You can’t build a CI/CD pipeline and support fast-paced development cycles without considering continuous reliability. On the one hand, this means being rehearsed and prepared for every scenario. On the other, this calls for a contingency plan for when (inevitably) something will go wrong.
Join this live event and see how DevOps tools can help you plan for the best and prepare for the worst, as Julie from Gremlin injects chaos into the Bank of Anthos’ system and Rona from Komodor troubleshoots things back into order.
{kind=link}
{kind=link}
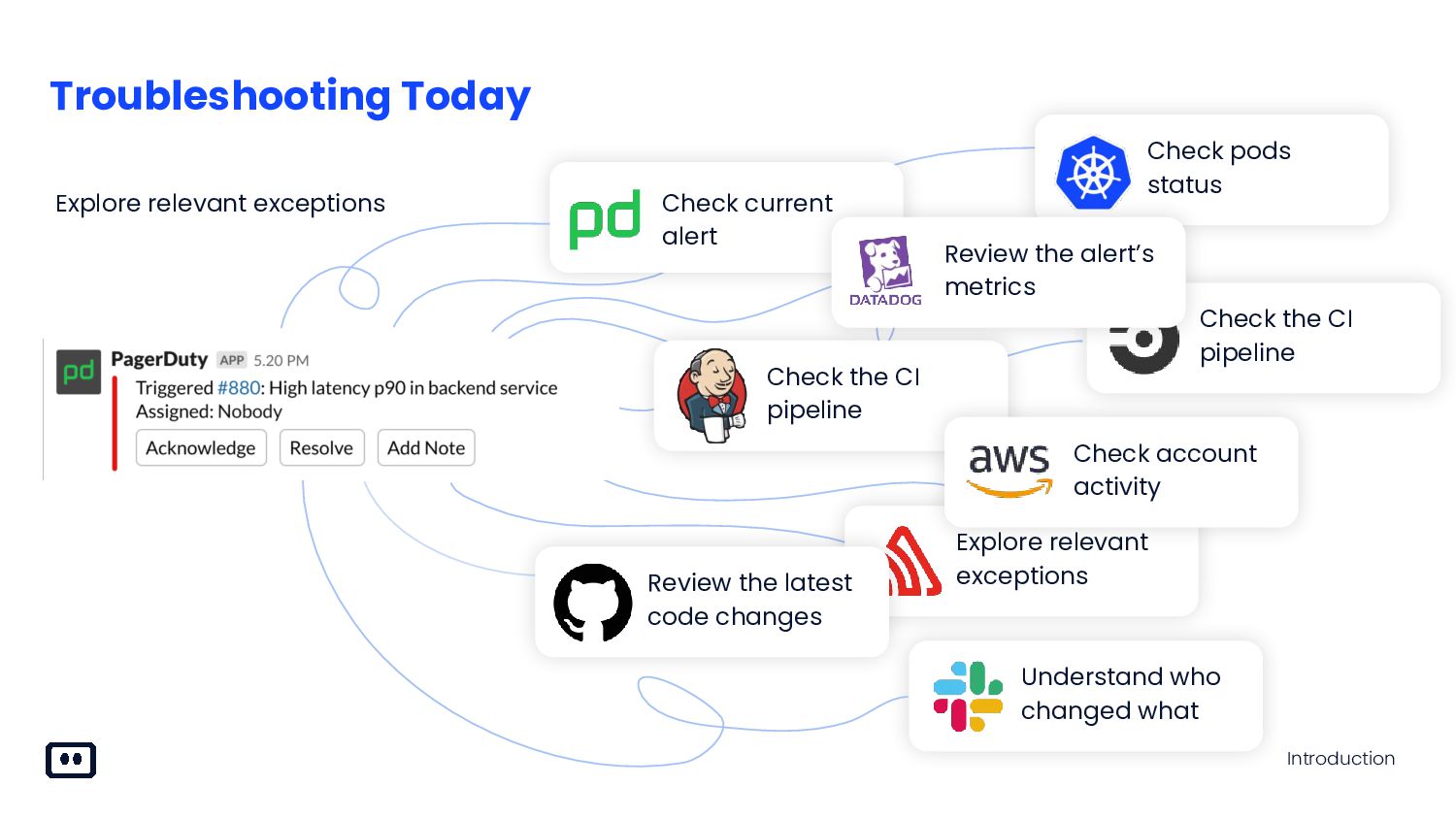{kind=link}
{kind=link}
{kind=link}
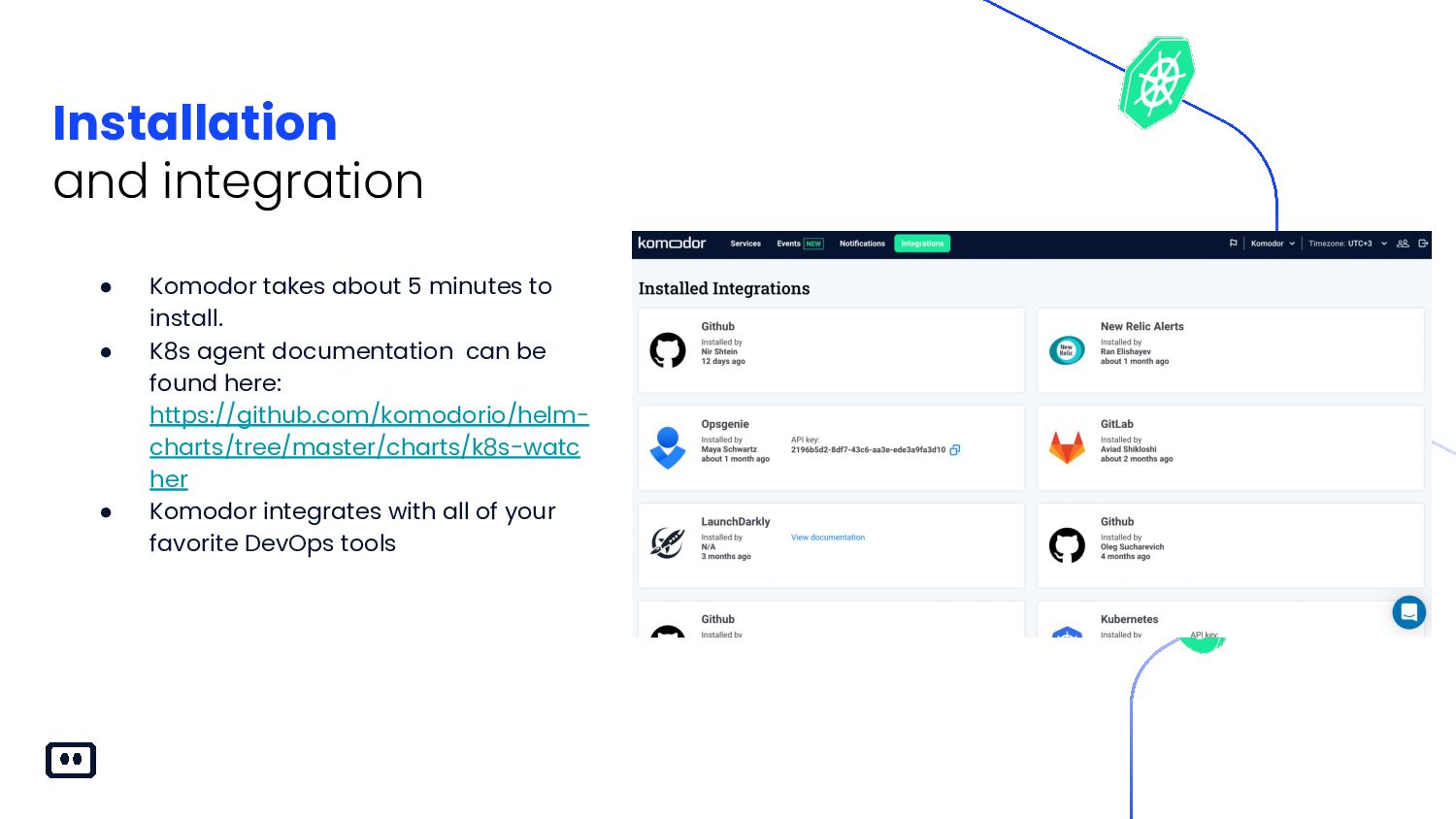{kind=link}
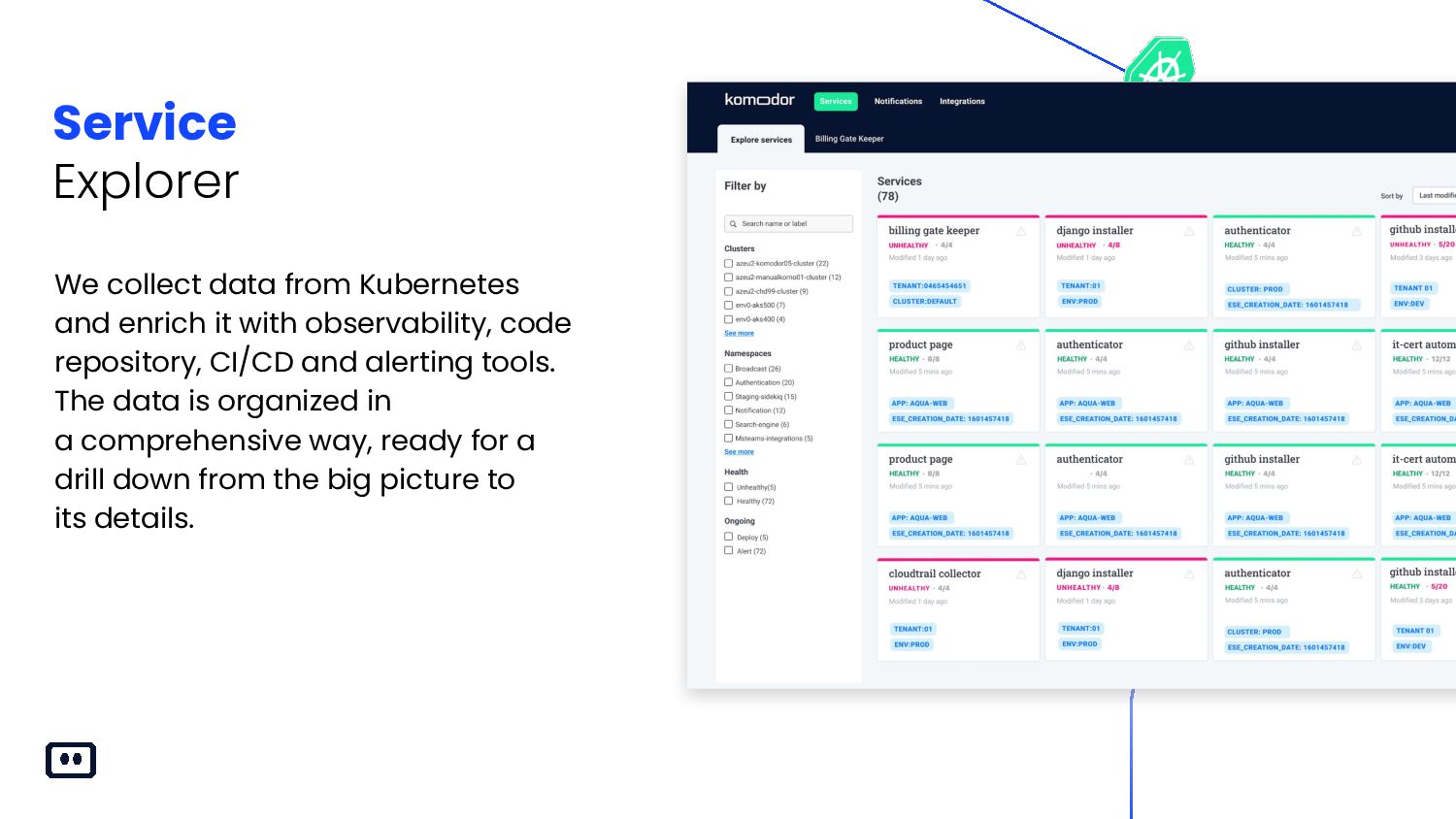{kind=link}
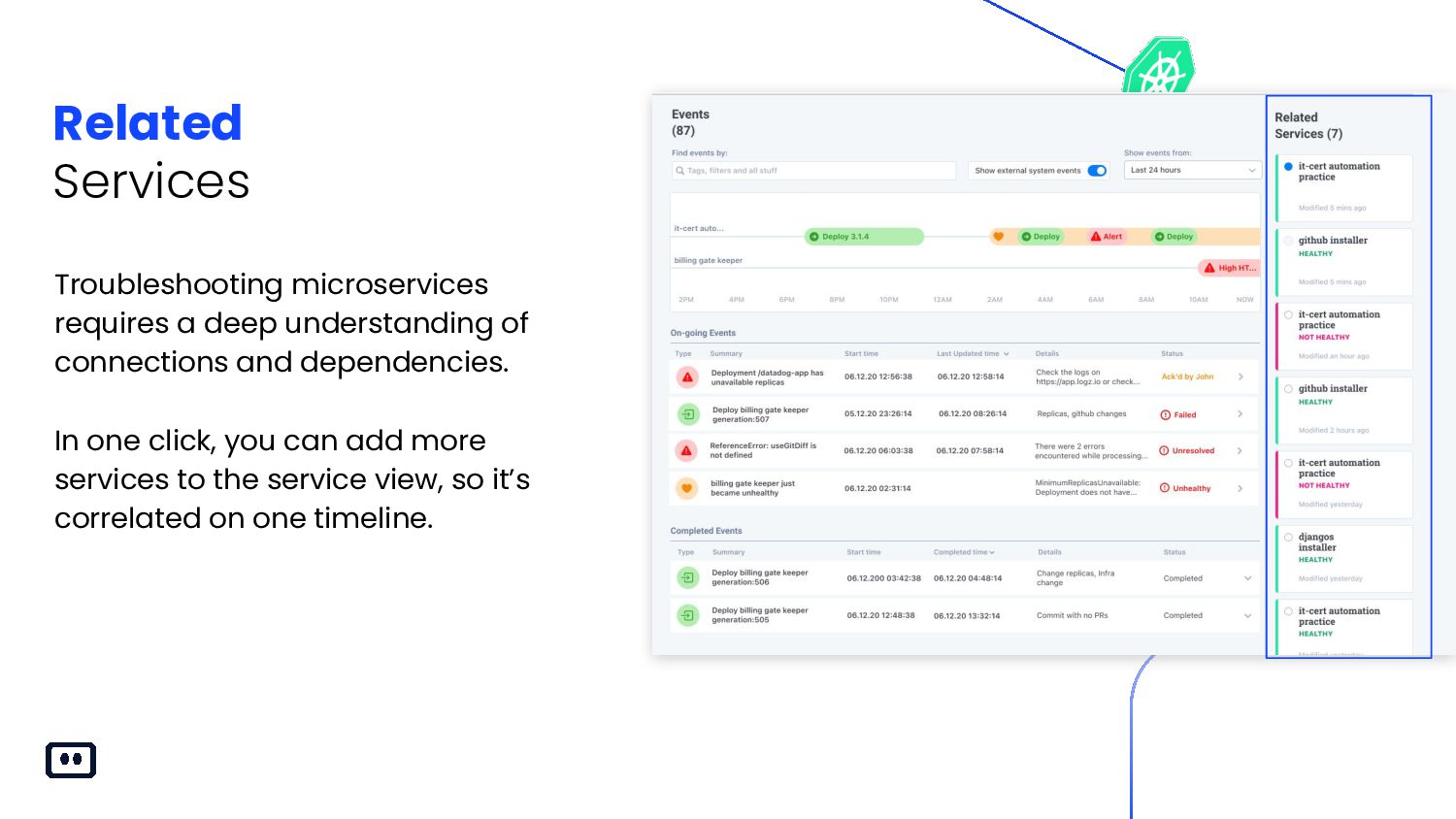{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}