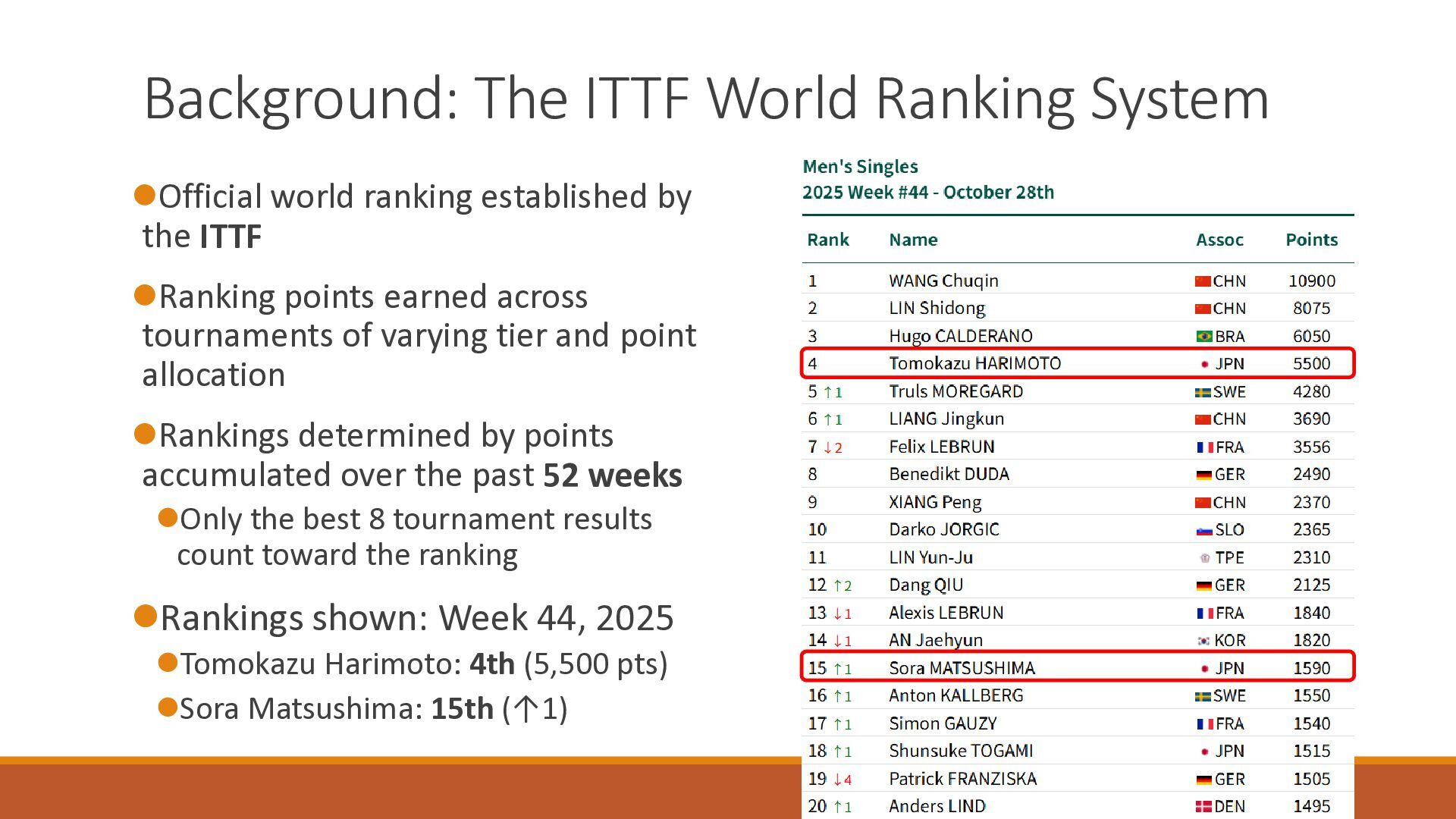
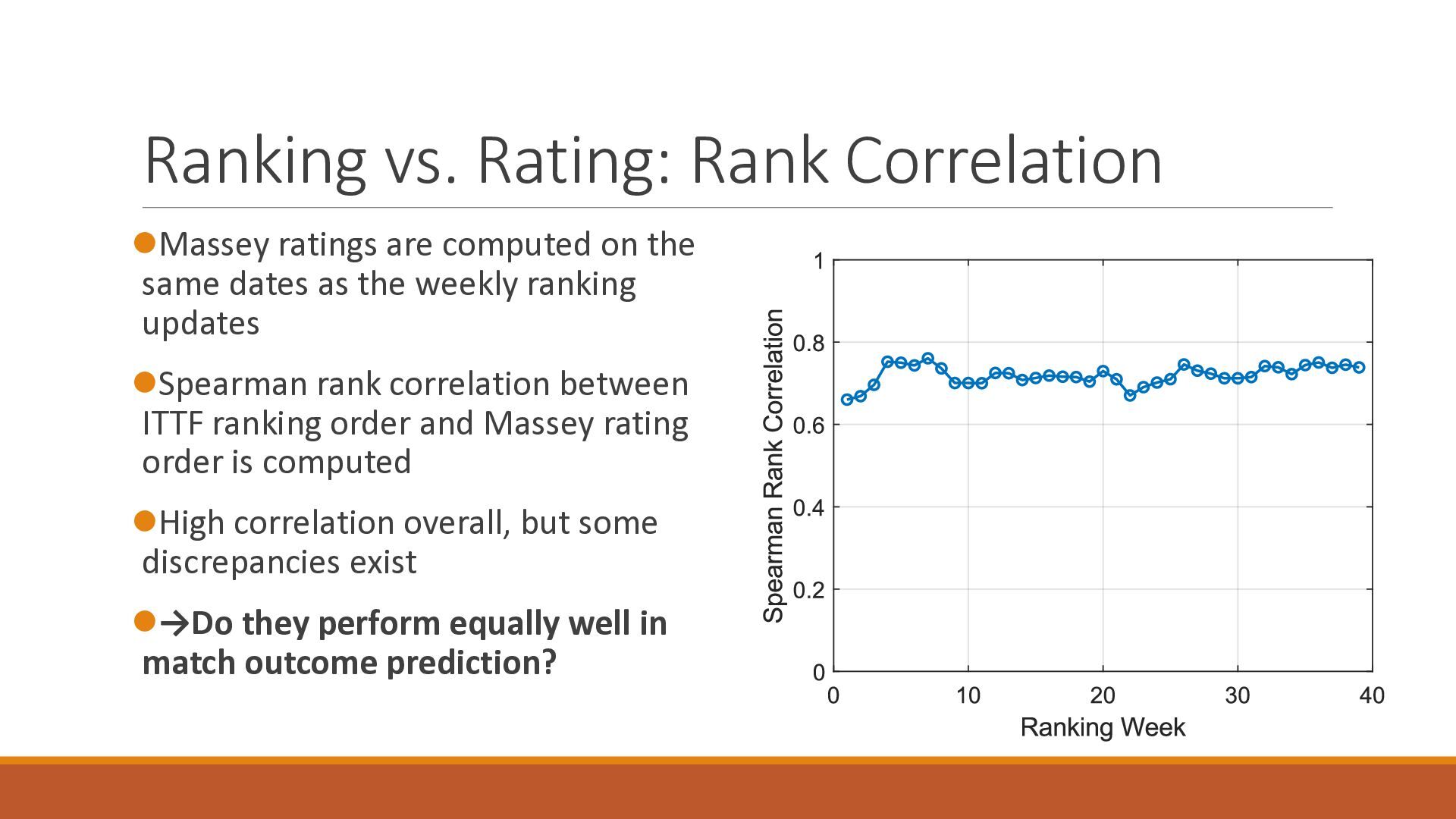
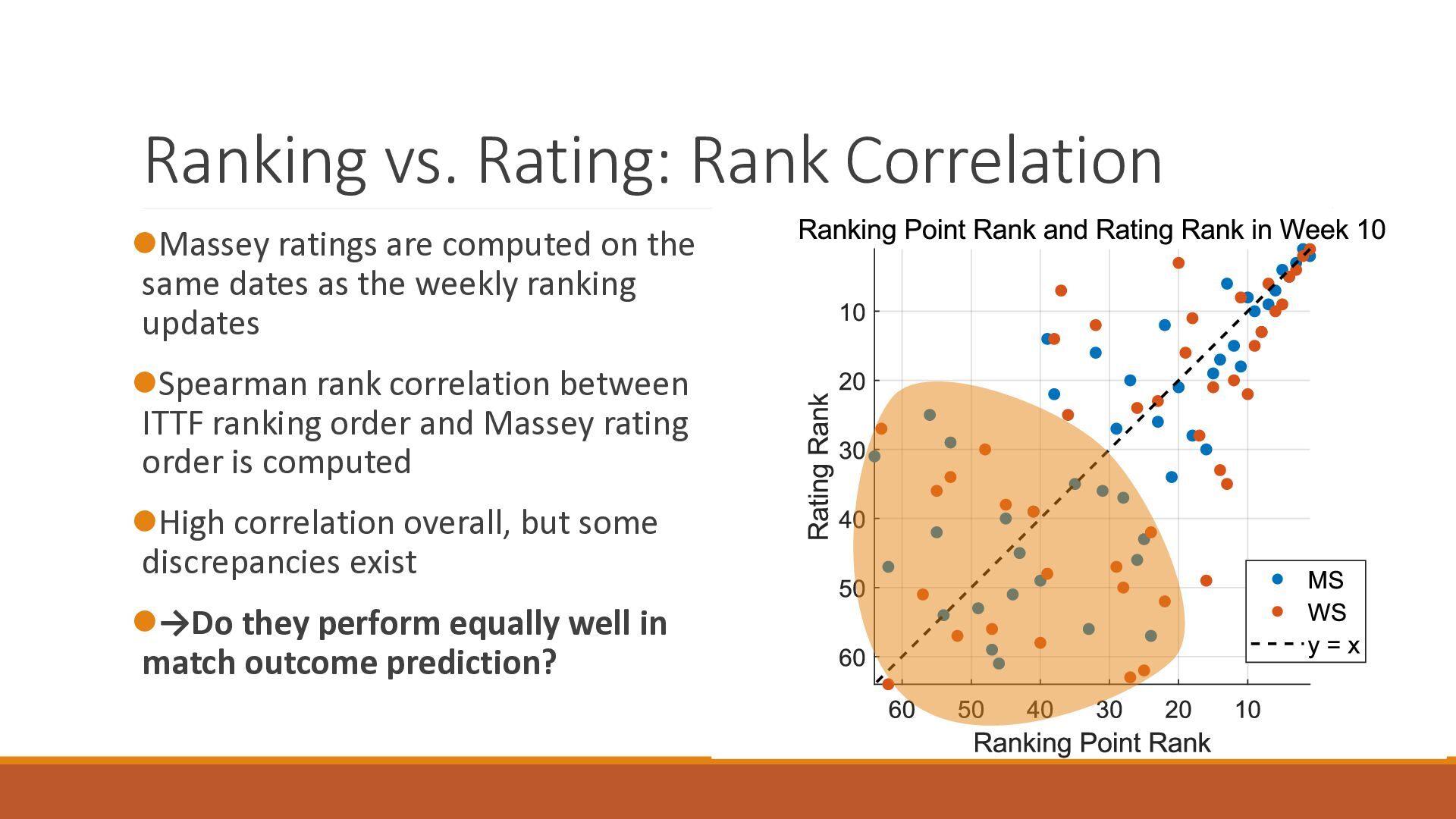
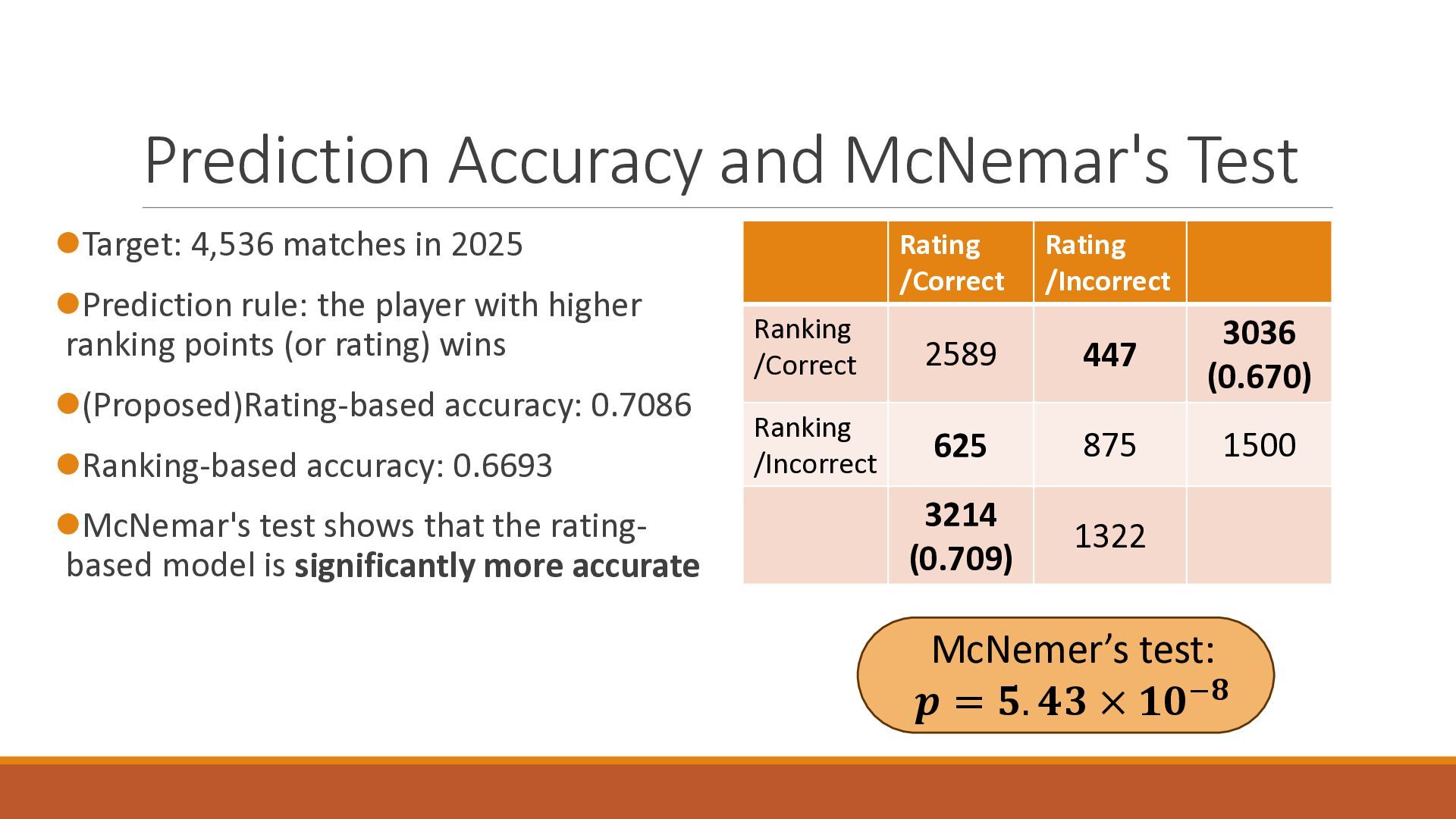
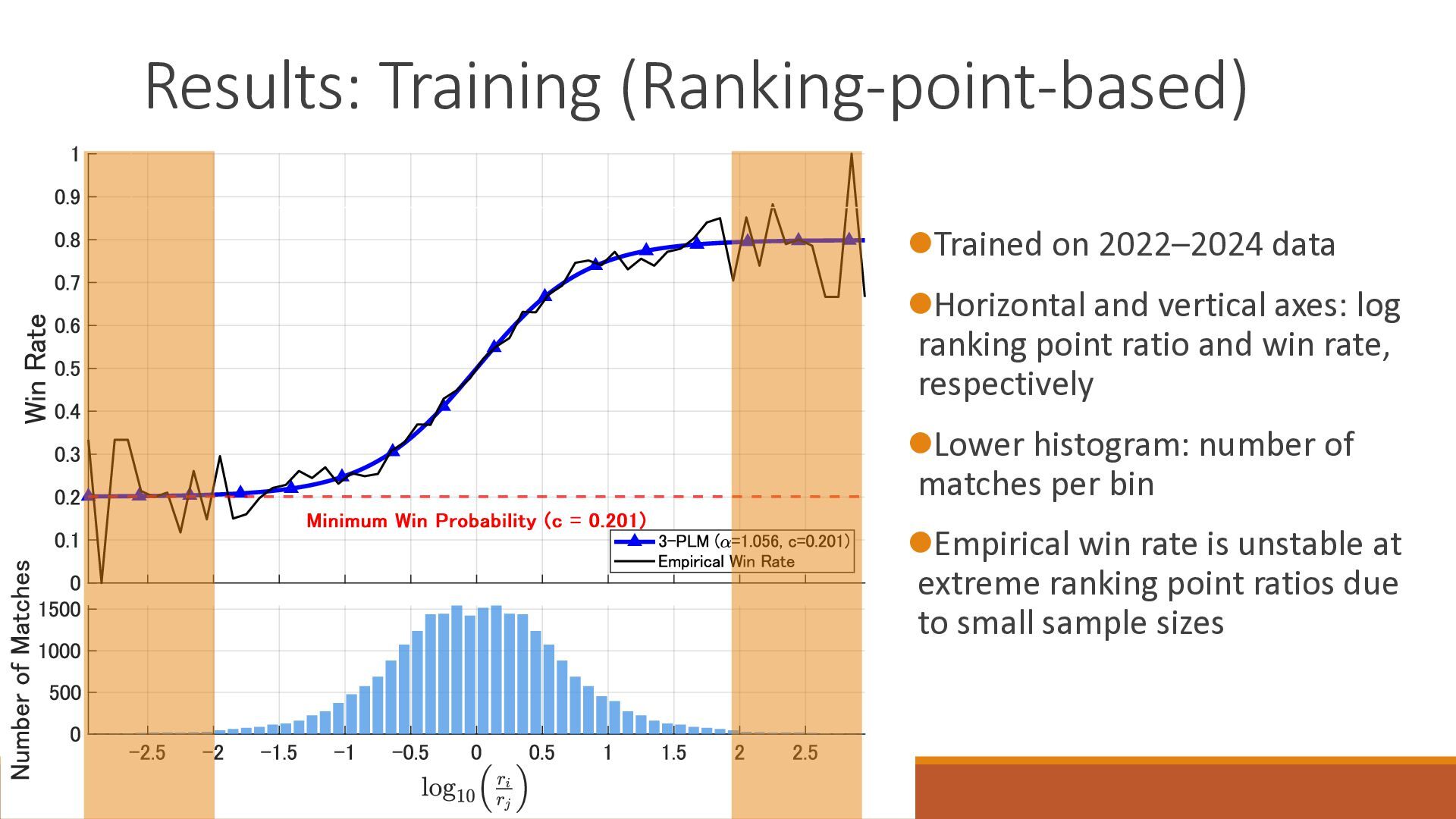
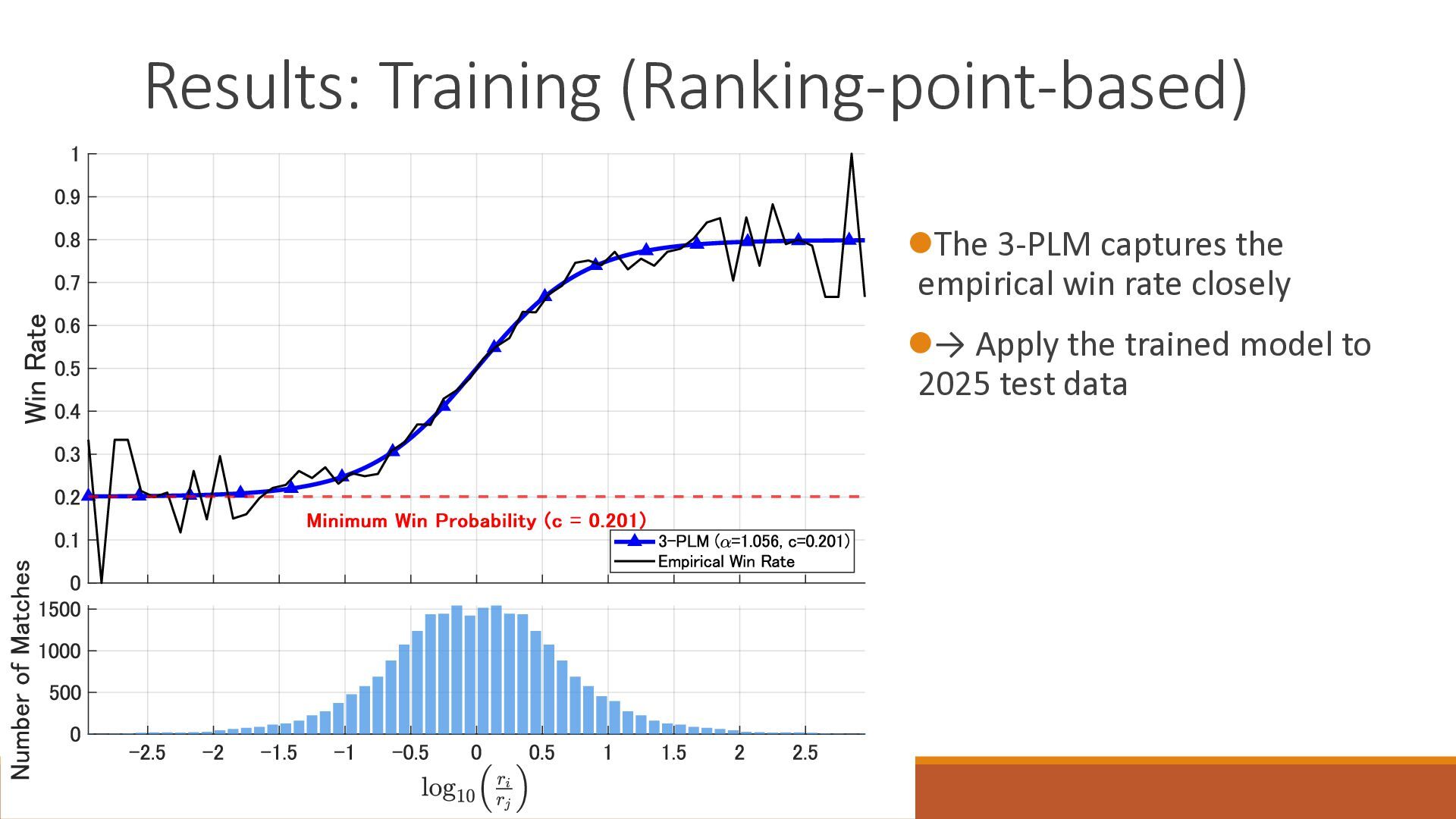
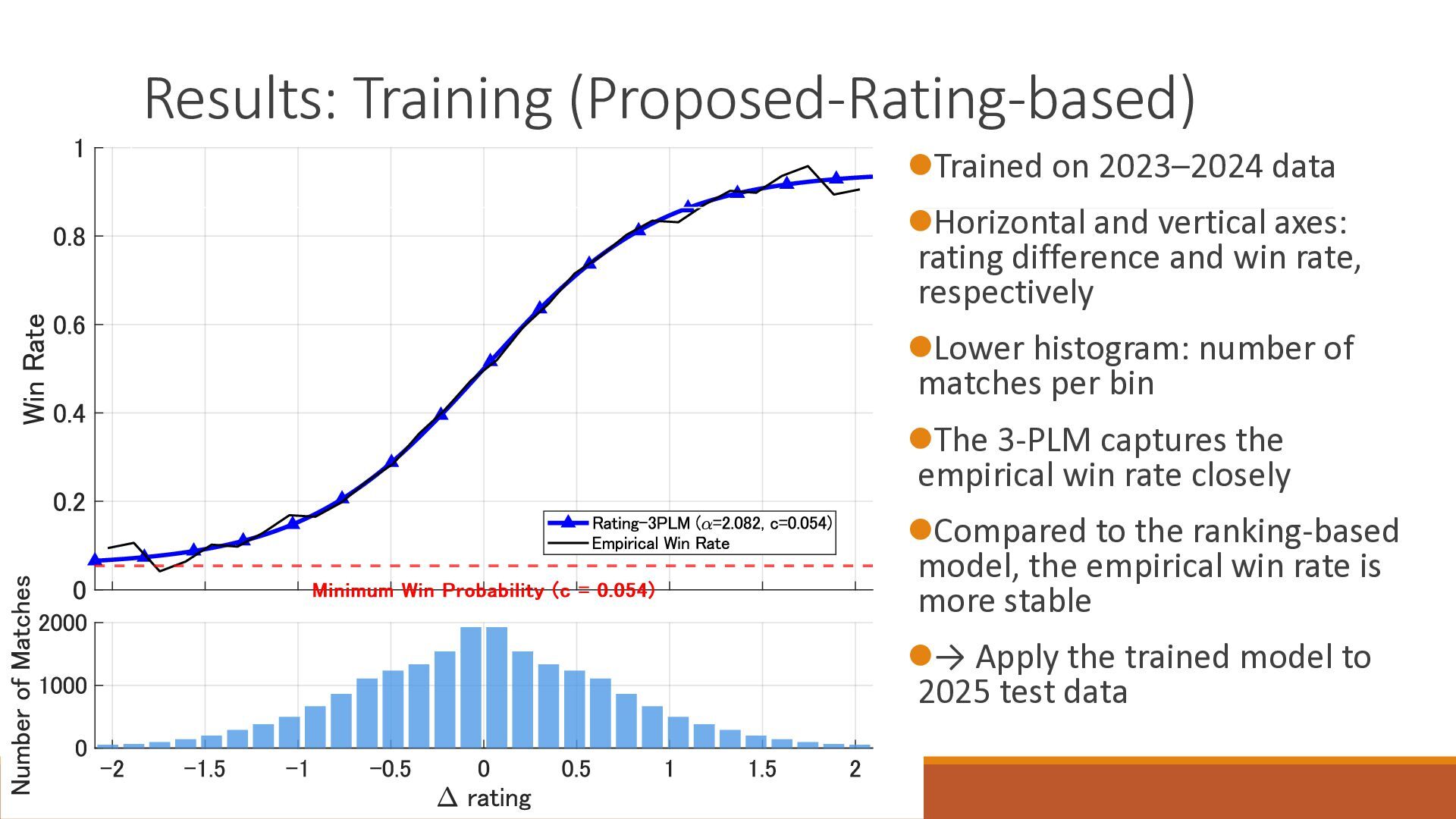
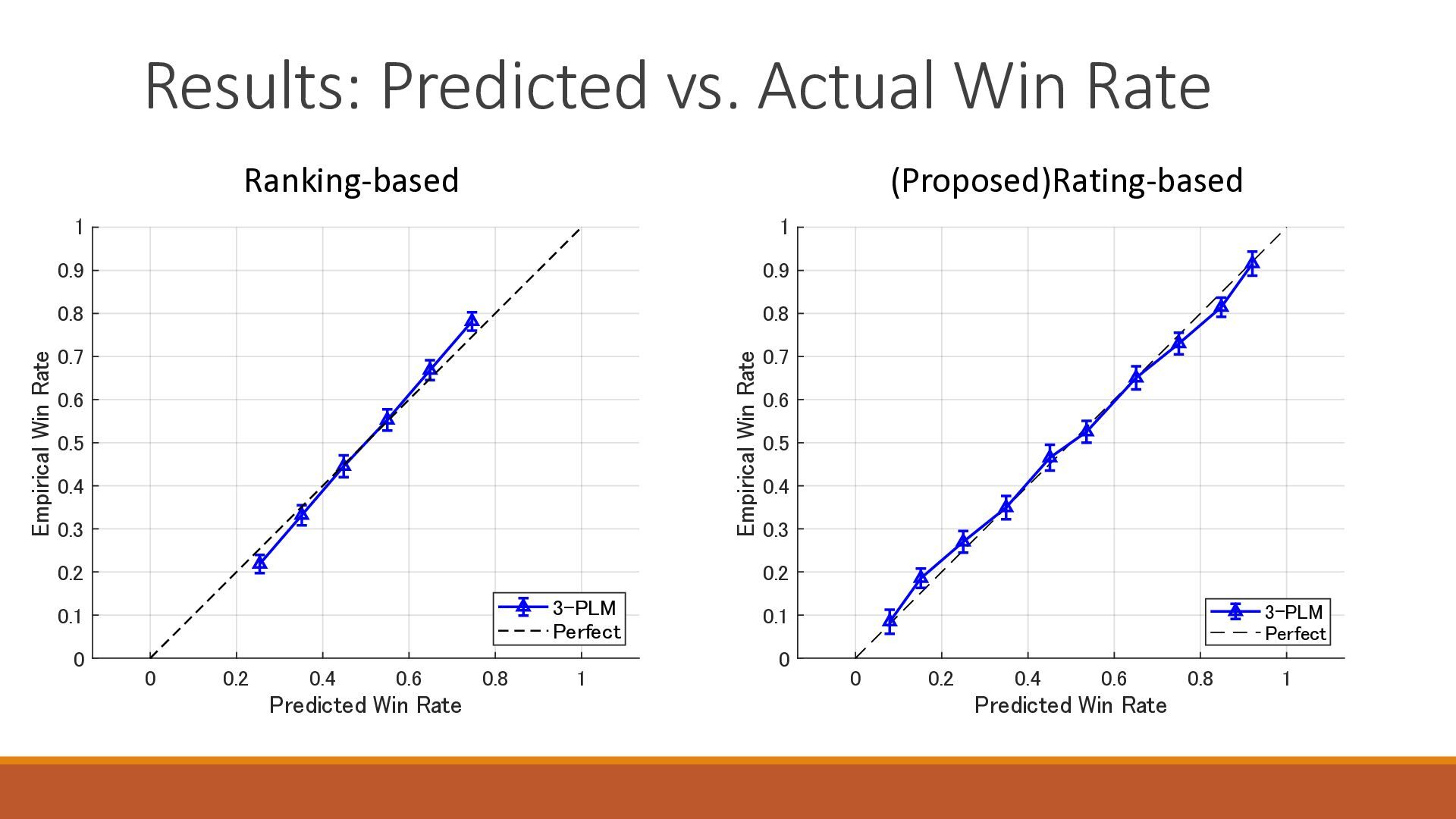
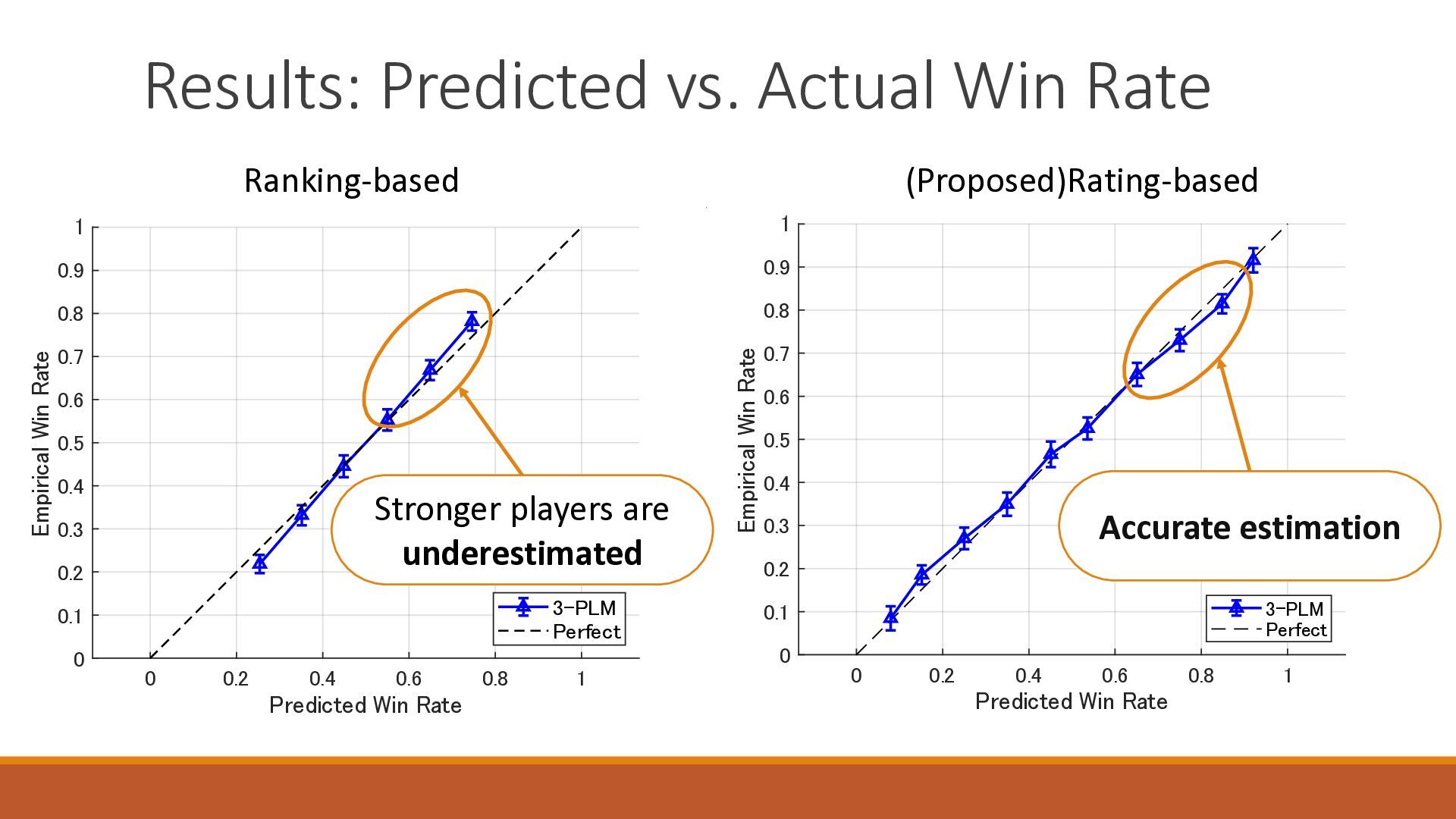
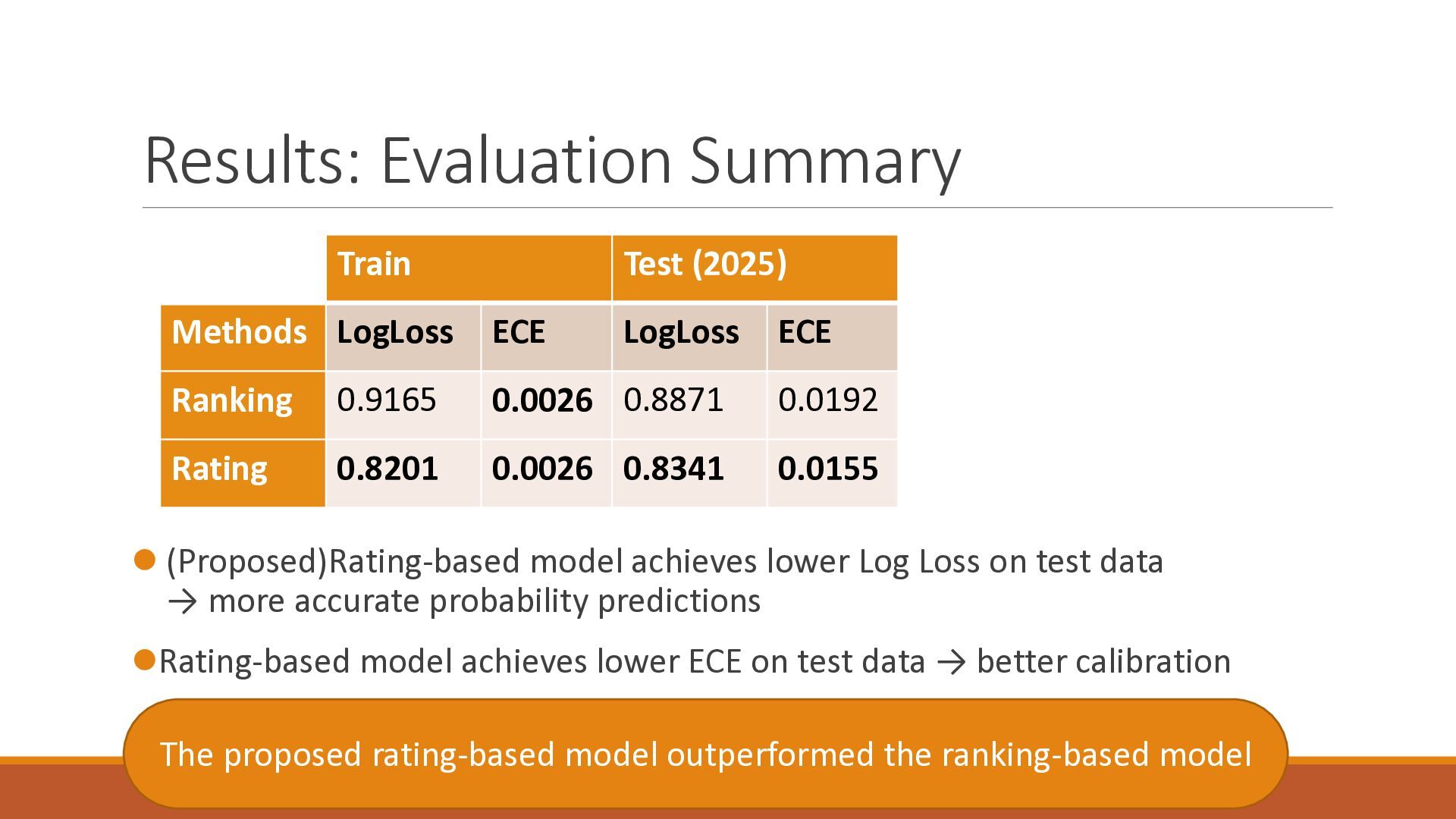
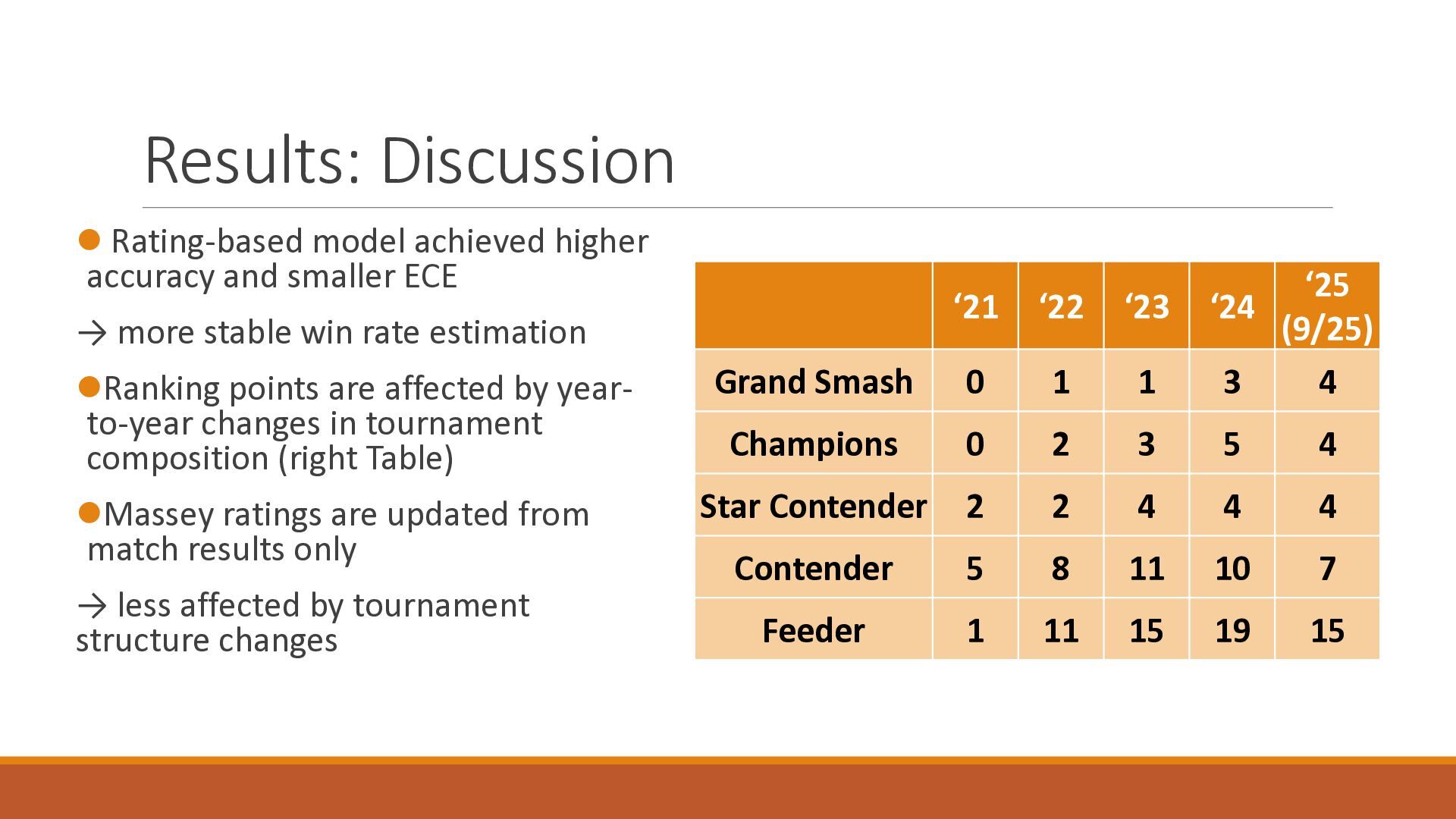
The 18th Australasian Conference on Mathematics and Computers in Sport (2026/7/1-3) で大学院生が発表したスライドです.卓球の世界ランキングの予測能力を定量的に分析したのち,ゲーム数を考慮したMassey法が予測能力を改善することを確認しました.
https://www.anziam.org.au/The+18th+Australasian+Conference+on+Mathematics+and+Computers+in+Sport
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}