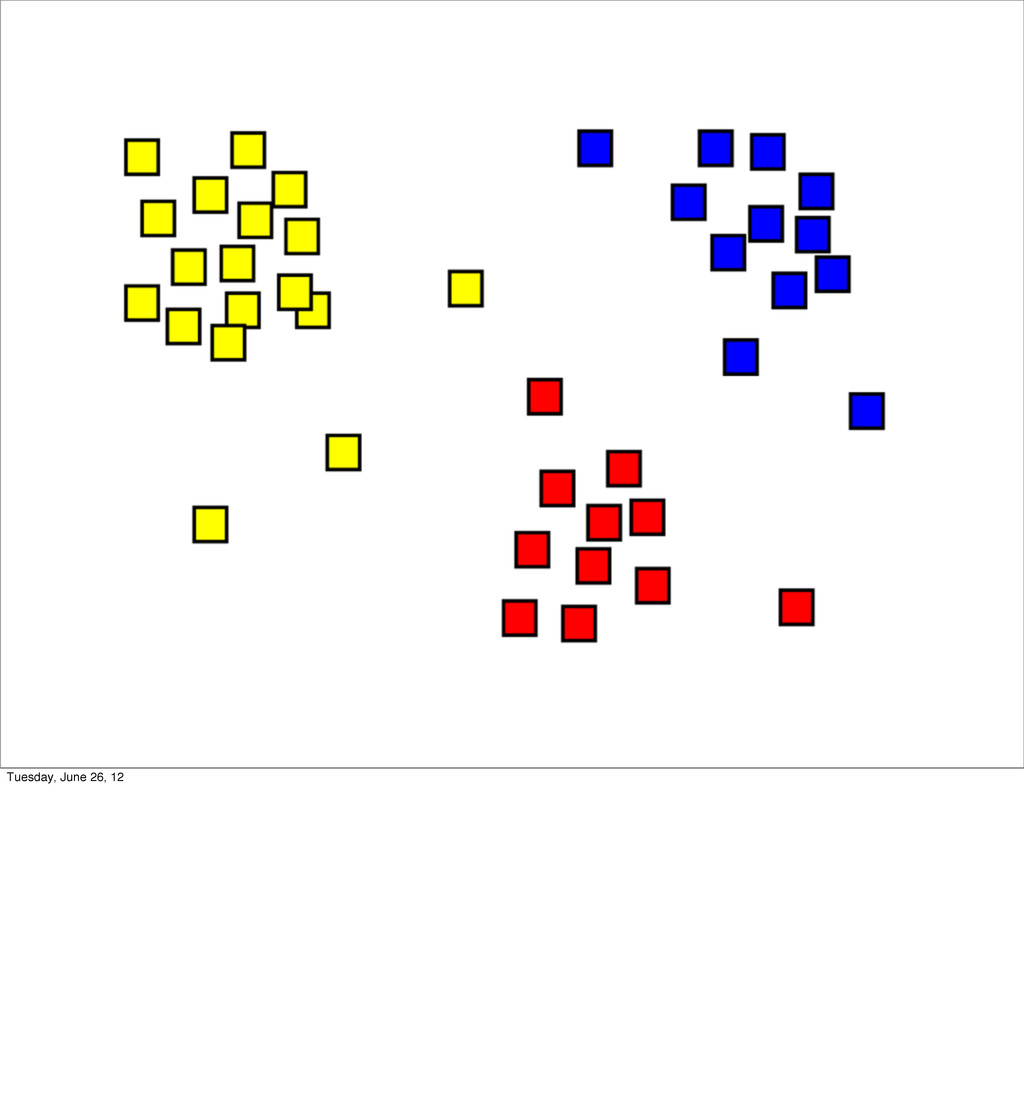
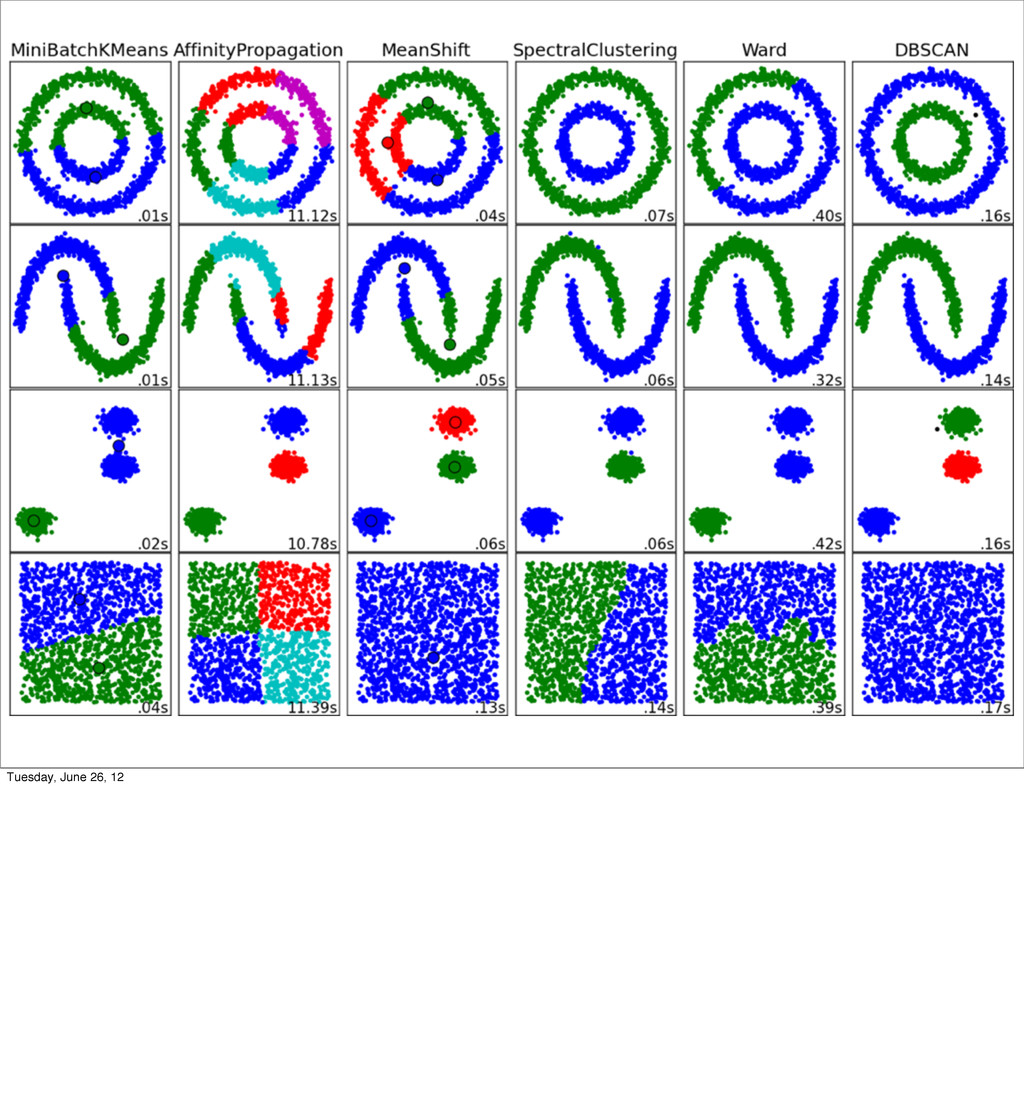
- Clustering
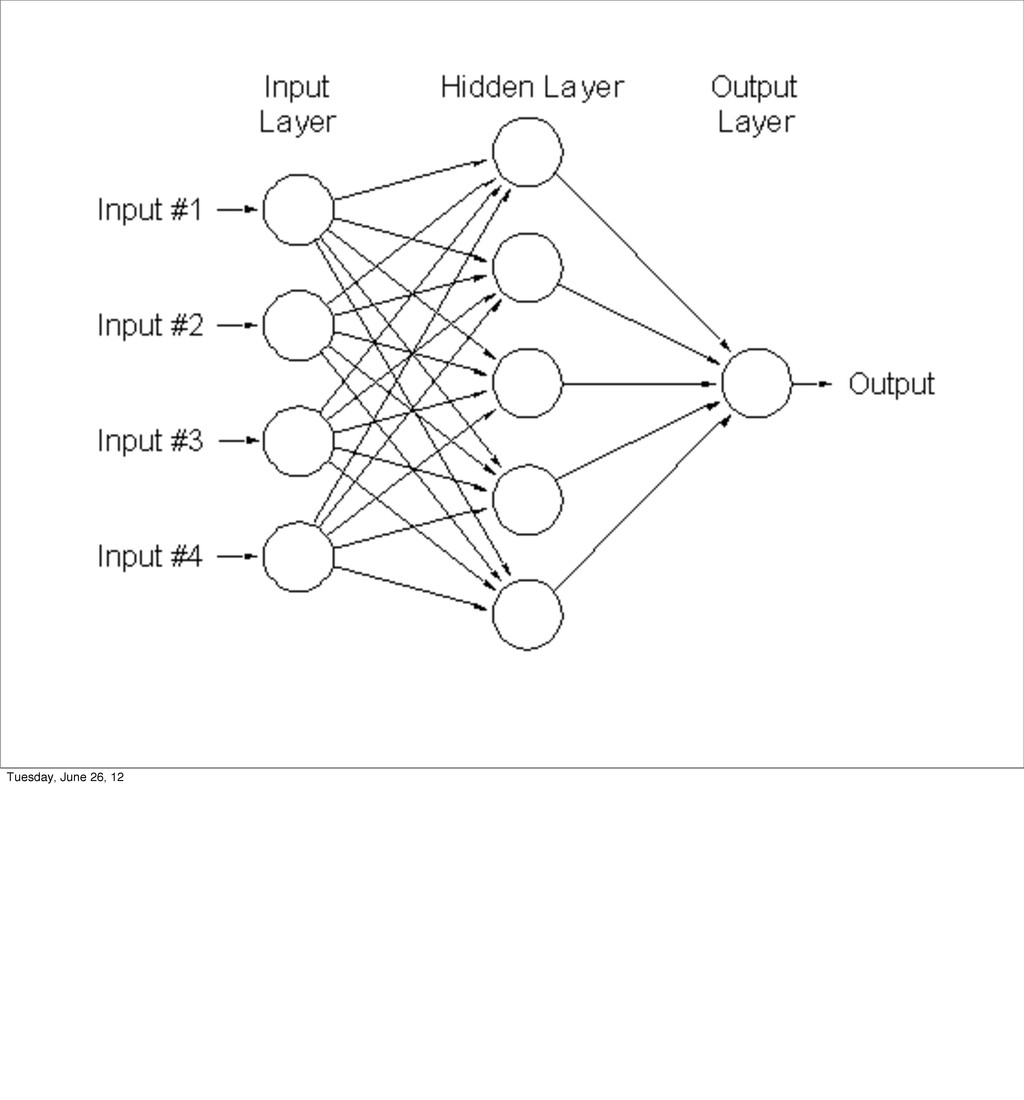
- Brief overview of more advanced algorithms such as neural networks
and support vector machines
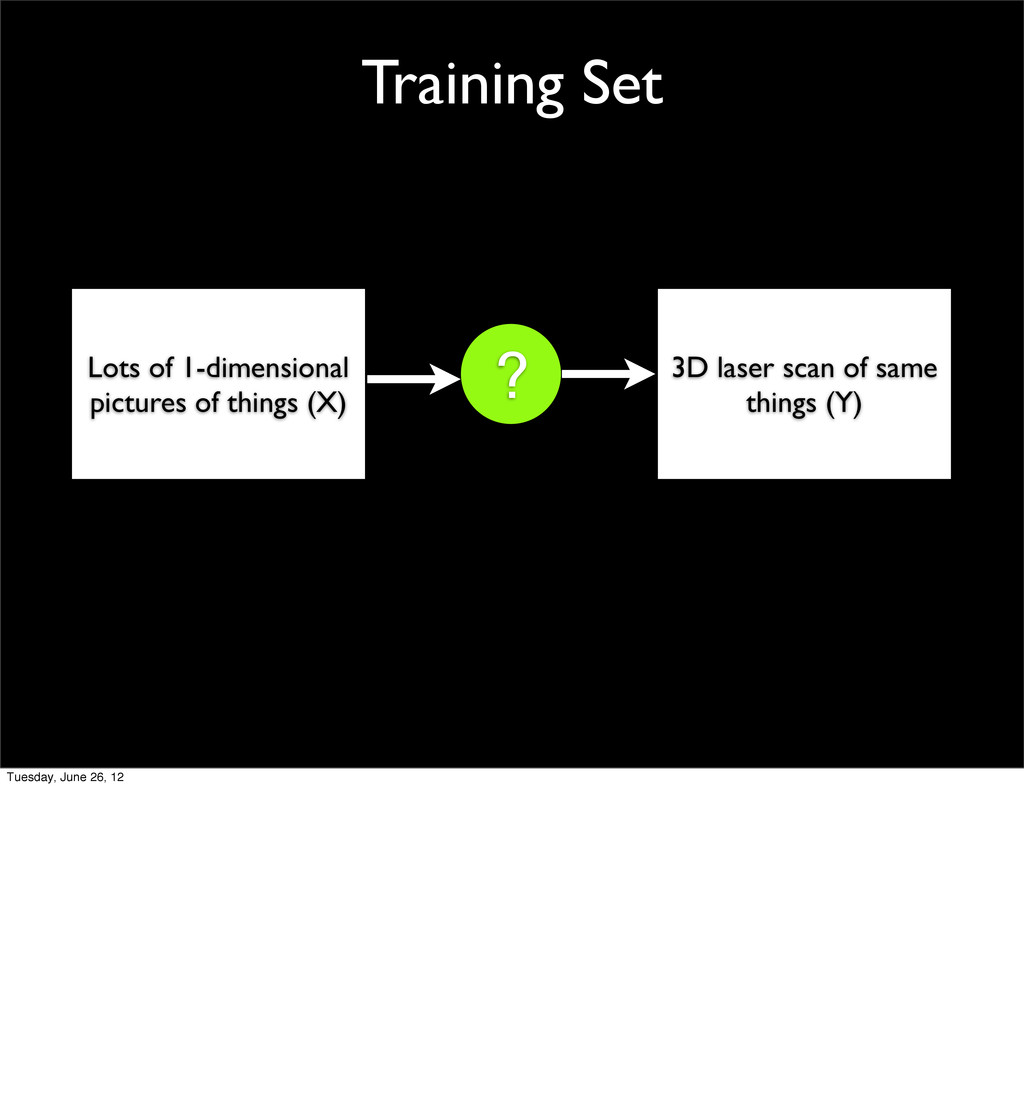
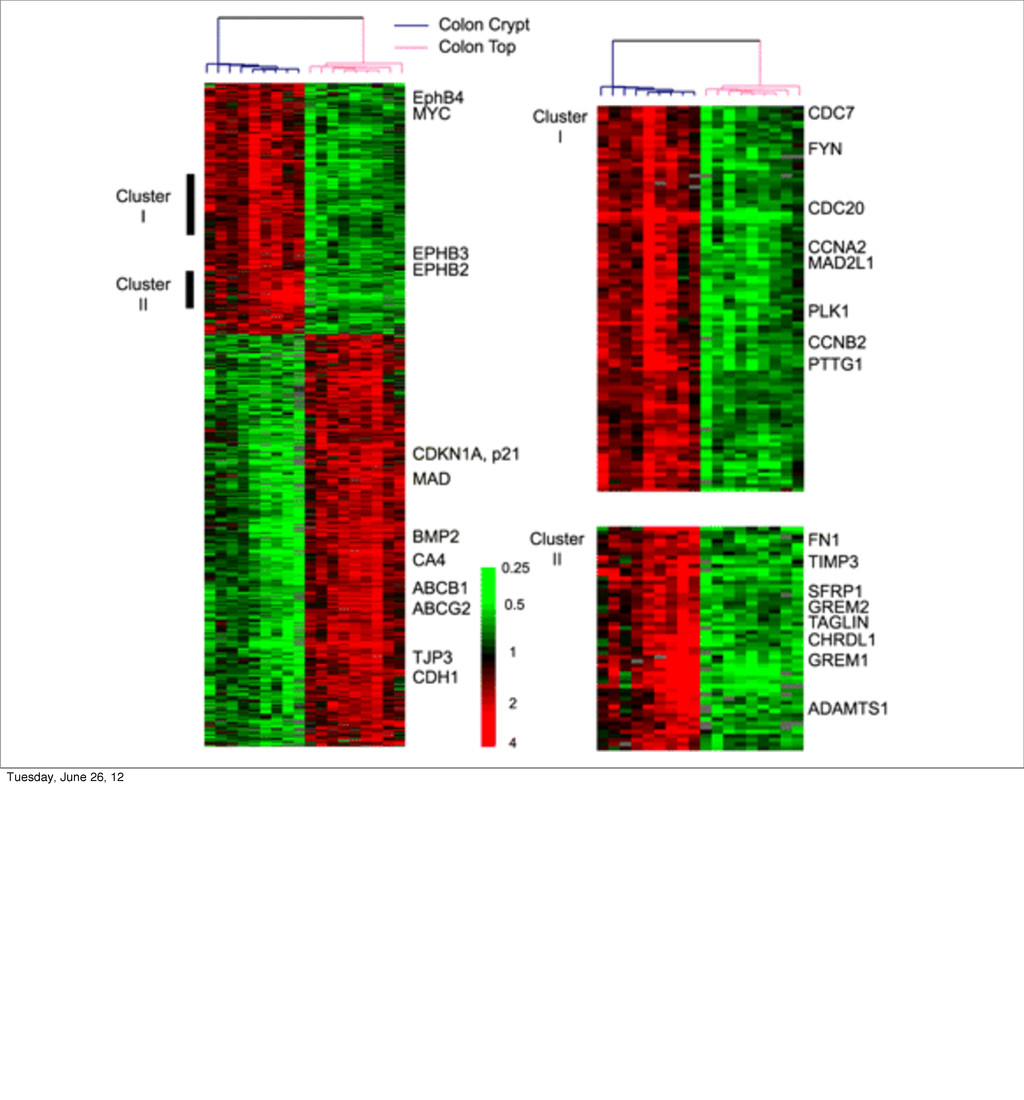
- Advanced applications such as digit recognition and collaborative filtering
Should be fun!
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
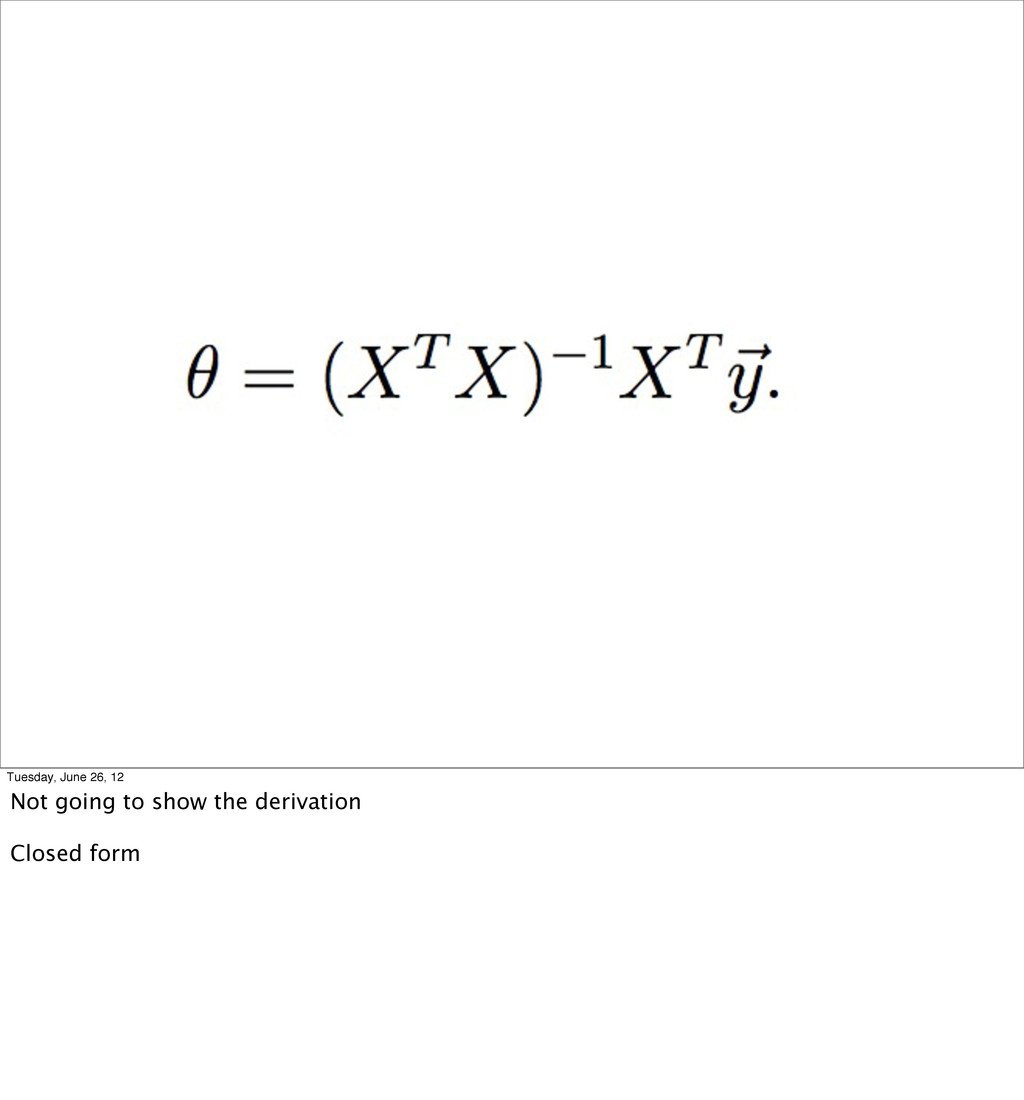{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}