論文紹介: Training Classifiers with Natural Language Explanations
TFUG, NN論文を肴に酒を飲む会#9
2019.9.4
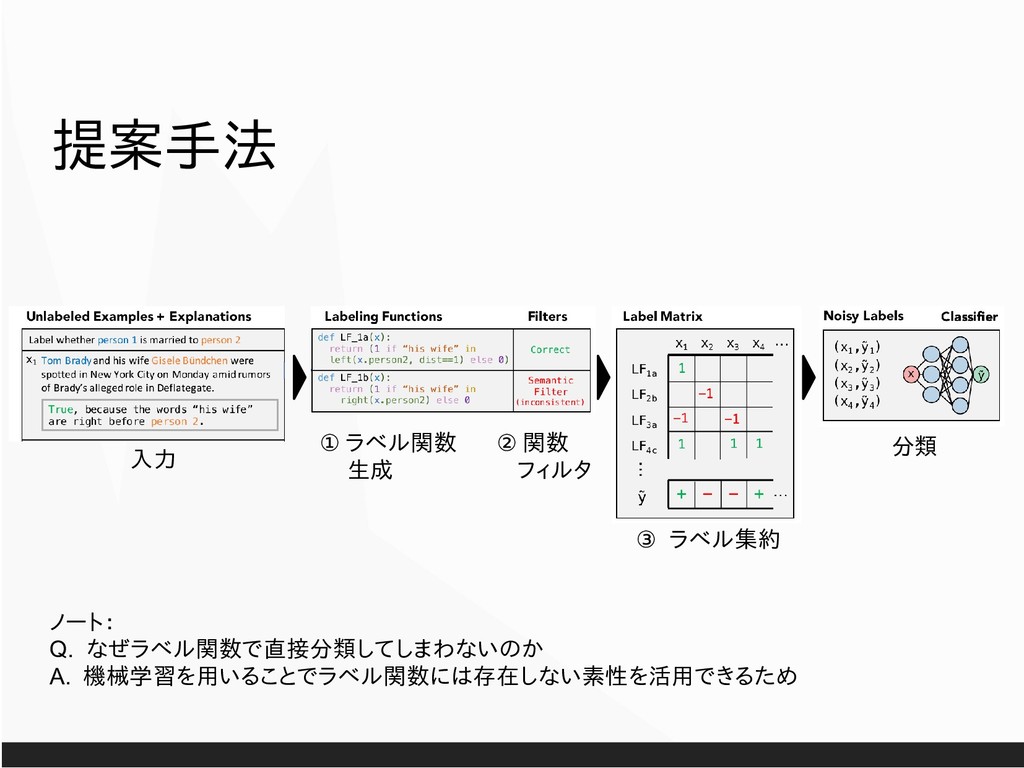
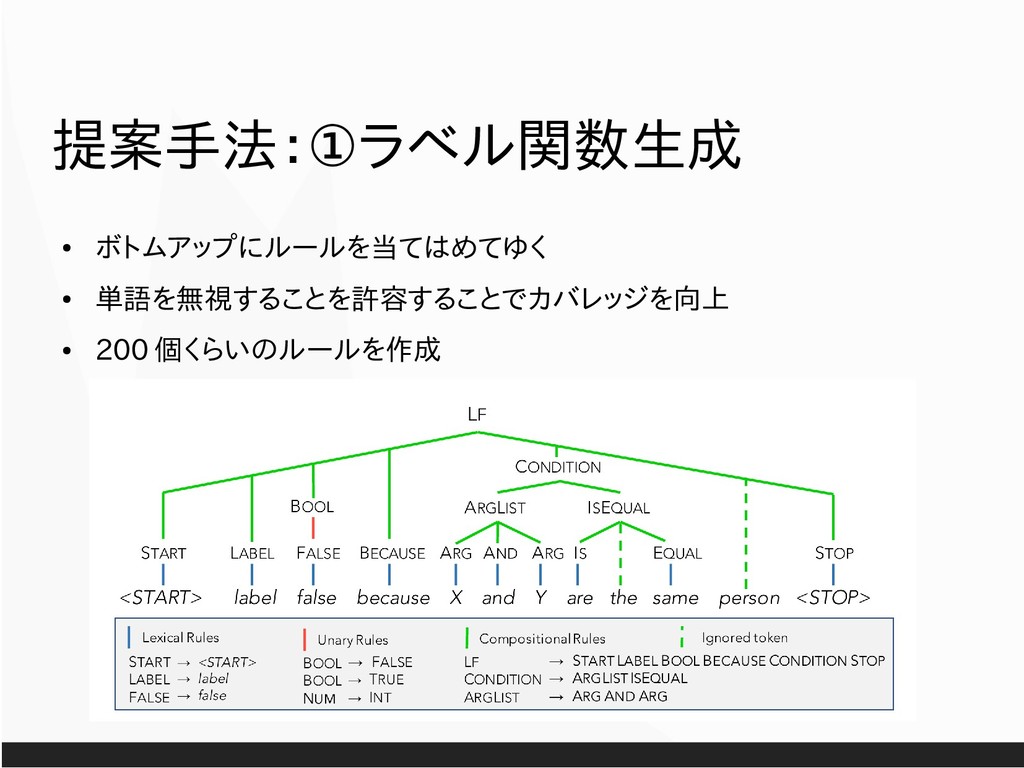
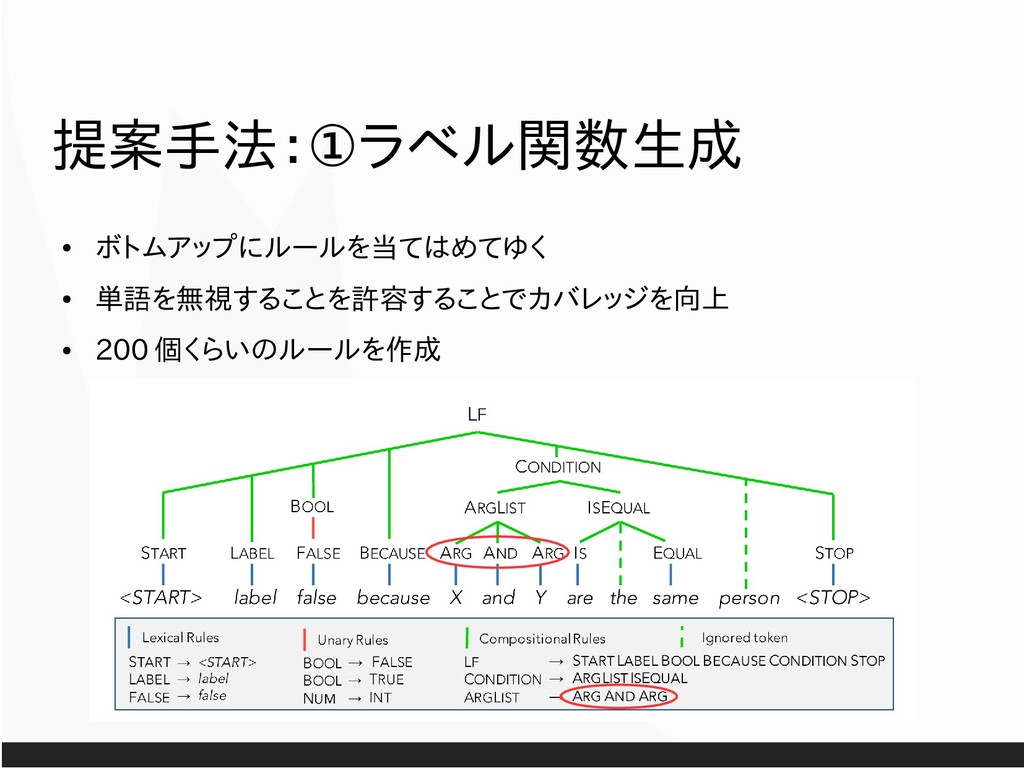
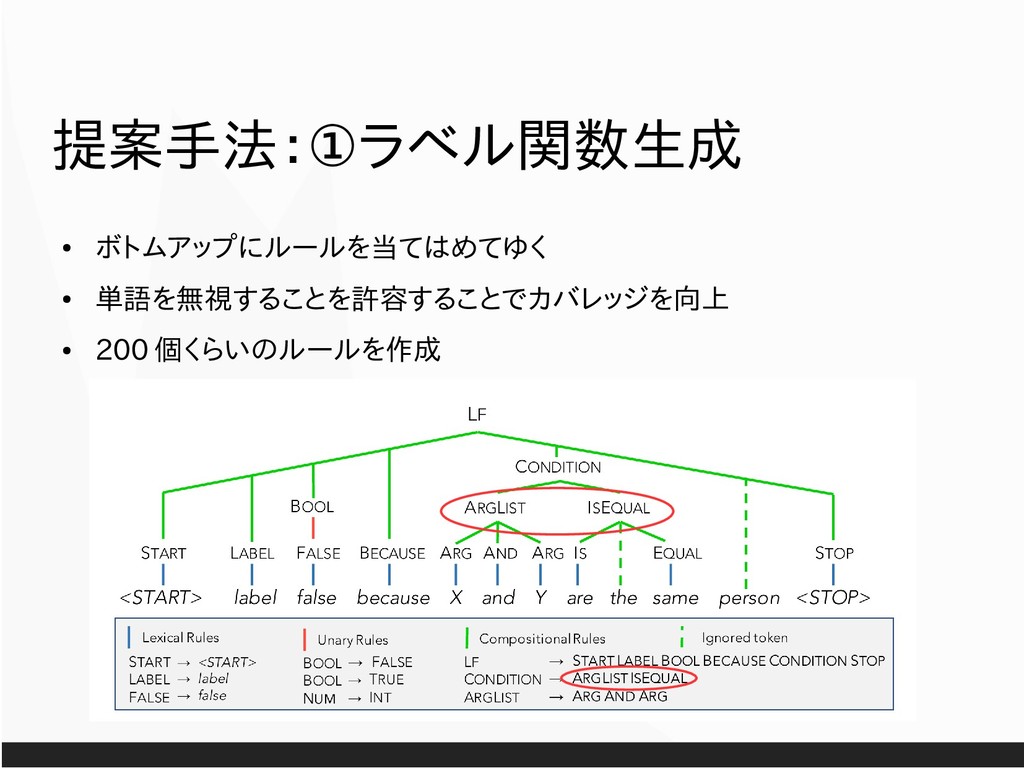
All figures from now on are cited from “Hancock et al. 2018. Training Classifiers with Natural Language Explanations. ACL.” unless otherwise specified. All texts are distributed as CC-01. Get raw slides from https://drive.google.com/open?id=1YPi9gvTtd6OEvCWKtqYVxb2BJE4EPn9f .
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}